SQLite GROUP BY子句
SQLite GROUP BY子句與SELECT語句一起使用,將相同的相同元素合併成一個組。
GROUP BY子句與SELECT語句中的WHERE子句一起使用,並且WHERE子句在ORDER BY子句之前。
語法:
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
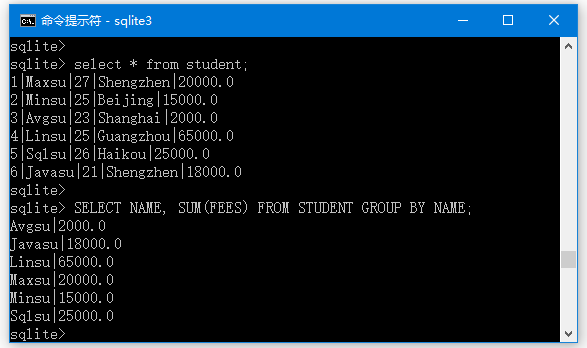
下面舉個例子來說明如何使用GROUP BY子句。 假設有一個名為student的表,具有以下資料:
sqlite> select * from student;
1|Maxsu|27|Shengzhen|20000.0
2|Minsu|25|Beijing|15000.0
3|Avgsu|23|Shanghai|2000.0
4|Linsu|25|Guangzhou|65000.0
5|Sqlsu|26|Haikou|25000.0
6|Javasu|21|Shengzhen|18000.0
sqlite>
使用GROUP BY查詢每位學生的費用總額:
SELECT NAME, SUM(FEES) FROM STUDENT GROUP BY NAME;
執行上面程式碼,得到以下結果 -
現在,使用以下INSERT語句向student表中建立一些記錄,為了更好演示,插入的部分列的資料值是相同的:
INSERT INTO STUDENT VALUES (7, 'Linsu', 27, 'Haikou', 10000.00 );
INSERT INTO STUDENT VALUES (8, 'Minsu', 23, 'Guangzhou', 5000.00 );
INSERT INTO STUDENT VALUES (9, 'Maxsu', 23, 'Shenzhen', 9000.00 );
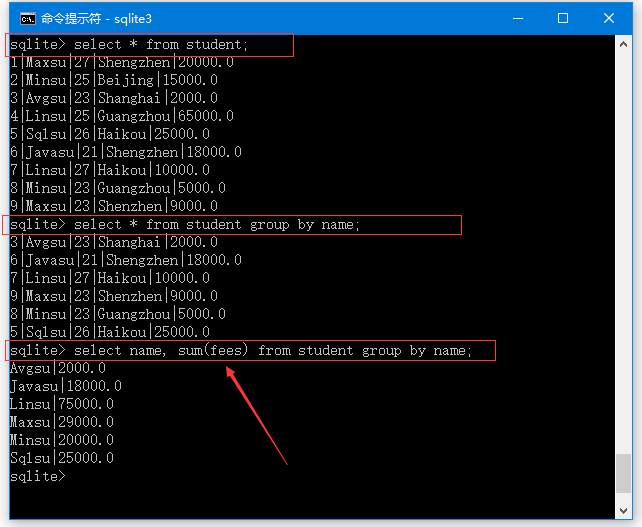
執行上面語句插入資料後,現在表中存在的資料如下 -
sqlite> select * from student;
1|Maxsu|27|Shengzhen|20000.0
2|Minsu|25|Beijing|15000.0
3|Avgsu|23|Shanghai|2000.0
4|Linsu|25|Guangzhou|65000.0
5|Sqlsu|26|Haikou|25000.0
6|Javasu|21|Shengzhen|18000.0
7|Linsu|27|Haikou|10000.0
8|Minsu|23|Guangzhou|5000.0
9|Maxsu|23|Shenzhen|9000.0
sqlite>
如上所示,現在有幾個欄位:name,age和city中的值是相同的。
現在,使用GROUP BY語句按NAME列來分組並對同分組內的所有的記錄的fees列求和:
select name, sum(fees) from student group by name;
執行上面程式碼,得到以下結果 -
可以使用ORDER BY子句和GROUP BY按升序或降序排列資料。
SELECT NAME, SUM(FEES) AS total_fees FROM STUDENT GROUP BY NAME ORDER BY NAME DESC;
-- 或者
SELECT NAME, SUM(FEES) AS total_fees FROM STUDENT GROUP BY NAME ORDER BY total_fees DESC;
執行上面程式碼,得到以下結果 -
sqlite> SELECT NAME, SUM(FEES) AS total_fees FROM STUDENT GROUP BY NAME ORDER BY NAME DESC;
Sqlsu|25000.0
Minsu|20000.0
Maxsu|29000.0
Linsu|75000.0
Javasu|18000.0
Avgsu|2000.0
sqlite>
sqlite> SELECT NAME, SUM(FEES) AS total_fees FROM STUDENT GROUP BY NAME ORDER BY total_fees DESC;
Linsu|75000.0
Maxsu|29000.0
Sqlsu|25000.0
Minsu|20000.0
Javasu|18000.0
Avgsu|2000.0
sqlite>