【UNIX/Liux】標準I/O庫【Part 1】
本文是筆者拜讀《UNIX環境高階程式設計》第5章(標準I/O庫)的學習筆記。本文的主要內容包括檔案流、FILE指針、緩衝、讀寫流、各種I/O的效率。文中不僅包含書中的知識點,也包括筆者的理解。
以UNIX爲例,操作系統的體系結構如下圖所示:
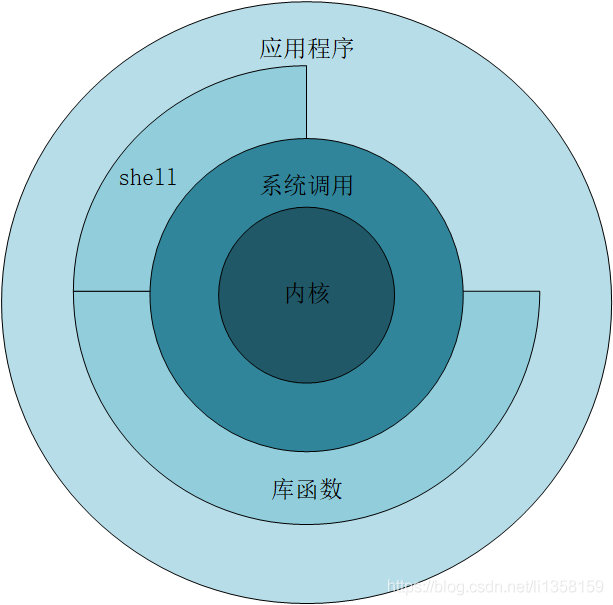
shell是一個特殊的應用程式,爲執行其他應用程式提供介面。系統呼叫和庫函數是應用程式存取內核的介面,前面兩章介紹的函數大都屬於系統呼叫,如open、read、write和lstat。
庫函數是對系統呼叫的封裝,更便於使用者使用。其中的標準I/O庫由ISO C標準所定義,該標準庫也移植到了UNIX之外的很多系統中。標準I/O庫處理了很多細節,如緩衝區分配、以優化的塊長度執行I/O等。這些處理使使用者不必擔心如何選擇正確的塊長度。
在使用
man命令查詢函數時,選項2表示系統呼叫,3表示庫函數。
流和FILE物件
標準I/O是圍繞流(stream)而不是檔案描述符進行的。當用標準I/O庫開啓或建立一個檔案時,使一個流與一個檔案相關聯。
標準I/O檔案流可用於單位元組或多位元組(寬)字元集。流的定向決定了所讀寫的字元是單位元組(位元組定向)還是多位元組(寬定向)。一個流剛被建立時,沒有定向。fwide函數用於設定流的定向,freopen函數清除一個流的定向。

如果mode參數值爲負,將指定流設定爲位元組定向。
如果mode參數值爲正,將指定流設定爲寬定向。
如果mode值爲0,不設定流的定向,返回標識該流定向的值。
fwide不改變已定向流的定向,且無出錯返回。
fopen函數返回一個FILE物件的指針,FILE物件包含了標準I/O庫爲管理該流所需要的所有資訊:檔案描述符、流緩衝區地址、緩衝區長度、緩衝區中的字元數、出錯標誌等。我們稱FILE*爲檔案指針。
在前面幾篇部落格裏,筆者將檔案偏移量也稱爲檔案指針。筆者把系統呼叫和庫函數裡的相關概念搞混了,表示抱歉。
標準輸入、標準輸出和標準錯誤
| 檔案描述符 | 檔案指針 | 說明 |
|---|---|---|
STDIN_FILENO |
stdin |
標準輸入 |
STDOUT_FILENO |
stdout |
標準輸出 |
STDERR_FILENO |
stderr |
標準錯誤 |
以上3個檔案指針定義在了標頭檔案<stdio.h>中。
緩衝
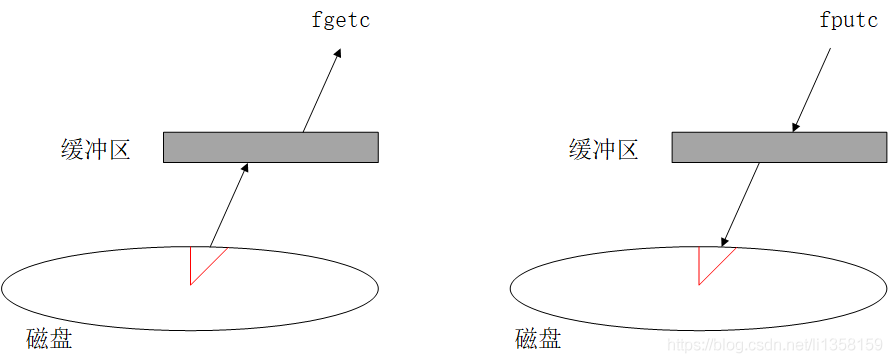
標準I/O庫提供緩衝的目的是儘可能減少read和write的呼叫次數(即減少存取內核的次數)。如下圖所示,進程每次讀/寫磁碟時,首先存取緩衝區,如果無法完成期望的行爲,才存取真正的磁碟。
標準I/O提供了3種類型的緩衝。
(1) 全緩衝。在標準I/O緩衝區被填滿後才進行實際的I/O操作。對於駐留在磁碟上的檔案通常是由標準I/O庫實施全緩衝的。(呼叫malloc獲得緩衝區)
沖洗(flush)說的是標準I/O緩衝區的寫操作。函數fflush可以沖洗一個流(有的編譯器不支援)。在標準I/O庫方面,沖洗指的是將緩衝區裡的內容寫到磁碟(不管緩衝區有沒有滿);在終端驅動程式方面,沖洗表示丟棄已儲存在緩衝區中的數據。
沖洗緩衝區:要麼把緩衝區裡的數據用掉,要麼刪掉。
(2) 行緩衝。在輸入和輸出中遇到換行符時,執行實際的I/O操作。標準輸入/輸出使用的是行緩衝。行緩衝的限制:
a.緩衝區的長度是固定的,只要填滿了緩衝區,即使沒遇到換行符,也會進行I/O操作。
b.任何時候只要通過標準I/O庫要求從一個不帶緩衝的流m,或者一個行緩衝的流n(從內核請求數據)得到數據,那麼就會沖洗相應的行緩衝輸出流。
在輸入數據來到緩衝區前,要衝洗緩衝區中的輸出數據。輸入/輸出共用一個緩衝區。
(3) 不帶緩衝。標準I/O庫不對字元進行緩衝儲存。標準錯誤流stderr通常是不帶緩衝的。
很多系統預設使用以下型別的緩衝:
(1) 標準錯誤流不帶緩衝。
(2) 如果流(除了標準錯誤流)指向的是終端裝置,則行緩衝的,否則全緩衝。
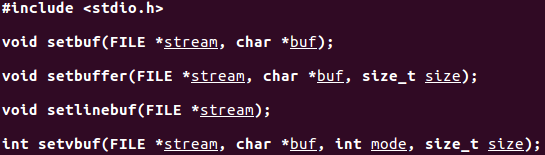
更換緩衝型別的函數:
成功返回0,出錯返回非0.
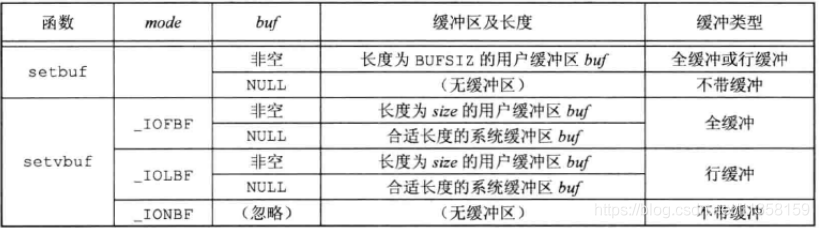
setbuf開啓或關閉緩衝機制 機製。buf爲NULL時,關閉緩衝。buf指向一個長度爲BUFSIZ的緩衝區時,設定爲全緩衝或行緩衝。
使用setvbuf可以精確地說明緩衝型別,如果指定不帶緩衝,則忽略buf和size,否則buf和size可選擇地指定緩衝區的地址和長度。一般而言,應由系統選擇緩衝區的長度並自動分配緩衝區。
fflush可強制沖洗一個流。此函數使該流所有未寫的數據都被傳送至內核。如果stream是 NULL,則沖洗所有輸出流。
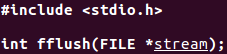
開啓流
以下函數開啓一個標準I/O流:
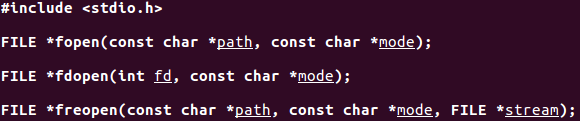
fopen:開啓路徑名爲path的指定檔案。
fdopen:從一個已有的檔案描述符上開啓檔案,使一個檔案指針和該描述符相關聯。此函數常用於由建立管道和網路通訊通道函數返回的描述符,因爲一開始只能直接使用檔案描述符存取這些特殊檔案。
freopen:在一個指定的流上開啓一個指定的檔案。如果流已經開啓,則先關閉它。若流已經定向,則清除定向。此函數一般用於將一個指定的檔案開啓爲一個預定義的流:標準輸入、標準輸出或標準錯誤流。
使
stream和path關聯起來,並返回stream。
mode參數指定了對流的讀寫方式,該參數和open函數的標誌對應。
mode |
open標誌 |
|---|---|
r或rb |
O_RDONLY |
w或wb |
O_WRONLY | O_CREAT | O_TRUNC |
a或ab |
O_WRONLY | O_CREAT | O_APPEND |
r+或r+b或rb+ |
O_RDWR |
w+或w+b或wb+ |
O_RDWR | O_CREAT | O_TRUNC |
a+或a+b或ab+ |
O_RDWR | O_CREAT | O_APPEND |
fopen函數區分了文字檔案和二進制檔案,而open函數將它們都看做普通檔案。
使用fdopen時,因爲檔案已經被開啓,所以以寫方式開啓檔案時不截斷檔案,以追加方式開啓時也不能建立該檔案。
當以讀和寫方式開啓一個檔案時,具有以下限制:
(1)如果中間沒有fflush、fseek、fsetpos或rewind,則在輸出的後面不能直接跟隨輸入。
(2)如果中間沒有fseek、fsetpos或rewind,或者一個輸入操作沒有到達檔案尾端,則在輸入操作之後不能直接跟隨輸出。
說到底,是因爲讀和寫共用一個緩衝區,要避免讀和寫數據混合儲存在緩衝區裡。
| 限制 | r |
w |
a |
r+ |
w+ |
a+ |
|---|---|---|---|---|---|---|
| 檔案必須已存在 | + | + | ||||
| 放棄檔案以前的內容 | + | + | ||||
| 流可以讀 | + | + | + | + | ||
| 流可以寫 | + | + | + | + | + | |
| 流只可在尾端處寫 | + | + |
在指定w和a型別建立一個新檔案時,我們無法說明該檔案的許可權位。POSIX要求實現使用如下的許可權位來建立檔案:
S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH
預設許可權?我們可以通過
umask函數遮蔽一些許可權。
fclose關閉一個開啓的流。
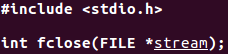
在該流被關閉之前,會自動沖洗緩衝區的輸出數據,緩衝區中的輸入數據被丟棄。如果標準I/O庫自動爲該流分配了一個緩衝區,則釋放緩衝區。
當一個進程正常終止時,所有緩衝區裡的輸出數據被沖洗,所有I/O流被關閉。
***例: ***
fopen和freopen的一般使用。
// test.c
#include <stdio.h>
int main() {
FILE *fp = fopen("./t1.txt", "w+");
fputs("hello t1.txt\n", fp);
fp = freopen("./t2.txt", "w+", fp);
fputs("hello t2.txt\n", fp);
fclose(fp);
return 0;
}
執行結果:

讀和寫流
一旦打開了流,則可在3種不同類型的非格式化I/O種進行選擇,對其進行讀、寫操作。
(1)每次一個字元的I/O。一次讀寫一個字元,如fgetc,fputc。如果流是帶緩衝的,則標準I/O函數處理緩衝。
(2)每次一行的I/O。一次讀寫一行,以一個換行符終止,如fgets、fputs。
(3)直接I/O,有時被稱爲二進制I/O。每次讀寫一定數量的數據,如fread和fwrite。

nmemb是數據項的個數,size是每個數據項的大小(單位是位元組)。
以上的都是非格式化
I/O,格式化I/O包括printf、scanf。
輸入函數
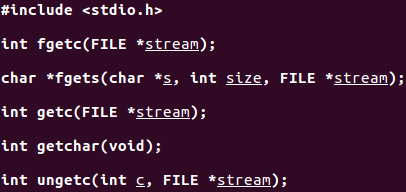
getchar()相當於getc(stdin)。
getc可以被實現爲宏,fgetc不能實現爲宏。這意味着:
(1) getc的參數不應當是具有副作用的表達式,因爲它可能會被計算多次。
(2) fgetc是一個函數,可以取到其地址。
(3) 呼叫函數fgetc所需的時間通常長於呼叫宏getc。
呼叫fgets時,應說明能處理的最大行長。
從流中讀取數據後,可以呼叫ungetc將字元再壓送迴流中。並沒有將壓送字元寫到底層檔案或裝置中,只是將它寫回了標準I/O緩衝區中。
呼叫一次
ungetc相當於將檔案偏移量前移了1位。
例:
測試ungetc的功能。
// test.c
#include <stdio.h>
int main() {
FILE *fp = fopen("./t.txt", "a+");
int c = fgetc(fp);
printf("%c\n", c);
c = fgetc(fp);
printf("%c\n", c);
c = ungetc(c, fp);
c = fgetc(fp);
printf("%c\n", c);
fclose(fp);
return 0;
}
執行結果如下:
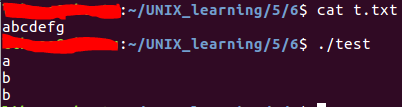
getchar、getc、fgetc在返回一個字元時,將讀到的unsigned char型別數據轉換爲int型別。常數EOF(-1)表示讀出錯或者是到了檔案末尾,爲了區分這兩種不同的情況,需要呼叫ferror或feof。
每個流在FILE物件種維護了兩個標誌:出錯標誌;檔案結束標誌。呼叫clearerr可以清除這兩個標誌。
輸出函數
輸出函數與上面的輸入函數對應。putchar(c)等同於fputc(c, stdout)。putc可被實現爲宏,fputc不能實現爲宏。
每次一行I/O
fgets和gets提供每次讀取一行的功能。gets從標準輸入讀,fgets從指定流讀。


對於fgets,必須指定緩衝長度size,此函數一直讀到'\n'爲止,以'\0'結尾。如果該行包括最後一個換行符的字元數超過了size-1,則會讀到一個不完整的行,對fgets的下一次呼叫會繼續讀該行。
gets不將'\n'存入緩衝區。不推薦使用gets,因爲可能會引起緩衝區溢位。
fputs和puts提供輸出一行的功能。
fputs和puts均將一個以'\0'作爲終止符的字串寫到指定流或標準輸出中,不列印'\0'本身。不同的是,puts會自動追加一個'\n',因此請儘量避免使用puts。
在
I/O系統呼叫的API中,檔案描述符通常是第一個參數。
在標準I/O庫的API中,流指針通常是最後一個參數。
標準I/O的效率
下面 下麪三個程式將標準輸入複製到了標準輸出。
a. 每次一個字元 I/O
// copy1.c
#include <stdio.h>
int main() {
int c;
while ((c = fgetc(stdin)) != EOF) {
if (fputc(c, stdout) != c) {
perror("fputc error");
return -1;
}
}
return 0;
}
b. 每次一行字元 I/O
// copy2.c
#include <stdio.h>
#define N 1024
int main() {
char buf[N];
while (fgets(buf, N, stdin)) {
if (!fputs(buf, stdout)) {
perror("fputs error");
return -1;
}
}
return 0;
}
c. 直接系統呼叫 I/O
// copy3.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define N 4096
int main() {
char buf[N];
int wNum;
int rNum;
while ((rNum = read(STDIN_FILENO, buf, N)) > 0) {
if ((wNum = write(STDOUT_FILENO, buf, rNum)) != rNum) {
perror("write error");
return -1;
}
}
if (rNum == -1) {
perror("read error");
}
return 0;
}
a和b使用的是庫函數,c使用的是系統呼叫。對測試結果進行分析:
(1) a的使用者CPU時間最長,因爲它每讀一個字元都要執行一次回圈;b次之,回圈的次數至少和檔案中'\n'的數量相當。c的最短,可以設定程式,使其每次最多讀一個磁碟塊大小的數據,回圈次數最少。
(2) 三者的系統CPU時間幾乎相同,因爲所有這些程式對內核提出的讀、寫請求數基本相同。
(3) 三者的時鐘時間差主要來源於使用者CPU時間差和等待I/O結束所消耗的時間差。
(4) a和b是帶緩衝的I/O,緩衝區的大小是系統的預設值;而c不帶緩衝。這就意味着,當c中的N被使用者指定的很小時,效率會極低,因爲每次I/O都要存取內核,而不是直接讀寫緩衝區。
綜合來看,標準I/O庫與read和write相比並不慢很多。對大多數比較複雜的應用程式而言,使用者CPU時間的主要部分是應用程式本身的各種數據處理,而不是I/O例程。