人工智慧監督學習(分類)
在本章中,我們將重點討論監督式學習 - 分類。
分類技術或模型試圖從觀測值中得出一些結論。 在分類問題中,我們有分類輸出,如「黑色」或「白色」或「教學」和「非教學」。 在構建分類模型時,需要有包含資料點和相應標籤的訓練資料集。 例如,如果想檢查影象是否屬於汽車。 要實現這個檢查,我們將建立一個訓練資料集,其中包含與「車」和「無車」相關的兩個類。 然後需要使用訓練樣本來訓練模型。 分類模型主要用於臉部辨識,垃圾郵件識別等。
在Python中構建分類器的步驟
為了在Python中構建分類器,將使用Python 3和Scikit-learn,這是一個用於機器學習的工具。 按照以下步驟在Python中構建分類器 -
第1步 - 匯入Scikit-learn
這將是在Python中構建分類器的第一步。 在這一步中,將安裝一個名為Scikit-learn的Python包,它是Python中最好的機器學習模組之一。 以下命令匯入包 -
import sklearn
第2步 - 匯入Scikit-learn的資料集
在這一步中,我們可以開始使用機器學習模型的資料集。 在這裡,將使用乳腺癌威斯康星診斷資料庫。 資料集包括有關乳腺癌腫瘤的各種資訊,以及惡性或良性分類標籤。 該資料集在569個腫瘤上具有569個範例或資料,並且包括關於30個屬性或特徵(諸如腫瘤的半徑,紋理,光滑度和面積)的資訊。 借助以下命令,匯入Scikit-learn的乳腺癌資料集 -
from sklearn.datasets import load_breast_cancer
現在,以下命令將載入資料集。
data = load_breast_cancer()
以下是字典鍵列表 -
- 分類標籤名稱(target_names)
- 實際標籤(目標)
- 屬性/功能名稱(feature_names)
- 屬性(資料)
現在,使用以下命令,可以為每個重要資訊集建立新變數並分配資料。 換句話說,可以用下列命令組織資料 -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
現在,為了使它更清晰,可以使用以下命令來列印類標籤,第一個資料範例的標籤,我們的功能名稱和功能的值 -
print(label_names)
上述命令將分別列印惡性和良性的分類名稱。輸出結果如下 -
['malignant' 'benign']
現在,下面的命令將顯示它們被對映到二進位制值0和1。這裡0表示惡性腫瘤,1表示良性癌症。得到以下輸出 -
print(labels[0])
0
下面給出的兩個命令將生成功能名稱和功能值。
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]
從上面的輸出中,可以看到第一個資料範例是一個半徑為1.7990000e + 01的惡性腫瘤。
第3步 - 組織資料
在這一步中,將把資料分成兩部分,即訓練集和測試集。 將資料分割成這些集合非常重要,因為必須在未看到的資料上測試模型。要將資料分成集合,sklearn有一個叫做train_test_split()函式的函式。 在以下命令的幫助下,可以分割這些集合中的資料 -
from sklearn.model_selection import train_test_split
上述命令將從sklearn中匯入train_test_split函式,下面的命令將資料分解為訓練和測試資料。 在下面給出的例子中,使用40%的資料進行測試,其餘資料將用於訓練模型。
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)
第4步 - 建立模型
在這一步中,我們將建立模型。使用樸素貝葉斯演算法來構建模型。 以下命令可用於構建模型 -
from sklearn.naive_bayes import GaussianNB
上述命令將匯入GaussianNB模組。 現在,以下命令用來初始化模型。
gnb = GaussianNB()
將通過使用gnb.fit()將它擬合到資料來訓練模型。
model = gnb.fit(train, train_labels)
第5步 - 評估模型及其準確性
在這一步中,我們將通過對測試資料進行預測來評估模型。為了做出預測,我們將使用predict()函式。 以下命令做到這一點 -
preds = gnb.predict(test)
print(preds)
## -- 結果如下
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
上述0和1系列是腫瘤類別的預測值 - 惡性和良性。
現在,通過比較兩個陣列即test_labels和preds,可以發現模型的準確性。使用accuracy_score()函式來確定準確性。 考慮下面的命令 -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965
結果顯示Na?veBayes分類器準確率為95.17%。
通過這種方式,借助上述步驟,我們可以使用Python構建分類器。
在Python中構建分類器
在本節中,我們將學習如何在Python中構建分類器。
樸素貝葉斯分類器
樸素貝葉斯是一種使用貝葉斯定理建立分類器的分類技術。 假設是預測變數是獨立的。 簡而言之,它假設類中某個特徵的存在與任何其他特徵的存在無關。要構建樸素貝葉斯分類器,我們需要使用名為scikit learn的python庫。 在scikit學習包中,有三種型別的樸素貝葉斯模型被稱為Gaussian,Multinomial和Bernoulli。
要構建樸素貝葉斯機器學習分類器模型,需要以下「減號」
資料集
我們將使用名為Breast Cancer Wisconsin Diagnostic Database資料集。 資料集包括有關乳腺癌腫瘤的各種資訊,以及惡性或良性分類標籤。 該資料集在569個腫瘤上具有569個範例或資料,並且包括關於30個屬性或特徵(諸如腫瘤的半徑,紋理,光滑度和面積)的資訊。可以從sklearn包中匯入這個資料集。
樸素貝葉斯模型
為了構建樸素貝葉斯分類器,需要一個樸素貝葉斯模型。 如前所述,scikit學習包中有三種型別的Na?veBayes模型,分別稱為Gaussian,Multinomial和Bernoulli。 在下面的例子中,將使用高斯樸素貝葉斯模型。
通過使用上述內容,我們將建立一個樸素貝葉斯機器學習模型來使用腫瘤資訊來預測腫瘤是否是惡性的或良性的。
首先,我們需要安裝sklearn模組。 它可以通過以下命令完成 -
import sklearn
現在,需要匯入名為Breast Cancer Wisconsin Diagnostic Database的資料集。
from sklearn.datasets import load_breast_cancer
現在,以下命令將載入資料集。
data = load_breast_cancer()
資料可以按如下方式組織 -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
現在,為了使它更清晰,可以在以下命令的幫助下列印類標籤,第一個資料範例的標籤,功能名稱和功能的值 -
print(label_names)
上述命令將分別列印惡性和良性的類名。 它顯示為下面的輸出 -
['malignant' 'benign']
現在,下面給出的命令將顯示它們對映到二進位制值0和1。這裡0表示惡性腫瘤,1表示良性癌症。 它顯示為下面的輸出 -
print(labels[0])
0
以下兩個命令將生成功能名稱和功能值。
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]
從以上輸出可以看出,第一個資料範例是一個主要半徑為1.7990000e + 01的惡性腫瘤。
要在未看到的資料上測試模型,我們需要將資料分解為訓練和測試資料。 它可以在下面的程式碼的幫助下完成 -
from sklearn.model_selection import train_test_split
上述命令將從sklearn中匯入train_test_split函式,下面的命令將資料分解為訓練和測試資料。 在下面的例子中,使用40%的資料進行測試,並將提示資料用於訓練模型。
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)
現在,使用以下命令構建模型 -
from sklearn.naive_bayes import GaussianNB
上述命令將從sklearn中匯入train_test_split函式,下面的命令將資料分解為訓練和測試資料。 在下面的例子中,我們使用40%的資料進行測試,並將提示資料用於訓練模型。
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)
現在,使用以下命令構建模型 -
from sklearn.naive_bayes import GaussianNB
上述命令將匯入GaussianNB模組。 現在,使用下面給出的命令,需要初始化模型。
gnb = GaussianNB()
將通過使用gnb.fit()將它擬合到資料來訓練模型。
model = gnb.fit(train, train_labels)
現在,通過對測試資料進行預測來評估模型,並且可以按如下方式完成 -
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
上述0和1系列是腫瘤類別的預測值,即惡性和良性。
現在,通過比較兩個陣列即test_labels和preds,可以看到模型的準確性。 我們將使用accuracy_score()函式來確定準確性。 考慮下面的命令 -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965
結果顯示Na?veBayes分類器準確率為95.17%。
這是基於Na?veBayse高斯模型的機器學習分類器。
支援向量機(SVM)
基本上,支援向量機(SVM)是一種有監督的機器學習演算法,可用於回歸和分類。 SVM的主要概念是將每個資料項繪製為n維空間中的一個點,每個特徵的值是特定坐標的值。以下是了解SVM概念的簡單圖形表示 -
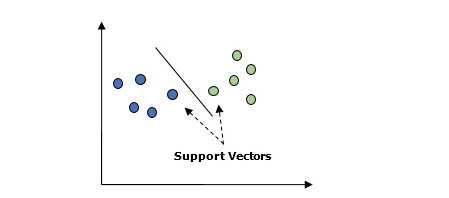
在上圖中,有兩個特徵。 因此,首先需要在二維空間中繪製這兩個變數,其中每個點都有兩個坐標,稱為支援向量。 該行將資料分成兩個不同的分類組。 這條線將是分類器。
在這裡,將使用scikit-learn和iris資料集來構建SVM分類器。 Scikitlearn庫具有sklearn.svm模組並提供sklearn.svm.svc進行分類。 下面顯示了基於4個特徵來預測虹膜植物種類的SVM分類器。
資料集
我們將使用包含3個類別(每個類別為50個範例)的虹膜資料集,其中每個類別指的是一類虹膜工廠。 每個範例具有四個特徵,即萼片長度,萼片寬度,花瓣長度和花瓣寬度。 下面顯示了基於4個特徵來預測虹膜植物分類的SVM分類器。
核心
這是SVM使用的技術。 基本上這些功能採用低維輸入空間並將其轉換到更高維空間。 它將不可分離的問題轉換成可分離的問題。 核函式可以是線性,多項式,rbf和sigmoid中的任何一種。 在這個例子中,將使用線性核心。
現在匯入下列軟體包 -
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as plt
現在,載入輸入資料 -
iris = datasets.load_iris()
我們使用前兩個功能 -
X = iris.data[:, :2]
y = iris.target
我們將用原始資料繪製支援向量機邊界,建立一個網格來繪製。
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]
需要給出正則化引數的值。
C = 1.0
需要建立SVM分類器物件。參考以下程式碼 -
Svc_classifier = svm_classifier.SVC(kernel='linear',
C=C, decision_function_shape = 'ovr').fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
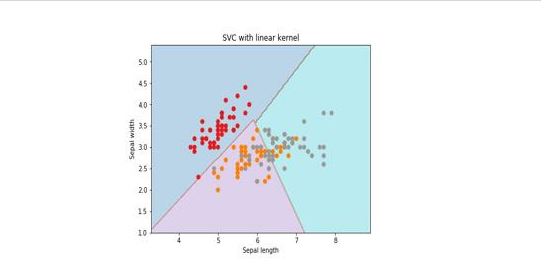
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
執行後得到以下結果 -
邏輯回歸
基本上,邏輯迴歸模型是監督分類演算法族的成員之一。 Logistic回歸通過使用邏輯函式估計概率來測量因變數和自變數之間的關係。
在這裡,如果我們討論依賴變數和獨立變數,那麼因變數就是要預測的目標類變數,另一方面,自變數是用來預測目標類的特徵。
在邏輯回歸中,估計概率意味著預測事件的可能性發生。例如,店主想要預測進入商店的顧客將購買遊戲站(例如)或不購買。顧客將會觀察到許多顧客的特徵 - 性別,年齡等,以便預測可能性的發生,即購買遊戲站或不購物。邏輯函式是用來構建具有各種引數的函式的S形曲線。
前提條件
在使用邏輯回歸構建分類器之前,我們需要在系統上安裝Tkinter軟體包。 它可以從 https://docs.python.org/2/library/tkinter.html 進行安裝。
現在,在下面給出的程式碼的幫助下,可以使用邏輯回歸來建立分類器 -
首先,匯入一些軟體包 -
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
現在,需要定義可以完成的樣本資料,如下所示 -
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4],
[3.2, 0.9], [2.9, 1.9],[2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])
接下來,我們需要建立邏輯迴歸分類器,可以按如下方式完成 -
Classifier_LR = linear_model.LogisticRegression(solver = 'liblinear', C = 75)
最後但重要的是,我們需要訓練這個分類器 -
Classifier_LR.fit(X, y)
現在,我們如何視覺化輸出? 可以通過建立一個名為Logistic_visualize()的函式來完成 -
Def Logistic_visualize(Classifier_LR, X, y):
min_x, max_x = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
min_y, max_y = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0
在上面的行中,我們定義了在網格中使用的最小值和最大值X和Y。另外,還將定義繪製網格的步長。
mesh_step_size = 0.02
下面定義X和Y值的網格,如下所示 -
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size),
np.arange(min_y, max_y, mesh_step_size))
使用以下程式碼,可以在網格網格上執行分類器 -
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = 'black',
linewidth=1, cmap = plt.cm.Paired)
以下程式碼行將指定圖的邊界 -
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(X[:, 0].min() - 1), int(X[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(X[:, 1].min() - 1), int(X[:, 1].max() + 1), 1.0)))
plt.show()
現在,在執行程式碼之後,我們將得到以下輸出,邏輯迴歸分類器 -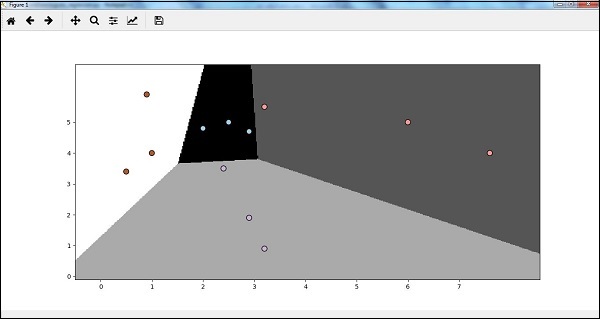
決策樹分類器
決策樹基本上是一個二元樹流程圖,其中每個節點根據某個特徵變數分割一組觀察值。
在這裡,我們正在構建一個用於預測男性或女性的決策樹分類器。這裡將採取一個非常小的資料集,有19個樣本。 這些樣本將包含兩個特徵 - 「身高」和「頭髮長度」。
前提條件
為了構建以下分類器,我們需要安裝pydotplus和graphviz。 基本上,graphviz是使用點檔案繪製圖形的工具,pydotplus是Graphviz的Dot語言模組。 它可以與包管理器或使用pip來安裝。
現在,可以在以下Python程式碼的幫助下構建決策樹分類器 -
首先,匯入一些重要的庫如下 -
import pydotplus
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn import cross_validation
import collections
現在,提供如下資料集 -
X = [[165,19],[175,32],[136,35],[174,65],[141,28],[176,15],[131,32],
[166,6],[128,32],[179,10],[136,34],[186,2],[126,25],[176,28],[112,38],
[169,9],[171,36],[116,25],[196,25]]
Y = ['Man','Woman','Woman','Man','Woman','Man','Woman','Man','Woman',
'Man','Woman','Man','Woman','Woman','Woman','Man','Woman','Woman','Man']
data_feature_names = ['height','length of hair']
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split
(X, Y, test_size=0.40, random_state=5)
在提供資料集之後,需要擬合可以如下完成的模型 -
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,Y)
預測可以使用以下Python程式碼來完成 -
prediction = clf.predict([[133,37]])
print(prediction)
使用以下Python程式碼來實現視覺化決策樹 -
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names,
out_file = None,filled = True,rounded = True)
graph = pydotplus.graph_from_dot_data(dot_data)
colors = ('orange', 'yellow')
edges = collections.defaultdict(list)
for edge in graph.get_edge_list():
edges[edge.get_source()].append(int(edge.get_destination()))
for edge in edges: edges[edge].sort()
for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0]
dest.set_fillcolor(colors[i])
graph.write_png('Decisiontree16.png')
它會將上述程式碼的預測作為[‘Woman’]並建立以下決策樹 -
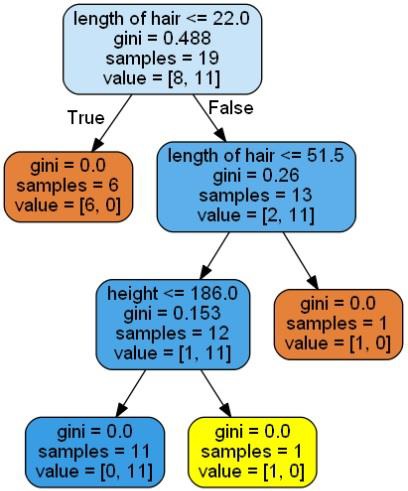
可以改變預測中的特徵值來測試它。
隨機森林分類器
整合方法是將機器學習模型組合成更強大的機器學習模型的方法。 隨機森林是決策樹的集合,就是其中之一。 它比單一決策樹好,因為在保留預測能力的同時,通過平均結果可以減少過度擬合。 在這裡,我們將在scikit學習癌症資料集上實施隨機森林模型。
匯入必要的軟體包 -
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as np
現在,需要按照以下方式提供資料集
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)
在提供資料集之後,需要擬合可以如下完成的模型 -
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)
現在,獲得訓練以及測試子集的準確性:如果增加估計器的數量,那麼測試子集的準確性也會增加。
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train)))
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test)))
上面程式碼,輸出結果如下所示 -
Accuracy on the training subset:(:.3f) 1.0
Accuracy on the training subset:(:.3f) 0.965034965034965
現在,與決策樹一樣,隨機森林具有feature_importance模組,它將提供比決策樹更好的特徵權重檢視。 它可以如下繪製和視覺化 -
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()
執行上面程式碼,得到以下輸出結果 -
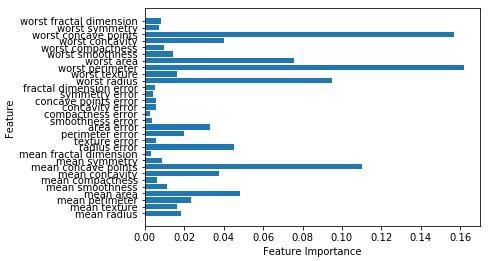
分類器的效能
在實現機器學習演算法之後,我們需要找出模型的有效性。 衡量有效性的標準可以基於資料集和度量標準。 為了評估不同的機器學習演算法,我們可以使用不同的效能指標。 例如,假設使用分類器來區分不同物件的影象,可以使用分類效能指標,如平均準確率,AUC等。從某種意義上說,我們選擇評估機器學習模型的指標是非常重要的,因為指標的選擇會影響機器學習演算法的效能如何被測量和比較。 以下是一些指標 -
混亂矩陣
基本上它用於輸出可以是兩種或更多種類的分類問題。 這是衡量分類器效能的最簡單方法。 混淆矩陣基本上是一個包含兩個維度即「實際」和「預測」的表格。 這兩個維度都有「真正的正面(TP)」,「真正的負面(TN)」,「錯誤的正面(FP)」,「錯誤的否定(FN)」。
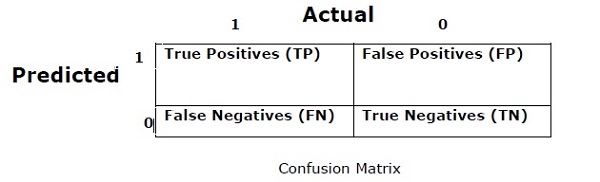
在上面的混淆矩陣中,1表示正類,0表示負類。
以下是與混淆矩陣相關的術語 -
- 真正 - 當實際的資料點類別為1並且預測也為1時,TP就是這種情況。
- 真負 - 當資料點的實際類別為0並且預測也為0時,TN就是這種情況。
- 假正 - 當實際的資料點類別為0並且預測也為1時,FP就是這種情況。
- 假負 - FN是資料點的實際類別為1且預測也為
0的情況。
準確性
混淆矩陣本身並不是一個效能指標,但幾乎所有的效能矩陣均基於混淆矩陣。 其中之一是準確性。 在分類問題中,它可能被定義為由模型對各種預測所做的正確預測的數量。 計算準確度的公式如下 -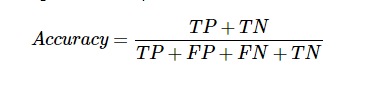
精確
它主要用於檔案檢索。 它可能被定義為返回的檔案有多少是正確的。 以下是計算精度的公式 -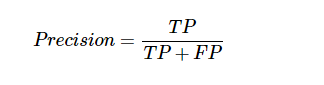
召回或靈敏度
它可能被定義為模型返回的正數有多少。 以下是計算模型召回/靈敏度的公式 -
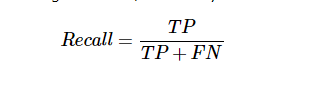
特異性
它可以定義為模型返回的負數有多少。 這與召回完全相反。 以下是計算模型特異性的公式 -
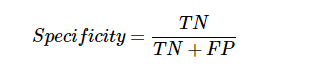
分類失衡問題
分類不平衡是屬於一個類別的觀察數量顯著低於屬於其他類別的觀測數量的場景。 例如,在我們需要識別罕見疾病,銀行欺詐性交易等情況下,這個問題非常突出。
不平衡分類的例子
讓我們考慮一個欺詐檢測資料集的例子來理解不平衡分類的概念 -
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
解決
平衡類的行為,解決不平衡的類問題。 平衡類的主要目標是增加少數類的頻率或減少多數類的頻率。 以下是解決失衡類問題的方法 -
重取樣
重新取樣是用於重建樣本資料集的一系列方法 - 包括訓練集和測試集。 重新抽樣是為了提高模型的準確性。 以下是一些重新抽樣技術 -
- 隨機抽樣 - 這項技術旨在通過隨機排除大多數類別的例子來平衡課堂分布。 這樣做直到大多數和少數群體的範例得到平衡。
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
在這種情況下,我們將10%的樣本從非欺詐範例中取而代之,然後將它們與欺詐範例相結合 -
隨機抽樣後的非欺詐性觀察:4950的10% = 495
將他們與欺詐觀察結合後的總觀測值: 50 + 495 = 545
因此,現在,低取樣後新資料集的事件率為: 9%
這種技術的主要優點是可以減少執行時間並改善儲存。 但另一方面,它可以丟棄有用的資訊,同時減少訓練資料樣本的數量。
- 隨機抽樣 - 這種技術旨在通過復制少數類中的範例數量來平衡類分布。
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
如果複製50次欺詐性觀察30次,那麼在複製少數類別觀察值後欺詐觀察值將為1500。然後,在過取樣後新資料中的總觀察值將為:4950 + 1500 = 6450。因此,新資料集的事件率是:1500/6450 = 23%。
這種方法的主要優點是不會丟失有用的資訊。 但另一方面,由於它複製了少數族群的事件,因此它有更多的過度機會。
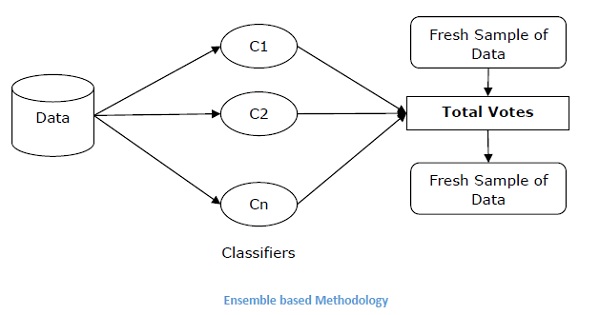
合奏技巧
這種方法基本上用於修改現有的分類演算法,使其適用於不平衡的資料集。 在這種方法中,我們從原始資料中構建幾個兩階段分類器,然後彙總它們的預測。 隨機森林分類器是基於集合的分類器的一個例子。