[西柚仔]ElasticSearch的IK分詞器詳細安裝教學及使用實操
1. IK分詞器
NOTE: 預設ES中採用標準分詞器進行分詞,這種方式並不適用於中文網站,因此需要修改ES對中文友好分詞,從而達到更佳的搜尋的效果。
1.1 線上安裝IK
線上安裝IK (v5.5.1版本後開始支援線上安裝 )
# 0.必須將es服務中原始數據刪除
- 進入es安裝目錄中將data目錄數據刪除
rm -rf data
# 1. 在es安裝目錄中執行如下命令
[es@linux elasticsearch-6.2.4]$ ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.0/elasticsearch-analysis-ik-6.8.0.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
[=================================================] 100%
-> Installed analysis-ik
[es@linux elasticsearch-6.2.4]$ ls plugins/
analysis-ik
[es@linux elasticsearch-6.2.4]$ cd plugins/analysis-ik/
[es@linux analysis-ik]$ ls
commons-codec-1.9.jar elasticsearch-analysis-ik-6.2.4.jar httpcore-4.4.4.jar
commons-logging-1.2.jar httpclient-4.5.2.jar plugin-descriptor.properties
# 2. 重新啓動es生效
# 3.測試ik安裝成功
GET /_analyze
{
"text": "中華人民共和國國歌",
"analyzer": "ik_smart"
}
# 4.線上安裝IK組態檔
- es安裝目錄中config目錄analysis-ik/IKAnalyzer.cfg.xml
NOTE: 要求版本嚴格與當前使用版本一致,如需使用其他版本替換
6.2.4爲使用的版本號
1.2 本地安裝IK
可以將對應的IK分詞器下載到本地,然後再安裝 NOTE: 本課程使用本地安裝
# 1. 下載對應版本
- [es@linux ~]$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
# 2. 解壓
- [es@linux ~]$ unzip elasticsearch-analysis-ik-6.2.4.zip #先使用yum install -y unzip
# 3. 移動到es安裝目錄的plugins目錄中
- [es@linux ~]$ ls elasticsearch-6.2.4/plugins/
[es@linux ~]$ mv elasticsearch elasticsearch-6.2.4/plugins/
[es@linux ~]$ ls elasticsearch-6.2.4/plugins/
elasticsearch
[es@linux ~]$ ls elasticsearch-6.2.4/plugins/elasticsearch/
commons-codec-1.9.jar config httpclient-4.5.2.jar plugin-descriptor.properties
commons-logging-1.2.jar elasticsearch-analysis-ik-6.2.4.jar httpcore-4.4.4.jar
# 4. 重新啓動es生效
# 5. 本地安裝ik設定目錄爲
- es安裝目錄中/plugins/analysis-ik/config/IKAnalyzer.cfg.xml
1.3 測試IK分詞器
NOTE: IK分詞器提供了兩種mapping型別用來做文件的分詞分別是
ik_max_word和ik_smart
ik_max_word 和 ik_smart 什麼區別?
ik_max_word: 會將文字做最細粒度的拆分,比如會將「中華人民共和國國歌」拆分爲「中華人民共和國,中華人民,中華,華人,人民共和國,人民,人,民,共和國,共和,和,國國,國歌」,會窮盡各種可能的組合;
ik_smart: 會做最粗粒度的拆分,比如會將「中華人民共和國國歌」拆分爲「中華人民共和國,國歌」。
測試數據
DELETE /ems
PUT /ems
{
"mappings":{
"emp":{
"properties":{
"name":{
"type":"text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"age":{
"type":"integer"
},
"bir":{
"type":"date"
},
"content":{
"type":"text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"address":{
"type":"keyword"
}
}
}
}
}
PUT /ems/emp/_bulk
{"index":{}}
{"name":"小黑","age":23,"bir":"2012-12-12","content":"爲開發團隊選擇一款優秀的MVC框架是件難事兒,在衆多可行的方案中決擇需要很高的經驗和水平","address":"北京"}
{"index":{}}
{"name":"王小黑","age":24,"bir":"2012-12-12","content":"Spring 框架是一個分層架構,由 7 個定義良好的模組組成。Spring 模組構建在覈心容器之上,核心容器定義了建立、設定和管理 bean 的方式","address":"上海"}
{"index":{}}
{"name":"張小五","age":8,"bir":"2012-12-12","content":"Spring Cloud 作爲Java 語言的微服務架構,它依賴於Spring Boot,有快速開發、持續交付和容易部署等特點。Spring Cloud 的元件非常多,涉及微服務的方方面面,井在開源社羣Spring 和Netflix 、Pivotal 兩大公司的推動下越來越完善","address":"無錫"}
{"index":{}}
{"name":"win7","age":9,"bir":"2012-12-12","content":"Spring的目標是致力於全方位的簡化Java開發。 這勢必引出更多的解釋, Spring是如何簡化Java開發的?","address":"南京"}
{"index":{}}
{"name":"梅超風","age":43,"bir":"2012-12-12","content":"Redis是一個開源的使用ANSI C語言編寫、支援網路、可基於記憶體亦可持久化的日誌型、Key-Value數據庫,並提供多種語言的API","address":"杭州"}
{"index":{}}
{"name":"張無忌","age":59,"bir":"2012-12-12","content":"ElasticSearch是一個基於Lucene的搜尋伺服器。它提供了一個分佈式多使用者能力的全文搜尋引擎,基於RESTful web介面","address":"北京"}
GET /ems/emp/_search
{
"query":{
"term":{
"content":"框架"
}
},
"highlight": {
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"],
"fields": {
"*":{}
}
}
}
1.4 設定擴充套件詞
IK支援自定義
擴充套件詞典和停用詞典,所謂**擴充套件詞典就是有些詞並不是關鍵詞,但是也希望被ES用來作爲檢索的關鍵詞,可以將這些詞加入擴充套件詞典。停用詞典**就是有些詞是關鍵詞,但是出於業務場景不想使用這些關鍵詞被檢索到,可以將這些詞放入停用詞典。如何定義擴充套件詞典和停用詞典可以修改IK分詞器中
config目錄中IKAnalyzer.cfg.xml這個檔案。NOTE:詞典的編碼必須爲UTF-8,否則無法生效
1. 修改vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴充套件設定</comment>
<!--使用者可以在這裏設定自己的擴充套件字典 -->
<entry key="ext_dict">ext_dict.dic</entry>
<!--使用者可以在這裏設定自己的擴充套件停止詞字典-->
<entry key="ext_stopwords">ext_stopword.dic</entry>
</properties>
2. 在ik分詞器目錄下config目錄中建立ext_dict.dic檔案 編碼一定要爲UTF-8才能 纔能生效
vim ext_dict.dic 加入擴充套件詞即可
3. 在ik分詞器目錄下config目錄中建立ext_stopword.dic檔案
vim ext_stopword.dic 加入停用詞即可
4.重新啓動es生效
1.5 新增擴充套件詞測試
- 建立ext_dict.dic和ext_stopword.dic檔案

- 設定前
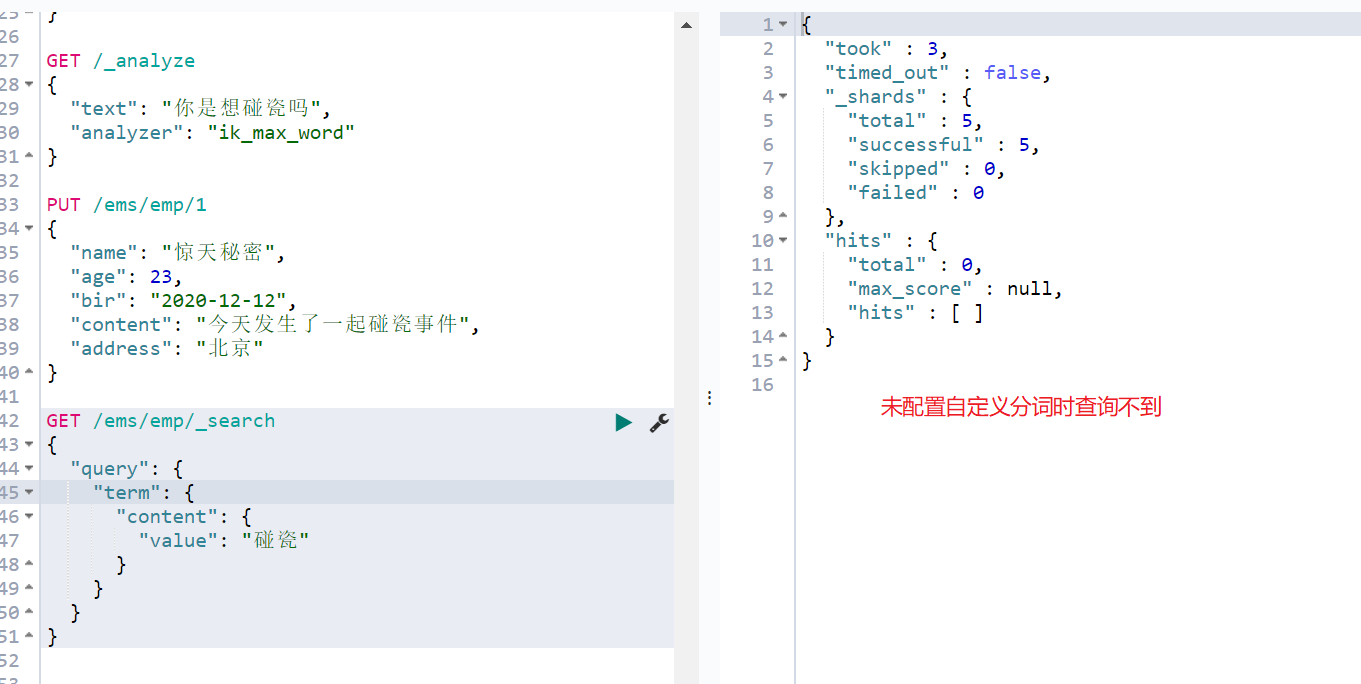
- 新增分詞
- 重新啓動ElasticSearch後測試
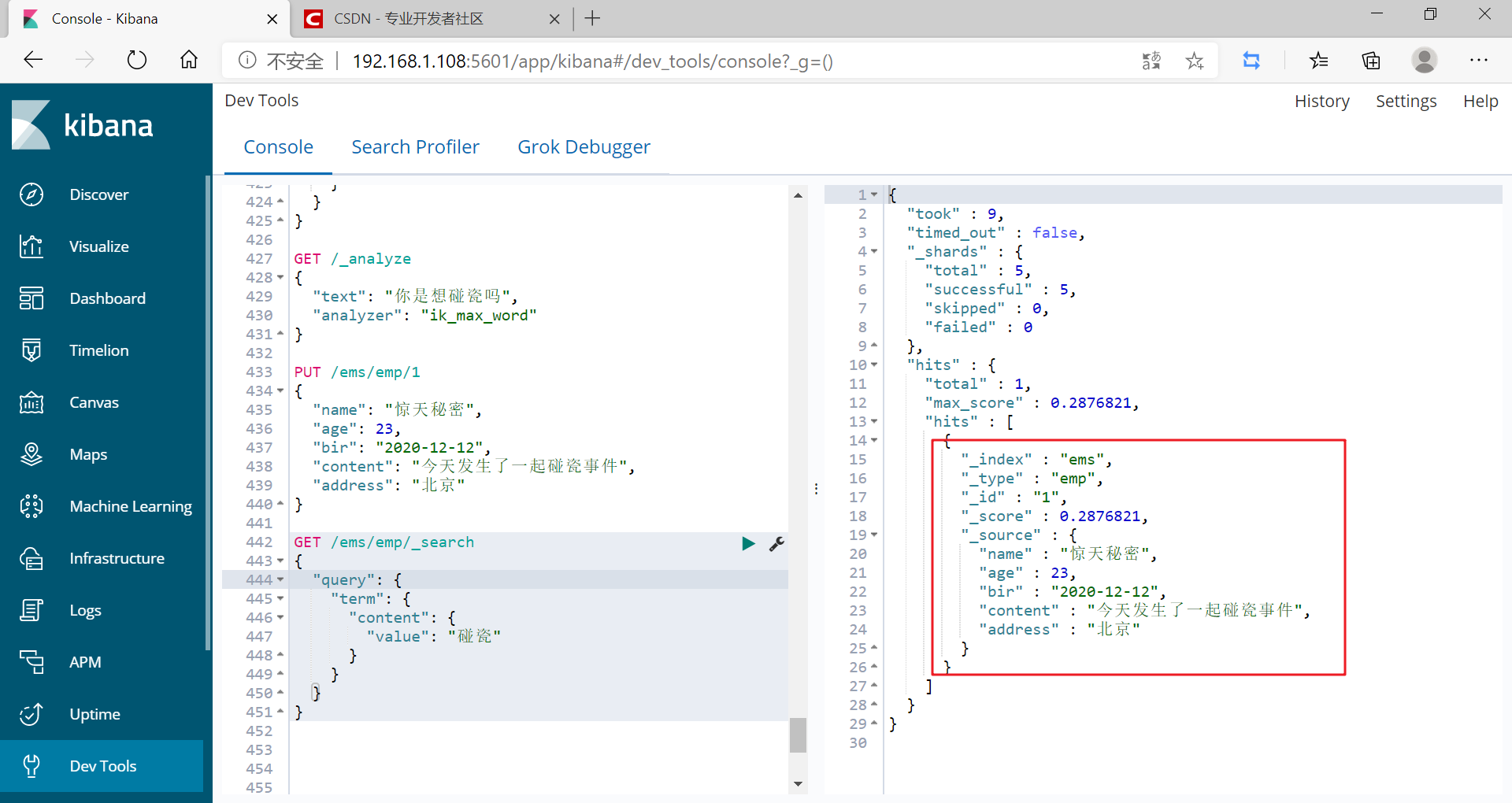
- 程式碼
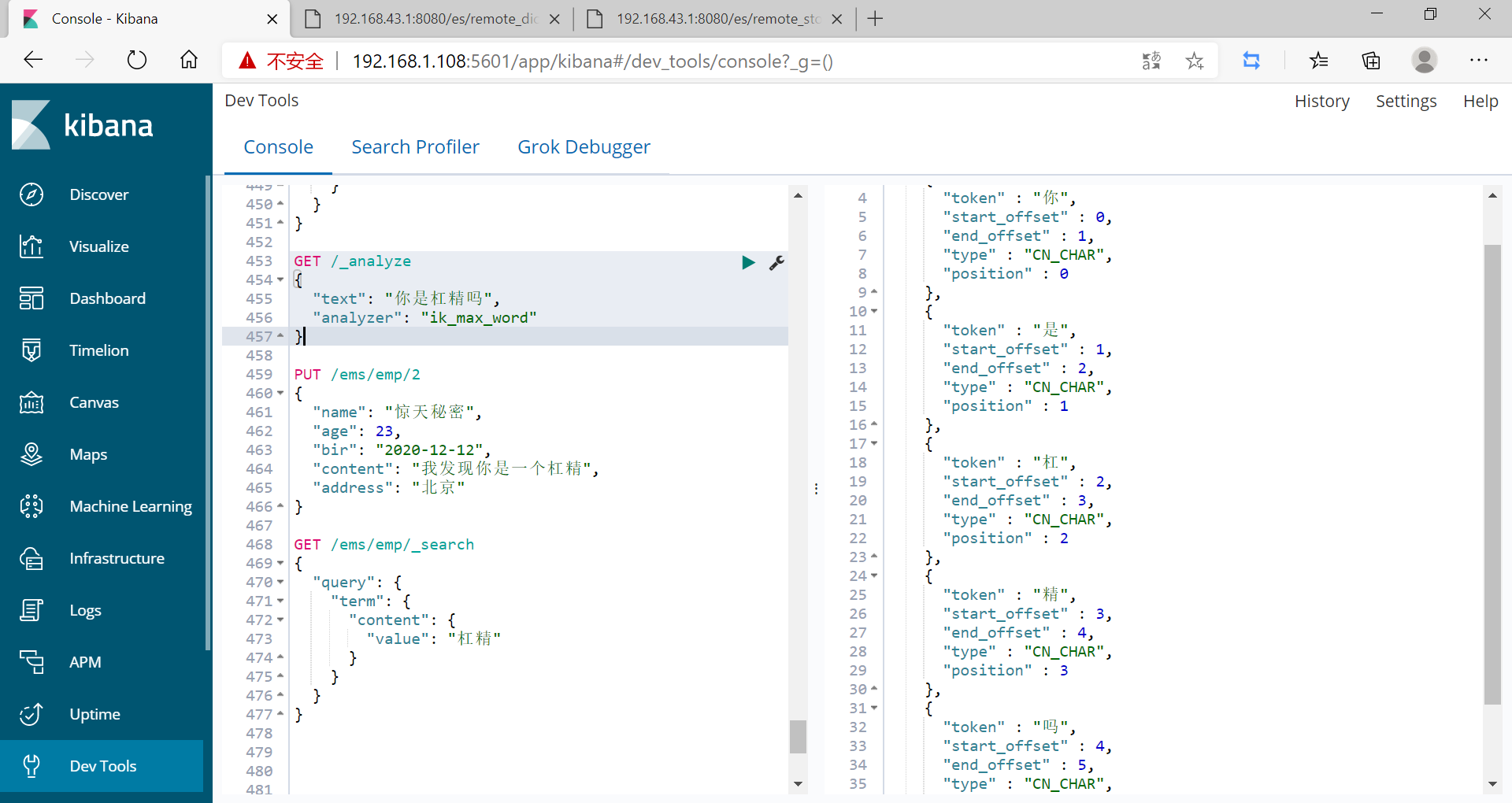
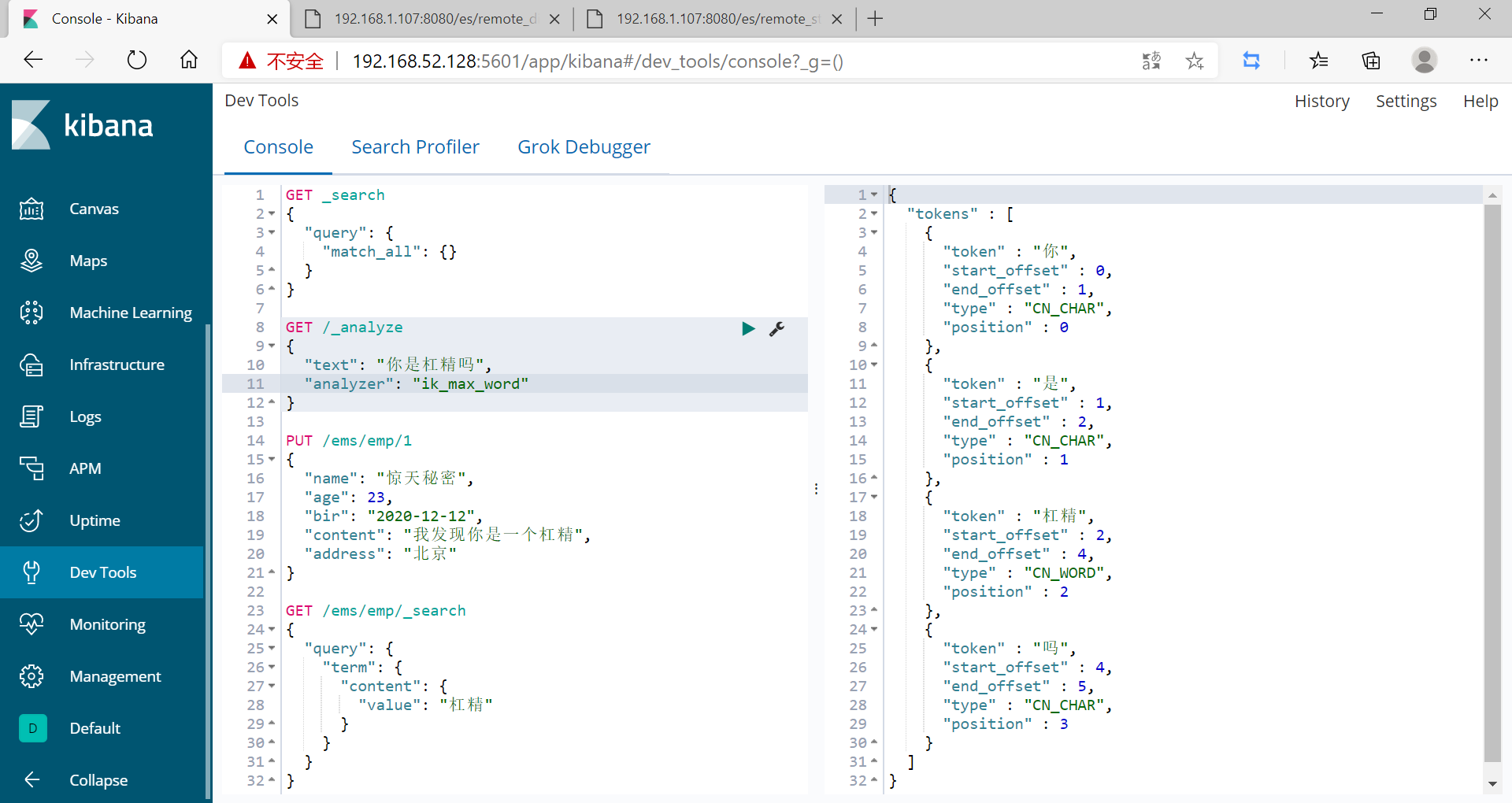
GET /_analyze
{
"text": "你是想碰瓷嗎",
"analyzer": "ik_max_word"
}
PUT /ems/emp/1
{
"name": "驚天祕密",
"age": 23,
"bir": "2020-12-12",
"content": "今天發生了一起碰瓷事件",
"address": "北京"
}
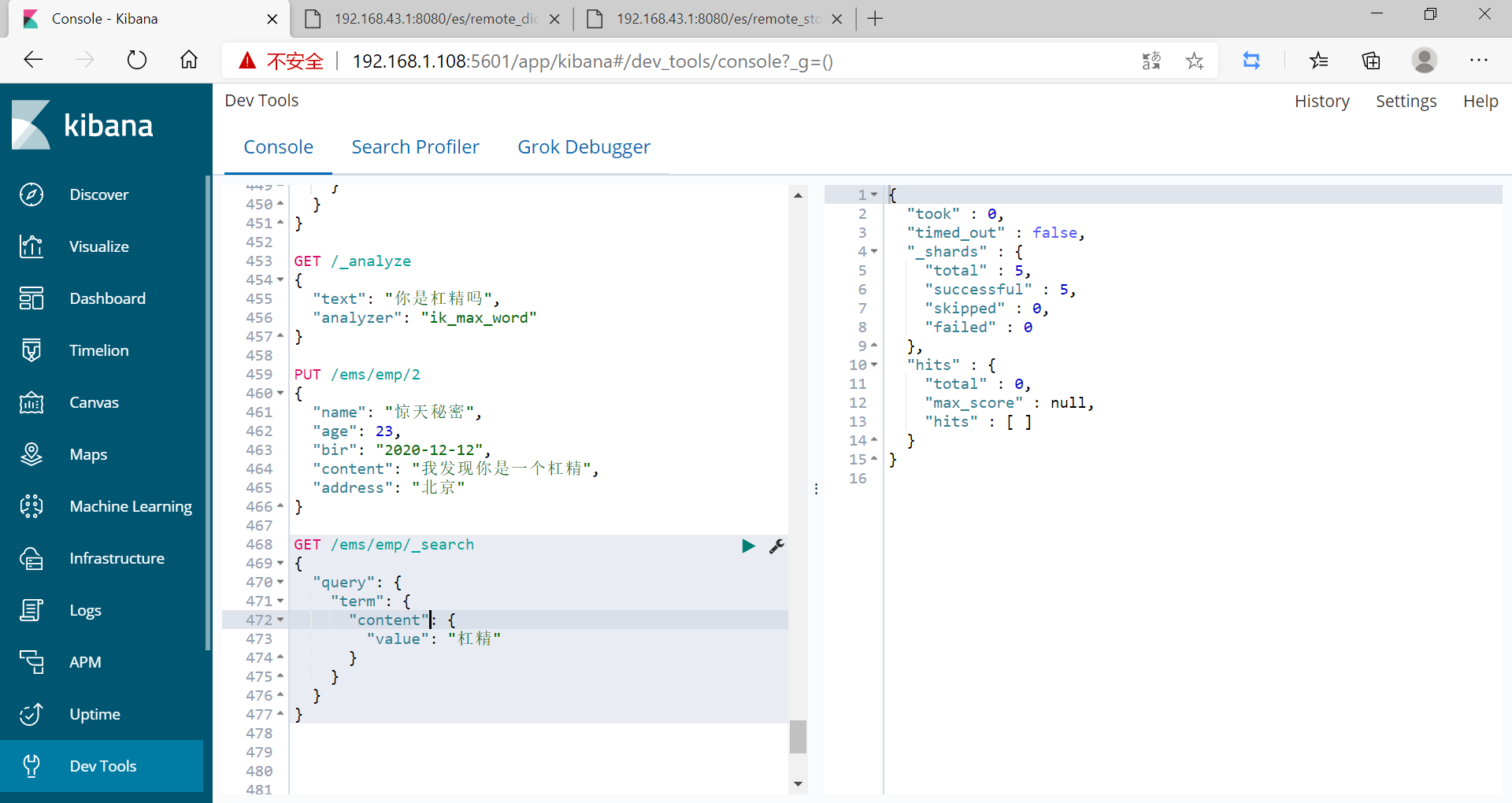
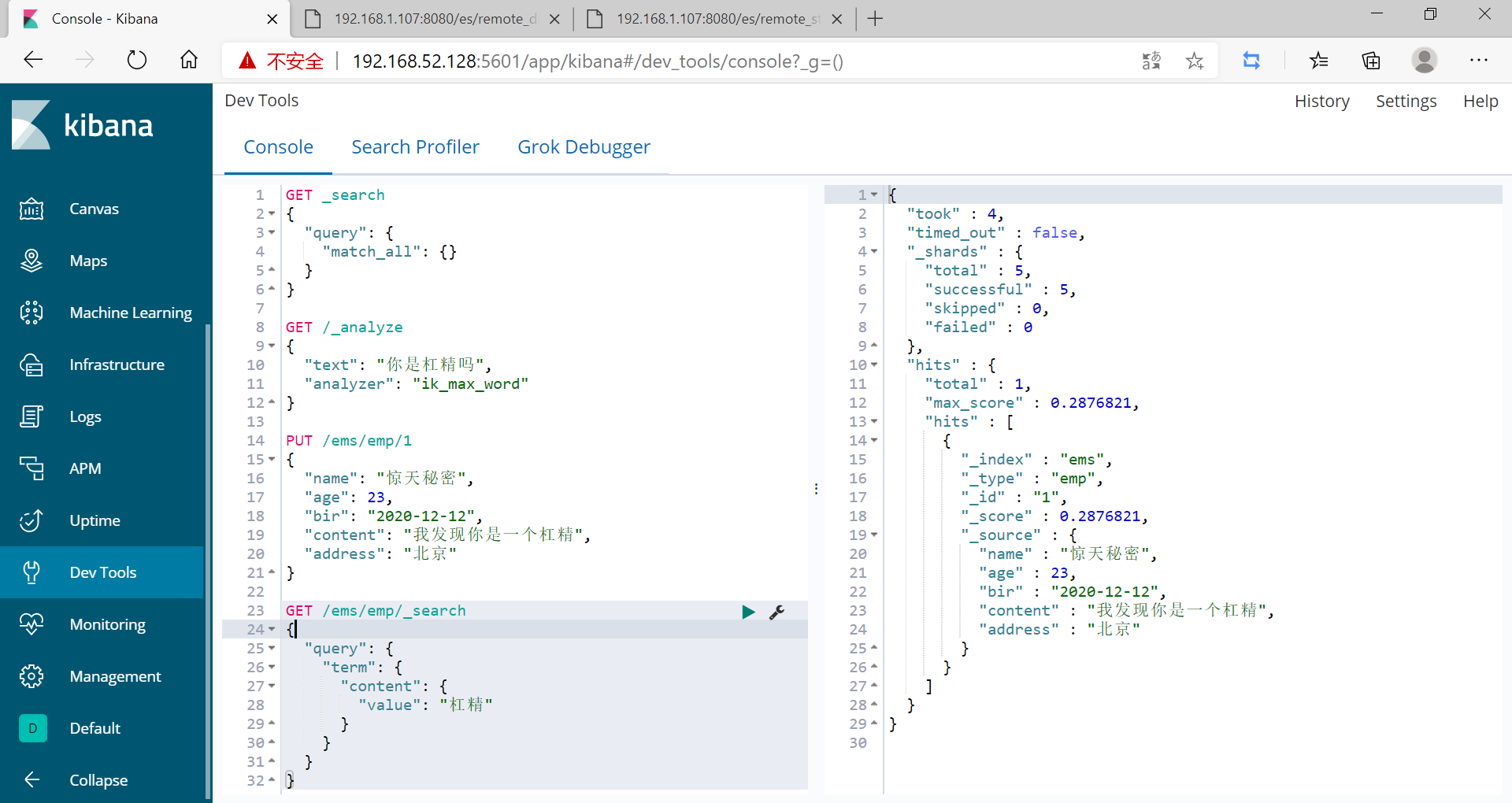
GET /ems/emp/_search
{
"query": {
"term": {
"content": {
"value": "碰瓷"
}
}
}
}
1.6 遠端擴充套件詞典
- 設定一個web專案,新建remote_dict.txt和remote_stopword.txt檔案
- 本地localhost存取測試是否能讀取到(只需確保檔案是UTF-8,無需關注瀏覽器是否亂碼)
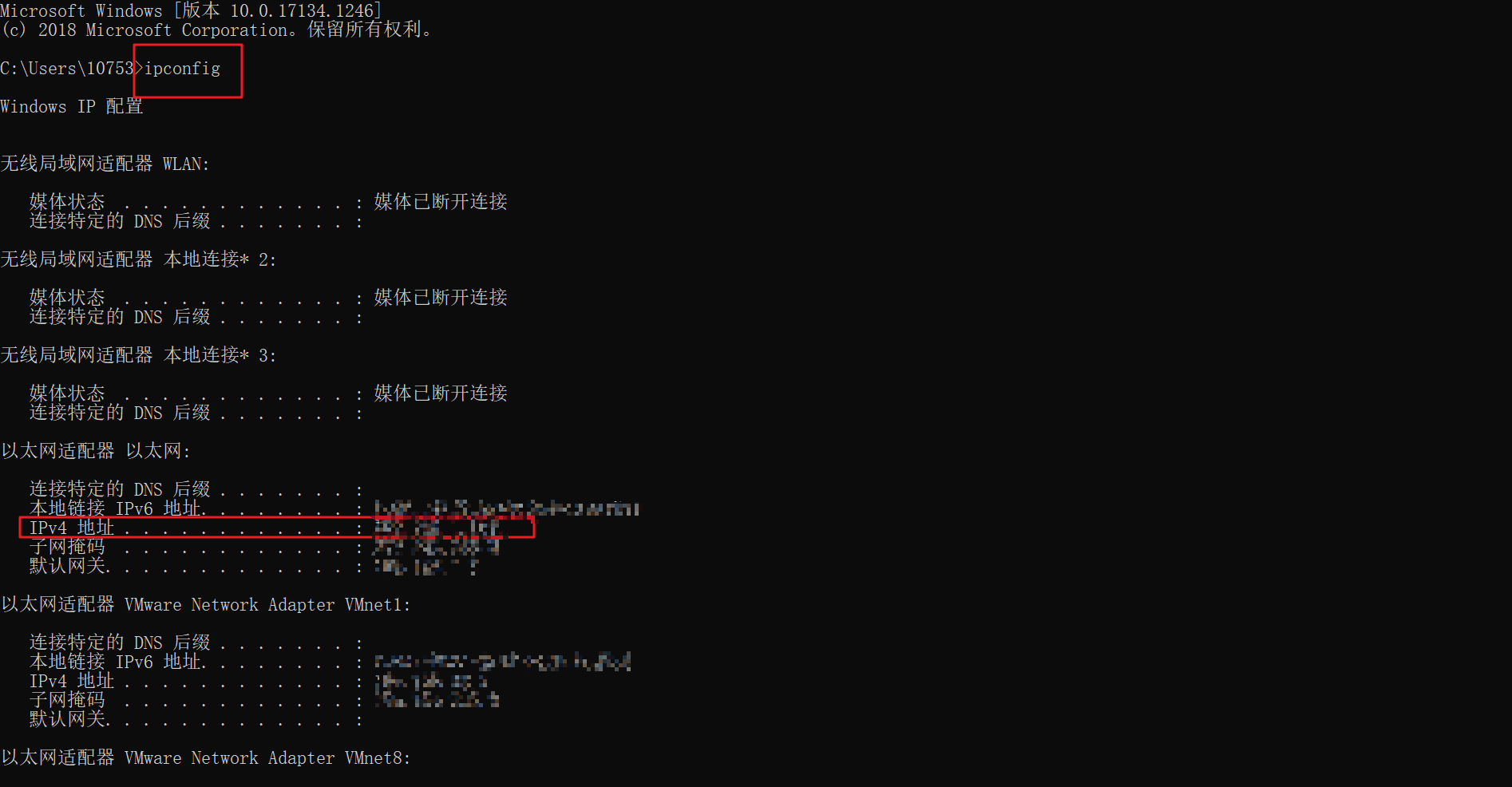
- window系統下cmd輸入ipconfig命令檢視IP地址
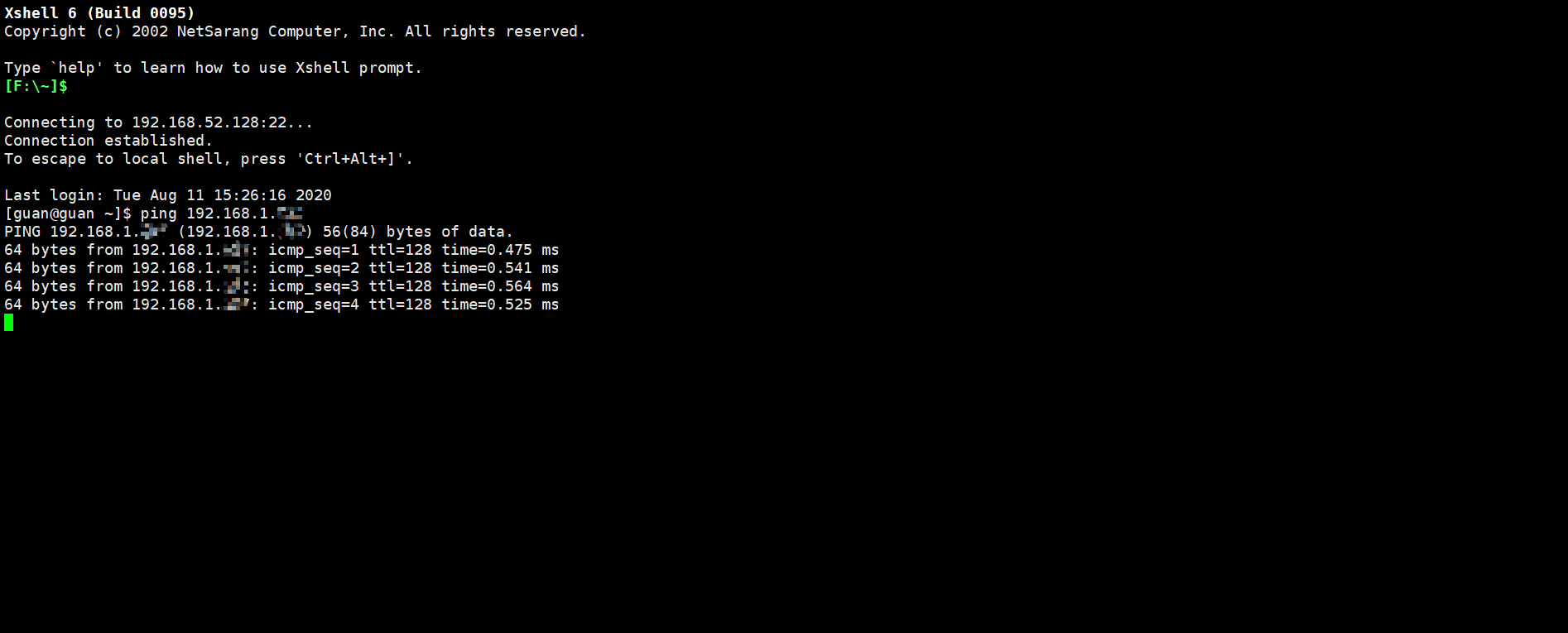
- 在LINUX中測試是否能連線上
-
如果無法連通,https://blog.csdn.net/yangdan1025/article/details/80935321
-
然後繼續修改IKAnalyzer.cfg.xml檔案
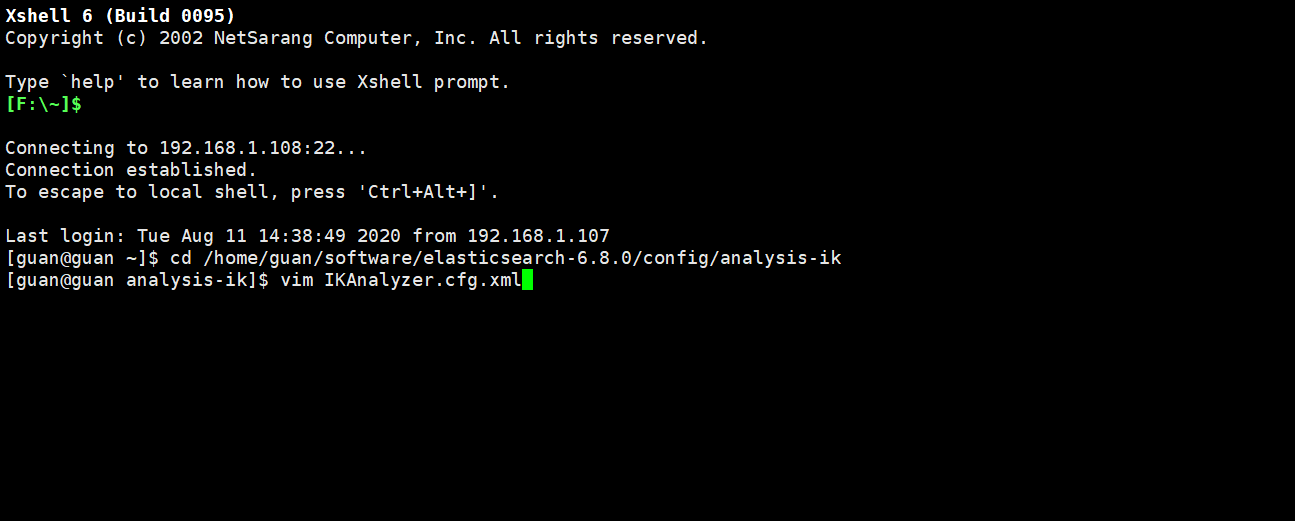
- 開啓註釋,填入存取路徑
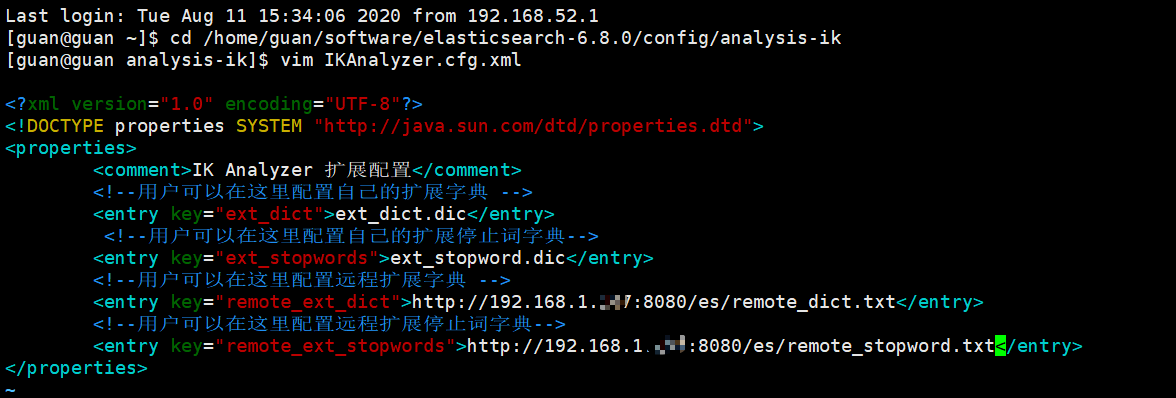
-
未重新啓動ElasticSearch前
預設把每個詞拆分,搜尋也搜尋不到
- 重新啓動ElasticSearch,重新啓動時也看到了已經獲取到詞典了
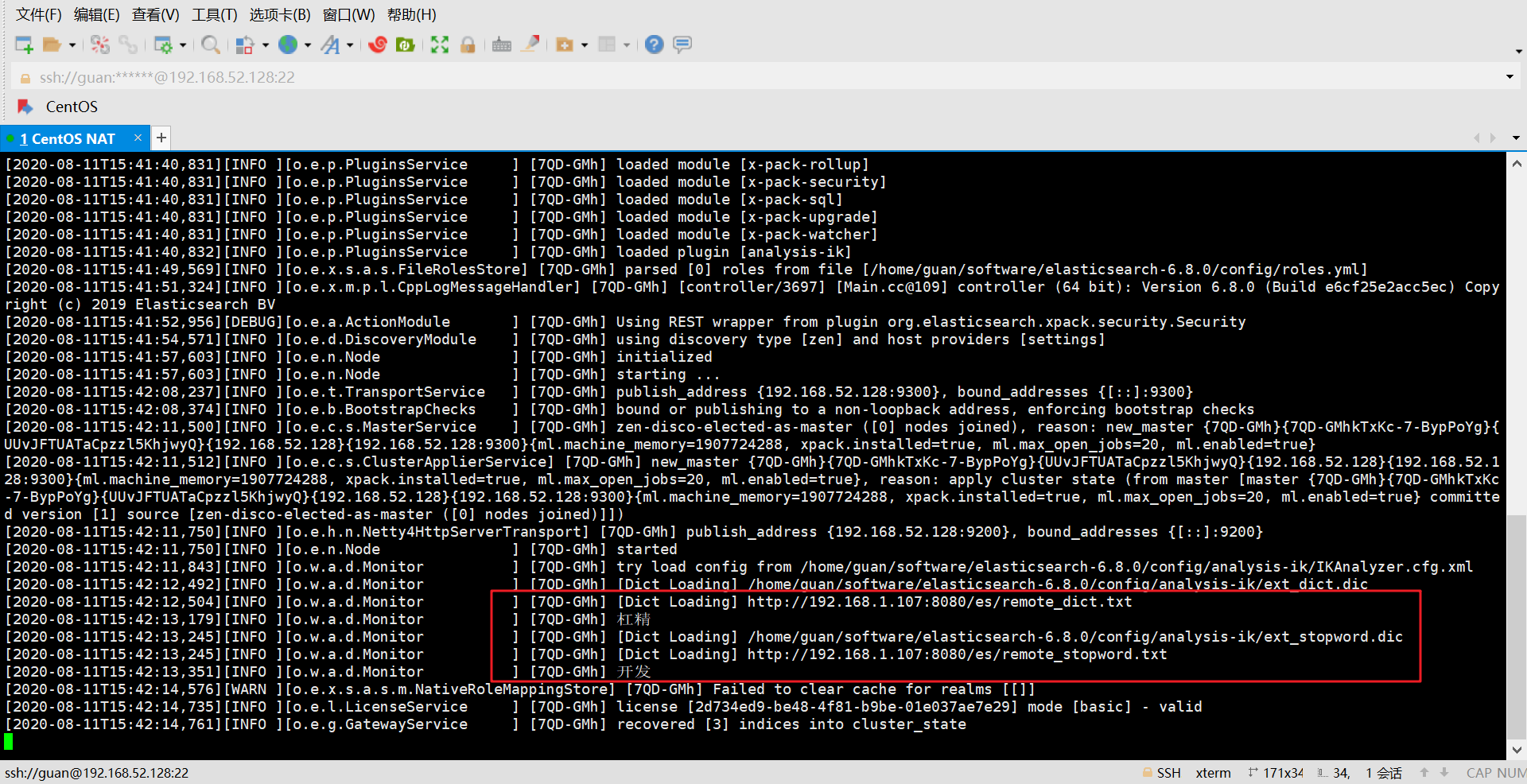
-
此時槓精這個詞已經成了一個詞典,而且能被搜尋出來了
- 另外:ElasticSearch是一直監聽着遠端介面的,遠端更新時,ElasticSearch也會自動更新,無需重新啓動ElasticSearch。