強化學習
在本章中,您將詳細學習使用Python進行AI強化學習的概念。
強化學習基礎
這種型別的學習被用來加強或加強基於評論者資訊的網路。 也就是說,在強化學習下訓練的網路從環境中獲得一些反饋。 但是,反饋是評價性的,並且不像監督式學習的情況那樣具有啟發性。 基於這種反饋,網路將對權重進行調整以獲得更好的評論資訊。
這個學習過程類似於監督學習,但我們可能擁有的資訊非常少。 下圖給出了強化學習的框圖 -
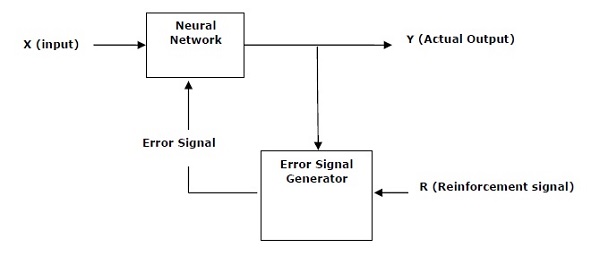
構建模組:環境和代理
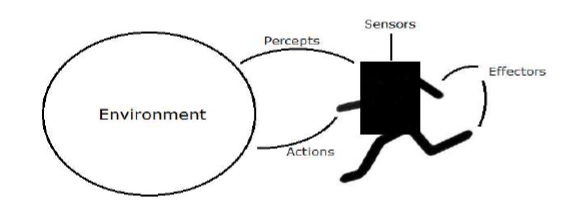
環境和代理是人工智慧強化學習的主要構件。 本節詳細討論它們 -
媒介代理
代理媒介是能夠通過感測器感知其環境並通過效應器作用於該環境的任何事物。
- 人用媒介具有與感測器平行。諸如眼睛,耳朵,鼻子,舌頭和面板之類的感覺器官以及用於效應器的諸如手,腿,嘴等其他器官。
- 機器人媒介取代了感測器的攝像頭和紅外測距儀,以及各種效應器的馬達和執行器。
- 軟體媒介已將位串編碼為其程式和操作。
代理術語
以下術語在AI中的強化學習中更頻繁地使用 -
- 代理的效能測量 - 這是決定代理成功程度的標準。
- 代理的行為 - 代理在任何給定的感知順序之後執行的行為。
- 感知 - 它是特定範例中代理的感知輸入。
- 感知序列 - 這是代理人迄今為止所了解的所有歷史。
- 代理功能 - 它是從訓示序列到動作的對映。
環境
某些程式在局限於鍵盤輸入,資料庫,計算機檔案系統和螢幕上字元輸出的完全人造環境中執行。
相比之下,一些軟體代理(如軟體機器人或軟碟機)存在於豐富且無限的軟域中。 模擬器具有非常詳細和複雜的環境。 軟體代理需要實時從多種行為中進行選擇。
例如,設計用於掃描顧客的線上偏好並向顧客展示有趣物品的軟堆可在真實環境和人工環境中工作。
環境屬性
如下所述,環境具有多重屬性 -
- 離散/連續 - 如果環境的數量有限且截然不同,則環境是離散的,否則它是連續的。 例如,象棋是一個離散的環境,駕駛是一個連續的環境。
- 可觀察/部分可觀察 - 如果可以從知覺中確定每個時間點環境的完整狀態,則可觀察到; 否則它只是部分可觀察的。
- 靜態/動態 - 如果環境在代理正在執行時沒有改變,那麼它是靜態的; 否則它是動態的。
- 單個代理/多個代理 - 環境可能包含其他代理,這些代理可能與代理的型別相同或不同。
- 可存取/不可存取 - 如果代理的感測裝置可以存取完整的環境狀態,則可以存取該代理的環境; 否則它是無法存取的。
- 確定性/非確定性 - 如果環境的下一個狀態完全由當前狀態和代理的行為決定,那麼環境是確定性的; 否則它是非確定性的。
- 情節式/非情節式 - 在情節化環境中,每個情節由代理人感知並然後行動組成。 其行動的品質取決於情節本身。 隨後的劇集不依賴於前幾集中的動作。 情景環境要簡單得多,因為代理人不需要提前思考。
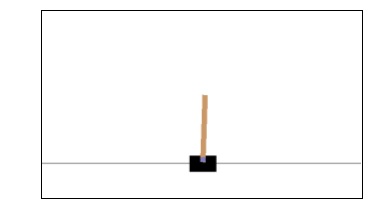
用Python構建環境
對於建設強化學習代理,將使用OpenAI Gym軟體包,該軟體包可使用以下命令來安裝 -
pip install gym
OpenAI健身房有各種各樣的環境可以用於各種目的。 其中很少是:Cartpole-v0,Hopper-v1和MsPacman-v0。 他們需要不同的引擎。 OpenAI Gym的詳細文件可以在 https://gym.openai.com/docs/ 找到。
以下程式碼顯示了cartpole-v0環境的Python程式碼範例 -
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())
您可以用類似的方式構建其他環境。
用Python構建一個學習代理
對於構建強化學習代理,我們將使用如下所示的OpenAI Gym包 -
import gym
env = gym.make('CartPole-v0')
for _ in range(20):
observation = env.reset()
for i in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(i+1))
break
觀察小推車可以平衡。