Spark cogroup函式
在Spark中,cogroup函式對不同的資料集執行,比方說,(K,V)和(K,W)並返回(K,(Iterable,Iterable))元組的資料集。此操作也稱為groupWith。
cogroup函式範例
在這個例子中,將執行groupWith操作。要在Scala模式下開啟Spark,請按照以下命令操作。
$ spark-shell
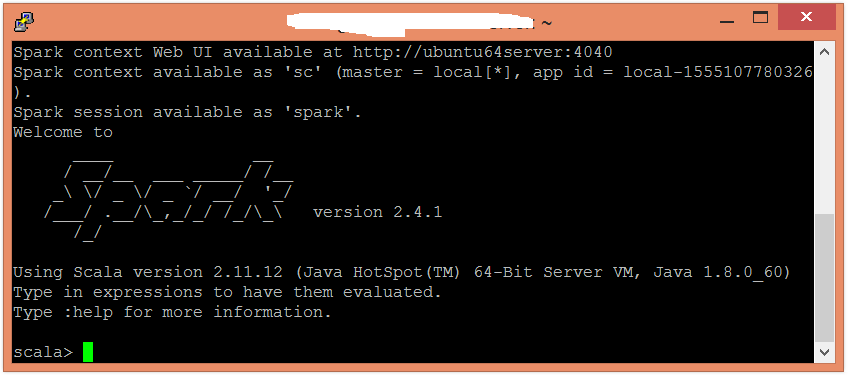
使用並行化集合建立RDD。
scala> val data1 = sc.parallelize(Seq(("A",1),("B",2),("C",3)))
現在,可以使用以下命令讀取生成的結果。
scala> data1.collect
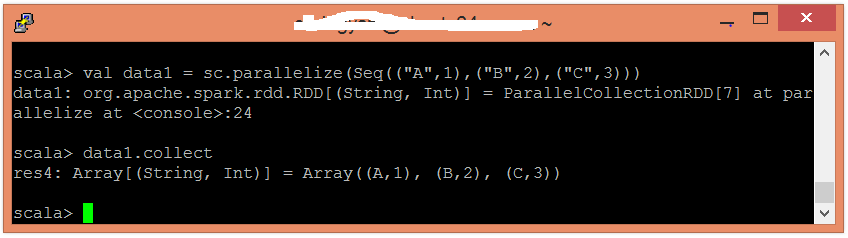
使用並行化集合建立另一個RDD。
scala> val data2 = sc.parallelize(Seq(("B",4),("E",5)))
現在,可以使用以下命令讀取生成的結果。
scala> data2.collect
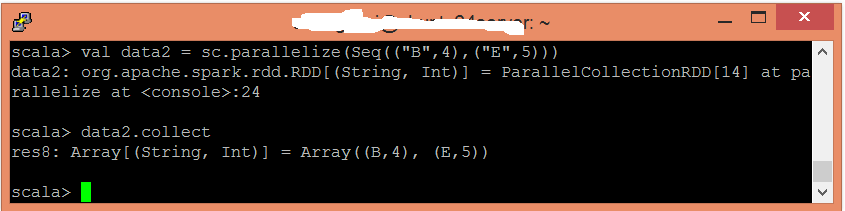
應用cogroup()函式對值進行分組。
scala> val cogroupfunc = data1.cogroup(data2)
現在,可以使用以下命令讀取生成的結果。
scala> cogroupfunc.collect
