SQL Group By子句
在本教學中,您將學習如何使用SQL GROUP BY子句根據一列或多列對行進行分組。
1. SQL GROUP BY子句簡介
分組是使用資料庫時必須處理的最重要任務之一。 要將行分組,請使用GROUP BY子句。
GROUP BY子句是SELECT語句的可選子句,它根據指定列中的匹配值將行組合成組,每組返回一行。
經常將GROUP BY與MIN,MAX,AVG,SUM或COUNT等聚合函式結合使用,以計算為每個分組提供資訊的度量。
以下是GROUP BY子句的語法。
SELECT
column1,
column2,
AGGREGATE_FUNCTION (column3)
FROM
table1
GROUP BY
column1,
column2;
在SELECT子句中包含聚合函式不是強制性的。 但是,如果使用聚合函式,它將計算每個組的匯總值。
如果要在分組之前過濾行,請新增WHERE子句。 但是要過濾組,請使用HAVING子句。
需要強調的是,在對行進行分組之前應用WHERE子句,而在對行進行分組之後應用HAVING子句。 換句話說,WHERE子句應用於行,而HAVING子句應用於分組。
要對組進行排序,請在GROUP BY子句後新增ORDER BY子句。
GROUP BY子句中出現的列稱為分組列。 如果分組列包含NULL值,則所有NULL值都匯總到一個分組中,因為GROUP BY子句認為NULL值相等。
2. SQL GROUP BY範例
我們將使用範例資料庫中的employees和departments表來演示GROUP BY子句的工作方式。
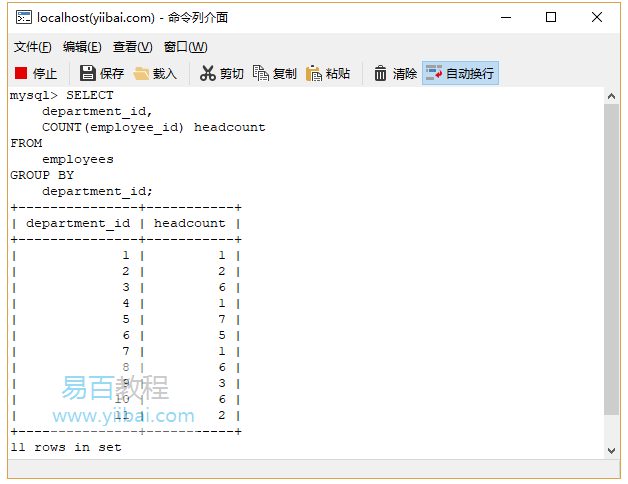
要查詢每個部門的員工數量,請按department_id列對員工進行分組,並將COUNT函式應用於每個組,如下所示:
SELECT
department_id,
COUNT(employee_id) headcount
FROM
employees
GROUP BY
department_id;
執行上面查詢語句,得到以下結果:
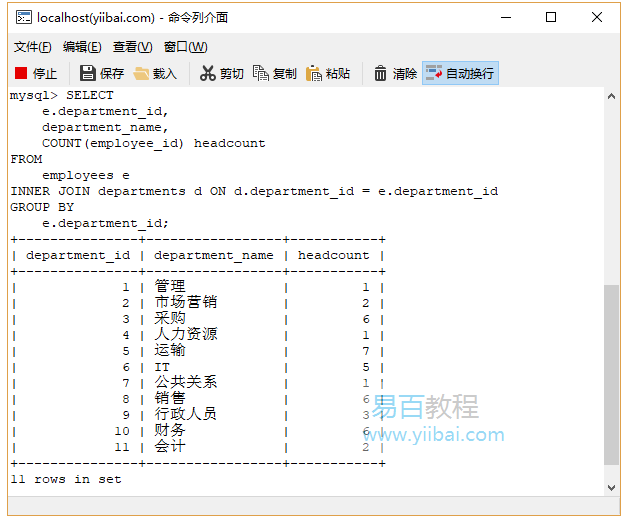
2.1. SQL GROUP BY帶有INNER JOIN範例
要獲取部門名稱,請使用departments表將employees表連線,如下所示:
SELECT
e.department_id,
department_name,
COUNT(employee_id) headcount
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id;
執行上面查詢語句,得到以下結果:
2.2. SQL GROUP BY帶有ORDER BY範例
要按人數排序部門,請新增ORDER BY子句作為以下語句:
SELECT
e.department_id,
department_name,
COUNT(employee_id) headcount
FROM
employees e
INNER JOIN
departments d ON d.department_id = e.department_id
GROUP BY e.department_id
ORDER BY headcount DESC;
執行上面查詢語句,得到以下結果:
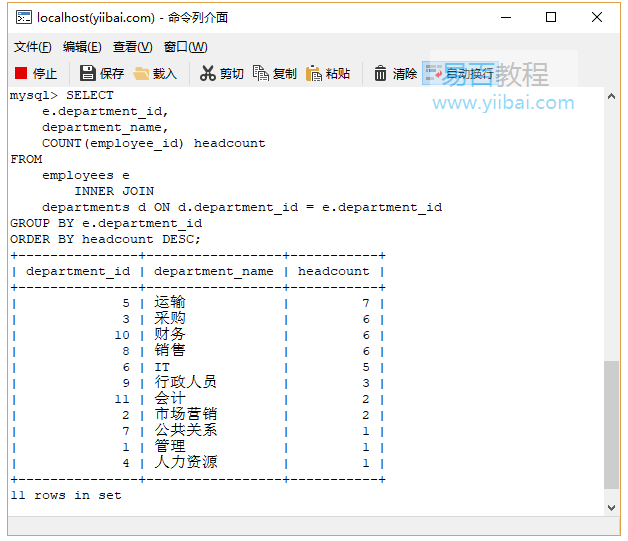
注意,可以在ORDER BY子句中使用headcount別名或COUNT(employee_id)。
2.3. SQL GROUP BY有HAVING範例
要查詢人數大於5的部門,請使用HAVING子句,如下查詢語句:
SELECT
e.department_id,
department_name,
COUNT(employee_id) headcount
FROM
employees e
INNER JOIN
departments d ON d.department_id = e.department_id
GROUP BY e.department_id
HAVING headcount > 5
ORDER BY headcount DESC;
執行上面查詢語句,得到以下結果:
+---------------+-----------------+-----------+
| department_id | department_name | headcount |
+---------------+-----------------+-----------+
| 5 | 運輸 | 7 |
| 3 | 採購 | 6 |
| 10 | 財務 | 6 |
| 8 | 銷售 | 6 |
+---------------+-----------------+-----------+
4 rows in set
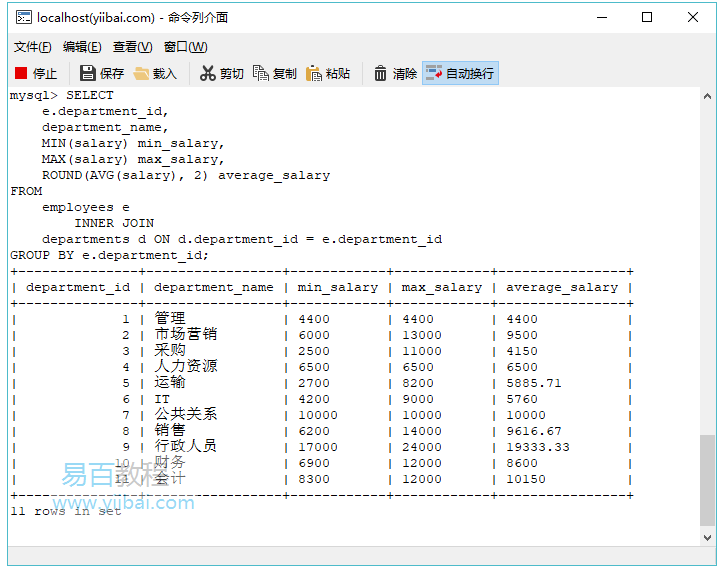
2.4. SQL GROUP BY與MIN,MAX和AVG範例
以下查詢返回每個部門中員工的最低,最高和平均工資。
SELECT
e.department_id,
department_name,
MIN(salary) min_salary,
MAX(salary) max_salary,
ROUND(AVG(salary), 2) average_salary
FROM
employees e
INNER JOIN
departments d ON d.department_id = e.department_id
GROUP BY e.department_id;
執行上面範例程式碼,得到以下結果:
2.5. SQL GROUP BY帶有SUM函式範例
要獲得每個部門的總薪水,請將SUM函式應用於salary列,並通過department_id列分組員工,如下所示:
SELECT
e.department_id,
department_name,
SUM(salary) total_salary
FROM
employees e
INNER JOIN
departments d ON d.department_id = e.department_id
GROUP BY e.department_id;
執行上面查詢語句,得到以下結果:
+---------------+-----------------+--------------+
| department_id | department_name | total_salary |
+---------------+-----------------+--------------+
| 1 | 管理 | 4400.00 |
| 2 | 市場行銷 | 19000.00 |
| 3 | 採購 | 24900.00 |
| 4 | 人力資源 | 6500.00 |
| 5 | 運輸 | 41200.00 |
| 6 | IT | 28800.00 |
| 7 | 公共關係 | 10000.00 |
| 8 | 銷售 | 57700.00 |
| 9 | 行政人員 | 58000.00 |
| 10 | 財務 | 51600.00 |
| 11 | 會計 | 20300.00 |
+---------------+-----------------+--------------+
11 rows in set
2.6. SQL GROUP BY多列
到目前為止,您已經看到將所有員工分組為一列。 例如,以下子句 -
GROUP BY department_id
將所有具有相同值的行放在一個組的department_id列中。如何按department_id和job_id列中的值對員工進行分組?
GROUP BY department_id, job_id
此子句將在一個組的department_id和job_id列中為所有具有相同值的員工進行分組。
以下語句將同一組中department_id和job_id列中具有相同值的行分組,然後返回每個組的行。
SELECT
e.department_id,
department_name,
e.job_id,
job_title,
COUNT(employee_id)
FROM
employees e
INNER JOIN
departments d ON d.department_id = e.department_id
INNER JOIN
jobs j ON j.job_id = e.job_id
GROUP BY e.department_id , e.job_id;
執行上面範例程式碼,得到以下結果:
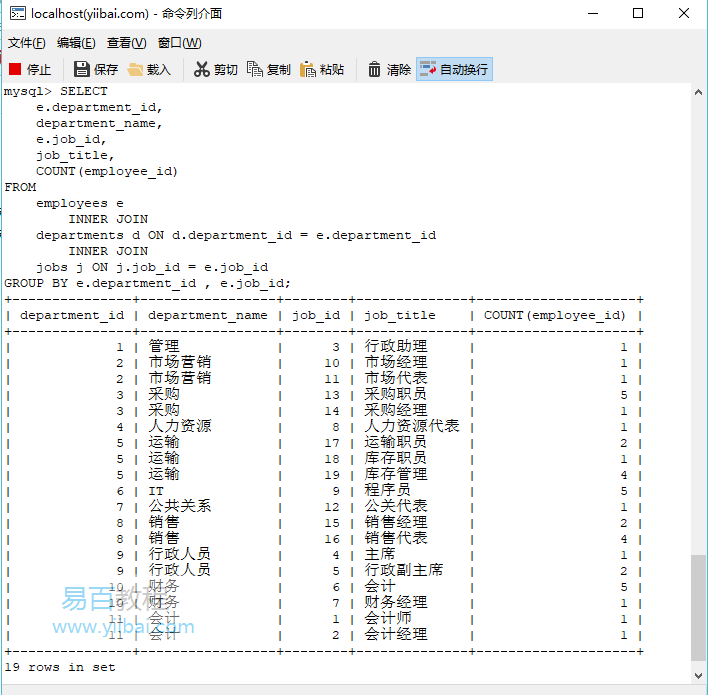
第2,3和5部門不止一個。
這是因為這些部門的員工有不同的工作。 例如,在運輸部門,有2名員工在運輸業務員工作,1名員工在庫存員工作,4名員工在庫存管理員工作。
2.7. SQL GROUP BY和DISTINCT
如果使用GROUP BY子句而不使用聚合函式,則GROUP BY子句的行為類似於DISTINCT運算子。
以下內容獲取員工的電話號碼,並按電話號碼分組。
SELECT
phone_number
FROM
employees
GROUP BY
phone_number;
注意,電話號碼已排序。
以下語句還檢索電話號碼,但不使用GROUP BY子句,而是使用DISTINCT運算子。
ELECT DISTINCT
phone_number
FROM
employees;
結果集是相同的,只是DISTINCT運算子返回的結果集沒有排序。
在本教學中,我們向您展示了如何使用GROUP BY子句將行匯總到分組中,並將聚合函式應用於每個分組。