CUDA 入門教學
在老闆的要求下,本博主從2012年上高效能運算課程開始接觸CUDA程式設計,隨後將該技術應用到了實際專案中,使處理程式加速超過1K,可見基於圖形顯示器的並行計算對於追求速度的應用來說無疑是一個理想的選擇。還有不到一年畢業,怕是畢業後這些技術也就隨畢業而去,準備這個暑假開闢一個CUDA專欄,從入門到精通,步步爲營,順便分享設計的一些經驗教訓,希望能給學習CUDA的童鞋提供一定指導。個人能力所及,錯誤難免,歡迎討論。
PS:申請專欄好像需要先發原創帖超過15篇。。。算了,先寫夠再申請吧,到時候一併轉過去。
NVIDIA於2006年推出CUDA(Compute Unified Devices Architecture),可以利用其推出的GPU進行通用計算,將並行計算從大型叢集擴充套件到了普通顯示卡,使得使用者只需要一臺帶有Geforce顯示卡的筆電就能跑較大規模的並行處理程式。
使用顯示卡的好處是,和大型叢集相比功耗非常低,成本也不高,但效能很突出。以我的筆電爲例,Geforce 610M,用DeviceQuery程式測試,可得到如下硬體參數:
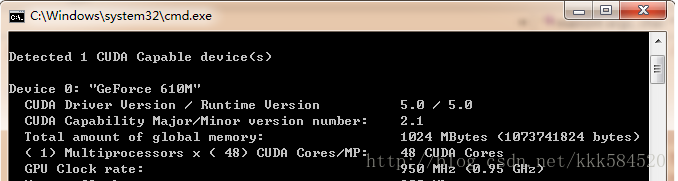
計算能力達48X0.95 = 45.6 GFLOPS。而筆電的CPU參數如下:
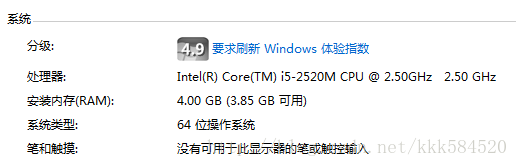
CPU計算能力爲(4核):2.5G*4 = 10GFLOPS,可見,顯示卡計算效能是4核i5 CPU的4~5倍,因此我們可以充分利用這一資源來對一些耗時的應用進行加速。
好了,工欲善其事必先利其器,爲了使用CUDA對GPU進行程式設計,我們需要準備以下必備工具:
1. 硬體平臺,就是顯示卡,如果你用的不是NVIDIA的顯示卡,那麼只能說抱歉,其他都不支援CUDA。
2. 操作系統,我用過windows XP,Windows 7都沒問題,本部落格用Windows7。
3. C編譯器,建議VS2008,和本部落格一致。
4. CUDA編譯器NVCC,可以免費免註冊免license從官網下載CUDA ToolkitCUDA下載,最新版本爲5.0,本部落格用的就是該版本。
5. 其他工具(如Visual Assist,輔助程式碼高亮)
準備完畢,開始安裝軟體。VS2008安裝比較費時間,建議安裝完整版(NVIDIA官網說Express版也可以),過程不必詳述。CUDA Toolkit 5.0裏面包含了NVCC編譯器、設計文件、設計例程、CUDA執行時庫、CUDA標頭檔案等必備的原材料。
安裝完畢,我們在桌面上發現這個圖示:
不錯,就是它,雙擊執行,可以看到一大堆例程。我們找到Simple OpenGL這個執行看看效果:
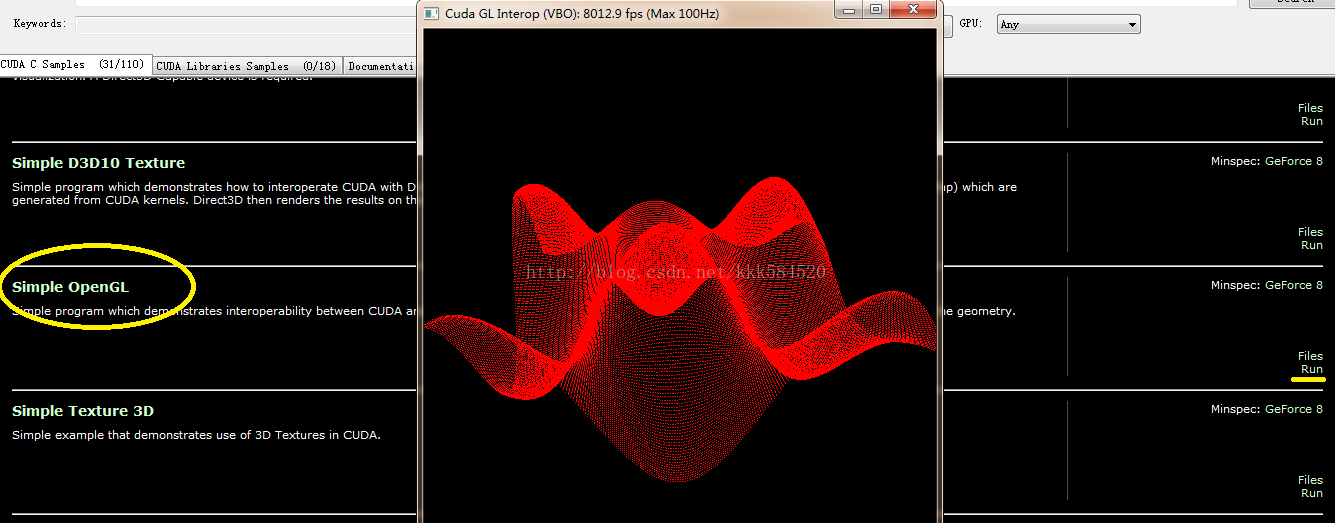
點右邊黃線標記處的Run即可看到美妙的三維正弦曲面,滑鼠左鍵拖動可以轉換角度,右鍵拖動可以縮放。如果這個執行成功,說明你的環境基本搭建成功。
出現問題的可能:
1. 你使用遠端桌面連線登錄到另一臺伺服器,該伺服器上有顯示卡支援CUDA,但你遠端終端不能執行CUDA程式。這是因爲遠程登錄使用的是你本地顯示卡資源,在遠程登錄時看不到伺服器端的顯示卡,所以會報錯:沒有支援CUDA的顯示卡!解決方法:1. 遠端伺服器裝兩塊顯示卡,一塊只用於顯示,另一塊用於計算;2.不要用圖形介面登錄,而是用命令列介面如telnet登錄。
2.有兩個以上顯示卡都支援CUDA的情況,如何區分是在哪個顯示卡上執行?這個需要你在程式裡控制,選擇符合一定條件的顯示卡,如較高的時鐘頻率、較大的視訊記憶體、較高的計算版本等。詳細操作見後面的部落格。
好了,先說這麼多,下一節我們介紹如何在VS2008中給GPU程式設計。
書接上回,我們既然直接執行例程成功了,接下來就是瞭解如何實現例程中的每個環節。當然,我們先從簡單的做起,一般程式語言都會找個helloworld例子,而我們的顯示卡是不會說話的,只能做一些簡單的加減乘除運算。所以,CUDA程式的helloworld,我想應該最合適不過的就是向量加了。
開啓VS2008,選擇File->New->Project,彈出下面 下麪對話方塊,設定如下:
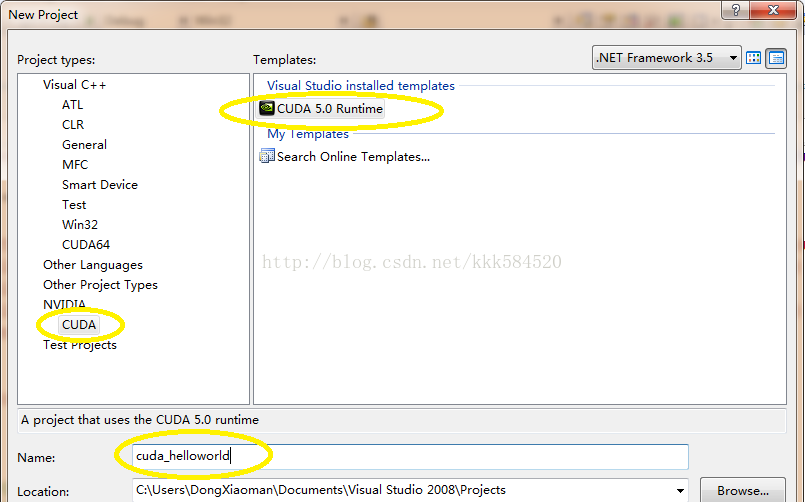
之後點OK,直接進入工程介面。
工程中,我們看到只有一個.cu檔案,內容如下:
[cpp] view plain copy
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
- int main()
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- const int b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
- c[0], c[1], c[2], c[3], c[4]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- // Launch a kernel on the GPU with one thread for each element.
- addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
- // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
-
#include "cuda_runtime.h" -
#include "device_launch_parameters.h" -
#include <stdio.h> -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size); -
__global__ void addKernel(int *c, const int *a, const int *b) -
{ -
int i = threadIdx.x; -
c[i] = a[i] + b[i]; -
} -
int main() -
{ -
const int arraySize = 5; -
const int a[arraySize] = { 1, 2, 3, 4, 5 }; -
const int b[arraySize] = { 10, 20, 30, 40, 50 }; -
int c[arraySize] = { 0 }; -
// Add vectors in parallel. -
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "addWithCuda failed!"); -
return 1; -
} -
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n", -
c[0], c[1], c[2], c[3], c[4]); -
// cudaThreadExit must be called before exiting in order for profiling and -
// tracing tools such as Nsight and Visual Profiler to show complete traces. -
cudaStatus = cudaThreadExit(); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaThreadExit failed!"); -
return 1; -
} -
return 0; -
} -
// Helper function for using CUDA to add vectors in parallel. -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size) -
{ -
int *dev_a = 0; -
int *dev_b = 0; -
int *dev_c = 0; -
cudaError_t cudaStatus; -
// Choose which GPU to run on, change this on a multi-GPU system. -
cudaStatus = cudaSetDevice(0); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); -
goto Error; -
} -
// Allocate GPU buffers for three vectors (two input, one output) . -
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
// Copy input vectors from host memory to GPU buffers. -
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
// Launch a kernel on the GPU with one thread for each element. -
addKernel<<<1, size>>>(dev_c, dev_a, dev_b); -
// cudaThreadSynchronize waits for the kernel to finish, and returns -
// any errors encountered during the launch. -
cudaStatus = cudaThreadSynchronize(); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus); -
goto Error; -
} -
// Copy output vector from GPU buffer to host memory. -
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
Error: -
cudaFree(dev_c); -
cudaFree(dev_a); -
cudaFree(dev_b); -
return cudaStatus; -
}
可以看出,CUDA程式和C程式並無區別,只是多了一些以"cuda"開頭的一些庫函數和一個特殊宣告的函數:
[cpp] view plain copy
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
-
__global__ void addKernel(int *c, const int *a, const int *b) -
{ -
int i = threadIdx.x; -
c[i] = a[i] + b[i]; -
}
這個函數就是在GPU上執行的函數,稱之爲核函數,英文名Kernel Function,注意要和操作系統內核函數區分開來。
我們直接按F7編譯,可以得到如下輸出:
[html] view plain copy
- 1>------ Build started: Project: cuda_helloworld, Configuration: Debug Win32 ------
- 1>Compiling with CUDA Build Rule...
- 1>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\nvcc.exe" -G -gencode=arch=compute_10,code=\"sm_10,compute_10\" -gencode=arch=compute_20,code=\"sm_20,compute_20\" --machine 32 -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\bin" -Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT " -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\include" -maxrregcount=0 --compile -o "Debug/kernel.cu.obj" kernel.cu
- 1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.gpu
- 1>tmpxft_000000ec_00000000-14_kernel.compute_10.cudafe2.gpu
- 1>tmpxft_000000ec_00000000-5_kernel.compute_20.cudafe1.gpu
- 1>tmpxft_000000ec_00000000-17_kernel.compute_20.cudafe2.gpu
- 1>kernel.cu
- 1>kernel.cu
- 1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.cpp
- 1>tmpxft_000000ec_00000000-24_kernel.compute_10.ii
- 1>Linking...
- 1>Embedding manifest...
- 1>Performing Post-Build Event...
- 1>copy "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart*.dll" "C:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\Debug"
- 1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart32_50_35.dll
- 1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart64_50_35.dll
- 1>已複製 2 個檔案。
- 1>Build log was saved at "file://c:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\cuda_helloworld\Debug\BuildLog.htm"
- 1>cuda_helloworld - 0 error(s), 105 warning(s)
- ========== Build: 1 succeeded, 0 failed, 0 up-to-date, 0 skipped ==========
-
1>------ Build started: Project: cuda_helloworld, Configuration: Debug Win32 ------ -
1>Compiling with CUDA Build Rule... -
1>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\nvcc.exe" -G -gencode=arch=compute_10,code=\"sm_10,compute_10\" -gencode=arch=compute_20,code=\"sm_20,compute_20\" --machine 32 -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\bin" -Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT " -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\include" -maxrregcount=0 --compile -o "Debug/kernel.cu.obj" kernel.cu -
1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.gpu -
1>tmpxft_000000ec_00000000-14_kernel.compute_10.cudafe2.gpu -
1>tmpxft_000000ec_00000000-5_kernel.compute_20.cudafe1.gpu -
1>tmpxft_000000ec_00000000-17_kernel.compute_20.cudafe2.gpu -
1>kernel.cu -
1>kernel.cu -
1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.cpp -
1>tmpxft_000000ec_00000000-24_kernel.compute_10.ii -
1>Linking... -
1>Embedding manifest... -
1>Performing Post-Build Event... -
1>copy "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart*.dll" "C:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\Debug" -
1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart32_50_35.dll -
1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart64_50_35.dll -
1>已複製 2 個檔案。 -
1>Build log was saved at "file://c:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\cuda_helloworld\Debug\BuildLog.htm" -
1>cuda_helloworld - 0 error(s), 105 warning(s) -
========== Build: 1 succeeded, 0 failed, 0 up-to-date, 0 skipped ==========
可見,編譯.cu檔案需要利用nvcc工具。該工具的詳細使用見後面部落格。
直接執行,可以得到結果圖如下:
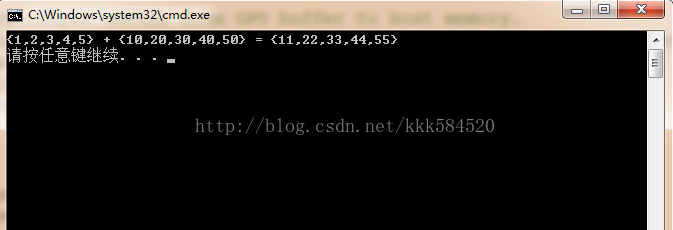
如果顯示正確,那麼我們的第一個程式宣告成功!
剛入門CUDA,跑過幾個官方提供的例程,看了看人家的程式碼,覺得並不難,但自己動手寫程式碼時,總是不知道要先幹什麼,後幹什麼,也不知道從哪個知識點學起。這時就需要有一本能提供指導的書籍或者教學,一步步跟着做下去,直到真正掌握。
一般講述CUDA的書,我認爲不錯的有下面 下麪這幾本:

初學者可以先看美國人寫的這本《GPU高效能程式設計CUDA實戰》,可操作性很強,但不要期望能全看懂(Ps:裏面有些概念其實我現在還是不怎麼懂),但不影響你進一步學習。如果想更全面地學習CUDA,《GPGPU程式設計技術》比較客觀詳細地介紹了通用GPU程式設計的策略,看過這本書,可以對顯示卡有更深入的瞭解,揭開GPU的神祕面紗。後面《OpenGL程式設計指南》完全是爲了體驗圖形互動帶來的樂趣,可以有選擇地看;《GPU高效能運算之CUDA》這本是師兄給的,適合快速查詢(感覺是將官方程式設計手冊翻譯了一遍)一些關鍵技術和概念。
有了這些指導材料還不夠,我們在做專案的時候,遇到的問題在這些書上肯定找不到,所以還需要有下面 下麪這些利器:
這裏面有很多工具的使用手冊,如CUDA_GDB,Nsight,CUDA_Profiler等,方便偵錯程式;還有一些有用的庫,如CUFFT是專門用來做快速傅裡葉變換的,CUBLAS是專用於線性代數(矩陣、向量計算)的,CUSPASE是專用於稀疏矩陣表示和計算的庫。這些庫的使用可以降低我們設計演算法的難度,提高開發效率。另外還有些入門教學也是值得一讀的,你會對NVCC編譯器有更近距離的接觸。
好了,前言就這麼多,本博主計劃按如下順序來講述CUDA:
1.瞭解裝置
2.執行緒並行
3.塊並行
4.流並行
5.執行緒通訊
6.執行緒通訊範例:規約
7.儲存模型
8.常數記憶體
9.紋理記憶體
10.主機頁鎖定記憶體
11.圖形互操作
12.優化準則
13.CUDA與MATLAB介面
14.CUDA與MFC介面
前面三節已經對CUDA做了一個簡單的介紹,這一節開始真正進入程式設計環節。
首先,初學者應該對自己使用的裝置有較爲紮實的理解和掌握,這樣對後面學習並行程式優化很有幫助,瞭解硬體詳細參數可以通過上節介紹的幾本書和官方資料獲得,但如果仍然覺得不夠直觀,那麼我們可以自己動手獲得這些內容。
以第二節例程爲模板,我們稍加改動的部分程式碼如下:
[cpp] view plain copy
- // Add vectors in parallel.
- cudaError_t cudaStatus;
- int num = 0;
- cudaDeviceProp prop;
- cudaStatus = cudaGetDeviceCount(&num);
- for(int i = 0;i<num;i++)
- {
- cudaGetDeviceProperties(&prop,i);
- }
- cudaStatus = addWithCuda(c, a, b, arraySize);
-
// Add vectors in parallel. -
cudaError_t cudaStatus; -
int num = 0; -
cudaDeviceProp prop; -
cudaStatus = cudaGetDeviceCount(&num); -
for(int i = 0;i<num;i++) -
{ -
cudaGetDeviceProperties(&prop,i); -
} -
cudaStatus = addWithCuda(c, a, b, arraySize);
這個改動的目的是讓我們的程式自動通過呼叫cuda API函數獲得裝置數目和屬性,所謂「知己知彼,百戰不殆」。
cudaError_t 是cuda錯誤型別,取值爲整數。
cudaDeviceProp爲裝置屬性結構體,其定義可以從cuda Toolkit安裝目錄中找到,我的路徑爲:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\include\driver_types.h,找到定義爲:
[cpp] view plain copy
- /**
- * CUDA device properties
- */
- struct __device_builtin__ cudaDeviceProp
- {
- char name[256]; /**< ASCII string identifying device */
- size_t totalGlobalMem; /**< Global memory available on device in bytes */
- size_t sharedMemPerBlock; /**< Shared memory available per block in bytes */
- int regsPerBlock; /**< 32-bit registers available per block */
- int warpSize; /**< Warp size in threads */
- size_t memPitch; /**< Maximum pitch in bytes allowed by memory copies */
- int maxThreadsPerBlock; /**< Maximum number of threads per block */
- int maxThreadsDim[3]; /**< Maximum size of each dimension of a block */
- int maxGridSize[3]; /**< Maximum size of each dimension of a grid */
- int clockRate; /**< Clock frequency in kilohertz */
- size_t totalConstMem; /**< Constant memory available on device in bytes */
- int major; /**< Major compute capability */
- int minor; /**< Minor compute capability */
- size_t textureAlignment; /**< Alignment requirement for textures */
- size_t texturePitchAlignment; /**< Pitch alignment requirement for texture references bound to pitched memory */
- int deviceOverlap; /**< Device can concurrently copy memory and execute a kernel. Deprecated. Use instead asyncEngineCount. */
- int multiProcessorCount; /**< Number of multiprocessors on device */
- int kernelExecTimeoutEnabled; /**< Specified whether there is a run time limit on kernels */
- int integrated; /**< Device is integrated as opposed to discrete */
- int canMapHostMemory; /**< Device can map host memory with cudaHostAlloc/cudaHostGetDevicePointer */
- int computeMode; /**< Compute mode (See ::cudaComputeMode) */
- int maxTexture1D; /**< Maximum 1D texture size */
- int maxTexture1DMipmap; /**< Maximum 1D mipmapped texture size */
- int maxTexture1DLinear; /**< Maximum size for 1D textures bound to linear memory */
- int maxTexture2D[2]; /**< Maximum 2D texture dimensions */
- int maxTexture2DMipmap[2]; /**< Maximum 2D mipmapped texture dimensions */
- int maxTexture2DLinear[3]; /**< Maximum dimensions (width, height, pitch) for 2D textures bound to pitched memory */
- int maxTexture2DGather[2]; /**< Maximum 2D texture dimensions if texture gather operations have to be performed */
- int maxTexture3D[3]; /**< Maximum 3D texture dimensions */
- int maxTextureCubemap; /**< Maximum Cubemap texture dimensions */
- int maxTexture1DLayered[2]; /**< Maximum 1D layered texture dimensions */
- int maxTexture2DLayered[3]; /**< Maximum 2D layered texture dimensions */
- int maxTextureCubemapLayered[2];/**< Maximum Cubemap layered texture dimensions */
- int maxSurface1D; /**< Maximum 1D surface size */
- int maxSurface2D[2]; /**< Maximum 2D surface dimensions */
- int maxSurface3D[3]; /**< Maximum 3D surface dimensions */
- int maxSurface1DLayered[2]; /**< Maximum 1D layered surface dimensions */
- int maxSurface2DLayered[3]; /**< Maximum 2D layered surface dimensions */
- int maxSurfaceCubemap; /**< Maximum Cubemap surface dimensions */
- int maxSurfaceCubemapLayered[2];/**< Maximum Cubemap layered surface dimensions */
- size_t surfaceAlignment; /**< Alignment requirements for surfaces */
- int concurrentKernels; /**< Device can possibly execute multiple kernels concurrently */
- int ECCEnabled; /**< Device has ECC support enabled */
- int pciBusID; /**< PCI bus ID of the device */
- int pciDeviceID; /**< PCI device ID of the device */
- int pciDomainID; /**< PCI domain ID of the device */
- int tccDriver; /**< 1 if device is a Tesla device using TCC driver, 0 otherwise */
- int asyncEngineCount; /**< Number of asynchronous engines */
- int unifiedAddressing; /**< Device shares a unified address space with the host */
- int memoryClockRate; /**< Peak memory clock frequency in kilohertz */
- int memoryBusWidth; /**< Global memory bus width in bits */
- int l2CacheSize; /**< Size of L2 cache in bytes */
- int maxThreadsPerMultiProcessor;/**< Maximum resident threads per multiprocessor */
- };
-
/** -
* CUDA device properties -
*/ -
struct __device_builtin__ cudaDeviceProp -
{ -
char name[256]; /**< ASCII string identifying device */ -
size_t totalGlobalMem; /**< Global memory available on device in bytes */ -
size_t sharedMemPerBlock; /**< Shared memory available per block in bytes */ -
int regsPerBlock; /**< 32-bit registers available per block */ -
int warpSize; /**< Warp size in threads */ -
size_t memPitch; /**< Maximum pitch in bytes allowed by memory copies */ -
int maxThreadsPerBlock; /**< Maximum number of threads per block */ -
int maxThreadsDim[3]; /**< Maximum size of each dimension of a block */ -
int maxGridSize[3]; /**< Maximum size of each dimension of a grid */ -
int clockRate; /**< Clock frequency in kilohertz */ -
size_t totalConstMem; /**< Constant memory available on device in bytes */ -
int major; /**< Major compute capability */ -
int minor; /**< Minor compute capability */ -
size_t textureAlignment; /**< Alignment requirement for textures */ -
size_t texturePitchAlignment; /**< Pitch alignment requirement for texture references bound to pitched memory */ -
int deviceOverlap; /**< Device can concurrently copy memory and execute a kernel. Deprecated. Use instead asyncEngineCount. */ -
int multiProcessorCount; /**< Number of multiprocessors on device */ -
int kernelExecTimeoutEnabled; /**< Specified whether there is a run time limit on kernels */ -
int integrated; /**< Device is integrated as opposed to discrete */ -
int canMapHostMemory; /**< Device can map host memory with cudaHostAlloc/cudaHostGetDevicePointer */ -
int computeMode; /**< Compute mode (See ::cudaComputeMode) */ -
int maxTexture1D; /**< Maximum 1D texture size */ -
int maxTexture1DMipmap; /**< Maximum 1D mipmapped texture size */ -
int maxTexture1DLinear; /**< Maximum size for 1D textures bound to linear memory */ -
int maxTexture2D[2]; /**< Maximum 2D texture dimensions */ -
int maxTexture2DMipmap[2]; /**< Maximum 2D mipmapped texture dimensions */ -
int maxTexture2DLinear[3]; /**< Maximum dimensions (width, height, pitch) for 2D textures bound to pitched memory */ -
int maxTexture2DGather[2]; /**< Maximum 2D texture dimensions if texture gather operations have to be performed */ -
int maxTexture3D[3]; /**< Maximum 3D texture dimensions */ -
int maxTextureCubemap; /**< Maximum Cubemap texture dimensions */ -
int maxTexture1DLayered[2]; /**< Maximum 1D layered texture dimensions */ -
int maxTexture2DLayered[3]; /**< Maximum 2D layered texture dimensions */ -
int maxTextureCubemapLayered[2];/**< Maximum Cubemap layered texture dimensions */ -
int maxSurface1D; /**< Maximum 1D surface size */ -
int maxSurface2D[2]; /**< Maximum 2D surface dimensions */ -
int maxSurface3D[3]; /**< Maximum 3D surface dimensions */ -
int maxSurface1DLayered[2]; /**< Maximum 1D layered surface dimensions */ -
int maxSurface2DLayered[3]; /**< Maximum 2D layered surface dimensions */ -
int maxSurfaceCubemap; /**< Maximum Cubemap surface dimensions */ -
int maxSurfaceCubemapLayered[2];/**< Maximum Cubemap layered surface dimensions */ -
size_t surfaceAlignment; /**< Alignment requirements for surfaces */ -
int concurrentKernels; /**< Device can possibly execute multiple kernels concurrently */ -
int ECCEnabled; /**< Device has ECC support enabled */ -
int pciBusID; /**< PCI bus ID of the device */ -
int pciDeviceID; /**< PCI device ID of the device */ -
int pciDomainID; /**< PCI domain ID of the device */ -
int tccDriver; /**< 1 if device is a Tesla device using TCC driver, 0 otherwise */ -
int asyncEngineCount; /**< Number of asynchronous engines */ -
int unifiedAddressing; /**< Device shares a unified address space with the host */ -
int memoryClockRate; /**< Peak memory clock frequency in kilohertz */ -
int memoryBusWidth; /**< Global memory bus width in bits */ -
int l2CacheSize; /**< Size of L2 cache in bytes */ -
int maxThreadsPerMultiProcessor;/**< Maximum resident threads per multiprocessor */ -
};
後面的註釋已經說明了其欄位代表意義,可能有些術語對於初學者理解起來還是有一定困難,沒關係,我們現在只需要關注以下幾個指標:
name:就是裝置名稱;
totalGlobalMem:就是視訊記憶體大小;
major,minor:CUDA裝置版本號,有1.1, 1.2, 1.3, 2.0, 2.1等多個版本;
clockRate:GPU時鐘頻率;
multiProcessorCount:GPU大核數,一個大核(專業點稱爲流多處理器,SM,Stream-Multiprocessor)包含多個小核(流處理器,SP,Stream-Processor)
編譯,執行,我們在VS2008工程的cudaGetDeviceProperties()函數處放一個斷點,單步執行這一函數,然後用Watch視窗,切換到Auto頁,展開+,在我的筆電上得到如下結果:
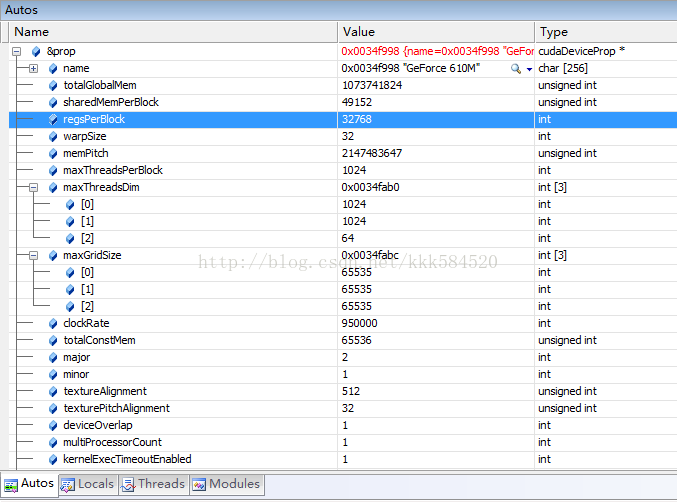
可以看到,裝置名爲GeForce 610M,視訊記憶體1GB,裝置版本2.1(比較高階了,哈哈),時鐘頻率爲950MHz(注意950000單位爲kHz),大核數爲1。在一些高效能GPU上(如Tesla,Kepler系列),大核數可能達到幾十甚至上百,可以做更大規模的並行處理。
PS:今天看SDK程式碼時發現在help_cuda.h中有個函數實現從CUDA裝置版本查詢相應大核中小核的數目,覺得很有用,以後程式設計序可以借鑑,摘抄如下:
[cpp] view plain copy
- // Beginning of GPU Architecture definitions
- inline int _ConvertSMVer2Cores(int major, int minor)
- {
- // Defines for GPU Architecture types (using the SM version to determine the # of cores per SM
- typedef struct
- {
- int SM; // 0xMm (hexidecimal notation), M = SM Major version, and m = SM minor version
- int Cores;
- } sSMtoCores;
- sSMtoCores nGpuArchCoresPerSM[] =
- {
- { 0x10, 8 }, // Tesla Generation (SM 1.0) G80 class
- { 0x11, 8 }, // Tesla Generation (SM 1.1) G8x class
- { 0x12, 8 }, // Tesla Generation (SM 1.2) G9x class
- { 0x13, 8 }, // Tesla Generation (SM 1.3) GT200 class
- { 0x20, 32 }, // Fermi Generation (SM 2.0) GF100 class
- { 0x21, 48 }, // Fermi Generation (SM 2.1) GF10x class
- { 0x30, 192}, // Kepler Generation (SM 3.0) GK10x class
- { 0x35, 192}, // Kepler Generation (SM 3.5) GK11x class
- { -1, -1 }
- };
- int index = 0;
- while (nGpuArchCoresPerSM[index].SM != -1)
- {
- if (nGpuArchCoresPerSM[index].SM == ((major << 4) + minor))
- {
- return nGpuArchCoresPerSM[index].Cores;
- }
- index++;
- }
- // If we don't find the values, we default use the previous one to run properly
- printf("MapSMtoCores for SM %d.%d is undefined. Default to use %d Cores/SM\n", major, minor, nGpuArchCoresPerSM[7].Cores);
- return nGpuArchCoresPerSM[7].Cores;
- }
- // end of GPU Architecture definitions
-
// Beginning of GPU Architecture definitions -
inline int _ConvertSMVer2Cores(int major, int minor) -
{ -
// Defines for GPU Architecture types (using the SM version to determine the # of cores per SM -
typedef struct -
{ -
int SM; // 0xMm (hexidecimal notation), M = SM Major version, and m = SM minor version -
int Cores; -
} sSMtoCores; -
sSMtoCores nGpuArchCoresPerSM[] = -
{ -
{ 0x10, 8 }, // Tesla Generation (SM 1.0) G80 class -
{ 0x11, 8 }, // Tesla Generation (SM 1.1) G8x class -
{ 0x12, 8 }, // Tesla Generation (SM 1.2) G9x class -
{ 0x13, 8 }, // Tesla Generation (SM 1.3) GT200 class -
{ 0x20, 32 }, // Fermi Generation (SM 2.0) GF100 class -
{ 0x21, 48 }, // Fermi Generation (SM 2.1) GF10x class -
{ 0x30, 192}, // Kepler Generation (SM 3.0) GK10x class -
{ 0x35, 192}, // Kepler Generation (SM 3.5) GK11x class -
{ -1, -1 } -
}; -
int index = 0; -
while (nGpuArchCoresPerSM[index].SM != -1) -
{ -
if (nGpuArchCoresPerSM[index].SM == ((major << 4) + minor)) -
{ -
return nGpuArchCoresPerSM[index].Cores; -
} -
index++; -
} -
// If we don't find the values, we default use the previous one to run properly -
printf("MapSMtoCores for SM %d.%d is undefined. Default to use %d Cores/SM\n", major, minor, nGpuArchCoresPerSM[7].Cores); -
return nGpuArchCoresPerSM[7].Cores; -
} -
// end of GPU Architecture definitions
可見,裝置版本2.1的一個大核有48個小核,而版本3.0以上的一個大核有192個小核!
前文說到過,當我們用的電腦上有多個顯示卡支援CUDA時,怎麼來區分在哪個上執行呢?這裏我們看一下addWithCuda這個函數是怎麼做的。
[cpp] view plain copy
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
-
cudaError_t cudaStatus; -
// Choose which GPU to run on, change this on a multi-GPU system. -
cudaStatus = cudaSetDevice(0); -
if (cudaStatus != cudaSuccess) { -
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); -
goto Error; -
}
使用了cudaSetDevice(0)這個操作,0表示能搜尋到的第一個裝置號,如果有多個裝置,則編號爲0,1,2...。
再看我們本節新增的程式碼,有個函數cudaGetDeviceCount(&num),這個函數用來獲取裝置總數,這樣我們選擇執行CUDA程式的裝置號取值就是0,1,...num-1,於是可以一個個列舉裝置,利用cudaGetDeviceProperties(&prop)獲得其屬性,然後利用一定排序、篩選演算法,找到最符合我們應用的那個裝置號opt,然後呼叫cudaSetDevice(opt)即可選擇該裝置。選擇標準可以從處理能力、版本控制、名稱等各個角度出發。後面講述流併發過程時,還要用到這些API。
如果希望瞭解更多硬體內容可以結合http://www.geforce.cn/hardware獲取。
多執行緒我們應該都不陌生,在操作系統中,進程是資源分配的基本單元,而執行緒是CPU時間排程的基本單元(這裏假設只有1個CPU)。
將執行緒的概念引申到CUDA程式設計中,我們可以認爲執行緒就是執行CUDA程式的最小單元,前面我們建立的工程程式碼中,有個核函數概念不知各位童鞋還記得沒有,在GPU上每個執行緒都會執行一次該核函數。
但GPU上的執行緒排程方式與CPU有很大不同。CPU上會有優先順序分配,從高到低,同樣優先順序的可以採用時間片輪轉法實現執行緒排程。GPU上執行緒沒有優先順序概念,所有執行緒機會均等,執行緒狀態只有等待資源和執行兩種狀態,如果資源未就緒,那麼就等待;一旦就緒,立即執行。當GPU資源很充裕時,所有執行緒都是併發執行的,這樣加速效果很接近理論加速比;而GPU資源少於匯流排程個數時,有一部分執行緒就會等待前面執行的執行緒釋放資源,從而變爲序列化執行。
程式碼還是用上一節的吧,改動很少,再貼一遍:
[cpp] view plain copy
- #include "cuda_runtime.h" //CUDA執行時API
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
- int main()
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- const int b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus;
- int num = 0;
- cudaDeviceProp prop;
- cudaStatus = cudaGetDeviceCount(&num);
- for(int i = 0;i<num;i++)
- {
- cudaGetDeviceProperties(&prop,i);
- }
- cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // 重點理解這個函數
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
- {
- int *dev_a = 0; //GPU裝置端數據指針
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus; //狀態指示
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0); //選擇執行平臺
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // 分配GPU裝置端記憶體
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // 拷貝數據到GPU
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- // 執行核函數
- <span style="BACKGROUND-COLOR: #ff6666"><strong> addKernel<<<1, size>>>(dev_c, dev_a, dev_b);</strong>
- </span> // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize(); //同步執行緒
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); //拷貝結果回主機
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- cudaFree(dev_c); //釋放GPU裝置端記憶體
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
-
#include "cuda_runtime.h" //CUDA執行時API -
#include "device_launch_parameters.h" -
#include <stdio.h> -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size); -
__global__ void addKernel(int *c, const int *a, const int *b) -
{ -
int i = threadIdx.x; -
c[i] = a[i] + b[i]; -
} -
int main() -
{ -
const int arraySize = 5; -
const int a[arraySize] = { 1, 2, 3, 4, 5 }; -
const int b[arraySize] = { 10, 20, 30, 40, 50 }; -
int c[arraySize] = { 0 }; -
// Add vectors in parallel. -
cudaError_t cudaStatus; -
int num = 0; -
cudaDeviceProp prop; -
cudaStatus = cudaGetDeviceCount(&num); -
for(int i = 0;i<num;i++) -
{ -
cudaGetDeviceProperties(&prop,i); -
} -
cudaStatus = addWithCuda(c, a, b, arraySize); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "addWithCuda failed!"); -
return 1; -
} -
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]); -
// cudaThreadExit must be called before exiting in order for profiling and -
// tracing tools such as Nsight and Visual Profiler to show complete traces. -
cudaStatus = cudaThreadExit(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadExit failed!"); -
return 1; -
} -
return 0; -
} -
// 重點理解這個函數 -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size) -
{ -
int *dev_a = 0; //GPU裝置端數據指針 -
int *dev_b = 0; -
int *dev_c = 0; -
cudaError_t cudaStatus; //狀態指示 -
// Choose which GPU to run on, change this on a multi-GPU system. -
cudaStatus = cudaSetDevice(0); //選擇執行平臺 -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); -
goto Error; -
} -
// 分配GPU裝置端記憶體 -
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
// 拷貝數據到GPU -
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
// 執行核函數 -
<span style="BACKGROUND-COLOR: #ff6666"><strong> addKernel<<<1, size>>>(dev_c, dev_a, dev_b);</strong> -
</span> // cudaThreadSynchronize waits for the kernel to finish, and returns -
// any errors encountered during the launch. -
cudaStatus = cudaThreadSynchronize(); //同步執行緒 -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus); -
goto Error; -
} -
// Copy output vector from GPU buffer to host memory. -
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); //拷貝結果回主機 -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
Error: -
cudaFree(dev_c); //釋放GPU裝置端記憶體 -
cudaFree(dev_a); -
cudaFree(dev_b); -
return cudaStatus; -
}
紅色部分即啓動核函數的呼叫過程,這裏看到呼叫方式和C不太一樣。<<<>>>表示執行時設定符號,裏面1表示只分配一個執行緒組(又稱執行緒塊、Block),size表示每個執行緒組有size個執行緒(Thread)。本程式中size根據前面傳遞參數個數應該爲5,所以執行的時候,核函數在5個GPU執行緒單元上分別執行了一次,總共執行了5次。這5個執行緒是如何知道自己「身份」的?是靠threadIdx這個內建變數,它是個dim3型別變數,接受<<<>>>中第二個參數,它包含x,y,z 3維座標,而我們傳入的參數只有一維,所以只有x值是有效的。通過核函數中int i = threadIdx.x;這一句,每個執行緒可以獲得自身的id號,從而找到自己的任務去執行。
同一版本的程式碼用了這麼多次,有點過意不去,於是這次我要做較大的改動,大家要擦亮眼睛,拭目以待。
塊並行相當於操作系統中多進程的情況,上節說到,CUDA有執行緒組(執行緒塊)的概念,將一組執行緒組織到一起,共同分配一部分資源,然後內部排程執行。執行緒塊與執行緒塊之間,毫無瓜葛。這有利於做更粗粒度的並行。我們將上一節的程式碼改爲塊並行版本如下:
下節我們介紹塊並行。
[cpp] view plain copy
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- <span style="BACKGROUND-COLOR: #ff0000"> int i = blockIdx.x;
- </span> c[i] = a[i] + b[i];
- }
- int main()
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- const int b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus;
- int num = 0;
- cudaDeviceProp prop;
- cudaStatus = cudaGetDeviceCount(&num);
- for(int i = 0;i<num;i++)
- {
- cudaGetDeviceProperties(&prop,i);
- }
- cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- // Launch a kernel on the GPU with one thread for each element.
- <span style="BACKGROUND-COLOR: #ff0000"> addKernel<<<size,1 >>>(dev_c, dev_a, dev_b);
- </span> // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
-
#include "cuda_runtime.h" -
#include "device_launch_parameters.h" -
#include <stdio.h> -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size); -
__global__ void addKernel(int *c, const int *a, const int *b) -
{ -
<span style="BACKGROUND-COLOR: #ff0000"> int i = blockIdx.x; -
</span> c[i] = a[i] + b[i]; -
} -
int main() -
{ -
const int arraySize = 5; -
const int a[arraySize] = { 1, 2, 3, 4, 5 }; -
const int b[arraySize] = { 10, 20, 30, 40, 50 }; -
int c[arraySize] = { 0 }; -
// Add vectors in parallel. -
cudaError_t cudaStatus; -
int num = 0; -
cudaDeviceProp prop; -
cudaStatus = cudaGetDeviceCount(&num); -
for(int i = 0;i<num;i++) -
{ -
cudaGetDeviceProperties(&prop,i); -
} -
cudaStatus = addWithCuda(c, a, b, arraySize); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "addWithCuda failed!"); -
return 1; -
} -
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]); -
// cudaThreadExit must be called before exiting in order for profiling and -
// tracing tools such as Nsight and Visual Profiler to show complete traces. -
cudaStatus = cudaThreadExit(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadExit failed!"); -
return 1; -
} -
return 0; -
} -
// Helper function for using CUDA to add vectors in parallel. -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size) -
{ -
int *dev_a = 0; -
int *dev_b = 0; -
int *dev_c = 0; -
cudaError_t cudaStatus; -
// Choose which GPU to run on, change this on a multi-GPU system. -
cudaStatus = cudaSetDevice(0); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); -
goto Error; -
} -
// Allocate GPU buffers for three vectors (two input, one output) . -
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
// Copy input vectors from host memory to GPU buffers. -
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
// Launch a kernel on the GPU with one thread for each element. -
<span style="BACKGROUND-COLOR: #ff0000"> addKernel<<<size,1 >>>(dev_c, dev_a, dev_b); -
</span> // cudaThreadSynchronize waits for the kernel to finish, and returns -
// any errors encountered during the launch. -
cudaStatus = cudaThreadSynchronize(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus); -
goto Error; -
} -
// Copy output vector from GPU buffer to host memory. -
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
Error: -
cudaFree(dev_c); -
cudaFree(dev_a); -
cudaFree(dev_b); -
return cudaStatus; -
}
和上一節相比,只有這兩行有改變,<<<>>>裡第一個參數改成了size,第二個改成了1,表示我們分配size個執行緒塊,每個執行緒塊僅包含1個執行緒,總共還是有5個執行緒。這5個執行緒相互獨立,執行核函數得到相應的結果,與上一節不同的是,每個執行緒獲取id的方式變爲int i = blockIdx.x;這是執行緒塊ID。
於是有童鞋提問了,執行緒並行和塊並行的區別在哪裏?
執行緒並行是細粒度並行,排程效率高;塊並行是粗粒度並行,每次排程都要重新分配資源,有時資源只有一份,那麼所有執行緒塊都只能排成一隊,序列執行。
那是不是我們所有時候都應該用執行緒並行,儘可能不用塊並行?
當然不是,我們的任務有時可以採用分治法,將一個大問題分解爲幾個小規模問題,將這些小規模問題分別用一個執行緒塊實現,執行緒塊內可以採用細粒度的執行緒並行,而塊之間爲粗粒度並行,這樣可以充分利用硬體資源,降低執行緒並行的計算複雜度。適當分解,降低規模,在一些矩陣乘法、向量內積計算應用中可以得到充分的展示。
實際應用中,常常是二者的結合。執行緒塊、執行緒組織圖如下所示。
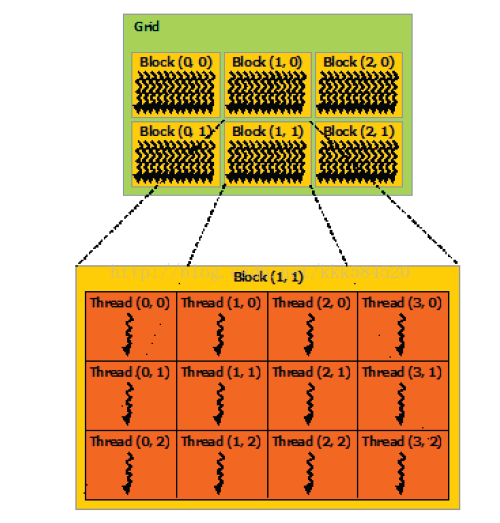
多個執行緒塊組織成了一個Grid,稱爲執行緒格(經歷了從一位執行緒,二維執行緒塊到三維執行緒格的過程,立體感很強啊)。
好了,下一節我們介紹流並行,是更高層次的並行。
前面我們沒有講程式的結構,我想有些童鞋可能迫不及待想知道CUDA程式到底是怎麼一個執行過程。好的,這一節在介紹流之前,先把CUDA程式結構簡要說一下。
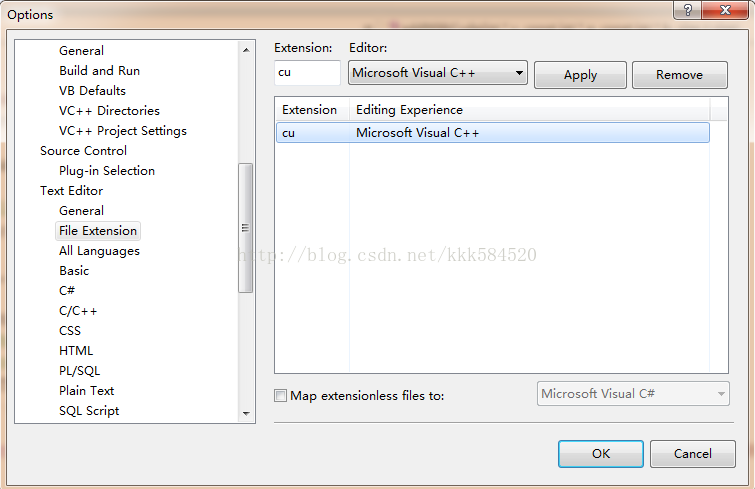
CUDA程式檔案後綴爲.cu,有些編譯器可能不認識這個後綴的檔案,我們可以在VS2008的Tools->Options->Text Editor->File Extension裡新增cu後綴到VC++中,如下圖:
一個.cu檔案內既包含CPU程式(稱爲主機程式),也包含GPU程式(稱爲裝置程式)。如何區分主機程式和裝置程式?根據宣告,凡是掛有「__global__」或者「__device__」字首的函數,都是在GPU上執行的裝置程式,不同的是__global__裝置程式可被主機程式呼叫,而__device__裝置程式則只能被裝置程式呼叫。
沒有掛任何字首的函數,都是主機程式。主機程式顯示宣告可以用__host__字首。裝置程式需要由NVCC進行編譯,而主機程式只需要由主機編譯器(如VS2008中的cl.exe,Linux上的GCC)。主機程式主要完成裝置環境初始化,數據傳輸等必備過程,裝置程式只負責計算。
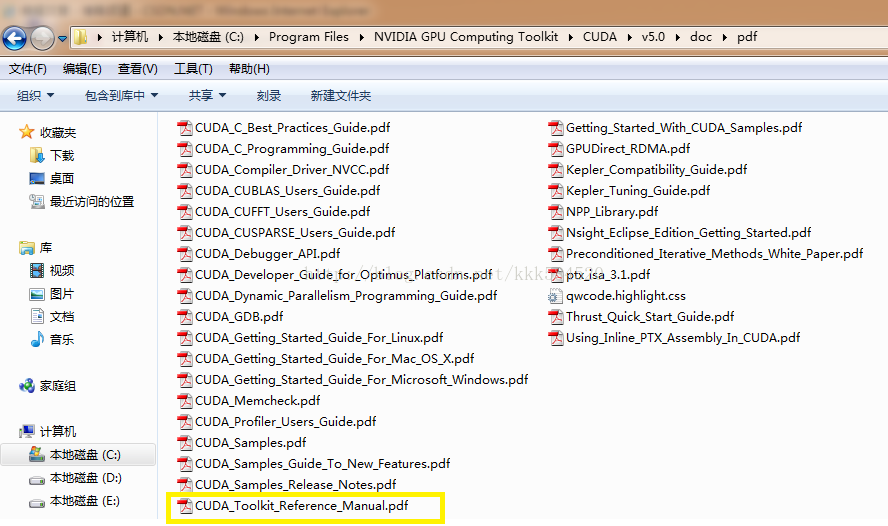
主機程式中,有一些「cuda」打頭的函數,這些都是CUDA Runtime API,即執行時函數,主要負責完成裝置的初始化、記憶體分配、記憶體拷貝等任務。我們前面第三節用到的函數cudaGetDeviceCount(),cudaGetDeviceProperties(),cudaSetDevice()都是執行時API。這些函數的具體參數宣告我們不必一一記下來,拿出第三節的官方利器就可以輕鬆查詢,讓我們開啓這個檔案:
開啓後,在pdf搜尋欄中輸入一個執行時函數,例如cudaMemcpy,查到的結果如下:
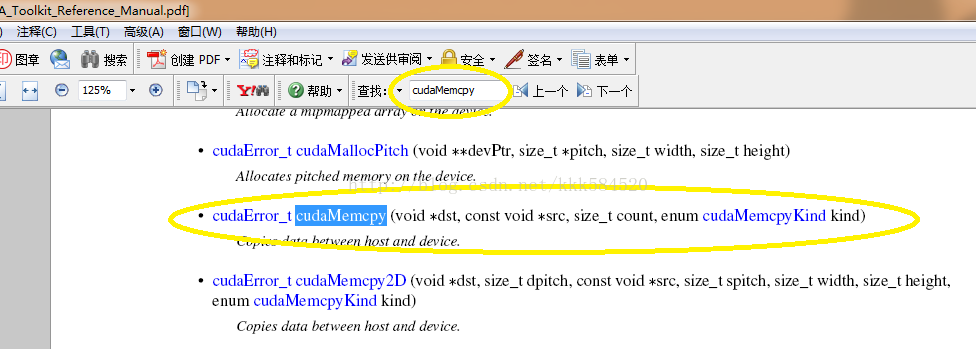
可以看到,該API函數的參數形式爲,第一個表示目的地,第二個表示來源地,第三個參數表示位元組數,第四個表示型別。如果對型別不瞭解,直接點選超鏈接,得到詳細解釋如下:

可見,該API可以實現從主機到主機、主機到裝置、裝置到主機、裝置到裝置的記憶體拷貝過程。同時可以發現,利用該API手冊可以很方便地查詢我們需要用的這些API函數,所以以後編CUDA程式一定要把它開啓,隨時準備查詢,這樣可以大大提高程式設計效率。
好了,進入今天的主題:流並行。
前面已經介紹了執行緒並行和塊並行,知道了執行緒並行爲細粒度的並行,而塊並行爲粗粒度的並行,同時也知道了CUDA的執行緒組織情況,即Grid-Block-Thread結構。一組執行緒並行處理可以組織爲一個block,而一組block並行處理可以組織爲一個Grid,很自然地想到,Grid只是一個網格,我們是否可以利用多個網格來完成並行處理呢?答案就是利用流。
流可以實現在一個裝置上執行多個核函數。前面的塊並行也好,執行緒並行也好,執行的核函數都是相同的(程式碼一樣,傳遞參數也一樣)。而流並行,可以執行不同的核函數,也可以實現對同一個核函數傳遞不同的參數,實現任務級別的並行。
CUDA中的流用cudaStream_t型別實現,用到的API有以下幾個:cudaStreamCreate(cudaStream_t * s)用於建立流,cudaStreamDestroy(cudaStream_t s)用於銷燬流,cudaStreamSynchronize()用於單個流同步,cudaDeviceSynchronize()用於整個裝置上的所有流同步,cudaStreamQuery()用於查詢一個流的任務是否已經完成。具體的含義可以查詢API手冊。
下面 下麪我們將前面的兩個例子中的任務改用流實現,仍然是{1,2,3,4,5}+{10,20,30,40,50} = {11,22,33,44,55}這個例子。程式碼如下:
[cpp] view plain copy
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = blockIdx.x;
- c[i] = a[i] + b[i];
- }
- int main()
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- const int b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus;
- int num = 0;
- cudaDeviceProp prop;
- cudaStatus = cudaGetDeviceCount(&num);
- for(int i = 0;i<num;i++)
- {
- cudaGetDeviceProperties(&prop,i);
- }
- cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- <span style="BACKGROUND-COLOR: #ff6666"> cudaStream_t stream[5];
- for(int i = 0;i<5;i++)
- {
- cudaStreamCreate(&stream[i]); //建立流
- }
- </span> // Launch a kernel on the GPU with one thread for each element.
- <span style="BACKGROUND-COLOR: #ff6666"> for(int i = 0;i<5;i++)
- {
- addKernel<<<1,1,0,stream[i]>>>(dev_c+i, dev_a+i, dev_b+i); //執行流
- }
- cudaDeviceSynchronize();
- </span> // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- <span style="BACKGROUND-COLOR: #ff6666"> for(int i = 0;i<5;i++)
- {
- cudaStreamDestroy(stream[i]); //銷燬流
- }
- </span> cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
-
#include "cuda_runtime.h" -
#include "device_launch_parameters.h" -
#include <stdio.h> -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size); -
__global__ void addKernel(int *c, const int *a, const int *b) -
{ -
int i = blockIdx.x; -
c[i] = a[i] + b[i]; -
} -
int main() -
{ -
const int arraySize = 5; -
const int a[arraySize] = { 1, 2, 3, 4, 5 }; -
const int b[arraySize] = { 10, 20, 30, 40, 50 }; -
int c[arraySize] = { 0 }; -
// Add vectors in parallel. -
cudaError_t cudaStatus; -
int num = 0; -
cudaDeviceProp prop; -
cudaStatus = cudaGetDeviceCount(&num); -
for(int i = 0;i<num;i++) -
{ -
cudaGetDeviceProperties(&prop,i); -
} -
cudaStatus = addWithCuda(c, a, b, arraySize); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "addWithCuda failed!"); -
return 1; -
} -
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]); -
// cudaThreadExit must be called before exiting in order for profiling and -
// tracing tools such as Nsight and Visual Profiler to show complete traces. -
cudaStatus = cudaThreadExit(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadExit failed!"); -
return 1; -
} -
return 0; -
} -
// Helper function for using CUDA to add vectors in parallel. -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size) -
{ -
int *dev_a = 0; -
int *dev_b = 0; -
int *dev_c = 0; -
cudaError_t cudaStatus; -
// Choose which GPU to run on, change this on a multi-GPU system. -
cudaStatus = cudaSetDevice(0); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); -
goto Error; -
} -
// Allocate GPU buffers for three vectors (two input, one output) . -
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
// Copy input vectors from host memory to GPU buffers. -
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
<span style="BACKGROUND-COLOR: #ff6666"> cudaStream_t stream[5]; -
for(int i = 0;i<5;i++) -
{ -
cudaStreamCreate(&stream[i]); //建立流 -
} -
</span> // Launch a kernel on the GPU with one thread for each element. -
<span style="BACKGROUND-COLOR: #ff6666"> for(int i = 0;i<5;i++) -
{ -
addKernel<<<1,1,0,stream[i]>>>(dev_c+i, dev_a+i, dev_b+i); //執行流 -
} -
cudaDeviceSynchronize(); -
</span> // cudaThreadSynchronize waits for the kernel to finish, and returns -
// any errors encountered during the launch. -
cudaStatus = cudaThreadSynchronize(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus); -
goto Error; -
} -
// Copy output vector from GPU buffer to host memory. -
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
Error: -
<span style="BACKGROUND-COLOR: #ff6666"> for(int i = 0;i<5;i++) -
{ -
cudaStreamDestroy(stream[i]); //銷燬流 -
} -
</span> cudaFree(dev_c); -
cudaFree(dev_a); -
cudaFree(dev_b); -
return cudaStatus; -
}
注意到,我們的核函數程式碼仍然和塊並行的版本一樣,只是在呼叫時做了改變,<<<>>>中的參數多了兩個,其中前兩個和塊並行、執行緒並行中的意義相同,仍然是執行緒塊數(這裏爲1)、每個執行緒塊中執行緒數(這裏也是1)。第三個爲0表示每個block用到的共用記憶體大小,這個我們後面再講;第四個爲流物件,表示當前核函數在哪個流上執行。我們建立了5個流,每個流上都裝載了一個核函數,同時傳遞參數有些不同,也就是每個核函數作用的物件也不同。這樣就實現了任務級別的並行,當我們有幾個互不相關的任務時,可以寫多個核函數,資源允許的情況下,我們將這些核函數裝載到不同流上,然後執行,這樣可以實現更粗粒度的並行。
好了,流並行就這麼簡單,我們處理任務時,可以根據需要,選擇最適合的並行方式。
我們前面幾節主要介紹了三種利用GPU實現並行處理的方式:執行緒並行,塊並行和流並行。在這些方法中,我們一再強調,各個執行緒所進行的處理是互不相關的,即兩個執行緒不回產生交集,每個執行緒都只關注自己的一畝三分地,對其他執行緒毫無興趣,就當不存在。。。。
當然,實際應用中,這樣的例子太少了,也就是遇到向量相加、向量對應點乘這類纔會有如此高的並行度,而其他一些應用,如一組數求和,求最大(小)值,各個執行緒不再是相互獨立的,而是產生一定關聯,執行緒2可能會用到執行緒1的結果,這時就需要利用本節的執行緒通訊技術了。
執行緒通訊在CUDA中有三種實現方式:
1. 共用記憶體;
2. 執行緒 同步;
3. 原子操作;
最常用的是前兩種方式,共用記憶體,術語Shared Memory,是位於SM中的特殊記憶體。還記得SM嗎,就是流多處理器,大核是也。一個SM中不僅包含若幹個SP(流處理器,小核),還包括一部分高速Cache,暫存器組,共用記憶體等,結構如圖所示:
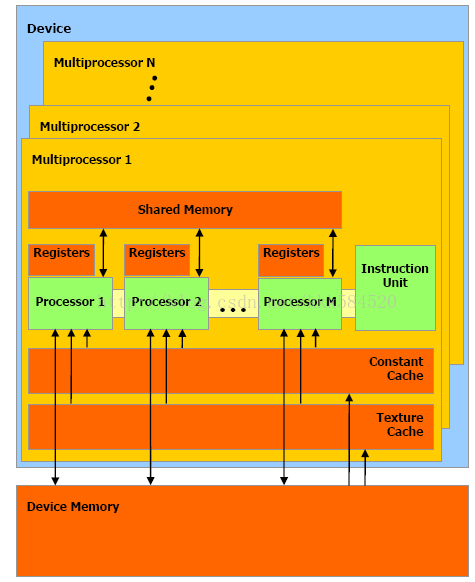
從圖中可看出,一個SM內有M個SP,Shared Memory由這M個SP共同佔有。另外指令單元也被這M個SP共用,即SIMT架構(單指令多執行緒架構),一個SM中所有SP在同一時間執行同一程式碼。
爲了實現執行緒通訊,僅僅靠共用記憶體還不夠,需要有同步機制 機製才能 纔能使執行緒之間實現有序處理。通常情況是這樣:當執行緒A需要執行緒B計算的結果作爲輸入時,需要確保執行緒B已經將結果寫入共用記憶體中,然後執行緒A再從共用記憶體中讀出。同步必不可少,否則,執行緒A可能讀到的是無效的結果,造成計算錯誤。同步機制 機製可以用CUDA內建函數:__syncthreads();當某個執行緒執行到該函數時,進入等待狀態,直到同一執行緒塊(Block)中所有執行緒都執行到這個函數爲止,即一個__syncthreads()相當於一個執行緒同步點,確保一個Block中所有執行緒都達到同步,然後執行緒進入執行狀態。
綜上兩點,我們可以寫一段執行緒通訊的虛擬碼如下:
[cpp] view plain copy
- //Begin
- if this is thread B
- write something to Shared Memory;
- end if
- __syncthreads();
- if this is thread A
- read something from Shared Memory;
- end if
- //End
-
//Begin -
if this is thread B -
write something to Shared Memory; -
end if -
__syncthreads(); -
if this is thread A -
read something from Shared Memory; -
end if -
//End
上面程式碼在CUDA中實現時,由於SIMT特性,所有執行緒都執行同樣的程式碼,所以線上程中需要判斷自己的身份,以免誤操作。
注意的是,位於同一個Block中的執行緒才能 纔能實現通訊,不同Block中的執行緒不能通過共用記憶體、同步進行通訊,而應採用原子操作或主機介入。
對於原子操作,如果感興趣可以翻閱《GPU高效能程式設計CUDA實戰》第九章「原子性」。
本節完。下節我們給出一個範例來看執行緒通訊的程式碼怎麼設計。
接着上一節,我們利用剛學到的共用記憶體和執行緒同步技術,來做一個簡單的例子。先看下效果吧:
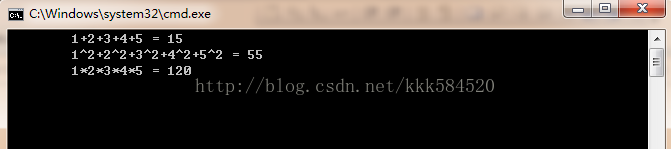
很簡單,就是分別求出1~5這5個數字的和,平方和,連乘積。相信學過C語言的童鞋都能用for回圈做出同上面一樣的效果,但爲了學習CUDA共用記憶體和同步技術,我們還是要把簡單的東西複雜化(^_^)。
簡要分析一下,上面例子的輸入都是一樣的,1,2,3,4,5這5個數,但計算過程有些變化,而且每個輸出和所有輸入都相關,不是前幾節例子中那樣,一個輸出只和一個輸入有關。所以我們在利用CUDA程式設計時,需要針對特殊問題做些讓步,把一些步驟序列化實現。
輸入數據原本位於主機記憶體,通過cudaMemcpy API已經拷貝到GPU視訊記憶體(術語爲全域性記憶體,Global Memory),每個執行緒執行時需要從Global Memory讀取輸入數據,然後完成計算,最後將結果寫回Global Memory。當我們計算需要多次相同輸入數據時,大家可能想到,每次都分別去Global Memory讀數據好像有點浪費,如果數據很大,那麼反覆 反復多次讀數據會相當耗時間。索性我們把它從Global Memory一次性讀到SM內部,然後在內部進行處理,這樣可以節省反覆 反復讀取的時間。
有了這個思路,結合上節看到的SM結構圖,看到有一片記憶體叫做Shared Memory,它位於SM內部,處理時存取速度相當快(差不多每個時鐘週期讀一次),而全域性記憶體讀一次需要耗費幾十甚至上百個時鐘週期。於是,我們就制定A計劃如下:
執行緒塊數:1,塊號爲0;(只有一個執行緒塊內的執行緒才能 纔能進行通訊,所以我們只分配一個執行緒塊,具體工作交給每個執行緒完成)
執行緒數:5,執行緒號分別爲0~4;(執行緒並行,前面講過)
共用記憶體大小:5個int型變數大小(5 * sizeof(int))。
步驟一:讀取輸入數據。將Global Memory中的5個整數讀入共用記憶體,位置一一對應,和執行緒號也一一對應,所以可以同時完成。
步驟二:執行緒同步,確保所有執行緒都完成了工作。
步驟三:指定執行緒,對共用記憶體中的輸入數據完成相應處理。
程式碼如下:
[cpp] view plain copy
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, const int *a, size_t size);
- __global__ void addKernel(int *c, const int *a)
- {
- int i = threadIdx.x;
- <span style="font-size:24px;"><strong> extern __shared__ int smem[];</strong>
- </span> smem[i] = a[i];
- __syncthreads();
- if(i == 0) // 0號執行緒做平方和
- {
- c[0] = 0;
- for(int d = 0; d < 5; d++)
- {
- c[0] += smem[d] * smem[d];
- }
- }
- if(i == 1)//1號執行緒做累加
- {
- c[1] = 0;
- for(int d = 0; d < 5; d++)
- {
- c[1] += smem[d];
- }
- }
- if(i == 2) //2號執行緒做累乘
- {
- c[2] = 1;
- for(int d = 0; d < 5; d++)
- {
- c[2] *= smem[d];
- }
- }
- }
- int main()
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus = addWithCuda(c, a, arraySize);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("\t1+2+3+4+5 = %d\n\t1^2+2^2+3^2+4^2+5^2 = %d\n\t1*2*3*4*5 = %d\n\n\n\n\n\n", c[1], c[0], c[2]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, const int *a, size_t size)
- {
- int *dev_a = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- // Launch a kernel on the GPU with one thread for each element.
- <span style="font-size:24px;"><strong> addKernel<<<1, size, size * sizeof(int), 0>>>(dev_c, dev_a);</strong>
- </span>
- // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- return cudaStatus;
- }
-
#include "cuda_runtime.h" -
#include "device_launch_parameters.h" -
#include <stdio.h> -
cudaError_t addWithCuda(int *c, const int *a, size_t size); -
__global__ void addKernel(int *c, const int *a) -
{ -
int i = threadIdx.x; -
<span style="font-size:24px;"><strong> extern __shared__ int smem[];</strong> -
</span> smem[i] = a[i]; -
__syncthreads(); -
if(i == 0) // 0號執行緒做平方和 -
{ -
c[0] = 0; -
for(int d = 0; d < 5; d++) -
{ -
c[0] += smem[d] * smem[d]; -
} -
} -
if(i == 1)//1號執行緒做累加 -
{ -
c[1] = 0; -
for(int d = 0; d < 5; d++) -
{ -
c[1] += smem[d]; -
} -
} -
if(i == 2) //2號執行緒做累乘 -
{ -
c[2] = 1; -
for(int d = 0; d < 5; d++) -
{ -
c[2] *= smem[d]; -
} -
} -
} -
int main() -
{ -
const int arraySize = 5; -
const int a[arraySize] = { 1, 2, 3, 4, 5 }; -
int c[arraySize] = { 0 }; -
// Add vectors in parallel. -
cudaError_t cudaStatus = addWithCuda(c, a, arraySize); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "addWithCuda failed!"); -
return 1; -
} -
printf("\t1+2+3+4+5 = %d\n\t1^2+2^2+3^2+4^2+5^2 = %d\n\t1*2*3*4*5 = %d\n\n\n\n\n\n", c[1], c[0], c[2]); -
// cudaThreadExit must be called before exiting in order for profiling and -
// tracing tools such as Nsight and Visual Profiler to show complete traces. -
cudaStatus = cudaThreadExit(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadExit failed!"); -
return 1; -
} -
return 0; -
} -
// Helper function for using CUDA to add vectors in parallel. -
cudaError_t addWithCuda(int *c, const int *a, size_t size) -
{ -
int *dev_a = 0; -
int *dev_c = 0; -
cudaError_t cudaStatus; -
// Choose which GPU to run on, change this on a multi-GPU system. -
cudaStatus = cudaSetDevice(0); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); -
goto Error; -
} -
// Allocate GPU buffers for three vectors (two input, one output) . -
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
// Copy input vectors from host memory to GPU buffers. -
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
// Launch a kernel on the GPU with one thread for each element. -
<span style="font-size:24px;"><strong> addKernel<<<1, size, size * sizeof(int), 0>>>(dev_c, dev_a);</strong> -
</span> -
// cudaThreadSynchronize waits for the kernel to finish, and returns -
// any errors encountered during the launch. -
cudaStatus = cudaThreadSynchronize(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus); -
goto Error; -
} -
// Copy output vector from GPU buffer to host memory. -
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
Error: -
cudaFree(dev_c); -
cudaFree(dev_a); -
return cudaStatus; -
}
從程式碼中看到執行設定<<<>>>中第三個參數爲共用記憶體大小(位元組數),這樣我們就知道了全部4個執行設定參數的意義。恭喜,你的CUDA終於入門了!
CUDA從入門到精通(十):效能剖析和Visual Profiler
入門後的進一步學習的內容,就是如何優化自己的程式碼。我們前面的例子沒有考慮任何效能方面優化,是爲了更好地學習基本知識點,而不是其他細節問題。從本節開始,我們要從效能出發考慮問題,不斷優化程式碼,使執行速度提高是並行處理的唯一目的。
測試程式碼執行速度有很多方法,C語言裡提供了類似於SystemTime()這樣的API獲得系統時間,然後計算兩個事件之間的時長從而完成計時功能。在CUDA中,我們有專門測量裝置執行時間的API,下面 下麪一一介紹。
翻開程式設計手冊《CUDA_Toolkit_Reference_Manual》,隨時準備查詢不懂得API。我們在執行核函數前後,做如下操作:
[cpp] view plain copy
- cudaEvent_t start, stop;<span style="white-space: pre;"> </span>//事件物件
- cudaEventCreate(&start);<span style="white-space: pre;"> </span>//建立事件
- cudaEventCreate(&stop);<span style="white-space: pre;"> </span>//建立事件
- cudaEventRecord(start, stream);<span style="white-space: pre;"> </span>//記錄開始
- myKernel<<<dimg,dimb,size_smem,stream>>>(parameter list);//執行核函數
- cudaEventRecord(stop,stream);<span style="white-space: pre;"> </span>//記錄結束事件
- cudaEventSynchronize(stop);<span style="white-space: pre;"> </span>//事件同步,等待結束事件之前的裝置操作均已完成
- float elapsedTime;
- cudaEventElapsedTime(&elapsedTime,start,stop);//計算兩個事件之間時長(單位爲ms)
-
cudaEvent_t start, stop; //事件物件 -
cudaEventCreate(&start); //建立事件 -
cudaEventCreate(&stop); //建立事件 -
cudaEventRecord(start, stream); //記錄開始 -
myKernel<<<dimg,dimb,size_smem,stream>>>(parameter list);//執行核函數 -
cudaEventRecord(stop,stream); //記錄結束事件 -
cudaEventSynchronize(stop); //事件同步,等待結束事件之前的裝置操作均已完成 -
float elapsedTime; -
cudaEventElapsedTime(&elapsedTime,start,stop);//計算兩個事件之間時長(單位爲ms)
核函數執行時間將被儲存在變數elapsedTime中。通過這個值我們可以評估演算法的效能。下面 下麪給一個例子,來看怎麼使用計時功能。
前面的例子規模很小,只有5個元素,處理量太小不足以計時,下面 下麪將規模擴大爲1024,此外將反覆 反復執行1000次計算總時間,這樣估計不容易受隨機擾動影響。我們通過這個例子對比執行緒並行和塊並行的效能如何。程式碼如下:
[cpp] view plain copy
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
- __global__ void addKernel_blk(int *c, const int *a, const int *b)
- {
- int i = blockIdx.x;
- c[i] = a[i]+ b[i];
- }
- __global__ void addKernel_thd(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i]+ b[i];
- }
- int main()
- {
- const int arraySize = 1024;
- int a[arraySize] = {0};
- int b[arraySize] = {0};
- for(int i = 0;i<arraySize;i++)
- {
- a[i] = i;
- b[i] = arraySize-i;
- }
- int c[arraySize] = {0};
- // Add vectors in parallel.
- cudaError_t cudaStatus;
- int num = 0;
- cudaDeviceProp prop;
- cudaStatus = cudaGetDeviceCount(&num);
- for(int i = 0;i<num;i++)
- {
- cudaGetDeviceProperties(&prop,i);
- }
- cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- for(int i = 0;i<arraySize;i++)
- {
- if(c[i] != (a[i]+b[i]))
- {
- printf("Error in %d\n",i);
- }
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaEvent_t start,stop;
- cudaEventCreate(&start);
- cudaEventCreate(&stop);
- cudaEventRecord(start,0);
- for(int i = 0;i<1000;i++)
- {
- // addKernel_blk<<<size,1>>>(dev_c, dev_a, dev_b);
- addKernel_thd<<<1,size>>>(dev_c, dev_a, dev_b);
- }
- cudaEventRecord(stop,0);
- cudaEventSynchronize(stop);
- float tm;
- cudaEventElapsedTime(&tm,start,stop);
- printf("GPU Elapsed time:%.6f ms.\n",tm);
- // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
-
#include "cuda_runtime.h" -
#include "device_launch_parameters.h" -
#include <stdio.h> -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size); -
__global__ void addKernel_blk(int *c, const int *a, const int *b) -
{ -
int i = blockIdx.x; -
c[i] = a[i]+ b[i]; -
} -
__global__ void addKernel_thd(int *c, const int *a, const int *b) -
{ -
int i = threadIdx.x; -
c[i] = a[i]+ b[i]; -
} -
int main() -
{ -
const int arraySize = 1024; -
int a[arraySize] = {0}; -
int b[arraySize] = {0}; -
for(int i = 0;i<arraySize;i++) -
{ -
a[i] = i; -
b[i] = arraySize-i; -
} -
int c[arraySize] = {0}; -
// Add vectors in parallel. -
cudaError_t cudaStatus; -
int num = 0; -
cudaDeviceProp prop; -
cudaStatus = cudaGetDeviceCount(&num); -
for(int i = 0;i<num;i++) -
{ -
cudaGetDeviceProperties(&prop,i); -
} -
cudaStatus = addWithCuda(c, a, b, arraySize); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "addWithCuda failed!"); -
return 1; -
} -
// cudaThreadExit must be called before exiting in order for profiling and -
// tracing tools such as Nsight and Visual Profiler to show complete traces. -
cudaStatus = cudaThreadExit(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadExit failed!"); -
return 1; -
} -
for(int i = 0;i<arraySize;i++) -
{ -
if(c[i] != (a[i]+b[i])) -
{ -
printf("Error in %d\n",i); -
} -
} -
return 0; -
} -
// Helper function for using CUDA to add vectors in parallel. -
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size) -
{ -
int *dev_a = 0; -
int *dev_b = 0; -
int *dev_c = 0; -
cudaError_t cudaStatus; -
// Choose which GPU to run on, change this on a multi-GPU system. -
cudaStatus = cudaSetDevice(0); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); -
goto Error; -
} -
// Allocate GPU buffers for three vectors (two input, one output) . -
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMalloc failed!"); -
goto Error; -
} -
// Copy input vectors from host memory to GPU buffers. -
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
cudaEvent_t start,stop; -
cudaEventCreate(&start); -
cudaEventCreate(&stop); -
cudaEventRecord(start,0); -
for(int i = 0;i<1000;i++) -
{ -
// addKernel_blk<<<size,1>>>(dev_c, dev_a, dev_b); -
addKernel_thd<<<1,size>>>(dev_c, dev_a, dev_b); -
} -
cudaEventRecord(stop,0); -
cudaEventSynchronize(stop); -
float tm; -
cudaEventElapsedTime(&tm,start,stop); -
printf("GPU Elapsed time:%.6f ms.\n",tm); -
// cudaThreadSynchronize waits for the kernel to finish, and returns -
// any errors encountered during the launch. -
cudaStatus = cudaThreadSynchronize(); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus); -
goto Error; -
} -
// Copy output vector from GPU buffer to host memory. -
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); -
if (cudaStatus != cudaSuccess) -
{ -
fprintf(stderr, "cudaMemcpy failed!"); -
goto Error; -
} -
Error: -
cudaFree(dev_c); -
cudaFree(dev_a); -
cudaFree(dev_b); -
return cudaStatus; -
}
addKernel_blk是採用塊並行實現的向量相加操作,而addKernel_thd是採用執行緒並行實現的向量相加操作。分別執行,得到的結果如下圖所示:
執行緒並行:

塊並行:
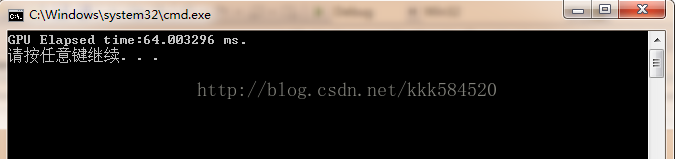
可見效能竟然相差近16倍!因此選擇並行處理方法時,如果問題規模不是很大,那麼採用執行緒並行是比較合適的,而大問題分多個執行緒塊處理時,每個塊內執行緒數不要太少,像本文中的只有1個執行緒,這是對硬體資源的極大浪費。一個理想的方案是,分N個執行緒塊,每個執行緒塊包含512個執行緒,將問題分解處理,效率往往比單一的執行緒並行處理或單一塊並行處理高很多。這也是CUDA程式設計的精髓。
上面這種分析程式效能的方式比較粗糙,只知道大概執行時間長度,對於裝置程式各部分程式碼執行時間沒有一個深入的認識,這樣我們就有個問題,如果對程式碼進行優化,那麼優化哪一部分呢?是將執行緒數調節呢,還是改用共用記憶體?這個問題最好的解決方案就是利用Visual Profiler。下面 下麪內容摘自《CUDA_Profiler_Users_Guide》
「Visual Profiler是一個圖形化的剖析工具,可以顯示你的應用程式中CPU和GPU的活動情況,利用分析引擎幫助你尋找優化的機會。」
其實除了視覺化的介面,NVIDIA提供了命令列方式的剖析命令:nvprof。對於初學者,使用圖形化的方式比較容易上手,所以本節使用Visual Profiler。
開啓Visual Profiler,可以從CUDA Toolkit安裝選單處找到。主介面如下:
我們點選File->New Session,彈出新建對談對話方塊,如下圖所示:
其中File一欄填入我們需要進行剖析的應用程式exe檔案,後面可以都不填(如果需要命令列參數,可以在第三行填入),直接Next,見下圖:
第一行爲應用程式執行超時時間設定,可不填;後面三個單選框都勾上,這樣我們分別使能了剖析,使能了併發核函數剖析,然後執行分析器。
點Finish,開始執行我們的應用程式並進行剖析、分析效能。
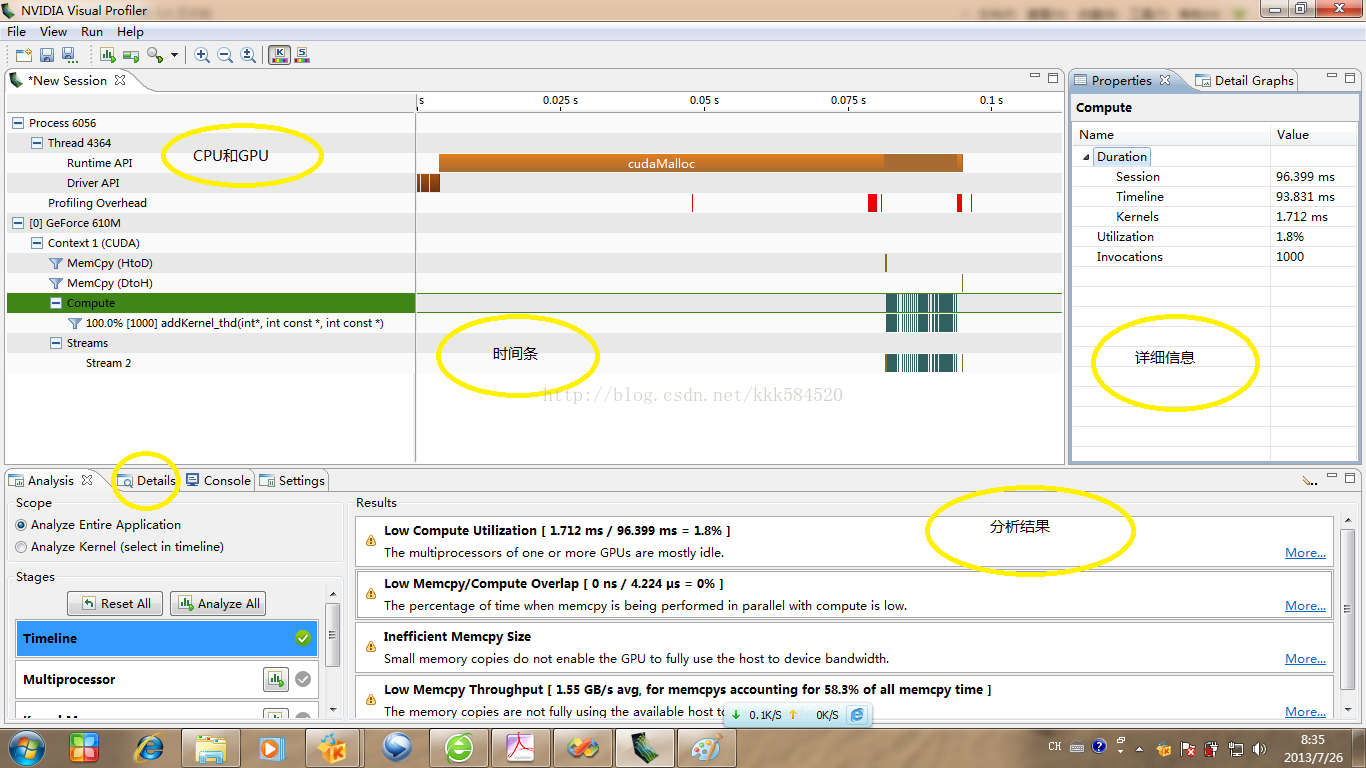
上圖中,CPU和GPU部分顯示了硬體和執行內容資訊,點某一項則將時間條對應的部分高亮,便於觀察,同時右邊詳細資訊會顯示執行時間資訊。從時間條上看出,cudaMalloc佔用了很大一部分時間。下面 下麪分析器給出了一些效能提升的關鍵點,包括:低計算利用率(計算時間只佔總時間的1.8%,也難怪,加法計算複雜度本來就很低呀!);低記憶體拷貝/計算交疊率(一點都沒有交疊,完全是拷貝——計算——拷貝);低儲存拷貝尺寸(輸入數據量太小了,相當於你淘寶買了個日記本,運費比實物價格還高!);低儲存拷貝吞吐率(只有1.55GB/s)。這些對我們進一步優化程式是非常有幫助的。
我們點一下Details,就在Analysis視窗旁邊。得到結果如下所示:
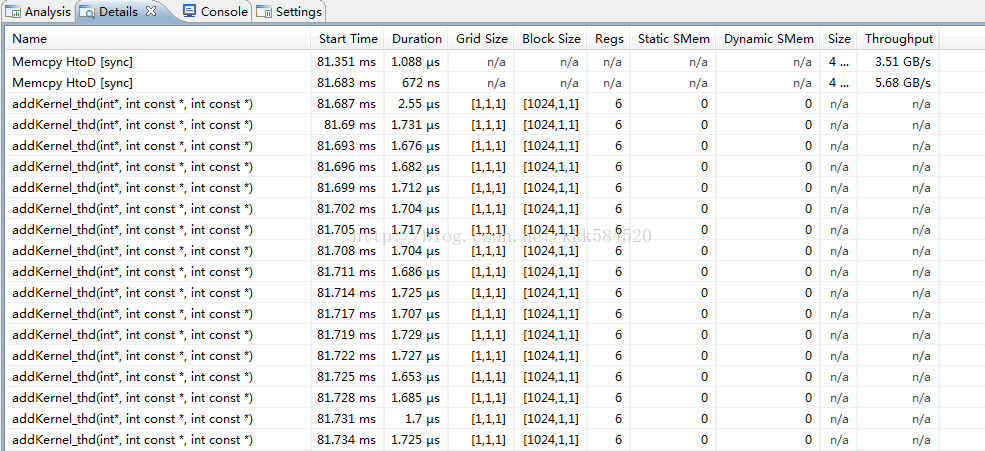
通過這個視窗可以看到每個核函數執行時間,以及執行緒格、執行緒塊尺寸,佔用暫存器個數,靜態共用記憶體、動態共用記憶體大小等參數,以及記憶體拷貝函數的執行情況。這個提供了比前面cudaEvent函數測時間更精確的方式,直接看到每一步的執行時間,精確到ns。
在Details後面還有一個Console,點一下看看。

這個其實就是命令列視窗,顯示執行輸出。看到加入了Profiler資訊後,總執行時間變長了(原來執行緒並行版本的程式執行時間只需4ms左右)。這也是「測不準定理」決定的,如果我們希望測量更細微的時間,那麼總時間肯定是不準 不準的;如果我們希望測量總時間,那麼細微的時間就被忽略掉了。
後面Settings就是我們建立對談時的參數設定,不再詳述。
轉自:http://blog.csdn.net/augusdi/article/details/12833235