【Muti-instance Learning 】論文閱讀與翻譯——Neural Networks for Multi-Instance Learning.(2002)
Z.-H. Zhou and M.-L. Zhang.Neural Networks for Multi-Instance Learning. Technical Report, AI Lab, Department of Computer Science & Technology, Nanjing University, Nanjing, China, Aug. 2002.
摘要
多範例學習是Dietterich等人提出的。在他們對藥物活性預測的研究中。在這樣的學習框架中,訓練範例是由範例組成的袋子,任務是通過分析帶有已知標籤的訓練袋子來預測未看見袋子的標籤。如果一個包至少包含一個正範例,則爲正;如果不包含正範例,則爲負。但是,構成訓練袋的範例的標籤是未知的。在本文中,解決了爲神經網路設計多範例修改的開放性問題。詳細地,提出了一種稱爲BP-MIP的神經網路演算法,該演算法是從流行的BP演算法派生而來,它採用了捕獲多範例學習性質的新誤差函數,即訓練包的標籤而不是訓練的標籤範例是已知的。在現實世界和人工基準多範例數據上的實驗表明,BP-MIP的效能可與某些完善的多範例學習方法相媲美。
1 Introduction
目前,從範例中學習被認爲是最有前途的機器學習方法[19]。根據Maron [16]的觀點,有3個框架可供學習。也就是說,監督學習,無監督學習和強化學習。監督學習嘗試學習正確標記未見範例的概念,其中訓練範例帶有標籤。無監督學習嘗試學習範例基礎資源的結構,其中培訓範例沒有標籤。強化學習嘗試學習從狀態到動作的對映,其中範例沒有標籤,但獎勵延遲,可以將其視爲延遲標籤。
Dietterich等。 [9]在他們的藥物活性預測研究中提出了多範例學習的概念。在多範例學習中,訓練集由許多包含許多範例的包組成。如果一個袋子包含至少一個陽性範例,則將其標記爲陽性袋子。否則,它被標記爲負袋。訓練袋的標籤是已知的,但是訓練範例的標籤是未知的。任務是從培訓中學習一些知識,以正確標記看不見的袋子。由於這類問題與監督學習,無監督學習和強化學習所解決的問題大不相同,因此,多範例學習被視爲從範例中學習的第四框架[16]。
當提出多範例學習的概念時,Dietterich等人。 [9]指出,在這一領域中一個特別有趣的問題是爲神經網路設計多範例修改。在本文中,通過提出一種名爲BP-MIP的神經網路演算法(即用於多範例問題的BP)來解決此開放問題。顧名思義,BP-MIP是從流行的BP演算法[23]派生而來,它通過將其誤差函數替換爲定義爲捕獲多範例學習性質的新函數(即,訓練包的標籤而不是訓練包的標籤)來定義的訓練範例是已知的。藥物活性預測數據(目前是唯一用於多範例學習的真實世界基準測試數據)和一些人工基準多範例數據的實驗表明,BP-MIP獲得的結果可與某些完善的多實體方法。
本文的其餘部分安排如下。在第2節中,簡要介紹了藥物活性預測問題。在第3節中,回顧了以前有關多範例學習的著作。在第4節中,介紹了BP-MIP。在第5節中,報告了BP-MIP在現實世界和人工數據上的實驗。最後,在第6節中,總結了本文的主要貢獻,並指出了一些未來的工作。
2 Drug Activity Prediction
大多數藥物都是通過與較大的蛋白質分子(例如酶和細胞表面受體)結合而起作用的小分子。藥物的效力取決於結合程度。對於有資格製造藥物的分子,其低能量形狀之一可以緊密結合到目標區域。儘管對於不合格的分子無法製造藥物,但其低能形狀都無法與目標區域緊密結合。
在1990年代中期,Dietterich等人[9]研究了藥物活性預測的問題。目的是通過分析已知分子的集合,使學習系統具有預測新分子是否有資格製造某些藥物的能力。這個問題的主要困難是每個分子可能具有許多其他的低能形狀,如圖1所示。但是生物化學家只知道一個分子是否有資格製造藥物,而不知道它的哪個。替代的低能耗影響了資格認證的反應。
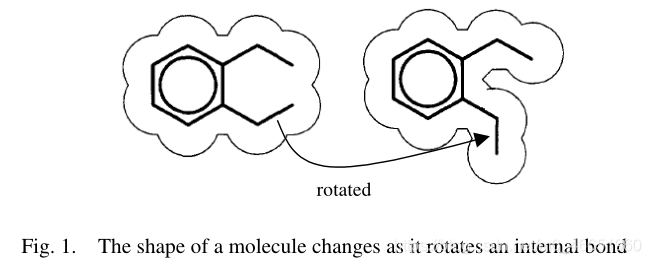
一個直觀的解決方案是通過將有資格使該藥物製成的分子的所有低能形狀視爲正訓練範例,而將所有不具有使該藥物製成的分子的所有低能形狀作爲負訓練範例來使用監督學習演算法。 。但是,如Dietterich等所示。 [9],這種方法幾乎行不通,因爲可能有很多錯誤的肯定例子。
爲了解決這個問題,Dietterich等。 [9]將每個分子視爲一個袋子,並將該分子的其他低能形狀視爲袋子中的範例,從而制定了多範例學習方法。爲了表示形狀,將分子放置在標準位置和方向,然後構造一組從原點發出的162射線,以便對分子表面進行大致均勻的採樣,如圖2所示。代表分子表面氧原子位置的四個特徵。因此,袋子中的每個範例都由166維數位特徵向量表示。
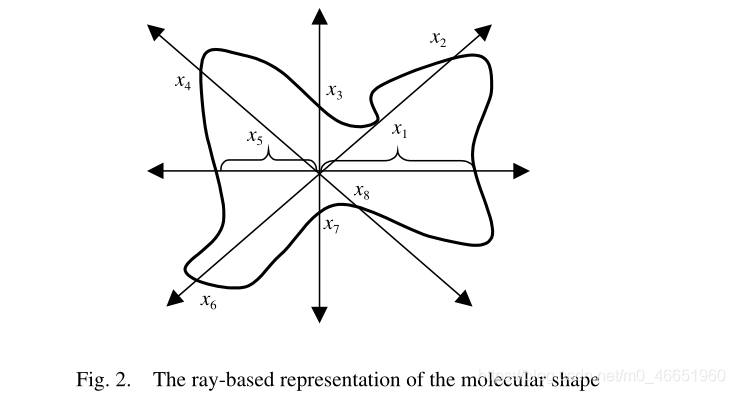
基於這樣的表述,Dietterich等。 [9]提出了三種Axis-Parallel Rectangle(縮寫爲APR)演算法,該演算法試圖搜尋由特徵的結合構成的適當的Axis-parallel矩形。他們的實驗表明,迭代分叉APR演算法在Musk數據上取得了最佳結果,而Musk數據是迄今爲止唯一的用於多範例學習的真實基準測試數據,而流行的監督學習演算法(例如C4.5)的效能決策樹和BP神經網路非常差。注意Dietterich等。 [9]指出,由於APR演算法已針對Musk數據進行了優化,因此,迭代式APR的效能可能是該數據的上限。
應當指出,從藥物活性預測中不會突然出現多範例問題。實際上,它們廣泛存在於現實應用中[14,24]。但是,不幸的是,直到Dietterich等人爲止,機器學習社羣纔對此類問題沒有給予特別的關注。 [9]。
3 Previous Work Review
學習演算法,用於學習一類恆定尺寸的幾何圖案,該模型可同時容忍噪聲和概念偏移。後來,對該演算法進行了擴充套件,使其可以處理實值輸出[11]。 Long和Tan [15]發起了在多範例學習框架下對平行軸矩形的PAC可學習性的研究。藉助P概念[13],他們表明,如果袋中的範例是從產品分佈中獨立得出的,則APR是PAC可學習的。他們還描述了多項式時間理論演算法。 Auer等。 [3]表明,如果包中的範例不是獨立的,則在多範例學習框架下的APR學習是NP難的。此外,他們提出了一種理論演算法,該演算法不需要產品分配,但樣本複雜度比Long和Tan的演算法要小。後來,該理論演算法被轉換爲名爲MULTINST的實用演算法[2]。 Blum和Kalai [5]描述了從多範例學習框架下的PAC學習問題減少到帶有隨機隨機分類噪聲的PAC學習的問題。在統計查詢模型[12]的幫助下,他們還提出了一種理論演算法,其樣本複雜度比Auer等人的演算法小。高盛等。 [10]提出了一種有效的線上不可知多範例
如上所述,理論機器學習社羣爲多範例學習做出了很大貢獻。但是,由於大多數結果是在諸如袋子中範例數必須爲常數之類的假設下獲得的,在實際問題中通常並非如此,因此這些結果很難直接用於實際應用中。
幸運的是,應用機器學習社羣已經提出了一些用於多範例學習的實用演算法,其中最著名的就是Maron和Lozano-Pérez提出的「多樣密度演算法」 [17]。以以下方式定義特徵空間中某個點的不同密度:正點袋越多,該點附近的負範例越少,該點的多樣性越大。因此,學習任務被轉換爲在特徵空間中以最大的不同密度搜尋點。該演算法已成功應用於一系列任務。首先是從一系列影象中學習一個人的簡單描述[17],其中影象被視爲包,而從影象中採樣的子影象被視爲相應包中的範例。對於每個影象,如果出現了特定的人,則將相應的袋子正面標記。否則,袋子會貼負標籤。第二項任務是選股,即出於根本原因選擇股票表現良好[17]。在此任務中,每月收益最高的100只股票被視爲一個正袋,而收益最低的5只股票被視爲一個負袋,其中該股票被視爲範例。第三個任務是自然場景分類[18],其中將影象視爲袋子,而從影象中採樣的斑點[18]被視爲相應袋子中的範例。如果使用者對影象的一部分(例如瀑布)感興趣,那麼將相應的袋子正面標記。否則,袋子會貼負標籤。最近,多樣密度演算法得到了擴充套件,並應用於基於內容的影象檢索[26]。(???)
Wang and Zucker [25]通過採用Hausdorff距離擴充套件了k-最近鄰演算法,用於多範例學習。提出了兩種演算法,即貝葉斯kNN和引文kNN。 Bayesian-kNN通過使用貝葉斯理論分析鄰近的袋子來標記袋子。 Citation-kNN借用了科學參考文獻的參照概念,它不僅通過分析鄰近的袋子,而且還通過分析將相關袋子視爲鄰居的袋子來標記袋子。 Ruffo [22]提出了一種名爲Relic的決策樹演算法,它是C4.5的多範例版本。後來,Chevaleyre和Zucker [6]導出了ID3-MI和RIPPER-MI,它們是決策樹演算法ID3和規則學習演算法RIPPER的多範例版本,其中的關鍵是多範例熵和多範例覆蓋函數分別。
值得一提的是,Chevaleyre和Zucker [6]指出,某些任務(例如自然場景分類)與自然界中的毒品活動預測完全不同。這是因爲在藥物活性預測中,袋子的範例是袋子的替代描述,不能同時出現。在自然場景分類中,袋子的範例是袋子不同部分的描述,應同時出現。爲了區分這兩種情況,Chevaleyre和Zucker [6]創造了術語「多部分學習」的情況,這些情況是袋子的部分描述,而範例是袋子的替代描述的情況。袋。但是,他們指出多部分問題可以通過多範例學習演算法來解決[6]。
在多範例學習的早期,大多數工作都是在離散值輸出的多範例分類上進行的。最近,具有實值輸出的多範例迴歸開始引起一些研究人員的注意。 Ray和Page [20]表明,多範例迴歸任務的一般公式是NP-hard,並提出了一種基於EM的多範例迴歸演算法。 Amar等。 [1]擴充套件了多元密度演算法進行多範例迴歸。此外,他們設計了一些人爲生成多迴歸數據的方法。可從http://www.cs.wustl.edu/~sg/ multi-inst-data /獲取其數據集。
多範例學習甚至引起了歸納邏輯程式設計社羣的關注。 De Raedt [8]指出,多範例問題可以看作是歸納邏輯程式設計的一個偏見。他還建議,多範例範式可能是命題和關係表示之間的關鍵,比前者更具表現力,比後者更容易學習。 Zucker和Ganascia [28,29]提出了REPEAT,這是一種基於獨創性偏見的ILP系統,它首先在多範例數據庫中重新構造了關係範例,然後通過多範例學習者得出了最終的假設。
值得注意的是,當Dietterich等人。 [9]創造了多範例學習一詞,他們指出,在這一領域中一個特別有趣的問題是爲決策樹,神經網路和其他流行的機器學習演算法設計多範例修改。近年來,已經提出了多範例版本的決策樹[6,22],規則學習演算法[6]和惰性學習演算法[25]。但是,到目前爲止,設計用於多範例學習的神經網路仍然是一個懸而未決的問題。
4 BP-MIP
假設訓練集由N個包組成,即{B1,B2,…,BN},第i個包由Mi個範例組成,即{Bi1,Bi2,…,iiM B},每個範例都是p維特徵向量,例如第i個包的第j個範例是[Bij1,Bij2,…,Bijp] T。正訓練包的期望輸出爲1,而負訓練包的期望輸出爲0。現在假設使用具有p個輸入單元和一個輸出單元的神經網路從訓練集中學習。由於多範例學習的目標是預測看不見的袋子的標籤,因此訓練集上網路的全域性誤差可以定義爲:(頁1)
式(2)表示,如果至少將一個正面訓練包的範例完美地預測爲正,或者如果將一個負面包的所有範例均完美地預測爲負,則所關注袋子的誤差爲零,且權重爲網路將不會更新。否則,將根據該範例的錯誤來更新權重,該範例的對應實際輸出在包中所有範例中最大。注意,這種情況對於正極袋最容易被預測爲陽性,而對於負極袋最難以預測爲陰性。看起來這對產生正輸出負有低負擔,但對產生負輸出負有沉重負擔。但是,正如Amar等。文獻[1]指出,一個袋子的價值完全取決於其範例的最大輸出量,儘管如此,袋子中有多少個真實的正負範例。因此,實際上產生正或負輸出的負擔並不是不平衡的。
注意,方程(4)所示的誤差函數是在訓練範例的級別定義的,而方程(3)所示的誤差函數是在訓練包的級別定義的。它們在外觀上的主要區別在於,方程(3)用包含多範例學習特徵的某些術語代替了方程(4)的第二個求和項,即一個正袋包含至少一個正範例,而一個負袋不包含任何正面範例。還值得注意的是,從等式(3)得出的梯度方向與從等式(4)得出的梯度方向是完全不同的。換句話說,在訓練袋水平上定義的梯度與在訓練範例水平上定義的梯度是不同的。我們認爲,這可以解釋Dietterich等人的觀點,即BP在多範例問題上無法很好地發揮作用[9]。
誤差函數如等式(3)所示,可以輕鬆導出BP-MIP的訓練過程,因爲它與BP演算法幾乎相同,除了後者的權重是針對每個訓練範例進行更新的,而在前者中每個訓練袋的重量都會更新。詳細地,在BP-MIP的每個訓練時期中,訓練包都被逐一饋送到網路。對於袋子Bi,如果已正確預測,則網路中的重量不變。否則,將根據範例的誤差修改權重,該範例的相應實際輸出爲Bi中的最大值。此後,將Bi,j + 1饋入網路,並迭代訓練過程,直到全域性誤差E減小到閾值或訓練時期的數量增加到閾值爲止。
簡而言之,BP根據訓練範例修改網路,而BP-MIP根據訓練包修改網路。以此方式,BP-MIP捕獲了多範例學習的本質,在這種情況下,訓練包的標籤而不是訓練範例的標籤是已知的。
請注意,在訓練BP-MIP網路時,可以將袋的期望輸出(即1表示正,0表示負)替換爲0.9表示正,而0.1表示負,這是加快訓練過程的技巧[21 ]。當訓練有素的BP-MIP網路用於預測時,當且僅當至少在其至少一個範例上網路的輸出不少於0.5時,纔會對包進行正面標記。
5 Experiment
5.1 Real-world data sets
Musk數據是目前唯一用於多範例學習的真實世界基準測試數據。數據由Dietterich等人生成。按照第2節中所述的方式進行操作。有兩個數據集,這兩個數據集均可從UCI機器學習儲存庫[4]中公開獲得。表1總結了這兩個數據集的資訊。請注意,這裏有一些不相關的功能,所有範例都是唯一的[9]。

使用BP-MIP演算法訓練具有1個輸出單元,1個隱藏層和166個輸入單元的前饋神經網路,每個輸入單元對應於166維特徵向量的維。功能單元的啓用功能爲Sigmoid。學習率設定爲0.05。隱藏單元的數量從20到100,間隔爲20,而訓練時期的數量從50到1,000,間隔爲50。
對兩個數據集都進行了留一法測試。詳細地說,一個袋子用於測試,而其他袋子則用於訓練神經網路。以將數據集中的每個包裝袋都用作一次測試袋的方式重複進行此過程。換句話說,爲每種設定訓練的神經網路的數量,即隱藏單元和訓練時期的數量,等於數據集中的包數。每種設定的最終結果是針對該設定訓練的神經網路的平均結果。
Musk1和Musk2的預測準確性的曲線隨訓練次數的增加而變化,分別如圖3和圖4所示。
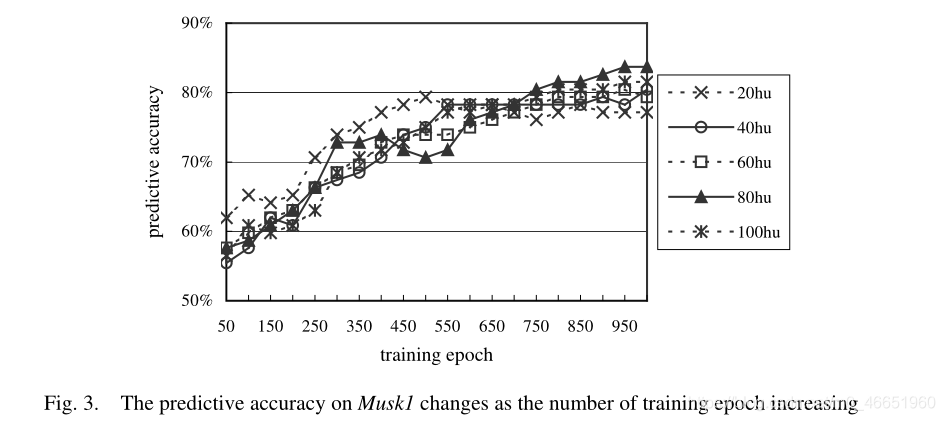
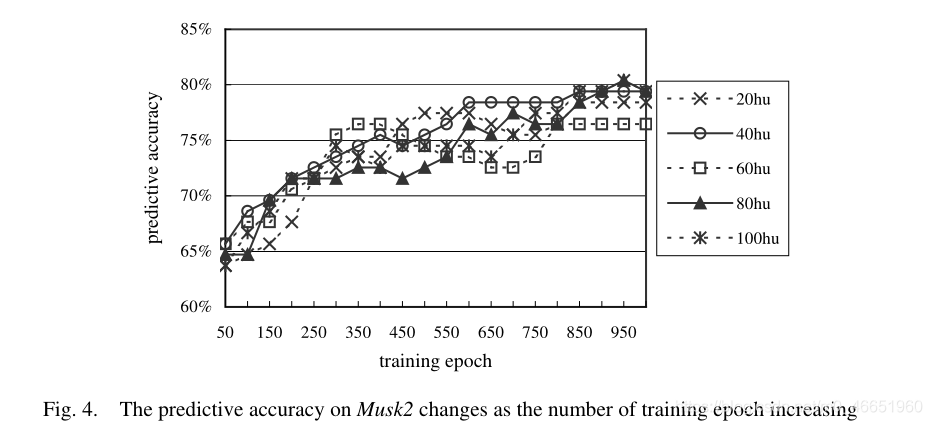
圖3和圖4顯示,隱藏單元的數量不會顯着影響BP-MIP網路的預測準確性,而訓練時期的數量會顯着影響預測準確性。實際上,存在明顯的趨勢,即隨着訓練時期的數量增加,網路的預測準確性也會增加。由於計算成本的限制,目前我們僅將網路訓練到1,000個紀元。但是我們認爲,如果對網路進行更多的訓練,則可以進一步提高預測準確性。
在圖3和圖4中,BP-MIP的最佳效能在Musk1上爲83.7%,在Musk2上爲80.4%,兩者都是通過具有80個隱藏單元和950個訓練時期的網路獲得的。表2將結果與文獻報道的結果進行了比較。請注意,表2中未顯示標準偏差,因爲大多數結果是通過留一法測試獲得的,並且此測試方法也沒有變化,儘管通常留一法與10倍法之間的差異爲不顯着[25]。
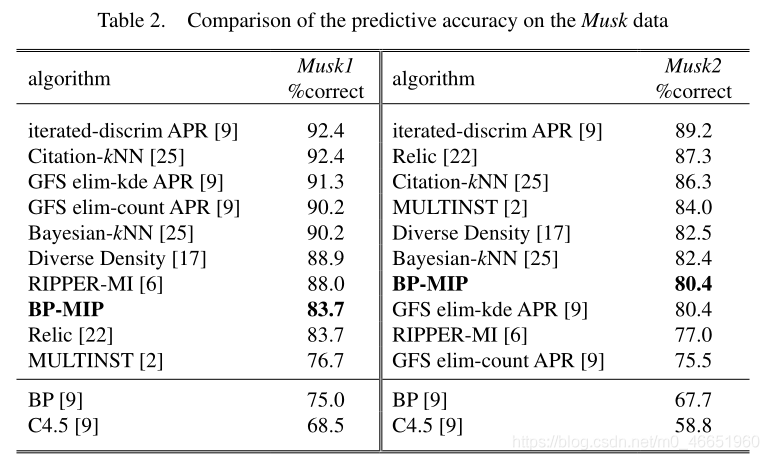
表2表明,BP-MIP明顯優於MULTINST [2],並且與Musk1上的Relic [22]相當;它明顯優於RIPPER-MI [6]和GFS elim-kde APR [9],與Musk2上的GFS elim-kde APR [9]相當。
請注意,儘管BP-MIP在預測準確性上僅比某些方法好,而不是所有行之有效的多範例學習方法,但它有其自身的優勢。例如,Dietterich等人的APR演算法[9]專爲Musk數據而設計,而BP-MIP是通用演算法,因此其適用性優於APR演算法。 Wang和Zucker的擴充套件kNN演算法[25]是一種惰性學習方法,在預測的迭代過程中需要花費大量時間,而BP-MIP在預測上的時間卻是微不足道的。 Maron和Lozano-Pérez的「多樣密度」演算法[17]採用了某些特徵選擇機制 機製,而BP-MIP尚未執行特徵選擇,我們相信,如果使用適當的特徵選擇機制 機製,其效能將會得到進一步改善。更重要的是,BP-MIP易於適應多範例迴歸問題。
表2還表明,所有多範例學習方法的效能均優於BP和C4.5,這在Musk2上尤其明顯,它比Musk1難學習。這一發現支援了Dietterich等人的觀點[9],即傳統的有監督學習方法無法解決多範例問題,因爲它們沒有結合多範例學習的特徵。
5.2 Artificial data sets
在多範例學習下進行的先前研究是用於分類的。然而,分子和受體之間的結合親和力是定量的,其表現爲諸如結合時分子-受體對釋放的能量之類的量,因此優選結合強度的實值標記。幸運的是,Amar等人。 [1]提出了一種建立人工多範例數據的方法。該方法首先產生人工受體。然後,生成每個袋子具有多個範例的人造分子,每個特徵值都被視爲當所有分子都處於相同方向時從原點到分子表面的距離。每個功能都有一個比例因子來表示其在系結過程中的重要性。人工分子與受體之間的結合能基於分子間相互作用的Lennard-Jones勢進行計算。
人工數據集被命名爲LJ-r.f.s,其中r是相關要素的數量,f是要素的數量,s是用於相關要素的不同比例因子的數量。爲了部分模仿Musk數據,某些數據集僅使用不接近1/2的標籤(由「 S」後綴表示),並且相關特徵的所有比例因子都是在[0.9,1]之間隨機選擇的。請注意,這些數據集主要用於多範例迴歸,但也可以通過將實值標籤四捨五入爲0或1來用於多範例分類。
本文使用了四個人工數據集,即LJ-160.166.1,LJ-160.166.1-S,LJ-80.166.1和LJ-80.166.1-S。每個數據集包含92個袋子。使用BP-MIP演算法訓練具有一個輸出單元,一個具有80個單元的隱藏層和166個輸入單元的前饋神經網路,每個輸入單元對應於166維特徵向量的維。功能單元的啓用功能爲Sigmoid。學習率設定爲0.05。訓練時期的數量從50到500不等,間隔爲50。
對這些數據集進行留一法測試。預測準確度的曲線隨訓練次數的增加而變化,如圖5所示。
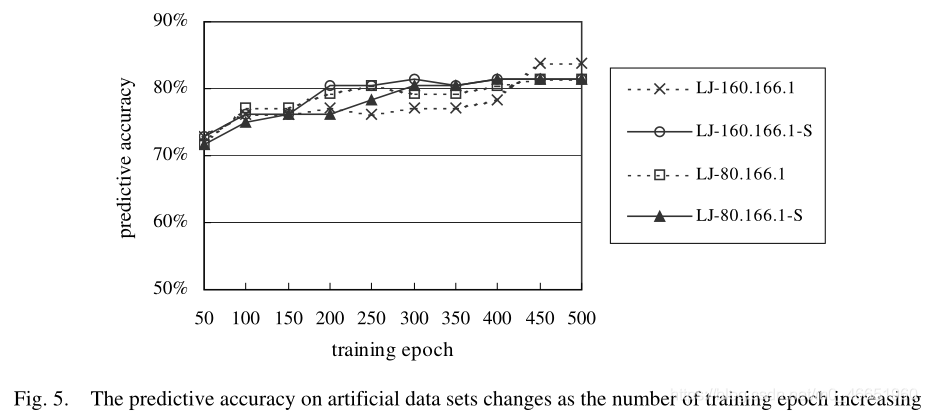
圖5顯示了一個明顯的趨勢,即隨着訓練時期的數量增加,網路的預測準確性也將增加。如表3所示,將圖5中BP-MIP的最佳效能與文獻[1]中報告的效能進行了比較,其中報告了預測誤差和平方損失。
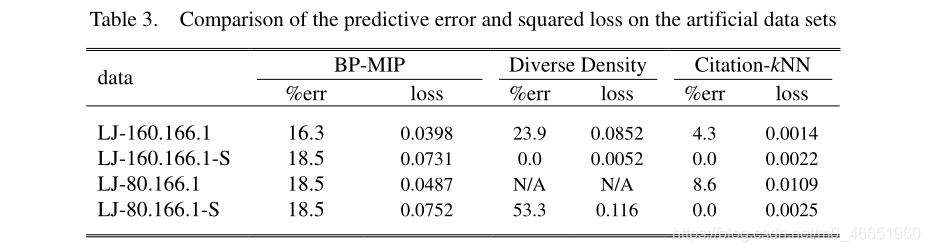
表3表明,儘管BP-MIP的效能比Citation-kNN差[25],但在LJ-P上,它明顯優於最著名的多範例學習演算法即「不同密度」 [17]。 160.166.1和LJ-80.166.1-S。這不僅顯示了BP-MIP在多範例迴歸中的有效性,而且表明在多範例學習方法中BP-MIP的排名可能比表2更好。
6. Conclusion and Future Work
本文提出了一種神經網路演算法BP-MIP,它是BP的多範例版本。通過採用新的錯誤功能,BP-MIP捕獲了多範例學習的本質,即訓練袋的標籤而不是訓練範例的標籤是已知的。在現實世界和人工基準多範例數據上的實驗表明,BP-MIP的效能可與某些公認的多範例學習方法相媲美。這解決了Dietterich等提出的開放問題。 [9],即爲神經網路設計多範例修改。
Maron [16]指出,從訓練集的歧義性的角度來看,多範例學習應該放在監督學習(其訓練集沒有歧義)和無監督學習(其訓練集具有最大歧義)之間。由於一些流行的監督學習演算法可以適用於多範例學習,例如一些研究人員在決策樹上的工作[6,22],規則學習演算法[6],懶惰學習演算法[25]以及我們在神經網路上的工作在本文中,我們認爲多範例學習應該比無監督學習更靠近監督學習。
BP-MIP的一個優點是它是一種通用演算法,尚未針對任何數據進行優化,這意味着它可以輕鬆應用於基於內容的影象檢索等應用程式。發現更多現實世界中的多範例問題並將BP-MIP應用於它們是未來工作中另一個有趣的問題。注意,將BP-MIP應用於實際問題時,通過實驗選擇適當的設定(即隱藏單元的數量和訓練時期)以實現最佳效能並不是很可行。因此,一項重要的工作是開發一些機制 機製來估計針對具體問題的BP-MIP的適當設定。
此外,由於許多演算法在多範例問題上都能很好地工作,例如迭代法APR [9]和Diverse Density [17],都內建了特徵選擇方案,因此探索BP-MIP的效能是否可以藉助功能選擇可顯着改善。
此外,最近的研究表明,神經網路整合可以顯着提高基於神經網路的學習系統的泛化能力,這已成爲機器學習和神經網路社羣中的熱門話題[27]。因此,有趣的是,是否可以通過BP-MIP網路的整合獲得更好的結果。