Oracle Distinct子句
在本教學中將學習如何使用Oracle SELECT DISTINCT語句從表中查詢不同(過濾相同值)的資料。
Oracle SELECT DISTINCT語句簡介
在SELECT語句中使用DISTINCT子句來過濾結果集中的重複行。它確保在SELECT子句中返回指定的一列或多列的值是唯一的。
以下說明了SELECT DISTINCT語句的語法:
SELECT DISTINCT
column_1
FROM
table_name;
在上面語法中,table_name表的column_1列中的值將進行比較以過濾重複項。
要根據多列檢索唯一資料,只需要在SELECT子句中指定列的列表,如下所示:
SELECT
DISTINCT column_1,
column_2,
...
FROM
table_name;
在此語法中,column_1,column_2和column_n中的值的組合用於確定資料的唯一性。
DISTINCT子句只能在SELECT語句中使用。
請注意,DISTINCT不是SQL標準的UNIQUE的同義詞。總是使用DISTINCT而不使用UNIQUE是一個好的習慣。
Oracle DISTINCT範例
下面來看看如何使用SELECT DISTINCT來看看它是如何工作的一些例子。
1. Oracle DISTINCT在一列上應用的範例
檢視範例資料庫中的聯絡人(contacts)表:

以下範例檢索所有聯絡人的名字:
SELECT first_name
FROM contacts
ORDER BY first_name;
執行上面查詢語句,得到以下結果 -
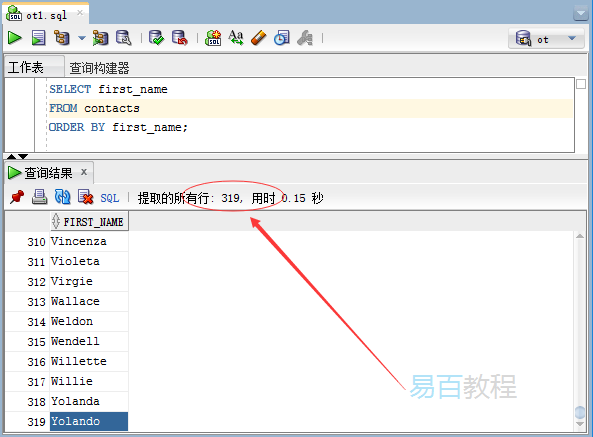
該查詢返回了319行,表示聯絡人(contacts)表有319行。
要獲得唯一的聯絡人名字,可以將DISTINCT關鍵字新增到上面的SELECT語句中,如下所示:
SELECT DISTINCT first_name
FROM contacts
ORDER BY first_name;
執行上面查詢語句,得到以下結果 -
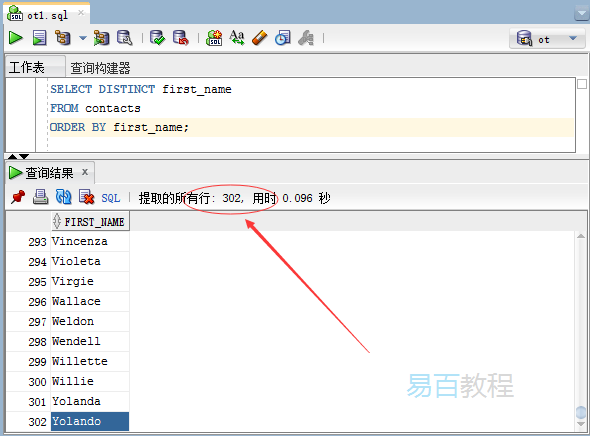
該查詢返回了302行,表示聯絡人(contacts)表有17行是重複的,它們已經被過濾了。
2. Oracle DISTINCT應用多列範例
看下面的order_items表,表的結構如下:

以下語句從order_items表中選擇不同的產品ID和數量:
SELECT
DISTINCT product_id,
quantity
FROM
ORDER_ITEMS
ORDER BY product_id;
執行上面查詢語句,得到以下結果 -
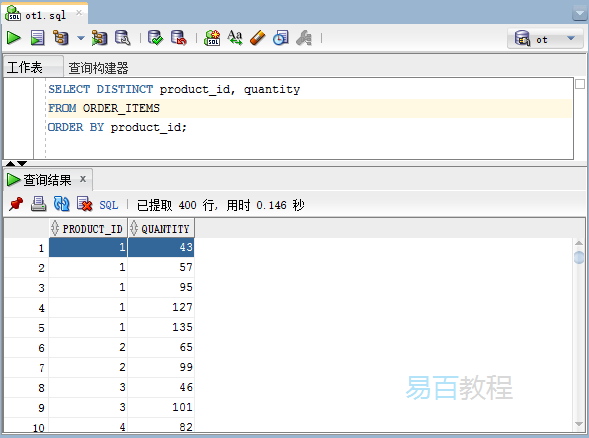
在此範例中,product_id和quantity列的值都用於評估結果集中行的唯一性。
3. Oracle DISTINCT和NULL
DISTINCT將NULL值視為重複值。如果使用SELECT DISTINCT語句從具有多個NULL值的列中查詢資料,則結果集只包含一個NULL值。
請參閱範例資料庫中的locations表,結構如下所示 -

以下語句從state列中檢索具有多個NULL值的資料:
SELECT DISTINCT state
FROM locations
ORDER BY state NULLS FIRST;
執行上面範例程式碼,得到以下結果 -
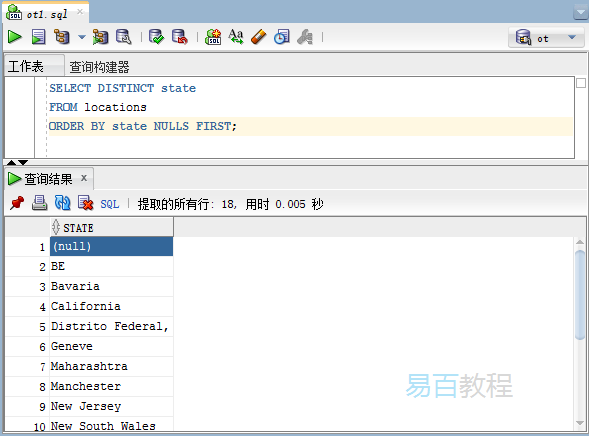
正如上圖所看到的,只返回一個NULL值。
在本教學中,您已學習如何使用SELECT DISTINCT語句來獲取基於一列或多列的過濾獲取唯一資料。