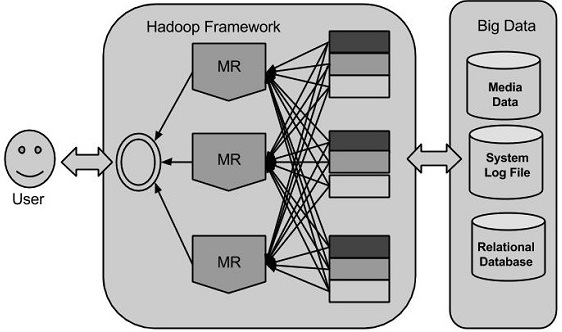
Hadoop巨量資料解決方案
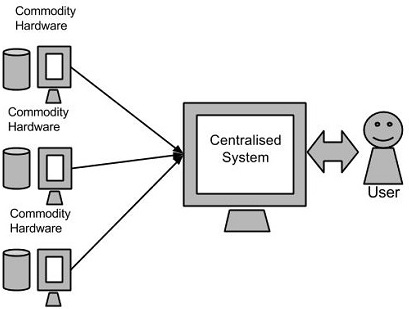
傳統的企業方法
在這種方法中,一個企業將有一個計算機儲存和處理巨量資料。對於儲存而言,程式員會自己選擇的資料庫廠商,如Oracle,IBM等的幫助下完成,使用者互動使用應用程式進而獲取並處理資料儲存和分析。
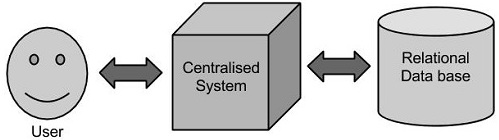
局限性
這種方式能完美地處理那些可以由標準的資料庫伺服器來儲存,或直至處理資料的處理器的限制少的大量資料應用程式。但是,當涉及到處理大量的可伸縮資料,這是一個繁忙的任務,只能通過單一的資料庫瓶頸來處理這些資料。
谷歌的解決方案
使用一種稱為MapReduce的演算法谷歌解決了這個問題。這個演算法將任務分成小份,並將它們分配到多台計算機,並且從這些機器收集結果並綜合,形成了結果資料集。
Hadoop
使用谷歌提供的解決方案,Doug Cutting和他的團隊開發了一個開源專案叫做HADOOP。
Hadoop使用的MapReduce演算法執行,其中資料在使用其他並行處理的應用程式。總之,Hadoop用於開發可以執行完整的統計分析巨量資料的應用程式。