人工智慧無監督學習:聚類
無監督機器學習演算法沒有任何監督者提供任何指導。 這就是為什麼它們與真正的人工智慧緊密結合的原因。
在無人監督的學習中,沒有正確的答案,也沒有監督者指導。 演算法需要發現用於學習的有趣資料模式。
什麼是聚類?
基本上,它是一種無監督學習方法,也是用於許多領域的統計資料分析的常用技術。 聚類主要是將觀測集合劃分為子集(稱為聚類)的任務,以同一聚類中的觀測在一種意義上相似並且與其他聚類中的觀測不相似的方式。 簡而言之,可以說聚類的主要目標是根據相似性和不相似性對資料進行分組。
例如,下圖顯示了不同群集中的類似資料 -
資料聚類演算法
以下是資料聚類的幾種常用演算法 -
K-Means演算法
K均值聚類演算法是眾所周知的資料聚類演算法之一。 我們需要假設簇的數量已經是已知的。 這也被稱為平面聚類。 它是一種疊代聚類演算法。 該演算法需要遵循以下步驟 -
第1步 - 需要指定所需的K個子組的數量。
第2步 - 修復群集數量並將每個資料點隨機分配到群集。 換句話說,我們需要根據群集數量對資料進行分類。
在這一步中,計算聚類質心。
由於這是一種疊代演算法,因此需要在每次疊代中更新K個質心的位置,直到找到全域性最優值或換句話說質心到達其最佳位置。
以下程式碼將有助於在Python中實現K-means聚類演算法。 我們將使用Scikit-learn模組。
匯入必需的軟體包 -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
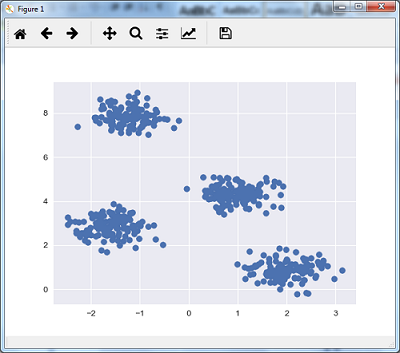
以下程式碼行將通過使用sklearn.dataset包中的make_blob來生成包含四個blob的二維資料集。
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)
可以使用下面的程式碼視覺化資料集 -
plt.scatter(X[:, 0], X[:, 1], s = 50);
plt.show()
得到以下結果 -
在這裡,將kmeans初始化為KMeans演算法,以及多少個群集(n_clusters)所需的引數。
kmeans = KMeans(n_clusters = 4)
需要用輸入資料訓練K-means模型。
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis')
centers = kmeans.cluster_centers_
下面給出的程式碼將根據資料繪製和視覺化機器的發現,並根據要找到的聚類數量進行擬合。
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5);
plt.show()
得到以下結果 -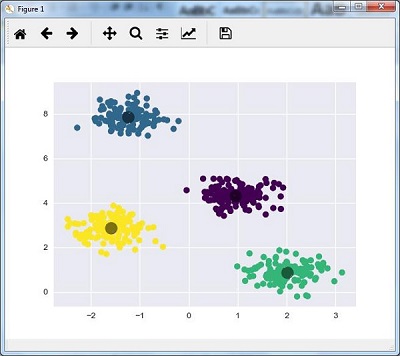
均值偏移演算法
它是另一種在無監督學習中使用的流行和強大的聚類演算法。 它不做任何假設,因此它是非引數演算法。 它也被稱為分層聚類或均值聚類分析。 以下將是該演算法的基本步驟 -
- 首先,需要從分配給它們自己的叢集的資料點開始。
- 現在,它計算質心並更新新質心的位置。
- 通過重複這個過程,向簇的頂點靠近,即朝向更高密度的區域移動。
- 該演算法停止在質心不再移動的階段。
在下面的程式碼的幫助下,在Python中實現了Mean Shift聚類演算法。使用Scikit-learn模組。
匯入必要的軟體包 -
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
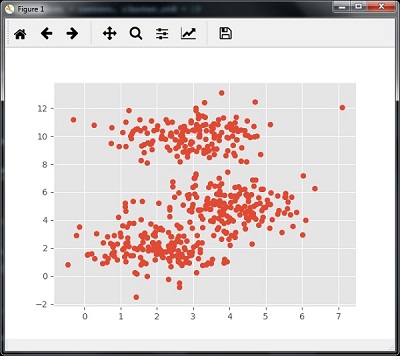
以下程式碼將通過使用sklearn.dataset包中的make_blob來生成包含四個blob的二維資料集。
from sklearn.datasets.samples_generator import make_blobs
可以用下面的程式碼視覺化資料集 -
centers = [[2,2],[4,5],[3,10]]
X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1)
plt.scatter(X[:,0],X[:,1])
plt.show()
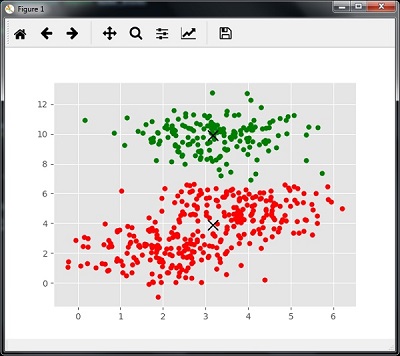
執行上面範例程式碼,得到以下結果 -
現在,我們需要用輸入資料來訓練Mean Shift聚類模型。
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
以下程式碼將按照輸入資料列印聚類中心和預期的聚類數量 -
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2
下面給出的程式碼將有助於根據資料繪製和視覺化機器的發現,並根據要找到的聚類數量進行裝配。
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10)
plt.show()
執行上面範例程式碼,得到以下結果 -
測量群集效能
現實世界的資料不是自然地組織成許多獨特的群集。 由於這個原因,要想象和推斷推理並不容易。 這就是為什麼需要測量聚類效能及其品質。 它可以在輪廓分析的幫助下完成。
輪廓分析
該方法可用於通過測量群集之間的距離來檢查聚類的品質。 基本上,它提供了一種通過給出輪廓分數來評估像叢集數量這樣的引數的方法。 此分數是衡量一個群集中每個點與相鄰群集中的點的距離的度量。
分析輪廓分數
得分範圍為[-1,1]。 以下是對這個分數的分析 -
- 得分為+1分 - 得分接近+1表示樣本距離相鄰叢集很遠。
- 得分為0分 - 得分0表示樣本與兩個相鄰群集之間的決策邊界處於或非常接近。
- 得分為-1分 - 得分為負分數表示樣本已分配到錯誤的群集。
計算輪廓分數
在本節中,我們將學習如何計算輪廓分數。
輪廓分數可以通過使用以下公式來計算 -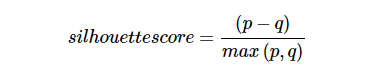
這裡,`