一篇文徹底理解KNN演算法 - 我點了一包華子,終於明白了海倫是個好女孩
一篇文徹底理解KNN演算法 - 我點了一包華子,終於明白了海倫是個好女孩
大家好,我是W
這次我們要手撕KNN,同時自己實現KNN。當然KNN的思想很簡單,所以重點會放在實現自己的KNN上。K-近鄰(KNN,K-NearestNeighbor)演算法是一種基本分類與迴歸演算法,這一篇文中我們用來實現分類。接下來的內容順序是:KNN演算法的原理、案例1-海倫約會、案例2-手寫數位識別。
KNN演算法的原理
假設在你面前擺設有一堆瓜子,你只能通過觀察其外表來分別瓜子的好壞,那麼你能夠獲得的觀察維度只能包括兩種特徵:瓜子殼的破損情況、瓜子的香味。因爲瓜子最初並沒有標籤,所以你並不知道瓜子好壞的標準,所以你被允許記錄並試吃一百顆瓜子。所以你在試吃的過程中得到了100顆瓜子的資訊,接下來你需要根據學習到的資訊來對剩餘的瓜子進行分類,所以你選擇的策略是**「在座標軸中標出試吃過的瓜子的座標,並且對每一顆需要判斷的瓜子也標註在座標軸中,最終通過與待判斷瓜子最近的K個已知瓜子的好壞程度來判斷其好壞」**。
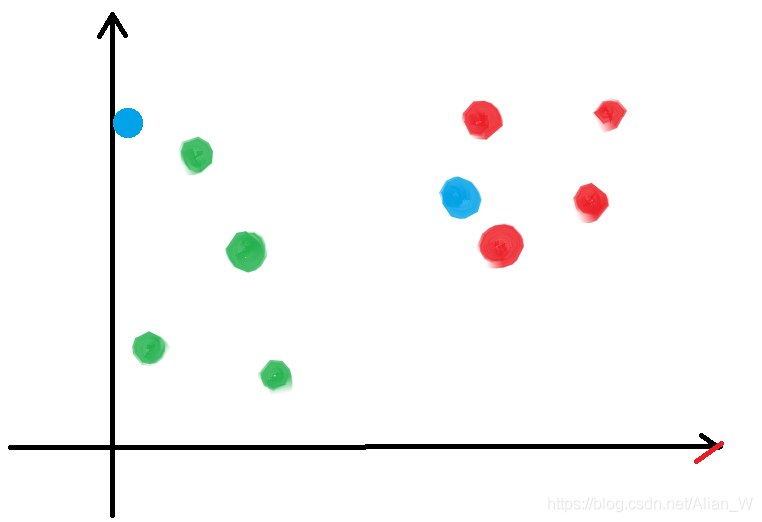
所以,KNN的核心就是一句話「近朱者赤」。
KNN的開發流程
| 步驟 | 方法 |
|---|---|
| 收集數據 | 任何方法 |
| 準備數據 | 得到計算所需的格式 |
| 分析數據 | 任何方法 |
| 測試演算法 | 計算準確率等指標 |
| 使用演算法 | 輸入樣本數據和結構化的輸出結果,執行knn判斷類別 |
KNN的特點
| 優點 | 缺點 |
|---|---|
| 精度高 | 計算複雜度高 |
| 對異常值不敏感、無數據輸入假定 | 空間複雜度高 |
適用數據範圍: 數值型和標稱型
案例1 - 海倫約會
案例背景
海倫在相親網站找約會物件,經過一段時間之後,她發現曾交往過三種類型的人:
- 不喜歡的人
- 魅力一般的人
- 極具魅力的人
並且她希望:
- 工作日跟魅力一般的人約會
- 週末與極具魅力的人約會
- 排除不喜歡的人
現在,她收集到了一些約會網站未曾記錄的數據資訊,這更有助於匹配物件的歸類。
開發流程
- 觀察數據集
- 解析數據集
- 分析數據集
- 測試演算法
1’ 觀察數據集
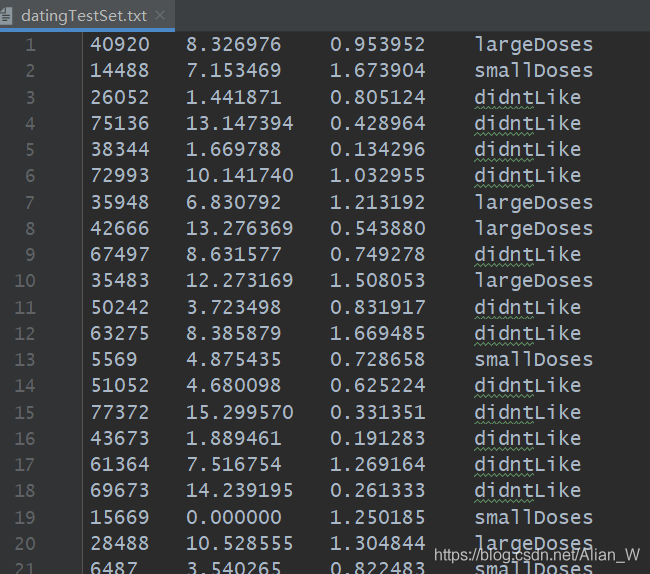
點選這裏下載數據集,海倫的數據集中共有三個特徵,分別是:
- 每年飛行公裡數
- 玩videoGame的時間佔比
- 每週消耗雪糕公升數
可以看到數據集並沒有表頭,但是還是可以清楚分辨出對應數據,並且第四列很明顯表示的是海倫對該樣本的喜愛程度。數據集共有1000個樣本,不是很大。
2’ 解析數據集
這一步我們使用pandas庫來對數據進行解析。
import pandas as pd
def read_data(file_path):
"""
讀取數據集
:param file_path: 檔案路徑
:return: dating_data
"""
dating_data = pd.read_csv(file_path, delimiter="\t", names=["飛行公裡數", "遊戲時間比例", "雪糕消耗", "喜愛程度"])
data = dating_data.iloc[:, :3]
target = dating_data.iloc[:, 3]
return data, target
3’ 分析數據集
在分析數據集這一步,我們使用matplotlib的pyplot從幾個角度分別畫出其二維散點圖。
import matplotlib.pyplot as plt
def draw_raw_data_01(data):
"""
畫出海倫約會數據集中遊戲時間與飛行時間分佈散點圖
:param data: [1000,4] 矩陣
:return: None
"""
plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文
plt.rcParams['axes.unicode_minus'] = False # 顯示負號
plt.figure(figsize=(20, 9), dpi=100)
plt.xlabel("飛行公裡數")
plt.ylabel("遊戲時間佔比")
plt.title("海倫約會數據集飛行公裡數與遊戲時間佔比喜愛程度分佈圖")
g1 = plt.scatter(x=data[data["喜愛程度"] == "largeDoses"]["飛行公裡數"], y=data[data["喜愛程度"] == "largeDoses"]["遊戲時間比例"],
c="red")
g2 = plt.scatter(x=data[data["喜愛程度"] == "smallDoses"]["飛行公裡數"], y=data[data["喜愛程度"] == "smallDoses"]["遊戲時間比例"],
c="blue")
g3 = plt.scatter(x=data[data["喜愛程度"] == "didntLike"]["飛行公裡數"], y=data[data["喜愛程度"] == "didntLike"]["遊戲時間比例"],
c="black")
plt.legend(handles=[g1, g2, g3], labels=["largeDoses", "smallDoses", "didntLike"], prop={'size': 16})
plt.savefig("./dataset/dating_pic/飛行時間與遊戲佔比分佈圖.png")
def draw_raw_data_02(data):
"""
畫出海倫約會數據集中飛行公裡數與雪糕消耗分佈散點圖
:param data: [1000,4] 矩陣
:return: None
"""
plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文
plt.rcParams['axes.unicode_minus'] = False # 顯示負號
plt.figure(figsize=(20, 9), dpi=100)
plt.xlabel("飛行公裡數")
plt.ylabel("雪糕消耗")
plt.title("海倫約會數據集飛行公裡數與雪糕消耗佔比喜愛程度分佈圖")
g1 = plt.scatter(x=data[data["喜愛程度"] == "largeDoses"]["飛行公裡數"], y=data[data["喜愛程度"] == "largeDoses"]["雪糕消耗"],
c="red")
g2 = plt.scatter(x=data[data["喜愛程度"] == "smallDoses"]["飛行公裡數"], y=data[data["喜愛程度"] == "smallDoses"]["雪糕消耗"],
c="blue")
g3 = plt.scatter(x=data[data["喜愛程度"] == "didntLike"]["飛行公裡數"], y=data[data["喜愛程度"] == "didntLike"]["雪糕消耗"],
c="black")
plt.legend(handles=[g1, g2, g3], labels=["largeDoses", "smallDoses", "didntLike"], prop={'size': 16})
plt.savefig("./dataset/dating_pic/飛行時間與雪糕消耗分佈圖.png")
def draw_raw_data_03(data):
"""
畫出海倫約會數據集中遊戲時間比例與雪糕消耗的喜愛成圖散點圖
:param data: [1000,4] 矩陣
:return: None
"""
plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文
plt.rcParams['axes.unicode_minus'] = False # 顯示負號
plt.figure(figsize=(20, 9), dpi=100)
plt.xlabel("遊戲時間比例")
plt.ylabel("雪糕消耗")
plt.title("海倫約會數據集遊戲時間比例與雪糕消耗佔比喜愛程度分佈圖")
g1 = plt.scatter(x=data[data["喜愛程度"] == "largeDoses"]["遊戲時間比例"], y=data[data["喜愛程度"] == "largeDoses"]["雪糕消耗"],
c="red")
g2 = plt.scatter(x=data[data["喜愛程度"] == "smallDoses"]["遊戲時間比例"], y=data[data["喜愛程度"] == "smallDoses"]["雪糕消耗"],
c="blue")
g3 = plt.scatter(x=data[data["喜愛程度"] == "didntLike"]["遊戲時間比例"], y=data[data["喜愛程度"] == "didntLike"]["雪糕消耗"],
c="black")
plt.legend(handles=[g1, g2, g3], labels=["largeDoses", "smallDoses", "didntLike"], prop={'size': 16})
plt.savefig("./dataset/dating_pic/遊戲時間比例與雪糕消耗分佈圖.png")
因爲總共就3個特徵,所以只需要畫出3張2維圖片就可以了,當然如果會花3-D的會更好,可惜我不會=。=
最終得到的圖片分別是:
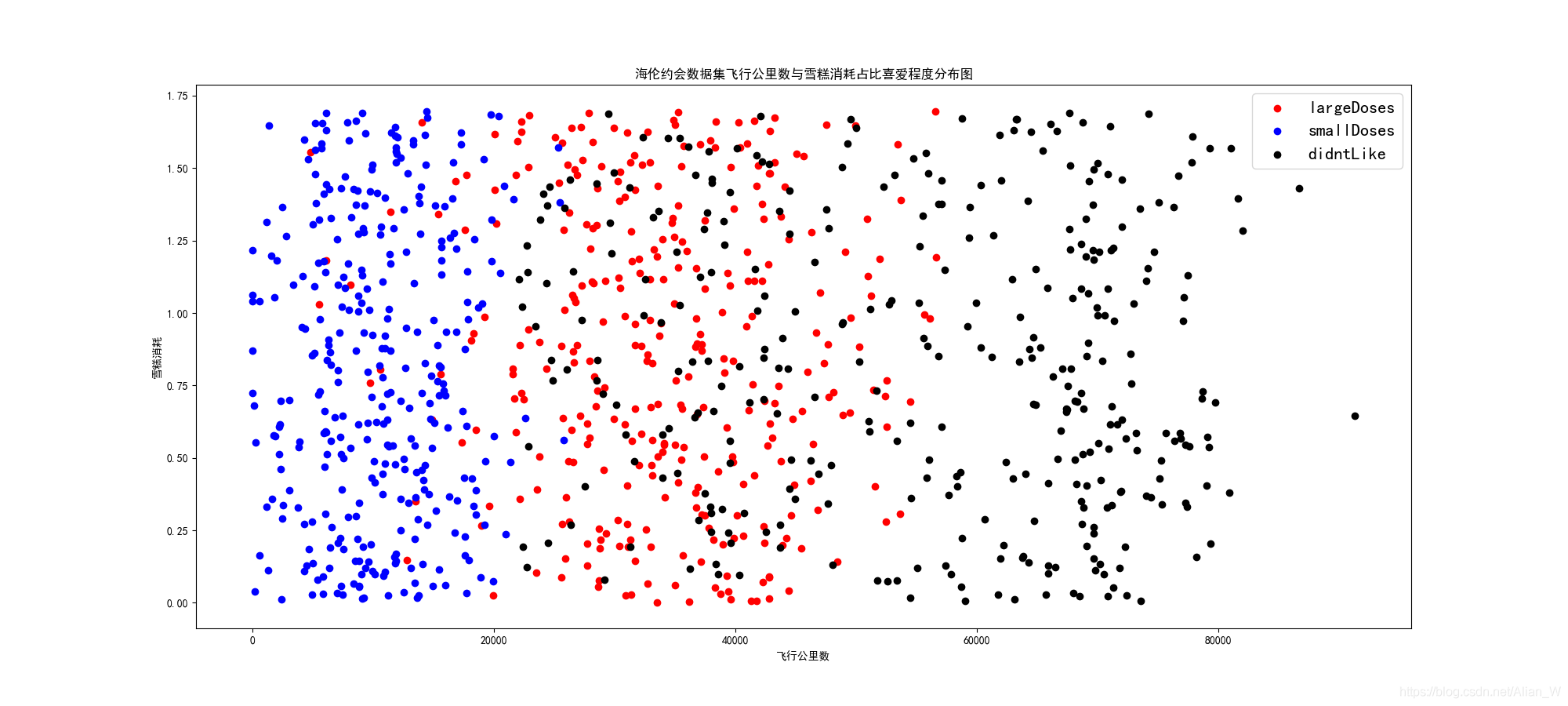
在上圖可以看到,藍、紅、黑三種點可以說是區分的很明顯的,對於飛行公裡數小於20000的男士,海倫的態度是smallDoses,即不是熱愛但也不討厭。對於飛行公裡數在20000~50000的男士,海倫大多數的態度是熱愛的。而對於飛行公裡數大於50000的男士,海倫顯然是didn’tLike的。
飛行公裡數在實際場景中可能代表着男人的事業,所以說,海倫對於男性的要求是希望對方有自己的事業(紅區),但是又能夠有時間陪陪自己(藍區),而對於只顧着工作的工作狂,海倫是沒有好感的(黑區)。
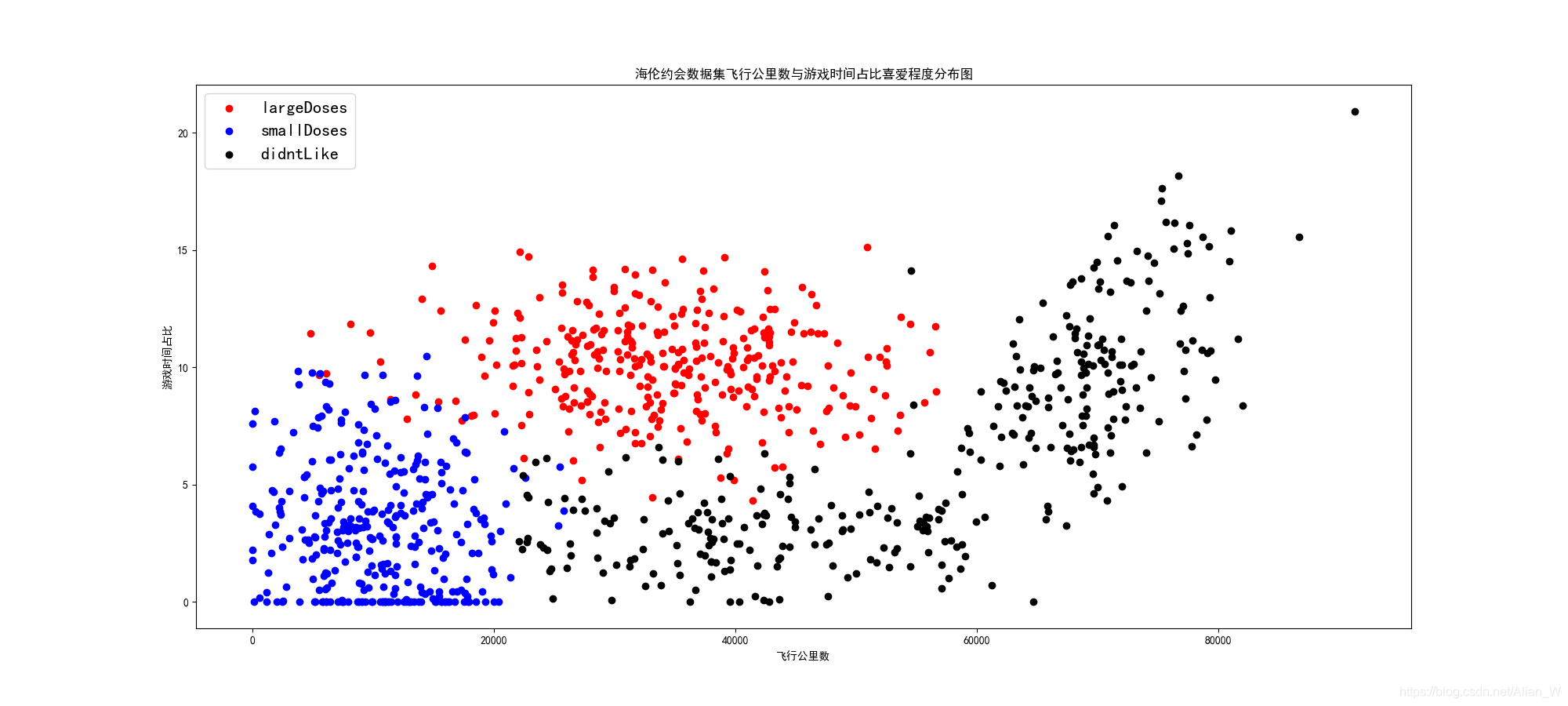
在這張圖可以看到,橫軸依然是飛行公裡數,縱軸則變成了遊戲時間佔比。與上一張圖一樣,我們可以在2萬公裡和5萬公裡處畫一條線。那麼上圖就會分爲左中右三個區域,對於左邊區域可以看到大部分的態度是smallDoses,而對於中間區域又可以分爲上下兩部分,上部分是largeDoses,下部分是didn’tLike,而右邊區域則基本上都是didn’tLike。
這就很有意思了,在實際場景中,遊戲時間可能代表着男生的幽默程度。所以說,海倫可以接受事業不繁忙,同時也沒那麼有趣的人(可能這就是女生的安全感吧,你可以陪着我,哪怕不是那麼優秀=。=)。海倫熱愛的是有自己的事業,同時相當有趣的男生(這是誰都會熱愛吧,又有事業又幽默),海倫討厭的是一心只顧着事業,沒有幽默感或者雖然有幽默感但是相當繁忙的男生。
所以,可以看出海倫更希望男朋友能夠多陪陪自己,給自己帶來快樂,有自己的事業是好事,但是沒有也沒關係啊!
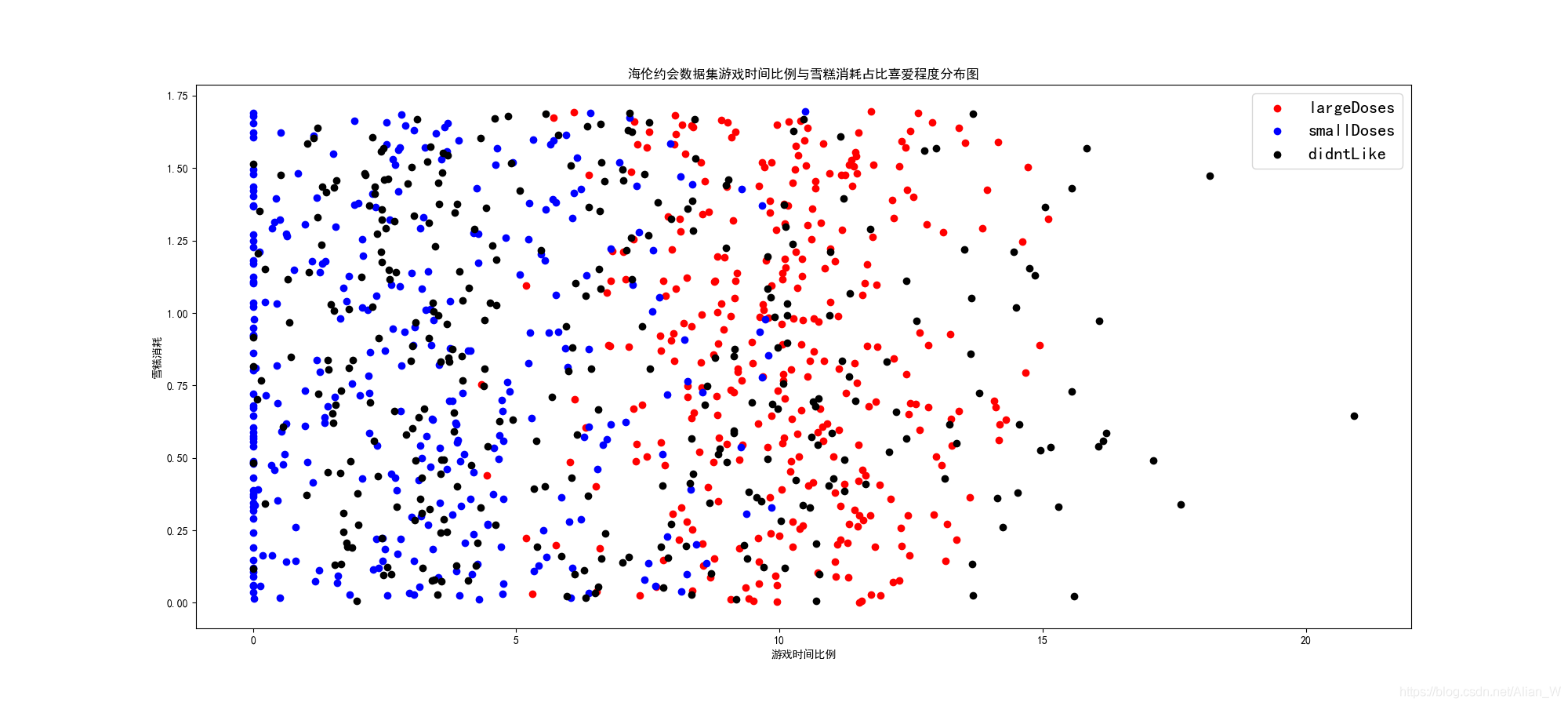
這張圖可以看到三色點散亂分佈在座標軸上,並沒有像上兩張圖那麼清晰的劃分,這就表明雪糕消耗對於海倫的喜好並沒有良好的區分。但是可以看到:
- 黑色均勻分佈在各個角落
- 藍色和紅色依然有一條較爲清晰的分界線,即遊戲佔比爲7%左右
首先,雪糕消耗在實際場景中可以理解爲男生的身材,雖然我們沒有把數據拉到3維來看,但是依然可以想象到,在上兩張圖中海倫厭惡的往往是過於繁忙和無趣的人,並且在這張圖中並沒有因雪糕消耗而產生的明顯分界,可以看出海倫並不是那麼看臉的人!
綜上,海倫希望尋找的是有自己的事業、幽默風趣的男生,她對自己的另一半身材相貌並沒有明顯的要求。她希望另一半能夠多陪陪自己(哪怕對方沒那麼有趣),而不是每天顧着工作不着家(哪怕對方很幽默)。當我從新看到這個數據我深深的陷入了沉思,抽了一包中華我才逐漸醒悟過來,原來海倫是個好女孩,她並不虛榮,並不看顏,她需要的是真真實實的,能夠跟她腳踏實地地過日子的男孩,陪伴對她來說勝過一切。
4’ 測試演算法
歸一化
因爲數據量綱的不同可以考慮歸一化,但是對於KNN分類來說這個並不是問題。但是歸一化的確可以帶來一些好處:
- 可以把數據限制在一定的範圍內
- 方便後期數據的處理
- 保證程式執行時收斂加快
歸一化的方法有很多,我們採用最常見的0-1歸一化:
import numpy
def to_normalize(data):
"""
給數據做(0,1)歸一化
:param data: [1000,4]
:return: data_normed
"""
# minVal_0 = min(data["飛行公裡數"])
# maxVal_0 = max(data["飛行公裡數"])
# print(minVal_0, maxVal_0)
# minVal_1 = min(data["遊戲時間比例"])
# maxVal_1 = max(data["遊戲時間比例"])
# print(minVal_1, maxVal_1)
# minVal_2 = min(data["雪糕消耗"])
# maxVal_2 = max(data["雪糕消耗"])
# print(minVal_2, maxVal_2)
# 取得data裡的每個特徵的最小值、最大值
minVal = data.min(0)
maxVal = data.max(0)
# 各個特徵的極差
ranges = maxVal - minVal
# print(ranges)
# 使用numpy生成新矩陣
new_matrix = numpy.zeros(shape=numpy.shape(data)) # [1000, 3]
# 做(0,1)歸一化
for i in range(numpy.shape(data)[0]):
new_matrix[i][0] = (data["飛行公裡數"][i] - minVal[0]) / ranges[0]
new_matrix[i][1] = (data["遊戲時間比例"][i] - minVal[1]) / ranges[1]
new_matrix[i][2] = (data["雪糕消耗"][i] - minVal[2]) / ranges[2]
return new_matrix
knn測試
import operator
def my_knn(data_normed, sample, labels, k=3):
"""
實現KNN演算法
:param data_normed: 歸一化後的樣本集
:param sample: 需要predict的樣本
:param k: 最近的k個人
:return: final_label
"""
# 通過sample陣列構建[1000,3]矩陣,然後實現矩陣相減得到new_data_normed
new_data_normed = tile(sample, (data_normed.shape[0], 1)) - data_normed
print(tile(sample, (data_normed.shape[0], 1)))
# 計算歐氏距離
double_matrix = new_data_normed ** 2
double_distance = double_matrix.sum(axis=1)
sqrt_distance = double_distance ** 0.5
new_matrix = pd.DataFrame()
new_matrix["distance"] = sqrt_distance
new_matrix["label"] = labels
# 排序
new_matrix = new_matrix.sort_values(by=["distance"], ascending=True)
# 取前k個
final_matrix = new_matrix.iloc[:k, :]
label_dict = {"didntLike": 0, "smallDoses": 0, "largeDoses": 0}
for i in range(k):
label_dict[final_matrix.iloc[i]["label"]] += 1
print(label_dict)
sorted_label = sorted(label_dict.items(), key=operator.itemgetter(1), reverse=True)
return sorted_label[0][0]
在這一個環節涉及一些numpy庫中的矩陣運算,大家若是由看不懂的地方我推薦可以列印出來看一看數據型別和實際數據,並不難理解。
主調函數
if __name__ == '__main__':
file_path = "./dataset/datingTestSet.txt"
data, target = read_data(file_path)
# print(data)
# draw_raw_data_01(data)
# draw_raw_data_02(data)
# draw_raw_data_03(data)
data_normed = to_normalize(data)
print(data_normed)
# 由於懶得對測試數據做歸一化所以直接寫入
sample = [0.29115949, 0.50910294, 0.51079493]
label = my_knn(data_normed, sample, target, k=3)
print("KNN結果是:", label)
案例2-手寫數位識別
案例背景
手寫數位識別也是tensorflow的一個經典案例,但是這個案例一樣可以使用KNN演算法來做。
開發流程
- 觀察數據集
- 解析數據集
- 測試演算法
1’ 觀察數據集
點選這裏可以下載數據集,提取碼:xrm6。開啓數據集可以看到兩個資料夾,一個是trainingDigits一個是testDigits,裏面的檔案都是txt格式的,並且檔案命名規則都是標籤_編號.txt格式,所以可以預測到我們需要對檔名做處理得到標籤。
點開txt檔案,可以看到是一個32*32的[0,1]矩陣,1的位置表示手寫數位的位置。
2’ 分析數據集
數據集標籤需要通過python的os模組和字串split拿到,我們需要做成一個np.array型別,也可以考慮與數據部分合併成一個DataFrame。
因爲本次使用的是KNN,並且矩陣是[0,1]矩陣,顯然不需要做歸一化,我們需要做的就是把矩陣從[32,32]轉變爲[1,1024]形狀。
3’ 測試演算法
這裏直接把整個程式碼貼上來了,但是不建議大家去讀。我建議大家可以自己想想如何去做,這裏的難點主要是數據讀取和處理的過程,KNN的過程其實和海倫約會一樣。
import os
import operator
import pandas as pd
import numpy as np
def read_data(file_path):
"""
讀取指定目錄下的所有txt檔案
並且[32,32] -> [1024,1] 的data轉換
並且獲取每一個檔案的target 做成一個向量
:param file_path: 需要讀取的資料夾路徑
:return: DataFrame[data,target]
"""
dir_list = os.listdir(file_path)
data = pd.DataFrame(columns=("data", "target"))
for file_name in dir_list:
# 獲得目標值
file_target = file_name.split(sep="_")[0]
# 讀取txt檔案,轉爲[1024,1]
data_32 = pd.read_table(filepath_or_buffer=file_path + file_name, header=None)
# df格式轉爲np.array
data_32 = np.array(data_32)
new_str = ""
for i in data_32:
new_str += i[0]
# 向dataframe中加一行
data = data.append({"data": new_str, "target": file_target}, ignore_index=True)
return data
def df_to_np(data):
"""
將df物件矩陣轉爲np.array矩陣
:param data: df型別 ["data","target"]
:return: np.array
"""
data = data["data"]
# 需要先做一個0向量才能 纔能生成
np_matrix = np.array(np.zeros(shape=(1, 1024)))
# 先構造一個np矩陣 因爲最小0 最大1 所以不需要歸一化了
for item in data:
item_list = []
for index in item:
item_list.append(int(index))
item_nparray = np.array(item_list)
np_matrix = np.row_stack((np_matrix, item_nparray))
np_matrix = np_matrix[1:]
# 把第一行全0除去
return np_matrix
def my_knn(line, train_matrix, train_label, k):
np_matrix = np.tile(line, (train_matrix.shape[0], 1)) - train_matrix
# 計算歐式距離
double_matrix = np_matrix ** 2
double_distance = double_matrix.sum(axis=1)
distance = double_distance ** 0.5
new_matrix = pd.DataFrame()
new_matrix["distance"] = distance
new_matrix["label"] = train_label
# 排序
new_matrix = new_matrix.sort_values(by=["distance"], ascending=True)
# 取前k個
final_matrix = new_matrix.iloc[:k, :]
label_dict = {}
for i in range(10):
label_dict[str(i)] = 0
for i in range(k):
label_dict[final_matrix.iloc[i]["label"]] += 1
sorted_label = sorted(label_dict.items(), key=operator.itemgetter(1), reverse=True)
print(sorted_label[0][0])
return sorted_label[0][0]
def cal_acc_recall(train_data, test_data, k=3):
"""
通過train_data來實現knn,然後遍歷test_data來算acc recall
:param train_data: 訓練集
:param test_data: 測試集
:param k: k個最臨近值
:return: None
"""
train_matrix = df_to_np(train_data)
train_label = train_data["target"]
test_matrix = df_to_np(test_data)
test_label = test_data["target"]
print(test_label[0])
# 計數器
iter = 0
# acc_num
acc_num = 0
for line in test_matrix:
predict_label = my_knn(line, train_matrix, train_label, k)
acc_num = acc_num + 1 if predict_label == test_label[iter] else acc_num
iter += 1
# 準確率
print("準確率是%f" % (acc_num / (iter + 1)))
# 召回率 懶得做了
return None
if __name__ == '__main__':
# 1' 讀取數據集、返回data,target
trainingDigits_path = "./dataset/knn-handwriting_num/trainingDigits/"
testDigits_path = "./dataset/knn-handwriting_num/testDigits/"
train_data = read_data(trainingDigits_path)
# 2' 讀取測試數據集
test_data = read_data(testDigits_path)
# 3' 使用KNN對test_data一一測試
cal_acc_recall(train_data, test_data, 3)
專案地址
吃完飯先,在搞。