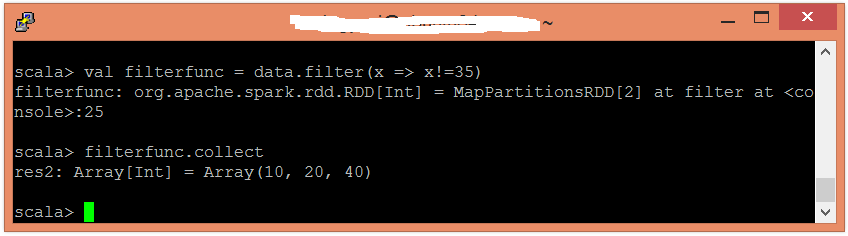
Spark Filter函式
在Spark中,Filter函式返回一個新資料集,該資料集是通過選擇函式返回true的源元素而形成的。因此,它僅檢索滿足給定條件的元素。
Filter函式範例
在此範例中,將過濾給定資料並檢索除35之外的所有值。
要在Scala模式下開啟Spark,請按照以下命令操作。
$ spark-shell
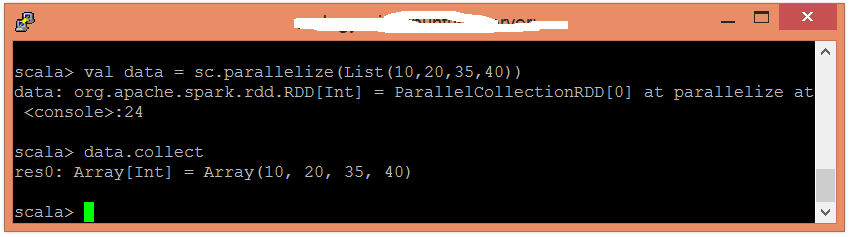
使用並行化集合建立RDD。
scala> val data = sc.parallelize(List(10,20,35,40))
現在,可以使用以下命令讀取生成的結果。
scala> data.collect
應用過濾器函式並傳遞執行所需的表示式。
scala> val filterfunc = data.filter(x => x!=35)
現在,可以使用以下命令讀取生成的結果。
scala> filterfunc.collect