一天時間搞定scala[僅針對spark開發]
一天時間搞定scala[僅針對spark開發]
好久沒寫部落格了,天氣一熱身上開始出現各種小毛病,苦不堪言,也希望廣大程式設計師同胞能珍重身體,堅持鍛鍊。
想學spark,但是又覺得又要學一門scala很繁瑣?本着先學會用,再學會原理的心態,我花了一週時間整理了這篇部落格,很乾但是很高效(1天時間基本可以學完所有spark開發所需的scala知識,前提是掌握了java),希望對大家能夠有些許參考價值。
scala是基於JVM的語言
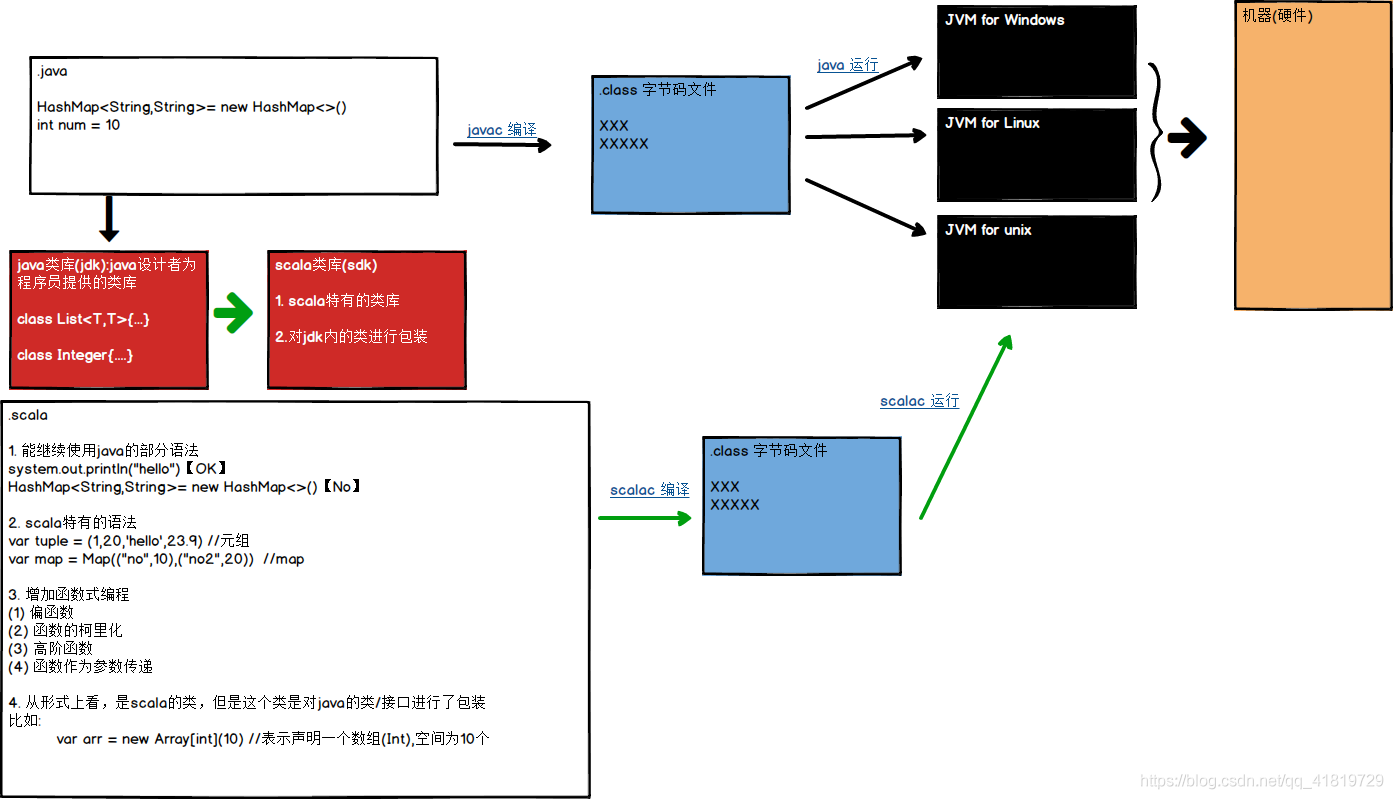
六大特性
1. 與java無縫整合
2. 型別推斷
3. 支援分佈式和併發Actor
4. Trait特質特性
5. 模式匹配match
6. 高階函數
類和物件
class
-
類中宣告的屬性會自動生成對應的setter/getter方法(val–>getter,var–>getter/setter)
object CatDemo { def main(args: Array[String]): Unit = { val cat = new Cat() cat.name="tom" //在底層中是cat.name_$eq("tom"),在Java中是cat.setName("tom") cat.age = 10 cat.color = "white" println(cat) } class Cat { //定義貓類的屬性 // 當宣告瞭var name:String時,在底層對應private name // 同時會生成兩個public方法--》類似setter/getter,public name_$eq()=>setter var name : String = "" //給初始值 var age:Int = _ //下劃線表示預設值 var color:String = _ override def toString: String = s"name:$name,age:$name,color:$name" } } -
當new類時,類中除了方法不執行其他都執行
-
class可以傳參,傳參就覆蓋了預設的無參構造
-
重寫構造時,第一行要先呼叫預設的構造this(…)
class Person(inName: String, inAge: Int) { val age: Int = inAge val name: String = inName var height: Int = _ //輔助構造 def this(height: Int) { this("sda", 123) this.height = height } } -
extends BaseA with BaseB
class Person(inName: String, inAge: Int) extends Human with Animal {...}
object(伴生物件)
package com.chanzany.scala.oop
/**
* Scala:
* 1. Scala object 相當於java中的單例(常用於工具類),在Object中定義的函數方法等全是靜態的,Object預設不可以傳參,
* 如果非要傳參,可以在該Object中定義apply方法
* 2. Scala中定義變數用var.定義常數用val,變數可變,常數不可變
* 3. Scala每行後面都會有分號自動推斷機制 機製,不用顯式寫出";"
* 4. Scala類中可以傳參(構造器),傳參一定要指定型別,類中的屬性預設有"getter"和"setter"方法
* 5. 類中重寫構造需要定義this構造方法,而且構造中第一行必須先呼叫預設構造
* 6. scala中當new class時,類中除了方法(除了構造),其他都執行
* 7. 在同一個scala檔案中,class名稱和object名稱一樣時,該類(class)和該物件(object)互爲伴生關係,
* 它們之間可以相互存取所有許可權的類屬性和方法,類似於C++中的友元
*/
class Person2(inName: String, inAge: Int) {
val name: String = inName
private val age: Int = inAge
// var sex: Char = _ //_表示對應數據型別的預設值
var sex: Char = 'M'
def this(inName: String, inAge: Int, inSex: Char) {
this(inName, inAge)
this.sex = inSex
}
// println("******Person Class in the __init__ function********")
def sayHello(): Unit = {
println(s"hello my name is $name")
}
// println("===========Person Class in the __init__ function===========")
}
object Lession_ClassAndObj {
// println("################Person Class in the __init__ function################") //靜態先載入
def main(args: Array[String]): Unit = {
// val person = new Person("zhangsna", 20)
// person.sayHello()
// Lession_ClassAndObj.sayHello() // 無需建立Object物件,相當於工具類,全是靜態方法
// val p = new Person("lisi", 20, 'F')
// val p2 = new Person("hha", 10)
// println(p.sex)
// println(p2.sex)
// person.age //當age並定義爲Private時,無法從類外方法,但是可以被伴生object存取
// Lession_ClassAndObj(2)
Lession_ClassAndObj(2, "Advised Using in Future")
}
//Object不支援構造傳參,但是爲了使得某些場景可以對object進行傳參,所以需要重寫object的apply方法來接受參數並做相關邏輯處理
def apply(versionID: Int): Unit = {
println(s"Version:$versionID")
}
def apply(versionID: Int, string: String): Unit = {
println(s"Version:$versionID")
println(string)
}
def sayHello(): Unit = {
println("hello")
}
}
/**
* 伴生object與其對應的伴生類同名,二者的關係類似於C++中的友元類
*/
object Person2 {
def main(args: Array[String]): Unit = {
val person = new Person("chanzany", 20)
println(person.age)
}
}
- object相當於Java中的單例/工具類,定義的屬性和方法都是靜態的
- object不可以傳參,除非使用
apply()方法接收呼叫該object時傳入的參數 - apply方法
- (1)通過伴生物件的apply方法,實現不使用new方法建立物件。
- (2)如果想讓主構造器變成私有的,可以在()之前加上private。
- (3)apply方法可以過載。
- (4)Scala中obj(arg)的語句實際是在呼叫該物件的apply方法,即obj.apply(arg)。用以同一物件導向程式設計和函數語言程式設計的風格。
Trait
package com.chanzany.scala.LessionTrait
/**
* Trait類似於JAVA中介面與抽象類的整合
* 一個類繼承多個trait時,第一個關鍵字使用extends,之後使用with
*/
trait Read {
def read(name: String) = {
println(s"$name is reading")
}
}
trait Listen {
def listen(name: String): Unit = {
println(s"$name is listening")
}
}
class Human() extends Read with Listen {
}
object TraitDemo {
def main(args: Array[String]): Unit = {
val h = new Human()
h.read("zhangsan")
h.listen("zhangsan")
}
}
- 相當於java中的介面和抽象類的結合。
- 可以在Trait中定義方法(實現/不實現),變數,常數
- Trait不可以傳參
- 類繼承Trait第一個關鍵字使用
extends,之後使用withclass Person(...)extends Trait1 with Trait2{...}
樣例類case class
case class Person1 (name:_String_,age:Int)
object Lesson_CaseClass {
def main(args: Array[_String_]): Unit = {
val p1 = new Person1("zhangsan",10)
val p2 = Person1("lisi",20)
val p3 = Person1("wangwu",30)
val list = List(p1,p2,p3)
list.foreach { x => {
x match {
case Person1("zhangsan",10) => println("zhangsan")
case Person1**("lisi",20) => println("lisi")
case _ => println("no match")
}
}
}
}
}
- 樣例類中參數,預設有getter/setter方法,對外可見
- 樣例類預設實現了toString,equals,copy和hashCode等方法。
- 樣例類可以new, 也可以不用new
基本語法
for…
- 1 to 10
- 1 until 10
- for(i <- 1 to 10)
- for(elem<-collection)
while…do…while
- i+=1,i=i+1
if…else…
- 與java相同
變數
- var修飾的物件參照可以改變,val修飾的則不可改變
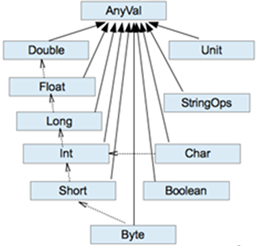
數據型別
-
整型:Byte,short,Int,Long
-
浮點型:Float,Double
-
字元型別Char,字串String
-
布爾型別Boolean
-
特殊型別
-
Unit
表示無值,和其他語言中void等同。用作不返回任何結果的方法的結果型別。Unit只有一個範例值,寫成()。 -
Null
null , Null 型別只有一個範例值null -
Nothing
Nothing型別在Scala的類層級的最低端;它是任何其他型別的子型別。
當一個函數,我們確定沒有正常的返回值,可以用Nothing來指定返回型別,這樣有一個好處,就是我們可以把返回的值(異常)賦給其它的函數或者變數(相容性)
-
-
型別轉換
-
自動轉換
-
強制轉換
- java : int num = (int)2.5
- scala : var num : Int = 2.7.toInt
-
方法和函數
1. 方法定義
- def 方法定義
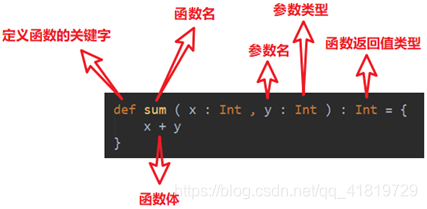
-
注意事項
- 方法中傳參要指定型別
- 方法可以推斷返回型別,預設將方法體中最後一行計算的結果當作返回值返回
- 如果要寫return來宣告返回值,就得顯式地宣告方法體的返回值型別
- 如果方法名稱和方法體之間沒有"=",無論方法返回什麼值都會被丟棄,返回Unit(Null)
-
函數/方法至簡原則
- (1)return可以省略,Scala會使用函數體的最後一行程式碼作爲返回值
- (2)返回值型別如果能夠推斷出來,那麼可以省略
- (3)如果函數體只有一行程式碼,可以省略花括號
- (4)如果函數無參,則可以省略小括號。若定義函數時省略小括號,則呼叫該函數時,也需省略小括號;若定時函數時未省略,則呼叫時,可省可不省。
- (5)如果函數明確宣告Unit,那麼即使函數體中使用return關鍵字也不起作用
- (6)Scala如果想要自動推斷無返回值,可以省略等號
- (7)如果不關心名稱,只關係邏輯處理,那麼函數名(def)可以省略
- (8)如果函數明確使用return關鍵字,那麼函數返回就不能使用自行推斷了,需要宣告返回值型別
// 0)函數標準寫法 def f1( s : String ): String = { return s + " jinlian" } println(f1("Hello")) // 至簡原則:能省則省 //(1) return可以省略,scala會使用函數體的最後一行程式碼作爲返回值 def f2( s : String ): String = { s + " jinlian" } println(f2("Hello")) // 如果函數名使用return關鍵字,那麼函數就不能使用自行推斷了,需要宣告返回值型別 /* def f22(s:String)={ return "jinlian" } */ //(2)返回值型別如果能夠推斷出來,那麼可以省略 def f3( s : String ) = { s + " jinlian" } println(f3("Hello")) //(3)如果函數體只有一行程式碼,可以省略花括號 //def f4(s:String) = s + " jinlian" //def f4(s:String) = "jinlian" def f4() = " dalang" // 如果函數無參,但是宣告參數列表,那麼呼叫時,小括號,可加可不加。 println(f4()) println(f4) //(4)如果函數沒有參數列表,那麼小括號可以省略,呼叫時小括號必須省略 def f5 = "dalang" // val f5 = "dalang" println(f5) //(5)如果函數明確宣告unit,那麼即使函數體中使用return關鍵字也不起作用 def f6(): Unit = { //return "abc" "dalang" } println(f6()) //(6)scala如果想要自動推斷無返回值,可以省略等號 // 將無返回值的函數稱之爲過程 def f7() { "dalang" } println(f7()) //(7)如果不關心名稱,只關係邏輯處理,那麼函數名(def)可以省略 //()->{println("xxxxx")} val f = (x:String)=>{"wusong"} // 萬物皆函數 : 變數也可以是函數 println(f("ximenqing")) //(8)如果函數明確使用return關鍵字,那麼函數返回就不能使用自行推斷了,需要宣告返回值型別 def f8() :String = { return "ximenqing" } println(f8())
2. 遞回方法
-
需要顯式寫出返回值型別
def feibo(n: Int): Int = { if (n == 1 || n == 2) { return 1 } feibo(n - 1) + feibo(n - 2) }
3. 參數有預設值的方法
- def fun(x:Int = 10,y:String=「hello」)
4. 可變長參數的方法
- def fun(s:String*)
5. 匿名函數
-
val fun = (…)=>{…}
-
"=>"是匿名函數的識別符號,多用於方法的參數是函數時,常用匿名函數,比如
list.foreach(s=>println)
6. 偏應用函數
某些情況下,方法中參數非常多,呼叫該方法又很頻繁,每次呼叫都只有固定的某幾個參數變換,就可以定義偏應用函數來實現。
def showLog(date:Date,log:String)={
println(s"data is $date, log is $log")
}
val date = new Date()
showLog(date,"a")
showLog(date,"b")
showLog(date,"c")
/** 定義偏應用函數**/
def fun = showLog(date, _: String)
fun ("aa")
fun ("bb")
fun ("cc")
7. 巢狀方法
-
Scala語言的語法非常靈活,可以在任何的語法結構中宣告任何的語法,所以在方法內部也可以定義方法
def test2(): Unit ={ println("test2") def test3(): Unit ={ println("函數可以巢狀函數的定義test3") } test3() }
8. 高階函數
-
函數的參數是函數
def fun1(f:(Int,Int)=>Int,s:String):String={ val i: Int = f(100, 200) i + "#"+s } val res = fun1((a:Int,b:Int)=>a*b, "scala") println(res) -
函數的返回值是函數 ,需要顯式寫出函數的返回是函數,如果加
_就可以不顯式的宣告方法的返回值def fun(s: String): (String, String) => String = { def fun1(s1: String, s2: String): String = { s + ":" + s1 + "~~" + s2 } fun1 } // val fun1 = fun("aaa") // println(fun1("hello", "scala")) println(fun("a")("hello","scala")) //柯裡化函數的呼叫 -
函數的參數和返回值都是函數
def fun(f:(Int,Int)=>Int):(String,String)=>String = { val i: Int = f(1, 2) def fun1(s1:String,s2:String): String ={ s1+i+"@"+s2+".com" } fun1 } println(fun((a,b)=>{a+b})("chanzany","163"))
9. 柯裡化函數
-
將一個接收多個參數的函數轉化成多個函陣列成的函數過程,可以簡單的理解爲一種特殊的參數列表宣告方式。
def fun(a:Int,b:Int)(c:Int,d:Int) ={ a+b+c+d } println(fun(1,2)(3,4))
10. 惰性求值
-
當函數返回值被宣告爲lazy時,函數的執行將被推遲,直到我們首次對此取值,該函數纔會執行。這種函數我們稱之爲惰性函數。
def main(args: Array[String]): Unit = { lazy val res = sum(10, 30) println("----------------") println("res=" + res) } def sum(n1: Int, n2: Int): Int = { println("sum被執行。。。") return n1 + n2 }
集合
Array
- 使用
(index)來操作Array中的元素 - 使用
[dataType]來指定Array的泛型 - new出來的物件和呼叫單例物件的區別
val arr = Array[String]("a","b","c") // 定義不可變陣列
val arr2 = new Array[Int](3) //length = 3,定義不可變陣列
val array = new Array[Array[Int]](3) //建立二維陣列,其中包含3個一維陣列
array(0) = Array[Int](1,2,3)
array(1) = Array[Int](4,5,6)
array(2) = Array[Int](7,8)
for(arr <- array){
arr.foreach(println)
}
for(arr<-array;elem<-arr){
println(elem)
}
array.foreach(arr=>{arr.foreach(println)})
ArrayBuffer(可變的Array)
- 可變陣列需要匯入scala.collections.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
//val arr = new ArrayBuffer[Int](10) //new出來的class,參數length = 10表示的是初始長度
val arr = ArrayBuffer[Int](1,2,3) //單例構建出來的object,參數elems = 1,2,3表示的是初始內容
arr.append(1,2,3,4,5,6,7,8,8,9,9,10,10,10) //尾插入
arr.+=(4) //尾插入
arr.+=:(100) //頭插入
arr.foreach(println)
List
預設爲不可變List,而且List在建立時不能用new
val list = List[String](...)
val list = List[String]("hello scala", "hello spark","nice","gca","ali")
- map :hello scala,hello spark --map–>[ [hello,scala],[hello,spark] ]
- flatMap :hello scala,hello spark --map–>[ [hello,scala],[hello,spark] ]–flat–>[hello,scala,hello,spark]
val results: List[Array[String]] = list.map(s => { //s相當於List中的每一個元素比如hello scala
s.split(" ")
})
results.foreach(arr => arr.foreach(println))
val res: List[String] = list.flatMap(s => s.split(" "))
res.foreach(println)
- list.filter
- list.count
/**
* List.filter(string->Boolean)
* 過濾出匹配成功的數據
*/
val res: List[String] = list.filter(s => {
"hello scala".equals(s)
})
res.foreach(println) // hello scala
/**
* List.count(String->Boolean)
* 統計滿足條件的數據條目數
*/
val count: Int = list.count(s => s.length > 4)
println(count)
ListBuffer(可變的List)
import scala.collection.mutable.ListBuffer
val list = ListBuffer[Int](1,2,3,4)
list.foreach(println)
list.append(9,10,11) //尾插
list.+=:(100) //頭插
list.+=(101) //尾插
list.foreach(s => print(s+"\t"))
Set
set 無序,元素不重複的集合
scala.collection.immutable.Set:不可變scala.collection.mutable.Set:可變
Map
map的元素表達形式不再是<Key,value>,而是key->value或者(key,value)
- 可變不可變(mutable,immutable)
Map.keysMap.valuesval option=Map.get(key)val value = map.get(key).getOrElse(...):沒有對應的key的時候返回getOrElse函數的輸入內容
val map = Map[String, Int]("a" -> 100, "b" -> 50, ("c" -> 80), ("c" -> 1000))
// map.foreach(println)
val opt: Option[Int] = map.get("a")
val opt2: Option[Int] = map.get("aa")
val opt_value: Int = map.get("a").get
val opt_value2: Int = map.get("aa").get
val opt_value3: Any = map.get("aa").getOrElse("no key in map")
println(opt)
println(opt2)
println(opt_value)
println(opt_value2)
println(opt_value3)
/*val keys: Iterable[String] = map.keys
keys.foreach(key=>{
val value: Int = map.get(key).get
println(s"key = $key,value = $value")
})*/
/*val values: Iterable[Int] = map.values
values.foreach(println)*/
val map1: Map[String, Int] = Map[String, Int](("a", 1), ("b", 2), ("c", 3), ("d", 4))
val map2: Map[String, Int] = Map[String, Int](("a", 100), ("b", 2), ("c", 300), ("e", 500))
//map的合併
val result: Map[String, Int] = map1.++(map2) //保留map2中key對應的值
val result2: Map[String, Int] = map1.++:(map2) //保留map1中key對應的值
result.foreach(println)
result2.foreach(println)
Tuple
-
最多支援22個元素
-
val iterator = tuple.productIterator//遍歷tuple val iter: Iterator[Any] = tuple5.productIterator /*while (iter.hasNext){ println(iter.next()) }*/ iter.foreach(println) -
二元組中有個
swap反轉方法 -
元組的建立
val tuple1 = new Tuple1[String]("hello") val tuple2 = new Tuple2[String, Int]("a",100) val tuple3 = new Tuple3[String, Int, Boolean]("a", 1, true) val tuple4: (Int, Double, String, Boolean) = Tuple4(1, 3.4, "abc", false) val tuple5: (Int, Double, Boolean, String, Char) = (1, 2.0, false, "and", 'C') -
元組的取值
tuple._nprintln(tuple4._1) println(tuple4._2) println(tuple4._3) println(tuple4._4)
集合常用函數
基本屬性和常用操作
-
(1)獲取集合長度
println(list.length)
-
(2)獲取集合大小
println(list.size)
-
(3)回圈遍歷
list.foreach(println)
-
(4)迭代器
for (elem <- list.iterator) { println(elem) }
-
(5)生成字串
println(list.mkString(","))
-
(6)是否包含
println(list.contains(3))
衍生集合
-
(1)獲取集合的頭head:
list1.head
-
(2)獲取集合的尾(不是頭就是尾)tail
list1.tail
-
(3)集合最後一個數據 last
list1.last
-
(4)集合初始數據(不包含最後一個)
list1.init
-
(5)反轉
list1.reverse
-
(6)取前(後)n個元素
println(list1.take(3))
println(list1.takeRight(3))
-
(7)去掉前(後)n個元素
println(list1.drop(3)),println(list1.dropRight(3))
-
(8)並集
list1.union(list2)
-
(9)交集
list1.intersect(list2)
-
(10)差集
list1.diff(list2)
-
(11)拉鍊
- 拉鍊 注:如果兩個集合的元素個數不相等,那麼會將同等數量的數據進行拉鍊,多餘的數據省略不用
println(list1.zip(list2))
- 拉鍊 注:如果兩個集合的元素個數不相等,那麼會將同等數量的數據進行拉鍊,多餘的數據省略不用
-
(12)滑窗
list1.sliding(2, 5).foreach(println)
集合計算初級函數
- (1)求和
list.sum
- (2)求乘積
list.product
- (3)最大值
list.max
- (4)最小值
list.min
- (5)排序
- (5.1)按照元素大小排序
list.sortBy(x => x)
- (5.2)按照元素的絕對值大小排序
list.sortBy(x => x.abs)
- (5.3)按元素大小升序排序
list.sortWith((x, y) => x < y)
- (5.4)按元素大小降序排序
list.sortWith((x, y) => x > y)
- (5.1)按照元素大小排序
集合計算高階函數

-
(1)過濾
list.filter(x => x % 2 == 0)
-
(2)轉化/對映
list.map(x => x + 1)
-
(3)扁平化
-
val nestedList: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9)) nestedList.flatten
-
-
(4)扁平化+對映 注:flatMap相當於先進行map操作,在進行flatten操作
wordList.flatMap(x => x.split(" "))
-
(5)分組
-
list.groupBy(x => x % 2)//Map(1 -> List(1, 3, 5, 7, 9), 0 -> List(2, 4, 6, 8)) println(list.groupBy(x => x % 2))
-
-
(6)簡化(規約)
// 將數據兩兩結合,實現運算規則 val i: Int = list.reduce( (x,y) => x-y ) -
(7)摺疊
// 兩個Map的數據合併 val map1 = mutable.Map("a"->1, "b"->2, "c"->3) val map2 = mutable.Map("a"->4, "b"->5, "d"->6) val map3: mutable.Map[String, Int] = map2.foldLeft(map1) { (map, kv) => { val k = kv._1 val v = kv._2 map(k) = map.getOrElse(k, 0) + v map } } println(map3)
模式匹配match
語法:match…case…
- 模式匹配中既可以匹配值也可以匹配數據的型別
- case 123 =>{…}
- case i:Int => {…}
-
模式匹配中,從上往下匹配,匹配上了就自動終止
-
模式匹配中會有值的轉換
-
case _ =>{…}預設匹配(匹配任意條件),要寫到最後
-
模式匹配外部的花括號可省略掉
o match ...case...相當於一大行(一段完整邏輯)
def MatchTest(o: Any): Unit = {
o match {
case 1 => println("value is 1") //匹配值
case i: Int => println(s"type is int,value is $i") //匹配型別
case d: Double => println(s"type is Double,value is $d")
case s: String => println(s"type is String,value is $s")
case c: Char => println(s"type is Char,value is $c")
case _ => println("no match...")
}
}
def main(args: Array[String]): Unit = {
val tp = (1, 1.2, "abc", 'a', true)
val iterator: Iterator[Any] = tp.productIterator
iterator.foreach(MatchTest)
}
匹配物件及樣例類
class User(val name: String, val age: Int)
object User {
def apply(name: String, age: Int): User = new User(name, age)
def unapply(user: User): Option[(String, Int)] = {
if (user == null)
None
else
Some(user.name, user.age)
}
}
object TestMatchUnapply {
def main(args: Array[String]): Unit = {
val user: User = User("zhangsan", 11)
val result = user match {
case User("zhangsan", 11) => "yes"
case _ => "no"
}
println(result)
}
}
偏函數
PartialFunction[匹配的型別,匹配上對應的返回值型別]- 偏函數相當於Java中的switch…case…,只能匹配相同類型
def MyTest:PartialFunction[String,Int] = { //進入string,出去int
case "abc" => 2
case "a" =>1
case _ => 0
}
def main(args: Array[String]): Unit = {
val res: Int = MyTest("abc")
println(res)
}
例外處理
樣例
def main(args: Array[String]): Unit = {
try {
var n= 10 / 0
}catch {
case ex: ArithmeticException=>{
// 發生算術異常
println("發生算術異常")
}
case ex: Exception=>{
// 對例外處理
println("發生了異常1")
println("發生了異常2")
}
}finally {
println("finally")
}
}
1)我們將可疑程式碼封裝在try塊中。在try塊之後使用了一個catch處理程式來捕獲異常。如果發生任何異常,catch處理程式將處理它,程式將不會異常終止。
2)Scala的異常的工作機制 機製和Java一樣,但是Scala沒有「checked(編譯期)」異常,即Scala沒有編譯異常這個概念,異常都是在執行的時候捕獲處理。
3)異常捕捉的機制 機製與其他語言中一樣,如果有異常發生,catch子句是按次序捕捉的。因此,在catch子句中,越具體的異常越要靠前,越普遍的異常越靠後,如果把越普遍的異常寫在前,把具體的異常寫在後,在Scala中也不會報錯,但這樣是非常不好的程式設計風格。
4)finally子句用於執行不管是正常處理還是有異常發生時都需要執行的步驟,一般用於物件的清理工作,這點和Java一樣。
5)用throw關鍵字,拋出一個異常物件。所有異常都是Throwable的子型別。throw表達式是有型別的,就是Nothing,因爲Nothing是所有型別的子型別,所以throw表達式可以用在需要型別的地方
def test():Nothing = {
throw new Exception("不對")
}
6)Scala提供了throws關鍵字來宣告異常。可以使用方法定義宣告異常。它向呼叫者函數提供了此方法可能引發此異常的資訊。它有助於呼叫函數處理並將該程式碼包含在try-catch塊中,以避免程式異常終止。在Scala中,可以使用throws註釋來宣告異常
def main(args: Array[String]): Unit = {
f11()
}
@throws(classOf[NumberFormatException])
def f11()={
"abc".toInt
}
隱式轉換
隱式轉換可以再不需改任何程式碼的情況下,擴充套件某個類的功能。
隱式函數
- 通過
implicit修飾的方法
需求:通過隱式轉化爲Int型別增加方法。
class MyRichInt(val self: Int) {
def myMax(i: Int): Int = {
if (self < i) i else self
}
def myMin(i: Int): Int = {
if (self < i) self else i
}
}
object TestImplicitFunction {
implicit def convert(arg: Int): MyRichInt = {
new MyRichInt(arg)
}
def main(args: Array[String]): Unit = {
println(2.myMax(6))
}
}
隱式參數
普通方法或者函數可以通過implicit關鍵字宣告隱式參數,呼叫該方法時,就可以傳入該參數,編譯器會再相應的作用域尋找符合條件的隱式值。
(1)同一個作用域中,相同類型的隱式值只能有一個
(2)編譯器按照隱式參數的型別去尋找對應型別的隱式值,與隱式值的名稱無關。
(3)隱式參數優先於預設參數
object TestImplicitParameter {
implicit val str: String = "hello world!"
def hello(implicit arg: String="good bey world!"): Unit = {
println(arg)
}
def main(args: Array[String]): Unit = {
hello
}
}
隱式類
使用implicit宣告類,隱式類的非常強大,同樣可以擴充套件類的功能,在集閤中隱式類會發揮重要的作用。
(1)其所帶的構造參數有且只能有一個
(2)隱式類必須被定義在「類」或「伴生物件」或「包物件」裡,即隱式類不能是頂級的。
object TestImplicitClass {
implicit class MyRichInt(arg: Int) {
def myMax(i: Int): Int = {
if (arg < i) i else arg
}
def myMin(i: Int) = {
if (arg < i) arg else i
}
}
def main(args: Array[String]): Unit = {
println(1.myMax(3))
}
}
scala版WordCount
需求:單詞計數:將集閤中出現的相同的單詞,進行計數,取計數排名前三的結果
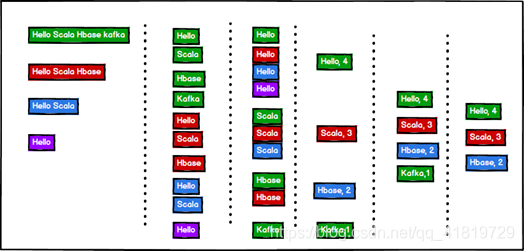
object TestWordCount {
def main(args: Array[String]): Unit = {
// 單詞計數:將集閤中出現的相同的單詞,進行計數,取計數排名前三的結果
val stringList = List("Hello Scala Hbase kafka", "Hello Scala Hbase", "Hello Scala", "Hello")
// 1) 將每一個字串轉換成一個一個單詞
val wordList: List[String] = stringList.flatMap(str=>str.split(" "))
//println(wordList)
// 2) 將相同的單詞放置在一起
val wordToWordsMap: Map[String, List[String]] = wordList.groupBy(word=>word)
//println(wordToWordsMap)
// 3) 對相同的單詞進行計數
// (word, list) => (word, count)
val wordToCountMap: Map[String, Int] = wordToWordsMap.map(tuple=>(tuple._1, tuple._2.size))
// 4) 對計數完成後的結果進行排序(降序)
val sortList: List[(String, Int)] = wordToCountMap.toList.sortWith {
(left, right) => {
left._2 > right._2
}
}
// 5) 對排序後的結果取前3名
val resultList: List[(String, Int)] = sortList.take(3)
println(resultList)
}
}