資料挖掘 - 挖掘文字資料
文字資料庫包括最龐大的收集檔案。他們從幾個來源,如新聞文章,書籍,數位圖書館,電子郵件和網頁等。由於增加的資訊量收集這些資訊,文字資料庫正在迅速增長。在許多文字資料庫的資料結構半。
例如,一個文件可能包含一些結構化的欄位,如標題,作者,publishing_date等,但隨著結構資料的文件也包含非結構化的文字成分,如摘要和內容。不知道什麼可能是在文件中,因此很難制定有效的查詢,用於從資料分析和提取有用的資訊。要比較的檔案和排名的文件的使用者需要的工具的重要性和相關性。因此,文字挖掘已經成為流行和重要的主題,在資料挖掘。
資訊檢索
資訊檢索處理的資訊從大量的基於文字的文件檢索。一些資料庫系統通常不存在於資訊檢索系統中,因為兩個處理不同型別的資料。以下是資訊檢索系統中的範例:
-
線上圖書目錄系統
-
線上檔案管理系統
-
站內搜尋系統等。
註: 在資訊檢索系統的主要問題是要根據使用者的查詢在一個文件集合查詢相關文件。這種使用者的查詢是由一些關鍵字的描述資訊需要。
在這種型別的搜尋問題的使用者採取主動從集合拉的相關資訊了。這是適當的時候使用者有臨時需要的資訊即短期需要。但如果使用者有長期需要的資訊,然後在檢索系統也可以主動採取任何新到達的資訊項推給使用者。
這種獲取資訊的被稱為資訊過濾。和相應的系統被稱為過濾系統或推薦系統。
用於文字檢索的基本措施
我們需要檢查系統如何準確或正確的是當系統檢索了一些檔案的使用者的輸入的基礎上。讓該組與查詢相關的文件被表示為{Relevant}和集合中檢索文件的定義為{}檢索。該組是相關和檢索的文件可以被表示為 {Relevant} ∩ {Retrieved}這可以被顯示在維恩圖中,如下所示:
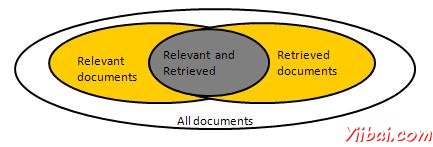
有評估文字檢索的品質三項基本措施:
-
Precision
-
Recall
-
F-score
精密
精度是檢索到的文件的相關的查詢是實際上的百分比。精度可以被定義為:
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
召回
召回的文件是相關的查詢,並在事實上檢索到的百分比。召回的定義為:
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|
F-SCORE
F值是常用的權衡。資訊檢索系統往往需要權衡精度或反之亦然。 F值被定義為召回或精密的調和平均數如下:
F-score = recall x precision / (recall + precision) / 2