塊和裂口
分塊是根據單詞的性質將相似單詞分組在一起的過程。 在下面的範例中,我們定義了必須生成塊的語法。 語法表示在建立塊時將遵循的諸如名詞和形容詞等短語的序列。 塊的圖形輸出如下所示。
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {?
*}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print(result)
result.draw()
當執行上面的程式時,我們得到以下輸出 -
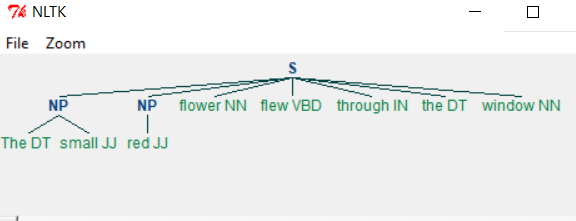
改變語法,我們得到一個不同的輸出,如下程式碼所示 -
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {
?*}"
chunkprofile = nltk.RegexpParser(grammar)
result = chunkprofile.parse(sentence)
print(result)
result.draw()
如下所示 -
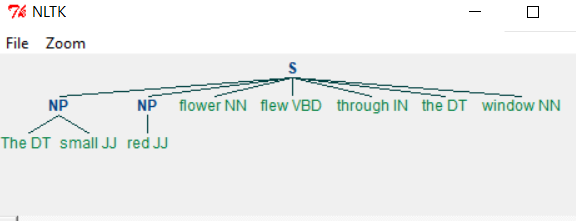
Chinking
Chinking是從塊中移除一系列令牌的過程。 如果令牌序列出現在塊的中間,則刪除這些令牌,留下兩個已經存在的塊。
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"), ("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = r"""
NP:
{<.*>+} # Chunk everything
}+{ # Chink sequences of JJ and NN
"""
chunkprofile = nltk.RegexpParser(grammar)
result = chunkprofile.parse(sentence)
print(result)
result.draw()
當執行上面的程式時,我們得到以下輸出 -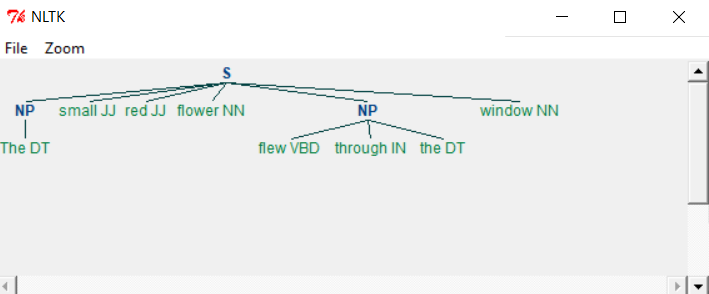
如所所示,符合語法標準的部分從名詞短語中省略為單獨的塊。 提取不在所需塊中的文字的過程稱為chinking。