Spark First函式
在Spark中,First函式始終返回資料集的第一個元素。它類似於take(1)。
First函式範例
在此範例中,檢索資料集的第一個元素。要在Scala模式下開啟Spark,請按照以下命令操作。
$ spark-shell
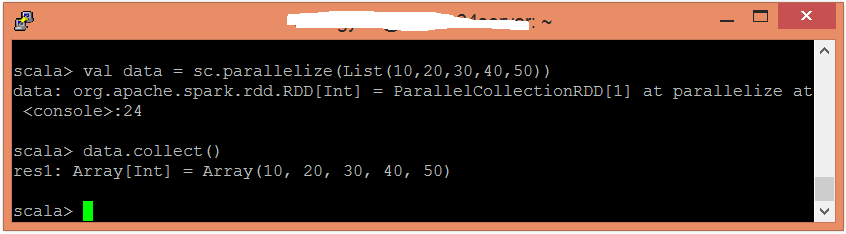
使用並行化集合建立RDD。
scala> val data = sc.parallelize(List(10,20,30,40,50))
現在,可以使用以下命令讀取生成的結果。
scala> data.collect
應用first()函式來檢索資料集的第一個元素。
scala> val firstfunc = data.first()
