Hadoop安裝
本教學是以Ubuntu 系統作為安裝講解環境,為了減少不必要的麻煩,請您 安裝Ubuntu 並能正常啟動進入系統。同時也必須要 安裝Java。
一、新增 Hadoop 系統使用者組和使用者
使用以下命令在終端中執行以下命令來先建立一個使用者組:yiibai@ubuntu:~$ sudo addgroup hadoop_操作結果如下:
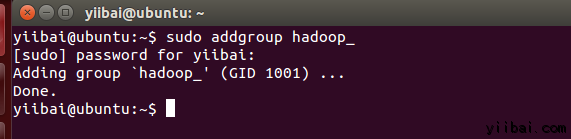

使用以下命令來新增使用者:
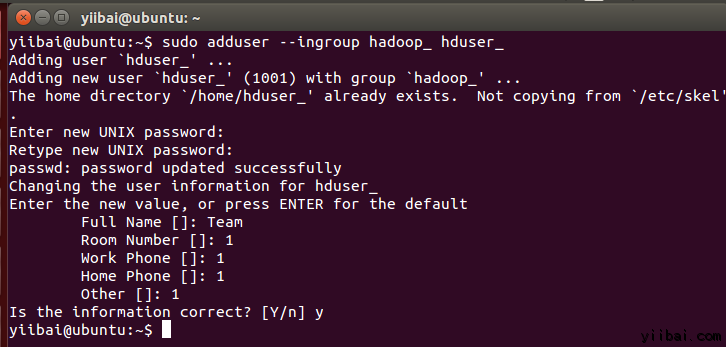
yiibai@ubuntu:~$ sudo adduser --ingroup hadoop_ hduser_
輸入您的密碼,姓名和其他詳細資訊。
二、組態SSH
為了在叢集管理節點,Hadoop需要SSH存取
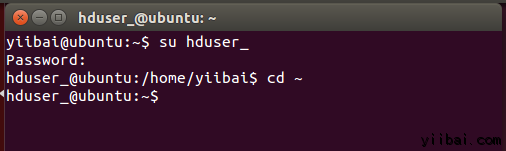
首先,切換使用者,輸入以下命令:
yiibai@ubuntu:~$ su hduser_

hduser_@ubuntu:~$ ssh-keygen -t rsa -P ""

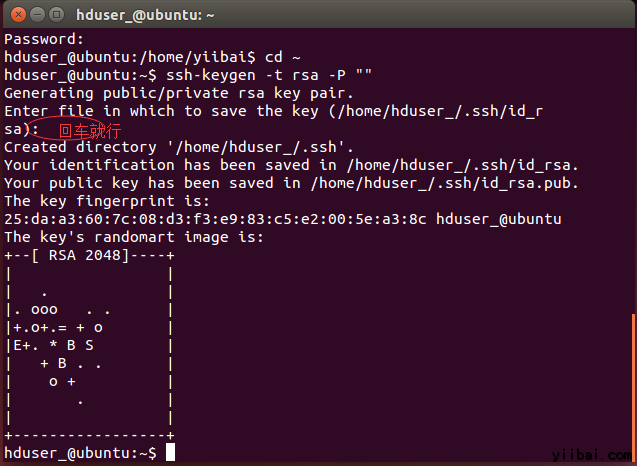
使用此金鑰啟用SSH存取本地計算機。
hduser_@ubuntu:~$ cat /home/hduser_/.ssd/id_rsa.pub >> /home/hduser_/.ssh/authorized_keys


現在,測試SSH設定通過“hduser”使用者連線到locahost。
hduser_@ubuntu:~$ ssh localhost

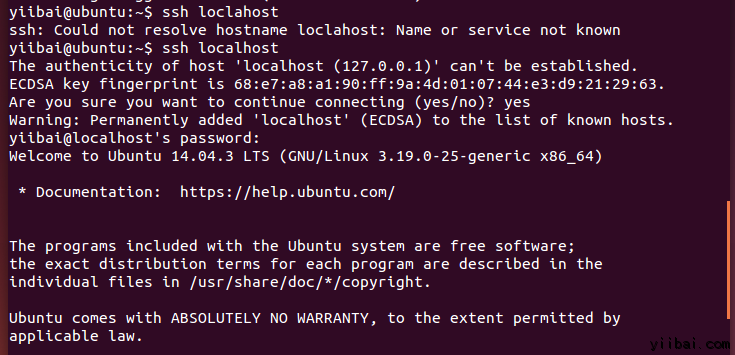
注意:
請注意,執行 'ssh localhost' 命令後如果看到下面的錯誤響應, 可能 SSH 在此系統不可用。

來解決上面這個問題,安裝 SSH 服務 -
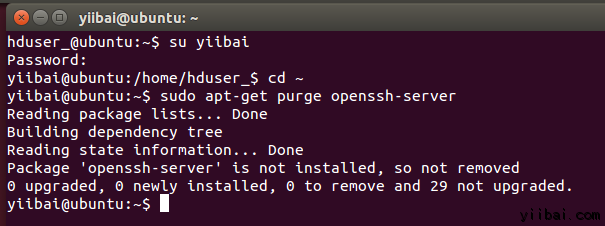
清除 SSH 使用以下命令:
hduser_@ubuntu:~$ sudo apt-get purge openssh-server
在安裝開始前清除 SSH 服務,這是一個很好的做法(建議),如果遇到“

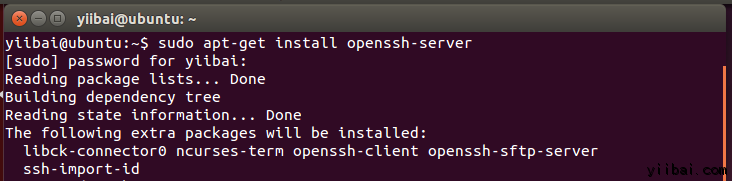
yiibai@ubuntu:~$ sudo apt-get install openssh-server

三、下載Hadoop
在瀏覽器中開啟網址:http://hadoop.apache.org/releases.html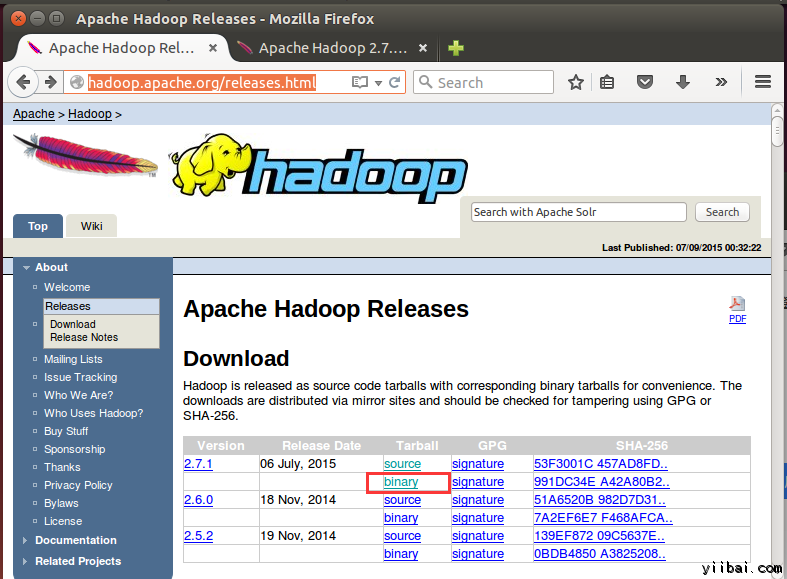
選擇一個最新 2.7.1 的穩定版本(stable)的二進位制包下載,如下:
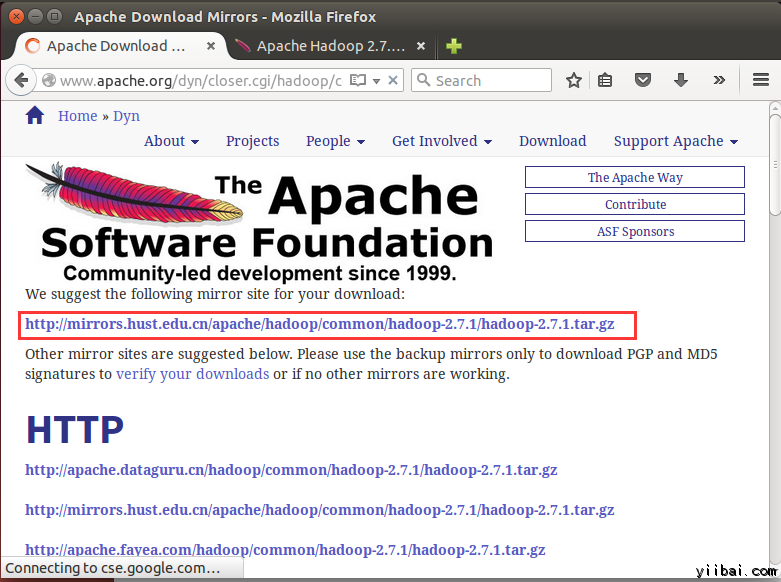

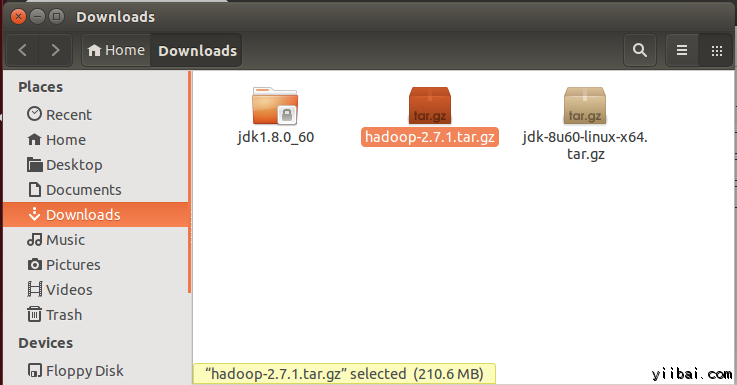

yiibai@ubuntu:~$ cd /home/yiibai/Downloads使用以下命令解壓檔案包:
yiibai@ubuntu:~$ sudo tar xzf hadoop-2.7.1.tar.gz
yiibai@ubuntu:~$ sudo mv hadoop-2.7.1 /usr/local/hadoop更改檔案使用者屬性,執行以下命令:
yiibai@ubuntu:~$ cd /usr/local yiibai@ubuntu:~$ sudo chown -R hduser_:hadoop_ hadoop
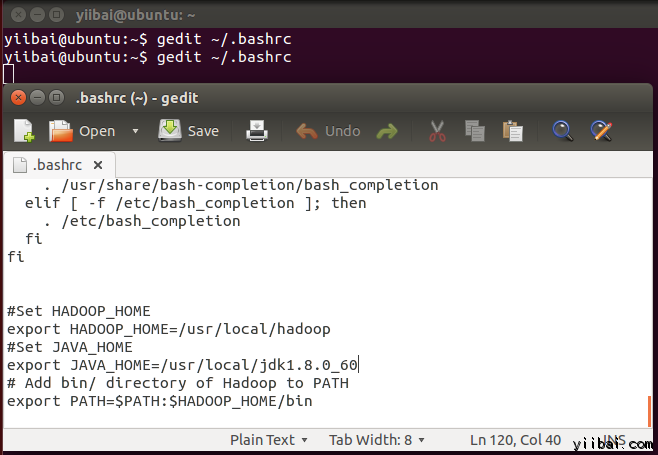
四、修改 ~/.bashrc 檔案
新增以下這些行到 ~/.bashrc 檔案的末尾,內容如下所示:
|
1
2
3
4
5
6
|
#Set HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
#Set JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_60
# Add bin/ directory of Hadoop to PATH
export PATH=$PATH:$HADOOP_HOME/bin
|
在終端下執行以下命令,開啟編輯器並將上面的內容加入到檔案的底部,如下圖所示:
yiibai@ubuntu:~$ vi ~/.bashrc

現在,使用下面的命令環境組態
yiibai@ubuntu:~$ . ~/.bashrc
五、組態關聯HDFS

在 $HADOOP_HOME/etc/hadoop/core-site.xml 檔案中還有兩個引數需要設定:
1. 'hadoop.tmp.dir' - 用於指定目錄讓 Hadoop 來儲存其資料檔案。
2. 'fs.default.name' - 指定預設的檔案系統
為了設定兩個引數,開啟檔案 core-site.xml
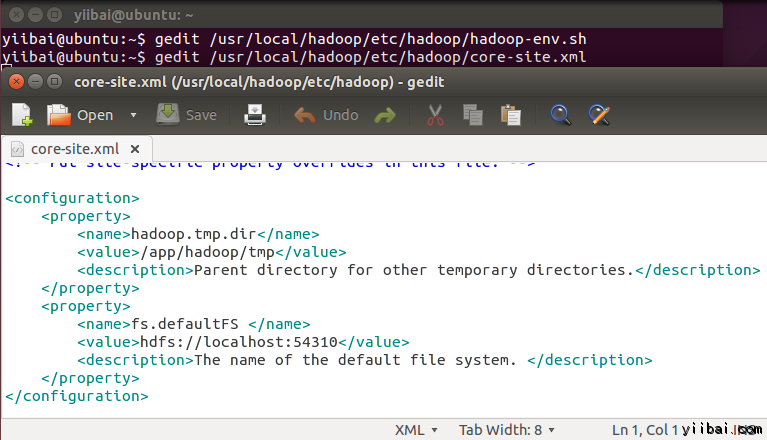
yiibai@ubuntu:~$ sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml拷貝以下所有行的內容放入到標籤 <configuration></configuration> 中間。
|
1
2
3
4
5
6
7
8
9
10
|
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>Parent directory for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS </name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. </description>
</property>
|
yiibai@ubuntu:~$ cd /usr/local/hadoop/etc/hadoop yiibai@ubuntu:/usr/local/hadoop/etc/hadoop$
現在建立一個目錄,如上面組態 core-site.xml 中使用的目錄:/app/hadoop/tmp
yiibai@ubuntu:/usr/local/hadoop/etc/hadoop$ sudo mkdir -p /app/hadoop/tmp
授予許可權目錄 /app/hadoop/tmp,執行如下的命令:
yiibai@ubuntu:~$ sudo chown -R hduser_:hadoop_ /app/hadoop/tmp yiibai@ubuntu:~$ sudo chmod 750 /app/hadoop/tmp
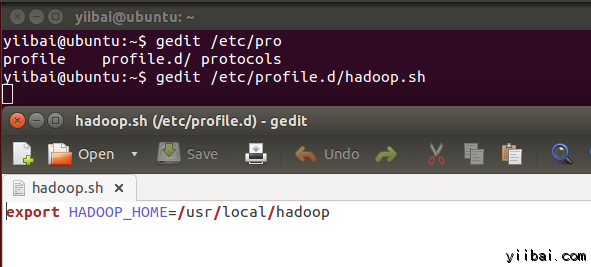
yiibai@ubuntu:~$ sudo gedit /etc/profile.d/hadoop.sh
然後輸入以下一行,
export HADOOP_HOME=/usr/local/hadoop

再執行以下命令:
yiibai@ubuntu:~$ sudo chmod +x /etc/profile.d/hadoop.sh
yiibai@ubuntu:~$ echo $HADOOP_HOME /usr/local/hadoop
現在複製檔案,執行以下命令:
yiibai@ubuntu:~$ sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
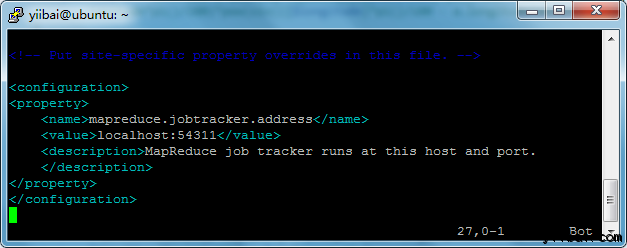
yiibai@ubuntu:~$ sudo vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
|
1
2
3
4
5
6
|
<property>
<name>mapreduce.jobtracker.address</name>
<value>localhost:54311</value>
<description>MapReduce job tracker runs at this host and port.
</description>
</property>
|

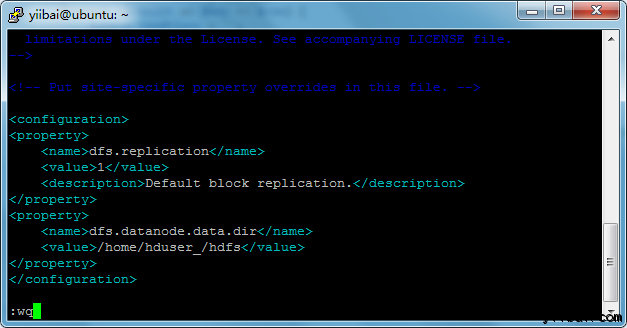
yiibai@ubuntu:~$ sudo vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
新增以下的設定內容到標籤<configuration> 和 </configuration> 中,如下圖所示:
|
1
2
3
4
5
6
7
8
9
|
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hduser_/hdfs</value>
</property>
|
yiibai@ubuntu:~$ sudo mkdir -p /home/hduser_/hdfs yiibai@ubuntu:~$ sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs yiibai@ubuntu:~$ sudo chmod 750 /home/hduser_/hdfs
七、格式化HDFS
yiibai@ubuntu:~$ $HADOOP_HOME/bin/hdfs namenode -format
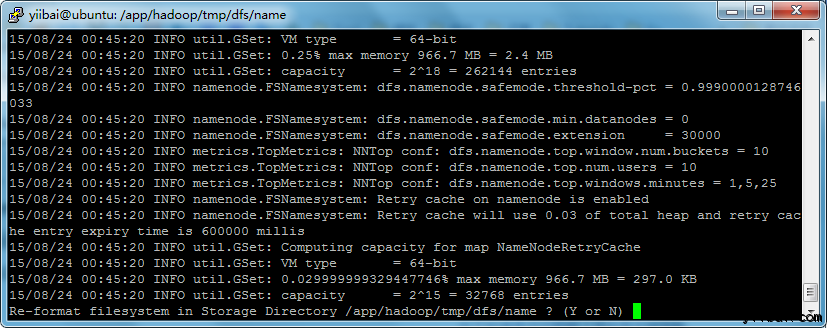
yiibai@ubuntu:~$ sudo mkdir -p /app/hadoop/tmp/dfs/name/current yiibai@ubuntu:~$ sudo chmod -R a+w /app/hadoop/tmp/dfs/name/current/
八、 啟動 Hadoop 的單節點叢集
使用以下命令啟動cHadoop 的單節點叢集(使用 hduser_ 使用者來啟動),如下:
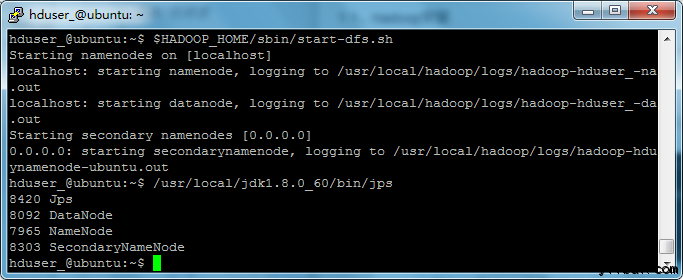
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-dfs.sh
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-yarn.sh
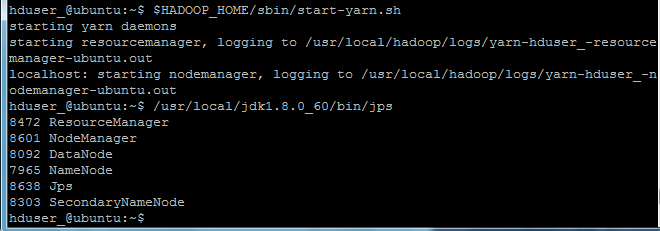

hduser_@ubuntu:~$ /usr/local/jdk1.8.0_60/bin/jps
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/stop-dfs.sh


hduser_@ubuntu:~$ $HADOOP_HOME/sbin/stop-yarn.sh


the end.