PL/SQL集合
在本章中,我們將討論PL/SQL中的集合。集合是具有相同資料型別的有序元素組。 每個元素都由一個唯一的下標來表示它在集合中的位置。
PL/SQL提供了三種集合型別 -
- 索引表或關聯陣列
- 巢狀的表
- 可變大小的陣列或
Varray型別
Oracle的每種型別的集合有以下特徵 -
| 集合型別 | 元素個數 | 下標型別 | 密集或稀疏 | 在哪建立 | 是否為物件型別屬性 |
|---|---|---|---|---|---|
| 關聯陣列(或索引表) | 無界 | 字串或整數 | 任意一種 | 只在PL/SQL塊中 | No |
| 巢狀表 | 無界 | 整數 | 開始密集,可以變得稀疏 | 在PL/SQL塊或模式級別 | Yes |
| 可變大小陣列(Varray) | 有界 | 整數 | 總是密集 | 在PL/SQL塊或模式級別 | Yes |
我們已經在「PL/SQL陣列」一章中討論了varray。 在本章中,將討論PL/SQL表。
兩種型別的PL/SQL表(即索引表和巢狀表)具有相同的結構,並且使用下標符號來存取它們的行。 但是,這兩種表在一個方面有所不同, 巢狀表可以儲存在資料庫列中,索引表不能。
索引表
索引表(也稱為關聯陣列)是一組鍵 - 值對。 每個鍵都是唯一的,用來定位相應的值。鍵可以是整數或字串。
使用以下語法建立索引表。 在這裡,正在建立一個名為table_name的索引表,其中的鍵是subscript_type,關聯的值是element_type,參考以下語法 -
TYPE type_name IS TABLE OF element_type [NOT NULL] INDEX BY subscript_type;
table_name type_name;
範例
以下範例顯示了如何建立一個表來儲存整數值以及名稱,然後列印出相同的名稱列表。
SET SERVEROUTPUT ON SIZE 99999;
DECLARE
TYPE salary IS TABLE OF NUMBER INDEX BY VARCHAR2(20);
salary_list salary;
name VARCHAR2(20);
BEGIN
-- adding elements to the table
salary_list('Rajnish') := 62000;
salary_list('Minakshi') := 75000;
salary_list('Martin') := 100000;
salary_list('James') := 78000;
-- printing the table
name := salary_list.FIRST;
WHILE name IS NOT null LOOP
dbms_output.put_line
('Salary of ' || name || ' is ' || TO_CHAR(salary_list(name)));
name := salary_list.NEXT(name);
END LOOP;
END;
/
執行上面範例程式碼,得到以下結果 -
Salary of James is 78000
Salary of Martin is 100000
Salary of Minakshi is 75000
Salary of Rajnish is 62000
PL/SQL 過程已成功完成。
範例2
索引表的元素也可以是任何資料庫表的%ROWTYPE或任何資料庫表欄位的%TYPE。 以下範例說明了這個概念。我們將使用儲存在資料庫中的CUSTOMERS表及資料 -
CREATE TABLE CUSTOMERS(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25),
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID)
);
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'kaushik', 23, 'Kota', 2000.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 );
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (6, 'Komal', 22, 'MP', 4500.00 );
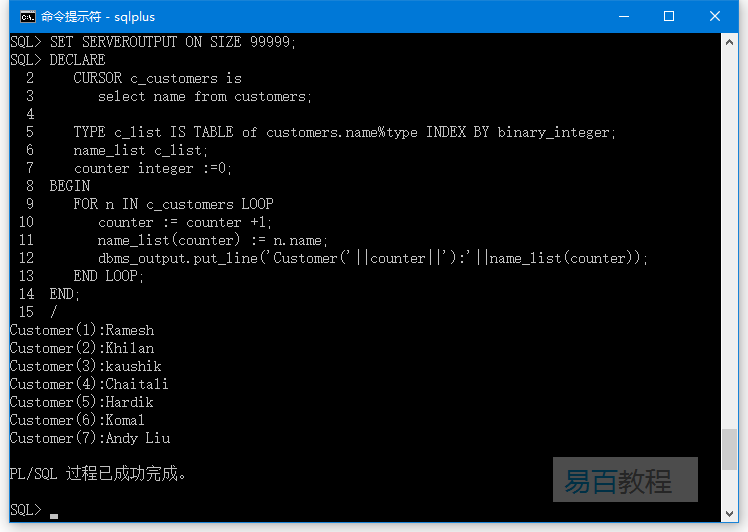
儲存過程程式碼如下 -
SET SERVEROUTPUT ON SIZE 99999;
DECLARE
CURSOR c_customers is
select name from customers;
TYPE c_list IS TABLE of customers.name%type INDEX BY binary_integer;
name_list c_list;
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_list(counter));
END LOOP;
END;
/
執行上面範例程式碼,得到以下結果 -
巢狀表
巢狀表就像一個具有任意數量元素的一維陣列。但是,巢狀表與陣列在以下幾個方面不同 -
- 陣列是一個有宣告數量的元素集合,但是一個巢狀的表沒有。巢狀表的大小可以動態增加。
- 陣列總是密集的,即它總是具有連續的下標。 巢狀陣列最初是密集的,但是當從其中刪除元素時,它可能變得稀疏。
使用以下語法建立巢狀表 -
TYPE type_name IS TABLE OF element_type [NOT NULL];
table_name type_name;
這個宣告類似於索引表的宣告,只是沒有INDEX BY子句。
巢狀表可以儲存在資料庫列中。 它可以進一步用於簡化SQL操作,您可以使用更大的表來連線單列表。關聯陣列不能儲存在資料庫中。
範例1
下面的例子說明了巢狀表的使用 -
SET SERVEROUTPUT ON SIZE 99999;
DECLARE
TYPE names_table IS TABLE OF VARCHAR2(10);
TYPE grades IS TABLE OF INTEGER;
names names_table;
marks grades;
total integer;
BEGIN
names := names_table('Kavita', 'Pritam', 'Ayan', 'Rishav', 'Aziz');
marks:= grades(98, 97, 78, 87, 92);
total := names.count;
dbms_output.put_line('Total '|| total || ' Students');
FOR i IN 1 .. total LOOP
dbms_output.put_line('Student:'||names(i)||', Marks:' || marks(i));
end loop;
END;
/
當上面的程式碼在SQL提示符下執行時,它會產生以下結果 -
Total 5 Students
Student:Kavita, Marks:98
Student:Pritam, Marks:97
Student:Ayan, Marks:78
Student:Rishav, Marks:87
Student:Aziz, Marks:92
PL/SQL 過程已成功完成。
範例2
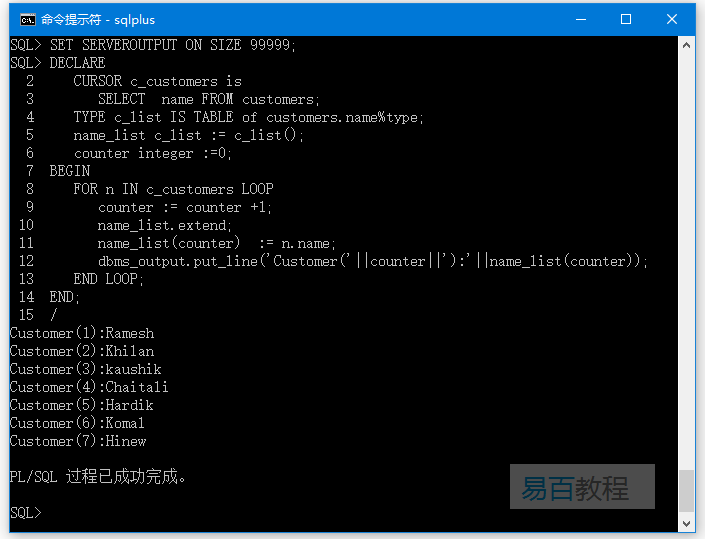
巢狀表的元素也可以是任何資料庫表的%ROWTYPE或任何資料庫表欄位的%TYPE。以下範例說明了這個概念。我們將使用儲存在資料庫中的CUSTOMERS表,參考以下程式碼的實現 -
SET SERVEROUTPUT ON SIZE 99999;
DECLARE
CURSOR c_customers is
SELECT name FROM customers;
TYPE c_list IS TABLE of customers.name%type;
name_list c_list := c_list();
counter integer :=0;
BEGIN
FOR n IN c_customers LOOP
counter := counter +1;
name_list.extend;
name_list(counter) := n.name;
dbms_output.put_line('Customer('||counter||'):'||name_list(counter));
END LOOP;
END;
/
執行上面範例程式碼,得到以下結果 -
集合方法
PL/SQL提供了內建的集合方法,使集合更易於使用。下表列出了方法及其用途 -
| 編號 | 方法 | 目的 |
|---|---|---|
| 1 | EXISTS(n) |
如果集合中的第n個元素存在,則返回TRUE; 否則返回FALSE。 |
| 2 | COUNT |
返回集合當前包含的元素的數量。 |
| 3 | LIMIT |
檢查集合的最大容量(大小)。 |
| 4 | FIRST |
返回使用整數下標的集合中的第一個(最小)索引編號。 |
| 5 | LAST |
返回使用整數下標的集合中的最後(最大)索引編號。 |
| 6 | PRIOR(n) |
返回集合中索引n之前的索引編號。 |
| 7 | NEXT(n) |
返回索引n成功的索引號。 |
| 8 | EXTEND |
追加一個空(null)元素到集合。 |
| 9 | EXTEND(n) |
將n個空(null)元素追加到集合中。 |
| 10 | EXTEND(n,i) |
將第i個元素的n個副本追加到集合中。 |
| 11 | TRIM |
刪除一個集合末尾的元素。 |
| 12 | TRIM(n) |
刪除集合末尾的n個元素。 |
| 13 | DELETE |
刪除集合中的所有元素,將COUNT設定為0。 |
| 14 | DELETE(n) |
使用數位鍵或巢狀表從關聯陣列中刪除第n個元素。 如果關聯陣列有一個字串鍵,則刪除鍵值對應的元素。 如果n為空,則DELETE(n)不執行任何操作。 |
| 15 | DELETE(m,n) |
從關聯陣列或巢狀表中移除m..n範圍內的所有元素。 如果m大於n,或者m或n為空,則DELETE(m,n)將不執行任何操作。 |
集合異常
下表提供了集合異常情況以及何時引發 -
| 編號 | 集合異常 | 引發的情況 |
|---|---|---|
| 1 | COLLECTION_IS_NULL |
嘗試在一個原子空集合上進行操作。 |
| 2 | NO_DATA_FOUND |
下標指定被刪除的元素或關聯陣列中不存在的元素。 |
| 3 | SUBSCRIPT_BEYOND_COUNT |
下標超出了集合中元素的數量。 |
| 4 | SUBSCRIPT_OUTSIDE_LIMIT |
下標超出允許的範圍。 |
| 5 | VALUE_ERROR |
下標為空或不能轉換為鍵型別。如果鍵定義為PLS_INTEGER範圍,並且下標超出此範圍,則可能會發生此異常。 |