sklearn學習4.數據處理與特徵工程
一.概述
1.數據預處理與特徵工程
數據挖掘的五大流程:
- 獲取數據
- 數據預處理 數據預處理是從數據中檢測,糾正或刪除損壞,不準 不準確或不適用於模型的記錄的過程 可能面對的問題有:數據型別不同,比如有的是文字,有的是數位,有的含時間序列,有的連續,有的間斷。 也可能,數據的品質不行,有噪聲,有異常,有缺失,數據出錯,量綱不一,有重複,數據是偏態,數據量太 大或太小 數據預處理的目的:讓數據適應模型,匹配模型的需求
- 特徵工程: 特徵工程是將原始數據轉換爲更能代表預測模型的潛在問題的特徵的過程,可以通過挑選最相關的特徵,提取 特徵以及創造特徵來實現。其中創造特徵又經常以降維演算法的方式實現。 可能面對的問題有:特徵之間有相關性,特徵和標籤無關,特徵太多或太小,或者乾脆就無法表現出應有的數 據現象或無法展示數據的真實面貌 特徵工程的目的:1) 降低計算成本,2) 提升模型上限
- 建模,測試模型並預測出結果
- 上線,驗證模型效果
2. sklearn中的數據預處理和特徵工程

模組preprocessing:幾乎包含數據預處理的所有內容
模組Impute:填補缺失值專用
模組feature_selection:包含特徵選擇的各種方法的實踐
模組decomposition:包含降維演算法
二.數據預處理 Preprocessing & Impute
1.數據無量綱化
在機器學習演算法實踐中,我們往往有着將不同規格的數據轉換到同一規格,或不同分佈的數據轉換到某個特定分佈 的需求,這種需求統稱爲將數據「無量綱化」。譬如梯度和矩陣爲核心的演算法中,譬如邏輯迴歸,支援向量機,神經 網路,無量綱化可以加快求解速度;而在距離類模型,譬如K近鄰,K-Means聚類中,無量綱化可以幫我們提升模 型精度,避免某一個取值範圍特別大的特徵對距離計算造成影響。(一個特例是決策樹和樹的整合演算法們,對決策 樹我們不需要無量綱化,決策樹可以把任意數據都處理得很好。)
數據的無量綱化可以是線性的,也可以是非線性的。線性的無量綱化包括中心化(Zero-centered或者Meansubtraction)處理和縮放處理(Scale)。中心化的本質是讓所有記錄減去一個固定值,即讓數據樣本數據平移到 某個位置。縮放的本質是通過除以一個固定值,將數據固定在某個範圍之中,取對數也算是一種縮放處理
preprocessing.MinMaxScaler
當數據(x)按照最小值中心化後,再按極差(最大值 - 最小值)縮放,數據移動了最小值個單位,並且會被收斂到 [0,1]之間,而這個過程,就叫做數據歸一化(Normalization,又稱Min-Max Scaling)。注意,Normalization是歸 一化,不是正則化,真正的正則化是regularization,不是數據預處理的一種手段。歸一化之後的數據服從正態分 布,公式如下:
在sklearn當中,我們使用preprocessing.MinMaxScaler來實現這個功能。MinMaxScaler有一個重要參數, feature_range,控制我們希望把數據壓縮到的範圍,預設是[0,1]。
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
#不太熟悉numpy的小夥伴,能夠判斷data的結構嗎? #如果換成表是什麼樣子? import pandas as pd pd.DataFrame(data)
#實現歸一化 scaler = MinMaxScaler() #範例化 scaler = scaler.fit(data) #fit,在這裏本質是生成min(x)和max(x) result = scaler.transform(data) #通過介面導出結果 result
result_ = scaler.fit_transform(data) #訓練和導出結果一步達成
scaler.inverse_transform(result) #將歸一化後的結果逆轉
#使用MinMaxScaler的參數feature_range實現將數據歸一化到[0,1]以外的範圍中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] scaler = MinMaxScaler(feature_range=[5,10]) #依然範例化
result = scaler.fit_transform(data) #fit_transform一步導出結果 result
#當X中的特徵數量非常多的時候,fit會報錯並表示,數據量太大了我計算不了 #此時使用partial_fit作爲訓練介面 #scaler = scaler.partial_fit(data)BONUS: 使用numpy來實現歸一化
import numpy as np X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
#歸一化 X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) X_nor
#逆轉歸一化 X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0) X_returned**preprocessing.StandardScaler **
當數據(x)按均值(μ)中心化後,再按標準差(σ)縮放,數據就會服從爲均值爲0,方差爲1的正態分佈(即標準正態分 布),而這個過程,就叫做數據標準化(Standardization,又稱Z-score normalization),公式如下:
from sklearn.preprocessing import StandardScaler data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler() #範例化 scaler.fit(data) #fit,本質是生成均值和方差
scaler.mean_ #檢視均值的屬性mean_ scaler.var_ #檢視方差的屬性var_
x_std = scaler.transform(data) #通過介面導出結果
x_std.mean() #導出的結果是一個數組,用mean()檢視均值 x_std.std() #用std()檢視方差
scaler.fit_transform(data) #使用fit_transform(data)一步達成結果
scaler.inverse_transform(x_std) #使用inverse_transform逆轉標準化 對於StandardScaler和MinMaxScaler來說,空值NaN會被當做是缺失值,在fit的時候忽略,在transform的時候 保持缺失NaN的狀態顯示。並且,儘管去量綱化過程不是具體的演算法,但在fit介面中,依然只允許匯入至少二維數 組,一維陣列匯入會報錯。通常來說,我們輸入的X會是我們的特徵矩陣,現實案例中特徵矩陣不太可能是一維所 以不會存在這個問題。
**StandardScaler和MinMaxScaler選哪個? **
大多數機器學習演算法中,會選擇StandardScaler來進行特徵縮放,因爲MinMaxScaler對異常值非常敏 感。在PCA,聚類,邏輯迴歸,支援向量機,神經網路這些演算法中,StandardScaler往往是最好的選擇
MinMaxScaler在不涉及距離度量、梯度、協方差計算以及數據需要被壓縮到特定區間時使用廣泛,比如數位影像 處理中量化畫素強度時,都會使用MinMaxScaler將數據壓縮於[0,1]區間之中。
(建議:先試試StandardScaler,效果不好換MinMaxScaler)
除了StandardScaler和MinMaxScaler之外,sklearn中也提供了各種其他縮放處理(中心化只需要一個pandas廣 播一下減去某個數就好了,因此sklearn不提供任何中心化功能)。比如,在希望壓縮數據,卻不影響數據的稀疏 性時(不影響矩陣中取值爲0的個數時),我們會使用MaxAbsScaler;在異常值多,噪聲非常大時,我們可能會選 用分位數來無量綱化,此時使用RobustScaler。詳情參考下列表

2.缺失值
機器學習和數據挖掘中所使用的數據,永遠不可能是完美的。很多特徵,對於分析和建模來說意義非凡,但對於實 際收集數據的人卻不是如此,因此數據挖掘之中,常常會有重要的欄位缺失值很多,但又不能捨棄欄位的情況。因 此,數據預處理中非常重要的一項就是處理缺失值
import pandas as pd data = pd.read_csv(r"C:\work\learnbetter\micro-class\ week 3 Preprocessing\Narrativedata.csv",index_col=0)
data.head() 在這裏,我們使用從泰坦尼克號提取出來的數據,這個數據有三個特徵,一個數值型,兩個字元型,標籤也是字元 型。從這裏開始,我們以此爲例熟悉數據預處理的各種方法
**impute.SimpleImputer **
在講解隨機森林的案例時,我們用這個類和隨機森林迴歸填補了缺失值,對比了不同的缺失值填補方式對數據的影 響。這個類是專門用來填補缺失值的。它包括四個重要參數:
1.missing_values
告訴SimpleImputer,數據中的缺失值長什麼樣,預設空值np.nan
2.strategy
我們填補缺失值的策略,預設均值。 輸入「mean」使用均值填補(僅對數值型特徵可用) 輸入「median"用中值填補(僅對數值型特徵可用) 輸入"most_frequent」用衆數填補(對數值型和字元型特徵都可用) 輸入「constant"表示請參考參數「fill_value"中的值(對數值型和字元型特徵都可用)
3.fill_value
當參數startegy爲」constant"的時候可用,可輸入字串或數位表示要填充的值,常用0
4.copy
預設爲True,將建立特徵矩陣的副本,反之則會將缺失值填補到原本的特徵矩陣中去。
data.info() #填補年齡
Age = data.loc[:,"Age"].values.reshape(-1,1) #sklearn當中特徵矩陣必須是二維
Age[:20]
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #範例化,預設均值填補
imp_median = SimpleImputer(strategy="median") #用中位數填補
imp_0 = SimpleImputer(strategy="constant",fill_value=0) #用0填補
imp_mean = imp_mean.fit_transform(Age) #fit_transform一步完成調取結果
imp_median = imp_median.fit_transform(Age)
imp_0 = imp_0.fit_transform(Age)
imp_mean[:20]
imp_median[:20]
imp_0[:20]
#在這裏我們使用中位數填補Age data.loc[:,"Age"] = imp_median
data.info()
#使用衆數填補Embarked Embarked = data.loc[:,"Embarked"].values.reshape(-1,1)
imp_mode = SimpleImputer(strategy = "most_frequent") data.loc[:,"Embarked"] = imp_mode.fit_transform(Embarked)
data.info()BONUS:用Pandas和Numpy進行填補其實更加簡單
import pandas as pd
data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 3 Preprocessing\Narrativedata.csv",index_col=0)
data.head()
data.loc[:,"Age"] =data.loc[:,"Age"].fillna(data.loc[:,"Age"].median()) #.fillna 在DataFrame裏面直接進行填補
data.dropna(axis=0,inplace=True) #.dropna(axis=0)刪除所有有缺失值的行,.dropna(axis=1)刪除所有有缺失值的列 #參數inplace,爲True表示在原數據集上進行修改,爲False表示生成一個複製物件,不修改原數據,預設False3.處理分型別特徵:編碼與啞變數
在機器學習中,大多數演算法,譬如邏輯迴歸,支援向量機SVM,k近鄰演算法等都只能夠處理數值型數據,不能處理 文字,在sklearn當中,除了專用來處理文字的演算法,其他演算法在fit的時候全部要求輸入陣列或矩陣,也不能夠導 入文字型數據(其實手寫決策樹和普斯貝葉斯可以處理文字,但是sklearn中規定必須匯入數值型)。然而在現實 中,許多標籤和特徵在數據收集完畢的時候,都不是以數位來表現的。比如說,學歷 學曆的取值可以是[「小學」,「初 中」,「高中」,「大學」],付費方式可能包含[「支付寶」,「現金」,「微信」]等等。在這種情況下,爲了讓數據適應演算法和 庫,我們必須將數據進行編碼,即是說,將文字型數據轉換爲數值型
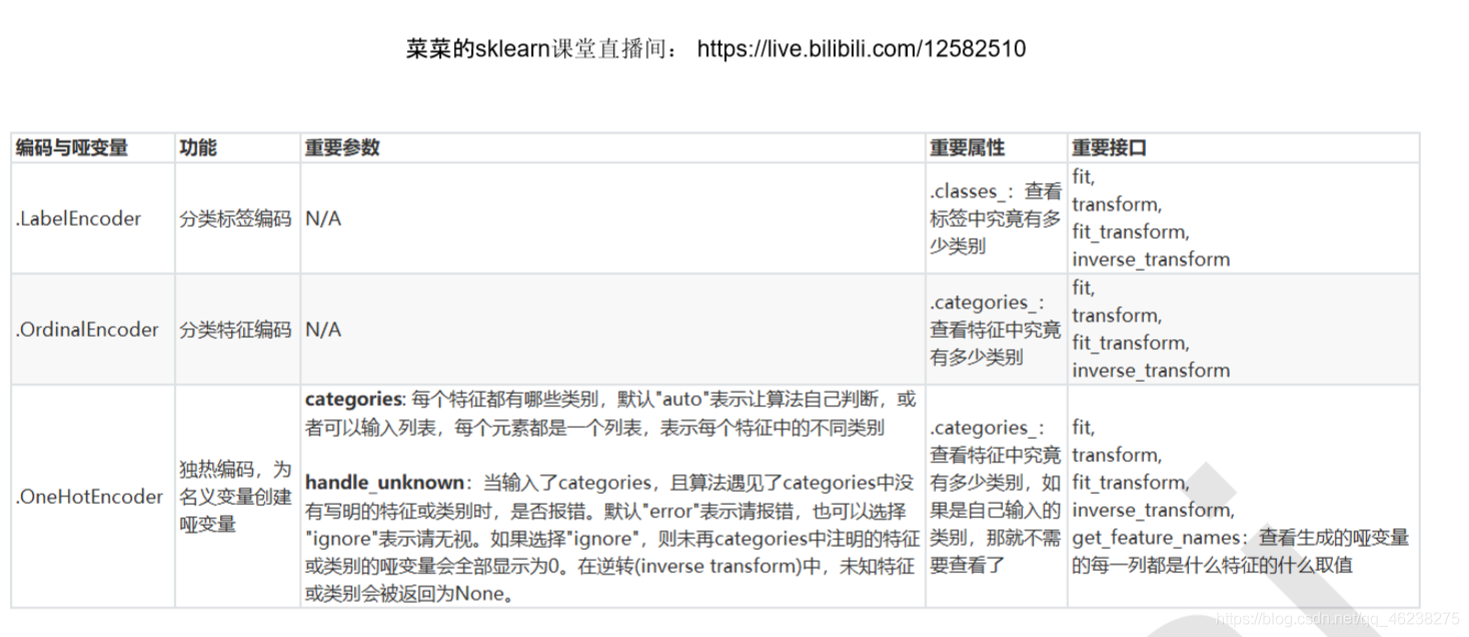
preprocessing.LabelEncoder:標籤專用,能夠將分類轉換爲分類數值
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:,-1] #要輸入的是標籤,不是特徵矩陣,所以允許一維
le = LabelEncoder() #範例化
le = le.fit(y) #匯入數據
label = le.transform(y) #transform介面調取結果
le.classes_ #屬性.classes_檢視標籤中究竟有多少類別
label #檢視獲取的結果label
le.fit_transform(y) #也可以直接fit_transform一步到位
le.inverse_transform(label) #使用inverse_transform可以逆轉
data.iloc[:,-1] = label #讓標籤等於我們執行出來的結果
data.head()
#如果不需要教學展示的話我會這麼寫:
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
preprocessing.OrdinalEncoder:特徵專用,能夠將分類特徵轉換爲分類數值
from sklearn.preprocessing import OrdinalEncoder
#介面categories_對應LabelEncoder的介面classes_,一模一樣的功能 data_ = data.copy()
data_.head()
OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
data_.head() preprocessing.OneHotEncoder:獨熱編碼,建立啞變數
我們剛纔已經用OrdinalEncoder把分類變數Sex和Embarked都轉換成數位對應的類別了。在艙門Embarked這一 列中,我們使用[0,1,2]代表了三個不同的艙門,然而這種轉換是正確的嗎?
我們來思考三種不同性質的分類數據:
1) 艙門(S,C,Q) 三種取值S,C,Q是相互獨立的,彼此之間完全沒有聯繫,表達的是S≠C≠Q的概念。這是名義變數。
2) 學歷 學曆(小學,初中,高中) 三種取值不是完全獨立的,我們可以明顯看出,在性質上可以有高中>初中>小學這樣的聯繫,學歷 學曆有高低,但是學 歷取值之間卻不是可以計算的,我們不能說小學 + 某個取值 = 初中。這是有序變數。
3) 體重(>45kg,>90kg,>135kg) 各個取值之間有聯繫,且是可以互相計算的,比如120kg - 45kg = 90kg,分類之間可以通過數學計算互相轉換。這 是有距變數。
然而在對特徵進行編碼的時候,這三種分類數據都會被我們轉換爲[0,1,2],這三個數位在演算法看來,是連續且可以 計算的,這三個數位相互不等,有大小,並且有着可以相加相乘的聯繫。所以演算法會把艙門,學歷 學曆這樣的分類特 徵,都誤會成是體重這樣的分類特徵。這是說,我們把分類轉換成數位的時候,忽略了數位中自帶的數學性質,所 以給演算法傳達了一些不準 不準確的資訊,而這會影響我們的建模。
類別OrdinalEncoder可以用來處理有序變數,但對於名義變數,我們只有使用啞變數的方式來處理,才能 纔能夠儘量 向演算法傳達最準確的資訊:

這樣的變化,讓演算法能夠徹底領悟,原來三個取值是沒有可計算性質的,是「有你就沒有我」的不等概念。在我們的 數據中,性別和艙門,都是這樣的名義變數。因此我們需要使用獨熱編碼,將兩個特徵都轉換爲啞變數。
data.head()
from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]
enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray() result
#依然可以直接一步到位,但爲了給大家展示模型屬性,所以還是寫成了三步
OneHotEncoder(categories='auto').fit_transform(X).toarray()
#依然可以還原
pd.DataFrame(enc.inverse_transform(result))
enc.get_feature_names()
result
result.shape
#axis=1,表示跨行進行合併,也就是將量表左右相連,如果是axis=0,就是將量表上下相連
newdata = pd.concat([data,pd.DataFrame(result)],axis=1)
newdata.head()
newdata.drop(["Sex","Embarked"],axis=1,inplace=True)
newdata.columns = ["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"]
newdata.head() 特徵可以做啞變數,標籤也可以嗎?可以,使用類sklearn.preprocessing.LabelBinarizer可以對做啞變數,許多算 法都可以處理多標籤問題(比如說決策樹),但是這樣的做法在現實中不常見,因此我們在這裏就不贅述了。
4.處理連續型特徵:二值化與分段
sklearn.preprocessing.Binarizer
根據閾值將數據二值化(將特徵值設定爲0或1),用於處理連續型變數。大於閾值的值對映爲1,而小於或等於閾 值的值對映爲0。預設閾值爲0時,特徵中所有的正值都對映到1。二值化是對文字計數數據的常見操作,分析人員 可以決定僅考慮某種現象的存在與否。它還可以用作考慮布爾隨機變數的估計器的預處理步驟(例如,使用貝葉斯 設定中的伯努利分佈建模)。
#將年齡二值化
data_2 = data.copy()
from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1) #類爲特徵專用,所以不能使用一維陣列
transformer = Binarizer(threshold=30).fit_transform(X)
transformerpreprocessing.KBinsDiscretize
將連續型變數劃分爲分類變數的類,能夠將連續型變數排序後按順序分箱後編碼。總共包含三個重要參數:
參數及其含義輸出
1.n_bins
每個特徵中分箱的個數,預設5,一次會被運用到所有匯入的特徵
2.encode
編碼的方式,預設「onehot」
「onehot」:做啞變數,之後返回一個稀疏矩陣,每一列是一個特徵中的一個類別,含有該
類別的樣本表示爲1,不含的表示爲0
「ordinal」:每個特徵的每個箱都被編碼爲一個整數,返回每一列是一個特徵,每個特徵下含 有不同整數編碼的箱的矩陣
「onehot-dense」:做啞變數,之後返回一個密集陣列
3.strategy
用來定義箱寬的方式,預設"quantile"
「uniform」:表示等寬分箱,即每個特徵中的每個箱的最大值之間的差爲
(特徵.max() - 特徵.min())/(n_bins)
「quantile」:表示等位分箱,即每個特徵中的每個箱內的樣本數量都相同
「kmeans」:表示按聚類分箱,每個箱中的值到最近的一維k均值聚類的簇心得距離都相同
from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:,0].values.reshape(-1,1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(X)
#檢視轉換後分的箱:變成了一列中的三箱
set(est.fit_transform(X).ravel())
est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform') #檢視轉換後分的箱:變成了啞變數
est.fit_transform(X).toarray()