何二狗mysql筆記
此筆記經過精心整理,希望對你們有幫助,你們每一個贊都是我最大的鼓勵,話不多說,先上腦圖
mysql的簡介:
1.MySQL是一種開放原始碼的關係型數據庫管理系統(RDBMS),使用最常用的數據庫管理語言–結構化查詢語言(SQL)進行數據庫管理。
- MySQL是開放原始碼的,因此任何人都可以在General Public License的許可下下載並根據個性化的需要對其進行修改。
3.MySQL因爲其速度、可靠性和適應性而備受關注。大多數人都認爲在不需要事務化處理的情況下,MySQL是管理內容最好的選擇。*該文字選自百度百科。
數據的基本組成:
- DB:數據庫(database):可以理解爲存放數據的倉庫。
- DBMS:數據庫管理系統:用於管理DB中的數據。
- SQL:結構化查詢語言:專門與數據庫通訊的語言。
SQL的特點:
1.所有的DBMS都支援。
2.簡單易學。
如何開啓mysql:
1.直接按圖示
- 通過Cmd連線數據庫時:mysql -u賬號 -p密碼
什麼是庫?什麼是表?什麼是數據?
1.先將數據放入表中,表再放入庫中。
2.數據庫可以有很多表,每個表都有一個名字,用來標識數據,具有唯一性。
(可以用excel的概念來理解)
| 這個就是表的名字 | 如:姓名 |
|---|---|
| 這個就是記載的數據 | 如:何二狗 |
下圖代表了庫,表,數據的關係:
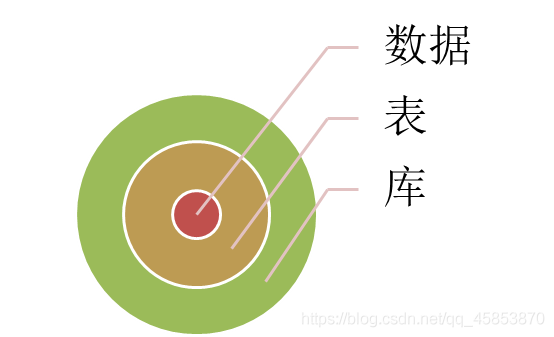
- 什麼是庫?:庫是用來存放n張表
- 什麼是表?:在數據庫中,表(table)類似於excel,可以用來存放數據
- 欄位:類似於Excel中的表頭
- 數據型別:字串(varchar)、整數(tinyint、int、bigint)、小數(float)、日期(Date、datetime)等
- 什麼是數據?:文字、視訊、圖片、音訊等
註釋
#單行註釋
– 單行註釋
/* */:多行註釋
基礎語法介紹
- net stop 伺服器名:停止mysql服務
- net start 伺服器名:開啓mysql服務
- mysql -u賬號 -p密碼:開啓mysql
- exit:退出mysql
- show databases:顯示所有數據庫
- show tables:顯示所有的表
- show tables from 庫名:顯示指定庫中的所有表
- select database():查詢自己所在的庫
- select * from 表名;顯示錶中的所有數據
- desc 表名; 檢視指定表的結構
- use 庫名\表名:進入庫或表
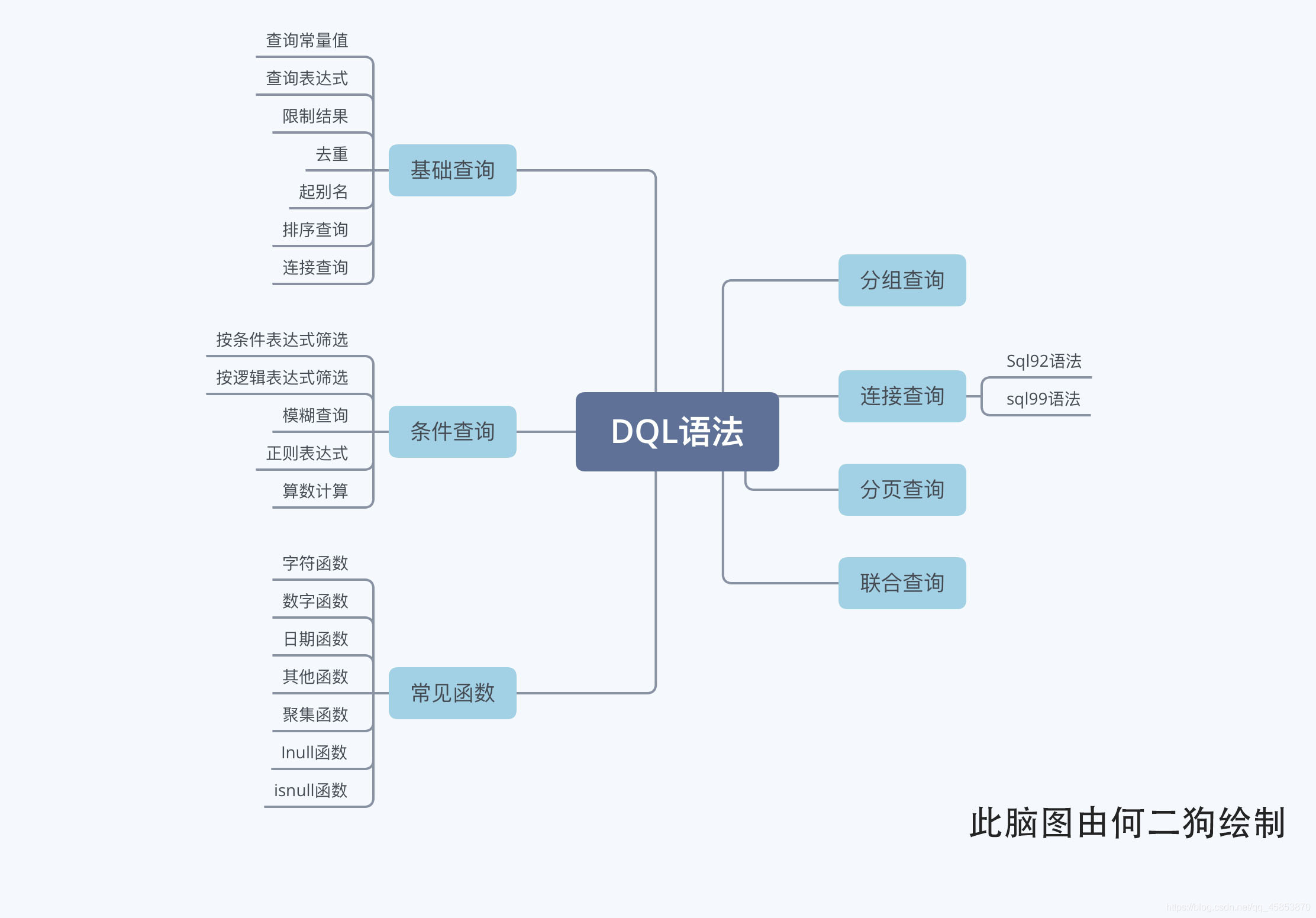
DQL語法
基礎查詢
select 查詢列表 from 表名;
1、查詢列表是:表中的欄位、常數值、表達式、函數
2、查詢的結果是一個虛擬的表格
查詢單個欄位語法:
1.查詢表中的單個欄位
SELECT 欄位名 FROM 表名
2.查詢表中的多個欄位
SELECT 欄位,欄位,欄位 FROM 表名;
3.查詢表中的所有欄位
第一種:SELECT 寫出所有欄位 FROM 表名
第二種:SELECT * FROM 表名;
查詢常數值
語法:select 常數;
查詢表達式
SELECT 100%98;
查詢函數
SELECT VERSION();
ps:用select簡單語法查出來的未進行排序
限制結果
語句
select 表名 from 欄位 limit 開始行,行數;
ps:如果不加開始行,則會從第一行開始檢索
limit必須在order by之後
去重
語法:DISTINCT
select distinct 欄位 from 表名;
ps:distinct應用於所有列,而不僅僅只是他後置的列。
起別名
作用:便於理解,且如果有重名易於區分。
第一種方法 :使用as。
語法:select 欄位 as 別名 from 表名
第二種方法: 使用空格
SELECT last_name 姓,first_name 名 FROM 表名;
排序查詢
特點:
1、asc :升序,(如果不寫預設升序)
desc:降序
2、排序列表 支援 單個欄位、多個欄位、函數、表達式、別名
3、order by的位置一般放在查詢語句的最後(除limit語句之外)
語法:
select 查詢列表
from 表
where 篩選條件
order by 排序列表 【asc}desc】
ps:如果想在多個列上進行降序排序,必須對每個列指定desc關鍵詞
同時對多個列進行排序時,優先滿足第一個排序順序
將多欄位連線CONCAT(‘a’,‘b’,‘c’)
語法:
select CONCAT(欄位,欄位,欄位) from 表單;
進階:條件查詢
語法:
select
查詢列表
from
表名
where
一、按條件表達式篩選
簡單條件運算子:> < = != <> >= <=
二、按邏輯表達式篩選
邏輯運算子:
作用:用於連線條件表達式
&& || !
and or not
&&和and:兩個條件都爲true,結果爲true,反之爲false
||或or: 只要有一個條件爲true,結果爲true,反之爲false
!或not: 如果連線的條件本身爲false,結果爲true,反之爲false
ps:and在計算次序中優先順序大於or 如果要讓or優先,應該加一個括號
三、模糊查詢
like
between and
in
is null /is not null:用於判斷null值
like 查詢
①一般和萬用字元搭配使用
萬用字元:
% 任意多個字元,包含0個字元
_ 任意單個字元
語法:
select
*
from
表單
where
last_name like '%查詢數據%';
between and
①使用between and 可以提高語句的簡潔度
②包含臨界值
③兩個臨界值不要調換順序
select 欄位 from 表名 where 欄位 between 限制 and 限制;
in 查詢
可以顯示in中指定的值
語法:
SELECT 欄位, 欄位, 欄位, 欄位
FROM 表名
WHERE 欄位 IN (數據值, 數據值, 數據值);
正則表達式
算數計算
| 操作符 | 說明 |
|---|---|
| + | 加 |
| - | 減 |
| * | 乘 |
| / | 除 |
常見函數
一、概述
功能:類似於java中的方法
好處:提高重用性和隱藏實現細節
呼叫:select 函數名(實參列表);
二、單行函數
字元函數
| 函數 | 作用 |
|---|---|
| concat: | 連線 |
| substr | 擷取子串 |
| upper | 變大寫 |
| lower | 變小寫 |
| replace | 替換 |
| length | 獲取位元組長度 |
| trim | 去前後空格 |
| lpad | 左填充 |
| rpad | 右填充 |
| instr | 獲取子串第一次出現的索引 |
數學函數
| 函數 | 作用 |
|---|---|
| ceil | 向上取整 |
| round | 四捨五入 |
| mod | 取模 |
| floor | 向下取整 |
| truncate | 截斷 |
| rand | 獲取亂數,返回0-1之間的小數 |
日期函數
| now | 返回當前日期+時間 |
|---|---|
| year | 返回年 |
| month | 返回月 |
| day | 返回日 |
| date_format | 將日期轉換成字元 |
| curdate | 返回當前日期 |
| str_to_date | 將字元轉換成日期 |
| curtime | 返回當前時間 |
| hour | 小時 |
| minute | 分鐘 |
| second | 秒 |
| datediff | 返回兩個日期相差的天數 |
| monthname | 以英文形式返回月 |
其他函數
| version | 當前數據庫伺服器的版本 |
|---|---|
| database | 當前開啓的數據庫 |
| user | 當前使用者 |
| password(‘字元’) | 返回該字元的密碼形式 |
| md5(‘字元’) | 返回該字元的md5加密形式 |
三、聚集函數
1、分類
| max | 最大值 |
|---|---|
| min | 最小值 |
| sum | 和 |
| avg | 平均值 |
| count | 計算個數 |
2、特點
①語法
select max(欄位) from 表名;
②支援的型別
sum和avg一般用於處理數值型
max、min、count可以處理任何數據型別
③以上分組函數都忽略null
④都可以搭配distinct使用,實現去重的統計
select sum(distinct 欄位) from 表;
⑤count函數
count(欄位):統計該欄位非空值的個數
count(*):統計結果集的行數
ifnull函數
功能:判斷某欄位或表達式是否爲null,如果爲null 返回指定的值,否則返回原本的值
語法:
select ifnull(欄位,指定的值) from 表名;
isnull函數
功能:判斷某欄位或表達式是否爲null,如果是,則返回1,否則返回0
分組查詢
語法:
select 分組函數,分組後的欄位
from 表
【where 篩選條件】
group by 分組的欄位
【having 分組後的篩選】
【order by 排序列表】
特點
| 使用關鍵字 | 篩選的表 | 位置 | |
|---|---|---|---|
| 分組前篩選 | where | 原始表 | group by的前面 |
| 分組後篩選 | having | 分組後的結果 | group by 的後面 |
連線查詢
含義:又稱多表查詢,當查詢的欄位來自於多個表時,就會用到連線查詢
笛卡爾乘積現象:表1 有m行,表2有n行,結果=m*n行
發生原因:沒有有效的連線條件
如何避免:新增有效的連線條件
二、分類
1.sql92:
等值
非等值
自連線
也支援一部分外連線(用於oracle、sqlserver,mysql不支援)
2.sql99【推薦使用】
內連線
等值
非等值
自連線
外連線
左外
右外
全外(mysql不支援)
交叉連線
SQL92語法
1、等值連線
語法:
select 查詢列表
from 表1 別名,表2 別名
where 表1.key=表2.key
【and 篩選條件】
【group by 分組欄位】
【having 分組後的篩選】
【order by 排序欄位】
特點:
① 一般爲表起別名
②多表的順序可以調換
③n表連線至少需要n-1個連線條件
④等值連線的結果是多表的交集部分
2、非等值連線
語法:
select 查詢列表
from 表1 別名,表2 別名
where 非等值的連線條件
【and 篩選條件】
【group by 分組欄位】
【having 分組後的篩選】
【order by 排序欄位】
3、自連線
語法:
select 查詢列表
from 表 別名1,表 別名2
where 等值的連線條件
【and 篩選條件】
【group by 分組欄位】
【having 分組後的篩選】
【order by 排序欄位】
SQL99語法
1、內連線
語法:
select 查詢列表
from 表1 別名
【inner】 join 表2 別名 on 連線條件
where 篩選條件
group by 分組列表
having 分組後的篩選
order by 排序列表
limit 子句;
特點:
①表的順序可以調換
②內連線的結果=多表的交集
③n表連線至少需要n-1個連線條件
分類:
等值連線
非等值連線
自連線
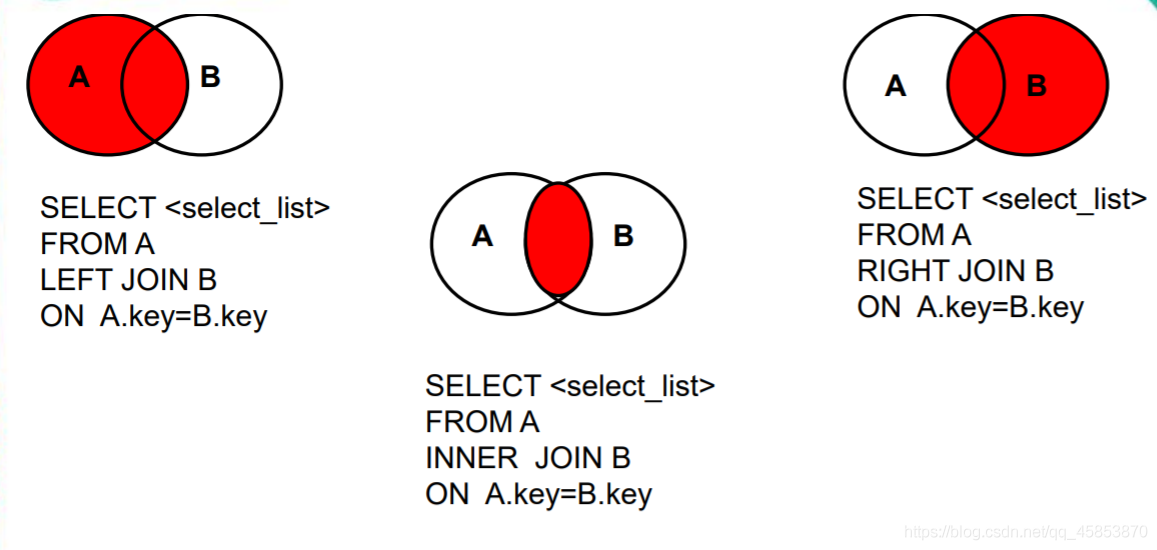
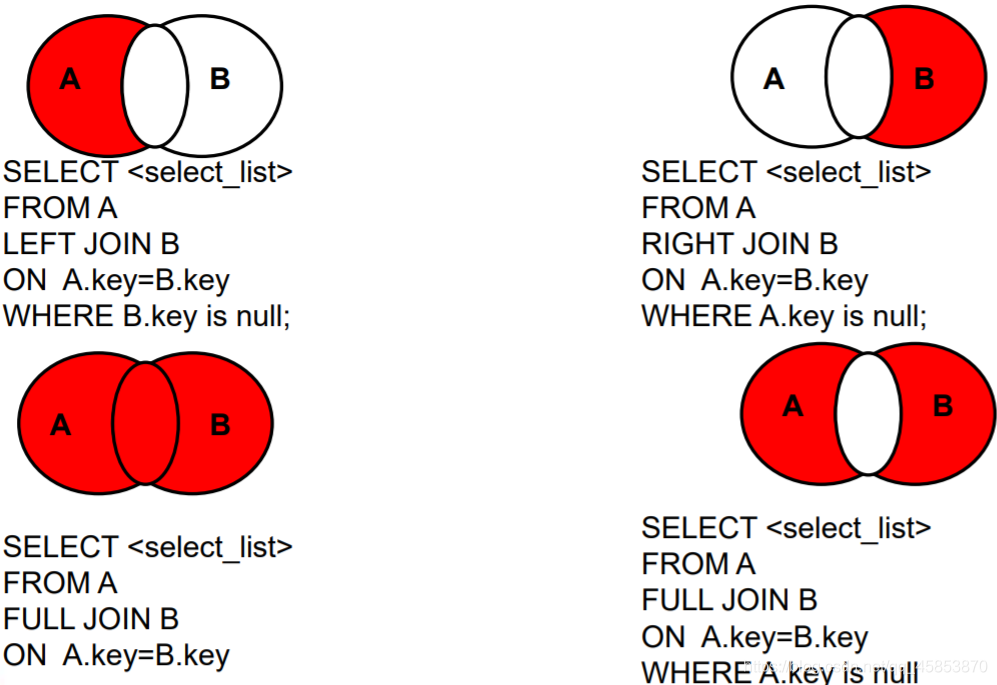
2、外連線
語法:
select 查詢列表
from 表1 別名
left|right|full【outer】 join 表2 別名 on 連線條件
where 篩選條件
group by 分組列表
having 分組後的篩選
order by 排序列表
limit 子句;
特點:
①查詢的結果=主表中所有的行,如果從表和它匹配的將顯示匹配行,如果從表沒有匹配的則顯示null
②left join 左邊的就是主表,right join 右邊的就是主表
full join 兩邊都是主表
③一般用於查詢除了交集部分的剩餘的不匹配的行
3、交叉連線
語法:
select 查詢列表
from 表1 別名
cross join 表2 別名;
特點:
類似於笛卡爾乘積
語法總結:
子查詢
- 含義:
巢狀在其他語句內部的select語句稱爲子查詢或內查詢,
外面的語句可以是insert、update、delete、select等,一般select作爲外面語句較多
外面如果爲select語句,則此語句稱爲外查詢或主查詢 - 分類:
標量子查詢(單行子查詢):結果集爲一行一列
列子查詢(多行子查詢):結果集爲多行一列
行子查詢:結果集爲多行多列
表子查詢:結果集爲多行多列 - 出現位置:
select後面:
僅僅支援標量子查詢
from後面:
表子查詢
where或having後面:
標量子查詢
列子查詢
行子查詢
exists後面:
標量子查詢
列子查詢
行子查詢
表子查詢
分頁查詢
如果要查詢的條目數太多,一頁顯示不全就用它
語法:
select 查詢列表
from 表
limit 【offset,】size;
offset代表的是起始的條目索引,預設從0卡死
size代表的是顯示的條目數
聯合查詢
union:合併、聯合,將多次查詢結果合併成一個結果
語法:
查詢語句1
union 【all】
查詢語句2
union 【all】
...
要求:
- 多條查詢語句的查詢列數必須一致
- 多條查詢語句的查詢的各列型別、順序最好一致
- union 去重,union all包含重複項
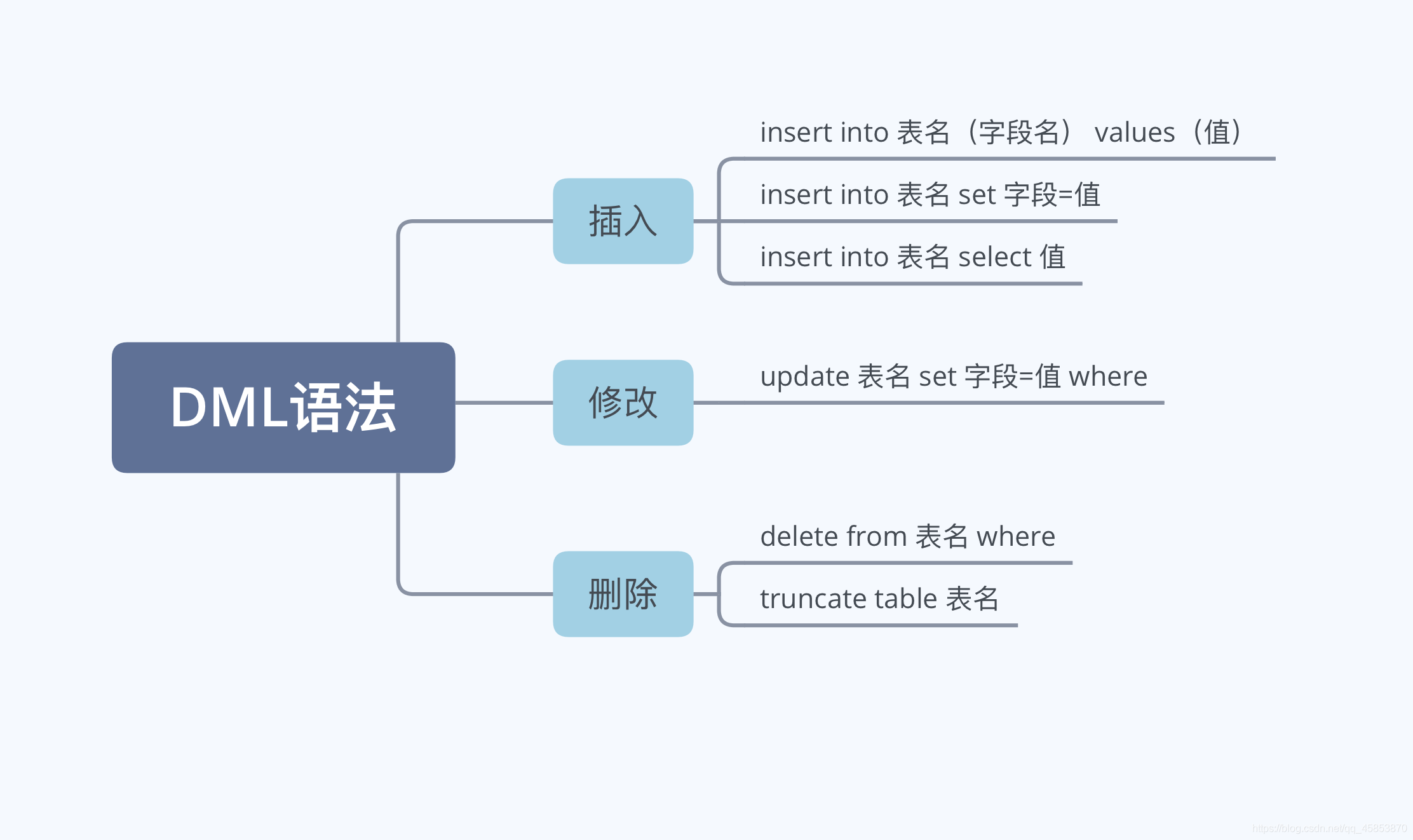
插入語法
一、方式一
語法:
insert into 表名(欄位名,...) values(值,...);
特點:
1、要求值的型別和欄位的型別要一致或相容
2、欄位的個數和順序不一定與原始表中的欄位個數和順序一致
但必須保證值和欄位一一對應
3、假如表中有可以爲null的欄位,注意可以通過以下兩種方式插入null值
①欄位和值都省略
②欄位寫上,值使用null
4、欄位和值的個數必須一致
5、欄位名可以省略,預設所有列
二、方式二
語法:
insert into 表名 set 欄位=值,欄位=值,...;
兩種方式 的區別:
1.方式一支援一次插入多行,語法如下:
insert into 表名【(欄位名,..)】 values(值,..),(值,...),...;
2.方式一支援子查詢,語法如下:
insert into 表名
查詢語句;
提高整體效能,降低語句的優先順序
語法:
insert low_priority into
同樣適用其他語法
修改語法
一、修改單表的記錄 ★
語法:
update 表名 set 欄位=值,欄位=值 【where 篩選條件】;
二、修改多表的記錄【補充】
語法:
update 表1 別名
left|right|inner join 表2 別名
on 連線條件
set 欄位=值,欄位=值
【where 篩選條件】;
在update語句中使用子查詢
語法:
update 表名
select 值
ignore關鍵字
如果對update語句更新多行,出現錯誤時,則語句取消。使用此關鍵詞,發生錯誤也能繼續進行更新
語法:
update ignore 表明
刪除語法
方式一:使用delete
一、刪除單表的記錄★
語法:
delete from 表名 【where 篩選條件】【limit 條目數】
二、級聯刪除[補充]
語法:
delete 別名1,別名2 from 表1 別名
inner|left|right join 表2 別名
on 連線條件
【where 篩選條件】
方式二:使用truncate
語法:
truncate table 表名
兩種方式的區別【面試題】★
- truncate刪除後,如果再插入,標識列從1開始
delete刪除後,如果再插入,標識列從斷點開始 - delete可以新增篩選條件
truncate不可以新增篩選條件 - truncate效率較高
- truncate沒有返回值
delete可以返回受影響的行數 - truncate不可以回滾
delete可以回滾
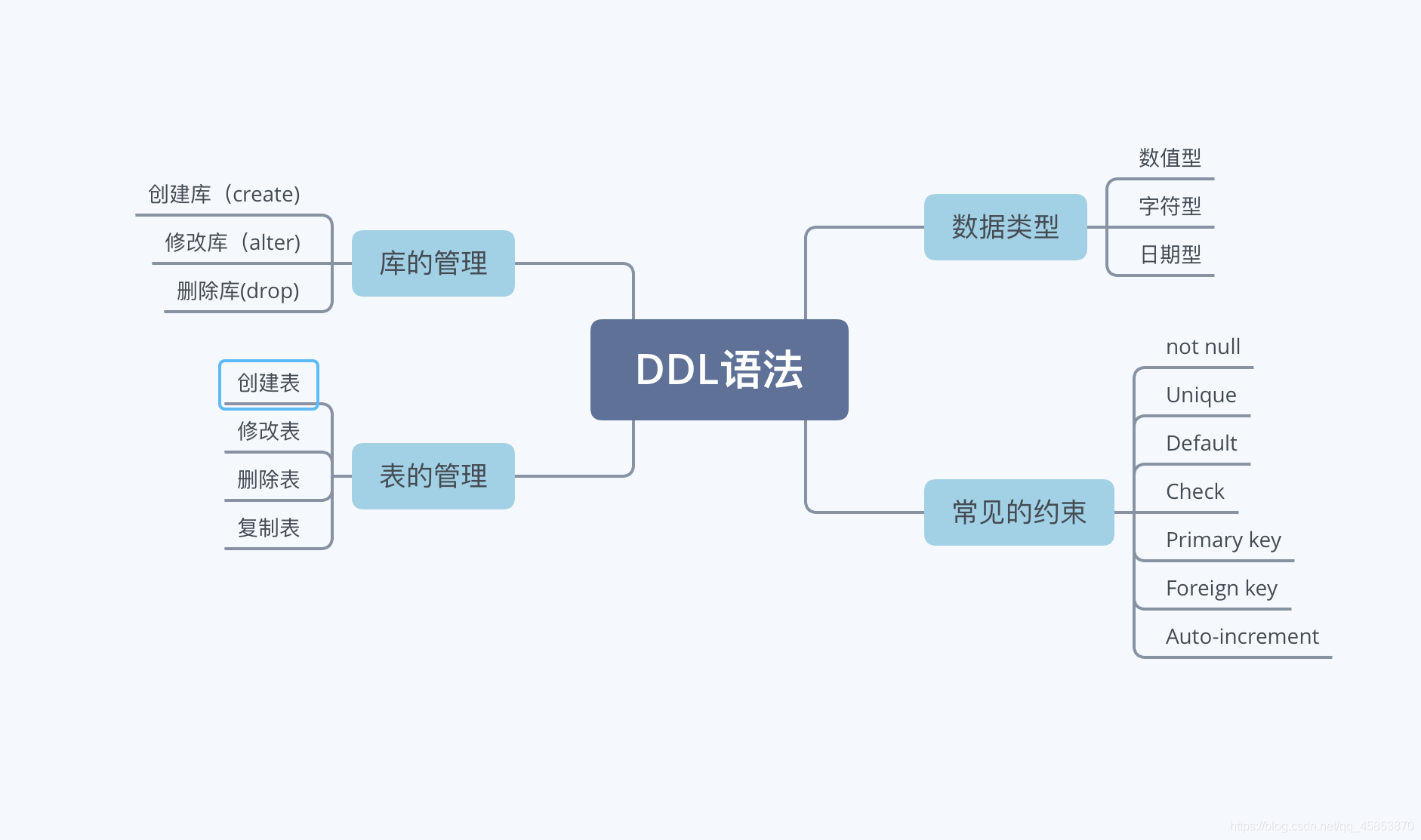
庫的管理
一、建立庫
create database 【if not exists】 庫名【 character set 字元集名】;
二、修改庫
alter database 庫名 character set 字元集名;
修改庫名
RENAME DATABASE books TO 新庫名;
三、刪除庫
drop database 【if exists】 庫名;
表的管理
一、建立表 ★
create table 【if not exists】 表名(
欄位名 欄位型別 【約束】,
欄位名 欄位型別 【約束】,
。。。
欄位名 欄位型別 【約束】
)
二、修改表
1.新增列
alter table 表名 add column 列名 型別 【first|after 欄位名】;
2.修改列的型別或約束
alter table 表名 modify column 列名 新型別 【新約束】;
3.修改列名
alter table 表名 change column 舊列名 新列名 型別;
4 .刪除列
alter table 表名 drop column 列名;
5.修改表名
alter table 表名 rename 【to】 新表名;
三、刪除表
drop table【if exists】 表名;
四、複製表
1、複製表的結構
create table 表名 like 舊錶;
2、複製表的結構+數據
create table 表名
select 查詢列表 from 舊錶【where 篩選】;
數據型別
一、數值型
1、整型
tinyint、smallint、mediumint、int/integer、bigint
1 2 3 4 8
特點:
①都可以設定無符號和有符號,預設有符號,通過unsigned設定無符號
②如果超出了範圍,會報out or range異常,插入臨界值
③長度可以不指定,預設會有一個長度
長度代表顯示的最大寬度,如果不夠則左邊用0填充,但需要搭配zerofill,並且預設變爲無符號整型
2、浮點型
定點數:decimal(M,D)
浮點數:
float(M,D) 4
double(M,D) 8
特點:
①M代表整數部位+小數部位的個數,D代表小數部位
②如果超出範圍,則報out or range異常,並且插入臨界值
③M和D都可以省略,但對於定點數,M預設爲10,D預設爲0
④如果精度要求較高,則優先考慮使用定點數
二、字元型
char、varchar、binary、varbinary、enum、set、text、blob
char:固定長度的字元,寫法爲char(M),最大長度不能超過M,其中M可以省略,預設爲1
varchar:可變長度的字元,寫法爲varchar(M),最大長度不能超過M,其中M不可以省略
三、日期型
year年
date日期
time時間
datetime 日期+時間 8
timestamp 日期+時間 4 比較容易受時區、語法模式、版本的影響,更能反映當前時區的真實時間
常見的約束
一、常見的約束
NOT NULL:非空,該欄位的值必填
UNIQUE:唯一,該欄位的值不可重複
DEFAULT:預設,該欄位的值不用手動插入有預設值
CHECK:檢查,mysql不支援
PRIMARY KEY:主鍵,該欄位的值不可重複並且非空 unique+not null
FOREIGN KEY:外來鍵,該欄位的值參照了另外的表的欄位
主鍵和唯一
1、區別:
①、一個表至多有一個主鍵,但可以有多個唯一
②、主鍵不允許爲空,唯一可以爲空
2、相同點
都具有唯一性
都支援組合鍵,但不推薦
外來鍵:
1、用於限制兩個表的關係,從表的欄位值參照了主表的某欄位值
2、外來鍵列和主表的被參照列要求型別一致,意義一樣,名稱無要求
3、主表的被參照列要求是一個key(一般就是主鍵)
4、插入數據,先插入主表
刪除數據,先刪除從表
可以通過以下兩種方式來刪除主表的記錄
#方式一:級聯刪除
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE CASCADE;
#方式二:級聯置空
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE SET NULL;
二、建立表時新增約束
create table 表名(
欄位名 欄位型別 not null,#非空
欄位名 欄位型別 primary key,#主鍵
欄位名 欄位型別 unique,#唯一
欄位名 欄位型別 default 值,#預設
constraint 約束名 foreign key(欄位名) references 主表(被參照列)
)
注意:
支援型別 可以起約束名
列級約束 除了外來鍵 不可以
表級約束 除了非空和預設 可以,但對主鍵無效
列級約束可以在一個欄位上追加多個,中間用空格隔開,沒有順序要求
三、修改表時新增或刪除約束
1、非空
新增非空
alter table 表名 modify column 欄位名 欄位型別 not null;
刪除非空
alter table 表名 modify column 欄位名 欄位型別 ;
2、預設
新增預設
alter table 表名 modify column 欄位名 欄位型別 default 值;
刪除預設
alter table 表名 modify column 欄位名 欄位型別 ;
3、主鍵
新增主鍵
alter table 表名 add【 constraint 約束名】 primary key(欄位名);
刪除主鍵
alter table 表名 drop primary key;
4、唯一
新增唯一
alter table 表名 add【 constraint 約束名】 unique(欄位名);
刪除唯一
alter table 表名 drop index 索引名;
5、外來鍵
新增外來鍵
alter table 表名 add【 constraint 約束名】 foreign key(欄位名) references 主表(被參照列);
刪除外來鍵
alter table 表名 drop foreign key 約束名;
四、自增長列
特點:
1、不用手動插入值,可以自動提供序列值,預設從1開始,步長爲1
auto_increment_increment
如果要更改起始值:手動插入值
如果要更改步長:更改系統變數
set auto_increment_increment=值;
2、一個表至多有一個自增長列
3、自增長列只能支援數值型
4、自增長列必須爲一個key
一、建立表時設定自增長列
create table 表(
欄位名 欄位型別 約束 auto_increment
)
二、修改表時設定自增長列
alter table 表 modify column 欄位名 欄位型別 約束 auto_increment
三、刪除自增長列
alter table 表 modify column 欄位名 欄位型別 約束
事務
一、含義
事務:一條或多條sql語句組成一個執行單位,一組sql語句要麼都執行要麼都不執行
二、特點(ACID)
A 原子性:一個事務是不可再分割的整體,要麼都執行要麼都不執行
C 一致性:一個事務可以使數據從一個一致狀態切換到另外一個一致的狀態
I 隔離性:一個事務不受其他事務的幹擾,多個事務互相隔離的
D 永續性:一個事務一旦提交了,則永久的持久化到本地
三、事務的使用步驟 ★
瞭解:
隱式(自動)事務:沒有明顯的開啓和結束,本身就是一條事務可以自動提交,比如insert、update、delete
顯式事務:具有明顯的開啓和結束
使用顯式事務:
①開啓事務
set autocommit=0;
start transaction;#可以省略
②編寫一組邏輯sql語句
注意:sql語句支援的是insert、update、delete
設定回滾點:
savepoint 回滾點名;
③結束事務
提交:commit;
回滾:rollback;
回滾到指定的地方:rollback to 回滾點名;
四、併發事務
1、事務的併發問題是如何發生的?
多個事務 同時 操作 同一個數據庫的相同數據時
2、併發問題都有哪些?
髒讀:一個事務讀取了其他事務還沒有提交的數據,讀到的是其他事務「更新」的數據
不可重複讀:一個事務多次讀取,結果不一樣
幻讀:一個事務讀取了其他事務還沒有提交的數據,只是讀到的是 其他事務「插入」的數據
3、如何解決併發問題
通過設定隔離級別來解決併發問題
4、隔離級別
| 髒讀 | 不可重複讀 | 幻讀 | ||
|---|---|---|---|---|
| read uncommitted | 讀未提交 | 不 | 不 | 不 |
| read committed | 讀已提交 | 可 | 不 | 不 |
| repeatable read | 可重複讀 | 可 | 可 | 不 |
| serializable | 序列化 | 可 | 可 | 可 |
檢視隔離級別
select @@tx_isolation;
設定隔離級別
set session|global transaction isolation level 隔離級別;
其他
檢視
一、含義
mysql5.1版本出現的新特性,本身是一個虛擬表,它的數據來自於表,通過執行時動態生成。
好處:
1、簡化sql語句
2、提高了sql的重用性
3、保護基表的數據,提高了安全性
二、建立
create view 檢視名
as
查詢語句;
三、修改
方式一:
create or replace view 檢視名
as
查詢語句;
方式二:
alter view 檢視名
as
查詢語句
四、刪除
drop view 檢視1,檢視2,...;
五、檢視
desc 檢視名;
show create view 檢視名;
六、使用
1.插入
insert
2.修改
update
3.刪除
delete
4.檢視
select
注意:檢視一般用於查詢的,而不是更新的,所以具備以下特點的檢視都不允許更新
①包含分組函數、group by、distinct、having、union、
②join
③常數檢視
④where後的子查詢用到了from中的表
⑤用到了不可更新的檢視
七、檢視和表的對比
| 關鍵字 | 是否佔用物理空間 | 使用 | |
|---|---|---|---|
| 檢視 | view | 佔用較小,只儲存sql邏輯 | 一般用於查詢 |
| 表 | table | 儲存實際的數據 | 增刪改查 |
變數
一、系統變數
說明:變數由系統提供的,不用自定義
語法:
①檢視系統變數
show 【global|session 】variables like '';
如果沒有顯式宣告global還是session,則預設是session
②檢視指定的系統變數的值
select @@【global|session】.變數名;
如果沒有顯式宣告global還是session,則預設是session
③爲系統變數賦值
方式一:
set 【global|session 】 變數名=值;
如果沒有顯式宣告global還是session,則預設是session
方式二:
set @@global.變數名=值;
set @@變數名=值;
1、全域性變數
伺服器層面上的,必須擁有super許可權才能 纔能爲系統變數賦值,作用域爲整個伺服器,也就是針對於所有連線(對談)有效
2、對談變數
伺服器爲每一個連線的用戶端都提供了系統變數,作用域爲當前的連線(對談)
二、自定義變數
說明:
1、使用者變數
作用域:針對於當前連線(對談)生效
位置:begin end裏面,也可以放在外面
使用:
①宣告並賦值:
set @變數名=值;或
set @變數名:=值;或
select @變數名:=值;
②更新值
方式一:
set @變數名=值;或
set @變數名:=值;或
select @變數名:=值;
方式二:
select xx into @變數名 from 表;
③使用
select @變數名;
2、區域性變數
作用域:僅僅在定義它的begin end中有效
位置:只能放在begin end中,而且只能放在第一句
使用:
①宣告
declare 變數名 型別 【default 值】;
②賦值或更新
方式一:
set 變數名=值;或
set 變數名:=值;或
select @變數名:=值;
方式二:
select xx into 變數名 from 表;
③使用
select 變數名;
儲存過程函數
說明:都類似於java中的方法,將一組完成特定功能的邏輯語句包裝起來,對外暴露名字
好處:
1、提高重用性
2、sql語句簡單
3、減少了和數據庫伺服器連線的次數,提高了效率
儲存過程
一、建立 ★
DELIMITER $
create procedure 儲存過程名(參數模式 參數名 參數型別)
begin
儲存過程體
end
注意:
1.參數模式:in、out、inout,其中in可以省略
2.儲存過程體的每一條sql語句都需要用分號結尾
二、呼叫
call 儲存過程名(實參列表)
舉例:
呼叫in模式的參數:call sp1(‘值’);
呼叫out模式的參數:set @name; call sp1(@name);select @name;
呼叫inout模式的參數:set @name=值; call sp1(@name); select @name;
三、檢視
show create procedure
儲存過程名;
四、刪除
drop procedure
儲存過程名;