js逆向心路歷程(二)
接上js逆向心路歷程(一)
現在我們會了js的必經之路 (全域性搜尋 定位 斷點 測試 得到結果)
但其實別人設計網站的也會知道我們要這樣 逆他們的加密,那麼他們就會在這些步驟中加大我們的時間成本,測試成本。
設計網站,跟我們爬蟲其實就是 盾與矛 雙方都有成本預算,只要他們的加密成本足夠大,他們就不會再加強了,甚至可能會減弱,因爲生意的本質是賺錢。(當然了他們成本加大了,我們的時間成本也會變大)
比較難的網站:某寶,某點評,某團等,還有一些 .gov 的網站在我們按f12 的時候他就會斷點卡住,不讓我們看f12的資訊,對於這些網站我仍需努力學習。
那麼進入今天的主題
第一個網站
老套路,填入賬號密碼 按 f12 登錄抓包
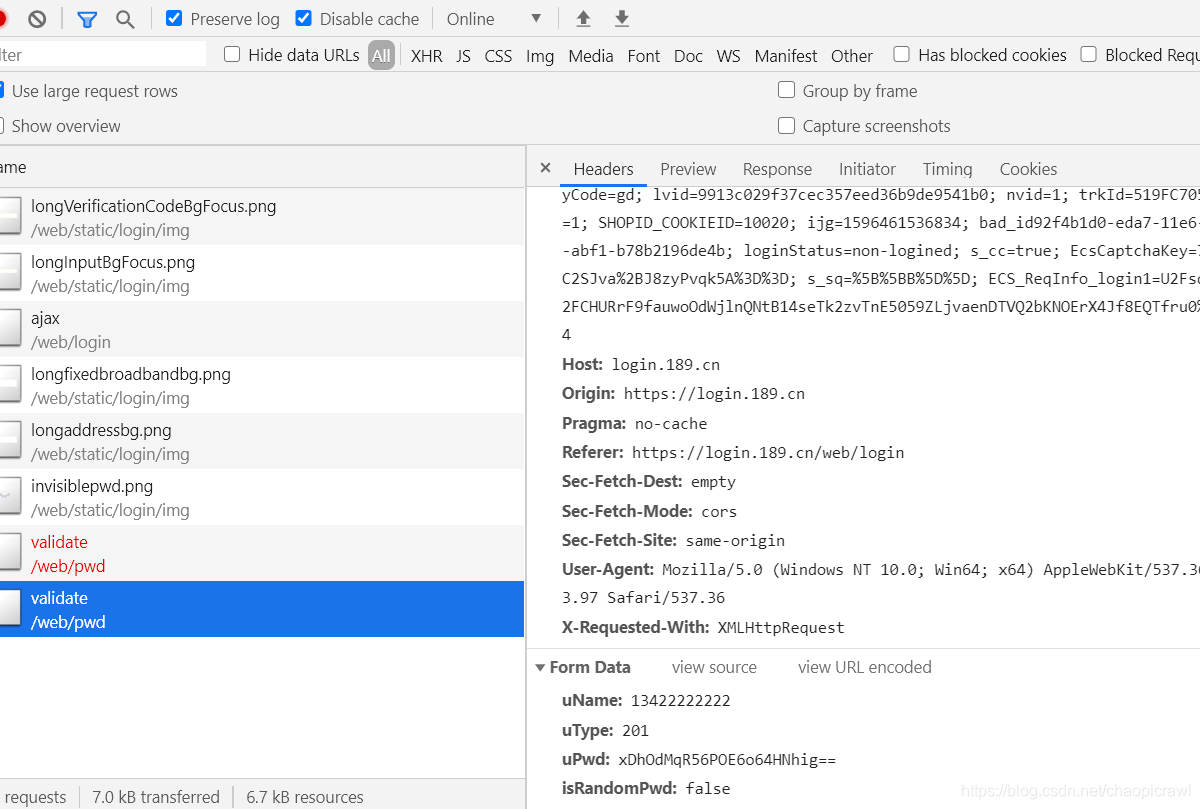
然後我們去搜這個uPwd 發現啥東西也不是
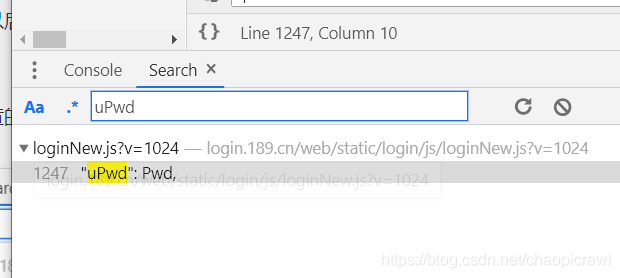
當我們點選進去的時候發現搜尋這個Pwd有135個那麼多,這肯定不是我們想要的
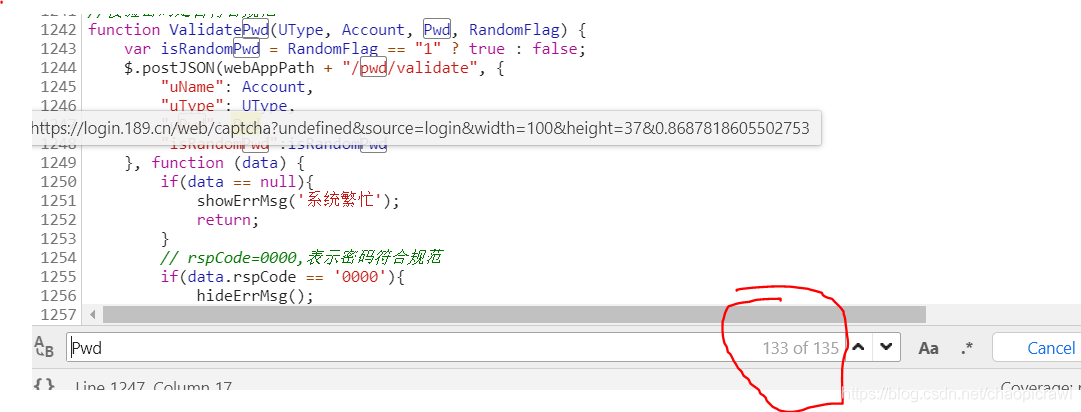
方法一:那就使用上篇文章的技巧,搜尋 js 加密的靈魂 encrypt
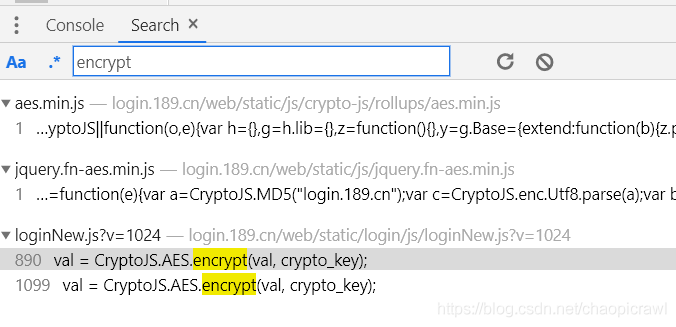
我們發現無論 uPwd 還是 encrypt都是指向 這個loginNew.js 檔案,我們可以肯定我們要的邏輯在這個js裡
方法二:當然了這裏還有一種方法可以確定是這個js檔案
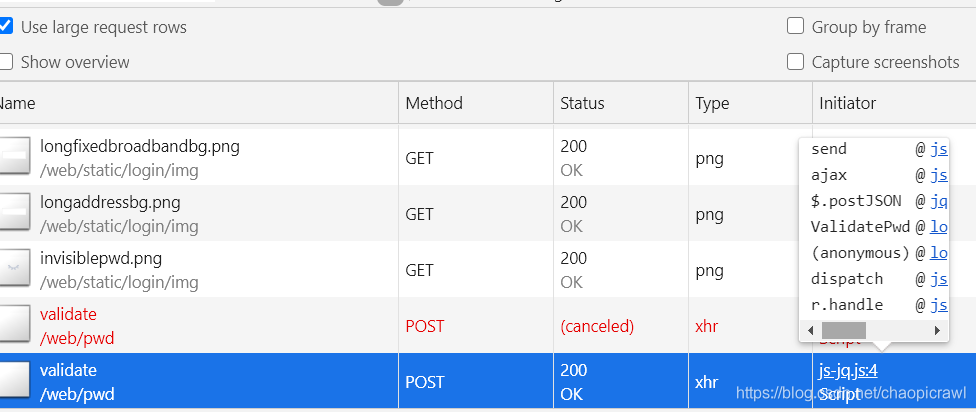
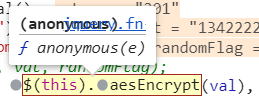
回到一開始抓包的位置,我們將滑鼠移到 validate這個包的 Initor 的位置,這個其實叫關聯包,然後我們需要的包 通常的名字都是 帶login字樣 或者這種 (anonymous(英文:匿名))的東西裡
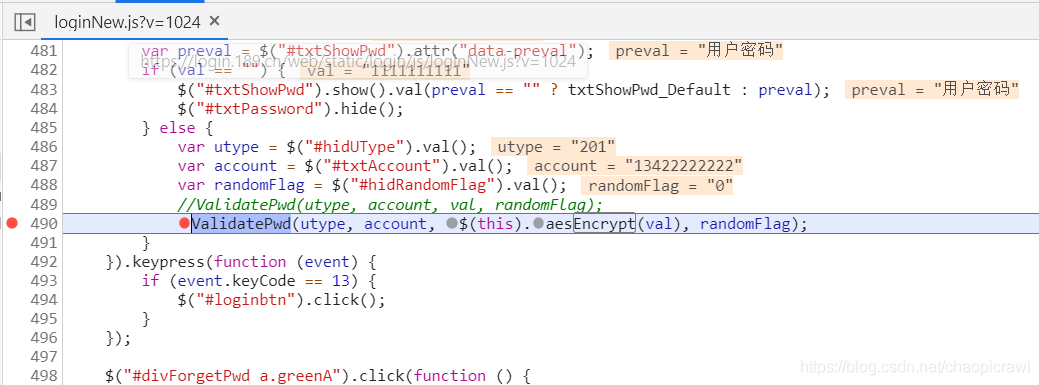
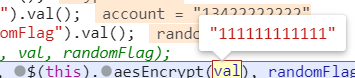
然後我們找到這裏,確定這裏的原因(因爲有pwd,有aesEncrypt(val) )那就可以嘗試重新整理了發現可以斷下

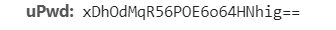
而我們只需要知道這個$(this).aesEncrypt(val) 的全部參數就可以得到我們的結果了
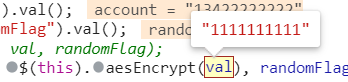
然後修改下
這就是我們 js逆向 的初始模樣了
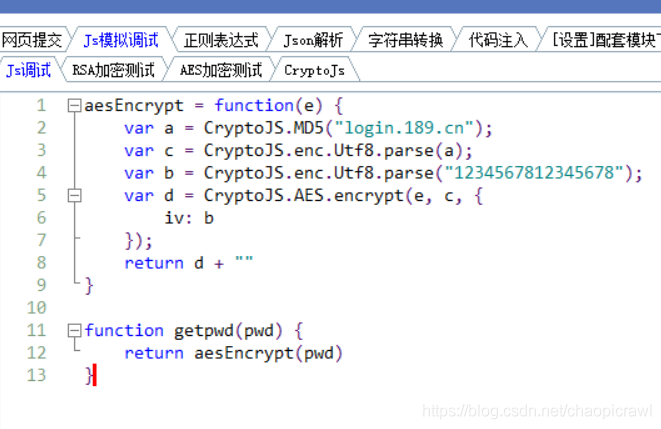
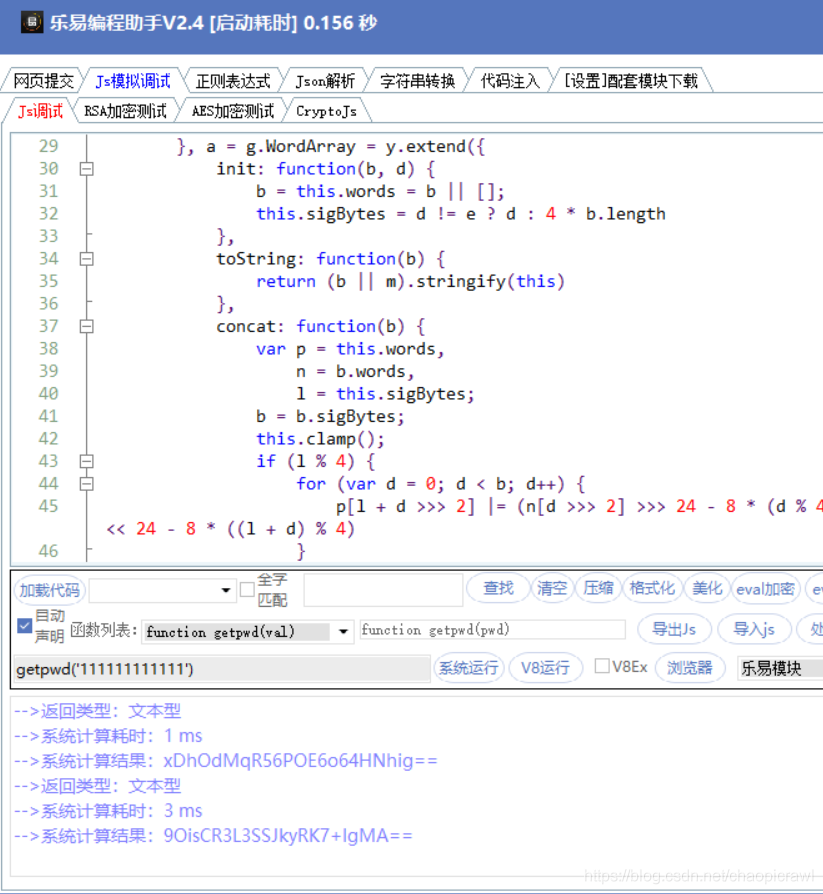
同樣的步驟,找到aesEncrypt裏面的所有參數 然後就可以了
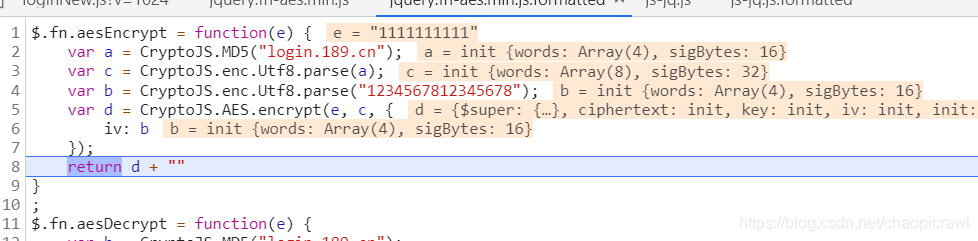
e就是我們的pwd ,然後找到其他就好了
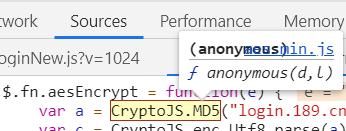
點進去然後我們看到整個js的頭部和尾部


頭是申明一個變數,尾是 賦值一個變數然後最後是 以 })();
這種模式結尾的,其實就是整個 js 的呼叫
我們將整個複製下來然後執行就得出結果了
最後一步就是判斷了

第二個網站
https://dynamic2.scrape.center/page/1
我們要獲取裏面的電影條目 但他是 ajax 載入的內容 所以還是抓包
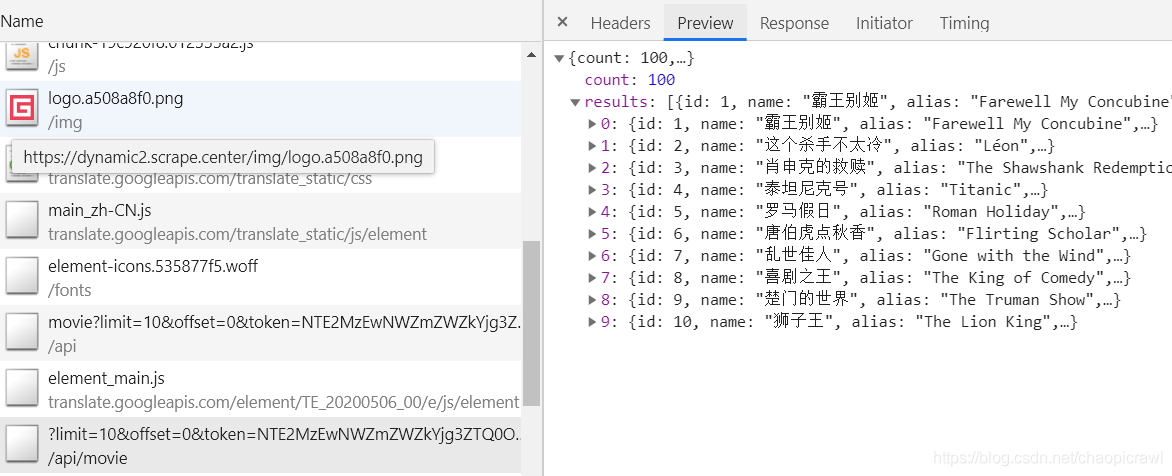
同樣的 全域性搜尋
找到了斷點位置並斷點重新整理

我們只需要找

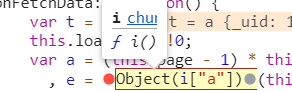
很明顯後面那個東西就是網站的api帶入進去的
然後找前面的object

到了這裏,我們其實就發現已經不需要執行 js 的檔案了,因爲這段程式碼邏輯很簡單,我們單純在python中模擬也可以
我們來分析一下
return的是c 那麼c需要的是 n 這個函數
而我們發現 n這個函數他包含了很多加密技術
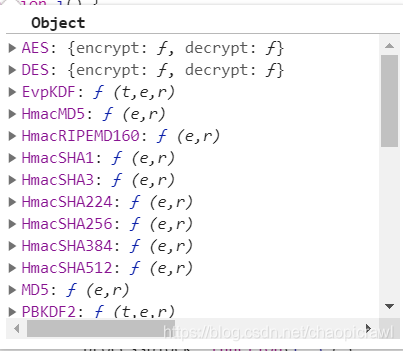
然後 t 是時間截
r是一個數組,數組裏面的東西就是 (for…)這個東西生成的

import hashlib,base64,time
def gettoken():
ts = time.time()
e = 1
r = ["/api/movie",str(ts)]
o = hashlib.sha1(",".join(r).encode('utf-8')).hexdigest()
c = base64.b64encode((",".join([o,str(ts)]).encode('utf-8'))).decode('utf-8')
print(c)
gettoken()
# MWRmYzE2MmRjNTQzMjA5YTdkNDM1ZWIyNzQzMWEwMmQ3MzcwZWIxYSwxNTk3MTMzOTEwLjE0NDM1OTQ=
因爲加了時間截所以無法測試是否相同,但可以請求到ajax的數據
同樣是這樣的 邏輯,我們看看更難一點的 js 文件
https://dynamic6.scrape.cuiqingcai.com/
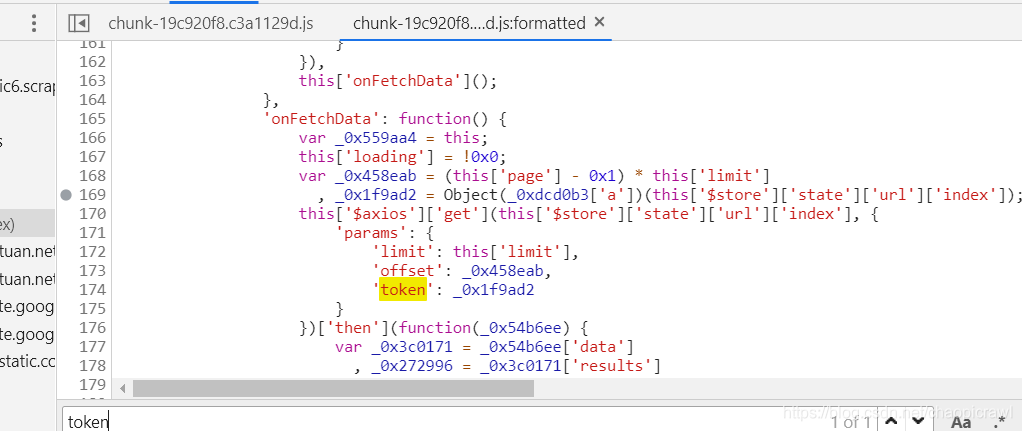
這個網站就將所有函數程式設計了16進位制的加密變得難以觀看,但我們仍然能查詢相同複製

斷點在同樣的位置,也是能斷的
然後步驟也跟上面的一樣了