PDFBox提取影象
在前一章中,我們已經看到了如何合併多個PDF文件。 在本章中,我們將了解如何從PDF文件的頁面提取影象。
從PDF文件生成影象
PDFBox庫提供了一個名稱為PDFRenderer的類,它將PDF文件呈現為AWT BufferedImage。
以下是從PDF文件生成影象的步驟。
第1步:載入現有的PDF文件
使用PDDocument類的靜態方法load()載入現有的PDF文件。 此方法接受一個檔案物件作為引數,因為這是一個靜態方法,可以使用類名稱呼叫它,如下所示。
File file = new File("path of the document")
PDDocument document = PDDocument.load(file);
第2步:範例化PDFRenderer類
PDFRenderer類將PDF文件呈現到AWT BufferedImage中。 因此,需要範例化這個類,如下所示。 這個類別建構函式接受一個文件物件; 傳遞上一步建立的文件物件,如下所示。
PDFRenderer renderer = new PDFRenderer(document);
第3步:從PDF文件渲染影象
可以使用Renderer類的renderImage()方法在特定頁面中呈現影象,以將此方法用於傳遞要渲染影象的頁面的索引。
BufferedImage image = renderer.renderImage(0);
第4步:將影象寫入檔案
可以使用write()方法將上一步中呈現的影象寫入檔案。 對於這種方法,需要傳遞三個引數 -
- 渲染的影象物件。
- 代表影象型別的字串(
jpg或png)。 - 需要儲存提取的影象的檔案物件。
ImageIO.write(image, "JPEG", new File("D:/PdfBoxExamples/myimage.jpg"));
第5步:關閉文件
最後,使用PDDocument類的close()方法關閉文件,如下所示。
document.close();
範例
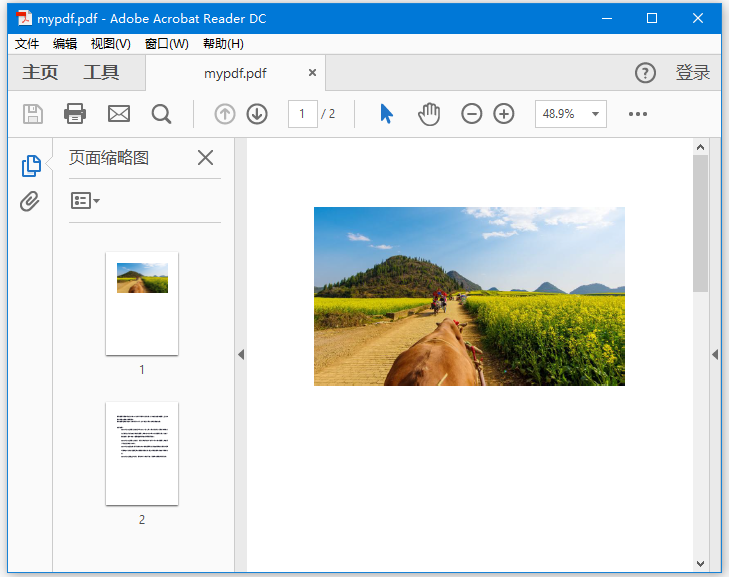
假設,在目錄:F:\worksp\pdfbox中有一個PDF文件 - mypdf.pdf,並且在其第一頁中包含一個影象,如下所示。
本範例演示如何將上述PDF文件轉換為影象檔案。 在這裡,將檢索PDF文件第一頁中的影象並將其儲存為myimage.jpg。 將此程式碼儲存為PdfToImage.java -
package com.yiibai;
import java.awt.image.BufferedImage;
import java.io.File;
import javax.imageio.ImageIO;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
public class PdfToImage {
public static void main(String args[]) throws Exception {
//Loading an existing PDF document
File file = new File("F:/worksp/pdfbox/mypdf.pdf");
PDDocument document = PDDocument.load(file);
//Instantiating the PDFRenderer class
PDFRenderer renderer = new PDFRenderer(document);
//Rendering an image from the PDF document
BufferedImage image = renderer.renderImage(0);
//Writing the image to a file
ImageIO.write(image, "JPEG", new File("F:/worksp/pdfbox/myimage.jpg"));
System.out.println("Image created");
//Closing the document
document.close();
}
}
執行時,上述程式將檢索給定PDF文件中的影象,並顯示以下訊息。
Image created
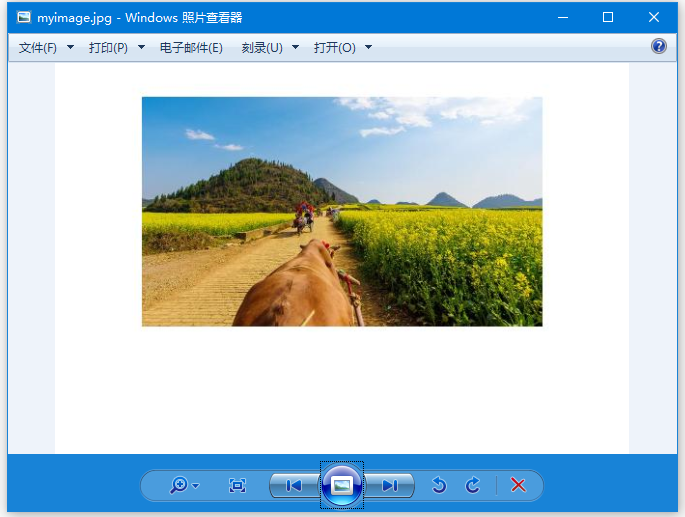
如果開啟F:/worksp/pdfbox/,可以觀察到影象檔案:myimage.jpg,開啟後如下所示。