Sqoop安裝
由於Sqoop是Hadoop的一個子專案,它只能工作在Linux作業系統。這裡需要按照下面系統上給定安裝Sqoop的步驟。
第1步:驗證JAVA安裝
在安裝Sqoop之前,需要確定是否已經在系統上安裝Java。用下面的命令來驗證Java安裝:
$ java –version
如果Java已經安裝在系統上,應該能看到如下回應:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果未在系統上安裝Java,那麼需要按照下面的步驟來執行安裝。
安裝java
按照下面給定簡單的步驟在系統上安裝Java。
第1步
下載Java (JDK <最新版本> - X64.tar.gz) 存取以下連結:下載
那麼jdk-7u71-linux-x64.tar.gz 下載到你的系統上。
第2步
通常情況下,可以找到下載檔案夾中下載的Java檔案。驗證它並提取 jdk-7u71-linux-x64.gz 檔案中使用下面的命令。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
第3步
為了使Java提供給所有的使用者,必須將它移動到的位置 “/usr/local/”. 開啟根目錄,鍵入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/java # exitStep IV:
第4步
有關設定PATH和JAVA_HOME變數,新增以下命令~/.bashrc檔案
export JAVA_HOME=/usr/local/java export PATH=PATH:$JAVA_HOME/bin
現在,應用所有更改到當前正在執行的系統。
$ source ~/.bashrc
第5步
使用下面的命令來組態Java方案:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
現在從終端上使用命令java -version 驗證安裝如上所述。
第2步:驗證Hadoop的安裝
在安裝Sqoop之前Hadoop必須在系統上安裝。使用下面的命令來驗證Hadoop的安裝:
$ hadoop version
如果Hadoop是已經安裝在系統上,那麼會得到以下回應:
Hadoop 2.4.1 -- Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果在系統上未安裝Hadoop,那麼繼續進行下面的步驟:
下載Hadoop
下載和Apache軟體基金會使用下面的命令提取Hadoop2.4.1
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
在模擬分散式模式下安裝Hadoop
按照下面給出的偽分散式模式下安裝的Hadoop2.4.1的步驟。
第1步:設定Hadoop
可以通過附加下面的命令到 ~/.bashrc檔案中設定Hadoop環境變數。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
現在,應用所有更改到當前正在執行的系統。
$ source ~/.bashrc
第2步:Hadoop組態
可以找到位置的所有Hadoop的組態檔案 “$HADOOP_HOME/etc/hadoop”. 需要根據Hadoop基礎架構作出適當的改修這些組態檔案。
$ cd $HADOOP_HOME/etc/hadoop
為了開發java能夠使用Hadoop專案,必須用java在系統中的位置替換JAVA_HOME值以重新設定hadoop-env.sh檔案的java環境變數。
export JAVA_HOME=/usr/local/java
下面給出的是,需要編輯組態Hadoop的檔案的列表。
core-site.xml
core-site.xml 檔案中包含的資訊,如用於Hadoop的範例中,分配給檔案系統的儲存器,用於儲存資料的記憶體限制的埠號,以及讀/寫緩衝器的大小。
開啟核心core-site.xml 並在<configuration>和</configuration>標籤之間新增以下屬性。
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000 </value> </property> </configuration>
hdfs-site.xml
hdfs-site.xml檔案中包含的資訊,如複製資料值,NameNode的路徑,本地檔案系統的資料節點的路徑。這意味著要儲存Hadoop基礎架構。
讓我們假設以下資料。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
開啟這個檔案,並在此檔案中<configuration>, </configuration> 之間標籤新增以下屬性。
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value> </property> </configuration>
註:在上面的檔案,所有的屬性值是使用者定義,可以根據自己的Hadoop的基礎架構進行更改。
yarn-site.xml
此檔案用於組態成yarn在Hadoop中。開啟yarn-site.xml檔案,並在在此檔案中的<configuration>, </configuration>標籤之間新增以下屬性。
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
此檔案用於指定正在使用MapReduce框架。預設情況下,包含yarn-site.xml的模板。首先,需要使用下面的命令來複製從mapred-site.xml 模板到 mapred-site.xml 檔案。
$ cp mapred-site.xml.template mapred-site.xml
開啟mapred-site.xml檔案,並在在此檔案中的 <configuration>, </configuration>標籤之間新增以下屬性。
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
驗證Hadoop的安裝
下面的步驟用來驗證 Hadoop 安裝。
第1步:名稱節點設定
使用命令 “hdfs namenode -format” 如下設定名稱節點。
$ cd ~ $ hdfs namenode -format
預期的結果如下
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
第2步:驗證Hadoop DFS
下面的命令用來啟動DFS。執行這個命令將開始Hadoop檔案系統。
$ start-dfs.sh
期望的輸出如下所示:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
第3步:驗證Yarn 指令碼
下面的命令用來啟動 yarn 指令碼。執行此命令將啟動yarn 守護行程。
$ start-yarn.sh
期望的輸出如下所示:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
第4步:在瀏覽器存取Hadoop
存取Hadoop的預設埠號為50070.使用以下URL來獲得瀏覽器的Hadoop服務。
http://localhost:50070/
下圖描述了Hadoop的瀏覽器。
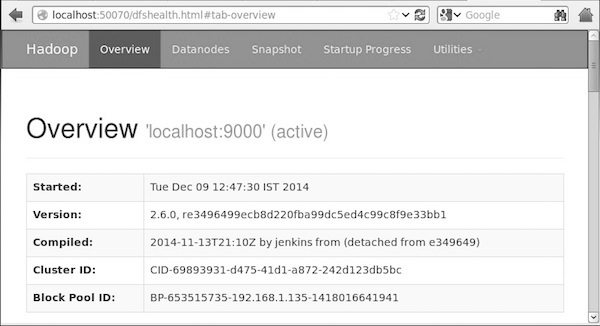
第5步:驗證所有應用程式的叢集
存取叢集中的所有應用程式的預設埠號為8088。使用以下URL存取該服務。
http://localhost:8088/
下圖描述了Hadoop叢集的瀏覽器。
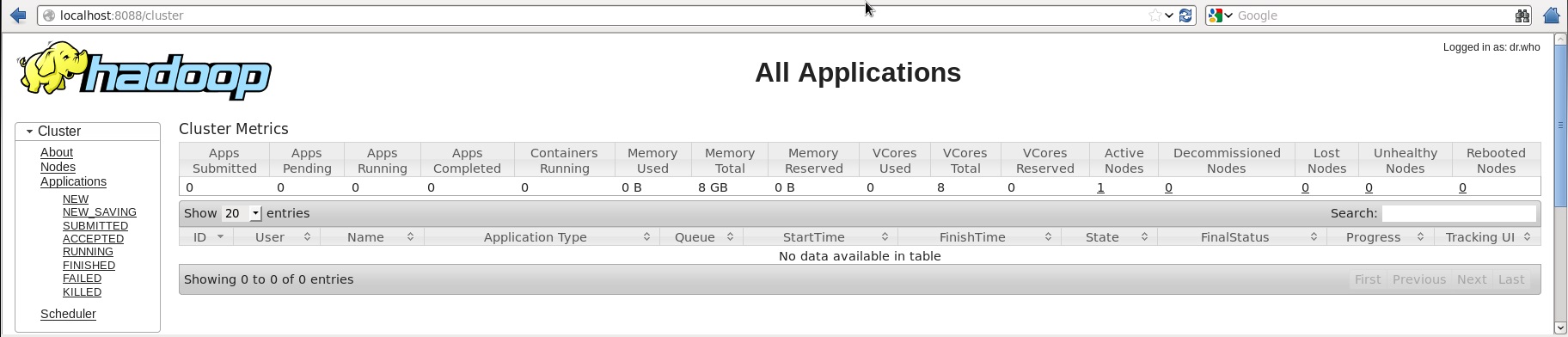
第3步下載Sqoop
在本教學中可以從以下連結下載Sqoop的最新版本,我們使用的是1.4.5版本:sqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz.
Step 4: 安裝Sqoop
下面的命令用於提取Sqoop.tar.gz並將其移動到“/usr/lib/sqoop” 目錄。
$tar -xvf sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz $ su password: # mv sqoop-1.4.4.bin__hadoop-2.0.4-alpha /usr/lib/sqoop #exit
第5步:組態.bashrc
必須設定Sqoop環境通過附加以下行到?/.bashrc檔案:
#Sqoop export SQOOP_HOME=/usr/lib/sqoop export PATH=$PATH:$SQOOP_HOME/bin
下面的命令是用來執行?/.bashrc檔案。
$ source ~/.bashrc
第6步:組態Sqoop
要組態Sqoop用Hadoop,需要編輯 sqoop-env.sh 檔案,該檔案被放置在 $SQOOP_HOME/conf 目錄。首先要重定向到 Sqoop config 目錄,並使用以下命令複製的模板檔案
$ cd $SQOOP_HOME/conf $ mv sqoop-env-template.sh sqoop-env.sh
開啟sqoop-env.sh並編輯下面幾行:
export HADOOP_COMMON_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=/usr/local/hadoop
第7步:下載並組態java的MySQL連線器(mysql-connector-java)
可以從下面的下載使用mysql-connector-java的5.1.30.tar.gz檔案:下載連結
下面的命令是用來提取使用 mysql-connector-java 壓縮包並移動 mysql-connector-java-5.1.30-bin.jar 到 /usr/lib/sqoop/lib 目錄
$ tar -zxf mysql-connector-java-5.1.30.tar.gz $ su password: # cd mysql-connector-java-5.1.30 # mv mysql-connector-java-5.1.30-bin.jar /usr/lib/sqoop/lib
第8步:驗證Sqoop
下面的命令被用來驗證Sqoop版本。
$ cd $SQOOP_HOME/bin $ sqoop-version
預期的輸出:
14/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 Sqoop 1.4.5 git commit id 5b34accaca7de251fc91161733f906af2eddbe83 Compiled by abe on Fri Aug 1 11:19:26 PDT 2014
到這裡,整個Sqoop安裝工作完成。