MySQL基礎(二)查詢語句知識點彙總
查詢語句知識點彙總
一、基礎查詢
基本語法爲:
SELECT 查詢列表 FROM 表名
其中,查詢列表可以是:表中欄位、常數值、表達式、函數;查詢的結果是一個虛擬的表格。
一些小tips:
1.可以用着重號 ''來區分欄位和關鍵字
2.經常會使用DISTINCT 去重
3.起別名:既可以使用as,也可以使用空格
# 使用as起別名
SELECT * FROM employees AS e;
# 使用空格起別名
SELECT * FROM employees e;
4.+的作用:運算子
- 兩個運算元都爲數值型,則做加法運算
- 若其中一方爲字元型,則嘗試將字元型數值轉換成數值型,轉換成功則繼續做運算,失敗則轉換爲0
- 只要一方爲null,結果肯定爲null
二、條件查詢
SELECT 查詢列表 第③步
FROM 表名 第①步
WHERE 篩選條件 第②步
篩選條件分類:
- 按條件表達式篩選:=、!=、<>、<=、>=、<、>
- 按邏輯表達式篩選:&&(and) 、||(or)、!(not)
- 模糊查詢:
- like:通常搭配萬用字元(%代表任意多個字元,包含0個字元;_代表任意單個字元)
- between and :包含臨界值
- in :列表內的值型別必須一致或相容
- is null、is not null
# 查詢名字中帶字母a的員工的所有資訊
SELECT * FROM employees
WHERE last_name LIKE '%a%';
# 查詢員工名中第二個字元爲_的員工名
SELECT last_name FROM employees
WHERE last_name LIKE '_\_%'; # 這裏的\起到的是跳脫的作用
三、排序查詢
SELECT 查詢列表 第③步
FROM 表名 第①步
[WHERE 篩選條件] 第②步
ORDER BY 排序列表 [DESC/ASC] 第④步
特點:
1.預設asc升序排列
2.order by 支援單個欄位、多個欄位、表達式、別名、函數
3.order by一般放在查詢語句的最後面,LIMIT子句除外
四、常見函數
需要掌握函數名、函數功能以及具有使用方法。
4.1 單行函數
4.1.1 字元函數
- length():獲取參數值的位元組個數
值得注意的是,該函數獲取的是位元組的個數;utf8下一個英文字母佔1個位元組,一個漢字佔3個位元組;gbk下一個漢字佔2個位元組
SELECT LENGTH('MySQL');
# 5
# 檢視字元集
SHOW VARIABLES LIKE ‘%char%’;
# 若用戶端的字元集爲utf8
SELECT LENGTH('數據庫');
# 9
- concat(str1, str2, …) :拼接
# 將員工的first_name和last_name用‘_’進行連線
SELECT CONCAT('first_name','_','last_name') output
FROM employees;
- upper()/lower():將字串中的小/大寫全轉換成大/小寫
SELECT UPPER('mysQL') output;
# MYSQL
SELECT LOWER('MYSQL') output;
# mysql
- substr/substring(str,起始索引,擷取長度):擷取指定索引下的字元
這裏,有一點需要注意一下:索引是從1開始的
SELECT SUBSTR('查詢語句知識點彙總',1,4) output;
# 查詢語句
SELECT SUBSTR('查詢語句知識點彙總',8) output;
# 彙總
- instr(str1,str2):返回子串第一次出現的索引,如果找不到,返回0
SELECT INSTR('查詢語句知識點彙總','彙總') output;
# 7
- trim():去除前後空格,也可去除指定字元
SELECT TRIM('a' from ' 數據庫 ') output;
# 數據庫
SELECT TRIM('a' from 'aaaa數aaaa據庫aaaa') output;
# 數aaaa據庫
SELECT TRIM('a' from 'aaaa數aaaa據庫AAAAA') output;
# 數aaaa據庫AAAAA
- lpad(str,指定長度,指定字元):用指定的字元實現左填充,使填充後的字串達到指定長度,rpad同理
SELECT LPAD('數',3,'*') output;
# 數**
SELECT LPAD('數據庫',2,'*') output;
# 數據
- replace(str,需要被替換的字串,替換的字串):替換
SELECT REPLACE('我愛學習','學習','看電視') output;
# 我愛看電視
4.1.2 數學函數
- rand():獲取亂數,返回0-1之間的小數
SELECT RAND();
# 0.36748154868137234
- round():四捨五入
# 保留兩位小數
SELECT ROUND(1.567, 2);
# 1.57
- ceil():向上取整,返回>=該參數的最小整數
floor():向下取整,返回<=該參數的最大整數
# 在0-99間隨機抽取一個整數
SELECT FLOOR(RAND()* 100);
# 在1-100間隨機抽取一個整數
SELECT CEIL(RAND()* 100);
- truncate():截斷
SELECT TRUNCATE(1.699999,1);
# 1.6
- mod(a, b):取餘;a爲被除數,b爲除數。等價於%
mod(a, b) = a - a/b*b
SELECT mod(10,3);
# 1
SELECT mod(-10,-3); # -10-(-10)/(-3)*(-3) = -1
# -1
SELECT mod(10,-3); # 10-(10)/(-3)*(-3) = 1
# 1
4.1.3 日期函數
- now(): 返回當前系統的日期+時間
- curdate(): 返回當前系統的日期,不包含時間
- curtime(): 返回當前時間
SELECT NOW();
# 2020-08-05T08:32:45Z
SELECT CURDATE();
# 2020-08-05
SELECT CURTIME();
# 08:35:20
- year()/month()/day()/hour()/minute()/second():獲取指定部分的年/月/日/小時/分鐘/秒
SELECT MONTH(NOW()) 月;
# 8
SELECT MONTHNAME(NOW()) 月; #monthname以英文的形式返回月
# August
- str_to_date(): 將日期格式的字元轉換成指定格式的日期
SELECT STR_TO_DATE('8-20-2050','%m-%d-%Y');
# 2050-08-20
- date_format(): 將日期轉換成字元
SELECT DATE_FORMAT(NOW(),'%y年%m月%d日') output;
# 20年08月05日
- datediff(date1, date2): 計算兩個日期之間的天數
其中,datediff()函數對時間差值的計算方式爲date1-date2
SELECT DATEDIFF('2020-06-05','2020-08-05') output;
# -61
4.1.4 其他函數
- version(): 檢視MySQL的版本型別,等價於
SHOW VARIABLES LIKE 'VERSION'; - database(): 檢視當前所使用的數據庫
- user(): 檢視當前登錄的使用者
4.1.5 流程控制函數
- if 函數
SELECT IF(10>5, '大', '小');
# 大
- case 函數
case可以搭配select充當表達式,也可以單獨作爲語句。
- 等值判斷
CASE 要判斷的欄位或表達式
WHEN 常數1 THEN 要顯示的值1或語句1
WHEN 常數2 THEN 要顯示的值2或語句2
......
[ELSE 要顯示的值n或語句n] <--- 可省略
END
【例】
SELECT salary 原始工資, department_id,
CASE department_id
WHEN 30 THEN salary*1.1
WHEN 40 THEN salary*1.2
WHEN 50 THEN salary*1.3
ELSE salary
END 新工資
FROM employees;
- 區間判斷
CASE
WHEN 條件1 THEN 要顯示的值1或語句1
WHEN 條件2 THEN 要顯示的值2或語句2
......
ELSE 要顯示的值n或語句n
END
【例】
CASE
WHEN score >= 90 THEN '優秀'
WHEN score >= 70 THEN '良好'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END
4.2 分組函數 (也稱爲聚合函數/統計函數/組函數)
| sum() | avg() | max() | min() | count() |
|---|---|---|---|---|
| 求和 | 求平均 | 求最大值 | 求最小值 | 統計個數 |
特點:
- sum()、avg()一般用於處理數值型;而max()、min()、count()可處理任何型別
- 以上5個函數都忽略null值
- 均可以與distinct搭配使用
- 統計總行數:
SELECT COUNT(*) FROM table1;或者SELECT COUNT(常數值,一般爲1) FROM table1; - 和分組函數一同查詢的欄位有限制:和分組函數一同查詢的欄位要求是group by後的欄位
五、分組查詢
SELECT 分組函數, 列(要求出現在group by的後面) 第④步
FROM 表名 第①步
[WHERE 篩選條件] 第②步
GROUP BY 需要分組的列 第③步
[ORDER BY子句] 第⑤步
特點:
- 分組查詢中的篩選條件分爲兩類
| 數據源 | 位置 | 關鍵字 | |
|---|---|---|---|
| 分組前篩選 | 原始表 | group by前 | where |
| 分組後篩選 | 分組後的結果集 | group by後 | having |
- 分組函數條件肯定是放在having子句中
- 能用分組前篩選的儘量在分組前篩
- group by子句支援單個、多個欄位分段(逗號隔開,沒有順序)
六、連線查詢(多表查詢)
6.1 笛卡爾乘積現象
當查詢的欄位來自於多個表時,就會用到連線查詢。
當表與表之間沒有建立有效的連線條件時,就會出現笛卡爾乘積現象,即表1m行,表2n行,結果將產生一個麼m*n行的表。
下面 下麪舉個例子,大家來直觀地感受一下笛卡爾乘積現象。
假設有兩張表,具體如下:
表6.1: 人物表authors
| id | author_name | sex | born_date | book_id |
|---|---|---|---|---|
| 1 | 林徽因 | 女 | 1904-6 | 2 |
| 2 | 楊絳 | 女 | 1911-7 | 1 |
表6.2: 作品表books
| id | book_name | publishing_date |
|---|---|---|
| 1 | 幹校六記 | 1981 |
| 2 | 你是人間四月天 | 2005 |
現在想要查詢作者及其作品名,我們期望得到的是:
| author_name | book_name |
|---|---|
| 林徽因 | 你是人間四月天 |
| 楊絳 | 幹校六記 |
但如果直接使用SELECT author_name, book_name FROM authors,books;對兩個表進行查詢,就相當於拿着表1的每一行記錄去依次匹配表2的每一行記錄,則會得到:
| author_name | book_name |
|---|---|
| 林徽因 | 你是人間四月天 |
| 林徽因 | 幹校六記 |
| 楊絳 | 你是人間四月天 |
| 楊絳 | 幹校六記 |
結果顯然與實際不符,這就是一個典型的笛卡爾乘積錯誤現象。
6.2 連線查詢的分類
按功能分類:
- 內連線:等值連線、非等值連線、自連線
- 外連線:左外連線、右外連線、全外連線(MySQL不支援)
- 交叉連線
按年代分類:
- sql92標準(只支援內連線)
- sql99標準
sql92 vs sql99:
功能:99支援的功能更多
可讀性:99實現了連線條件和篩選條件的分離,可讀性較高
因此,一般較爲推薦使用99語法。
6.2.1 sql92標準語法
我們先簡單瞭解一下92語法:
SELECT 查詢列表
FROM 表1名, 表2名
WHERE 連線條件;
接着,直接來看例子吧,先來個等值連線的。
沿用表6.1、6.2的數據,我們現在想要查詢作者及其作品名,則可以寫成:
SELECT a.author_name, b.book_name
FROM authors a,books b
WHERE a.book_id = b.id;
是不是很容易?
再來看一個非等值連線的例子。
依舊假設有兩張表,一張是學生成績表grade,一張是成績等級表grade_level,具體內容如下:
表6.3: 學生成績表grade
| stu_name | grade |
|---|---|
| 小明 | 98 |
| 小剛 | 86 |
| 小強 | 72 |
| 小新 | 48 |
表6.4: 成績等級表grade_level
| grade_level | lowest_grade | highest_grade |
|---|---|---|
| A | 90 | 100 |
| B | 70 | 89 |
| C | 60 | 69 |
| D | 0 | 59 |
現在我們想要查詢每個學生的成績及其等級,這就用到了非等值查詢,我們可以寫:
SELECT stu_name,grade,grade_level
FROM grade g, grade_level gl
WHERE grade BETWEEN gl.lowest_grade AND gl.highest_grade;
即可得到結果如下:
| stu_name | grade | grade_level |
|---|---|---|
| 小明 | 98 | A |
| 小剛 | 86 | B |
| 小強 | 72 | B |
| 小新 | 48 | D |
最後,來看看自連線。
這次只有一張表:員工表employees,表中有三個欄位:employee_ id員工編號、name員工姓名、manager_id上級經理編號。現在想要查詢的是員工名,以及其上級經理的名字。
| employee_ id | name | manager_id |
|---|---|---|
| 1 | 小紅 | NULL |
| 2 | 小橙 | 1 |
| 3 | 小黃 | 1 |
| 4 | 小綠 | 3 |
| 5 | 小青 | 2 |
| 6 | 小藍 | 4 |
| 7 | 小紫 | 3 |
想要查詢員工上級的名字,即先找到員工對應上級的編號manager_id(第一次用員工表employees,記作表1)。找到對應上級編號manager_id後,拿着這個編號去比對員工編號employee_ id和name(第二次用員工表employees,記作表2),這就涉及到一表複用,即自連線。
我們可以看到,在第一次用員工表employees時,該表中的employee_ id被看作的是普通員工編號;在第二次用這個表的時候,是將表中的employee_ id當作是擔任上級的員工編號。而這兩張表之間的連線條件就在於,表1中的上級編號manager_id等於表2中的員工編號employee_ id。
所以,我們可以得到具體過程,如下:
SELECT e.name 員工名, m.name 領導名
FROM employees e, employees m #此處可以看出起別名的好處,可以清楚地看到我們將前表當成的是普通員工表,後一張表代表的是經理表
WHERE e.manager_id = m.employee_id;
最終結果爲:
| 員工名 | 領導名 |
|---|---|
| 小橙 | 小紅 |
| 小黃 | 小紅 |
| 小綠 | 小黃 |
| 小青 | 小橙 |
| 小藍 | 小綠 |
| 小紫 | 小黃 |
6.2.2 sql99標準語法
看完了92語法,下面 下麪我們瞅瞅99語法下的連線查詢,其具體語法如下:
SELECT 查詢列表 第⑦步
FROM 表1 別名 第①步
[連線型別] JOIN 表2 別名 第②步
ON 連線條件 第③步
WHERE 篩選條件 第④步
GROUP BY 分組 第⑤步
HAVING 篩選條件 第⑥步
ORDER BY 排序列表 第⑧步
語法中的連線型別主要如下:
1.內連線:inner
- 等值連線(inner可省略)
- 非等值連線
- 自連線
由於上面在92語法中分別舉過例子,只是語法上有些許變化,這裏就不贅述了。
接下來,一起來看一下92語法並不支援的外連線。
2.外連線:用於查詢一個表中有但一個表中沒有的記錄。 那個有記錄的表爲主表,沒有記錄的則爲從表。
- 左外連線:left [outer]
- 右外連線:right [outer]
- 全外連線:full [outer] (MySQL不支援)
特點:
1.外連線的查詢結果爲主表中的所有記錄,如果從表中有和它匹配的,則顯示匹配的值,如果從表中沒有和它匹配的,則顯示null值。所以,可以列出公式:外連線查詢的結果 = 內連線結果+主表中有而從表中沒有的結果
2.left左邊的是主表,right右邊的是主表
3.交換左外連線表的順序,效果與右外連線一致,右外連線同理
4.全外連線 = 內連線的結果+表1中有但表2沒有的結果+表2中有但表1中沒有的結果
老規矩,繼續上個例子吧。
繼續以作家6.1和作品6.2這兩張表爲例,先將這兩張表擴充點記錄吧,如下:
表6.1(續): 人物表authors
| id | author_name | sex | born_date | book_id |
|---|---|---|---|---|
| 1 | 林徽因 | 女 | 1904-6 | 2 |
| 2 | 楊絳 | 女 | 1911-7 | 1 |
| 3 | 畢淑敏 | 女 | 1952-10 | 3 |
| 4 | 鐵凝 | 女 | 1957-9 | 6 |
| 5 | 嚴歌苓 | 女 | 1958-11 | 9 |
| 6 | 遲子建 | 女 | 1964-2 | 4 |
表6.2(續): 作品表books
| id | book_name | publishing_date |
|---|---|---|
| 1 | 幹校六記 | 1981 |
| 2 | 你是人間四月天 | 2005 |
| 3 | 藍色天堂 | 2011 |
| 4 | 羣山之巔 | 2015 |
現想要查詢作品 不在作品表books中 的作家的名字。
我們在做外連線的時候,最關鍵的一點就在於確定哪張表是主表。在這道題中很容易看出人物表爲主表,如果一下子看不出的小夥伴,可以記住一個技巧:找題目的中心詞,看最終想要查詢的物件是誰。你要查詢的資訊主要來自於哪個表,誰就是主表。
以這個例題爲例,我們最終想要查詢的是作家的名字,而作家的名字顯然是來自於人物表authors,所以根據我們上面所說的你要查詢的資訊主要來自於哪個表,誰就是主表可以確定人物表authors爲主表。
確定完主表authors,若我們選擇左外連線,就將該表放在join左邊,若選擇的是右外連線,就將其放在右邊。
寫好連線條件後,即得到authors表中欄位作家名 author_name的所有記錄,根據之前提及到的外連線特點1可知,作品表books中有和人物表authors匹配的,則顯示匹配的值,若無,則返回null。得到結果如下:
| author_name | id | book_name |
|---|---|---|
| 林徽因 | 2 | 你是人間四月天 |
| 楊絳 | 1 | 幹校六記 |
| 畢淑敏 | 3 | 藍色天堂 |
| 鐵凝 | NULL | NULL |
| 嚴歌苓 | NULL | NULL |
| 遲子建 | 4 | 羣山之巔 |
通過這個大致的結果表可以更加直觀地看到上述的結果。第一列欄位來自主表authors,保留着其中的所有條記錄;後兩列欄位均來自從表books,在連線條件下,有匹配的欄位顯示相應的對應值,沒有找到匹配欄位的呢,則整條記錄顯示爲null。
有了以上的結果,再來看題目想讓我們查詢的東西:作品不在作品表裏 的作家。換種說法就是在人物表中匹配不到的作家,顯而易見,一個is null就可以解決了。
重頭梳理一遍,我們可以得到整個查詢過程,如下(以左外連線爲例,右外連線同理):
SELECT a.author_name
FROM authors a
LEFT [OUTER] JOIN books b #outer一般可省略
ON a.book_id = b.id
WHERE b.id IS NULL;
3.交叉連線: cross
交叉連線,相當於6.1所說的笛卡爾乘積,這裏也不再贅述了。
以上,已解鎖全部的連線查詢內容啦~
七、子查詢
下面 下麪我們一起來看看,查詢語句中較爲複雜點的一類查詢:子查詢。
含義:出現在其他語句中的select語句,稱爲子查詢或內查詢。
這裏的其他語句是指,子查詢不僅僅可以用在select語句中,增刪改中均可以使用。
與子查詢(或稱爲內查詢)相對應,外部的查詢語句(即包含着子查詢的語句)稱爲主查詢(或稱爲外查詢)。
子查詢的分類:
1.按結果集的行列數不同:
- 標量子查詢(結果集只有一行一列)
- 列子查詢(結果集只有一列多行)
- 行子查詢(結果集有一行多列或多行多列)
- 表子查詢(結果集一般爲多行多列)
2.按照子查詢出現的位置:
- select 後面:僅僅支援標量子查詢
- from 後面:支援表子查詢
- where或having後面:支援標量子查詢、列子查詢、行子查詢(不常用)
- exists後面(相關子查詢):支援表子查詢
7.1 where或having後面
由於where或having後面接的子查詢更多常見普遍,是子查詢中的重點,因此,我們就首先來看看放在該關鍵字後的子查詢。
特點:
1.子查詢放在小括號內
2.子查詢一般放在條件的右側
3.標量子查詢,一般搭配着單行操作符(<、>、>=、<=、=、<>)使用
列子查詢,一般搭配着多行操作符(IN、ANY/SOME、ALL)使用
4.子查詢的執行優於主查詢的執行,主查詢的條件用到了子查詢的結果
太抽象?看個例子叭。
【 例1 - 標量子查詢 】
以表6.3學生成績表grade爲數據,查詢誰的成績比小強高。
表6.3:學生成績表grade
| stu_name | grade |
|---|---|
| 小明 | 98 |
| 小剛 | 86 |
| 小強 | 72 |
| 小新 | 48 |
首先第一步,我們需要查詢出小強的成績:
SELECT grade
FROM grade
WHERE stu_name = '小強'
很容易得到結果,爲:
| grade |
|---|
| 72 |
可以看到,得到的結果集一行一列,這就是我們所說的標量子查詢。
接着,我們需要查詢哪個學生的成績大於我們上一步所查到的成績,可以這樣寫:
SELECT stu_name
FROM grade
WHERE grade > (
SELECT grade
FROM grade
WHERE stu_name = '小強'
);
這就是一個子查詢。
【 例2 - 標量子查詢 】
再來看一個用在having後面的子查詢的例子。
假設有一張成績表,包含學生名、班級名、成績等欄位,具體如下:
表7.1: 成績表grades
| stu_name | class_id | score |
|---|---|---|
| 小七 | 2 | 98 |
| 小寶 | 2 | 91 |
| 小琉 | 1 | 86 |
| 小璃 | 3 | 72 |
| 小塔 | 1 | 65 |
| 小小 | 3 | 72 |
| 小宗 | 3 | 72 |
| 小主 | 1 | 65 |
我們現在想要查詢,最低分大於一班最低分的班級id和其最低分。
第一步,我們應該查出一班的最低分是多少,這肯定是個一行一列的值叭,查詢如下:
SELECT MIN(score)
FROM grades
WHERE class_id = 1
第二步,我們是不是應該查詢每個班級的最低分,即:
SELECT MIN(score)
FROM grades
GROUP BY class_id
最後,我們基於第二步的結果進行篩選,篩選出最低分大於第一步的結果,查詢如下:
SELECT class_id, MIN(score)
FROM grades
GROUP BY class_id
HAVING MIN(score) > (
SELECT MIN(score)
FROM grades
WHERE class_id = 1
);
【例3 - 列子查詢】
在上面特點3中提到,列子查詢,一般搭配着多行操作符(IN、ANY/SOME、ALL)使用。所以在看例子前,我們先來簡單看一下多行比較操作符的含義是啥。
| 多行比較操作符 | 含義 |
|---|---|
| IN / NOT IN | 等於列表中的任意一個 |
| ANY / SOME | 和子查詢返回的某一個值比較 |
| ALL | 和子查詢返回的所有值比較 |
懵懵的?來看道題吧。
表7.2: 學生表students
| stu_id | stu_name | class_id | score |
|---|---|---|---|
| 202001 | 小三 | 2 | 98 |
| 202002 | 小五 | 5 | 86 |
| 202003 | 小奧 | 1 | 97 |
| 202004 | 小榮 | 3 | 72 |
| 202005 | 小竹 | 1 | 94 |
| 202006 | 小戴 | 3 | 94 |
| 202007 | 小俊 | 4 | 81 |
| 202008 | 小娜 | 2 | 96 |
| 202009 | 小清 | 1 | 98 |
| 202010 | 小昊 | 3 | 87 |
| 202011 | 小銀 | 4 | 66 |
表7.3: 班級評級表class_level
| class_id | level |
|---|---|
| 1 | A |
| 2 | B |
| 3 | A |
| 4 | C |
| 5 | B |
查詢A類班或B類班所有學生的姓名。
第一步,我們先要查到A類班或B類班的班級編號class_id。
SELECT class_id
FROM class_level
WHERE level IN ('A','B')
不難看出,以上查詢得到的結果爲一列多行,即包含一個欄位class_id,多行記錄1,2,3,5。這就是上面所說的列子查詢。
第二步,基於第一步的結果,查詢結果集班級中所有學生的姓名。
SELECT stu_name
FROM students
WHERE class_id IN (
SELECT class_id
FROM class_level
WHERE level IN ('A','B')
);
這就是一個簡單的列子查詢。
【例4 - 列子查詢】
以表7.2爲數據,繼續來看道題。
查詢其他班級中比三班任一學生成績低的學生的姓名及成績。
第一步,先查三班所有學生的成績。
SELECT DISTINCT score
FROM students
WHERE class_id = 3
第二步,再查學生名、成績,要求成績小於any(三班所有學生的成績,即第一步的結果)。
SELECT stu_name, score
FROM students
WHERE score < ANY(
SELECT DISTINCT score
FROM students
WHERE class_id = 3
) AND class_id <> 3;
最終的查詢結果爲:
| stu_name | score |
|---|---|
| 小五 | 86 |
| 小俊 | 81 |
| 小銀 | 66 |
當然,此處主要是爲了練習一下any的用法, 其實我們也可以不用any,只要去查詢score小於三班最高分的學生即可。
7.2 select後面
select後面只支援標量子查詢,直接來看道題吧。
依舊以表7.2和7.3爲源數據,查詢各等級的下的學生人數。
第一步,查詢班級的等級和學生人數。其中班級等級來源於表class_level,學生人數來源於表students,我們可以寫出框架,如下:
SELECT cl.*, (
SELECT COUNT(*)
FROM students
) 學生人數
FROM class_level cl
執行一下,我們可以得到結果:
| class_id | level | 學生人數 |
|---|---|---|
| 1 | A | 11 |
| 2 | B | 11 |
| 3 | A | 11 |
| 4 | C | 11 |
| 5 | B | 11 |
顯然,學生人數的值是錯誤的,我們想要得到的是各等級下的學生人數,而現在返回的是總人數。出現錯誤的原因是,我們的子查詢中並沒有建立起與主查詢的聯繫。所以,我們接下來要做的是,在子查詢裏面做一個篩選,讓我查詢的班級號正好等於等級表中的班級。
SELECT cl.*, (
SELECT COUNT(*)
FROM students s
WHERE s.class_id = cl.class_id
) 學生人數
FROM class_level cl;
再次執行一下,我們可以得到結果:
| class_id | level | 學生人數 |
|---|---|---|
| 1 | A | 3 |
| 2 | B | 2 |
| 3 | A | 3 |
| 4 | C | 2 |
| 5 | B | 1 |
嗯?距離我們想要的結果還差一點。
現在得到的學生人數還只是每個班級下的人數,我們想要得到的是各等級下的人數,所有還需要將學生人數按照等級進行彙總。
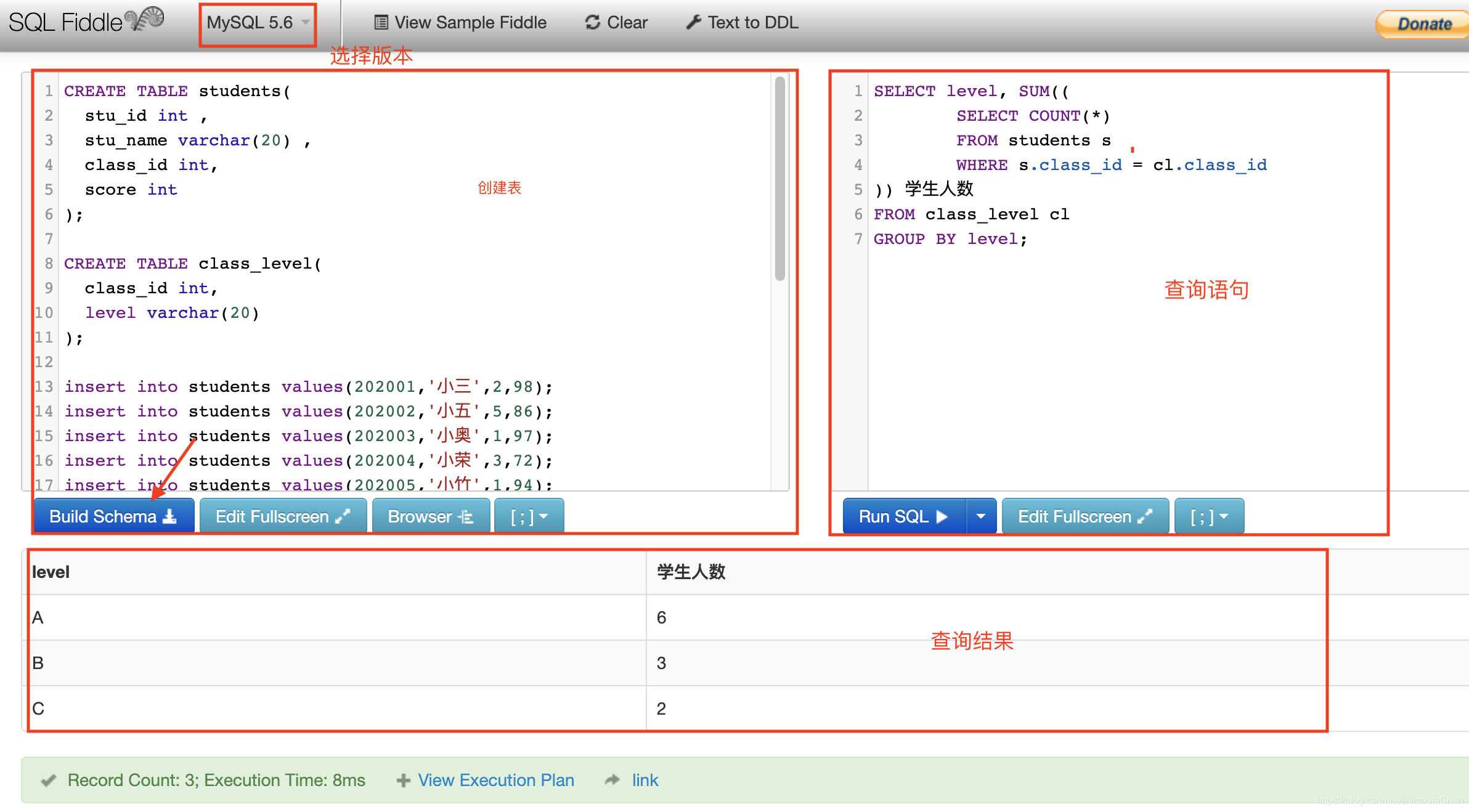
SELECT level, SUM((
SELECT COUNT(*)
FROM students s
WHERE s.class_id = cl.class_id
)) 學生人數
FROM class_level cl
GROUP BY level;
可得到最終結果:
| level | 學生人數 |
|---|---|
| A | 6 |
| B | 3 |
| C | 2 |
7.3 from後面
from後面子查詢得到的結果集,實際上就是被當作表來使用,因此必須起別名。具體幾行幾列都是可以的,主要是看需求。
繼續來看個例子。
此處,我們需要用到表7.2和表6.4。
查詢每個班級平均分的等級。
表7.2: 學生表students
| stu_id | stu_name | class_id | score |
|---|---|---|---|
| 202001 | 小三 | 2 | 98 |
| 202002 | 小五 | 5 | 86 |
| 202003 | 小奧 | 1 | 97 |
| 202004 | 小榮 | 3 | 72 |
| 202005 | 小竹 | 1 | 94 |
| 202006 | 小戴 | 3 | 94 |
| 202007 | 小俊 | 4 | 81 |
| 202008 | 小娜 | 2 | 96 |
| 202009 | 小清 | 1 | 98 |
| 202010 | 小昊 | 3 | 87 |
| 202011 | 小銀 | 4 | 66 |
表6.4: 成績等級表grade_level
| grade_level | lowest_grade | highest_grade |
|---|---|---|
| A | 90 | 100 |
| B | 70 | 89 |
| C | 60 | 69 |
| D | 0 | 59 |
第一步,查詢每個班級的平均分。
SELECT AVG(score),class_id
FROM students
GROUP BY class_id
第二步,將第一步的結果集與成績等級表grade_level連線,篩選條件爲平均分between最低分lowest_grade and 最高分highest_grad,即可得到我們想要的結果,具體查詢過程如下:
SELECT avg_score.class_id, gl.grade_level
FROM (
SELECT AVG(score) ag, class_id
FROM students
GROUP BY class_id
) avg_score #必須起別名,否則後面如何表示這個結果集,如何知道是這個「表」
INNER JOIN grade_level gl
ON avg_score.ag BETWEEN gl.lowest_grade AND gl.highest_grade;
7.4 exists後面(相關子查詢)
具體的語法:exists(完整的查詢語句)
結果:0 或 1
作用:判斷查詢結果中是否有值,有則返回1,沒有則返回0
需要注意一下的是,不同於之前的三種子查詢,exists後面的子查詢的執行是後於主查詢的,是對主查詢結果的一個篩選。
來看個例子吧,此處使用表6.1(續)、6.2(續)的數據。
表6.1(續): 人物表authors
| id | author_name | sex | born_date | book_id |
|---|---|---|---|---|
| 1 | 林徽因 | 女 | 1904-6 | 2 |
| 2 | 楊絳 | 女 | 1911-7 | 1 |
| 3 | 畢淑敏 | 女 | 1952-10 | 3 |
| 4 | 鐵凝 | 女 | 1957-9 | 6 |
| 5 | 嚴歌苓 | 女 | 1958-11 | 9 |
| 6 | 遲子建 | 女 | 1964-2 | 4 |
表6.2(續): 作品表books
| id | book_name | publishing_date |
|---|---|---|
| 1 | 幹校六記 | 1981 |
| 2 | 你是人間四月天 | 2005 |
| 3 | 藍色天堂 | 2011 |
| 4 | 羣山之巔 | 2015 |
想要查詢有作品的人物名,我們可以這樣寫:
SELECT author_name
FROM authors a
WHERE EXISTS(
SELECT *
FROM books b
WHERE a.book_id = b.id
);
當然,我們也可以用in來替代exists,如下:
SELECT author_name
FROM authors a
WHERE a.book_id IN (
SELECT b.id
FROM books b
);
以上,已解鎖全部的子查詢內容啦~
八、分頁查詢
當要顯示的數據一頁顯示不全時,就需要分頁提交sql請求。
SELECT 查詢列表 第⑦步
FROM 表1 第①步
[連線條件] JOIN 表2 第②步
ON 連線條件 第③步
WHERE 篩選條件 第④步
GROUP BY 需要分組的列 第⑤步
HAVING 篩選條件 第⑥步
ORDER BY子句 第⑧步
LIMIT [offset],size 第⑨步
# offset表示的是:要顯示條目的索引數(從0開始)
# size表示的是:要顯示的條目個數
特點:
1.limit語句放在查詢語句的最後
2.要顯示N頁,已知每頁的條目數爲size,則可使用公式LIMIT (N-1)*size ,size;
九、聯合查詢
當我們想要查詢的結果來自於多個表,且多個表沒有直接的連線關係,但是查詢的資訊是一致的時候,我們通常會使用聯合查詢。使用關鍵字union將多條查詢語句的結果合併成一個結果。具體語法如下:
查詢語句1
UNION
查詢語句2
UNION
...
特點:
1.要求多條查詢語句的查詢列數是一致的
2.要求多條查詢語句查詢的每一列的型別和順序最好一致
3.union關鍵字預設去重,如果使用union all 可以包含重複項
下面 下麪再一起來看個例子,近距離感受一下聯合查詢的魅力吧。假設現有兩個班級的成績表,如下:
表9.1: 一班的成績表class1
| stu_id | stu_name | sex | grade |
|---|---|---|---|
| 1 | 小明 | 男 | 98 |
| 2 | 小黃 | 女 | 91 |
| 3 | 小剛 | 男 | 86 |
| 4 | 小強 | 男 | 72 |
| 5 | 小知 | 男 | 65 |
| 6 | 小新 | 女 | 48 |
表9.2: 二班的成績表class2
| id | s_name | score |
|---|---|---|
| 01 | 小紅 | 100 |
| 02 | 小黃 | 91 |
| 03 | 小藍 | 84 |
| 04 | 小綠 | 71 |
想要查詢一下這兩個班成績在90分以上的學生,給出姓名與成績
SELECT stu_name, grade FROM class1 WHERE grade > 90
UNION
SELECT s_name, score FROM class2 WHERE score >90;
查詢結果如下:
| stu_name | grade |
|---|---|
| 小明 | 98 |
| 小黃 | 91 |
| 小紅 | 100 |
細心的小夥伴會注意到,一班和二班的學生名和成績所使用的欄位名是不一樣的,在結果中使用的是一班的欄位名作爲聯合表的欄位名。所以,可以看見,在使用union進行聯合查詢時,欄位名是預設爲第一條語句的欄位名的。
此外,還有小夥伴可能還會發現,一班和二班都有個叫小黃的學生,並且成績都超過90分,但是在結果中卻只出現了一個小黃的記錄。所以,還有一點要記住的是,union是預設去重的。當我們需要包含重複項時,可以選擇使用union all關鍵字,語法類似,比如說這裏我們應該寫成:
SELECT stu_name, grade FROM class1 WHERE grade > 90
UNION ALL
SELECT s_name, score FROM class2 WHERE score >90;
好了,以上便是DQL數據查詢語言中最最基礎的全部內容啦~
最後,給大家推薦一個SQL線上練習平臺:http://sqlfiddle.com/。以上所有內容均可以在這個平臺上,自行建立表執行檢視。無需註冊簡單易操作,支援多類SQL語言,是個寶藏網站啦,蓋戳~
附該網頁圖: