JAVA初中面試題集
因爲自己想要換一個工作,最近百度了不少面試知識點,在這裏分享兩個比較完善的筆記
爲了更好的樹立知識體系,我附加了相關的思維導圖,分爲pdf版和mindnote版.比如java相關的導圖如下:
相關概念
物件導向的三個特徵
封裝,繼承,多型.這個應該是人人皆知.有時候也會加上抽象.
多型的好處
允許不同類物件對同一訊息做出響應,即同一訊息可以根據發送物件的不同而採用多種不同的行爲方式(發送訊息就是函數呼叫).主要有以下優點:
可替換性:多型對已存在程式碼具有可替換性.
可擴充性:增加新的子類不影響已經存在的類結構.
介面性:多型是超類通過方法簽名,向子類提供一個公共介面,由子類來完善或者重寫它來實現的.
靈活性:
簡化性:
程式碼中如何實現多型
實現多型主要有以下三種方式:
- 介面實現
- 繼承父類別重寫方法
- 同一類中進行方法過載
虛擬機器是如何實現多型的
動態系結技術(dynamic binding),執行期間判斷所參照物件的實際型別,根據實際型別呼叫對應的方法.
介面的意義
介面的意義用三個詞就可以概括:規範,擴充套件,回撥.
抽象類的意義
抽象類的意義可以用三句話來概括:
爲其他子類提供一個公共的型別
封裝子類中重複定義的內容
定義抽象方法,子類雖然有不同的實現,但是定義時一致的
介面和抽象類的區別
比較抽象類介面預設方法抽象類可以有預設的方法實現,java 8之前,介面中不存在方法的實現.實現方式子類使用extends關鍵字來繼承抽象類.如果子類不是抽象類,子類需要提供抽象類中所宣告方法的實現.子類使用implements來實現介面,需要提供介面中所有宣告的實現.構造器抽象類中可以有構造器,介面中不能和正常類區別抽象類不能被範例化介面則是完全不同的型別存取修飾符抽象方法可以有public,protected和default等修飾介面預設是public,不能使用其他修飾符多繼承一個子類只能存在一個父類別一個子類可以存在多個介面新增新方法想抽象類中新增新方法,可以提供預設的實現,因此可以不修改子類現有的程式碼如果往介面中新增新方法,則子類中需要實現該方法.
父類別的靜態方法能否被子類重寫
不能.重寫只適用於實體方法,不能用於靜態方法,而子類當中含有和父類別相同簽名的靜態方法,我們一般稱之爲隱藏.
什麼是不可變物件
不可變物件指物件一旦被建立,狀態就不能再改變。任何修改都會建立一個新的物件,如 String、Integer及其它包裝類。
靜態變數和範例變數的區別?
靜態變數儲存在方法區,屬於類所有.範例變數儲存在堆當中,其參照存在當前執行緒棧.
能否建立一個包含可變物件的不可變物件?
當然可以建立一個包含可變物件的不可變物件的,你只需要謹慎一點,不要共用可變物件的參照就可以了,如果需要變化時,就返回原物件的一個拷貝。最常見的例子就是物件中包含一個日期物件的參照.
java 建立物件的幾種方式
採用new
通過反射
採用clone
通過序列化機制 機製
前2者都需要顯式地呼叫構造方法. 造成耦合性最高的恰好是第一種,因此你發現無論什麼框架,只要涉及到解耦必先減少new的使用.
switch中能否使用string做參數
在idk 1.7之前,switch只能支援byte,short,char,int或者其對應的封裝類以及Enum型別。從idk 1.7之後switch開始支援String.
switch能否作用在byte,long上?
可以用在byte上,但是不能用在long上.
String s1=」ab」,String s2=」a」+」b」,String s3=」a」,String s4=」b」,s5=s3+s4請問s5==s2返回什麼?
返回false.在編譯過程中,編譯器會將s2直接優化爲」ab」,會將其放置在常數池當中,s5則是被建立在堆區,相當於s5=new String(「ab」);
你對String物件的intern()熟悉麼?
intern()方法會首先從常數池中查詢是否存在該常數值,如果常數池中不存在則現在常數池中建立,如果已經存在則直接返回.
比如
String s1=」aa」;
String s2=s1.intern();
System.out.print(s1==s2);//返回true
Object中有哪些公共方法?
equals()
clone()
getClass()
notify(),notifyAll(),wait()
toString
java當中的四種參照
強參照,軟參照,弱參照,虛參照.不同的參照型別主要體現在GC上:
強參照:如果一個物件具有強參照,它就不會被垃圾回收器回收。即使當前記憶體空間不足,JVM也不會回收它,而是拋出 OutOfMemoryError 錯誤,使程式異常終止。如果想中斷強參照和某個物件之間的關聯,可以顯式地將參照賦值爲null,這樣一來的話,JVM在合適的時間就會回收該物件
軟參照:在使用軟參照時,如果記憶體的空間足夠,軟參照就能繼續被使用,而不會被垃圾回收器回收,只有在記憶體不足時,軟參照纔會被垃圾回收器回收。
弱參照:具有弱參照的物件擁有的生命週期更短暫。因爲當 JVM 進行垃圾回收,一旦發現弱參照物件,無論當前記憶體空間是否充足,都會將弱參照回收。不過由於垃圾回收器是一個優先順序較低的執行緒,所以並不一定能迅速發現弱參照物件
虛參照:顧名思義,就是形同虛設,如果一個物件僅持有虛參照,那麼它相當於沒有參照,在任何時候都可能被垃圾回收器回收。
更多瞭解參見深入物件參照
WeakReference與SoftReference的區別?
這點在四種參照型別中已經做瞭解釋,這裏簡單說明一下即可:
雖然 WeakReference 與 SoftReference 都有利於提高 GC 和 記憶體的效率,但是 WeakReference ,一旦失去最後一個強參照,就會被 GC 回收,而軟參照雖然不能阻止被回收,但是可以延遲到 JVM 記憶體不足的時候。
爲什麼要有不同的參照型別
不像C語言,我們可以控制記憶體的申請和釋放,在Java中有時候我們需要適當的控制物件被回收的時機,因此就誕生了不同的參照型別,可以說不同的參照型別實則是對GC回收時機不可控的妥協.有以下幾個使用場景可以充分的說明:
利用軟參照和弱參照解決OOM問題:用一個HashMap來儲存圖片的路徑和相應圖片物件關聯的軟參照之間的對映關係,在記憶體不足時,JVM會自動回收這些快取圖片物件所佔用的空間,從而有效地避免了OOM的問題.
通過軟參照實現Java物件的快取記憶體:比如我們建立了一Person的類,如果每次需要查詢一個人的資訊,哪怕是幾秒中之前剛剛查詢過的,都要重新構建一個範例,這將引起大量Person物件的消耗,並且由於這些物件的生命週期相對較短,會引起多次GC影響效能。此時,通過軟參照和 HashMap 的結合可以構建快取記憶體,提供效能.
java中==和eqauls()的區別,equals()和`hashcode的區別
是運算子,用於比較兩個變數是否相等,而equals是Object類的方法,用於比較兩個物件是否相等.預設Object類的equals方法是比較兩個物件的地址,此時和的結果一樣.換句話說:基本型別比較用==,比較的是他們的值.預設下,物件用==比較時,比較的是記憶體地址,如果需要比較物件內容,需要重寫equal方法
equals()和hashcode()的聯繫
hashCode()是Object類的一個方法,返回一個雜湊值.如果兩個物件根據equal()方法比較相等,那麼呼叫這兩個物件中任意一個物件的hashCode()方法必須產生相同的雜湊值.
如果兩個物件根據eqaul()方法比較不相等,那麼產生的雜湊值不一定相等(碰撞的情況下還是會相等的.)
a.hashCode()有什麼用?與a.equals(b)有什麼關係
hashCode() 方法是相應物件整型的 hash 值。它常用於基於 hash 的集合類,如 Hashtable、HashMap、LinkedHashMap等等。它與 equals() 方法關係特別緊密。根據 Java 規範,使用 equal() 方法來判斷兩個相等的物件,必須具有相同的 hashcode。
將物件放入到集閤中時,首先判斷要放入物件的hashcode是否已經在集閤中存在,不存在則直接放入集合.如果hashcode相等,然後通過equal()方法判斷要放入物件與集閤中的任意物件是否相等:如果equal()判斷不相等,直接將該元素放入集閤中,否則不放入.
有沒有可能兩個不相等的物件有相同的hashcode
有可能,兩個不相等的物件可能會有相同的 hashcode 值,這就是爲什麼在 hashmap 中會有衝突。如果兩個物件相等,必須有相同的hashcode 值,反之不成立.
可以在hashcode中使用亂數字嗎?
不行,因爲同一物件的 hashcode 值必須是相同的
a==b與a.equals(b)有什麼區別
如果a 和b 都是物件,則 a==b 是比較兩個物件的參照,只有當 a 和 b 指向的是堆中的同一個物件纔會返回 true,而 a.equals(b) 是進行邏輯比較,所以通常需要重寫該方法來提供邏輯一致性的比較。例如,String 類重寫 equals() 方法,所以可以用於兩個不同對象,但是包含的字母相同的比較。
3*0.1==0.3返回值是什麼
false,因爲有些浮點數不能完全精確的表示出來。
a=a+b與a+=b有什麼區別嗎?
+=操作符會進行隱式自動型別轉換,此處a+=b隱式的將加操作的結果型別強制轉換爲持有結果的型別,而a=a+b則不會自動進行型別轉換.如:
byte a = 127;
byte b = 127;
b = a + b; // error : cannot convert from int to byte
b += a; // ok
(譯者注:這個地方應該表述的有誤,其實無論 a+b 的值爲多少,編譯器都會報錯,因爲 a+b 操作會將 a、b 提升爲 int 型別,所以將 int 型別賦值給 byte 就會編譯出錯)
short s1= 1; s1 = s1 + 1; 該段程式碼是否有錯,有的話怎麼改?
有錯誤,short型別在進行運算時會自動提升爲int型別,也就是說s1+1的運算結果是int型別.
short s1= 1; s1 += 1; 該段程式碼是否有錯,有的話怎麼改?
+=操作符會自動對右邊的表達式結果強轉匹配左邊的數據型別,所以沒錯.
& 和 &&的區別
首先記住&是位元運算,而&&是邏輯運算子.另外需要記住邏輯運算子具有短路特性,而&不具備短路特性.
public class Test{
static String name;
public static void main(String[] args){
if(name!=null&userName.equals("")){
System.out.println("ok");
}else{
System.out.println("erro");
}
}
}
以上程式碼將會拋出空指針異常.
一個.java檔案內部可以有類?(非內部類)
只能有一個public公共類,但是可以有多個default修飾的類.
如何正確的退出多層巢狀回圈.
使用標號和break;
通過在外層回圈中新增識別符號
內部類的作用
內部類可以有多個範例,每個範例都有自己的狀態資訊,並且與其他外圍物件的資訊相互獨立.在單個外圍類當中,可以讓多個內部類以不同的方式實現同一介面,或者繼承同一個類.建立內部類物件的時刻不依賴於外部類物件的建立.內部類並沒有令人疑惑的」is-a」關係,它就像是一個獨立的實體.
內部類提供了更好的封裝,除了該外圍類,其他類都不能存取
final,finalize和finally的不同之處
final 是一個修飾符,可以修飾變數、方法和類。如果 final 修飾變數,意味着該變數的值在初始化後不能被改變。finalize 方法是在物件被回收之前呼叫的方法,給物件自己最後一個復活的機會,但是什麼時候呼叫 finalize 沒有保證。finally 是一個關鍵字,與 try 和 catch 一起用於異常的處理。finally 塊一定會被執行,無論在 try 塊中是否有發生異常。
clone()是哪個類的方法?
java.lang.Cloneable 是一個標示性介面,不包含任何方法,clone 方法在 object 類中定義。並且需要知道 clone() 方法是一個本地方法,這意味着它是由 c 或 c++ 或 其他本地語言實現的。
深拷貝和淺拷貝的區別是什麼?
淺拷貝:被複制物件的所有變數都含有與原來的物件相同的值,而所有的對其他物件的參照仍然指向原來的物件。換言之,淺拷貝僅僅複製所考慮的物件,而不復制它所參照的物件。
深拷貝:被複制物件的所有變數都含有與原來的物件相同的值,而那些參照其他物件的變數將指向被複制過的新物件,而不再是原有的那些被參照的物件。換言之,深拷貝把要複製的物件所參照的物件都複製了一遍。
static都有哪些用法?
幾乎所有的人都知道static關鍵字這兩個基本的用法:靜態變數和靜態方法.也就是被static所修飾的變數/方法都屬於類的靜態資源,類範例所共用.
除了靜態變數和靜態方法之外,static也用於靜態塊,多用於初始化操作:
public calss PreCache{
static{
//執行相關操作
}
}
此外static也多用於修飾內部類,此時稱之爲靜態內部類.
最後一種用法就是靜態導包,即import static.import static是在JDK 1.5之後引入的新特性,可以用來指定匯入某個類中的靜態資源,並且不需要使用類名.資源名,可以直接使用資源名,比如:
import static java.lang.Math.*;
public class Test{
public static void main(String[] args){
//System.out.println(Math.sin(20));傳統做法
System.out.println(sin(20));
}
}
final有哪些用法
final也是很多面試喜歡問的地方,能回答下以下三點就不錯了:
1.被final修飾的類不可以被繼承
2.被final修飾的方法不可以被重寫
3.被final修飾的變數不可以被改變.如果修飾參照,那麼表示參照不可變,參照指向的內容可變.
4.被final修飾的方法,JVM會嘗試將其內聯,以提高執行效率
5.被final修飾的常數,在編譯階段會存入常數池中.
回答出編譯器對final域要遵守的兩個重排序規則更好:
1.在建構函式內對一個final域的寫入,與隨後把這個被構造物件的參照賦值給一個參照變數,這兩個操作之間不能重排序.
2.初次讀一個包含final域的物件的參照,與隨後初次讀這個final域,這兩個操作之間不能重排序.
數據型別相關
java中int char,long各佔多少位元組?
型別位數位節數short216int432long864float432double864char216
64位元的JVM當中,int的長度是多少?
Java 中,int 型別變數的長度是一個固定值,與平臺無關,都是 32 位。意思就是說,在 32 位 和 64 位 的Java 虛擬機器中,int 型別的長度是相同的。
int和Integer的區別
Integer是int的包裝型別,在拆箱和裝箱中,二者自動轉換.int是基本型別,直接存數值,而integer是物件,用一個參照指向這個物件.
int 和Integer誰佔用的記憶體更多?
Integer 物件會佔用更多的記憶體。Integer是一個物件,需要儲存物件的元數據。但是 int 是一個原始型別的數據,所以佔用的空間更少。
String,StringBuffer和StringBuilder區別
String是字串常數,final修飾;StringBuffer字串變數(執行緒安全);
StringBuilder 字串變數(執行緒不安全).
String和StringBuffer
String和StringBuffer主要區別是效能:String是不可變物件,每次對String型別進行操作都等同於產生了一個新的String物件,然後指向新的String物件.所以儘量不在對String進行大量的拼接操作,否則會產生很多臨時物件,導致GC開始工作,影響系統效能.
StringBuffer是對物件本身操作,而不是產生新的物件,因此在有大量拼接的情況下,我們建議使用StringBuffer.
但是需要注意現在JVM會對String拼接做一定的優化:
String s=「This is only 」+」simple」+」test」會被虛擬機器直接優化成String s=「This is only simple test」,此時就不存在拼接過程.
StringBuffer和StringBuilder
StringBuffer是執行緒安全的可變字串,其內部實現是可變陣列.StringBuilder是jdk 1.5新增的,其功能和StringBuffer類似,但是非執行緒安全.因此,在沒有多執行緒問題的前提下,使用StringBuilder會取得更好的效能.
什麼是編譯器常數?使用它有什麼風險?
公共靜態不可變(public static final )變數也就是我們所說的編譯期常數,這裏的 public 可選的。實際上這些變數在編譯時會被替換掉,因爲編譯器知道這些變數的值,並且知道這些變數在執行時不能改變。這種方式存在的一個問題是你使用了一個內部的或第三方庫中的公有編譯時常數,但是這個值後面被其他人改變了,但是你的用戶端仍然在使用老的值,甚至你已經部署了一個新的jar。爲了避免這種情況,當你在更新依賴 JAR 檔案時,確保重新編譯你的程式。
java當中使用什麼型別表示價格比較好?
如果不是特別關心記憶體和效能的話,使用BigDecimal,否則使用預定義精度的 double 型別。
如何將byte轉爲String
可以使用 String 接收 byte[] 參數的構造器來進行轉換,需要注意的點是要使用的正確的編碼,否則會使用平臺預設編碼,這個編碼可能跟原來的編碼相同,也可能不同。
可以將int強轉爲byte型別麼?會產生什麼問題?
我們可以做強制轉換,但是Java中int是32位元的而byte是8 位的,所以,如果強制轉化int型別的高24位元將會被丟棄,byte 型別的範圍是從-128到128
關於垃圾回收
你知道哪些垃圾回收演算法?
垃圾回收從理論上非常容易理解,具體的方法有以下幾種:
- 標記-清除
- 標記-複製
- 標記-整理
- 分代回收
更詳細的內容參見深入理解垃圾回收演算法
如何判斷一個物件是否應該被回收
這就是所謂的物件存活性判斷,常用的方法有兩種:1.參照計數法;2:物件可達性分析.由於參照計數法存在互相參照導致無法進行GC的問題,所以目前JVM虛擬機器多使用物件可達性分析演算法.
簡單的解釋一下垃圾回收
Java 垃圾回收機制 機製最基本的做法是分代回收。記憶體中的區域被劃分成不同的世代,物件根據其存活的時間被儲存在對應世代的區域中。一般的實現是劃分成3個世代:年輕、年老和永久。記憶體的分配是發生在年輕世代中的。當一個物件存活時間足夠長的時候,它就會被複制到年老世代中。對於不同的世代可以使用不同的垃圾回收演算法。進行世代劃分的出發點是對應用中物件存活時間進行研究之後得出的統計規律。一般來說,一個應用中的大部分物件的存活時間都很短。比如區域性變數的存活時間就只在方法的執行過程中。基於這一點,對於年輕世代的垃圾回收演算法就可以很有針對性.
呼叫System.gc()會發生什麼?
通知GC開始工作,但是GC真正開始的時間不確定.
進程,執行緒相關
說說進程,執行緒,協程之間的區別
簡而言之,進程是程式執行和資源分配的基本單位,一個程式至少有一個進程,一個進程至少有一個執行緒.進程在執行過程中擁有獨立的記憶體單元,而多個執行緒共用記憶體資源,減少切換次數,從而效率更高.執行緒是進程的一個實體,是cpu排程和分派的基本單位,是比程式更小的能獨立執行的基本單位.同一進程中的多個執行緒之間可以併發執行.
你瞭解守護執行緒嗎?它和非守護執行緒有什麼區別
程式執行完畢,jvm會等待非守護執行緒完成後關閉,但是jvm不會等待守護執行緒.守護執行緒最典型的例子就是GC執行緒
什麼是多執行緒上下文切換
多執行緒的上下文切換是指CPU控制權由一個已經正在執行的執行緒切換到另外一個就緒並等待獲取CPU執行權的執行緒的過程。
建立兩種執行緒的方式?他們有什麼區別?
通過實現java.lang.Runnable或者通過擴充套件java.lang.Thread類.相比擴充套件Thread,實現Runnable介面可能更優.原因有二:
Java不支援多繼承.因此擴充套件Thread類就代表這個子類不能擴充套件其他類.而實現Runnable介面的類還可能擴充套件另一個類.
類可能只要求可執行即可,因此繼承整個Thread類的開銷過大.
Thread類中的start()和run()方法有什麼區別?
start()方法被用來啓動新建立的執行緒,而且start()內部呼叫了run()方法,這和直接呼叫run()方法的效果不一樣。當你呼叫run()方法的時候,只會是在原來的執行緒中呼叫,沒有新的執行緒啓動,start()方法纔會啓動新執行緒。
怎麼檢測一個執行緒是否持有物件監視器
Thread類提供了一個holdsLock(Object obj)方法,當且僅當物件obj的監視器被某條執行緒持有的時候纔會返回true,注意這是一個static方法,這意味着」某條執行緒」指的是當前執行緒。
Runnable和Callable的區別
Runnable介面中的run()方法的返回值是void,它做的事情只是純粹地去執行run()方法中的程式碼而已;Callable介面中的call()方法是有返回值的,是一個泛型,和Future、FutureTask配合可以用來獲取非同步執行的結果。
這其實是很有用的一個特性,因爲多執行緒相比單執行緒更難、更復雜的一個重要原因就是因爲多執行緒充滿着未知性,某條執行緒是否執行了?某條執行緒執行了多久?某條執行緒執行的時候我們期望的數據是否已經賦值完畢?無法得知,我們能做的只是等待這條多執行緒的任務執行完畢而已。而Callable+Future/FutureTask卻可以方便獲取多執行緒執行的結果,可以在等待時間太長沒獲取到需要的數據的情況下取消該執行緒的任務
什麼導致執行緒阻塞
阻塞指的是暫停一個執行緒的執行以等待某個條件發生(如某資源就緒),學過操作系統的同學對它一定已經很熟悉了。Java 提供了大量方法來支援阻塞,下面 下麪讓我們逐一分析。
方法說明sleep()sleep() 允許 指定以毫秒爲單位的一段時間作爲參數,它使得執行緒在指定的時間內進入阻塞狀態,不能得到CPU 時間,指定的時間一過,執行緒重新進入可執行狀態。 典型地,sleep() 被用在等待某個資源就緒的情形:測試發現條件不滿足後,讓執行緒阻塞一段時間後重新測試,直到條件滿足爲止suspend() 和 resume()兩個方法配套使用,suspend()使得執行緒進入阻塞狀態,並且不會自動恢復,必須其對應的resume() 被呼叫,才能 纔能使得執行緒重新進入可執行狀態。典型地,suspend() 和 resume() 被用在等待另一個執行緒產生的結果的情形:測試發現結果還沒有產生後,讓執行緒阻塞,另一個執行緒產生了結果後,呼叫 resume() 使其恢復。yield()yield() 使當前執行緒放棄當前已經分得的CPU 時間,但不使當前執行緒阻塞,即執行緒仍處於可執行狀態,隨時可能再次分得 CPU 時間。呼叫 yield() 的效果等價於排程程式認爲該執行緒已執行了足夠的時間從而轉到另一個執行緒wait() 和 notify()兩個方法配套使用,wait() 使得執行緒進入阻塞狀態,它有兩種形式,一種允許 指定以毫秒爲單位的一段時間作爲參數,另一種沒有參數,前者當對應的 notify() 被呼叫或者超出指定時間時執行緒重新進入可執行狀態,後者則必須對應的 notify() 被呼叫.
wait(),notify()和suspend(),resume()之間的區別
初看起來它們與 suspend() 和 resume() 方法對沒有什麼分別,但是事實上它們是截然不同的。區別的核心在於,前面敘述的所有方法,阻塞時都不會釋放佔用的鎖(如果佔用了的話),而這一對方法則相反。上述的核心區別導致了一系列的細節上的區別。
首先,前面敘述的所有方法都隸屬於 Thread 類,但是這一對卻直接隸屬於 Object 類,也就是說,所有物件都擁有這一對方法。初看起來這十分不可思議,但是實際上卻是很自然的,因爲這一對方法阻塞時要釋放佔用的鎖,而鎖是任何物件都具有的,呼叫任意物件的 wait() 方法導致執行緒阻塞,並且該物件上的鎖被釋放。而呼叫 任意物件的notify()方法則導致從呼叫該物件的 wait() 方法而阻塞的執行緒中隨機選擇的一個解除阻塞(但要等到獲得鎖後才真正可執行)。
其次,前面敘述的所有方法都可在任何位置呼叫,但是這一對方法卻必須在 synchronized 方法或塊中呼叫,理由也很簡單,只有在synchronized 方法或塊中當前執行緒才佔有鎖,纔有鎖可以釋放。同樣的道理,呼叫這一對方法的物件上的鎖必須爲當前執行緒所擁有,這樣纔有鎖可以釋放。因此,這一對方法呼叫必須放置在這樣的 synchronized 方法或塊中,該方法或塊的上鎖物件就是呼叫這一對方法的物件。若不滿足這一條件,則程式雖然仍能編譯,但在執行時會出現IllegalMonitorStateException 異常。
wait() 和 notify() 方法的上述特性決定了它們經常和synchronized關鍵字一起使用,將它們和操作系統進程間通訊機制 機製作一個比較就會發現它們的相似性:synchronized方法或塊提供了類似於操作系統原語的功能,它們的執行不會受到多執行緒機制 機製的幹擾,而這一對方法則相當於 block 和wakeup 原語(這一對方法均宣告爲 synchronized)。它們的結合使得我們可以實現操作系統上一系列精妙的進程間通訊的演算法(如號志演算法),並用於解決各種複雜的執行緒間通訊問題。
關於 wait() 和 notify() 方法最後再說明兩點:
第一:呼叫 notify() 方法導致解除阻塞的執行緒是從因呼叫該物件的 wait() 方法而阻塞的執行緒中隨機選取的,我們無法預料哪一個執行緒將會被選擇,所以程式設計時要特別小心,避免因這種不確定性而產生問題。
第二:除了 notify(),還有一個方法 notifyAll() 也可起到類似作用,唯一的區別在於,呼叫 notifyAll() 方法將把因呼叫該物件的 wait() 方法而阻塞的所有執行緒一次性全部解除阻塞。當然,只有獲得鎖的那一個執行緒才能 纔能進入可執行狀態。
談到阻塞,就不能不談一談死鎖,略一分析就能發現,suspend() 方法和不指定超時期限的 wait() 方法的呼叫都可能產生死鎖。遺憾的是,Java 並不在語言級別上支援死鎖的避免,我們在程式設計中必須小心地避免死鎖。
以上我們對 Java 中實現執行緒阻塞的各種方法作了一番分析,我們重點分析了 wait() 和 notify() 方法,因爲它們的功能最強大,使用也最靈活,但是這也導致了它們的效率較低,較容易出錯。實際使用中我們應該靈活使用各種方法,以便更好地達到我們的目的。
產生死鎖的條件
1.互斥條件:一個資源每次只能被一個進程使用。
2.請求與保持條件:一個進程因請求資源而阻塞時,對已獲得的資源保持不放。
3.不剝奪條件:進程已獲得的資源,在末使用完之前,不能強行剝奪。
4.回圈等待條件:若幹進程之間形成一種頭尾相接的回圈等待資源關係。
爲什麼wait()方法和notify()/notifyAll()方法要在同步塊中被呼叫
這是JDK強制的,wait()方法和notify()/notifyAll()方法在呼叫前都必須先獲得物件的鎖
wait()方法和notify()/notifyAll()方法在放棄物件監視器時有什麼區別
wait()方法和notify()/notifyAll()方法在放棄物件監視器的時候的區別在於:wait()方法立即釋放物件監視器,notify()/notifyAll()方法則會等待執行緒剩餘程式碼執行完畢纔會放棄物件監視器。
wait()與sleep()的區別
關於這兩者已經在上面進行詳細的說明,這裏就做個概括好了:
sleep()來自Thread類,和wait()來自Object類.呼叫sleep()方法的過程中,執行緒不會釋放物件鎖。而 呼叫 wait 方法執行緒會釋放物件鎖
sleep()睡眠後不出讓系統資源,wait讓其他執行緒可以佔用CPU
sleep(milliseconds)需要指定一個睡眠時間,時間一到會自動喚醒.而wait()需要配合notify()或者notifyAll()使用
爲什麼wait,nofity和nofityAll這些方法不放在Thread類當中
一個很明顯的原因是JAVA提供的鎖是物件級的而不是執行緒級的,每個物件都有鎖,通過執行緒獲得。如果執行緒需要等待某些鎖那麼呼叫物件中的wait()方法就有意義了。如果wait()方法定義在Thread類中,執行緒正在等待的是哪個鎖就不明顯了。簡單的說,由於wait,notify和notifyAll都是鎖級別的操作,所以把他們定義在Object類中因爲鎖屬於物件。
怎麼喚醒一個阻塞的執行緒
如果執行緒是因爲呼叫了wait()、sleep()或者join()方法而導致的阻塞,可以中斷執行緒,並且通過拋出InterruptedException來喚醒它;如果執行緒遇到了IO阻塞,無能爲力,因爲IO是操作系統實現的,Java程式碼並沒有辦法直接接觸到操作系統。
什麼是多執行緒的上下文切換
多執行緒的上下文切換是指CPU控制權由一個已經正在執行的執行緒切換到另外一個就緒並等待獲取CPU執行權的執行緒的過程。
synchronized和ReentrantLock的區別
synchronized是和if、else、for、while一樣的關鍵字,ReentrantLock是類,這是二者的本質區別。既然ReentrantLock是類,那麼它就提供了比synchronized更多更靈活的特性,可以被繼承、可以有方法、可以有各種各樣的類變數,ReentrantLock比synchronized的擴充套件性體現在幾點上:
(1)ReentrantLock可以對獲取鎖的等待時間進行設定,這樣就避免了死鎖
(2)ReentrantLock可以獲取各種鎖的資訊
(3)ReentrantLock可以靈活地實現多路通知
另外,二者的鎖機制 機製其實也是不一樣的:ReentrantLock底層呼叫的是Unsafe的park方法加鎖,synchronized操作的應該是物件頭中mark word.
FutureTask是什麼
這個其實前面有提到過,FutureTask表示一個非同步運算的任務。FutureTask裏面可以傳入一個Callable的具體實現類,可以對這個非同步運算的任務的結果進行等待獲取、判斷是否已經完成、取消任務等操作。當然,由於FutureTask也是Runnable介面的實現類,所以FutureTask也可以放入執行緒池中。
一個執行緒如果出現了執行時異常怎麼辦?
如果這個異常沒有被捕獲的話,這個執行緒就停止執行了。另外重要的一點是:如果這個執行緒持有某個某個物件的監視器,那麼這個物件監視器會被立即釋放
Java當中有哪幾種鎖
自旋鎖: 自旋鎖在JDK1.6之後就預設開啓了。基於之前的觀察,共用數據的鎖定狀態只會持續很短的時間,爲了這一小段時間而去掛起和恢復執行緒有點浪費,所以這裏就做了一個處理,讓後面請求鎖的那個執行緒在稍等一會,但是不放棄處理器的執行時間,看看持有鎖的執行緒能否快速釋放。爲了讓執行緒等待,所以需要讓執行緒執行一個忙回圈也就是自旋操作。在jdk6之後,引入了自適應的自旋鎖,也就是等待的時間不再固定了,而是由上一次在同一個鎖上的自旋時間及鎖的擁有者狀態來決定
偏向鎖: 在JDK1.之後引入的一項鎖優化,目的是消除數據在無競爭情況下的同步原語。進一步提升程式的執行效能。 偏向鎖就是偏心的偏,意思是這個鎖會偏向第一個獲得他的執行緒,如果接下來的執行過程中,改鎖沒有被其他執行緒獲取,則持有偏向鎖的執行緒將永遠不需要再進行同步。偏向鎖可以提高帶有同步但無競爭的程式效能,也就是說他並不一定總是對程式執行有利,如果程式中大多數的鎖都是被多個不同的執行緒存取,那偏向模式就是多餘的,在具體問題具體分析的前提下,可以考慮是否使用偏向鎖。
輕量級鎖: 爲了減少獲得鎖和釋放鎖所帶來的效能消耗,引入了「偏向鎖」和「輕量級鎖」,所以在Java SE1.6裡鎖一共有四種狀態,無鎖狀態,偏向鎖狀態,輕量級鎖狀態和重量級鎖狀態,它會隨着競爭情況逐漸升級。鎖可以升級但不能降級,意味着偏向鎖升級成輕量級鎖後不能降級成偏向鎖
如何在兩個執行緒間共用數據
通過線上程之間共用物件就可以了,然後通過wait/notify/notifyAll、await/signal/signalAll進行喚起和等待,比方說阻塞佇列BlockingQueue就是爲執行緒之間共用數據而設計的
如何正確的使用wait()?使用if還是while?
wait() 方法應該在回圈呼叫,因爲當執行緒獲取到 CPU 開始執行的時候,其他條件可能還沒有滿足,所以在處理前,回圈檢測條件是否滿足會更好。下面 下麪是一段標準的使用 wait 和 notify 方法的程式碼:
synchronized (obj) {
while (condition does not hold)
obj.wait(); // (Releases lock, and reacquires on wakeup)
… // Perform action appropriate to condition
}
什麼是執行緒區域性變數ThreadLocal
執行緒區域性變數是侷限於執行緒內部的變數,屬於執行緒自身所有,不在多個執行緒間共用。Java提供ThreadLocal類來支援執行緒區域性變數,是一種實現執行緒安全的方式。但是在管理環境下(如 web 伺服器)使用執行緒區域性變數的時候要特別小心,在這種情況下,工作執行緒的生命週期比任何應用變數的生命週期都要長。任何執行緒區域性變數一旦在工作完成後沒有釋放,Java 應用就存在記憶體泄露的風險。
ThreadLoal的作用是什麼?
簡單說ThreadLocal就是一種以空間換時間的做法在每個Thread裏面維護了一個ThreadLocal.ThreadLocalMap把數據進行隔離,數據不共用,自然就沒有執行緒安全方面的問題了.
生產者消費者模型的作用是什麼?
(1)通過平衡生產者的生產能力和消費者的消費能力來提升整個系統的執行效率,這是生產者消費者模型最重要的作用
(2)解耦,這是生產者消費者模型附帶的作用,解耦意味着生產者和消費者之間的聯繫少,聯繫越少越可以獨自發展而不需要收到相互的制約
寫一個生產者-消費者佇列
可以通過阻塞佇列實現,也可以通過wait-notify來實現.
使用阻塞佇列來實現
//消費者
public class Producer implements Runnable{
private final BlockingQueue queue;
public Producer(BlockingQueue q){
this.queue=q;
}
@Override
public void run() {
try {
while (true){
Thread.sleep(1000);//模擬耗時
queue.put(produce());
}
}catch (InterruptedException e){
}
}
private int produce() {
int n=new Random().nextInt(10000);
System.out.println("Thread:" + Thread.currentThread().getId() + " produce:" + n);
return n;
}
}
//消費者
public class Consumer implements Runnable {
private final BlockingQueue queue;
public Consumer(BlockingQueue q){
this.queue=q;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(2000);//模擬耗時
consume(queue.take());
}catch (InterruptedException e){
}
}
}
private void consume(Integer n) {
System.out.println("Thread:" + Thread.currentThread().getId() + " consume:" + n);
}
}
//測試
public class Main {
public static void main(String[] args) {
BlockingQueue<Integer> queue=new ArrayBlockingQueue<Integer>(100);
Producer p=new Producer(queue);
Consumer c1=new Consumer(queue);
Consumer c2=new Consumer(queue);
new Thread§.start();
new Thread(c1).start();
new Thread(c2).start();
}
}
使用wait-notify來實現
該種方式應該最經典,這裏就不做說明了
如果你提交任務時,執行緒池佇列已滿,這時會發生什麼
如果你使用的LinkedBlockingQueue,也就是無界佇列的話,沒關係,繼續新增任務到阻塞佇列中等待執行,因爲LinkedBlockingQueue可以近乎認爲是一個無窮大的佇列,可以無限存放任務;如果你使用的是有界佇列比方說ArrayBlockingQueue的話,任務首先會被新增到ArrayBlockingQueue中,ArrayBlockingQueue滿了,則會使用拒絕策略RejectedExecutionHandler處理滿了的任務,預設是AbortPolicy。
爲什麼要使用執行緒池
避免頻繁地建立和銷燬執行緒,達到執行緒物件的重用。另外,使用執行緒池還可以根據專案靈活地控制併發的數目。
java中用到的執行緒排程演算法是什麼
搶佔式。一個執行緒用完CPU之後,操作系統會根據執行緒優先順序、執行緒飢餓情況等數據算出一個總的優先順序並分配下一個時間片給某個執行緒執行。
Thread.sleep(0)的作用是什麼
由於Java採用搶佔式的執行緒排程演算法,因此可能會出現某條執行緒常常獲取到CPU控制權的情況,爲了讓某些優先順序比較低的執行緒也能獲取到CPU控制權,可以使用Thread.sleep(0)手動觸發一次操作系統分配時間片的操作,這也是平衡CPU控制權的一種操作。
什麼是CAS
CAS,全稱爲Compare and Swap,即比較-替換。假設有三個運算元:記憶體值V、舊的預期值A、要修改的值B,當且僅當預期值A和記憶體值V相同時,纔會將記憶體值修改爲B並返回true,否則什麼都不做並返回false。當然CAS一定要volatile變數配合,這樣才能 纔能保證每次拿到的變數是主記憶體中最新的那個值,否則舊的預期值A對某條執行緒來說,永遠是一個不會變的值A,只要某次CAS操作失敗,永遠都不可能成功
什麼是樂觀鎖和悲觀鎖
樂觀鎖:樂觀鎖認爲競爭不總是會發生,因此它不需要持有鎖,將比較-替換這兩個動作作爲一個原子操作嘗試去修改記憶體中的變數,如果失敗則表示發生衝突,那麼就應該有相應的重試邏輯。
悲觀鎖:悲觀鎖認爲競爭總是會發生,因此每次對某資源進行操作時,都會持有一個獨佔的鎖,就像synchronized,不管三七二十一,直接上了鎖就操作資源了。
ConcurrentHashMap的併發度是什麼?
ConcurrentHashMap的併發度就是segment的大小,預設爲16,這意味着最多同時可以有16條執行緒操作ConcurrentHashMap,這也是ConcurrentHashMap對Hashtable的最大優勢,任何情況下,Hashtable能同時有兩條執行緒獲取Hashtable中的數據嗎?
ConcurrentHashMap的工作原理
ConcurrentHashMap在jdk 1.6和jdk 1.8實現原理是不同的.
jdk 1.6:
ConcurrentHashMap是執行緒安全的,但是與Hashtablea相比,實現執行緒安全的方式不同。Hashtable是通過對hash表結構進行鎖定,是阻塞式的,當一個執行緒佔有這個鎖時,其他執行緒必須阻塞等待其釋放鎖。ConcurrentHashMap是採用分離鎖的方式,它並沒有對整個hash表進行鎖定,而是區域性鎖定,也就是說當一個執行緒佔有這個區域性鎖時,不影響其他執行緒對hash表其他地方的存取。
具體實現:ConcurrentHashMap內部有一個Segment
jdk 1.8
在jdk 8中,ConcurrentHashMap不再使用Segment分離鎖,而是採用一種樂觀鎖CAS演算法來實現同步問題,但其底層還是「陣列+鏈表->紅黑樹」的實現。
CyclicBarrier和CountDownLatch區別
這兩個類非常類似,都在java.util.concurrent下,都可以用來表示程式碼執行到某個點上,二者的區別在於:
CyclicBarrier的某個執行緒執行到某個點上之後,該執行緒即停止執行,直到所有的執行緒都到達了這個點,所有執行緒才重新執行;CountDownLatch則不是,某執行緒執行到某個點上之後,只是給某個數值-1而已,該執行緒繼續執行
CyclicBarrier只能喚起一個任務,CountDownLatch可以喚起多個任務
CyclicBarrier可重用,CountDownLatch不可重用,計數值爲0該CountDownLatch就不可再用了
java中的++操作符執行緒安全麼?
不是執行緒安全的操作。它涉及到多個指令,如讀取變數值,增加,然後儲存回記憶體,這個過程可能會出現多個執行緒交差
你有哪些多執行緒開發良好的實踐?
給執行緒命名
最小化同步範圍
優先使用volatile
儘可能使用更高層次的併發工具而非wait和notify()來實現執行緒通訊,如BlockingQueue,Semeaphore
優先使用併發容器而非同步容器.
考慮使用執行緒池
關於volatile關鍵字
可以建立Volatile陣列嗎?
Java 中可以建立 volatile型別陣列,不過只是一個指向陣列的參照,而不是整個陣列。如果改變參照指向的陣列,將會受到volatile 的保護,但是如果多個執行緒同時改變陣列的元素,volatile標示符就不能起到之前的保護作用了
volatile能使得一個非原子操作變成原子操作嗎?
一個典型的例子是在類中有一個 long 型別的成員變數。如果你知道該成員變數會被多個執行緒存取,如計數器、價格等,你最好是將其設定爲 volatile。爲什麼?因爲 Java 中讀取 long 型別變數不是原子的,需要分成兩步,如果一個執行緒正在修改該 long 變數的值,另一個執行緒可能只能看到該值的一半(前 32 位)。但是對一個 volatile 型的 long 或 double 變數的讀寫是原子。
一種實踐是用 volatile 修飾 long 和 double 變數,使其能按原子型別來讀寫。double 和 long 都是64位元寬,因此對這兩種型別的讀是分爲兩部分的,第一次讀取第一個 32 位,然後再讀剩下的 32 位,這個過程不是原子的,但 Java 中 volatile 型的 long 或 double 變數的讀寫是原子的。volatile 修復符的另一個作用是提供記憶體屏障(memory barrier),例如在分佈式框架中的應用。簡單的說,就是當你寫一個 volatile 變數之前,Java 記憶體模型會插入一個寫屏障(write barrier),讀一個 volatile 變數之前,會插入一個讀屏障(read barrier)。意思就是說,在你寫一個 volatile 域時,能保證任何執行緒都能看到你寫的值,同時,在寫之前,也能保證任何數值的更新對所有執行緒是可見的,因爲記憶體屏障會將其他所有寫的值更新到快取。
volatile型別變數提供什麼保證?
volatile 主要有兩方面的作用:1.避免指令重排2.可見性保證.例如,JVM 或者 JIT爲了獲得更好的效能會對語句重排序,但是 volatile 型別變數即使在沒有同步塊的情況下賦值也不會與其他語句重排序。 volatile 提供 happens-before 的保證,確保一個執行緒的修改能對其他執行緒是可見的。某些情況下,volatile 還能提供原子性,如讀 64 位數據型別,像 long 和 double 都不是原子的(低32位元和高32位元),但 volatile 型別的 double 和 long 就是原子的.
關於集合
Java中的集合及其繼承關係
關於集合的體系是每個人都應該爛熟於心的,尤其是對我們經常使用的List,Map的原理更該如此
poll()方法和remove()方法區別?
poll() 和 remove() 都是從佇列中取出一個元素,但是 poll() 在獲取元素失敗的時候會返回空,但是 remove() 失敗的時候會拋出異常。
LinkedHashMap和PriorityQueue的區別
PriorityQueue 是一個優先順序佇列,保證最高或者最低優先順序的的元素總是在佇列頭部,但是 LinkedHashMap 維持的順序是元素插入的順序。當遍歷一個 PriorityQueue 時,沒有任何順序保證,但是 LinkedHashMap 課保證遍歷順序是元素插入的順序。
WeakHashMap與HashMap的區別是什麼?
WeakHashMap 的工作與正常的 HashMap 類似,但是使用弱參照作爲 key,意思就是當 key 物件沒有任何參照時,key/value 將會被回收。
ArrayList和LinkedList的區別?
最明顯的區別是 ArrrayList底層的數據結構是陣列,支援隨機存取,而 LinkedList 的底層數據結構是雙向回圈鏈表,不支援隨機存取。使用下標存取一個元素,ArrayList 的時間複雜度是 O(1),而 LinkedList 是 O(n)。
ArrayList和Array有什麼區別?
Array可以容納基本型別和物件,而ArrayList只能容納物件。
Array是指定大小的,而ArrayList大小是固定的
ArrayList和HashMap預設大小?
在 Java 7 中,ArrayList 的預設大小是 10 個元素,HashMap 的預設大小是16個元素(必須是2的冪)。這就是 Java 7 中 ArrayList 和 HashMap 類的程式碼片段
private static final int DEFAULT_CAPACITY = 10;
//from HashMap.java JDK 7
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
1
2
3
4
Comparator和Comparable的區別?
Comparable 介面用於定義物件的自然順序,而 comparator 通常用於定義使用者定製的順序。Comparable 總是隻有一個,但是可以有多個 comparator 來定義物件的順序。
如何實現集合排序?
你可以使用有序集合,如 TreeSet 或 TreeMap,你也可以使用有順序的的集合,如 list,然後通過 Collections.sort() 來排序。
如何列印陣列內容
你可以使用 Arrays.toString() 和 Arrays.deepToString() 方法來列印陣列。由於陣列沒有實現 toString() 方法,所以如果將陣列傳遞給 System.out.println() 方法,將無法列印出陣列的內容,但是 Arrays.toString() 可以列印每個元素。
LinkedList的是單向鏈表還是雙向?
雙向回圈列表,具體實現自行查閱原始碼.
TreeMap是實現原理
採用紅黑樹實現,具體實現自行查閱原始碼.
遍歷ArrayList時如何正確移除一個元素
該問題的關鍵在於面試者使用的是 ArrayList 的 remove() 還是 Iterator 的 remove()方法。這有一段範例程式碼,是使用正確的方式來實現在遍歷的過程中移除元素,而不會出現 ConcurrentModificationException 異常的範例程式碼。
什麼是ArrayMap?它和HashMap有什麼區別?
ArrayMap是Android SDK中提供的,非Android開發者可以略過.
ArrayMap是用兩個陣列來模擬map,更少的記憶體佔用空間,更高的效率.
具體參考這篇文章:ArrayMap VS HashMap
HashMap的實現原理
1 HashMap概述: HashMap是基於雜湊表的Map介面的非同步實現。此實現提供所有可選的對映操作,並允許使用null值和null鍵。此類不保證對映的順序,特別是它不保證該順序恆久不變。
2 HashMap的數據結構: 在java程式語言中,最基本的結構就是兩種,一個是陣列,另外一個是模擬指針(參照),所有的數據結構都可以用這兩個基本結構來構造的,HashMap也不例外。HashMap實際上是一個「鏈表雜湊」的數據結構,即陣列和鏈表的結合體。
當我們往Hashmap中put元素時,首先根據key的hashcode重新計算hash值,根絕hash值得到這個元素在陣列中的位置(下標),如果該陣列在該位置上已經存放了其他元素,那麼在這個位置上的元素將以鏈表的形式存放,新加入的放在鏈頭,最先加入的放入鏈尾.如果陣列中該位置沒有元素,就直接將該元素放到陣列的該位置上.
需要注意Jdk 1.8中對HashMap的實現做了優化,當鏈表中的節點數據超過八個之後,該鏈表會轉爲紅黑樹來提高查詢效率,從原來的O(n)到O(logn)
你瞭解Fail-Fast機制 機製嗎
Fail-Fast即我們常說的快速失敗,更多內容參看fail-fast機制 機製
Fail-fast和Fail-safe有什麼區別
Iterator的fail-fast屬性與當前的集合共同起作用,因此它不會受到集閤中任何改動的影響。Java.util包中的所有集合類都被設計爲fail->fast的,而java.util.concurrent中的集合類都爲fail-safe的。當檢測到正在遍歷的集合的結構被改變時,Fail-fast迭代器拋出ConcurrentModificationException,而fail-safe迭代器從不拋出ConcurrentModificationException。
關於日期
SimpleDateFormat是執行緒安全的嗎?
非常不幸,DateFormat 的所有實現,包括 SimpleDateFormat 都不是執行緒安全的,因此你不應該在多執行緒序中使用,除非是在對外執行緒安全的環境中使用,如 將 SimpleDateFormat 限制在 ThreadLocal 中。如果你不這麼做,在解析或者格式化日期的時候,可能會獲取到一個不正確的結果。因此,從日期、時間處理的所有實踐來說,我強力推薦 joda-time 庫。
如何格式化日期?
Java 中,可以使用 SimpleDateFormat 類或者 joda-time 庫來格式日期。DateFormat 類允許你使用多種流行的格式來格式化日期。參見答案中的範例程式碼,程式碼中演示了將日期格式化成不同的格式,如 dd-MM-yyyy 或 ddMMyyyy。
關於異常
簡單描述java異常體系
相比沒有人不瞭解異常體系,關於異常體系的更多資訊可以見:白話異常機制 機製
什麼是異常鏈
詳情直接參見白話異常機制 機製,不做解釋了.
throw和throws的區別
throw用於主動拋出java.lang.Throwable 類的一個範例化物件,意思是說你可以通過關鍵字 throw 拋出一個 Error 或者 一個Exception,如:throw new IllegalArgumentException(「size must be multiple of 2″),
而throws 的作用是作爲方法宣告和簽名的一部分,方法被拋出相應的異常以便呼叫者能處理。Java 中,任何未處理的受檢查異常強制在 throws 子句中宣告。
關於序列化
Java 中,Serializable 與 Externalizable 的區別
Serializable 介面是一個序列化 Java 類的介面,以便於它們可以在網路上傳輸或者可以將它們的狀態儲存在磁碟上,是 JVM 內嵌的預設序列化方式,成本高、脆弱而且不安全。Externalizable 允許你控制整個序列化過程,指定特定的二進制格式,增加安全機制 機製。
關於JVM
JVM特性
平臺無關性.
Java語言的一個非常重要的特點就是與平臺的無關性。而使用Java虛擬機器是實現這一特點的關鍵。一般的高階語言如果要在不同的平臺上執行,至少需要編譯成不同的目的碼。而引入Java語言虛擬機器後,Java語言在不同平臺上執行時不需要重新編譯。Java語言使用模式Java虛擬機器遮蔽了與具體平臺相關的資訊,使得Java語言編譯程式只需生成在Java虛擬機器上執行的目的碼(位元組碼),就可以在多種平臺上不加修改地執行。Java虛擬機器在執行位元組碼時,把位元組碼解釋成具體平臺上的機器指令執行。
簡單解釋一下類載入器
有關類載入器一般會問你四種類載入器的應用場景以及雙親委派模型,更多的內容參看深入理解JVM載入器。
簡述堆和棧的區別
VM 中堆和棧屬於不同的記憶體區域,使用目的也不同。棧常用於儲存方法幀和區域性變數,而物件總是在堆上分配。棧通常都比堆小,也不會在多個執行緒之間共用,而堆被整個 JVM 的所有執行緒共用。
簡述JVM記憶體分配
基本數據型別比變數和物件的參照都是在棧分配的
堆記憶體用來存放由new建立的物件和陣列
類變數(static修飾的變數),程式在一載入的時候就在堆中爲類變數分配記憶體,堆中的記憶體地址存放在棧中
範例變數:當你使用java關鍵字new的時候,系統在堆中開闢並不一定是連續的空間分配給變數,是根據零散的堆記憶體地址,通過雜湊演算法換算爲一長串數位以表徵這個變數在堆中的」物理位置」,範例變數的生命週期–當範例變數的參照丟失後,將被GC(垃圾回收器)列入可回收「名單」中,但並不是馬上就釋放堆中記憶體
區域性變數: 由宣告在某方法,或某程式碼段裡(比如for回圈),執行到它的時候在棧中開闢記憶體,當區域性變數一但脫離作用域,記憶體立即釋放
其他
XML解析的幾種方式和特點
DOM,SAX,PULL三種解析方式:
DOM:消耗記憶體:先把xml文件都讀到記憶體中,然後再用DOM API來存取樹形結構,並獲取數據。這個寫起來很簡單,但是很消耗記憶體。要是數據過大,手機不夠牛逼,可能手機直接宕機
SAX:解析效率高,佔用記憶體少,基於事件驅動的:更加簡單地說就是對文件進行順序掃描,當掃描到文件(document)開始與結束、元素(element)開始與結束、文件(document)結束等地方時通知事件處理常式,由事件處理常式做相應動作,然後繼續同樣的掃描,直至文件結束。
PULL:與 SAX 類似,也是基於事件驅動,我們可以呼叫它的next()方法,來獲取下一個解析事件(就是開始文件,結束文件,開始標籤,結束標籤),當處於某個元素時可以呼叫XmlPullParser的getAttributte()方法來獲取屬性的值,也可呼叫它的nextText()獲取本節點的值。
JDK 1.7特性
然 JDK 1.7 不像 JDK 5 和 8 一樣的大版本,但是,還是有很多新的特性,如 try-with-resource 語句,這樣你在使用流或者資源的時候,就不需要手動關閉,Java 會自動關閉。Fork-Join 池某種程度上實現 Java 版的 Map-reduce。允許 Switch 中有 String 變數和文字。菱形操作符(<>)用於型別推斷,不再需要在變數宣告的右邊申明泛型,因此可以寫出可讀寫更強、更簡潔的程式碼
JDK 1.8特性
java 8 在 Java 歷史上是一個開創新的版本,下面 下麪 JDK 8 中 5 個主要的特性:
Lambda 表達式,允許像物件一樣傳遞匿名函數
Stream API,充分利用現代多核 CPU,可以寫出很簡潔的程式碼
Date 與 Time API,最終,有一個穩定、簡單的日期和時間庫可供你使用
擴充套件方法,現在,介面中可以有靜態、預設方法。
重複註解,現在你可以將相同的註解在同一型別上使用多次。
Maven和ANT有什麼區別?
雖然兩者都是構建工具,都用於建立 Java 應用,但是 Maven 做的事情更多,在基於「約定優於設定」的概念下,提供標準的Java 專案結構,同時能爲應用自動管理依賴(應用中所依賴的 JAR 檔案.
JDBC最佳實踐
優先使用批次操作來插入和更新數據
使用PreparedStatement來避免SQL漏洞
使用數據連線池
通過列名來獲取結果集
IO操作最佳實踐
使用有緩衝的IO類,不要單獨讀取位元組或字元
使用NIO和NIO 2或者AIO,而非BIO
在finally中關閉流
使用記憶體對映檔案獲取更快的IO
快取
memcache的分佈式原理
memcached 雖然稱爲 「 分佈式 」 快取伺服器,但伺服器端並沒有 「 分佈式 」 功能。每個伺服器都是完全獨立和隔離的服務。 memcached 的分佈式,則是完全由用戶端程式庫實現的。 這種分佈式是 memcached 的最大特點。
memcache的記憶體分配機制 機製
如何存放數據到memcached快取中?(memcache記憶體分配機制 機製)
Slab Allocator記憶體分配機制 機製:
預先將記憶體分配成數個slab倉庫,每個倉庫再切出不同大小的chunk,去適配收到的數據。多餘的只能造成浪費,不可避免。
增長因子(Grace factor):一般而言觀察數據大小的變化規律設定合理的增長因子,預設1.25倍.
太大容易造成浪費。memcached.exe -m 64 -p 11211 -f 1.25
如果有100byte的內容要儲存,但122大小的倉庫的chunk用滿了怎麼辦?
答:是並不會尋找更大倉庫的chunk來儲存,而是把122倉庫中的舊數據踢掉!
memcache的惰性失效機制 機製
1 當某個值過期後並不會從記憶體刪除。(因此status統計時的curr_items有其資訊)
2 如果之前沒有get過,將不會自動刪除。
如果(過期失效,沒get過一次)又沒有一個新值去佔用他的位置時,當做空的chunk佔用。
3 當取其值(get)時,判斷是否過期:如果過期返回空,且清空。(所以curr_items就減少了)
即這個過期只是讓使用者看不到這個數據而已,並沒有在過期的瞬間立即從記憶體刪除,這個過程
稱爲lazy expirtion,屬性失效,好處是節約了cpu和檢測的成本,稱爲「惰性失效機制 機製」
memcache快取的無底洞現象 快取的無底洞現象:
facebook的工作人員反應,他們在2010年左右,memcacahed節點就已經達到3000個,大約數千G的快取,他們發現一個問題,memchache連線頻率太高導致效率下降,於是加memcache節點,新增後發現連線頻率導致的問題仍然沒有好轉,稱之爲「無底洞現象」。
問題分析:
以使用者爲例:user-133-age,user-133_name,user-133-height…N個key
當伺服器增多,133號使用者的資訊也被散落在更多的伺服器,
所以同樣是訪問個人主頁,得到相同的個人資訊,節點越多,要連線節點越多,對於memcache的連線數並沒有隨着節點的增多而降低,問題出現。
事實上:
nosql和傳統的rdbms並不是水火不容,兩者在某些設計上是可以相互參考的。
對於nosql的key-value這種儲存,key的設計可以參考mysql中表和列的設計。
比如user表下有age、name、height列,對應的key可以用user:133:age=23,user:133:name=ls,user:133:height=168;
問題的解決方案:
把某一組key按其共同字首來分佈,比如:user:133:age=23,user:133:name=ls,user:133:height=168;
在用分佈式演算法求其節點時,應該以user:133來計算,而不是以user:133:age來計算,這樣這三個關於個人資訊的key都落在同一個節點上。
再次存取只需要連線一個節點。問題解決。
一致性Hash演算法的實現原理
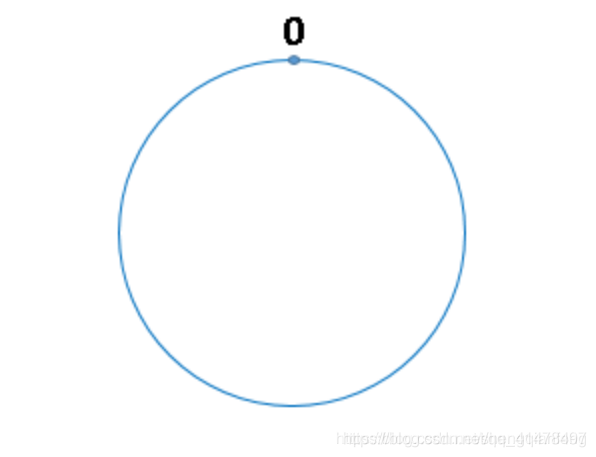
Hash環
我們把2^32次方想成一個環,比如鐘錶上有60個分針點組成一個圓,那麼hash環就是由232個點組成的圓。第一個點是0,最後一個點是232-1,我們把這232個點組成的環稱之爲HASH環。
一致性Hash演算法
將memcached物理機節點通過Hash演算法虛擬到一個虛擬閉環上(由0到232構成),key請求的時候通過Hash演算法計算出Hash值然後對232取模,定位到環上順時針方向最接近的虛擬物理節點就是要找到的快取伺服器。
假設有ABC三臺快取伺服器:
我們使用這三臺伺服器各自的IP進行hash計算然後對2~32取模即:
Hash(伺服器IP)%2~32
計算出來的結果是0到2~32-1的一個整數,那麼Hash環上必有一個點與之對應。比如:
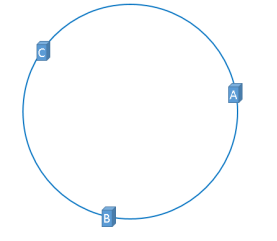
現在快取伺服器已經落到了Hash環上,接下來我們就看我們的數據是怎麼放到快取伺服器的?
我們可以同樣對Object取Hash值然後對2~32取模,比如落到了接近A的一個點上:
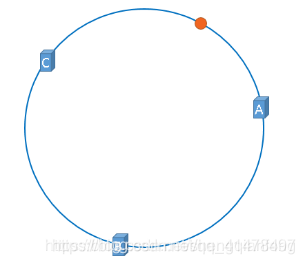
那麼這個數據理應存到A這個快取伺服器節點上
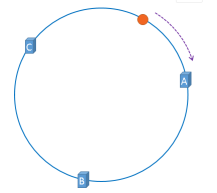
所以,在快取伺服器節點數量不變的情況下,快取的落點是不會變的。
但是如果B掛掉了呢?
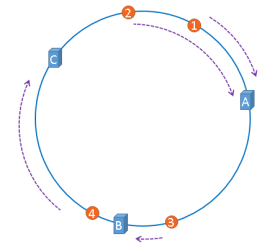
按照hash且取模的演算法,圖中3這個Object理應就分配到了C這個節點上去了,所以就會到C上找快取數據,結果當然是找不到,進而從DB讀取數據重新放到了C上。
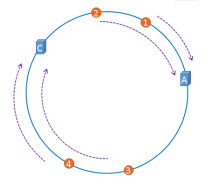
但是對於編號爲1,2的Object還是落到A,編號爲4的Object還是落到C,B宕機所影響的僅僅是3這個Object。這就是一致性Hash演算法的優點。
Hash環的傾斜
前面我們理想化的把三臺memcache機器均勻分到了Hash環上:
但是現實情況可能是:
如果Hash環傾斜,即快取伺服器過於集中將會導致大量快取數據被分配到了同一個伺服器上。比如編號1,2,3,4,6的Object都被存到了A,5被存到B,而C上竟然一個數據都沒有,這將造成記憶體空間的浪費。
爲了解決這個問題,一致性Hash演算法中使用「虛擬節點」解決。
虛擬節點解決Hash環傾斜
「虛擬節點」是「實際節點」在hash環上的複製品,一個實際節點可能對應多個虛擬節點。這樣就可以將ABC三臺伺服器相對均勻分配到Hash環上,以減少Hash環傾斜的影響,使得快取被均勻分配到hash環上。
hash演算法平衡性
平衡性指的是hash的結果儘可能分佈到所有的快取中去,這樣可以使得所有的快取空間都可以得到利用。但是hash演算法不保證絕對的平衡性,爲了解決這個問題一致性hash引入了「虛擬節點」的概念。虛擬節點」( virtual node )是實際節點在 hash 空間的複製品( replica ),一實際個節點對應了若幹個「虛擬節點」,這個對應個數也成爲「複製個數」,「虛擬節點」在 hash 空間中以 hash 值排列。「虛擬節點」的hash計算可以採用對應節點的IP地址加數位後綴的方式。
例如假設 cache A 的 IP 地址爲202.168.14.241 。
引入「虛擬節點」前,計算 cache A 的 hash 值: Hash(「202.168.14.241」);
引入「虛擬節點」後,計算「虛擬節」點 cache A1 和 cache A2 的 hash 值:
Hash(「202.168.14.241#1」); // cache A1
Hash(「202.168.14.241#2」); // cache A2
這樣只要是命中cacheA1和cacheA2節點,就相當於命中了cacheA的快取。這樣平衡性就得到了提高。
參考:一致性hash和虛擬節點 - 依稀|.мīss.чou - 部落格園
memcached與redis的區別
1 redis做儲存,可以持久化,memcache做快取,數據易丟失。
2 redis支援多數據型別,memcache存放字串。
3 redis伺服器端僅支援單進程、單執行緒存取,也就是先來後到的序列模式,避免執行緒上下文切換,自然也就保證數據操作的原子性。Memcache伺服器端是支援多執行緒存取的。
4 redis雖然是單進程單執行緒模式,但是redis使用了IO多路複用技術做到一個執行緒可以處理很多個請求來保證高效能。
Redis的主從複製
1 在Slave啓動並連線到Master之後,它將主動發送一個SYNC命令給Master。
2 Master在收到SYNC命令之後,將執行BGSAVE命令執行後臺存檔進程(rdb快照), 同時收集所有接收到的修改數據集的命令即寫命令到緩衝區,在後台存檔進程執行完畢後,Master將傳送整個數據庫檔案到Slave。
3 Slave在接收到數據庫檔案數據之後,將自身記憶體清空,載入rdb檔案到記憶體中完成一次完全同步。
4 接着,Master繼續將所有已經收集到緩衝區的修改命令,和新的修改命令依次傳送給Slaves
5 Slave將在本地執行這些數據修改命令,從而達到最終的數據同步
6 之後Master和Slave之間會不斷通過非同步方式進行命令的同步,從而保證數據的實時同步
7 如果Master和Slave之間的鏈接出現斷連現象,Slave可以自動重連Master,但是在
重新連線成功之後:
2.8之前的redis將進行一次完全同步
2.8之後進行部分同步,使用的是PSYNC命令
如下:
Redis的部分複製過程
部分同步工作原理如下:
1):Master爲被髮送的複製流建立一個記憶體緩衝區(in-memory backlog),記錄最近發送的複製流命令
2):Master和Slave之間都記錄一個複製偏移量(replication offset)和當前Master ID(Master run id)
3):當出現網路斷開,Slave會重新連線,並且向Master請求繼續執行原來的複製進程
4):如果Slave中斷網前的MasterID和當前要連的MasterID相同,並且從斷開時到當前時刻Slave記錄的偏移量所指定的數據仍然儲存在Master的複製流緩衝區裏面,則Master會向Slave發送缺失的那部分數據,Slave執行後複製工作可以繼續執行。
5):否則Slave就執行完整重同步操作
Redis的主從複製阻塞模式
1 同一個Master服務可以同步n多個Slave服務
2 Slave節點同樣可以接受其它Slave節點的連線和同步服務請求,分擔Master節點的同步壓力
3 Master是以非阻塞方式爲Slave提供同步服務,所以主從複製期間Master一樣可以提供讀寫請求。
4 Slave同樣是以非阻塞的方式完成數據同步,在同步期間,如果有用戶端提交查詢請求,Redis則返回同步之前的數據
Redis的數據持久化方式
Rdb快照和aof
RDB快照:可以設定在n秒內有m個key修改就做自動化快照方式
AOF:每一個收到的寫命令都通過write函數追加到檔案中。更安全。
Redis的高可用部署方式
哨兵模式
redis3.0之前的Sentinel哨兵機制 機製,redis3.0之前只能使用一致性hash方式做分佈式快取。哨兵的出現主要是解決了主從複製出現故障時需要人爲幹預的問題。
Redis哨兵主要功能
(1)叢集監控:負責監控Redis master和slave進程是否正常工作
(2)訊息通知:如果某個Redis範例有故障,那麼哨兵負責發送訊息作爲報警通知給管理員
(3)故障轉移:如果master node掛掉了,會自動轉移到slave node上
(4)設定中心:如果故障轉移發生了,通知client用戶端新的master地址
Redis哨兵的高可用
原理:當主節點出現故障時,由Redis Sentinel自動完成故障發現和轉移,並通知應用方,實現高可用性
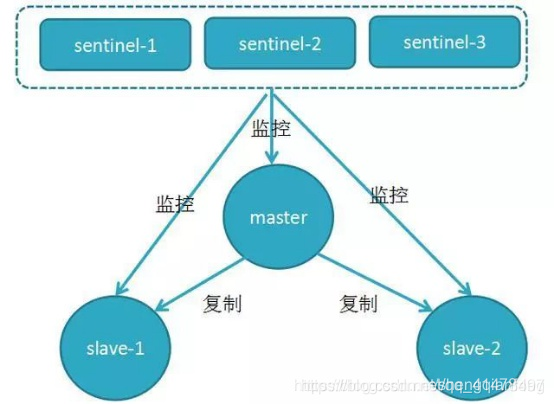
哨兵機制 機製建立了多哨兵節點,共同監控數據節點的執行狀況。
同時哨兵節點之間也互相通訊,交換對主從節點的監控狀況。
每隔1秒每個哨兵會向整個叢集:Master主伺服器+Slave從伺服器+其他Sentinel(哨兵)進程,發送一次ping命令做一次心跳檢測。
哨兵如何判斷redis主從節點是否正常?
涉及兩個新的概念:主觀下線和客觀下線。
主觀下線:一個哨兵節點判定主節點down掉是主觀下線。
客觀下線:只有半數哨兵節點都主觀判定主節點down掉,此時多個哨兵節點交換主觀判定結果,纔會判定主節點客觀下線。
原理:基本上哪個哨兵節點最先判斷出這個主節點客觀下線,就會在各個哨兵節點中發起投票機制 機製Raft演算法(選舉演算法),最終被投爲領導者的哨兵節點完成主從自動化切換的過程。
叢集模式
redis3.0之後的容錯叢集方式,無中心結構,每個節點儲存數據和整個叢集狀態,每個節點都和其他所有節點連線,需要至少三個master提供寫的功能。
因此叢集中至少應該有奇數個節點,因此至少有三個節點,每個節點至少有一個備份節點,所以redis叢集應該至少6個節點。
每個Master有一個範圍的slot槽位用於寫數據。
Redis可以線上擴容嗎?zk呢
Reids的線上擴容,不需要重新啓動伺服器,動態的在原始叢集中新增新的節點,並分配slot槽。
但是zk不能線上擴容,需要重新啓動,但是我們可以選擇一個一個重新啓動。
Redis高併發和快速的原因
1.redis是基於記憶體的,記憶體的讀寫速度非常快;
2.redis是單執行緒的,省去了很多上下文切換執行緒的時間;
3.redis使用多路複用技術,可以處理併發的連線。
缺點:無法發揮多核CPU效能
瀏覽器本地快取的瞭解和使用
資源在瀏覽器端的本地快取可以通過Expires和Last-Modified返回頭資訊進行有效控制。
1)Expires告訴瀏覽器在該指定過期時間前再次存取同一URL時,直接從本地快取讀取,無需再向伺服器發起http請求;
優點是:瀏覽器直接讀取快取資訊無需發起http請求。
缺點是:當使用者按F5或Ctl+F5重新整理頁面時瀏覽器會再次發起http請求。
2)當伺服器返回設定了Last-Modified頭,下次發起同一URL的請求時,請求頭會自動包含If-Modified-Since頭資訊,伺服器對靜態內容會根據該資訊跟檔案的最後修改時間做比較,如果最後修改時間不大於If-Modified-Since頭資訊,則返回304:告訴瀏覽器請求內容未更新可直接使用本地快取。
(注意:只對靜態內容有效,如js/css/image/html等,不包括動態內容,如JSP)
優點:無論使用者行爲如何都有效;
缺點:仍需向伺服器發起一次http請求;
快取雪崩
如果快取集中在一段時間內失效,發生大量的快取穿透,所有的查詢都落在數據庫上,造成了快取雪崩。
解決辦法:
沒有完美的解決方案,可以通過隨機演算法讓失效時間隨機分佈,避免同一時刻失效。
快取穿透
存取一個不存在的key,快取不起作用,請求會穿透到DB,可能DB也沒查到,流量大時DB會掛掉。
解決辦法:
1.採用布隆過濾器,使用一個足夠大的bitmap,用於儲存可能存取的key,不存在的key直接被過濾;
2存取key未在DB查詢到值,也將空值寫進快取,但可以設定較短過期時間。
HashMap HashMap的Hash碰撞
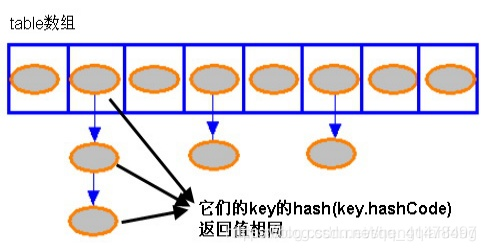
Hash值衝突問題是Hash表儲存模型需要解決的一個問題。通常有兩種方法:
將相同Hash值的Entry物件組織成一個鏈表放置在hash值對應的槽位。HashMap採用的是鏈表法,且是單向鏈表(通過head元素就可以操作後續所有元素,對鏈表而言,新加入的節點會從頭節點加入。)
核心原始碼:
private void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
以上程式碼說明:
系統總是將新新增的 Entry 物件放入 table 陣列的 bucketIndex 索引處。
1 如果 bucketIndex 索引處已經有了一個 Entry 物件,那新新增的 Entry 物件指向原有的 Entry 物件
(產生一個 Entry 鏈)
2 如果 bucketIndex 索引處沒有 Entry 物件,也就是上面程式程式碼的 e 變數是 null,也就是新放入的
Entry 物件指向 null,也就是沒有產生 Entry 鏈。
HashMap裏面沒有出現hash衝突時,沒有形成單鏈表時,hashmap查詢元素很快,get()方法能夠直接定位到元素,
但是出現單鏈表後,單個bucket 裡儲存的不是一個 Entry,而是一個 Entry 鏈,系統只能必須按順序遍歷每個
Entry,直到找到想搜尋的 Entry 爲止——如果恰好要搜尋的 Entry 位於該 Entry 鏈的最末端(該 Entry 是最早
放入該 bucket 中),那系統必須回圈到最後才能 纔能找到該元素。
HashMap的get和put原理 PUT原理:
當呼叫HashMap的put方法傳遞key和value時,先呼叫key的hashcode方法。
通過key的Hash值來找到Bucket----‘桶’的位置,然後迭代這個位置的Entry列表
判斷是否存在key的hashcode和equals完全相同的key,如果完全相同則覆蓋value,
否則插入到entry鏈的頭部。
HashMap在put時的Entry鍊形成的場景?
當程式試圖將一個key-value對放入HashMap中時,程式首先根據該 key 的 hashCode() 返回值決定該 Entry 的儲存位置:
如果這兩個 Entry 的 key 的 hashCode() 返回值相同,那它們的儲存位置相同。
如果這兩個 Entry 的 key 通過 equals 比較返回 true,新新增 Entry 的 value 將覆蓋集閤中原有 Entry 的 value,但key不會覆蓋。
如果這兩個 Entry 的 key 通過 equals 比較返回 false,新新增的 Entry 將與集閤中原有 Entry 形成 Entry 鏈,而且新新增的 Entry 位於 Entry 鏈的頭部
GET原理:
根據該 key 的 hashCode 值計算它的 hash 碼,遍歷並回圈取出 Entry 陣列中指定索引處的Entry值,如果該 Entry 的 key 與被搜尋 key 相同 ,且Enrty的hash值跟key的hash碼相同,然後看是否是Entry鏈,如果是則迭代這個位置的Entry列表,判斷是否存在key的hashcode和equals完全相同的key,如果完全相同則獲取value。
HashMap的rehash
HashMap初始容量大小爲16,一般來說,當有數據要插入時,都會檢查容量有沒有超過設定的thredhold,如果超過,需要增大Hash表的尺寸,但是這樣一來,整個Hash表裏的元素都需要被重算一遍。這叫rehash,這個成本相當的大
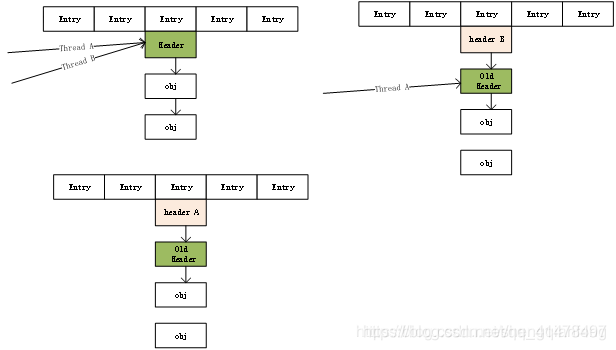
HashMap的執行緒不安全問題
比如put操作時,有兩個執行緒A和B,首先A希望插入一個key-value對到HashMap中,首先計算記錄所要落到的桶的索引BucketIndex座標,然後獲取到該桶裏面的Entry鏈表header頭結點,此時執行緒A的時間片用完了,而此時執行緒B被排程得以執行,和執行緒A一樣執行,只不過執行緒B成功將記錄插到了桶裏面,假設執行緒A插入的記錄計算出來的桶索引和執行緒B要插入的記錄計算出來的桶索引是一樣的,那麼當執行緒B成功插入之後,執行緒A再次被排程執行時,它依然持有過期的鏈表頭但是它對此一無所知,以至於它認爲它應該這樣做,如此一來就覆蓋了執行緒B插入的記錄,這樣執行緒B插入的記錄就憑空消失了,造成了數據不一致的行爲。另一個不安全的體現是是get操作可能由於resize而死回圈。
參考:HashMap爲什麼執行緒不安全(hash碰撞與擴容導致) - 邱明成 - 部落格園
HashMap和Hashtable的區別
相同點:
1 都實現了Map介面
2 Hashtable和HashMap採用的hash/rehash演算法都大概一樣,所以效能不會有很大的差異
不同點:
1 hashMap允許NULL作爲key和value,而hashtable不允許
2 hashMap執行緒不安全,Hashtable執行緒安全
3 hashMap速度快於hashtable
4 HashMap 把 Hashtable的contains方法去掉了,改成containsvalue和containsKey,避免引起誤會
5 Hashtable是基於陳舊的Dictionary類的,HashMap是Java 1.2引進的Map介面的一個實現
爲什麼collection沒有實現clonable介面
Collection介面有很多不同的集合實現形式,而clonable只對具體的物件有意義。
爲什map沒有實現collection介面
Set 和List 都繼承了Conllection,Map沒有繼承於Collection介面,Map提供的是key-Value的對映,而Collection代表一組物件。
Map介面的實現有哪些,區別是什麼
HashMap,LinkedHashMap,Hashtable,TreeMap。
LinkedHashMap 是HashMap的一個子類,儲存了記錄的插入順序
Hashtable和HashMap類似,它繼承自Dictionary類,不同的是它不允許鍵或值爲空。
TreeMap實現SortMap介面,能夠把它儲存的記錄根據鍵排序,預設是按鍵值的升序排序,也可以指定排序的比較器
執行緒池
Executors框架的四種執行緒池及拒絕策略
四種執行緒池
ExecutorService executorService =
固定大小執行緒池
Executors.newFixedThreadPool(60);
設定固定值會造成高併發執行緒排隊等待空閒執行緒,尤其是當讀取大數據量時執行緒處理時間長而不釋放執行緒,導致無法建立新執行緒。
可快取執行緒池
Executors.newCachedThreadPool();
執行緒池無限大,而系統資源(記憶體等)有限,會導致機器記憶體溢位OOM。
定長且可定時、週期執行緒池
Executors.newScheduledThreadPool(5);
單執行緒執行緒池
Executors.newSingledThreadPool();
/* 自定義執行緒池。
* 構造參數:
* public ThreadPoolExecutor(
* int corePoolSize,–當前執行緒池核心執行緒數
* int maximumPoolSize,–當前執行緒池最大執行緒數
* long keepAliveTime,–保持活着的空間時間
* TimeUnit unit,–時間單位
* BlockingQueue workQueue,–排隊等待的自定義佇列
* ThreadFactoty threadFactory,
* RejectedExecutionHandler handler–佇列滿以後,其他任務被拒絕執行的方法
* ){…}
在使用有界佇列時,若有新的任務需要執行,
若執行緒池實際執行緒數小於corePoolSize,則優先建立執行緒,
若大於corePoolSize,則會將任務加入佇列,
若佇列已滿,則在匯流排程數不大於maximumPoolSize的前提下,建立新的執行緒,
若執行緒數大於maximumPoolSize,則執行拒絕策略。或其他自定義方式。
JDK拒絕策略
AbortPolicy:預設,直接拋出異常,系統正常工作。
DiscardOldestPolicy:丟棄最老的一個請求,嘗試再次提交當前任務。
CallerRunsPolicy:只要執行緒池未關閉,該策略直接在呼叫者執行緒中,執行當前被丟棄的任務。用執行緒池中的執行緒執行,而是交給呼叫方來執行, 如果新增到執行緒池失敗,那麼主執行緒會自己去執行該任務,不會等待執行緒池中的執行緒去執行
new ThreadPoolExecutor(
2, 3, 30, TimeUnit.SECONDS,
new SynchronousQueue(),
new RecorderThreadFactory(「CookieRecorderPool」),
new ThreadPoolExecutor.CallerRunsPolicy());
DiscardPolicy:丟棄無法處理的任務,不給予任何處理。
自定義拒絕策略
如果需要自定義策略,可以實現RejectedExecutionHandler介面。
Reactor模式
參考:Netty中的三種Reactor(反應堆) - duanxz - 部落格園
Reactor單執行緒模型
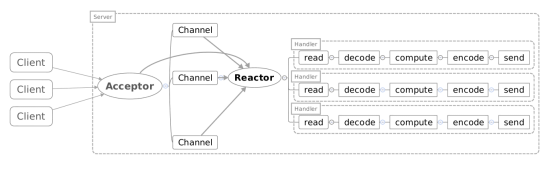
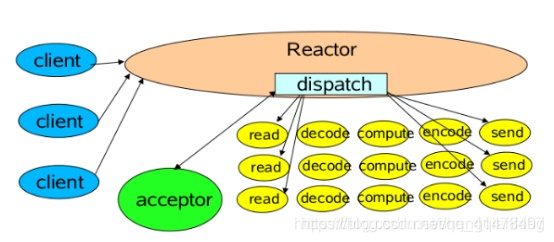
一個Acceptor執行緒,監聽Accept事件,負責接收用戶端的連線SocketChannel,SocketChannel註冊到Selector上並關心可讀可寫事件。
一個Reactor執行緒,負責輪訓selector,將selector註冊的就緒事件的key讀取出來,拿出attach任務Handler根據事件型別分別去執行讀寫等。
單執行緒模型的瓶頸:
比如:拿一個用戶端來說,進行多次請求,如果Handler中數據讀出來後處理的速度比較慢(非IO操作:解碼-計算-編碼-返回)會造成用戶端的請求被積壓,導致響應變慢!
所以引入Reactor多執行緒模型!
Reactor多執行緒模型
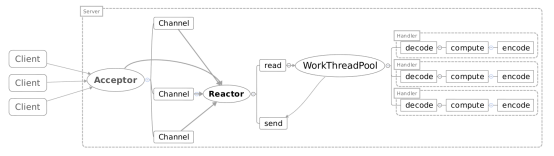
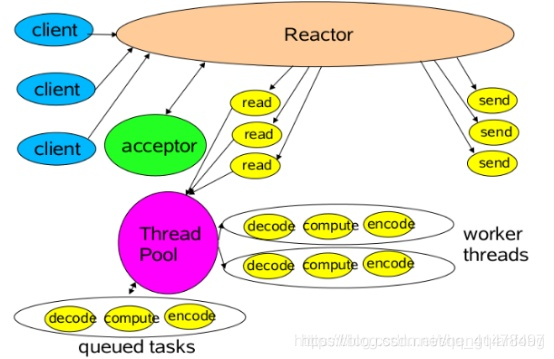
Reactor多執行緒就是把Handler中的IO操作,非IO操作分開。
操作IO的執行緒稱爲IO執行緒,操作非IO的執行緒叫做工作執行緒。
用戶端的請求(IO操作:讀取出來的數據)可以直接放進工作執行緒池(非IO操作:解碼-計算-編碼-返回)中,這樣非同步處理,用戶端發送的請求就得到返回了不會一直阻塞在Handler中。
但是當使用者進一步增加的時候,Reactor執行緒又會出現瓶頸,因爲Reactor中既有IO操作,又要響應連線請求。爲了分擔Reactor的負擔,所以引入了主從Reactor模型!
主從Reactor模型
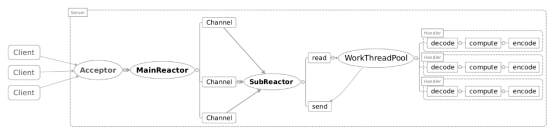
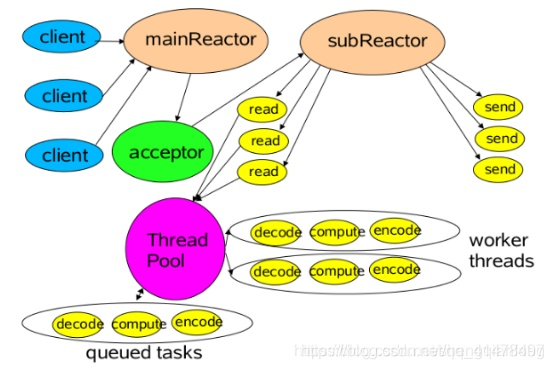
主Reactor用於響應連線請求,從Reactor用於處理IO操作請求!
特點是:伺服器端用於接收用戶端連線的不再是1個單獨的NIO執行緒(Acceptor執行緒),而是一個獨立的NIO執行緒池。
Acceptor執行緒池接收到用戶端TCP連線請求處理完成後(可能包含接入認證等),將新建立的SocketChannel註冊到I/O執行緒池(sub reactor執行緒池)的某個I/O執行緒上,由它負責SocketChannel的讀寫和編解碼工作。
Acceptor執行緒池只用於用戶端的登錄、握手和安全認證,一旦鏈路建立成功,就將鏈路註冊到後端subReactor執行緒池的I/O執行緒上,有I/O執行緒負責後續的I/O操作。
第三種模型比起第二種模型,是將Reactor分成兩部分,mainReactor負責監聽server socket,accept新連線,並將建立的socket分派給subReactor。subReactor負責多路分離已連線的socket,讀寫網 絡數據,對業務處理功能,其扔給worker執行緒池完成。通常,subReactor個數上可與CPU個數等同。
JVM Object的記憶體佈局

方法區解除安裝Class的條件
該類所有的範例已經被回收
載入該類的ClassLoader已經被回收
該類對應的java.lang.Class物件沒有任何地方被參照
Ps:方法區除了回收無用class,也回收廢棄常數,即沒有被參照常數
可以作爲GC Roots的物件包括哪些
虛擬機器棧(棧幀中的區域性變數表)中參照的變數
方法區中類靜態屬性參照的物件
方法區中常數參照的物件
本地方法棧中JNI參照的變數
JVM執行時記憶體模型
方法區、堆、虛擬機器棧、本地方法棧、程式計數器
Netty的ByteBuffer的參照計數器機制 機製
從netty的4.x版本開始,netty使用參照計數機制 機製進行部分物件的管理,通過該機制 機製netty可以很好的實現自己的共用資源池。
如果應用需要一個資源,可以從netty自己的共用資源池中獲取,新獲取的資源物件的參照計數被初始化爲1,可以通過資源物件的retain方法增加參照計數,當參照計數爲0的時候該資源物件擁有的資源將會被回收。
判斷物件是否存活的兩種方法
1 參照計數法:缺點是對回圈參照的物件無法回收
2 可達性分析
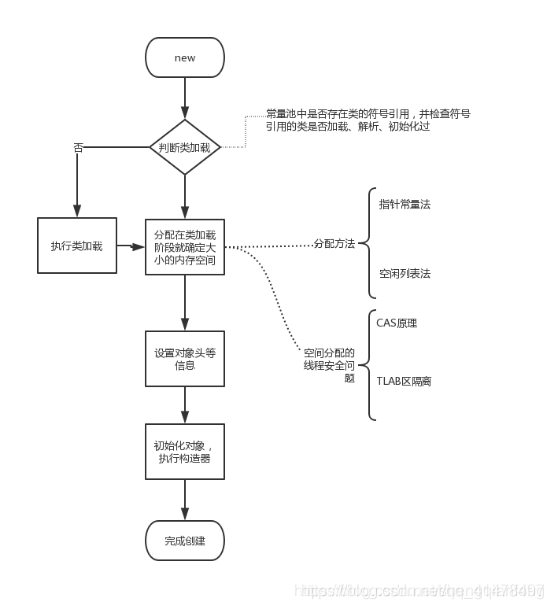
Java物件的初始化過程
類載入雙親委派模型
從上到下分三個類載入器:
BootStrap classloader:啓動類載入器,負責將Java_HOME/lib下的類庫載入到虛擬機器記憶體中,比如rt.jar
Extension classloader:擴充套件類載入器,負責將JAVA_HOME/lib/ext下的類庫載入到虛擬機器記憶體中。
Application classloader:應用程式類載入器,負責載入classpath環境變數下指定的類庫。如果程式中沒有自定義過類載入器,那麼這個就是程式中預設的類載入器。
雙親委派模型:
如果一個類載入器收到類載入的請求,它首先不會自己去嘗試載入這個類,而是把這個請求委派給父類別載入器完成。每個類載入器都是如此,只有當父載入器在自己的搜尋範圍內找不到指定的類時(即ClassNotFoundException),子載入器纔會嘗試自己去載入。
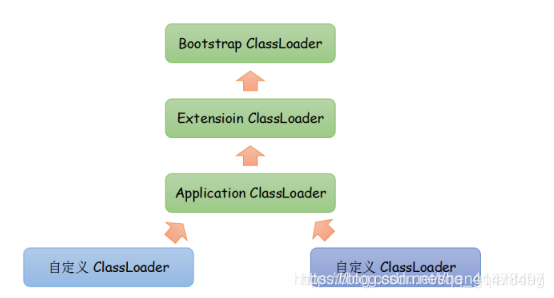
防止自定義的一些跟jdk標準庫中衝突的全限定名的類被載入,導致標準庫函數不可用。
Zookeeper
Zookeeper的常用應用場景有哪些
分佈式鎖:獲取父節點下的最小節點作爲獲得鎖的一方
命名服務:通過在zookeeper節點下建立全域性唯一的一個path
設定管理:設定放在zk上,所有應用監聽節點改變。
叢集管理:GroupMembers叢集管理,是否有機器退出和加入
Zookeeper的分佈式數據一致性演算法
ZAB原子訊息廣播協定。
一種是基於basic paxos實現的,另外一種是基於fast paxos演算法實現的。
參考:Zookeeper的核心:ZAB原子訊息廣播協定
ZAB協定定義了選舉(election)、發現(discovery)、同步(sync)、廣播(Broadcast)四個階段;
Zk啓動過程的Leader選舉分析及數據同步
參考:【分佈式】Zookeeper的Leader選舉 - leesf - 部落格園
Zookeeper數據同步的簡單描述
在ZooKeeper中所有的用戶端事務請求都由一個主伺服器也就是Leader來處理,其他伺服器爲Follower,Leader將用戶端的事務請求轉換爲事務Proposal,並且將Proposal分發給叢集中其他所有的Follower,然後Leader等待Follwer反饋,當有過半數(>=N/2+1)的Follower反饋資訊後,Leader將再次向叢集內Follower廣播Commit資訊,Commit爲將之前的Proposal提交;
ZK叢集最少需要幾臺機器?
三臺,2N+1,保證奇數,主要是爲了leader選舉演算法中的「超過半數有效(>=N/2+1)」
Zookeeper和Eureka的區別
答:ZK保證Cp,即一致性,分割區容錯性,比如當master節點因爲網路故障和其他節點失去聯繫的時候,剩餘節點會重新進行Master選舉。問題在於Master選舉的時間太長30~210s,選舉期間整個zk叢集是不可用的,這就導致選舉期間的註冊服務癱瘓。
Eureka保證Ap,高可用性,它沒有所謂主從節點概念,各節點平等。某節點掛掉不影響其他節點功能,其他節點照樣提供查詢和註冊功能。Eureka用戶端發現Eureka節點掛掉直接切換到其他正常的節點上去。只不過可能查到的數據不是最新的,也就是Eureka不保證數據的強一致性。
作爲註冊中心,推薦Eureka,因爲註冊服務更重要的是可用性。
Mysql
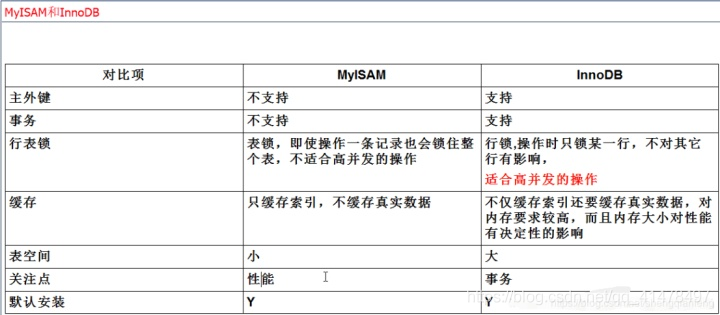
InnoDB和MyISAM儲存引擎的區別
Starting from MySQL 5.5.5, the default storage engine for new tables isInnoDB rather than MyISAM.
Btree索引和Hash索引的區別
Btree索引適合範圍查詢,Hash索引適合精確查詢
數據庫的ACID特性
數據庫事務必須具備ACID特性
原子性:Atomic,所有的操作執行成功,纔算整個事務成功
一致性:Consistency,不管事務success或fail,不能破壞關係數據的完整性以及業務邏輯上的一致性
隔離性:Isolation,每個事務擁有獨立數據空間,多個事務的數據修改相互隔離。事務檢視數據更新時,數據要麼是另一個事務修改前的狀態,要麼是修改後狀態,不應該檢視到中間狀態數據。
永續性:Durability,事務執行成功,數據必須永久儲存。重新啓動DB,數據需要恢復到事務執行成功後的狀態。
原子性、一致性、永續性DBMS通過日誌來實現。
隔離性DBMS通過鎖來實現
Mysql數據庫的隔離級別
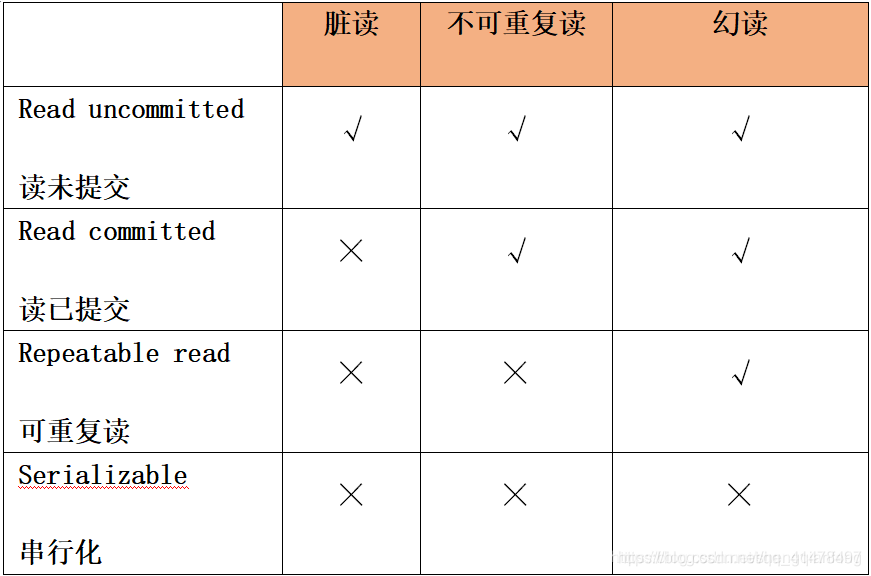
Select For Update使用場景
select for update 的使用場景,爲了避免自己看到的數據並不是數據庫儲存的最新數據並且看到的數據只能由自己修改,需要用 for update 來限制。
分佈式事務模型之XA和TCC的區別和聯繫?
XA-DTP模型
最早的分佈式事務模型是 X/Open 國際聯盟提出的 X/Open Distributed Transaction Processing(DTP)模型,也就是大家常說的 X/Open XA 協定,簡稱XA 協定。
DTP 模型中包含一個全域性事務管理器(TM,Transaction Manager)和多個資源管理器(RM,Resource Manager)。全域性事務管理器負責管理全域性事務狀態與參與的資源,協同資源一起提交或回滾;資源管理器則負責具體的資源操作。
TCC模型
TCC(Try-Confirm-Cancel)分佈式事務模型相對於 XA 等傳統模型,其特徵在於它不依賴資源管理器(RM)對分佈式事務的支援,而是通過對業務邏輯的分解來實現分佈式事務。
Try-Confirm-Cancel
Try 操作對應2PC 的一階段準備(Prepare);Confirm 對應 2PC 的二階段提交(Commit),Cancel 對應 2PC 的二階段回滾(Rollback),可以說 TCC 就是應用層的 2PC。
Mysql-binlog日誌複製方式
①基於段的複製
記錄的是執行的語句
②基於行的複製
記錄是表中每一行的操作
③混合複製
mysql主從複製原理
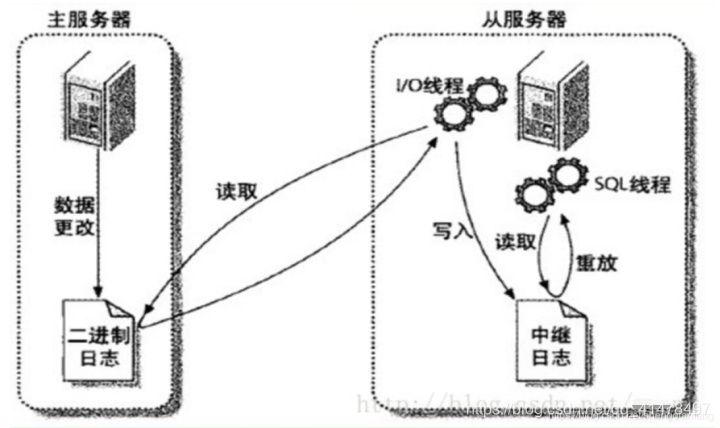
從伺服器的IO執行緒讀取主伺服器的二進制日誌變更,寫入到中繼日誌relaylog中,如果IO執行緒追趕上了主伺服器的日誌,則進入sleep狀態,直到主伺服器發送喚醒信號,從伺服器上的SQL執行緒重放relaylog中的日誌。
基於日誌點的複製和GTID的複製有何區別?
基於日誌點的複製:從主伺服器的哪個二進制日誌的偏移量進行增量同步,如果指定錯誤會造成遺漏或重複。
基於GTID的複製:從伺服器會告訴主伺服器,已經在從伺服器上已經執行完了哪些gtid值,然後主庫會把從庫未執行的事務gtid值發送給從庫執行。同一個事務只在指定的從庫上執行一次。
Mysql效能診斷和優化
聚簇索引和非聚簇索引的區別
聚簇索引,就是指主索引檔案和數據檔案爲同一份檔案,聚簇索引主要用在Innodb儲存引擎中。如主鍵。B+Tree的葉子節點上的data就是數據本身。
非聚簇索引就是指B+Tree的葉子節點上的data,並不是數據本身,而是數據存放的地址
訊息佇列
消費者宕機:怎麼保證訊息佇列訊息不丟失?
比如activemq或者rabbitmq生產者訊息投遞到訊息佇列後,消費者拿到訊息後,預設是自動簽收機制 機製,訊息佇列將刪除這條訊息,但是如果僅僅是拿到但是沒有來得及處理業務邏輯時,消費者就宕機,那麼此訊息將會丟失,以後也不會再收到。
解決辦法:
消費端要設定簽收機制 機製爲手動簽收,只有當訊息最終被處理,才告訴訊息佇列已經消費,此時訊息佇列再刪除這條訊息。
MQ叢集宕機:怎麼保證訊息不丟失?
生產者投遞訊息到mq伺服器,如果不保證訊息和佇列的持久化,那麼當mq宕機時訊息將徹底丟失,所以需要對訊息做持久化儲存,可以儲存到磁碟或者數據庫中,當mq伺服器恢復時,消費端可以繼續消費mq伺服器中的訊息。
但是,比如RabbitMQ的訊息持久化,是不承諾100%的訊息不丟失的!
&emsp**;原因**:因爲有可能RabbitMQ接收到了訊息,但是還沒來得及持久化到磁碟,他自己就宕機了,這個時候訊息還是會丟失的。如果要完全100%保證寫入RabbitMQ的數據必須落地磁碟,不會丟失,需要依靠其他的機制 機製。
Spring原始碼系列
springmvc如何解決回圈依賴的問題
當使用構造器方式初始化一個bean,而且此時多個Bean之間有回圈依賴的情況,spring容器就會拋出異常!
解決辦法:初始化bean的時候(注意此時的bean必須是單例,否則不能提前暴露一個建立中的bean)使用set方法進行注入屬性,此時bean物件會先執行構造器範例化,接着將範例化後的bean放入一個map中,並提供參照。當需要通過set方式設定bean的屬性的時候,spring容器就會從map中取出被範例化的bean。比如A物件需要set注入B物件,那麼從Map中取出B物件即可。以此類推,不會出現回圈依賴的異常。
spring事務的傳播行爲和隔離級別
spring事務七個事務傳播行爲
在TransactionDefinition介面中定義了七個事務傳播行爲:
PROPAGATION_REQUIRED 如果存在一個事務,則支援當前事務。如果沒有事務則開啓一個新的事務。
PROPAGATION_SUPPORTS 如果存在一個事務,支援當前事務。如果沒有事務,則非事務的執行。但是對於事務同步的事務管理器,PROPAGATION_SUPPORTS與不使用事務有少許不同。
PROPAGATION_MANDATORY 如果已經存在一個事務,支援當前事務。如果沒有一個活動的事務,則拋出異常。
PROPAGATION_REQUIRES_NEW 總是開啓一個新的事務。如果一個事務已經存在,則將這個存在的事務掛起。
PROPAGATION_NOT_SUPPORTED 總是非事務地執行,並掛起任何存在的事務。
PROPAGATION_NEVER 總是非事務地執行,如果存在一個活動事務,則拋出異常
PROPAGATION_NESTED如果一個活動的事務存在,則執行在一個巢狀的事務中. 如果沒有活動事務, 則按TransactionDefinition.PROPAGATION_REQUIRED 屬性執行
Spring事務的五種隔離級別
在TransactionDefinition介面中定義了五個不同的事務隔離級別
ISOLATION_DEFAULT 這是一個PlatfromTransactionManager預設的隔離級別,使用數據庫預設的事務隔離級別.另外四個與JDBC的隔離級別相對應
ISOLATION_READ_UNCOMMITTED 這是事務最低的隔離級別,它充許別外一個事務可以看到這個事務未提交的數據。這種隔離級別會產生髒讀,不可重複讀和幻像讀
ISOLATION_READ_COMMITTED 保證一個事務修改的數據提交後才能 纔能被另外一個事務讀取。另外一個事務不能讀取該事務未提交的數據。這種事務隔離級別可以避免髒讀出現,但是可能會出現不可重複讀和幻像讀。
ISOLATION_REPEATABLE_READ 這種事務隔離級別可以防止髒讀,不可重複讀。但是可能出現幻像讀。它除了保證一個事務不能讀取另一個事務未提交的數據外,還保證了避免下面 下麪的情況產生(不可重複讀)。
ISOLATION_SERIALIZABLE 這是花費最高代價但是最可靠的事務隔離級別。事務被處理爲順序執行。除了防止髒讀,不可重複讀外,還避免了幻像讀。
設計模式
單例模式
1懶漢模式-非安全
懶漢模式(執行緒不安全,可能出現多個Singleton 範例)
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
2懶漢模式-安全
懶漢模式 (執行緒安全)
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
3餓漢模式
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
4餓漢模式(變種)
餓漢(變種,跟第三種差不多,都是在類初始化即範例化instance)
public class Singleton {
private Singleton instance = null;
static {
instance = new Singleton();
}
private Singleton (){}
public static Singleton getInstance() {
return this.instance;
}
}
5靜態內部類
靜態內部類,跟三四有細微差別:
Singleton類被裝載instance不一定被初始化,因爲內部類SingletonHolder沒有被主動使用,只有顯示呼叫getInstance纔會顯示裝載SingletonHolder 類,從而範例化instance
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
6列舉
列舉(既可以避免多執行緒同步問題,還可以防止被反序列化重建物件)
public enum Singleton {
INSTANCE;
public void whateverMethod() {
}
public static void main(String[] args) {
Singleton s = Singleton.INSTANCE;
Singleton s2 = Singleton.INSTANCE;
System.out.println(s==s2);
}
}
**輸出結果:**true
說明這種方式建立的物件是同一個,因爲列舉類中的INSTANCE是static final型別的,只能被範例化一次。對於Enum中每一個列舉範例,都是相當於一個單獨的Singleton範例。所以借用 《Effective Java》一書中的話,單元素的列舉型別已經成爲實現Singleton的最佳方法
7懶漢升級版
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
策略模式
JDK原始碼
ThreadLocal的實現原理
ThreadLocal的實現原理,有什麼缺點?跟執行緒池結合使用要注意什麼
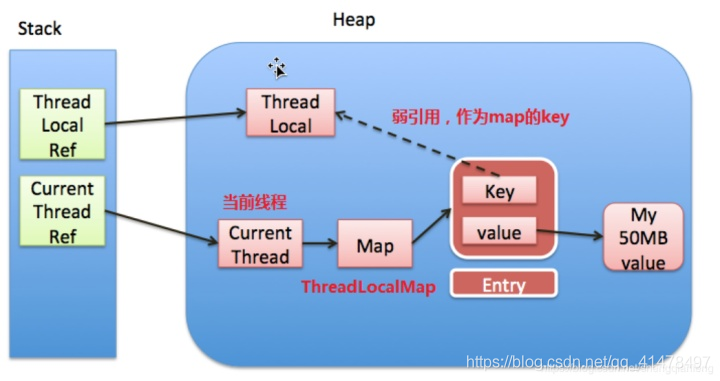
原理:Current Thread當前執行緒中有一個ThreadLocalMap物件,它的key是ThreadLocal的弱參照,Value是ThreadLocal呼叫set方法設定的物件值。每一個執行緒維護一個各自的ThreadLocalMap,所以多個執行緒之間變數相互隔離,互不幹 不乾擾。
缺點:存在記憶體漏失問題,因爲當ThreadLocal設定爲null後,ThreadLocalMap的key的弱參照指向了null,又沒有任何的強參照指向threadlocal,所以threadlocal會被GC回收掉。但是,ThreadLocalMap的Value不會被回收,CurrentThread當前執行緒的強參照指向了ThreadLocalMap,進而指向了這個Entry<key,value>,所以只有當currentThread結束強參照斷開後,currentThread、ThreadLocalMap、Entry將全部被GC回收。
所以結論是:
只要currentThread被GC回收,就不會出現記憶體漏失。
但是在currentThread被GC回收之前,threadlocal設定爲null之後的這段時間裏,Value不會被回收,比如當使用執行緒池的時候,執行緒結束不會被GC回收,會被繼續複用,那這個Value肯定還會繼續存在。如果這個Value很大的情況下,可能就會記憶體漏失。
雖然threadlocal的set和get方法執行時會清除key爲null的value,但是如果當前執行緒在使用中沒有呼叫threadlocal的set或者get方法一樣可能會記憶體漏失。
跟執行緒池結合使用的注意事項:
因爲執行緒池中執行緒複用的情況,本次的threadlocal中可能已經存在數據,所以上一次使用完threadlocal的變數後,要呼叫threadlocal的remove方法清除value。而且要注意呼叫完remove後應該保證不會再呼叫get方法。
AQS實現公平鎖和非公平鎖
基於AQS的鎖(比如ReentrantLock)原理大體是這樣:
有一個state變數,初始值爲0,假設當前執行緒爲A,每當A獲取一次鎖,status++. 釋放一次,status–.鎖會記錄當前持有的執行緒。
當A執行緒擁有鎖的時候,status>0. B執行緒嘗試獲取鎖的時候會對這個status有一個CAS(0,1)的操作,嘗試幾次失敗後就掛起執行緒,進入一個等待佇列。
如果A執行緒恰好釋放,–status==0, A執行緒會去喚醒等待佇列中第一個執行緒,即剛剛進入等待佇列的B執行緒,B執行緒被喚醒之後回去檢查這個status的值,嘗試CAS(0,1),而如果這時恰好C執行緒也嘗試去爭搶這把鎖。
非公平鎖實現:
C直接嘗試對這個status CAS(0,1)操作,併成功改變了status的值,B執行緒獲取鎖失敗,再次掛起,這就是非公平鎖,B在C之前嘗試獲取鎖,而最終是C搶到了鎖。
公平鎖:
C發現有執行緒在等待佇列,直接將自己進入等待佇列並掛起,B獲取鎖
RPC
RPC的序列化方式有哪些
Thrift—facebook
ProtoBuf—google
Hessian
JAVA原生的序列化介面
Json/xml
服務熔斷與服務降級概念
服務熔斷:
一般指某個服務的下遊服務出現問題時採用的手段,而服務降級一般是從整體層面考慮的。下遊服務出現問題時可以進行服務熔斷。
對於目標服務的請求和呼叫大量超時或失敗,這時應該熔斷該服務的所有呼叫,並且對於後續呼叫應直接返回,從而快速釋放資源,確保在目標服務不可用的這段時間內,所有對它的呼叫都是立即返回,不會阻塞的。再等到目標服務好轉後進行介面恢復。
服務降級:
當伺服器壓力劇增的情況下,根據當前業務情況及流量對一些服務和頁面有策略的降級,以此釋放伺服器資源以保證核心任務的正常執行。
其他整理
ThreadLocalMap的線性探測法、HashMap的拉鍊法。兩種解決hash碰撞的方式有何不同?
Netty的RPC如何實現
Netty中原始碼inbound和outbound有啥區別?
怎麼分庫分表可以做到多維度查詢
Fork/Join框架
JAVA執行緒執行中怎麼kill掉
1 通過設定全域性變數標誌來控制執行緒的任務執行完成.進而銷燬執行緒
2 如果執行緒處於長久的阻塞狀態,可以interrupt脫離執行緒阻塞狀態跳出程式體
HA主備怎麼預防腦裂
一般採用2個方法
仲裁:「當兩個節點出現分歧時,由第3方的仲裁者決定聽誰的。這個仲裁者,可能是一個鎖服務,一個共用盤或者其它什麼東西」。
fencing:「當不能確定某個節點的狀態時,通過fencing把對方幹掉,確保共用資源被完全釋放,前提是必須要有可靠的fence裝置」。
性別欄位是否需要加索引
1.聚集索引,葉子節點儲存行記錄,InnoDB索引和記錄是儲存在一起的。
2.普通索引,葉子節點儲存了主鍵的值。
在InnoDB引擎中每個表都會有一個聚集索引,如果表定義了主鍵,那主鍵就是聚集索引.一個表只有一個聚集索引,其餘爲普通索引.如果性別sex欄位定義爲普通的索引,那麼在使用普通索引查詢時,會先載入普通索引,通過普通索引查詢到實際行的主鍵,用主鍵通過聚集索引去查詢最終的行.
如果不對sex性別欄位加索引,那麼查詢過程就是直接全表掃描查詢到聚集索引定位到行,而不需要普通索引和聚集索引的切換,所以效率可能更高一點.
Https的SSL握手過程
Https協定由兩部分組成:http+ssl,即在http協定的基礎上增加了一層ssl的握手過程.
瀏覽器作爲發起方,向網站發送一套瀏覽器自身支援的加密規則,比如用戶端支援的加密演算法,Hash演算法,ssl版本,以及一個28位元組的亂數client_random
網站選出一套加密演算法和hash演算法,生成一個伺服器端亂數server_random並以證書的形式返回給用戶端瀏覽器,這個證書還包含網站地址、公鑰public_key、證書的頒發機構CA以及證書過期時間。
瀏覽器解析證書是否有效,如果無效則瀏覽器彈出提示框告警。如果證書有效,則根據server_random生成一個preMaster_secret和Master_secret[對談金鑰], master_secret 的生成需要 preMaster_key ,並需要 client_random 和 server_random 作爲種子。瀏覽器向伺服器發送經過public_key加密的preMaster_secret,以及對握手訊息取hash值並使用master_secret進行加密發送給網站.[用戶端握手結束通知,表示用戶端的握手階段已經結束。這一項同時也是前面發送的所有內容的hash值,用來供伺服器校驗]
伺服器使用private_key 解密後得到preMaster_secret,再根據client_random 和 server_random 作爲種子得到master_secret.然後使用master_secret解密握手訊息並計算hash值,跟瀏覽器發送的hash值對比是否一致然後把握手訊息通過master_secret進行對稱加密後返回給瀏覽器.以及把握手訊息進行hash且master_secret加密後發給瀏覽器.[伺服器握手結束通知,表示伺服器的握手階段已經結束。這一項同時也是前面發送的所有內容的hash值,用來供用戶端校驗。]
用戶端同樣可以使用master_secret進行解密得到握手訊息.校驗握手訊息的hash值是否跟伺服器發送過來的hash值一致,一致則握手結束.通訊開始
以後的通訊都是通過master_secret+對稱加密演算法的方式進行. 用戶端與伺服器進入加密通訊,就完全是使用普通的HTTP協定,只不過用"對談金鑰"加密內容。SSL握手過程中如果有任何錯誤,都會使加密連線斷開,從而阻止了隱私資訊的傳輸
非對稱加密演算法:RSA,DSA/DSS
對稱加密演算法:AES,RC4,3DES
HASH演算法:MD5,SHA1,SHA256
參考: SSL/TLS協定執行機制 機製的概述 - 阮一峯的網路日誌
select和epoll的區別
1 select有最大併發數限制,預設最大檔案控制代碼數1024,可修改。
epoll沒有最大檔案控制代碼數限制,僅受系統中進程能開啓的最大檔案控制代碼限制。
2 select效率低,每次都要線性掃描其維護的fd_set集合。
epoll只在集合不爲空才輪訓
3select存在內核空間和使用者空間的記憶體拷貝問題。
epoll中減少記憶體拷貝,mmap將使用者空間的一塊地址和內核空間的一塊地址同時對映到相同的一塊實體記憶體地址
NIO使用的多路複用器是epoll
Epoll導致的selector空輪詢
Java NIO Epoll 會導致 Selector 空輪詢,最終導致 CPU 100%
官方聲稱在 JDK 1.6 版本的 update18 修復了該問題,但是直到 JDK 1.7 版本該問題仍舊存在,只不過該 BUG 發生概率降低了一些而已,它並沒有得到根本性解決
Netty的解決方案:
對 Selector 的 select 操作週期進行統計,每完成一次空的 select 操作進行一次計數,若在某個週期內連續發生 N 次空輪詢,則判斷觸發了 Epoll 死回圈 Bug。
然後,Netty 重建 Selector 來解決。判斷是否是其他執行緒發起的重建請求,若不是則將原 SocketChannel 從舊的 Selector 上取消註冊,然後重新註冊到新的 Selector 上,最後將原來的 Selector 關閉。
正排索引和倒排索引
正排索引
也叫正向索引,正排表是以document文件的ID爲關鍵字,記錄了document文件中所有的關鍵字keyword的資訊,所以在查詢某個keyword的時候,會掃描正排表中每個document文件,直到查出所有包含keyword的文件。
圖示:
倒排索引
也叫反向索引,倒排表示以keyword關鍵字建立索引,關鍵詞keyword所對應的的表項記錄了出現這個keyword的所有文件。表項包含了該文件的ID和在該文件中出現的位置情況。
倒排表一次可以查出keyword關鍵字對應的所有文件,效率高於正排表。
正排索引是從文件到關鍵字的對映(已知文件求關鍵字)
倒排索引是從關鍵字到文件的對映(已知關鍵字求文件)
轉載:https://www.zhihu.com/tardis/sogou/art/100714892
轉載:https://www.zhihu.com/tardis/sogou/art/66160652