注意力機制 機製的分類 | Soft Attention和Hard Attention
在前面兩節的內容中我們已經介紹了注意力機制 機製的實現原理,在這節內容中我們講一講有關於注意力機制 機製的幾個變種:
Soft Attention和Hard Attention
我們常用的Attention即爲Soft Attention,每個權重取值範圍爲[0,1]
對於Hard Attention來說,每個key的注意力只會取0或者1,也就是說我們只會令某幾個特定的key有注意力,且權重均爲1。
Global Attention和Local Attention
一般不特殊說明的話,我們採用的Attention都是GlobalAttention。根據原始的Attention機制 機製,每個解碼時刻,並不限制解碼狀態的個數,而是可以動態適配編碼器長度,從而匹配所有的編碼器狀態。下面 下麪是模型示意圖:
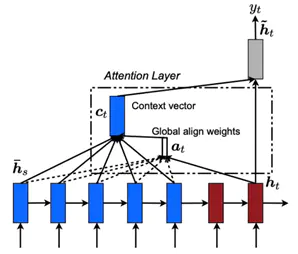
在長文字中我們對整個編碼器長度進行對齊匹配,可以會導致注意力不集中的問題,因此我們通過限制注意力機制 機製的範圍,令注意力機制 機製更加有效。
在LocalAttention中,每個解碼器的ht對應一個編碼器位置pt,選定區間大小D(一般是根據經驗來選的),進而在編碼器的[pt-D,pt+D]位置使用Attention機制 機製,根據選擇的pt不同,又可以把Local Attention分爲Local-m和Local-p兩種。
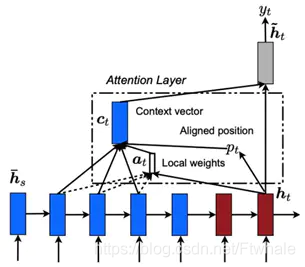
圖 LocalAttention
Local-m:簡單設定pt爲ht對應位置:
Pt= t
Local-p:利用ht預測pt,進而使用高斯分佈使得Local Attention的權重以pt呈現峯值形狀。
Hierarchical Attention
Hierarchical Attention也可以用來解決長文字注意力不集中的問題,與Local Attention不同的是,Local Attention強行限制了注意力機制 機製的範圍,忽略剩餘位置;
而Hierarchical Attention使用分層思想,在所有的狀態上都利用了注意力機制 機製,示意圖如下:
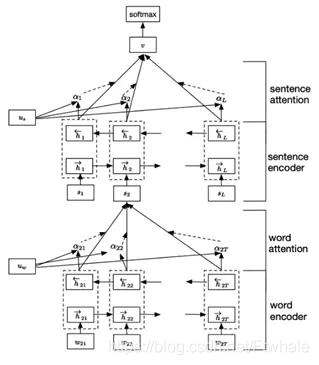
圖 HierarchicalAttention
在長文字中,文字由多個句子組成,句子由多個詞語組成。在這樣的思路中,首先分別在各個句子中使用注意力機制 機製,提取出每個句子的關鍵資訊,進而對每個句子的關鍵資訊使用注意力機制 機製,提取出文字的關鍵資訊,最終利用文字的關鍵資訊進行篇章及文字分類,公式如下:
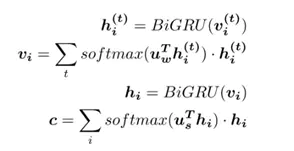
Attention Over Attention
Attention Over Attention的基本思想是對Attention的結果再Attention一次,但是具體步驟和Hierarchical Attention不同。
在AttentionOver Attention中,第一次Attention的結果是獲得一個權重矩陣,兩個維度分別是請求長度和文字長度,橫軸和縱軸分別代表一方對另一方的注意力分佈。對文字長度進行均值歸一化得出和請求長度相同的注意力平均分佈向量;在請求長度上歸一化,則可以表示文字中各個詞關於請求的注意力分佈矩陣。
在第二次Attention中,我們用第一次Attention的兩個結果再次求Attention權重,可以得到一個關於閱讀文字的注意力分佈向量。
總結:本節內容主要介紹了Attention機制 機製的幾個不同的分類變種,目前Attention機制 機製已經成爲深度學習和自然語言處理中重要的一部分,出現在各種各樣的模型和任務裡,事實證明,Attention機制 機製在許多場景下是非常有效的,並且由於其形式簡潔,通常不會爲模型帶來更多的複雜度。因此,Attention機制 機製應當是我們在做自然語言處理尤其是Seq2Seq任務中幾乎必不可少的幫手。
關注小鯨融創,一起深度學習金融科技!
