【操作系統】面試語言組織:進程間通訊
文章目錄
一、前言
操作系統,一般是大廠面試需要考察一下
純理論的東西,沒有實踐,組織好語言,面試好吹逼
二、進程間通訊
2.1 如何實現進程間通訊?
每個進程的使用者地址空間都是獨立的,一般而言是不能互相存取的,但內核空間是每個進程都共用的,所以進程之間要通訊必須通過內核,如下圖:
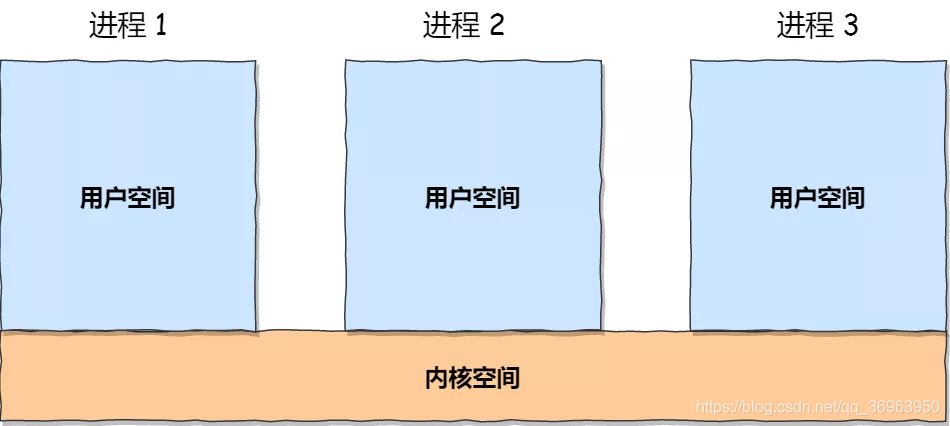
Linux 內核提供了不少進程間通訊的機制 機製,我們來一起瞧瞧有哪些?
2.2 進程間通訊的方式
進程間通訊方式包括:管道、訊息佇列、共用記憶體、號志、信號、Socket
爲什麼要進程間通訊?如何實現進程間通訊?
每個進程的使用者空間都是獨立的,不能互相存取的,不能通訊;但是他們的內核空間是每個進程都共用的,可以通訊,所以進程之間要通訊必須通過內核。
進程間通訊的方式有哪些?
進程間通訊方式包括:管道、訊息佇列、共用記憶體、號志、信號、Socket
三、進程間通訊方式:管道
3.1 第一種管道:匿名管道
如果你學過 Linux 命令,那你肯定很熟悉「|」這個豎線。
$ ps auxf | grep mysql
上面命令列裡的「|」豎線就是一個管道,它的功能是將前一個命令(ps auxf)的輸出,作爲後一個命令(grep mysql)的輸入,從這功能描述,可以看出管道傳輸數據是單向的,如果想相互通訊,我們需要建立兩個管道才行。
同時,我們得知上面這種管道是沒有名字,所以「|」表示的管道稱爲匿名管道,用完了就銷燬。
3.2 第二種管道:命名管道
管道還有另外一個型別是命名管道,也被叫做 FIFO,因爲數據是先進先出的傳輸方式。
在使用命名管道前,先需要通過 mkfifo 命令來建立,並且指定管道名字:
$ mkfifo myPipe
myPipe 就是這個管道的名稱,基於 Linux 一切皆檔案的理念,所以管道也是以檔案的方式存在,我們可以用 ls 看一下,這個檔案的型別是 p,也就是 pipe(管道) 的意思:
$ ls -l
prw-r--r--. 1 root root 0 Jul 17 02:45 myPipe
金手指:
ls //顯示不隱藏的檔案與資料夾
ls -a //顯示當前目錄下的所有檔案及資料夾包括隱藏的.和…等
ls -l //顯示不隱藏的檔案與資料夾的詳細資訊
ls -al //顯示當前目錄下的所有檔案及資料夾包括隱藏的.和…等的詳細資訊
3.3 管道讀寫(先將數據寫入管道,再從管道中讀出數據)
接下來,我們往 myPipe 這個管道寫入數據:
$ echo "hello" > myPipe // 將數據寫進管道
// 停住了 ...
你操作了後,你會發現命令執行後就停在這了,這是因爲管道裡的內容沒有被讀取,只有當管道裡的數據被讀完後,命令纔可以正常退出。
於是,我們執行另外一個命令來讀取這個管道裡的數據:
$ cat < myPipe // 讀取管道裡的數據
hello
可以看到,管道裡的內容被讀取出來了,並列印在了終端上,另外一方面,echo 那個命令也正常退出了。
3.4 進程間通訊:管道的優缺點
缺點:效率低,不適合進程間頻繁地交換數據。
優點:簡單,我們很容易得知管道裡的數據已經被另一個進程讀取了。
面試官:介紹一下管道通訊?
第一,管道包括兩種,匿名管道和命名管道。
匿名管道(管道新建、管道輸入、管道輸出)
匿名管道就是命令列中的 | ,| 前面的輸出是 | 後面內容的輸入,這樣就使用匿名管道完成了進程間通訊。
一句小結匿名管道:| 新建管道,| 前面的輸出的管道的輸入,然後管道將內容輸出到 | 後面的進程去。
windows和linux都適用
windows如:netstat -ano|findStr 8080
Linux如:ps auxf | grep mysql
命名管道(管道新建、管道輸入、管道輸出):
一句話總結:
$ mkfifo myPipe // 新建命名管道
$ echo 「hello」 > myPipe // 命名管道輸入
$ cat < myPipe // 命名管道輸出
第二,linux中一切都是檔案,管道也是檔案,管道是型別爲p的檔案。
第三,管道作爲一種進程間通訊方式的優缺點。
缺點:效率低,不適合進程間頻繁地交換數據。
優點:簡單,我們很容易得知管道裡的數據已經被另一個進程讀取了。
3.5 管道底層的系統呼叫
那管道如何建立呢,背後原理是什麼?
匿名管道(新建、輸入、輸出)
匿名管道的建立,需要通過下面 下麪這個系統呼叫:
int pipe(int fd[2])
這裏表示建立一個匿名管道,並返回了兩個描述符,一個是管道的讀取端描述符 fd[0],另一個是管道的寫入端描述符 fd[1]。注意,這個匿名管道是特殊的檔案,和一般檔案不同,它只存在於記憶體,不存於檔案系統中。
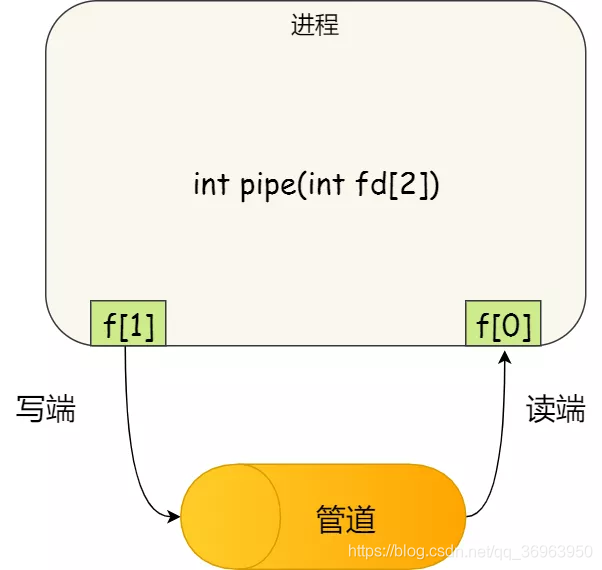
其實,所謂的管道,本質上是內核裏面的一串快取。從管道的一端寫入的數據,實際上是快取在內核中的,另一端讀取,也就是從內核中讀取這段數據。另外,管道傳輸的數據是無格式的流且大小受限。
看到這,你可能會有疑問了,這兩個描述符都是在一個進程裏面,並沒有起到進程間通訊的作用,怎麼樣才能 纔能使得管道是跨過兩個進程的呢?
我們可以使用 fork 建立子進程,建立的子進程會複製父進程的檔案描述符,這樣就做到了兩個進程各有兩個「 fd[0] 與 fd[1]」,兩個進程就可以通過各自的 fd 寫入和讀取同一個管道檔案實現跨進程通訊了。
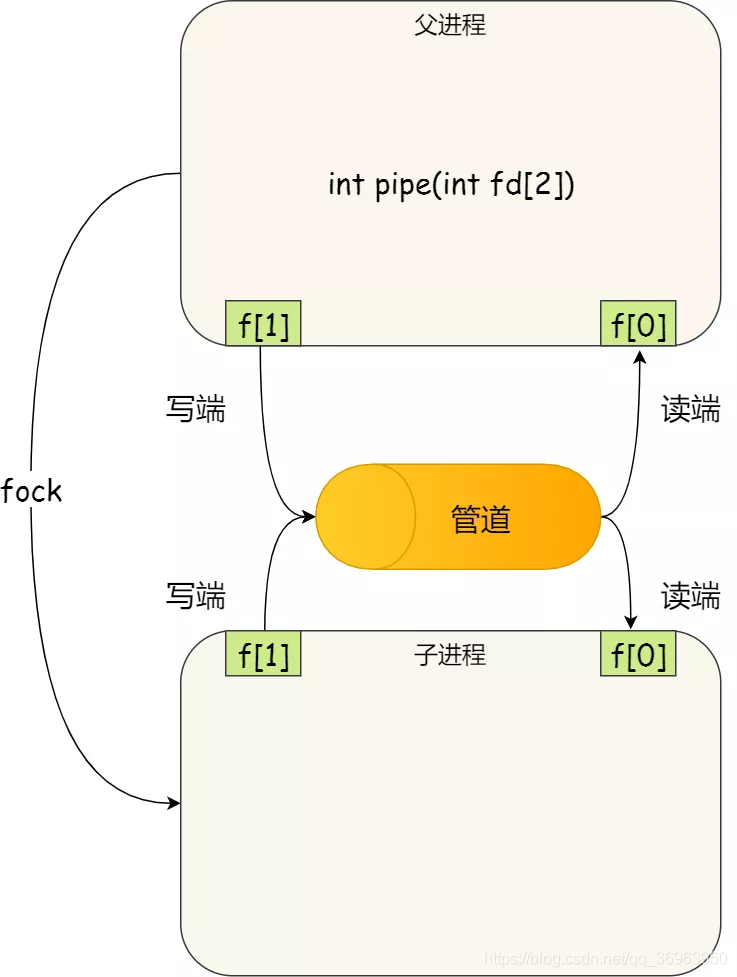
管道只能一端寫入,另一端讀出,所以上面這種模式容易造成混亂,因爲父進程和子進程都可以同時寫入,也都可以讀出。那麼,爲了避免這種情況,通常的做法是:
(1)父進程關閉讀取的 fd[0],只保留寫入的 fd[1];
(2)子進程關閉寫入的 fd[1],只保留讀取的 fd[0];
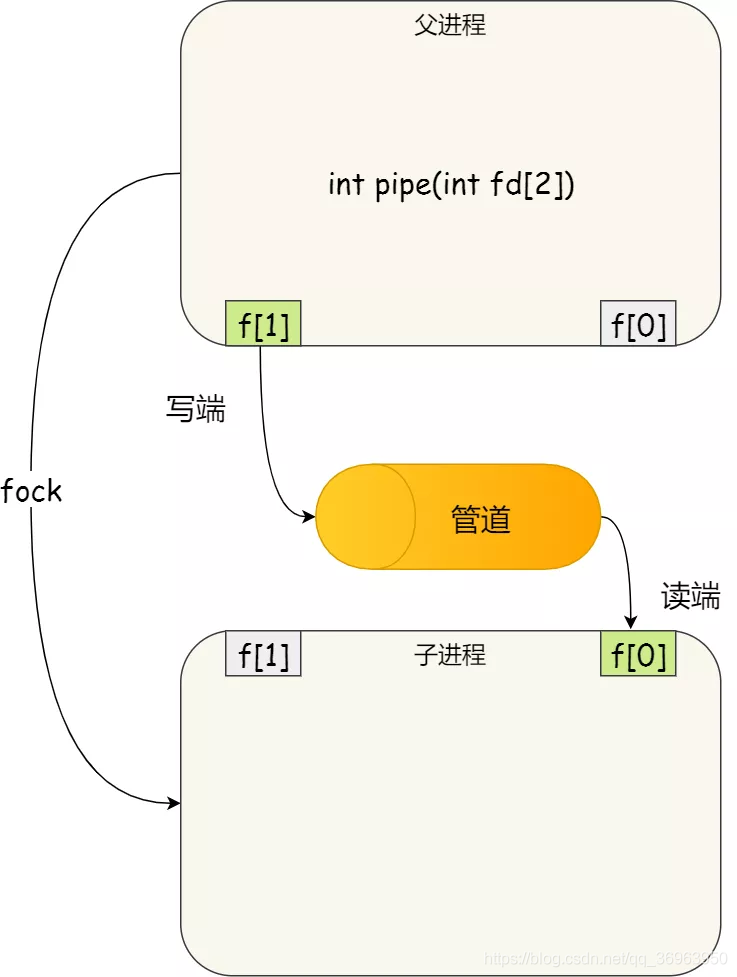
管道雙向通訊就要建立兩個管道
所以說如果需要雙向通訊,則應該建立兩個管道。
到這裏,我們僅僅解析了使用管道進行父進程與子進程之間的通訊,但是在我們 shell 裏面並不是這樣的。
在 shell 裏面執行 A | B命令的時候,A 進程和 B 進程都是 shell 建立出來的子進程,A 和 B 之間不存在父子關係,它倆的父進程都是 shell。
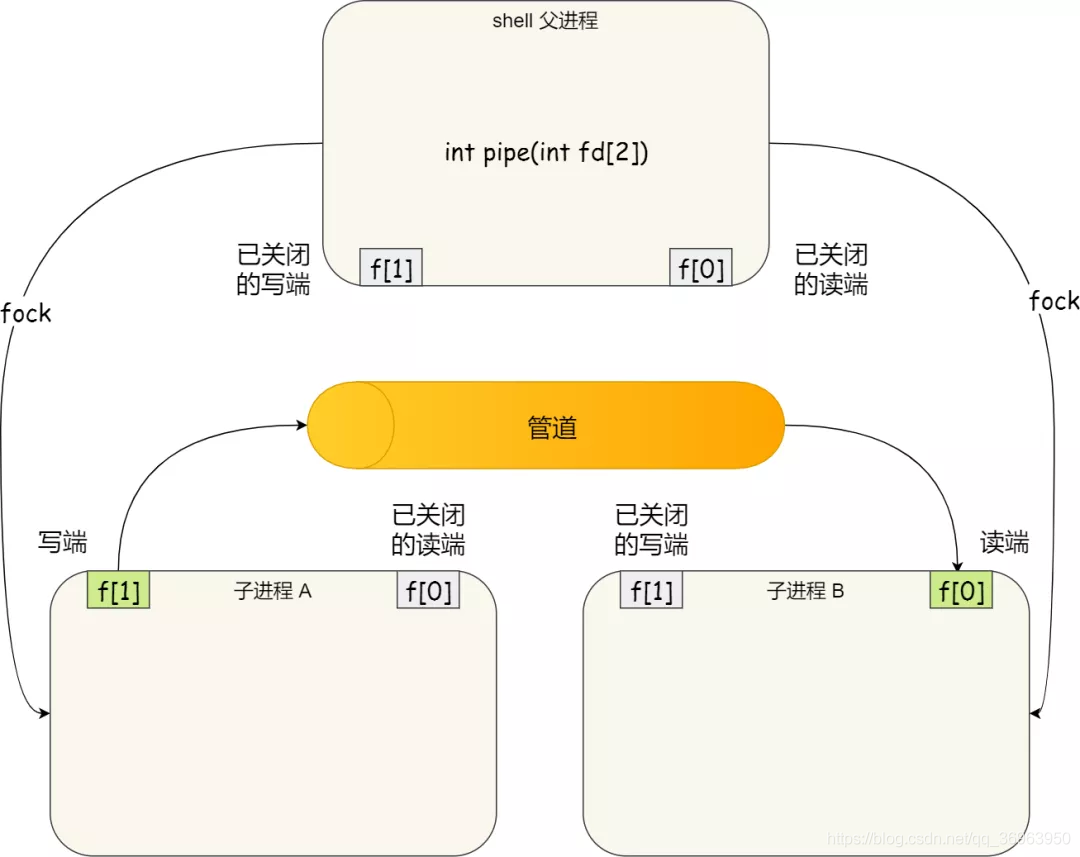
所以說,在 shell 裡通過「|」匿名管道將多個命令連線在一起,實際上也就是建立了多個子進程,那麼在我們編寫 shell 指令碼時,能使用一個管道搞定的事情,就不要多用一個管道,這樣可以減少建立子進程的系統開銷。
我們可以得知,對於匿名管道,它的通訊範圍是存在父子關係的進程。因爲管道沒有實體,也就是沒有管道檔案(匿名管道只存在於記憶體中而不存在檔案系統中,命名管道存在檔案系統中,是一個檔案型別爲p的檔案),只能通過 fork 來複制父進程 fd 檔案描述符,來達到通訊的目的。
另外,對於命名管道,它可以在不相關的進程間也能相互通訊。因爲命令管道,提前建立了一個型別爲管道的裝置檔案,在進程裡只要使用這個裝置檔案,就可以相互通訊。
不管是匿名管道還是命名管道,進程寫入的數據都是快取在內核中,另一個進程讀取數據時候自然也是從內核中獲取,同時通訊數據都遵循先進先出原則,不支援 lseek 之類的檔案定位元運算。
面試官:組織語言闡述進程間通訊管道底層實現 匿名管道(新建、輸入、輸出)
第一,匿名管道的建立
從宏觀命令 | 到底層 int pipe(int fd[2])
進程通過使用 | 命令建立匿名管道,底層,匿名管道建立對應的系統呼叫: int pipe(int fd[2]),這個 int pipe(int fd[2]) 的業務邏輯:
(1)建立一個匿名管道,(2)返回了兩個描述符給呼叫的進程來操作新建建立的管道,一個是管道的讀取端描述符 fd[0],另一個是管道的寫入端描述符 fd[1] 用於該進程對應新建立的管道進行寫操作。
附:新建立的匿名管道到底是個什麼東西?
(1)linux上一切都是檔案,所有這個新建立的管道是一個檔案。
(2)這個新建立的匿名管道是一個特殊的檔案,和一般檔案不同,它只存在於記憶體,不存於檔案系統中,就是一個沒有被持久化的檔案;
(3)這個新建立的匿名管道,本質上是內核裏面的一串快取。從管道的一端寫入的數據,實際上是快取在內核中的,另一端讀取,也就是從內核中讀取這段數據。另外,管道傳輸的數據是無格式的流且大小受限
第二,如何使用這個新建立的匿名管道來實現進程間通訊(匿名管道的輸入輸出)?
key:一個管道的通訊是單向的,所以一個管道只能實現A進程到B進程的單向通訊,要想同時實現A進程和B進程之間的相互通訊,必須在A進程和B進程之間新建兩個管道。
管道的單向通訊的實現(父進程向子進程通訊):
一個進程使用 fork 建立子進程,建立的子進程會複製父進程的檔案描述符,這樣就做到了兩個進程各有兩個「 fd[0] 與 fd[1]」,然後,
父進程關閉讀取的 fd[0],只保留寫入的 fd[1];子進程關閉寫入的 fd[1],只保留讀取的 fd[0];從而實現父子進程之間通訊。
注意:雙向通訊一定要兩個管道。
管道的雙向通訊的實現( | 命令,A進程和B進程之間相互通訊):
所以說如果需要雙向通訊,則應該建立兩個管道,
如果要進程A向進程B通訊,執行命令 A | B
如果要進程B向進程A通訊,執行命令 B | A
值得注意的是,在 shell 裏面執行 A | B命令的時候,如上面將的一個父進程建立一個子進程不是一回事,而是一個父進程shell建立兩個子進程 A 進程和 B 進程
命名管道(建立、輸入、輸出)
命名管道和匿名管道不僅在使用上不同,在底層也是不同的,
不同點1:管道檔案是否持久化到檔案系統中,匿名管道只存在於記憶體中而不存在檔案系統中,命名管道存在檔案系統中,是一個檔案型別爲p的檔案
不同點2:匿名管道,它的通訊範圍是存在父子關係的進程,只能通過 fork 來複制父進程 fd 檔案描述符,來達到通訊的目的( | 命令爲一個父進程建立兩個子進程);命名管道,它可以在不相關的進程間(沒有父子關係的進程)也能相互通訊。因爲命名管道,提前建立了一個型別爲管道的裝置檔案,在進程裡只要使用這個裝置檔案,就可以相互通訊
相同點1:進程寫入的數據都是快取在內核中,另一個進程讀取數據時候自然也是從內核中獲取;
相同點2:通訊數據都遵循先進先出原則,不支援 lseek 之類的檔案定位元運算
四、進程間通訊:訊息佇列
管道通訊的缺陷,引入訊息佇列作爲進程間通訊
管道進程間通訊缺陷:效率低,不適合進程間頻繁地交換數據。
訊息佇列(或者說郵件)作爲進程間通訊方式的優點
1、從一個個訊息發送,到一批批訊息發送來提高效率。對於管道通訊效率低,訊息佇列的通訊模式就可以解決。比如,A 進程要給 B 進程發送訊息,A 進程把數據放在對應的訊息佇列後就可以正常返回了,B 進程需要的時候再去讀取數據就可以了。同理,B 進程要給 A 進程發送訊息也是如此。
從管道到訊息佇列
1、從一個個訊息發送,到一批批訊息發送來提高效率。
2、在提高效率的基礎上,爲保證管道通訊(匿名管道+命名管道)的FIFO不被破壞,數據結構上使用了佇列。
2、固定大小的訊息體而不是無格式位元組流數據:每次發送的是訊息體,是固定大小的儲存塊,不像管道是無格式的位元組流數據。(過程:訊息佇列是儲存在內核中的訊息鏈表,在發送數據時,會分成一個一個獨立的數據單元,也就是訊息體(數據塊),訊息體是使用者自定義的數據型別,訊息的發送方和接收方要約定好訊息體的數據型別,發送方發送訊息體,接收方進程從訊息佇列中讀取訊息體,然後linux內核就會把這個訊息體刪除。)
3、生命週期:對於訊息佇列:訊息佇列生命週期隨內核,如果沒有釋放訊息佇列或者沒有關閉操作系統,訊息佇列會一直存在;對於匿名管道:匿名管道生命週期,是隨進程的建立而建立,隨進程的結束而銷燬。
訊息佇列三個優點:
1、接收進程自己到訊息佇列中取,發送進程放到訊息佇列中就好了,和方式上和管道還是一樣的(A 進程要給 B 進程發送訊息,A 進程把數據放在對應的訊息佇列後就可以正常返回了,B 進程需要的時候再去讀取數據就可以了)
1.1 從一個個訊息發送,到一批批訊息發送來提高效率。
1.2 在提高效率的基礎上,爲保證管道通訊(匿名管道+命名管道)的FIFO不被破壞,數據結構上使用了佇列。
2、固定大小的訊息體而不是無格式位元組流數據
3、生命週期:
對於訊息佇列:訊息佇列生命週期隨內核,如果沒有釋放訊息佇列或者沒有關閉操作系統,訊息佇列會一直存在;
對於匿名管道:匿名管道生命週期,是隨進程的建立而建立,隨進程的結束而銷燬。
訊息這種模型,兩個進程之間的通訊就像平時發郵件一樣,你來一封,我回一封,可以頻繁溝通了。
訊息佇列(或者說郵件)作爲進程間通訊方式的缺陷:
一是通訊不及時,二是附件也有大小限制
linux對於訊息體的大小限制:訊息佇列不適合比較大數據的傳輸,因爲在內核中每個訊息體都有一個最大長度的限制,同時所有佇列所包含的全部訊息體的總長度也是有上限。在 Linux 內核中,會有兩個宏定義 MSGMAX 和 MSGMNB,它們以位元組爲單位,分別定義了一條訊息的最大長度和一個佇列的最大長度。
訊息佇列通訊過程中,存在使用者態與內核態之間的數據拷貝開銷,因爲進程寫入數據到內核中的訊息佇列時,會發生從使用者態拷貝數據到內核態的過程,同理另一進程讀取內核中的訊息數據時,會發生從內核態拷貝數據到使用者態的過程。
訊息佇列兩個缺陷:
1、通訊不及時:類似郵件,接收進程自己到訊息佇列中取,發送進程放到訊息佇列中就好了,如果接收進程不能及時取出訊息體,造成通訊不及時。
1、通訊不及時,使用者態與內核態之間的數據拷貝開銷:兩個通訊進程在使用者態,訊息佇列在內核態,所以,存在使用者態與內核態之間的數據拷貝開銷,因爲進程寫入數據到內核中的訊息佇列時,會發生從使用者態拷貝數據到內核態的過程,同理另一進程讀取內核中的訊息數據時,會發生從內核態拷貝數據到使用者態的過程
2、訊息體大小限制和一個佇列大小限制和全部佇列大小限制:訊息佇列不適合比較大數據的傳輸,因爲在內核中每個訊息體都有一個最大長度的限制,同時所有佇列所包含的全部訊息體的總長度也是有上限
五、進程間通訊:共用記憶體
從訊息佇列的不足到共用記憶體的引入
訊息佇列的讀取和寫入的過程,都會有發生使用者態與內核態之間的訊息拷貝過程。那共用記憶體的方式,就很好的解決了這一問題。
從每個進程獨立的虛擬記憶體空間到共用記憶體
現代操作系統,對於記憶體管理,採用的是虛擬記憶體技術,也就是每個進程都有自己獨立的虛擬記憶體空間,不同進程的虛擬記憶體對映到不同的實體記憶體中。所以,即使進程 A 和 進程 B 的虛擬地址是一樣的,其實存取的是不同的實體記憶體地址,對於數據的增刪查改互不影響。
共用記憶體的機制 機製,就是拿出一塊虛擬地址空間來,對映到相同的實體記憶體中。這樣這個進程寫入的東西,另外一個進程馬上就能看到了,都不需要拷貝來拷貝去,傳來傳去,大大提高了進程間通訊的速度。
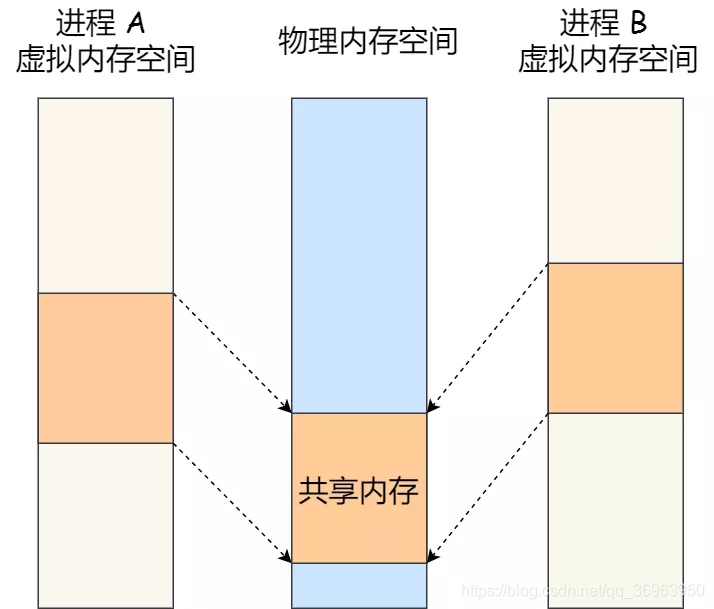
共用記憶體作爲進程間通訊的定義和優點:
1、虛擬記憶體技術:虛擬記憶體=實際記憶體+一部分硬碟;
2、每個進程的虛擬記憶體:每個進程都有自己獨立的虛擬記憶體空間,不同進程的虛擬記憶體對映到不同的實體記憶體中
進程 A 和 進程 B 的虛擬地址是一樣的,其實存取的是不同的實體記憶體地址,對於數據的增刪查改互不影響
3、共用記憶體定義:共用記憶體的機制 機製,就是拿出一塊虛擬地址空間來,對映到相同的實體記憶體中。
4、優點:進程間可見性:一個進程寫入的東西,另外一個進程馬上就能看到了,都不需要拷貝來拷貝去,傳來傳去,大大提高了進程間通訊的速度
六、進程間通訊:號志(處理共用記憶體多進程寫衝突,類似Java中處理共用變數多執行緒寫衝突)
共用記憶體多進程寫衝突,類似Java中處理共用變數多執行緒寫衝突
用了共用記憶體通訊方式,帶來新的問題,那就是如果多個進程同時修改同一個共用記憶體,很有可能就衝突了。例如兩個進程都同時寫一個地址,那先寫的那個進程會發現內容被別人覆蓋了。
共用記憶體多進程寫衝突解決方式:使用號志處理
爲了防止多進程競爭共用資源,而造成的數據錯亂,所以需要保護機制 機製,使得共用的資源,在任意時刻只能被一個進程存取。正好,號志就實現了這一保護機制 機製。
號志PV操作,處理進程同步和進程通訊的基礎
號志實際上是一個整型的計數器,主要用於實現進程間的互斥與同步,而不是用於快取進程間通訊的數據。
號志是一個整型的計數器,主要用於實現進程間的互斥與同步,而不是用於快取進程間通訊的數據
號志表示資源的數量,控制號志的方式有兩種原子操作:
(1)一個是 P 操作,這個操作會把號志減去 -1,相減後如果號志 < 0,則表明資源已被佔用,進程需阻塞等待;相減後如果號志 >= 0,則表明還有資源可使用,進程可正常繼續執行。
(2)另一個是 V 操作,這個操作會把號志加上 1,相加後如果號志 <= 0,則表明當前有阻塞中的進程,於是會將該進程喚醒執行;相加後如果號志 > 0,則表明當前沒有阻塞中的進程;
從Java多執行緒理解PV操作:
P操作完成兩件事,號志減少1,不符合條件則阻塞進程(相對於java中wait()),符合條件不操作。
V操作完成兩件事,號志增加1,呼叫notify(),有阻塞執行緒則喚醒,無阻塞執行緒無用。
P 操作是用在進入共用資源之前,V 操作是作用在離開共用資源之後,這兩個操作是必須成對出現的。
資源號志實現進程同步(資源的互斥存取)
接下來,舉個例子,如果要使得兩個進程互斥存取共用記憶體,爲保證原子性,任意時候只能允許一個進程存取共用記憶體,我們可以初始化號志爲 1。
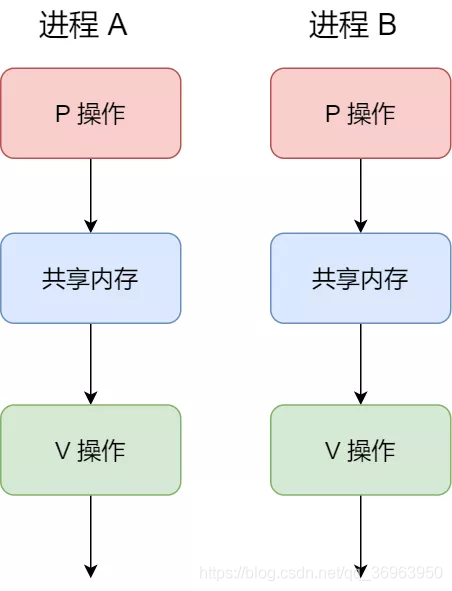
具體的過程如下:
(1)進程 A 在存取共用記憶體前,先執行了 P 操作,由於號志的初始值爲 1,故在進程 A 執行 P 操作後號志變爲 0,表示共用資源可用,於是進程 A 就可以存取共用記憶體。
(2)若此時,進程 B 也想存取共用記憶體,執行了 P 操作,結果號志變爲了 -1,這就意味着臨界資源已被佔用,因此進程 B 被阻塞。
(3)直到進程 A 存取完共用記憶體,纔會執行 V 操作,使得號志恢復爲 0,接着就會喚醒阻塞中的執行緒 B,使得進程 B 可以存取共用記憶體,最後完成共用記憶體的存取後,執行 V 操作,使號志恢復到初始值 1。
可以發現,信號初始化爲 1,就代表着是互斥號志,它可以保證共用記憶體在任何時刻只有一個進程在存取,這就很好的保護了共用記憶體。
通訊號志,進程之間通訊
另外,在多進程裡,每個進程並不一定是順序執行的,它們基本是以各自獨立的、不可預知的速度向前推進,但有時候我們又希望多個進程能密切合作,以實現一個共同的任務。
例如,進程 A 是負責生產數據,而進程 B 是負責讀取數據,這兩個進程是相互合作、相互依賴的,進程 A 必須先生產了數據,進程 B 才能 纔能讀取到數據,所以執行是有前後順序的。
那麼這時候,就可以用號志來實現多進程同步的方式,我們可以初始化號志爲 0。
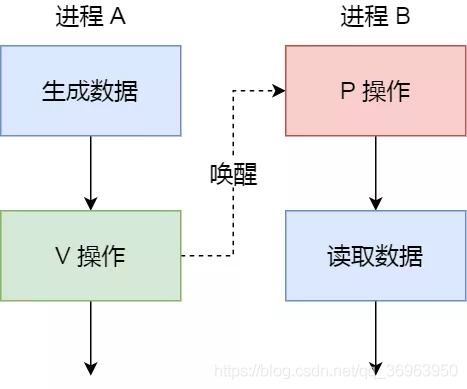
具體過程:
(1)如果進程 B 比進程 A 先執行了,那麼執行到 P 操作時,由於號志初始值爲 0,故號志會變爲 -1,表示進程 A 還沒生產數據,於是進程 B 就阻塞等待wait();
(2)接着,當進程 A 生產完數據後,執行了 V 操作,就會使得號志變爲 0,於是就會喚醒阻塞在 P 操作的進程 B;
(3)最後,進程 B 被喚醒後,意味着進程 A 已經生產了數據,於是進程 B 就可以正常讀取數據了。
可以發現,信號初始化爲 0,就代表着是同步號志,它可以保證進程 A 應在進程 B 之前執行。
P減一併自帶wait
V加一併自帶notify
這裏進程A只有V,沒有P,保證進程A不會阻塞,進程B只有P,沒有V,保證進程B不會喚醒自己,一定要進程A才能 纔能喚醒進程B(因爲只有進程A纔有V操作)
號志小結:
信號初始化爲 1,就代表着是互斥號志,它可以保證共用記憶體在任何時刻只有一個進程在存取
信號初始化爲 0,就代表着是同步號志,它可以保證進程 A 應在進程 B 之前執行
P減一併自帶wait
V加一併自帶notify
這裏進程A只有V,沒有P,保證進程A不會阻塞,進程B只有P,沒有V,保證進程B不會喚醒自己,一定要進程A才能 纔能喚醒進程B(因爲只有進程A纔有V操作)
七、進程間通訊:信號
7.1 信號引入
對於異常情況下的工作模式,就需要用「信號」的方式來通知進程
上面說的進程間通訊,都是常規狀態下的工作模式。對於異常情況下的工作模式,就需要用「信號」的方式來通知進程。
信號跟號志雖然名字相似度 66.66%,但兩者用途完全不一樣,就好像 Java 和 JavaScript 的區別。
在 Linux 操作系統中, 爲了響應各種各樣的事件,提供了幾十種信號,分別代表不同的意義。我們可以通過 kill -l 命令,檢視所有的信號:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
7.2 信號事件的兩種來源
執行在 shell 終端的進程,我們可以通過鍵盤輸入某些組合鍵的時候,給進程發送信號。例如
(1)Ctrl+C 產生 SIGINT 信號,表示終止該進程;
(2)Ctrl+Z 產生 SIGTSTP 信號,表示停止該進程,但還未結束;
如果進程在後台執行,可以通過 kill 命令的方式給進程發送信號,但前提需要知道執行中的進程 PID 號,例如:
kill -9 1050 ,表示給 PID 爲 1050 的進程發送 SIGKILL 信號,用來立即結束該進程;
所以,信號事件的來源主要有硬體來源(如鍵盤 Cltr+C )和軟體來源(如 kill 命令)。
7.3 信號響應的三種方式
信號是進程間通訊機制 機製中唯一的非同步通訊機制 機製,因爲可以在任何時候發送信號給某一進程,一旦有信號產生,我們就有下面 下麪這幾種,使用者進程對信號的處理方式。
-
執行預設操作。Linux 對每種信號都規定了預設操作,例如,上面列表中的 SIGTERM 信號,就是終止進程的意思。Core 的意思是 Core Dump,也即終止進程後,通過 Core Dump 將當前進程的執行狀態儲存在檔案裏面,方便程式設計師事後進行分析問題在哪裏。
-
捕捉信號。我們可以爲信號定義一個信號處理常式。當信號發生時,我們就執行相應的信號處理常式。
-
忽略信號。當我們不希望處理某些信號的時候,就可以忽略該信號,不做任何處理。有兩個信號是應用進程無法捕捉和忽略的,只能執行預設操作,即 SIGKILL 和 SEGSTOP,它們用於在任何時候中斷或結束某一進程。
小結:
信號定義:對於異常情況下的工作模式,就需要用「信號」的方式來通知進程。
信號兩種來源:信號事件的來源主要有硬體來源(如鍵盤 Cltr+C )和軟體來源(如 kill 命令)。
信號三種響應:
信號是進程間通訊機制 機製中唯一的非同步通訊機制 機製,因爲可以在任何時候發送信號給某一進程,一旦有信號產生,我們就有下面 下麪這幾種,使用者進程對信號的處理方式。
- 執行預設操作。Linux 對每種信號都規定了預設操作,直接執行信號預設操作。
- 捕捉信號。我們可以爲信號定義一個信號處理常式。當信號發生時,我們就執行相應的信號處理常式。
- 忽略信號。當我們不希望處理某些信號的時候,就可以忽略該信號,不做任何處理。有兩個信號是應用進程無法捕捉和忽略的,只能執行預設操作,即 SIGKILL 和 SEGSTOP,它們用於在任何時候中斷或結束某一進程。
八、跨網路不同主機之間進程通訊:Socket
8.1 Socket通訊的系統呼叫(int socket(int domain, int type, int protocal),前兩個參數有用)
爲什麼需要Socket,Socket的意義?
前面提到的管道、訊息佇列、共用記憶體、號志和信號都是在同一臺主機上進行進程間通訊,那要想跨網路與不同主機上的進程之間通訊,就需要 Socket 通訊了。
實際上,Socket 通訊不僅可以跨網路與不同主機的進程間通訊,還可以在同主機上進程間通訊。
我們來看看建立 socket 的系統呼叫:
int socket(int domain, int type, int protocal)
三個參數分別代表:
(1)第一個參數 domain 參數用來指定協定族,
AF_INET 用於 IPV4、
AF_INET6 用於 IPV6、(暫時不用)
AF_LOCAL/AF_UNIX 用於本機;
(2)第二個參數 type 參數用來指定通訊特性,
SOCK_STREAM 表示的是位元組流 對應 TCP,
SOCK_DGRAM 表示的是數據報 對應 UDP,
SOCK_RAW 表示的是原始通訊端;(沒用過)
(3)第三個參數 protocal 參數原本是用來指定通訊協定的,但現在基本廢棄。因爲協定已經通過前面兩個參數指定完成,protocol 目前一般寫成 0 即可;
根據建立 socket 型別的不同,通訊的方式也就不同:
(1)不同主機的進程之間遠端通訊:實現 TCP 位元組流通訊:socket 型別是 AF_INET (第一個參數domain ipv4)和 SOCK_STREAM(第二個參數type TCP);
(2)不同主機的進程之間遠端通訊:實現 UDP 數據報通訊:socket 型別是 AF_INET (第一個參數domain ipv4)和 SOCK_DGRAM (第二個參數type UDP);
(3)同一主機的進程之間本地通訊:實現本地進程間通訊:
「本地位元組流 socket 」型別是 AF_LOCAL (第一個參數 domain 本機)和 SOCK_STREAM(第二個參數type tcp),
「本地數據報 socket 」型別是 AF_LOCAL (第一參數domain 本機)和 SOCK_DGRAM(第二個參數type udp)。
另外,AF_UNIX 和 AF_LOCAL 是等價的,所以 AF_UNIX 也屬於本地 socket;
小結:
Socket通訊的系統呼叫(int socket(int domain, int type, int protocal),前兩個參數有用
第一個參數domain AF_INET 用於 IPV4、 AF_LOCAL/AF_UNIX 用於本機;
第二個參數type SOCK_STREAM 表示的是位元組流 對應 TCP、SOCK_DGRAM 表示的是數據報 對應 UDP;
兩兩組合四種情況。
接下來,簡單說一下這三種通訊的程式設計模式。
8.2 針對 TCP 協定通訊的 socket 程式設計模型
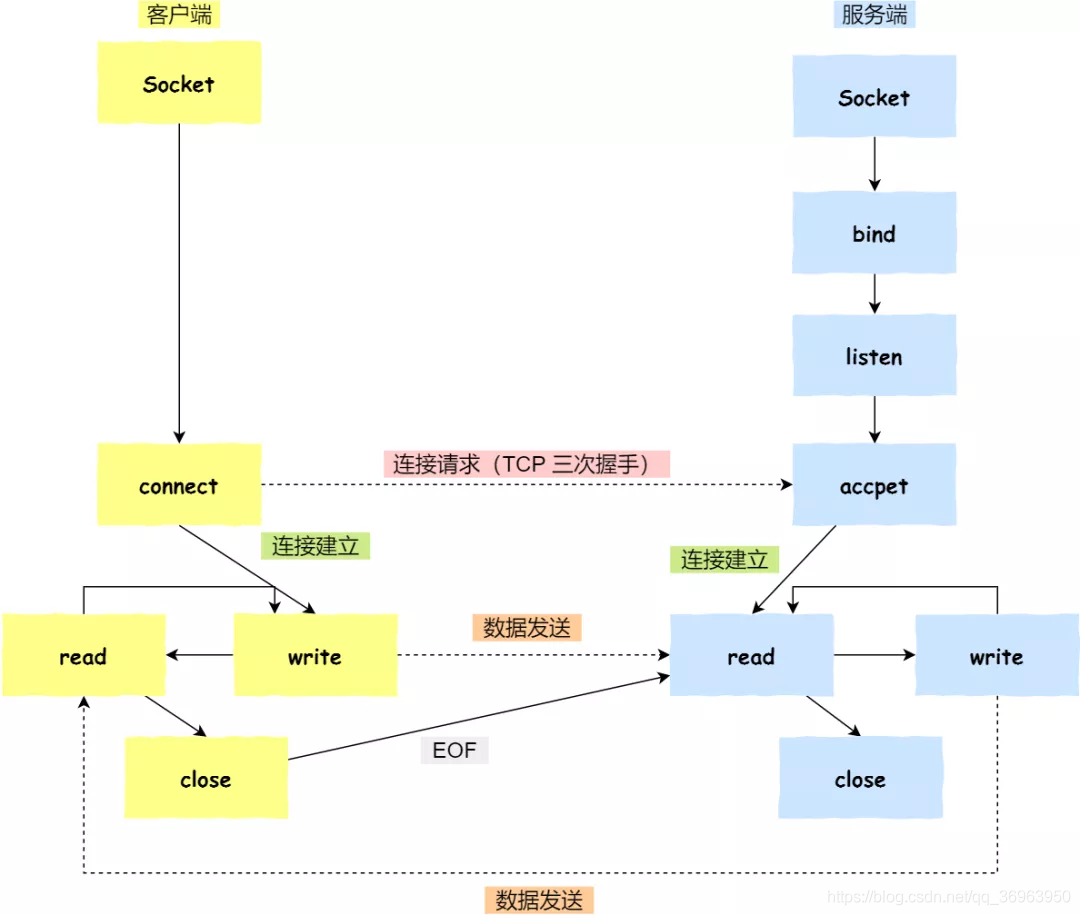
(1)伺服器端和用戶端初始化 socket,得到檔案描述符;
(2)伺服器端呼叫 bind,將系結在 IP 地址和埠;
(3)伺服器端呼叫 listen,進行監聽;(事件注入事件觸發者、事件監聽注入事件,保證事件發生時,監聽者執行相關操作)
(4)伺服器端呼叫 accept,等待用戶端連線;(伺服器端阻塞)
(5)用戶端呼叫 connect,向伺服器端的地址和埠發起連線請求;
(6)伺服器端 accept 返回用於傳輸的 socket 的檔案描述符;
(7)用戶端呼叫 write 寫入數據;伺服器端呼叫 read 讀取數據;
(8)用戶端斷開連線時,會呼叫 close,那麼伺服器端 read 讀取數據的時候,就會讀取到了 EOF,待處理完數據後(金手指:這就是爲什麼建立連線要三個報文,但是釋放連線要四個報文的原因,因爲釋放的時候另一端不一定處理完成了,要等待),伺服器端呼叫 close,表示連線關閉。
注意1:兩個socket,伺服器端呼叫 accept 時,連線成功了會返回一個已完成連線的 socket,後續用來傳輸數據。所以,監聽的 socket 和真正用來傳送數據的 socket,是「兩個」 socket,一個叫作監聽 socket,一個叫作已完成連線 socket。
注意2:雙方都是read write,所以上圖中類似回圈:成功連線建立之後,雙方開始通過 read 和 write 函數來讀寫數據,就像往一個檔案流裏面寫東西一樣。
8.3 針對 UDP 協定通訊的 socket 程式設計模型
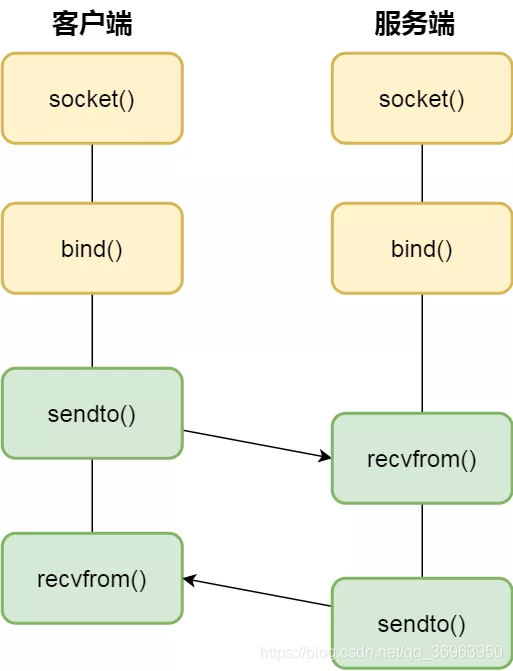
UDP 是沒有連線的,所以不需要三次握手,也就不需要像 TCP 呼叫 listen 和 connect,但是 UDP 的互動仍然需要 IP 地址和埠號,因此也需要 bind。
對於 UDP 來說,不需要要維護連線,那麼也就沒有所謂的發送方和接收方,甚至都不存在用戶端和伺服器端的概念,只要有一個 socket 多臺機器就可以任意通訊,因此每一個 UDP 的 socket 都需要 bind。
另外,每次通訊時,呼叫 sendto 和 recvfrom,都要傳入目標主機的 IP 地址和埠。
8.4 針對本地進程間通訊的 socket 程式設計模型
本地 socket 被用於在同一臺主機上進程間通訊的場景:
(1)本地 socket 的程式設計介面和 IPv4 、IPv6 通訊端程式設計介面是一致的,可以支援「位元組流」和「數據報」兩種協定;
(2)本地 socket 的實現效率大大高於 IPv4 和 IPv6 的位元組流、數據報 socket 實現;
對於本地位元組流 socket,其 socket 型別是 AF_LOCAL 和 SOCK_STREAM。
對於本地數據報 socket,其 socket 型別是 AF_LOCAL 和 SOCK_DGRAM。
本地位元組流 socket 和 本地數據報 socket 在 bind 的時候,不像 TCP 和 UDP 要系結 IP 地址和埠,而是系結一個本地檔案,這也就是它們之間的最大區別。
九、面試金手指(面試語言組織,需要背下來的東西)
9.0 進程間通訊
爲什麼要進程間通訊?如何實現進程間通訊?
每個進程的使用者空間都是獨立的,不能互相存取的,不能通訊;但是他們的內核空間是每個進程都共用的,可以通訊,所以進程之間要通訊必須通過內核。
進程間通訊的方式有哪些?
進程間通訊方式包括:管道、訊息佇列、共用記憶體、號志、信號、Socket
9.1 管道
面試官:介紹一下管道通訊?
第一,管道包括兩種,匿名管道和命名管道。
匿名管道(管道新建、管道輸入、管道輸出)
匿名管道就是命令列中的 | ,| 前面的輸出是 | 後面內容的輸入,這樣就使用匿名管道完成了進程間通訊。
一句小結匿名管道:| 新建管道,| 前面的輸出的管道的輸入,然後管道將內容輸出到 | 後面的進程去。
windows和linux都適用
windows如:netstat -ano|findStr 8080
Linux如:ps auxf | grep mysql
命名管道(管道新建、管道輸入、管道輸出):
一句話總結:
$ mkfifo myPipe // 新建命名管道
$ echo 「hello」 > myPipe // 命名管道輸入
$ cat < myPipe // 命名管道輸出
第二,linux中一切都是檔案,管道也是檔案,管道是型別爲p的檔案。
第三,管道作爲一種進程間通訊方式的優缺點。
缺點:效率低,不適合進程間頻繁地交換數據。
優點:簡單,我們很容易得知管道裡的數據已經被另一個進程讀取了。
面試官:組織語言闡述進程間通訊管道底層實現 匿名管道(新建、輸入、輸出)
第一,匿名管道的建立
從宏觀命令 | 到底層 int pipe(int fd[2])
進程通過使用 | 命令建立匿名管道,底層,匿名管道建立對應的系統呼叫: int pipe(int fd[2]),這個 int pipe(int fd[2]) 的業務邏輯:
(1)建立一個匿名管道,(2)返回了兩個描述符給呼叫的進程來操作新建建立的管道,一個是管道的讀取端描述符 fd[0],另一個是管道的寫入端描述符 fd[1] 用於該進程對應新建立的管道進行寫操作。
附:新建立的匿名管道到底是個什麼東西?
(1)linux上一切都是檔案,所有這個新建立的管道是一個檔案。
(2)這個新建立的匿名管道是一個特殊的檔案,和一般檔案不同,它只存在於記憶體,不存於檔案系統中,就是一個沒有被持久化的檔案;
(3)這個新建立的匿名管道,本質上是內核裏面的一串快取。從管道的一端寫入的數據,實際上是快取在內核中的,另一端讀取,也就是從內核中讀取這段數據。另外,管道傳輸的數據是無格式的流且大小受限
第二,如何使用這個新建立的匿名管道來實現進程間通訊(匿名管道的輸入輸出)?
key:一個管道的通訊是單向的,所以一個管道只能實現A進程到B進程的單向通訊,要想同時實現A進程和B進程之間的相互通訊,必須在A進程和B進程之間新建兩個管道。
管道的單向通訊的實現(父進程向子進程通訊):
一個進程使用 fork 建立子進程,建立的子進程會複製父進程的檔案描述符,這樣就做到了兩個進程各有兩個「 fd[0] 與 fd[1]」,然後,
父進程關閉讀取的 fd[0],只保留寫入的 fd[1];子進程關閉寫入的 fd[1],只保留讀取的 fd[0];從而實現父子進程之間通訊。
注意:雙向通訊一定要兩個管道。
管道的雙向通訊的實現( | 命令,A進程和B進程之間相互通訊):
所以說如果需要雙向通訊,則應該建立兩個管道,
如果要進程A向進程B通訊,執行命令 A | B
如果要進程B向進程A通訊,執行命令 B | A
值得注意的是,在 shell 裏面執行 A | B命令的時候,如上面將的一個父進程建立一個子進程不是一回事,而是一個父進程shell建立兩個子進程 A 進程和 B 進程
命名管道(建立、輸入、輸出)
命名管道和匿名管道不僅在使用上不同,在底層也是不同的,
不同點1:管道檔案是否持久化到檔案系統中,匿名管道只存在於記憶體中而不存在檔案系統中,命名管道存在檔案系統中,是一個檔案型別爲p的檔案
不同點2:匿名管道,它的通訊範圍是存在父子關係的進程,只能通過 fork 來複制父進程 fd 檔案描述符,來達到通訊的目的( | 命令爲一個父進程建立兩個子進程);命名管道,它可以在不相關的進程間(沒有父子關係的進程)也能相互通訊。因爲命名管道,提前建立了一個型別爲管道的裝置檔案,在進程裡只要使用這個裝置檔案,就可以相互通訊
相同點1:進程寫入的數據都是快取在內核中,另一個進程讀取數據時候自然也是從內核中獲取;
相同點2:通訊數據都遵循先進先出原則,不支援 lseek 之類的檔案定位元運算
9.2 訊息佇列
訊息佇列的通訊流程?
訊息佇列實際上是儲存在內核的「訊息鏈表」,訊息佇列的訊息體是可以使用者自定義的數據型別,發送數據時,會被分成一個一個獨立的訊息體,當然接收數據時,也要與發送方發送的訊息體的數據型別保持一致,這樣才能 纔能保證讀取的數據是正確的。
訊息佇列三個優點:
1、接收進程自己到訊息佇列中取,發送進程放到訊息佇列中就好了,和方式上和管道還是一樣的(A 進程要給 B 進程發送訊息,A 進程把數據放在對應的訊息佇列後就可以正常返回了,B 進程需要的時候再去讀取數據就可以了)
1.1 從一個個訊息發送,到一批批訊息發送來提高效率。
1.2 在提高效率的基礎上,爲保證管道通訊(匿名管道+命名管道)的FIFO不被破壞,數據結構上使用了佇列。
2、固定大小的訊息體而不是無格式位元組流數據
3、生命週期:
對於訊息佇列:訊息佇列生命週期隨內核,如果沒有釋放訊息佇列或者沒有關閉操作系統,訊息佇列會一直存在;
對於匿名管道:匿名管道生命週期,是隨進程的建立而建立,隨進程的結束而銷燬。
訊息佇列兩個缺陷:
1、通訊不及時:類似郵件,接收進程自己到訊息佇列中取,發送進程放到訊息佇列中就好了,如果接收進程不能及時取出訊息體,造成通訊不及時。
1、通訊不及時,使用者態與內核態之間的數據拷貝開銷:兩個通訊進程在使用者態,訊息佇列在內核態,所以,存在使用者態與內核態之間的數據拷貝開銷,因爲進程寫入數據到內核中的訊息佇列時,會發生從使用者態拷貝數據到內核態的過程,同理另一進程讀取內核中的訊息數據時,會發生從內核態拷貝數據到使用者態的過程
2、訊息體大小限制和一個佇列大小限制和全部佇列大小限制:訊息佇列不適合比較大數據的傳輸,因爲在內核中每個訊息體都有一個最大長度的限制,同時所有佇列所包含的全部訊息體的總長度也是有上限
9.3 共用記憶體
過渡問題:共用記憶體是如何處理訊息佇列的缺陷的(使用者態與內核態之間切換開銷)?
共用記憶體可以解決訊息佇列通訊中使用者態與內核態之間數據拷貝過程帶來的開銷,它直接分配一個共用空間,每個進程都可以直接存取,就像存取進程自己的空間一樣快捷方便,不需要陷入內核態或者系統呼叫,大大提高了通訊的速度,享有最快的進程間通訊方式之名。但是便捷高效的共用記憶體通訊,帶來新的問題,多進程競爭同個共用資源會造成數據的錯亂。
共用記憶體作爲進程間通訊的定義和優點:
1、虛擬記憶體技術:虛擬記憶體=實際記憶體+一部分硬碟;
2、每個進程的虛擬記憶體:每個進程都有自己獨立的虛擬記憶體空間,不同進程的虛擬記憶體對映到不同的實體記憶體中
進程 A 和 進程 B 的虛擬地址是一樣的,其實存取的是不同的實體記憶體地址,對於數據的增刪查改互不影響
3、共用記憶體定義:共用記憶體的機制 機製,就是拿出一塊虛擬地址空間來,對映到相同的實體記憶體中。
4、優點:進程間可見性:一個進程寫入的東西,另外一個進程馬上就能看到了,都不需要拷貝來拷貝去,傳來傳去,大大提高了進程間通訊的速度
9.4 號志(共用記憶體的補充)
過渡問題:號志如何處理共用記憶體的多進程寫問題? 號志保護共用資源,以確保任何時刻只能有一個進程存取共用資源,這種方式就是互斥存取。
號志小結:
信號初始化爲 1,就代表着是互斥號志,它可以保證共用記憶體在任何時刻只有一個進程在存取
信號初始化爲 0,就代表着是同步號志,它可以保證進程 A 應在進程 B 之前執行
P減一併自帶wait
V加一併自帶notify
這裏進程A只有V,沒有P,保證進程A不會阻塞,進程B只有P,沒有V,保證進程B不會喚醒自己,一定要進程A才能 纔能喚醒進程B(因爲只有進程A纔有V操作)
9.5 信號(共用記憶體的補充)
小結:
信號定義:對於異常情況下的工作模式,就需要用「信號」的方式來通知進程,信號是進程間通訊機制 機製中唯一的非同步通訊機制 機製,信號可以在應用進程和內核之間直接互動,內核也可以利用信號來通知使用者空間的進程發生了哪些系統事件。
信號兩種來源:信號事件的來源主要有硬體來源(如鍵盤 Cltr+C )和軟體來源(如 kill 命令)。
信號三種響應:
在任何時候發送信號給某一進程,一旦有信號產生,我們就有幾種使用者進程對信號的處理方式:
- 執行預設操作。Linux 對每種信號都規定了預設操作,直接執行信號預設操作。
- 捕捉信號。我們可以爲信號定義一個信號處理常式。當信號發生時,我們就執行相應的信號處理常式。
- 忽略信號。當我們不希望處理某些信號的時候,就可以忽略該信號,不做任何處理。有兩個信號是應用進程無法捕捉和忽略的,只能執行預設操作,即 SIGKILL 和 SEGSTOP,它們用於在任何時候中斷或結束某一進程。
9.6 Socket通訊
Socket 第一種情況
Socket通訊的系統呼叫(int socket(int domain, int type, int protocal),前兩個參數有用
第一個參數domain AF_INET 用於 IPV4、 AF_LOCAL/AF_UNIX 用於本機;
第二個參數type SOCK_STREAM 表示的是位元組流 對應 TCP、SOCK_DGRAM 表示的是數據報 對應 UDP;
兩兩組合四種情況。
Socket 不僅用於不同的主機進程間通訊,還可以用於本地主機進程間通訊,可根據建立 Socket 的型別不同,分爲三種常見的通訊方式,一個是基於 TCP 協定的通訊方式,一個是基於 UDP 協定的通訊方式,一個是本地進程間通訊方式。
(1)伺服器端和用戶端初始化 socket,得到檔案描述符;
(2)伺服器端呼叫 bind,將系結在 IP 地址和埠;
(3)伺服器端呼叫 listen,進行監聽;(事件注入事件觸發者、事件監聽注入事件,保證事件發生時,監聽者執行相關操作)
(4)伺服器端呼叫 accept,等待用戶端連線;(伺服器端阻塞)
(5)用戶端呼叫 connect,向伺服器端的地址和埠發起連線請求;
(6)伺服器端 accept 返回用於傳輸的 socket 的檔案描述符;
(7)用戶端呼叫 write 寫入數據;伺服器端呼叫 read 讀取數據;
(8)用戶端斷開連線時,會呼叫 close,那麼伺服器端 read 讀取數據的時候,就會讀取到了 EOF,待處理完數據後(金手指:這就是爲什麼建立連線要三個報文,但是釋放連線要四個報文的原因,因爲釋放的時候另一端不一定處理完成了,要等待),伺服器端呼叫 close,表示連線關閉。
注意1:兩個socket,伺服器端呼叫 accept 時,連線成功了會返回一個已完成連線的 socket,後續用來傳輸數據。所以,監聽的 socket 和真正用來傳送數據的 socket,是「兩個」 socket,一個叫作監聽 socket,一個叫作已完成連線 socket。
注意2:雙方都是read write,所以上圖中類似回圈:成功連線建立之後,雙方開始通過 read 和 write 函數來讀寫數據,就像往一個檔案流裏面寫東西一樣。
1、bind:UDP 是沒有連線的,所以不需要三次握手,也就不需要像 TCP 呼叫 listen 和 connect,但是 UDP 的互動仍然需要 IP 地址和埠號,因此也需要 bind。
2、每一個 UDP 的 socket 都需要 bind:對於 UDP 來說,不需要要維護連線,那麼也就沒有所謂的發送方和接收方,甚至都不存在用戶端和伺服器端的概念,只要有一個 socket 多臺機器就可以任意通訊,因此每一個 UDP 的 socket 都需要 bind。
3、sendto和recvfrom:每次通訊時,呼叫 sendto 和 recvfrom,都要傳入目標主機的 IP 地址和埠。
本地 socket 被用於在同一臺主機上進程間通訊的場景:
(1)本地 socket 的程式設計介面和 IPv4 、IPv6 通訊端程式設計介面是一致的,可以支援「位元組流」和「數據報」兩種協定;
(2)本地 socket 的實現效率大大高於 IPv4 和 IPv6 的位元組流、數據報 socket 實現;
對於本地位元組流 socket,其 socket 型別是 AF_LOCAL 和 SOCK_STREAM。
對於本地數據報 socket,其 socket 型別是 AF_LOCAL 和 SOCK_DGRAM。
本地位元組流 socket 和 本地數據報 socket 在 bind 的時候,不像 TCP 和 UDP 要系結 IP 地址和埠,而是系結一個本地檔案,這也就是它們之間的最大區別。
9.7 附加問題:執行緒間通訊
附加問題:執行緒之間通訊?
同個進程下的執行緒之間都是共用進程的資源,只要是共用變數都可以做到執行緒間通訊,比如全域性變數,所以對於執行緒間關注的不是通訊方式,而是關注多執行緒競爭共用資源的問題,號志也同樣可以線上程間實現互斥與同步:互斥的方式,可保證任意時刻只有一個執行緒存取共用資源;
同步的方式,可保證執行緒 A 應線上程 B 之前執行;
十、小結
談一談你對進程間通訊的理解?完成了。
天天打碼,天天進步!!!
參考:https://mp.weixin.qq.com/s?__biz=MzAwNDA2OTM1Ng==&mid=2453145217&idx=2&sn=9f7e20a4837c11870a8e715f43b993d4&chksm=8cfd2402bb8aad140f0958bb38c136c5e3d552101e1d3fc620be4012458ed2e0f85ba4abe955&scene=126&sessionid=1597023041&key=041bb01ba83758f981a9a7a6d18865c8f728e62d55ebca0c7b7219674dbe59af84ea6e9d1ebc3abd0a11545da81ef344d3a24103e2d67c0cca4d71e871d3d9a063eb0497bccf0eb571d919e3f98fb92b&ascene=1&uin=MjA2MzM0NTY2OA%3D%3D&devicetype=Windows+10+x64&version=62090529&lang=zh_CN&exportkey=A%2FA%2BA47b95JZt7y5A8XYBw8%3D&pass_ticket=5U5MXaGCShax3W0jxUiaVzq7r8yGJHn3sG4s%2FbqJbwFUMKOY7%2F4ho8k8kZa7IJmM