Hadoop HDFS入門
HDFS叢集主要由 NameNode 管理檔案系統 Metadata 和 DataNodes 儲存的實際資料。
-
NameNode: NameNode可以被認為是系統的主站。它維護所有系統中存在的檔案和目錄的檔案系統樹和後設資料 。 兩個檔案:“名稱空間映像“和”編輯紀錄檔“是用來儲存後設資料資訊。Namenode 有所有包含資料塊為一個給定的檔案中的資料節點的知識,但是不儲存塊的位置持續。從資料節點在系統每次啟動時資訊重構一次。
-
DataNode : DataNodes作為從機,每台機器位於一個叢集中,並提供實際的儲存. 它負責為客戶讀寫請求服務。
HDFS中的讀/寫操作執行在塊級。HDFS資料檔案被分成塊大小的塊,這是作為獨立的單元儲存。預設塊大小為64 MB。
HDFS操作上是資料複製的概念,其中在資料塊的多個副本被建立,分布在整個節點的群集以使在節點故障的情況下資料的高可用性。
註: 在HDFS的檔案,比單個塊小,不占用塊的全部儲存。
在HDFS讀操作
資料讀取請求將由 HDFS,NameNode和DataNode來服務。讓我們把讀取器叫 “客戶”。下圖描繪了檔案的讀取操作在 Hadoop 中。
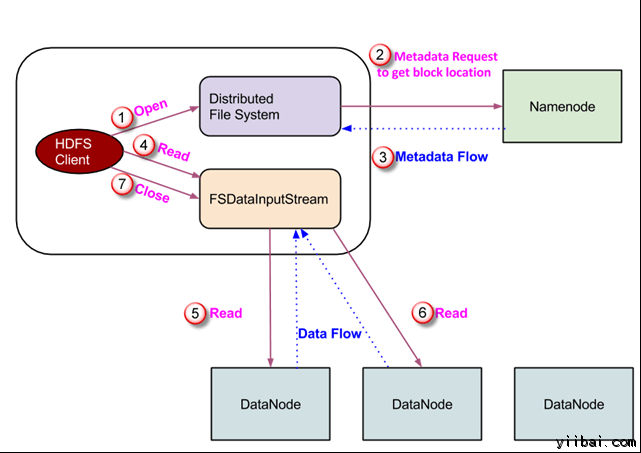
- 用戶端啟動通過呼叫檔案系統物件的 open() 方法讀取請求; 它是 DistributedFileSystem 型別的物件。
- 此物件使用 RPC 連線到 namenode 並獲取的後設資料資訊,如該檔案的塊的位置。 請注意,這些地址是檔案的前幾個塊。
- 響應該後設資料請求,具有該塊副本的 DataNodes 地址被返回。
-
一旦接收到 DataNodes 的地址,FSDataInputStream 型別的一個物件被返回到用戶端。 FSDataInputStream 包含 DFSInputStream 這需要處理互動 DataNode 和 NameNode。在上圖所示的步驟4,用戶端呼叫 read() 方法,這將導致 DFSInputStream 建立與第一個 DataNode 檔案的第一個塊連線。
-
以資料流的形式讀取資料,其中用戶端多次呼叫 “read() ” 方法。 read() 操作這個過程一直持續,直到它到達塊結束位置。
- 一旦到模組的結尾,DFSInputStream 關閉連線,移動定位到下一個 DataNode 的下一個塊
- 一旦用戶端已讀取完成後,它會呼叫 close()方法。
HDFS寫操作
在本節中,我們將了解如何通過的檔案將資料寫入到 HDFS。
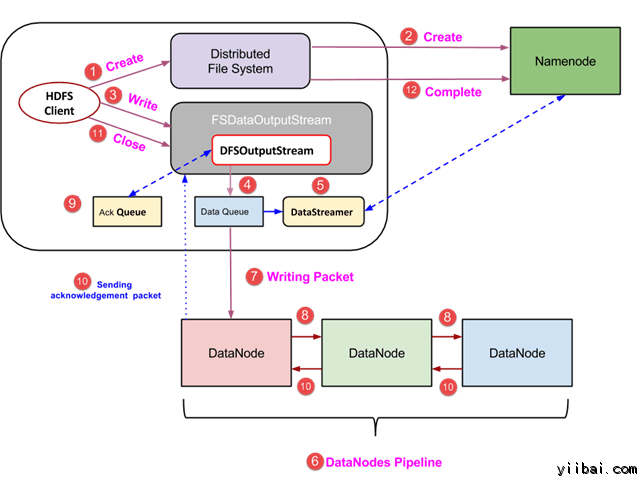
- 用戶端通過呼叫 DistributedFileSystem物件的 create() 方法建立一個新的檔案,並開始寫操作 - 在上面的圖中的步驟1
- DistributedFileSystem物件使用 RPC 呼叫連線到 NameNode,並啟動新的檔案建立。但是,此檔案建立操作不與檔案任何塊相關聯。NameNode 的責任是驗證檔案(其正被建立的)不存在,並且用戶端具有正確許可權來建立新檔案。如果檔案已經存在,或者用戶端不具有足夠的許可權來建立一個新的檔案,則丟擲 IOException 到用戶端。否則操作成功,並且該檔案新的記錄是由 NameNode 建立。
- 一旦 NameNode 建立一條新的記錄,返回FSDataOutputStream 型別的一個物件到用戶端。用戶端使用它來寫入資料到 HDFS。資料寫入方法被呼叫(圖中的步驟3)。
- FSDataOutputStream包含DFSOutputStream物件,它使用 DataNodes 和 NameNode 通訊後查詢。當客戶機繼續寫入資料,DFSOutputStream 繼續建立這個資料包。這些資料包連線排隊到一個佇列被稱為 DataQueue
- 還有一個名為 DataStreamer 元件,用於消耗DataQueue。DataStreamer 也要求 NameNode 分配新的塊,揀選 DataNodes 用於複製。
- 現在,複製過程始於使用 DataNodes 建立一個管道。 在我們的例子中,選擇了複製水平3,因此有 3 個 DataNodes 管道。
- 所述 DataStreamer 注入包分成到第一個 DataNode 的管道中。
- 在每個 DataNode 的管道中儲存資料包接收並同樣轉發在第二個 DataNode 的管道中。
- 另一個佇列,“Ack Queue”是由 DFSOutputStream 保持儲存,它們是 DataNodes 等待確認的資料包。
- 一旦確認在佇列中的分組從所有 DataNodes 已接收在管道,它從 'Ack Queue' 刪除。在任何 DataNode 發生故障時,從佇列中的包重新用於操作。
- 在用戶端的資料寫入完成後,它會呼叫close()方法(第9步圖中),呼叫close()結果進入到清除快取剩餘資料包到管道之後等待確認。
- 一旦收到最終確認,NameNode 連線告訴它該檔案的寫操作完成。
使用JAVA API存取HDFS
在本節中,我們來了解 Java 介面並用它們來存取Hadoop的檔案系統。
為了使用程式設計方式與 Hadoop 檔案系統進行互動,Hadoop 提供多種 Java 類。org.apache.hadoop.fs 包中包含操縱 Hadoop 檔案系統中的檔案類工具。這些操作包括,開啟,讀取,寫入,和關閉。實際上,對於 Hadoop 檔案 API 是通用的,可以擴充套件到 HDFS 的其他檔案系統互動。
程式設計從 HDFS 讀取檔案
java.net.URL 物件是用於讀取檔案的內容。首先,我們需要讓 Java 識別 Hadoop 的 HDFS URL架構。這是通過呼叫 URL 物件的 setURLStreamHandlerFactory方法和 FsUrlStreamHandlerFactory 的一個範例琮傳遞給它。此方法只需要執行一次在每個JVM,因此,它被封閉在一個靜態塊中。
範例程式碼
|
publicclassURLCat {
static{
URL.setURLStreamHandlerFactory(newFsUrlStreamHandlerFactory());
}
publicstaticvoidmain(String[] args) throwsException {
InputStream in = null;
try{
in = newURL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally{
IOUtils.closeStream(in);
}
}
}
|
這段程式碼用於開啟和讀取檔案的內容。HDFS檔案的路徑作為命令列引數傳遞給該程式。
使用命令列介面存取HDFS
這是與 HDFS 互動的最簡單的方法之一。 命令列介面支援對檔案系統操作,例如:如讀取檔案,建立目錄,移動檔案,刪除資料,並列出目錄。
可以執行 '$HADOOP_HOME/bin/hdfs dfs -help' 來獲得每一個命令的詳細幫助。這裡, 'dfs' HDFS是一個shell命令,它支援多個子命令。首先要啟動 Haddop 服務(使用 hduser_使用者),執行命令如下:
hduser_@ubuntu:~$ su hduser_ hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-dfs.sh hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-yarn.sh
一些廣泛使用的命令的列表如下
1. 從本地檔案系統複製檔案到 HDFS
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal temp.txt /
此命令將檔案從本地檔案系統拷貝 temp.txt 檔案到 HDFS。
2. 我們可以通過以下命令列出一個目錄下存在的檔案 -ls
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -ls /


我們可以看到一個檔案 'temp.txt“(之前複製)被列在”/“目錄。
3. 以下命令將檔案從 HDFS 拷貝到本地檔案系統
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyToLocal /temp.txt
我們可以看到 temp.txt 已經複製到本地檔案系統。
4. 以下命令用來建立新的目錄
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -mkdir /mydirectory
 接下來檢查是否已經建立了目錄。現在,應該知道怎麼做了吧?
接下來檢查是否已經建立了目錄。現在,應該知道怎麼做了吧?