09-使用snappy對Sentinel-1 GRDH數據進行預處理
09-使用snappy對Sentinel-1數據進行預處理
前言
OK! 經過前面數篇有點冗長的部落格,介紹snappy的時機終於成熟透!接下來,是時候向各位展示一下snappy的一些「奇巧淫技」了!
08篇中使用SNAP的命令列工具gpt,結合流程圖檔案,快速對Sentinel-1和Sentinel-2數據進行預處理,後面的幾篇博文將使用snappy(SNAP的python介面包)實現相同的預處理。另外,需要說明的是snappy和gpt也有比較密切的關係,因此,先介紹了gpt工具的使用,以便輔助snappy的使用。
在我看來,snappy這個python介面是非常有用的,因爲它可以讀取Sentinel等衛星數據爲numpy包的ndarray類(n維陣列類),這樣,我們可以藉助python豐富、強大的開源包擴充套件SNAP不完善或欠缺的功能,比如結合最近幾年比較火的scikit-learn庫、深度學習框架tensorflow, keras, pytorch完成更高階的分類(土地利用分類等)或迴歸問題(定量遙感反演等)。
snappy包,目前看來還是資料還是比較少,另外,剛開始使用(不熟悉其模組和功能的話),可能會不太習慣,因爲其是通過jpy(一個將python和java程式碼連線起來的橋樑包)將python程式碼轉爲java程式碼傳到SNAP所帶的Java虛擬機器執行的,如果不注意就會將Java和python語法混亂,也是因爲這個原因,snappy的doc文件很難直接獲取(程式碼補全困難),需要檢視SNAP 的Java API doc文件。
但是,一般的比較常見的操作和功能在官方的部落格、論壇等是能找到其相關的參考程式碼的。儘管snappy還有一些缺陷,但考慮到其可以比較便捷地完成Sentinel等系列衛星的預處理,和結合豐富的python開源包,意味着我們可以更快更好做更多的事情,還是很值得研究一下的。
準備工作
請參照01篇部落格利用SNAP在本地電腦設定好snappy。如果你想利用snappy來開發利用或擴充套件SNAP的功能,務必安裝好snappy,否則,後面程式碼無法執行。博主這是使用的是win64 python3.6 設定的,這個目前可以絕大數開源的python包適配,比如適配深度學習框架tensorflow, pytorch等。
儘管可以編寫、執行、偵錯python程式碼的IDE工具很多,但目前看來Pycharm的python程式碼補全功能最爲強大,使用起來比較方便,建議有條件的同學可以試下,儘管pycharm也有點缺點,比如啓動很慢等。(博主使用的是正版的Pycharm專業版,因爲可以使用Jupyter notebook,可以互動式寫程式碼。如果你有教育郵箱的話就可以免費啓用使用Pycharm專業版IDE)。
源數據
數據源爲覆蓋上海市全境的6景Sentinel-1 GRDH 數據:
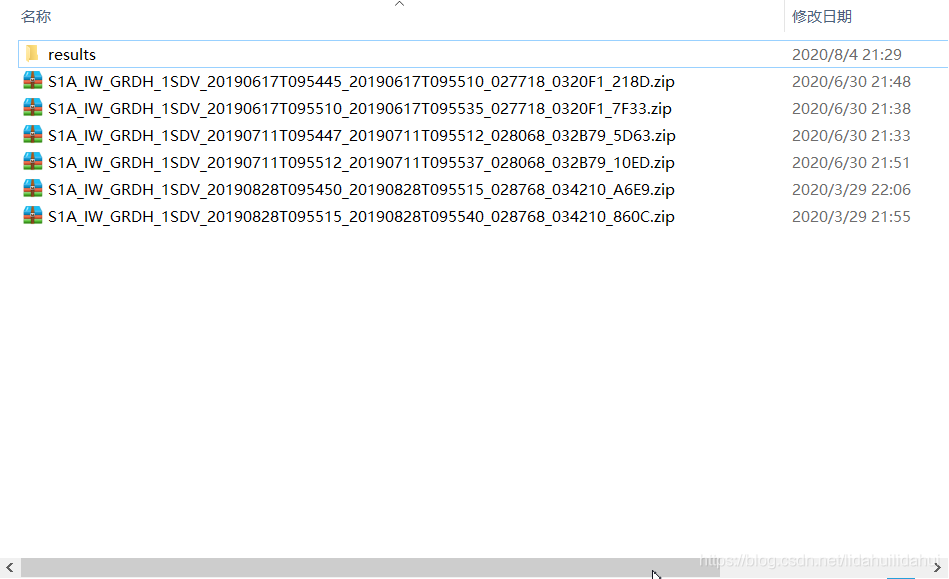
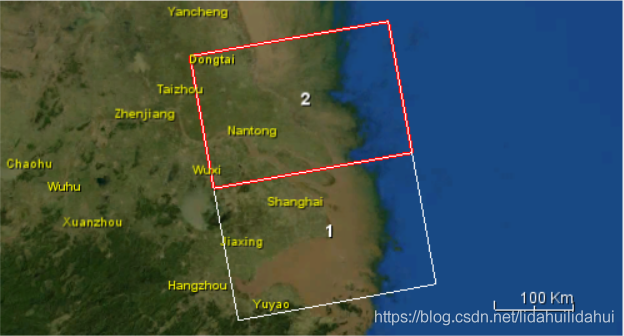
同一天的兩景影像鑲嵌剛好覆蓋整個上海市範圍(這裏共有3景):
本篇部落格涉及到的程式碼見百度雲盤鏈接:
鏈接:https://pan.baidu.com/s/1DgH5S3i4CogzH0YqC3cVyQ
提取碼:e2dj
snappy包重要類和其屬性、方法
snappy包包括衆多的Java類以及其屬性、方法(這些來自SNAP的Java原始碼),在我看來snappy包中比較重要的是數據的輸入和輸出(和numpy的互動),還有就是通用的GPF(Graph Processing Framework,流程處理框架)操作符(預處理和呼叫SNAP的封裝的功能函數),這裏暫時只介紹這些。
如果你比較熟悉Java程式碼,可以直接利用Java程式碼呼叫或擴充套件SNAP的功能想利用,可以參考SNAP官方的SNAP wiki部落格SNAP development部分,奈何博主Java比較菜,Python相對熟悉一些,因此,博主目前只能介紹一些比較常見的snappy操作,以下內容主要參考SNAP官方的snappy 使用wiki部落格。注意,某一些內容還需要修改,比如路徑,下面 下麪的程式碼纔可以執行。
SNAP的Java原始碼使用到了Java版的GDAL庫,比較多的類和函數設計和GDAL庫有點類似,有的GDAL庫基礎的同學理解起來會容易一些。Java中基本上許多東西都是設計成類的,
因此,從snappy中往往匯入的是類,然後再匯入其屬性或方法。此外,雖然snappy封裝了較多的類,但是,還有一些Java類只能通過jpy包(Python-Java橋樑包)的gettype()函數才能 纔能建立(即jpy.gettype(), 該函數需要傳入一個Java類名字串, 見後文方式1 使用SNAP自帶的操作符處理)。
以下的內容如果有物件導向的程式設計知識,可能會容易理解很多。
數據的讀和寫操作
from snappy import ProductIO
# 讀入產品數據集,MER_FRS_L1B_SUBSET.dim爲(snappy自帶的測試數據集,在snappy的安裝路徑下)數據集的路徑,
# 這裏是相對路徑,你可能需要修改爲你的絕對路徑或相對路徑
# 返回值p是一個snappy.Product類物件
p = ProductIO.readProduct(r'E:\Anaconda\Anaconda3\envs\py36\Lib\site-packages\snappy\testdata\MER_FRS_L1B_SUBSET.dim')
# 寫入數據,需要傳入一個snappy.Product物件,'<your/out/directory>'爲你的輸出檔名路徑
# '<write format>'爲儲存的數據格式,可以是SNAP的標準數據格式'BEAM-DIMAP'(預設值),
# 或者常見的'GeoTiff'格式等,如果有寫入的格式參數的話,儲存的檔名可以沒有不帶後綴.dim、.tif等
# ProductIO.writeProduct(p, '<your/out/directory>', '<write format>') # 寫入產品數據集
# snappy的測試數據大小很小,我直接儲存在當前路徑下了, 儲存爲test_write1.tif
ProductIO.writeProduct(p, 'test_write1', 'GeoTiff') # 寫入產品數據集
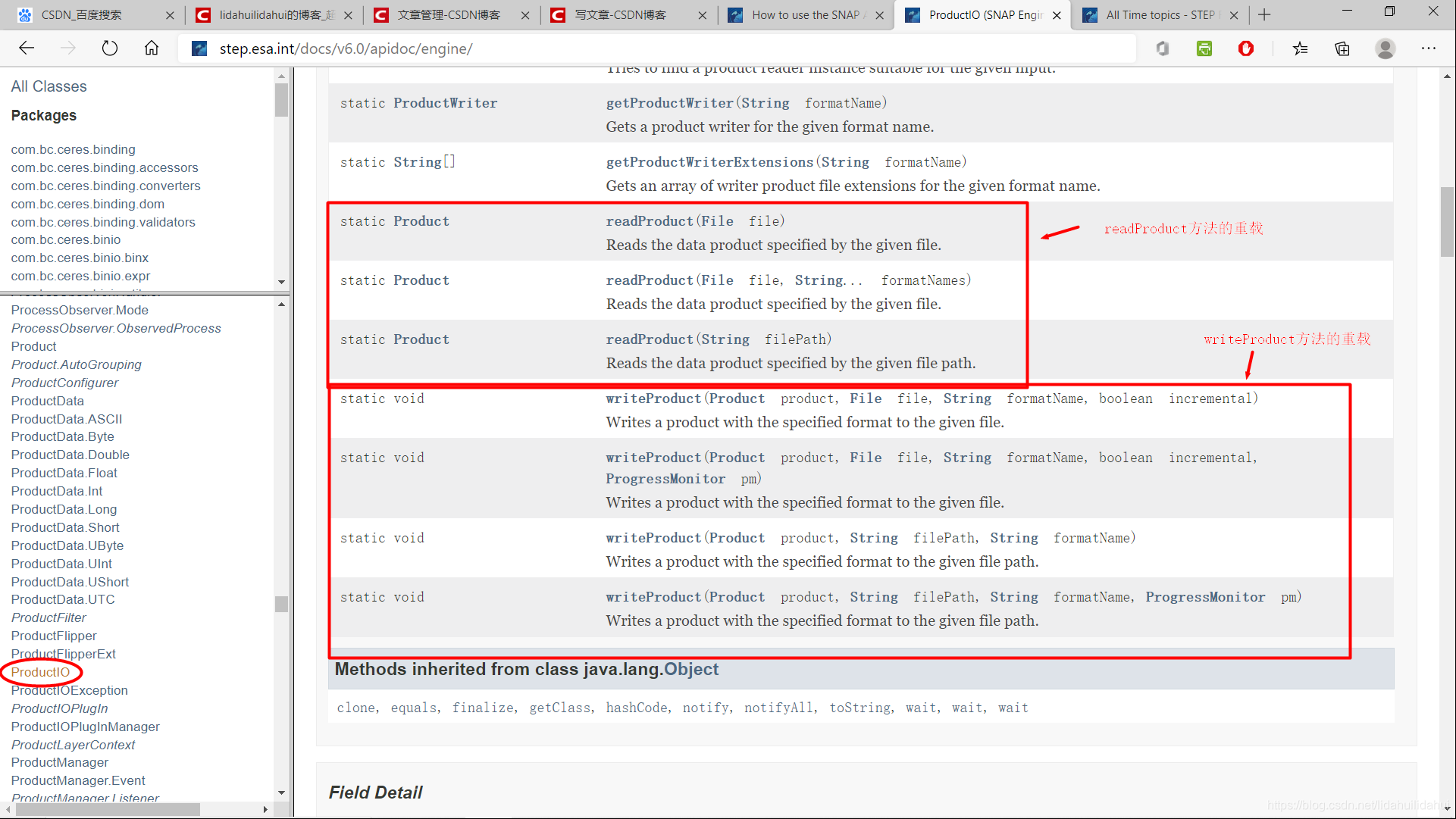
上述程式碼通過snappy的ProductIO類(Product類的輸入和輸出模組類)的readProduct和writeProduct方法。
- readProduct方法 :從磁碟讀入一個產品數據,該函數輸入的參數要讀取的數據集路徑(可以是絕對路徑或相對路徑)或者File物件,是返回的是一個snappy.Product類物件(產品類物件,可以理解爲一個數據集物件)。
可以參考後文的單個數據集預處理演示讀入操作部分的程式碼。
- writeProduct方法:向磁碟寫入一個產品數據,三個輸入參數分別是product類物件,儲存的檔名絕對路徑或相對路徑或者Java的File類物件,寫入格式的格式字串說明,實際上該函數還有其它的參數,如進度條參數,預設是Null,不顯示進度條。
可以參考後文所寫的單個數據集預處理演示寫入數據部分的程式碼。
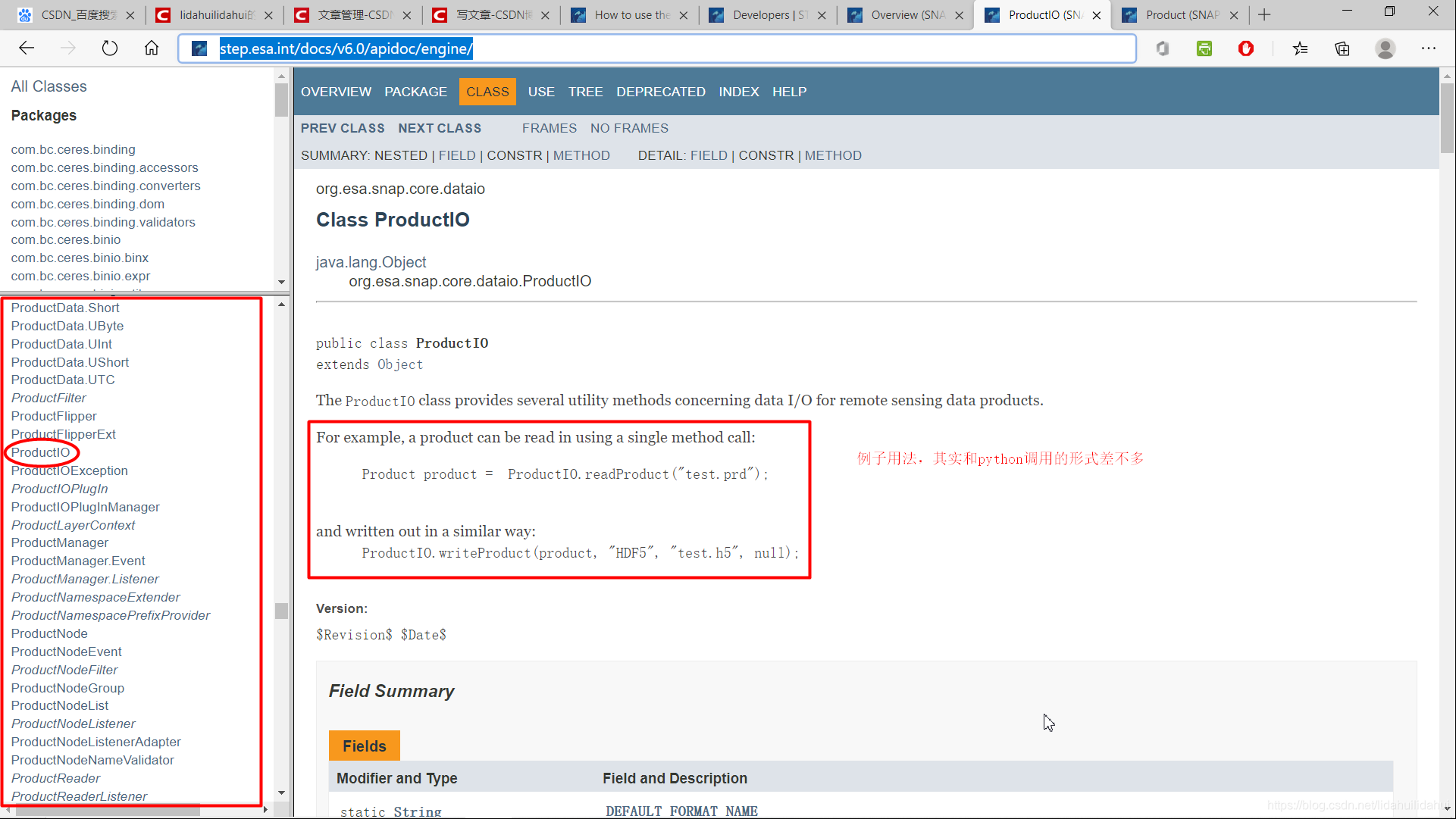
如果你要檢視snappy.ProductIO類的介面,你需要查閱SNAP本來的Java API, 主要有兩個,基本我們只需要查閱第一個 SNAP Engine API文件就可以,另一個文件主要是SNAP GUI 介面API文件。
SNAP Engine API Documentation
SNAP Desktop API Documentation
比如我要查閱ProductIO類的原始碼定義,只需要到SNAP Engine API Documentation網頁上查詢ProductIO類即可(左下方側框是SNAP Engine 定義所有類,預設是按字母升序排序的,不是很難查詢):
更詳細的readProduct和writeProduct方法的參數介紹:
Product類的屬性和方法使用簡介
snappy.Product可能我們使用snappy時最常用的類,其封裝大量方法和函數,很難一一詳述,所有這些方法和屬性,可以通過SNAP Engine API文件找到, 以該類爲例,展示API文件的查閱使用,學會使用API文件,才能 纔能在更好地使用其原始碼,從而,創造出更方便和強大的用法。該開始看到一大堆的英文API文件可能會比較苦惱,但是如果靜下心來細看,其實是不難理解。
儘管有些類定義的屬性和方法衆多,但是在絕大數的情況下,我們可能用不到,往往是需要用到時才查閱該類的方法使用。當然,如果你能以開發者的角度理解該類的定義,他爲什麼這樣設計,怎樣才能 纔能使使用者更便捷是使用該API,你就能思考得更深入,理解得更透切。實際上,對於開源庫包而言,原始碼的可讀性比效率性更重要,因此,流行的開源包絕大數是比較容易學和利用的。SNAP的開發者團隊也是很看中這點。因此,就常規應用而言,我們不必爲某些龐大的類物件感到恐慌。例外的話,SNAP開發者團隊會在SNAP官方論壇解答疑問,如果不懂的話,可以到那裏去詢問一下。
SNAP Engine API文件查閱
Product類的定義:
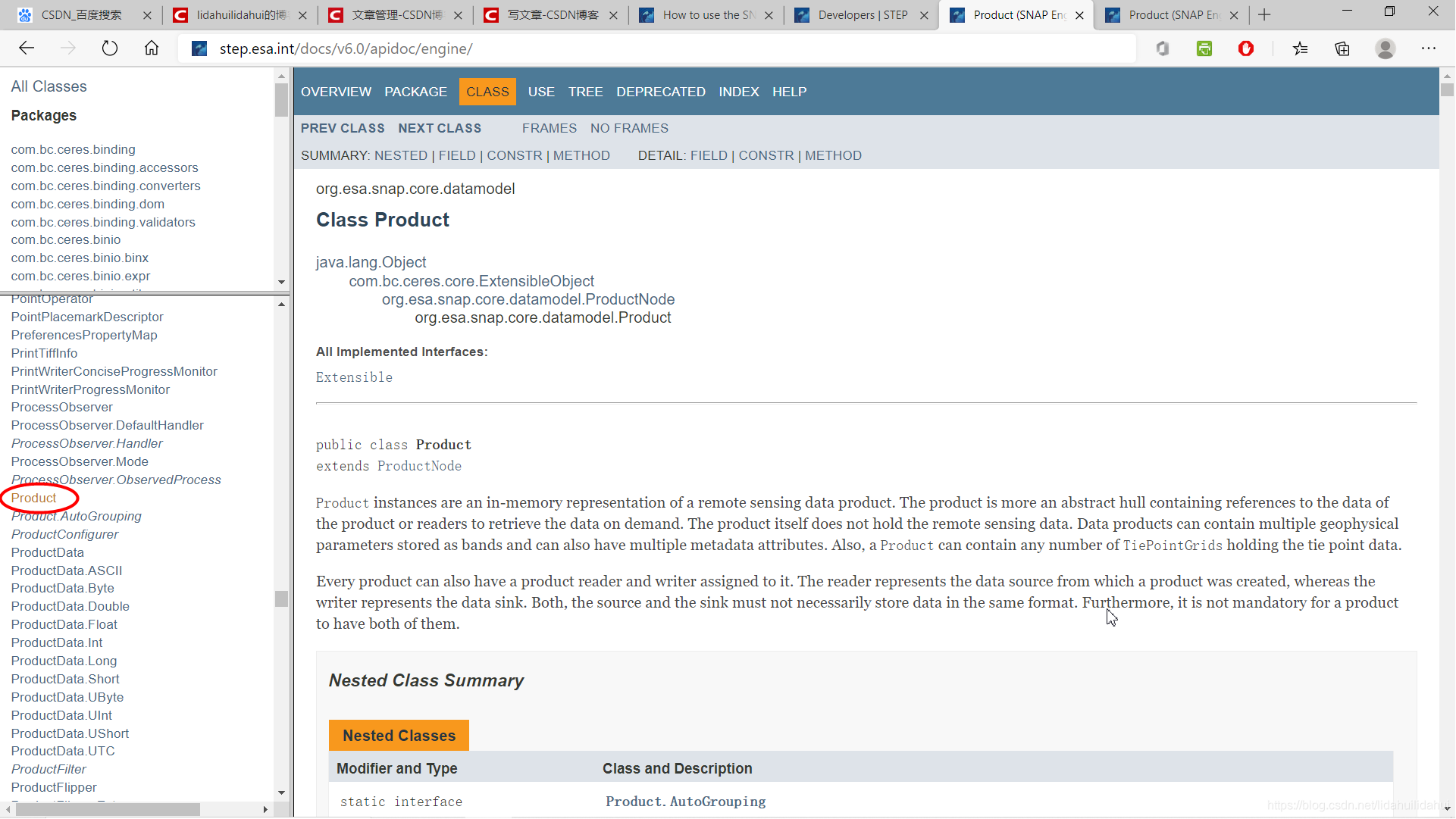
再往下是屬性總結:
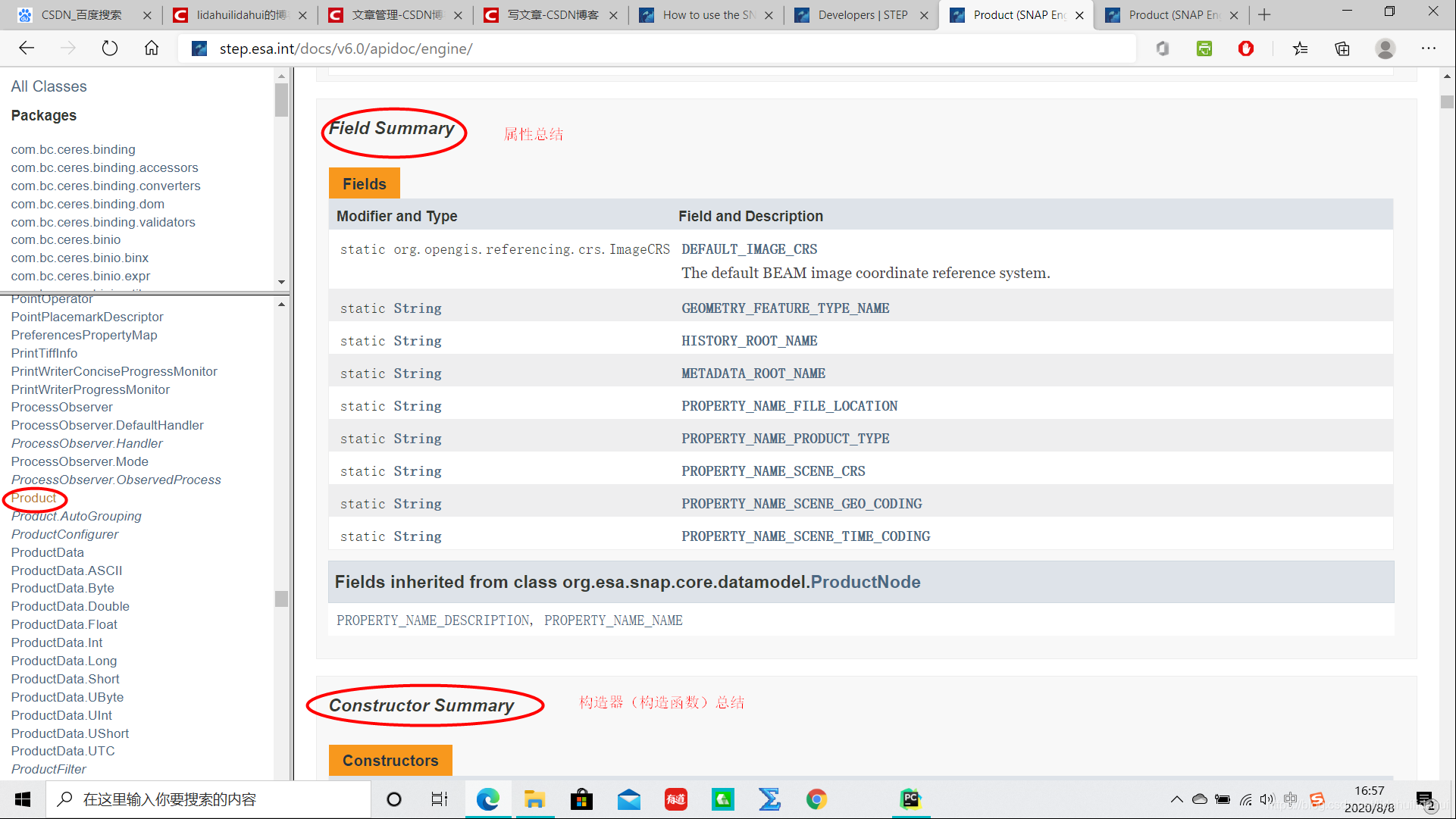
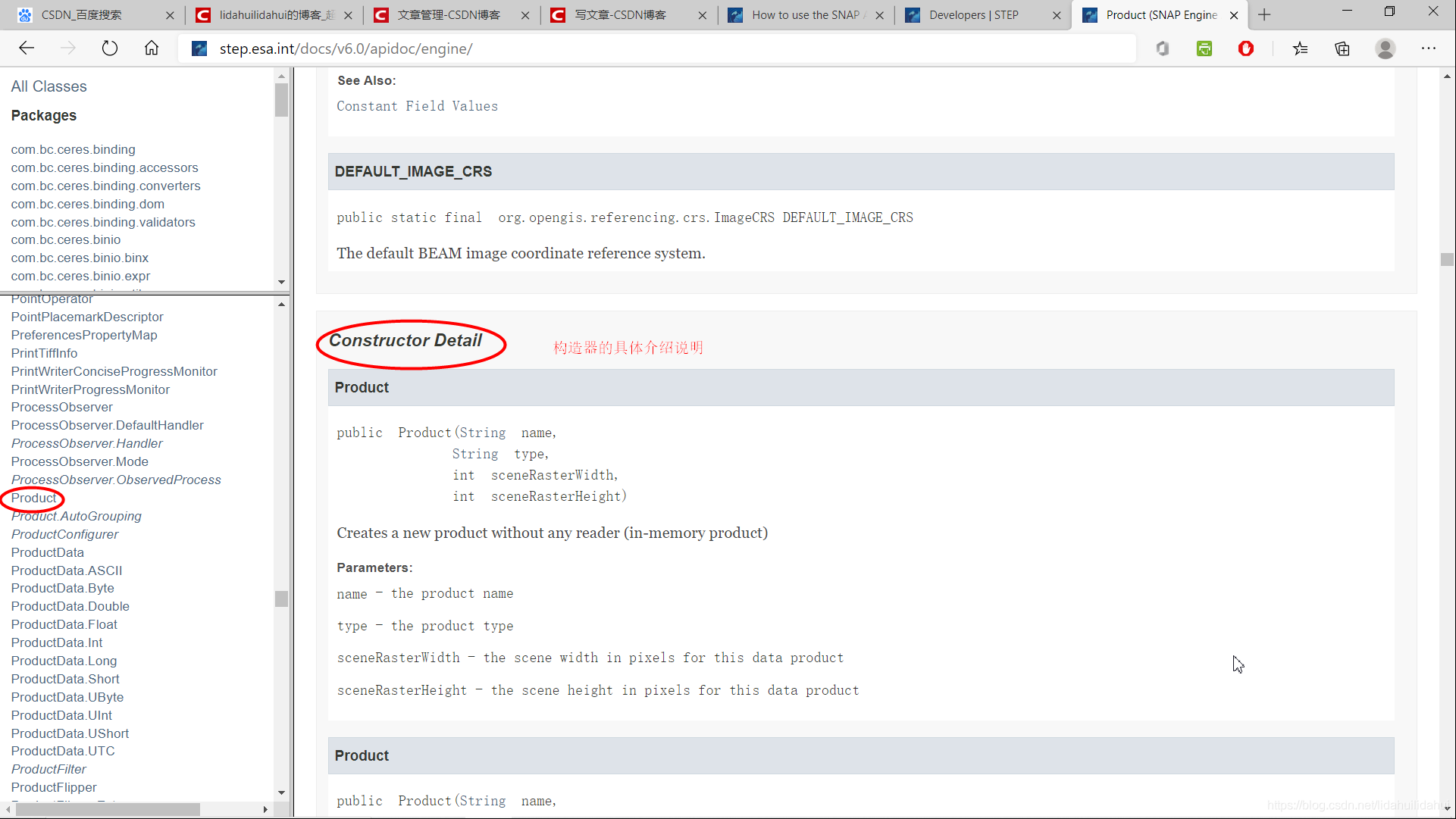
再往下爲該類建構函式和方法:
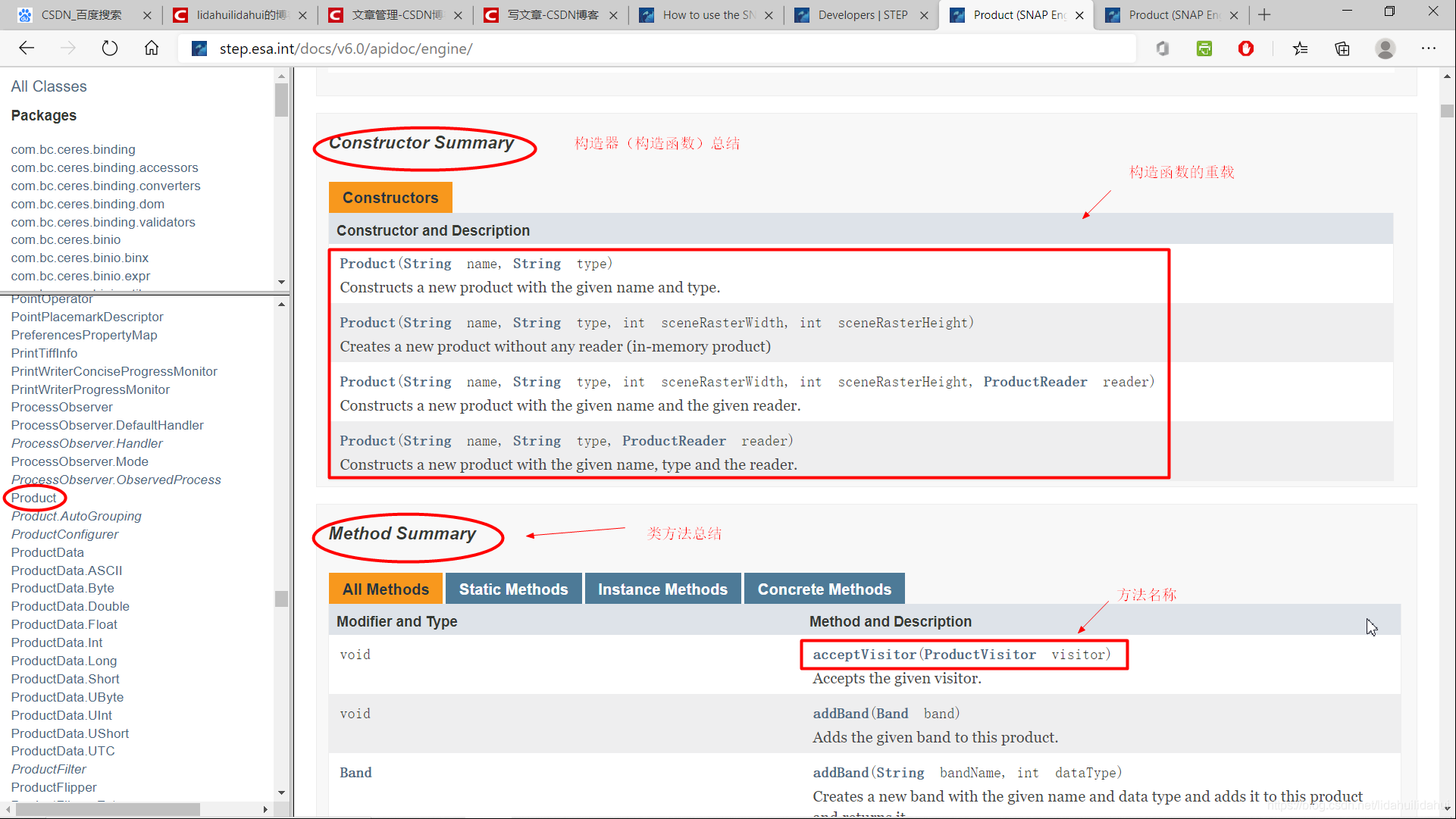
前面只是一些簡潔的總結,要往後翻才能 纔能看到跟詳細的參數說明:
父類別的繼承以及屬性參數介紹:
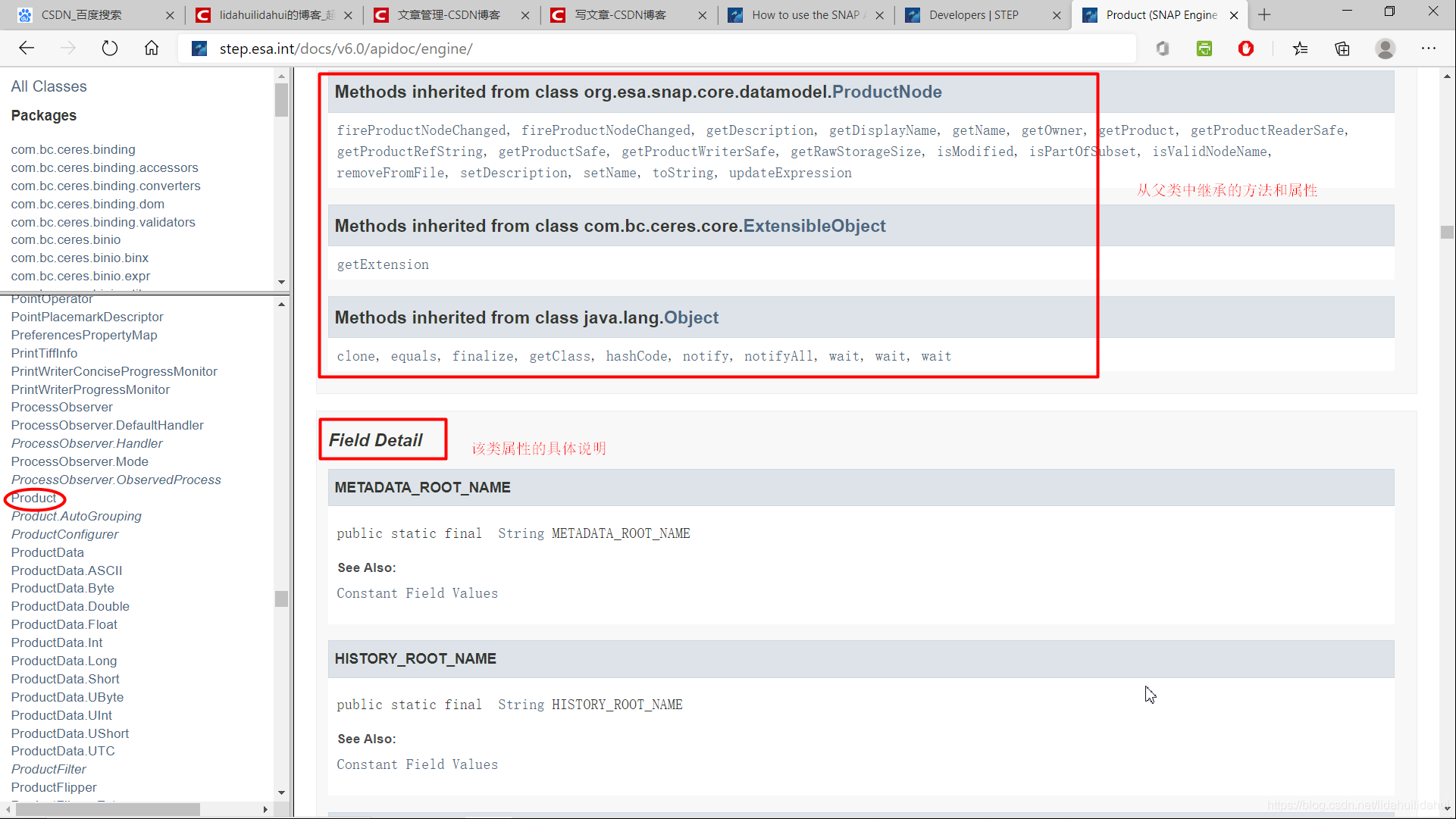
建構函式的參數介紹:
該類方法的功能和參數介紹: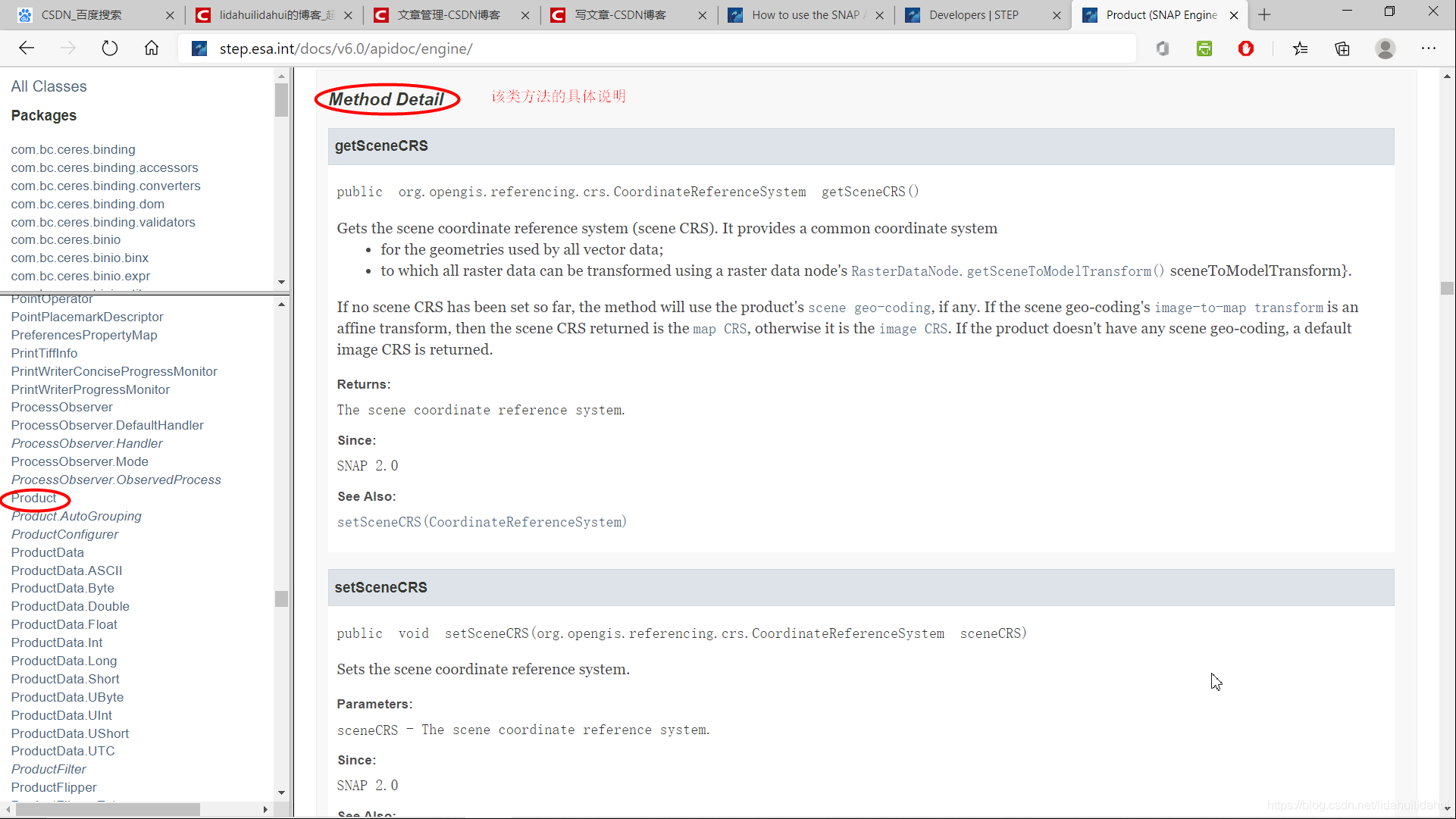
get和set方法
Product類(包括snappy的其它類)的方法,很大一部分方法都是以get和set開頭的方法,通常表示獲取某些屬性或物件、設定或修改某些屬性和物件。
# p是snappy.Product類物件
# getBand是該類的方法,通過傳入一個波段名(字串),獲取該波段物件(snappy.Band類)
rad13 = p.getBand('radiance_13')
# 通過snappy.Band類的setName方法設定該類物件rad13的波段名
rad13.setName('just_a_test')
下面 下麪這段程式碼暫時不可以執行,因爲target_product還沒有定義,這只是舉例,見後面。
# target_product是snappy.Product類物件
# 設定波段some_output_band_based_on_rad13的缺失值(NoDataValue)
# target是snappy.Band物件
target_band = target_product.getBand('some_output_band_based_on_rad13')
# 從rad13波段從獲取其缺失值,並賦予到target波段(some_output_band_based_on_rad13)
target_band.setNoDataValue(rad13.getNoDataValue())
通常snappy子類方法返回值是整數或字串物件(例如:這裏的p.getSceneRasterWidth()返回的是整數,p.getName()返回的是字串),這是python可以直接解釋和識別的。
# p是snappy.Product類物件
# 獲取該產品數據的名字,返回的name是字串
name = p.getName()
width = p.getSceneRasterWidth()
band_names = p.getBandNames()
但是有時一些snappy子類的函數返回是一個Java物件,這通常python不能識別(例如上面p.getBandNames()返回的就是一個java物件,python不能直接識該物件)
p.getBandNames()
#>>>[Ljava.lang.String;(objectRef=0x00000000391DEAE8)
這時可以使用python大的list函數將其轉化list物件,其
bands = list(p.getBandNames())
bands
#>>> ['radiance_1', 'radiance_2', 'radiance_3', 'radiance_4', 'radiance_5', 'radiance_6', 'radiance_7',
#'radiance_8', 'radiance_9', 'radiance_10', 'radiance_11', 'radiance_12', 'just_a_test', 'radiance_14', 'radiance_15', 'l1_flags', 'detector_index']
type(bands)
#>>> <class 'list'>
如果類屬性方法返回的是Java字串(Java String),如p.getAutoGrouping()方法的返回值
p.getAutoGrouping()
#>>> org.esa.snap.core.datamodel.Product$AutoGrouping(objectRef=0x00000000391DEAC8)
這時,可以通過python的str()函數將其轉換爲python的字串類物件。
autogrouping = str(p.getAutoGrouping())
autogrouping
#>>> 'Oa*_reflectance:Oa*_reflectance_err:A865:ADG:CHL:IWV:KD490:PAR:T865:TSM:atmospheric_temperature_profile:lambda0:FWHM:solar_flux'
type(autogrouping)
#>>> <class 'str'>
snappy處理數據
方式1 使用SNAP自帶的操作符處理
如果可以直接使用SNAP Engine Operators(SNAP GUI介面中的操作)實現的操作,通過snappy.GPF類的 createProduct()方法可以呼叫該操作。這和使用SNAP的命令列gpt工具呼叫的操作是一樣的。後面主要使用該種處理方式對Sentinel-1數據進行預處理。
GPF.createProduct()方法:
- 第一個的參數是gpt工具對應的操作符字串(流程圖檔案.xml檔案<operator>節點的字串);
- 第二個參數是一個Java的HashMap物件(相當於Python的字典物件),通過該HashMap物件傳入gpt工具對應的操作符的參數名及其值(流程圖檔案中也可以看到該參數鍵值對,SNAP GUI 介面也可以看到操作符對應的參數);
- 第三個參數是要處理的Product類物件。
- 其返回值也是一個Product類物件。
注意,向一個操作符傳入一個空的HashMap類物件,使用的是該操作符的預設參數值。這意味着,當你也可以通過HashMap類物件只修改部分的參數,其它不修改部分將使用預設參數。此外, 使用預設參數值要必須傳入一個空的HashMap類物件,而不可以將其省略。
查閱操作符
或許你想知道,SNAP中有哪些可以直接條用的操作符,SNAP GUI介面的選單欄選項,或許可以給予你提示,但是可以藉助SNAP的命令列工具gpt查詢更全面,可以開啓命令列視窗,輸入gpt -h
gpt -h
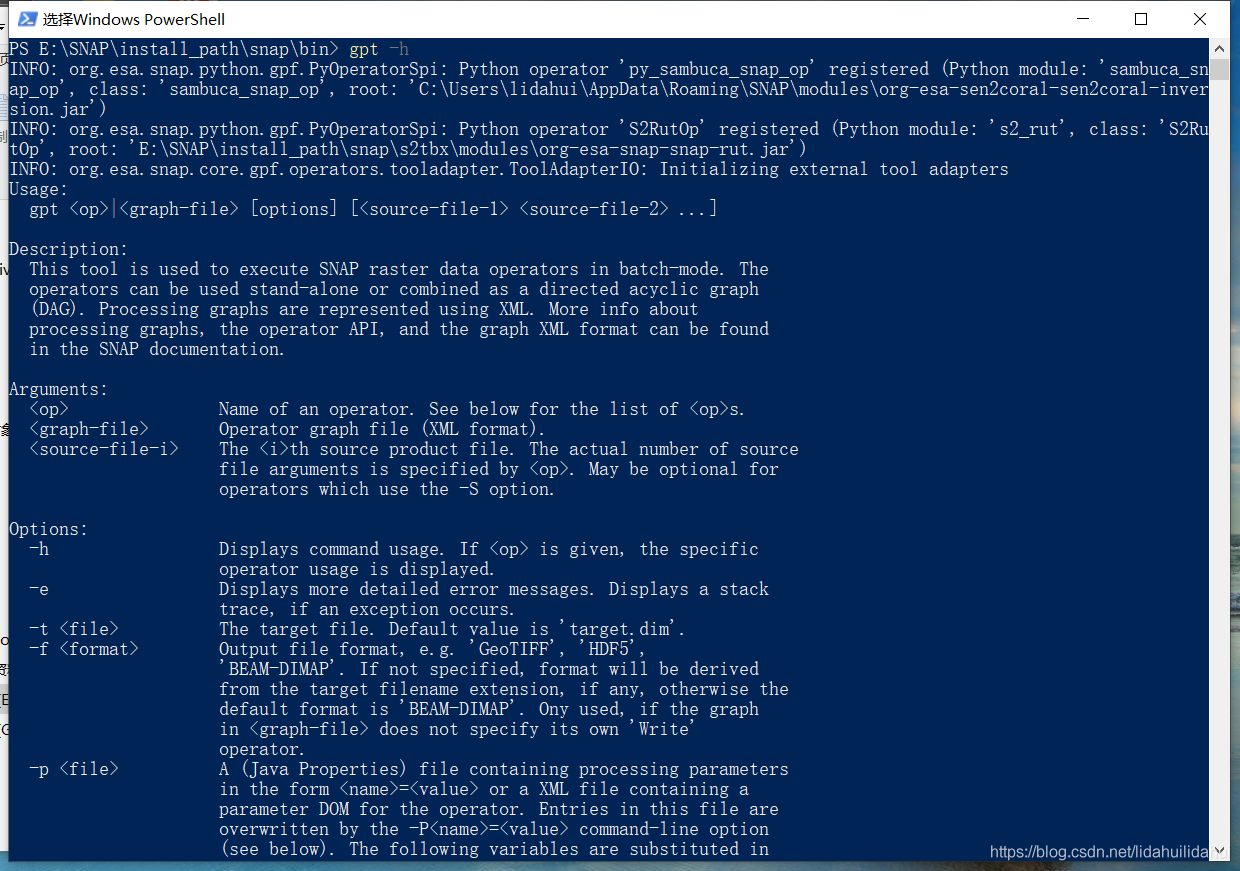
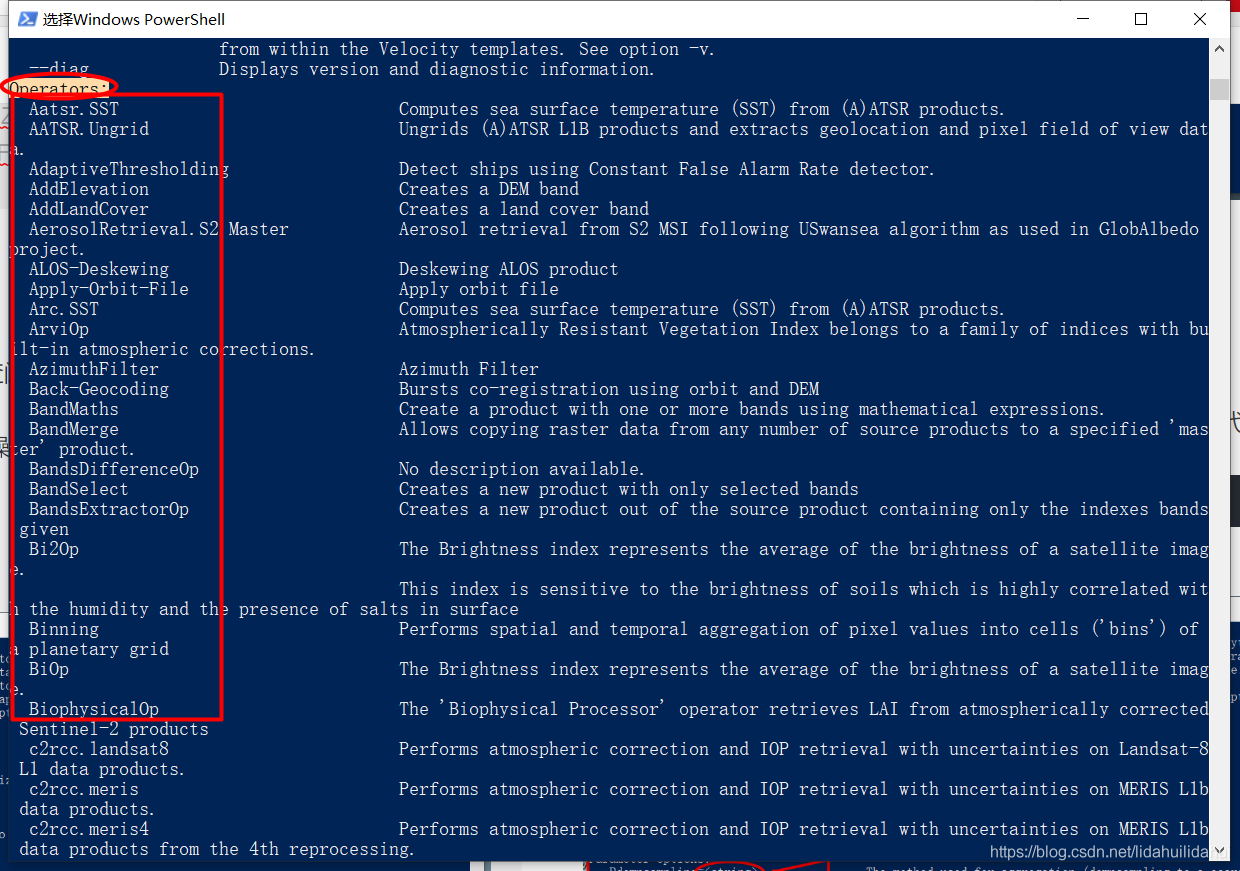
往下拉,可以找到‘Operators’字眼:
然後,你就可以看到很多的操作符名字以及其功能描述:
查閱操作符參數
以從重採樣操作(‘Resample’)爲例,查閱該操作其相關的參數:
- 1.使用SNAP的命令列工具gpt查詢:
開啓命令列視窗,對於查詢Resample操作而言,輸入以下程式碼即可:
gpt Resample -h
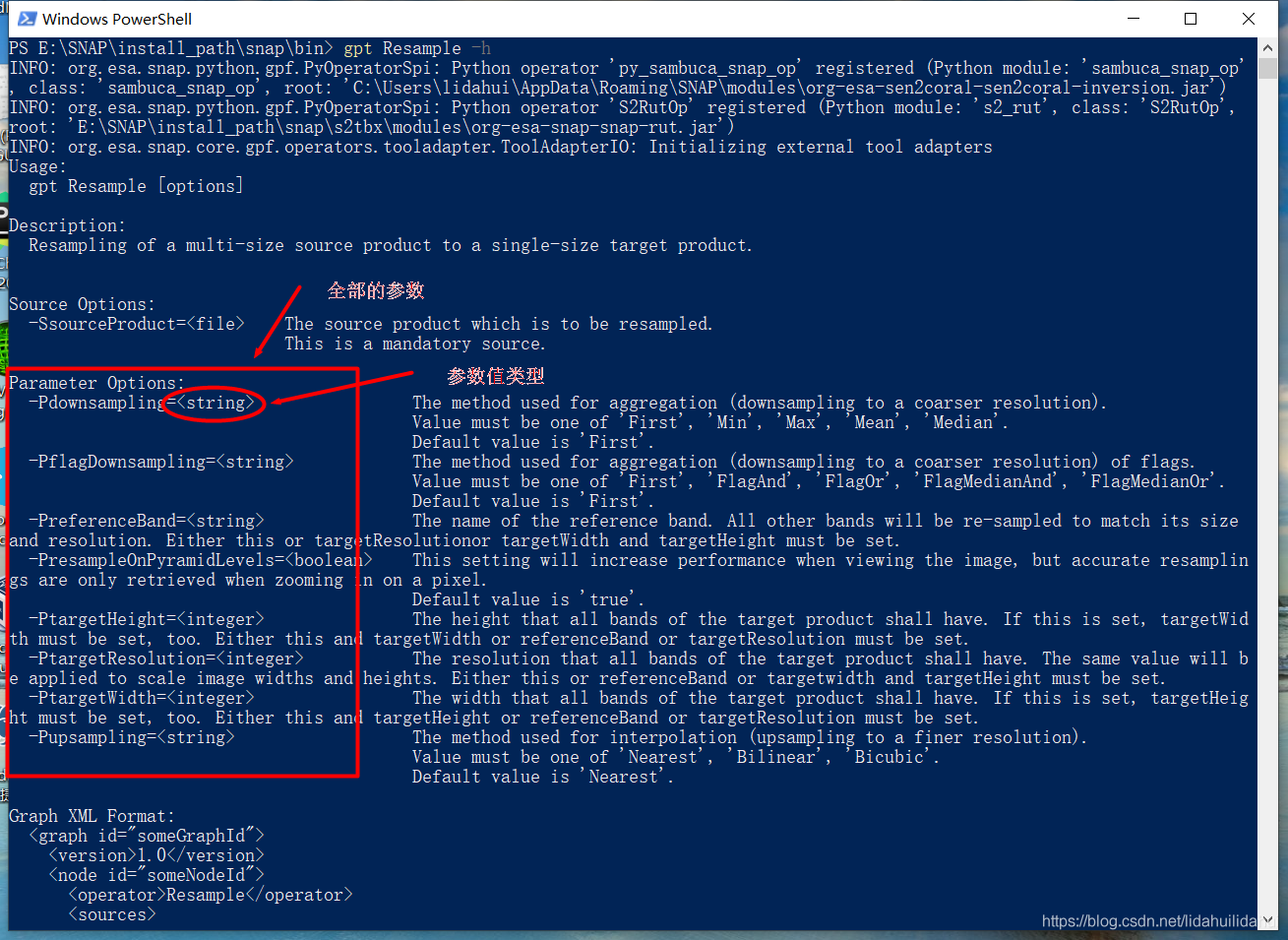
這個查詢結果比較好,因爲其指出其參數值的類,注意,向HashMap傳入實際的參數名沒有前面-P(-PXXXX是gpt工具的-P參數設定方法),比如,命令列中使用-Pdownsampling參數,向HashMap物件傳入參數名是downsampling。
- 2.使用SNAP的GUI介面查詢
在SNAP的操作介面找到操作的選單按鈕,在開啓的該操作選單的GUI介面上,選擇
File–>Display Parameters: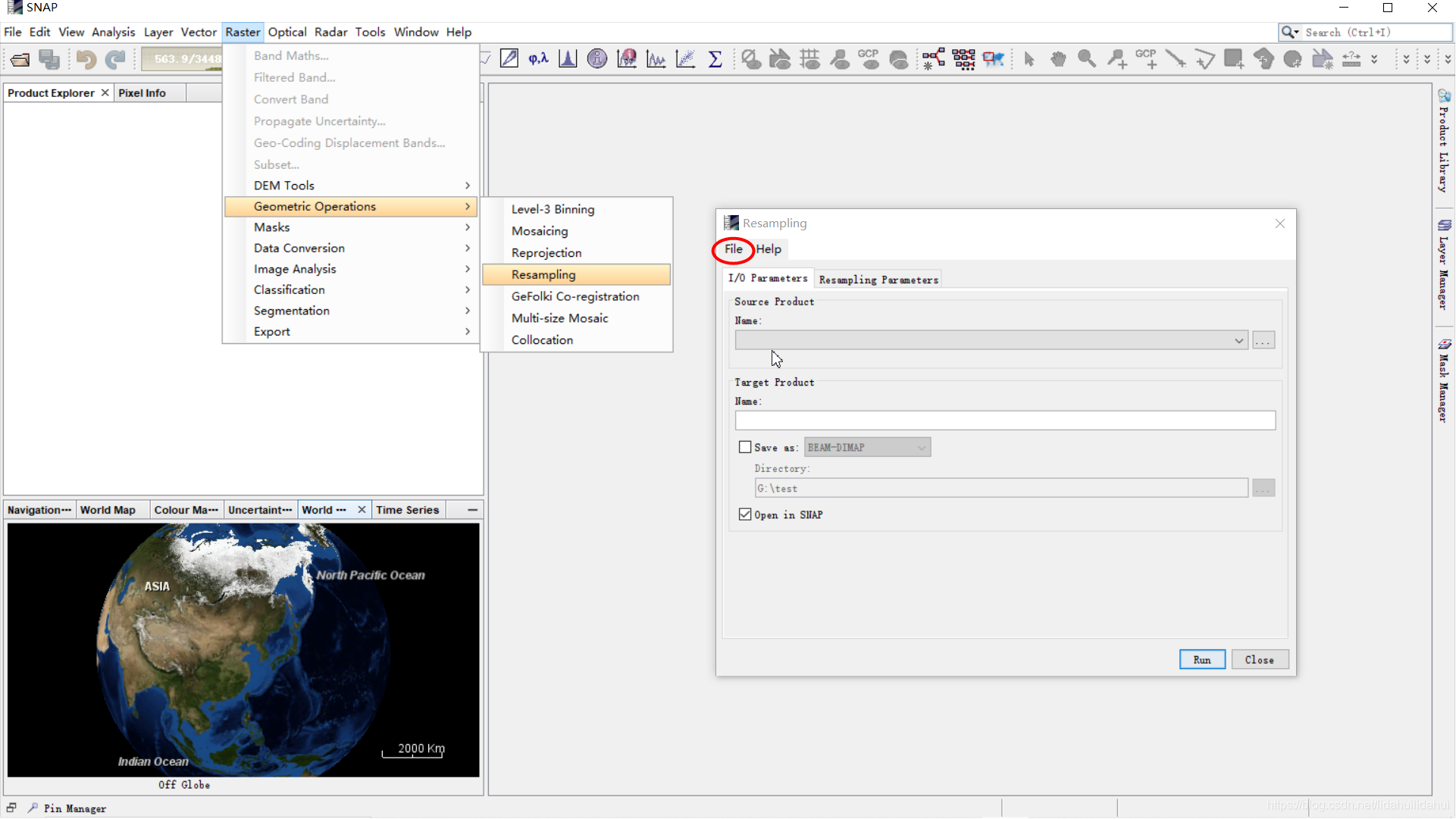
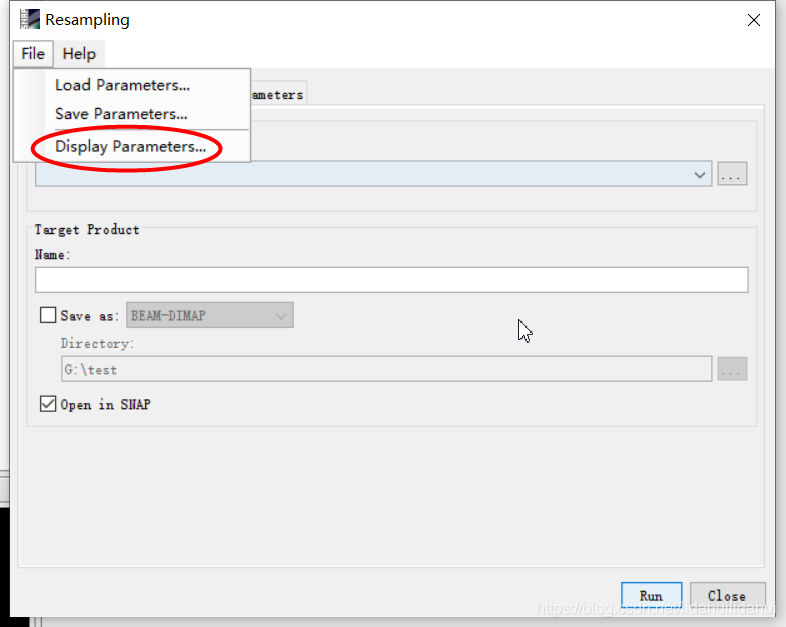
顯示的參數選項(這裏的參數顯示不是很全,因爲沒有新增數據集):
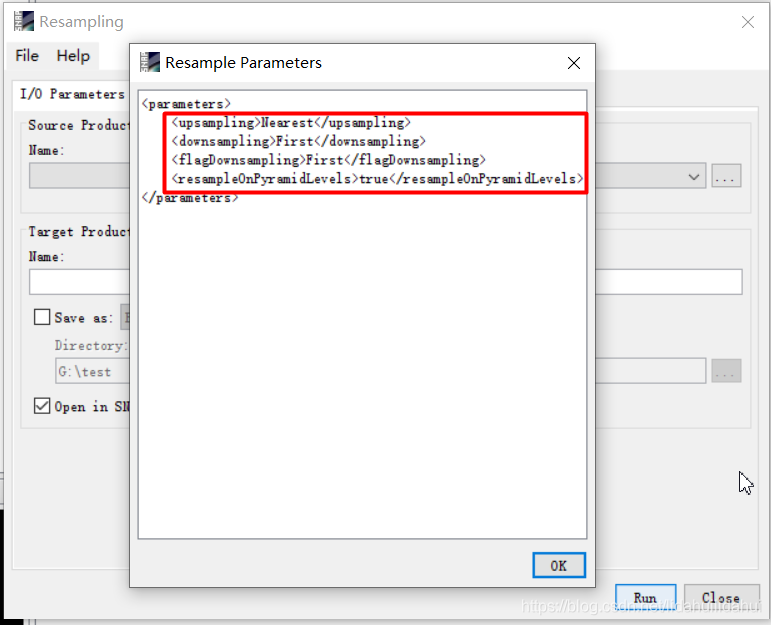
- 3.流程圖檔案.xml中也可以看到該操作操作名及其參數:
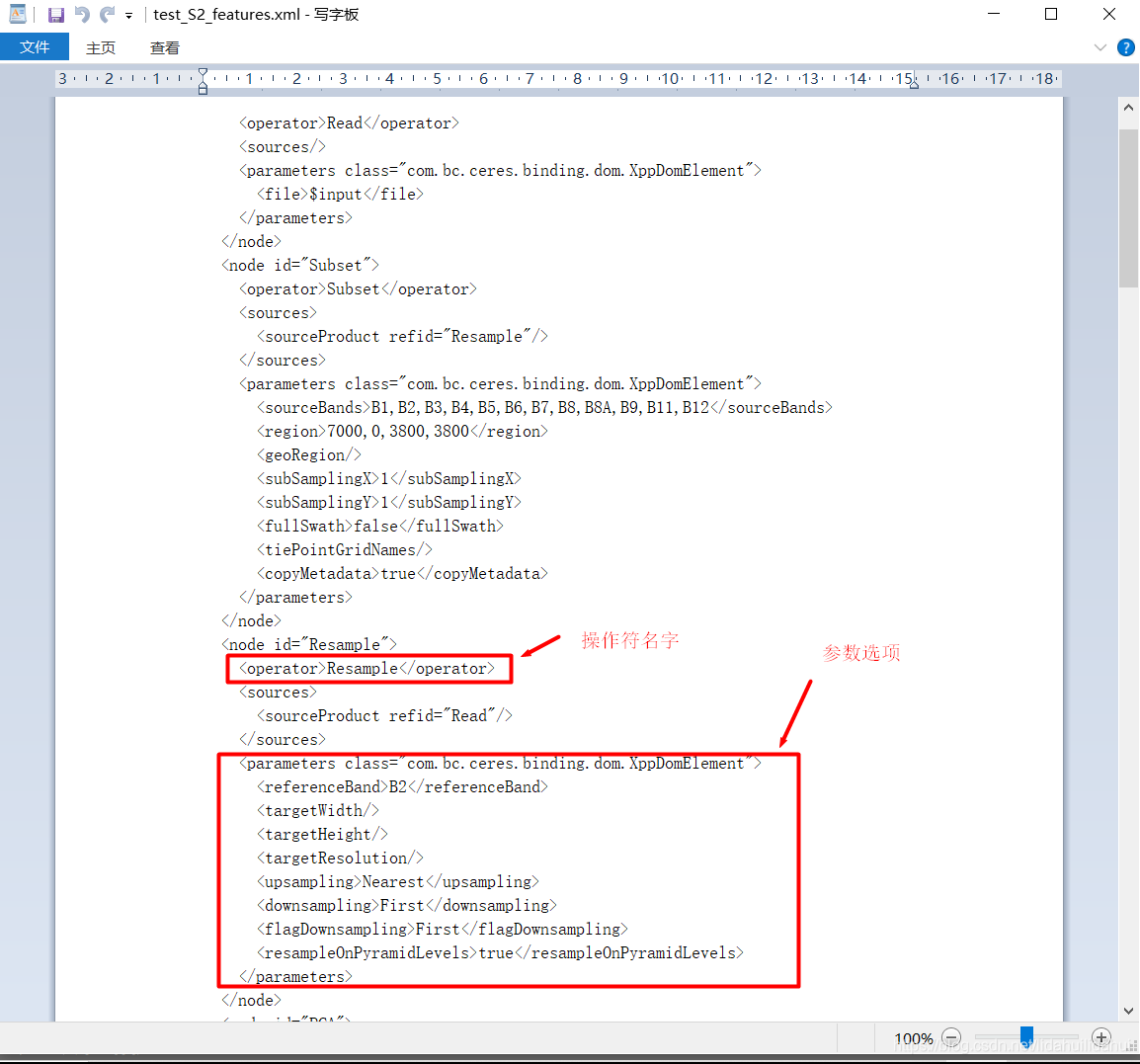
在我看來,第一種方式較好些,因爲可以看到輸入參數的型別,這樣,可以避免向HashMap物件傳入錯誤的參數值,儘管有一些麻煩。
#匯入相關類
from snappy import ProductIO
from snappy import GPF
from snappy import Hashmap
from snappy import ProgressMonitor
from snappy import jpy
# 向Hashmap物件,傳入參數鍵值對
parameters = Hashmap()
parameters.put('targetResolution', '10')
parameters.put('referenceBand', 'B4')
# 呼叫GPF(流程圖處理框架)定義的操作
operator_name = 'Resample'
target_product = GPF.createProduct(operator_name, parameters, p)
# 通過ProductIO類物件寫入數據
# 通過ProductIO類的writeProduct方法寫入
# 這是單執行緒的寫入方式,寫入大影像時速度會比較慢
write_format = 'BEAM-DIMAP' # 以BEAM-DIMAP格式寫入
# ProductIO.writeProduct(target_product , <'your/out/directory'>, write_format)
ProductIO.writeProduct(target_product ,'./test_write2', write_format)
# 另一種寫入方式,通過GPF操作符寫入,這種方式使用GPF操作符呼叫
# 預設使用多執行緒計算,因此效率很高,推薦使用這種方式,特別是在數據量大的時候
WriteOp = jpy.get_type('org.esa.snap.core.gpf.common.WriteOp')
# 以GeoTiff-BigTiff格式寫入,這是一種儲存大影像的.tif格式
writeOp = WriteOp(target_product, File('./test_write3.tif'), 'GeoTIFF-BigTIFF')
writeOp.writeProduct(ProgressMonitor.NULL)
# 上面writeOp部分程式碼和下面 下麪的方式是一樣的,
# 多數的格式寫入器不支援在寫入數據更新數據更新數據(除了預設的'BEAM-DIMAP'格式)
# 這時可以將incrementtal參數設定爲False
incremental = False
# GPF.writeproduct(target_product, File('your/out/directory'), write_format, incremental, pm)
GPF.writeProduct(target_product , File('./test_write4'), write_format, incremental, ProgressMonitor.NULL)
# 官方的教學多了這個程式碼,但似乎在Jupyter Notebook上不起作用
# 下述程式碼是在寫入時加入一個進度條顯示
def createProgressMonitor():
PWPM = jpy.get_type('com.bc.ceres.core.PrintWriterProgressMonitor')
JavaSystem = jpy.get_type('java.lang.System')
monitor = PWPM(JavaSystem.out)
return monitor
pm = createProgressMonitor()
GPF.writeProduct(target_product , File('./just_test2'), write_format, incremental, pm)
方式2 讀入numpy陣列處理
SNAP自帶的操作不能滿足你的計算需求時或者你打算實現自己的計算的情況下,Band類物件的readPixels()和writePixels()方法(這兩個方法繼承自AbstractBand類)可以獲取計算所需柵格值、儲存結果(和numpy陣列互動)。如果你想以SNAP中的定義的寫入器寫入數據,建議在計算開始之前在指令碼中完全設定好Product類target_product類的相關屬性。在下面 下麪的例子中,p仍然是前面所提到的Product類物件(是數據源)。
通過SNAP Engine API可以查到AbstractBand類的readPixels()和writePixels()方法,如下:
參數x, y柵格左上角畫素座標值(x, y,整型,其中x表示第幾列,y表示第幾行, 從0開始計算,而不是1);w爲讀入柵格範圍的寬度(列數,整型); h爲讀入柵格範圍的高度(行數, 整型); double[] , float[], int[] pixels爲要讀入或寫入的numpy一維float64, float32, int32陣列; pm是可選參數(ProgressMonitor類),用於讀入或寫入展示進度條;
有兩點需要需要強調, 再強調的,w,h分別指寬度和高度,而不是右下角的畫素座標值;傳入的numpy陣列必須是一維陣列,且元素總數和二維柵格包含的總像元數相同(相當將二維陣列展開爲一維陣列)。這兩點很容易出錯!
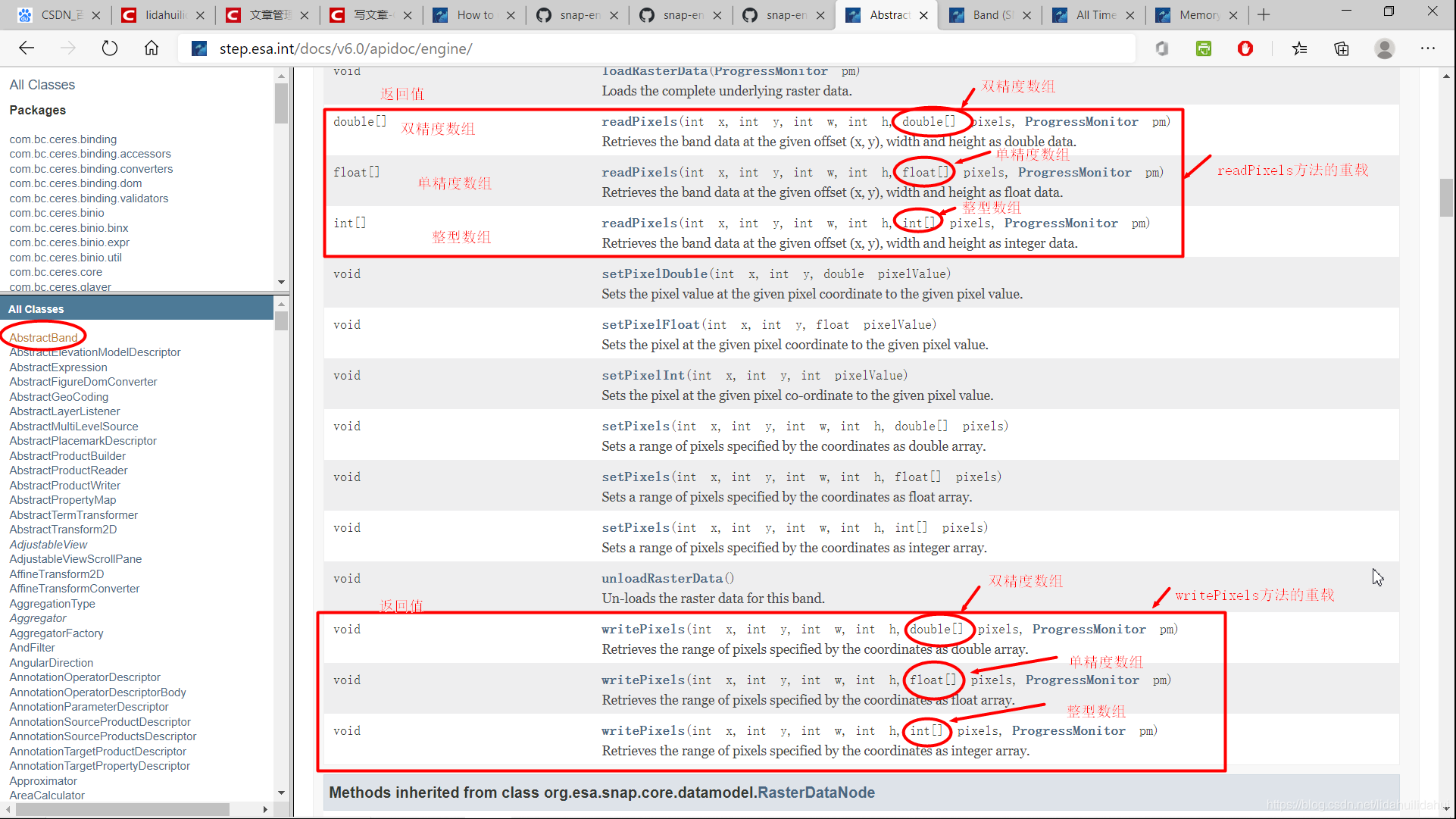
通過這兩個方法實現和numpy陣列的互動,從而可以和衆多的python第三方包互動,例如scipy,scikit-learn等,從而大大擴其功能。該函數用法見下文程式碼的第6,7部分。
# 1.匯入相關庫和類
import snappy
from snappy import ProductUtils
import numpy as np
p = ProductIO.readProduct(r'E:\Anaconda\Anaconda3\envs\py36\Lib\site-packages\snappy\testdata\MER_FRS_L1B_SUBSET.dim')
# 這裏的p的是前文的Product類物件
# 獲取該Product類物件的柵格集寬度大小
width = p.getSceneRasterWidth()
# 獲取該Product類物件的柵格集高度大小
height = p.getSceneRasterHeight()
# 建立一個空的Product類物件,'My target product'指其Product類物件名字
# 'The type of my target product'指該Product類物件的產品型別字串
# width 柵格數據集的寬度
# height 柵格數據集的高度
#target_product = snappy.Product('My target product', 'The type of my target product', width, height)
target_product = snappy.Product('target_product', 'temp_type', width, height)
# 2. 可選的操作:從Product類物件複製元數據到target_product
ProductUtils.copyMetadata(p, target_product)
# 可選也可以設定target_product特定描述,如下
target_product.setDescription('Product containing very valuable output bands')
# 3.設定Product類的寫入器
# 使用write_format格式字串定義 (這裏如 'BEAM-DIMAP'):
target_product.setProductWriter(ProductIO.getProductWriter(write_format))
# 4.向新建的Product類物件新增Band類物件
# Now, you could copy bands form the source product if you are interested in writing them to the target product as well. Check out ProductUtils.copyBand() regarding this task.
# 在計算之前需要建立爲新建的Product類物件建立一個空的波段物件
# 新的波段名
band_name = 'new_band'
# 柵格值型別爲snappy.ProductData.TYPE_FLOAT32
target_band = target_product.addBand(band_name, snappy.ProductData.TYPE_FLOAT32)
# 對剛建立的band對進行更多的屬性設定
# 從Product類物件p的'source_band_name'波段獲取該波段的缺失值
nodata_value = p.getBand('radiance_13').getNoDataValue()
# 設定Band類物件target_band的缺失值以及波長值(nm)
target_band.setNoDataValue(nodata_value)
target_band.setNoDataValueUsed(True)
target_band.setSpectralWavelength(425.0)
# 你還可以對其它的波段屬性進行設定,有一些屬性的設定對得到你所期望的波段非常關鍵
# 5.寫入檔案頭
# 剛剛新增到target_product的所有結構和元資訊仍然在記憶體中。因此,我們必須在寫入數據之前先
# 寫入它的頭。writeHeader()的唯一參數是數據集的絕對路徑,不帶副檔名。此路徑的最後一個
# 字串是寫入時的目標產品名稱。
# 最後輸出的數據檔名爲test_write3.dim
target_product.writeHeader('test_write3')
# 6. 從源產品數據集中匯入波段source_band_name的數據
sourceband = p.getBand('source_band_name')
# 建立一個一維陣列,其大小和讀入柵格範圍的二維陣列展開後得到的
# 一維陣列大小一致,用於儲存數據
r1 = np.zeros(width * height, dtype=np.float32)
print('Reading...')
rad13.readPixels(0, 0, width, height, r1)
# 7. 向新建的波段寫入數據
print("Writing...")
target_band.writePixels(0, 0, width, height, r1)
target_product.closeIO()
print("Done.")
上述程式碼很有代表性,涉及到數據讀入和寫入,以及和numpy庫的互動,建議多看看幾遍,後面可能經常用到相似的程式碼片段。
Sentinel-1 GRDH數據預處理
利用SNAP對Sentinel-1 GRDH數據進行預處理的詳細步驟及解釋請看07篇部落格,利用SNAP的命令列對其進行預處理請看08篇部落格。
單個數據集預處理演示
預處理流程和之前部落格中展示的是一樣的,如下:
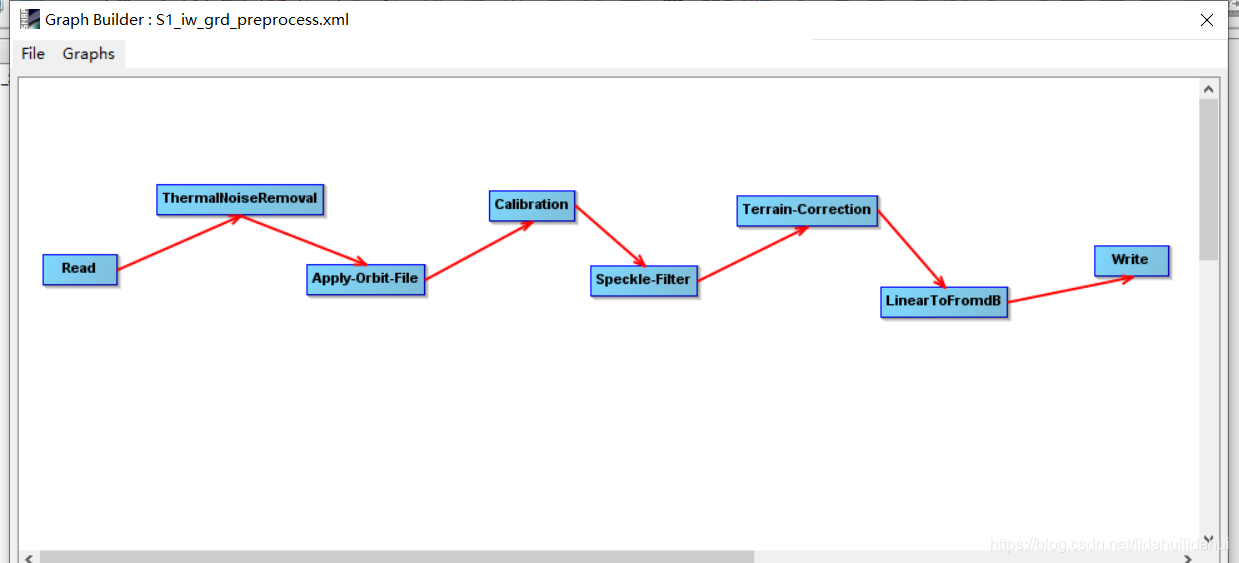
爲了避免程式碼過長,這裏將按預處理的步驟將其分隔開來。剛開始部分是一些輔助函數,比如檢視某個處理操作的參數、數據視覺化的函數。(博主是用jupyter notebook 寫的程式碼, 每個步驟是分開,但是,如果你想封裝爲函數以便批次處理,也是非常容易的)。注意,我不會講解太多python的基礎知識,下面 下麪的程式碼,除了snappy外,都是比較常見的python自帶包或第三方開源包,並且博主加了必要的註釋,應該是可以理解的。
一些輔助函數
以下是匯入的相關包和定義的輔助函數程式碼:
# -*- coding: utf-8 -*-
# Author: 超級禾欠水
# 匯入相關庫
import matplotlib.image as mpimg # 視覺化
import matplotlib.pyplot as plt # 視覺化
from zipfile import ZipFile # 壓縮檔案類
import os # 存取檔案
from glob import iglob # 存取檔案
import pandas as pd # 數據分析和操作常用庫
import numpy as np # 科學計算庫
import subprocess # 呼叫系統進程
import snappy # SNAP的python介面包
import math # 基本的數學函數包
# 修改pandas列的字元寬度,因爲Sentinel數據檔名很長
pd.options.display.max_colwidth = 80
# 視覺化函數
def output_view(product:snappy.Product, band_names:list,
stretch_percent:float=0.02)->None:
"""
:param product: snappy GPF product物件,輸入的Sentinel-1產品數據集類物件
:param band_names: 要視覺化的波段名
:param stretch_percent: 直方圖拉伸的百分比,預設爲2%(0.02)拉伸
:return: None
"""
band_count = len(band_names) # 波段數
band_data_list = [] # 儲存波段數據的列表
vmins = [] # 儲存波段數據拉伸的下邊界值列表
vmaxs = [] # 儲存波段數據拉伸的上邊界值列表
for band_name in band_names:
band = product.getBand(band_name)
w = band.getRasterWidth()
h = band.getRasterHeight()
band_data = np.zeros(w * h, np.float32)
band.readPixels(0, 0, w, h, band_data)
band_data = band_data.reshape((h, w))
band_data_list.append(band_data)
# 求取該波段數據拉伸的上下下邊界值列表
vmin, vmax = np.percentile(band_data, (100 * stretch_percent / 2, 100 - 100 * stretch_percent / 2 ))
vmins.append(vmin)
vmaxs.append(vmax)
rows = math.ceil(band_count / 3)
# 每行最多放3個圖
fig, axes = plt.subplots(rows, 3, figsize=(15, rows * 5))
for i, ax in enumerate(axes):
if i > band_count - 1:
ax.set_axis_off()
break
ax.imshow(band_data_list[i], cmap='gray', vmin=vmins[i], vmax=vmaxs[i])
ax.set_title(band_names[0])
# 檢視SNAP某個操作的函數
def print_operator_help(operator_name:str)->None:
"""
:param operator_name: SNAP中的操作名,可以通過命令列工具gpt -h
:return: None
"""
print(subprocess.Popen(['gpt', operator_name, '-h'], stdout=subprocess.PIPE,
universal_newlines=True).communicate()[0])
# 檢視影像快檢視,以瞭解其覆蓋範圍
def look_S1_zip_quick_look(S1_zip_file_name:str)->None:
"""
:param S1_zip_file_name: Sentinel數據壓縮檔名
:return: None
"""
with ZipFile(S1_zip_file_name, 'r') as qck_look:
qck_look_img = qck_look.open(name[0] + '.SAFE/preview/quick-look.png')
img = mpimg.imread(qck_look_img)
plt.figure(figsize=(15, 15))
plt.title('Quicklook visualition - ' + name[0] + '\n')
plt.axis('off')
plt.imshow(img)
讀入操作
# 讀取Sentinel-1數據
product_path = r"G:\test\S1_GRDH"
input_S1_files = sorted(list(iglob(os.path.join(product_path, '**', '*S1*.zip'), recursive=True)))
# 獲取其檔名,拍攝模式,產品等級型別,極化方式,影像高度,影像寬度,波段名
name, sensing_mode, product_type, polarization, height, width, band_names = ([] for _ in range(7))
for i in input_S1_files:
sensing_mode.append(i.split('_')[3])
product_type.append(i.split('_')[4])
polarization.append(i.split('_')[-6])
# Read with snappy
s1_read = snappy.ProductIO.readProduct(i)
name.append(s1_read.getName())
height.append(s1_read.getSceneRasterHeight())
width.append(s1_read.getSceneRasterWidth())
band_names.append(s1_read.getBandNames())
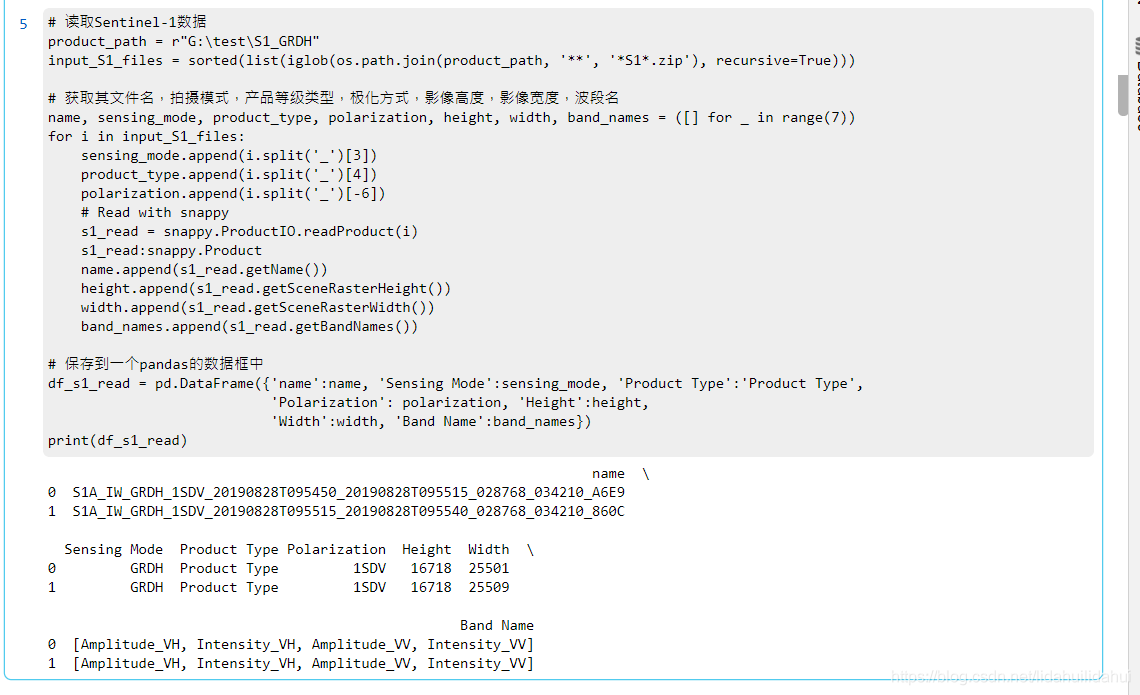
# 儲存到一個pandas的數據框中
df_s1_read = pd.DataFrame({'name':name, 'Sensing Mode':sensing_mode, 'Product Type':'Product Type',
'Polarization': polarization, 'Height':height,
'Width':width, 'Band Name':band_names})
print(df_s1_read)
結果:
檢視快檢視:
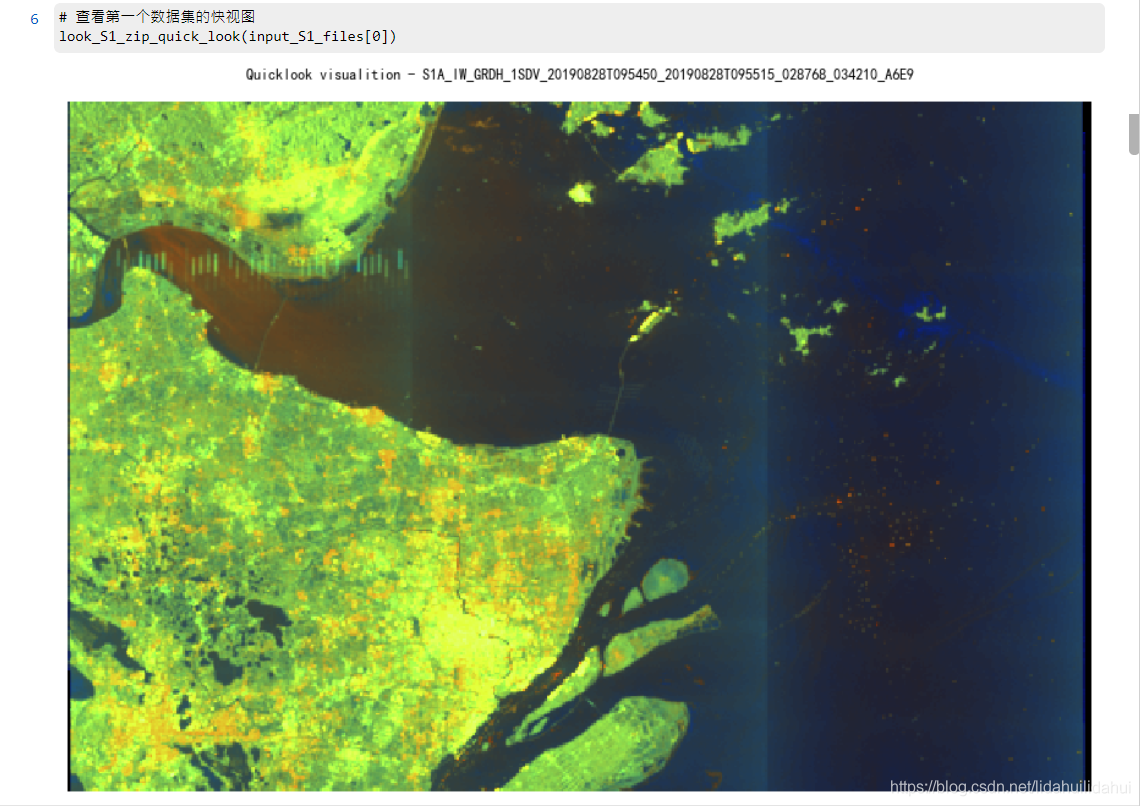
# 檢視第一個數據集的快檢視
look_S1_zip_quick_look(input_S1_files[0])
結果:
(與你手動開啓解壓後的壓縮檔案檢視到的快示圖應該是一樣的)
裁剪操作
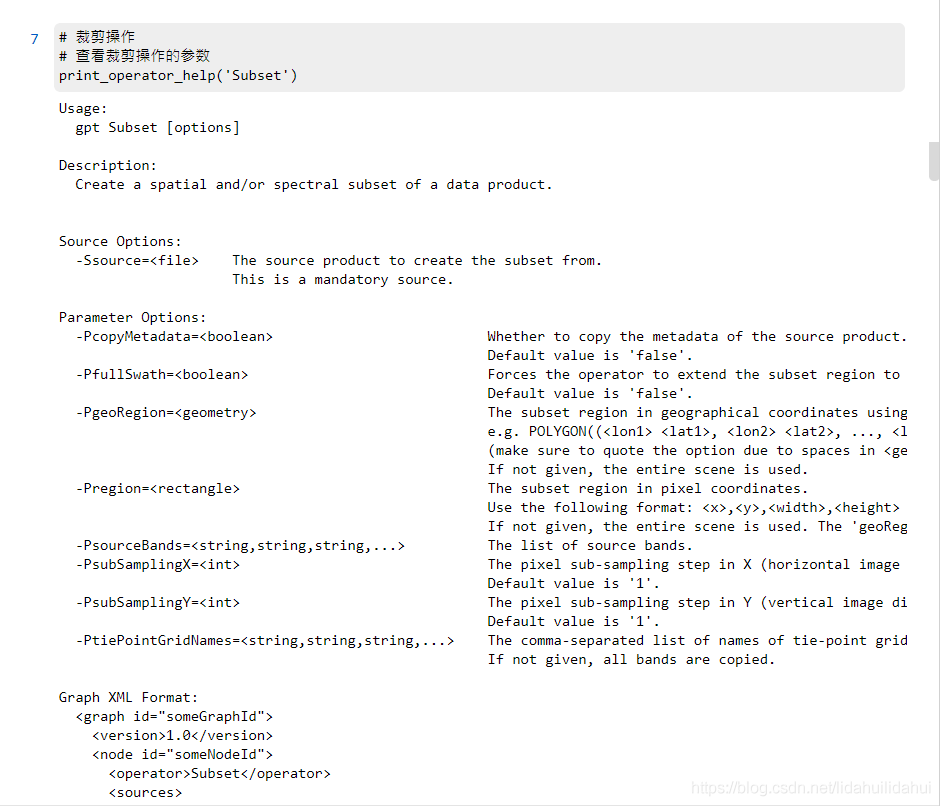
爲了減少數據量,這裏使用裁剪操作(這樣,即使小記憶體的電腦也能較好較快地得到結果)。
檢視該操作的參數:
# 裁剪操作
# 檢視裁剪操作的參數
print_operator_help('Subset')
結果:
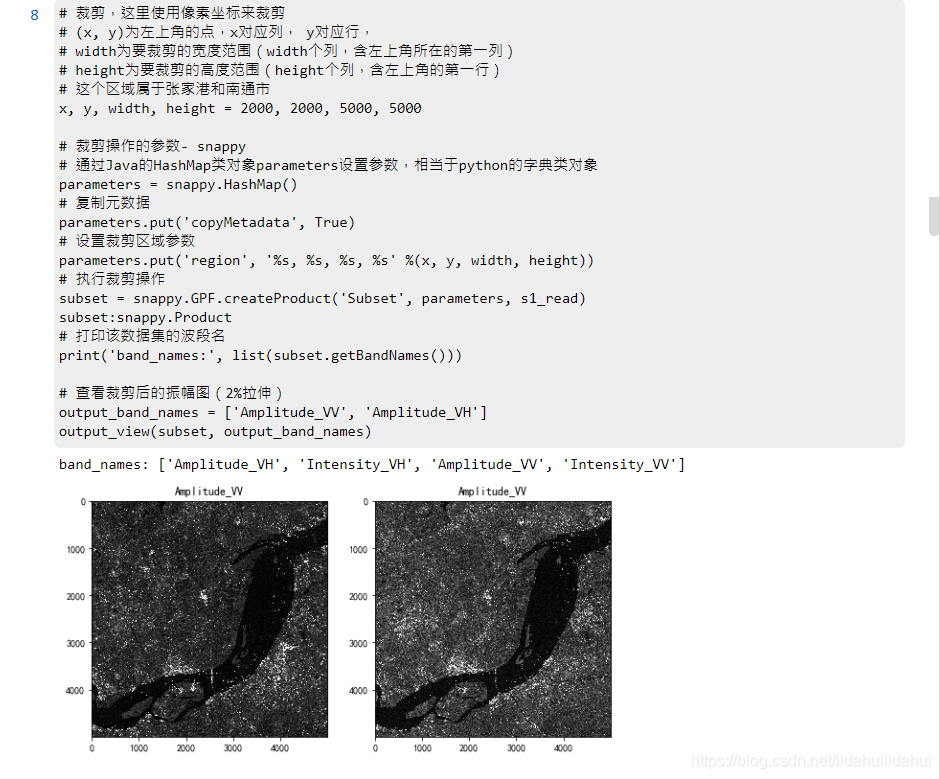
執行該操作:
# 裁剪,這裏使用畫素座標來裁剪
# (x, y)爲左上角的點,x對應列, y對應行,
# width爲要裁剪的寬度範圍(width個列,含左上角所在的第一列)
# height爲要裁剪的高度範圍(height個列,含左上角的第一行)
# 這個區域屬於張家港和南通市
x, y, width, height = 2000, 2000, 5000, 5000
# 裁剪操作的參數- snappy
# 通過Java的HashMap類物件parameters設定參數,相當於python的字典類物件
parameters = snappy.HashMap()
# 複製元數據
parameters.put('copyMetadata', True)
# 設定裁剪區域參數
parameters.put('region', '%s, %s, %s, %s' %(x, y, width, height))
# 執行裁剪操作
subset = snappy.GPF.createProduct('Subset', parameters, s1_read)
subset:snappy.Product
# 列印該數據集的波段名
print('band_names:', list(subset.getBandNames()))
# 檢視裁剪後的振幅圖(2%拉伸)
output_band_names = ['Amplitude_VV', 'Amplitude_VH']
output_view(subset, output_band_names)
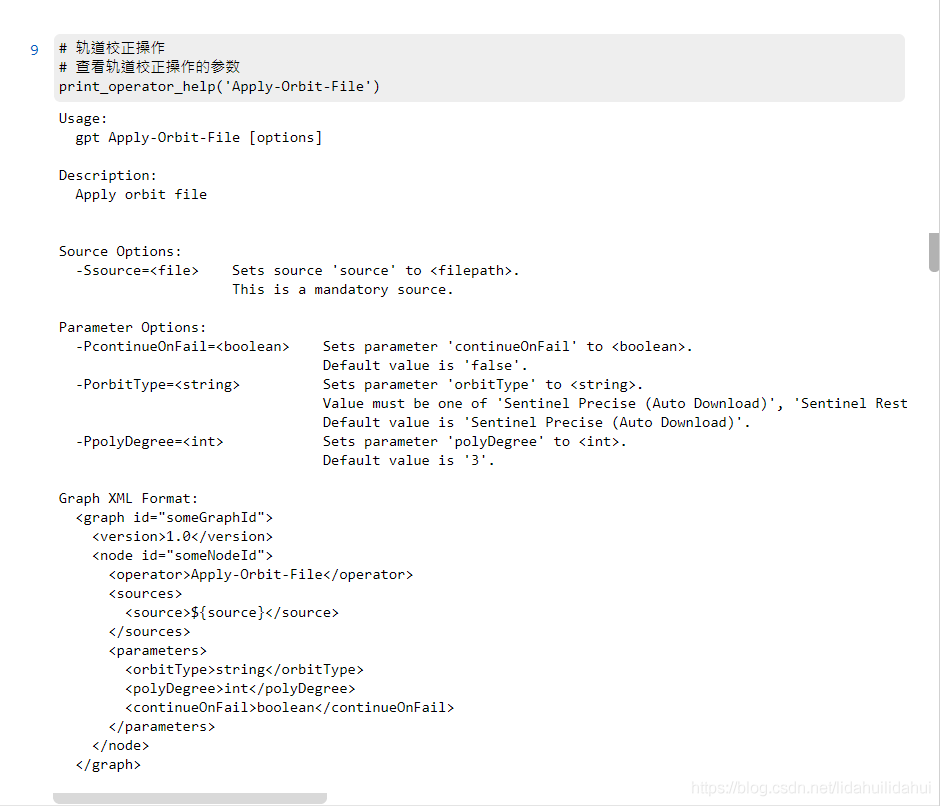
軌道校正操作
檢視該操作的參數:
# 軌道校正操作
# 檢視軌道校正操作的參數
print_operator_help('Apply-Orbit-File')
結果:
執行該操作:
# 軌道校正操作 - snappy
parameters = snappy.HashMap()
parameters.put('Apply-Orbit-File', True)
# 執行軌道校正操作
apply_orbit = snappy.GPF.createProduct('Apply-Orbit-File', parameters, subset)
這裏沒有視覺化該結果。
熱噪聲去除操作
檢視該操作的參數:
# 熱噪聲去除操作
# 檢視熱噪聲去除操作的參數
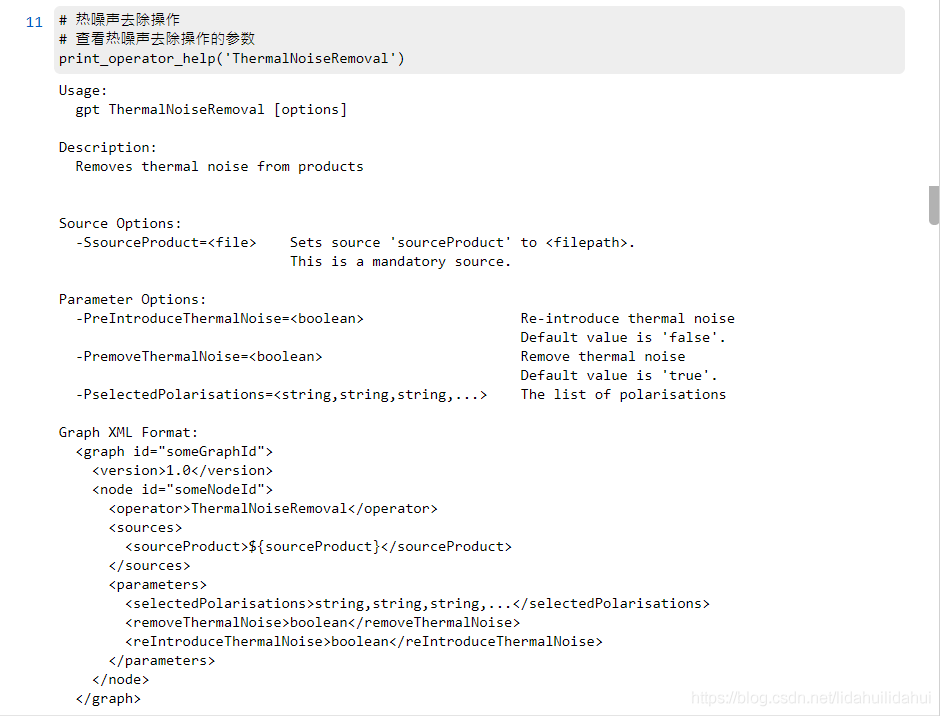
print_operator_help('ThermalNoiseRemoval')
結果:
執行該操作:
# 熱噪聲去除操作 - snappy
parameters = snappy.HashMap()
parameters.put('removeThermalNoise', True)
# 執行熱噪聲去除操作
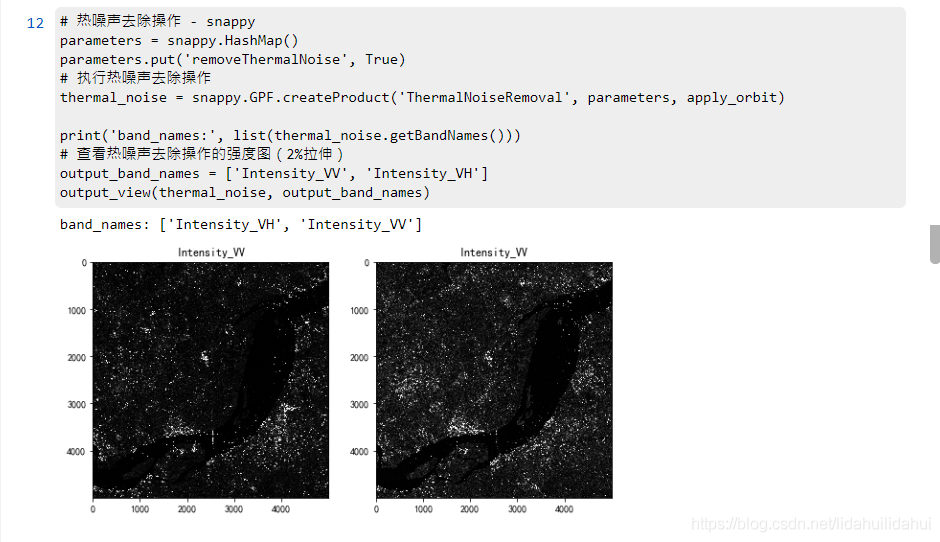
thermal_noise = snappy.GPF.createProduct('ThermalNoiseRemoval', parameters, apply_orbit)
print('band_names:', list(thermal_noise.getBandNames()))
# 檢視熱噪聲去除操作的強度圖(2%拉伸)
output_band_names = ['Intensity_VV', 'Intensity_VH']
output_view(thermal_noise, output_band_names)
輻射定標操作
檢視該操作的參數:
# 輻射定標操作
# 檢視輻射定標操作的參數
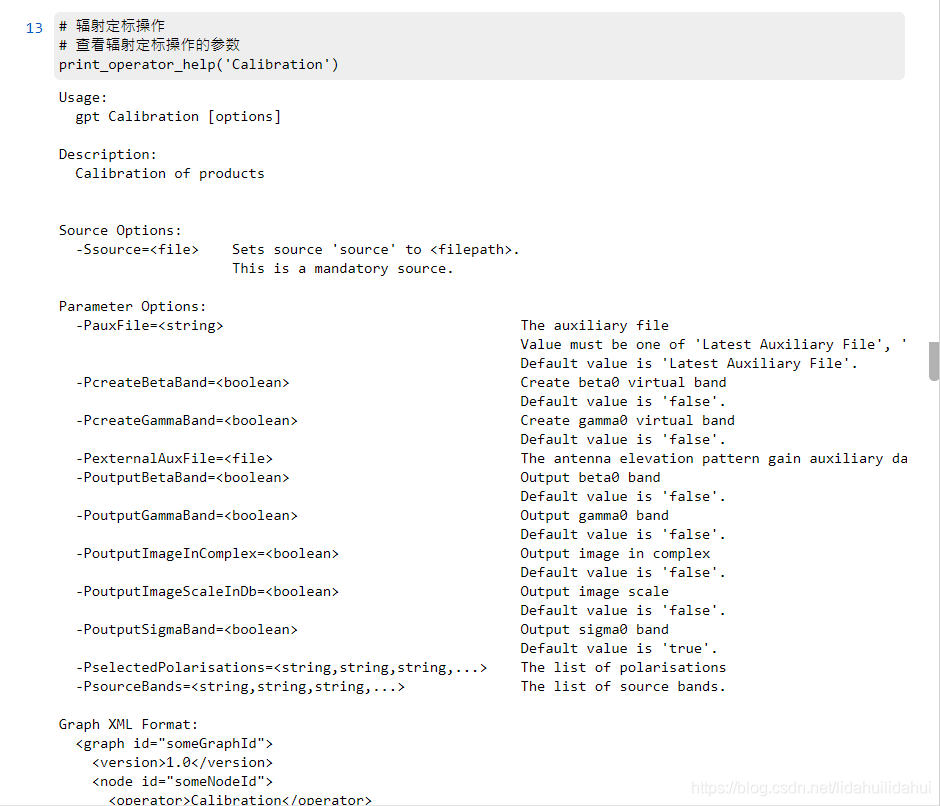
print_operator_help('Calibration')
結果:
執行該操作:
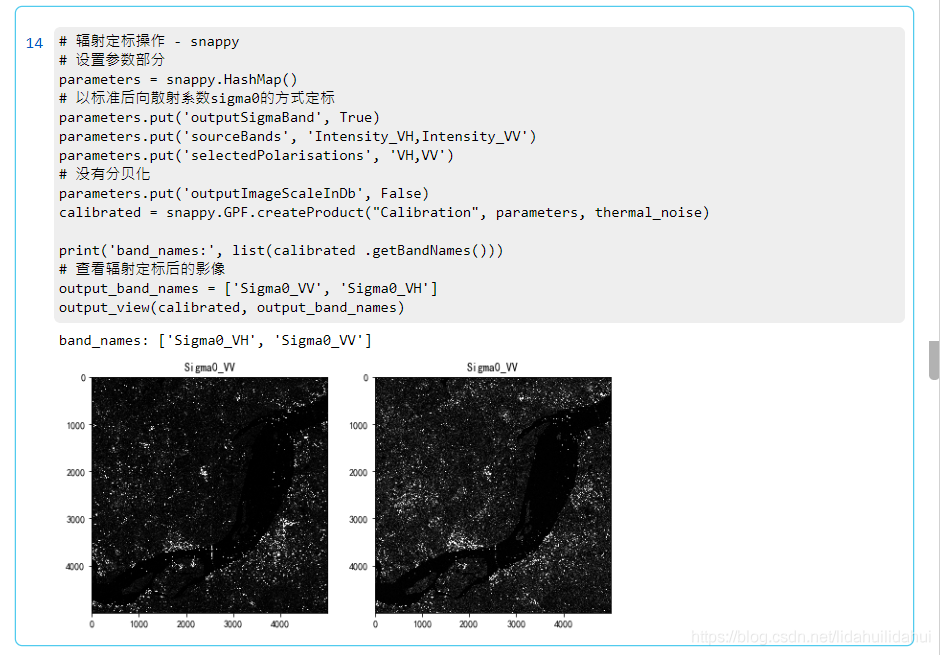
# 輻射定標操作 - snappy
# 設定參數部分
parameters = snappy.HashMap()
# 以標準後向散射係數sigma0的方式定標
parameters.put('outputSigmaBand', True)
parameters.put('sourceBands', 'Intensity_VH,Intensity_VV')
parameters.put('selectedPolarisations', 'VH,VV')
# 沒有分貝化
parameters.put('outputImageScaleInDb', False)
calibrated = snappy.GPF.createProduct("Calibration", parameters, thermal_noise)
print('band_names:', list(calibrated .getBandNames()))
# 檢視輻射定標後的影像
output_band_names = ['Sigma0_VV', 'Sigma0_VH']
output_view(calibrated, output_band_names)
結果:
斑點濾波(相幹斑濾波)
檢視該操作的參數:
# 斑點濾波操作
# 檢視斑點濾波操作參數
print_operator_help('Speckle-Filter')
結果:
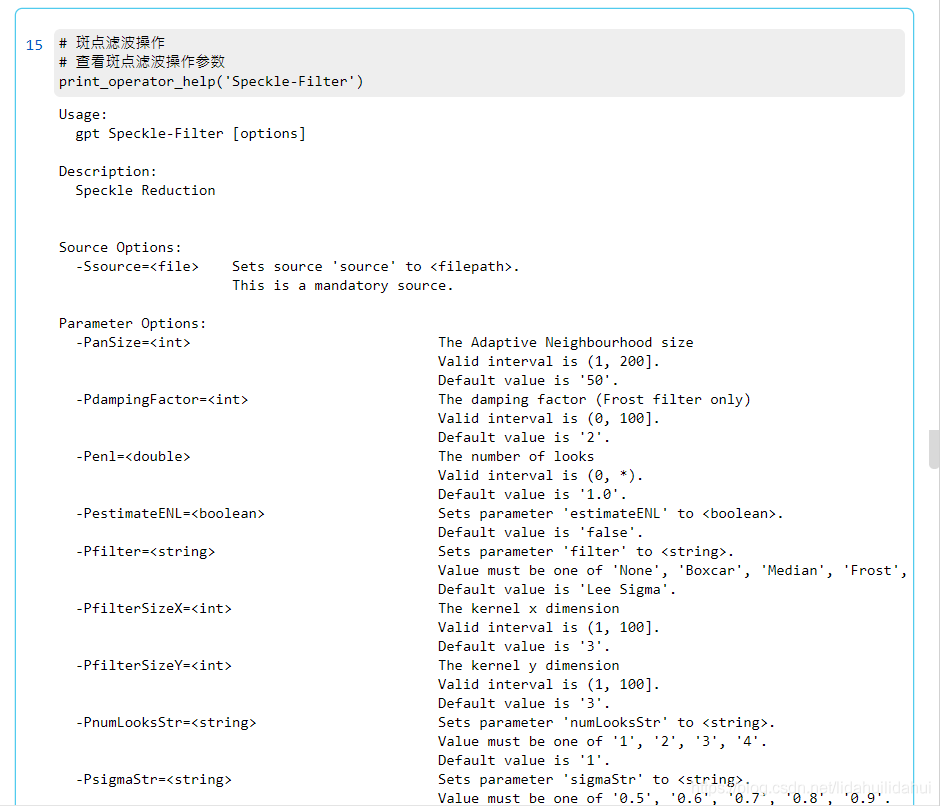
執行該操作:
# 斑點濾波操作 - snappy
parameters = snappy.HashMap()
# 使用改進型Lee濾波器濾波
parameters.put('filter', 'Refined Lee')
parameters.put('filterSizeX', 5)
parameters.put('filterSizeY', 5)
speckle = snappy.GPF.createProduct('Speckle-Filter', parameters, calibrated)
print('band_names:', list(speckle .getBandNames()))
# 檢視斑點濾波的影像
output_band_names = ['Sigma0_VV', 'Sigma0_VH']
output_view(speckle, output_band_names)
結果:

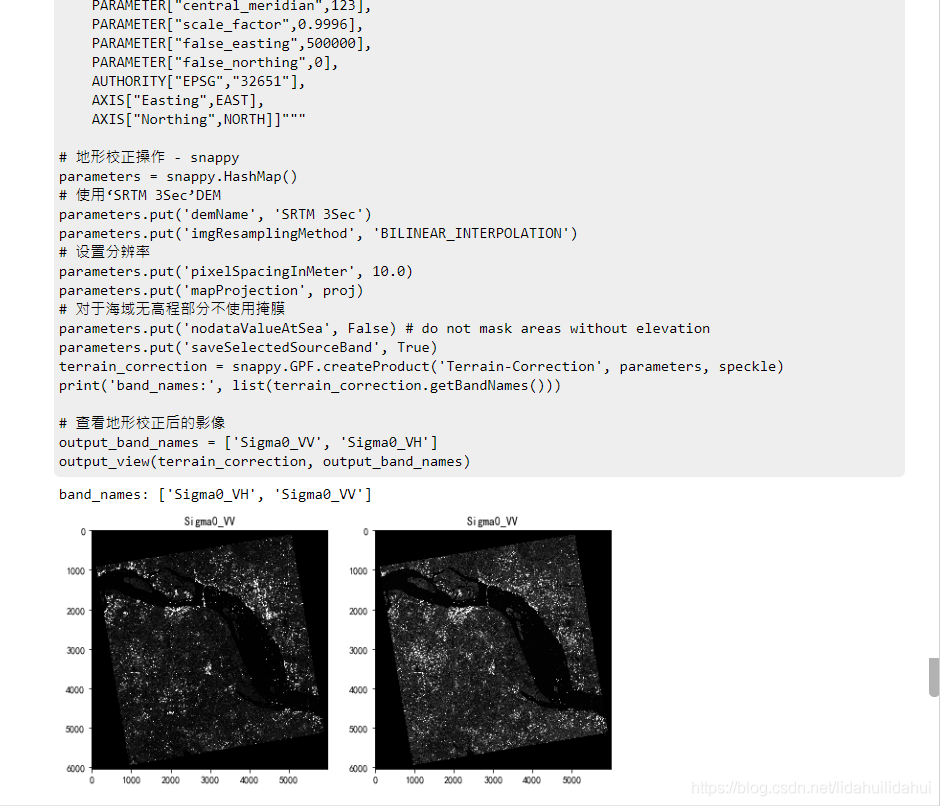
地形校正
地形校正時,使用了和當地Sentinel-2相同的UTM 51/WGS84座標系(注意,每個區域的UTM投影帶號可能不同,你可能需要修改爲自身研究區的UTM投影座標),並且去掉了沒有DEM數據的掩膜功能(對於靠海和水域地區,需要去掉這個,否則,該部分會被愛掩膜掉)。
檢視該操作的參數:
# 地形校正操作
# 檢視地形校正操作的參數
print_operator_help('Terrain-Correction')
結果:
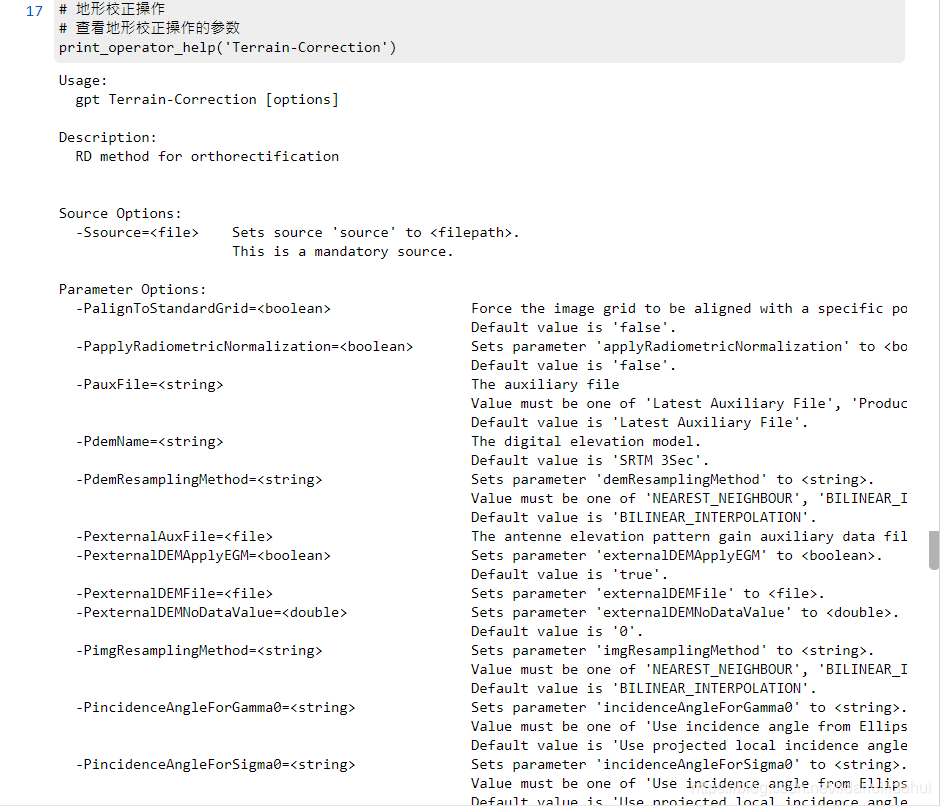
地形校正等類似操作需要獲取投影參數WKT文字表示(這是一大段的座標系描述字串,如果如果自己一個一個字元地輸入是很痛苦的事情,並且很容易出錯,好在,有兩種方式可以獲取有效所需座標系的WKT表示):
- 1.在SNAP GUI 地形校正介面中選擇好投影後,便可以在檢視該操作的參數中,找到相應的參數值:
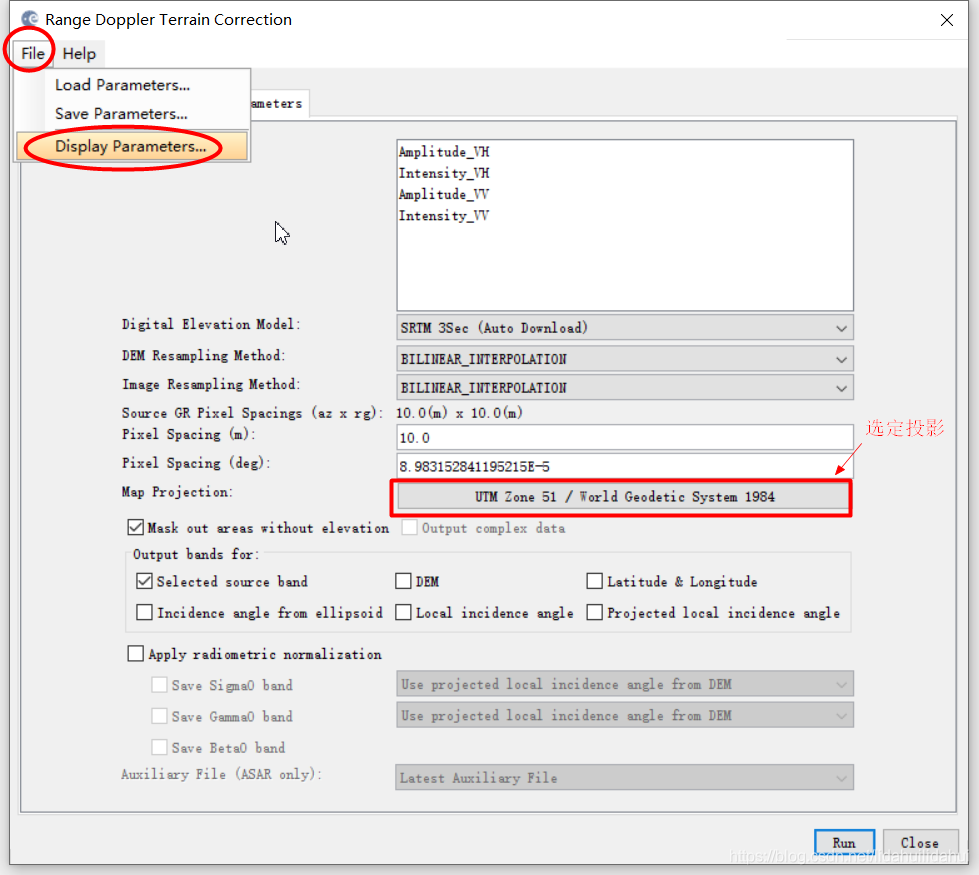
找到<mapProjection>的節點參數,即可以找到對應地理座標系的WKT文字表示:
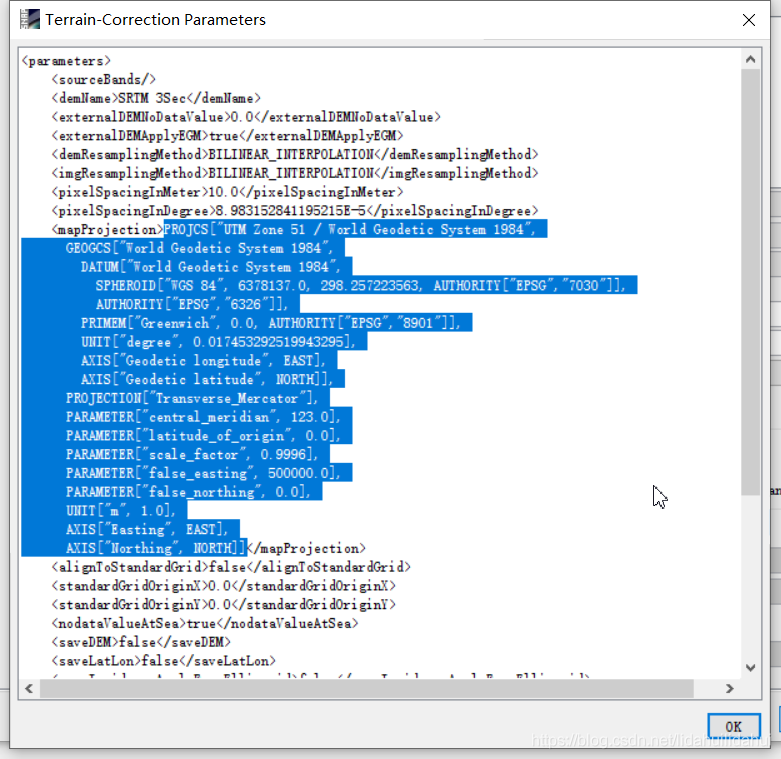
- 2.使用Spatial Reference官網查詢對應座標系的OGC WKT文字
經過博主的測試,OGC WKT文字表示,SNAP是可以識別的,大概是因爲SNAP是開源軟體,所以對開源的東西(OGC)支援比較好,比例QGIS、OTB等表示:
(但是,實際上該文字和SNAP產生的WKT文字還是有點細微的出入的(儘管相對別的表示最爲接近),另外,ESRI WKT文字似乎在SNAP的支援上有點問題,最好,使用OGC WKT,如果需要和別的GIS/RS軟體打交道的話)
執行該操作:
# 設定投影(wkt形式)
# 這裏使用UTM投影(WGS84橢球體下)
proj = """PROJCS["WGS 84 / UTM zone 51N",
GEOGCS["WGS 84",
DATUM["WGS_1984",
SPHEROID["WGS 84",6378137,298.257223563,
AUTHORITY["EPSG","7030"]],
AUTHORITY["EPSG","6326"]],
PRIMEM["Greenwich",0,
AUTHORITY["EPSG","8901"]],
UNIT["degree",0.01745329251994328,
AUTHORITY["EPSG","9122"]],
AUTHORITY["EPSG","4326"]],
UNIT["metre",1,
AUTHORITY["EPSG","9001"]],
PROJECTION["Transverse_Mercator"],
PARAMETER["latitude_of_origin",0],
PARAMETER["central_meridian",123],
PARAMETER["scale_factor",0.9996],
PARAMETER["false_easting",500000],
PARAMETER["false_northing",0],
AUTHORITY["EPSG","32651"],
AXIS["Easting",EAST],
AXIS["Northing",NORTH]]"""
# 地形校正操作 - snappy
parameters = snappy.HashMap()
# 使用‘SRTM 3Sec’DEM
parameters.put('demName', 'SRTM 3Sec')
parameters.put('imgResamplingMethod', 'BILINEAR_INTERPOLATION')
# 設定解析度
parameters.put('pixelSpacingInMeter', 10.0)
parameters.put('mapProjection', proj)
# 對於海域無高程部分不使用掩膜
parameters.put('nodataValueAtSea', False) # do not mask areas without elevation
parameters.put('saveSelectedSourceBand', True)
terrain_correction = snappy.GPF.createProduct('Terrain-Correction', parameters, speckle)
print('band_names:', list(terrain_correction.getBandNames()))
# 檢視地形校正後的影像
output_band_names = ['Sigma0_VV', 'Sigma0_VH']
output_view(terrain_correction, output_band_names)
結果:
分貝化操作
檢視該操作的參數:
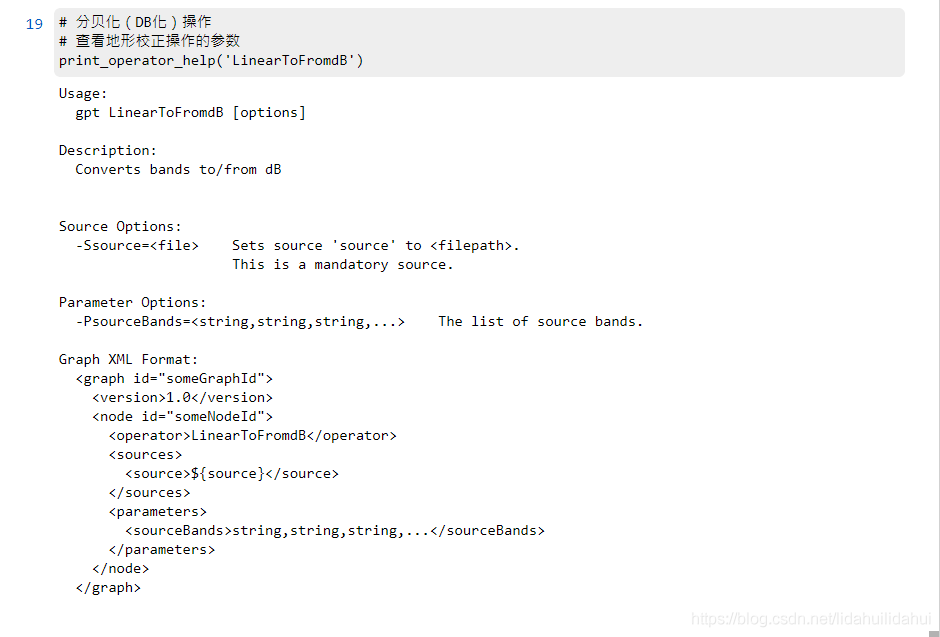
# 分貝化(DB化)操作
# 檢視地形校正操作的參數
print_operator_help('LinearToFromdB')
結果:
執行該操作:
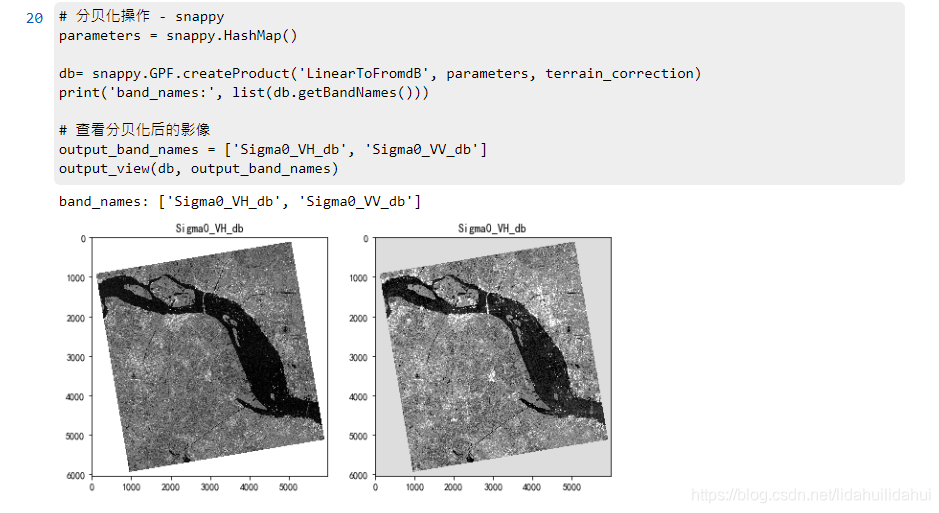
# 分貝化操作 - snappy
parameters = snappy.HashMap()
db= snappy.GPF.createProduct('LinearToFromdB', parameters, terrain_correction)
print('band_names:', list(db.getBandNames()))
# 檢視分貝化後的影像
output_band_names = ['Sigma0_VH_db', 'Sigma0_VV_db']
output_view(db, output_band_names)
結果:
寫入數據
這裏儲存爲geotiff格式。
執行該操作:
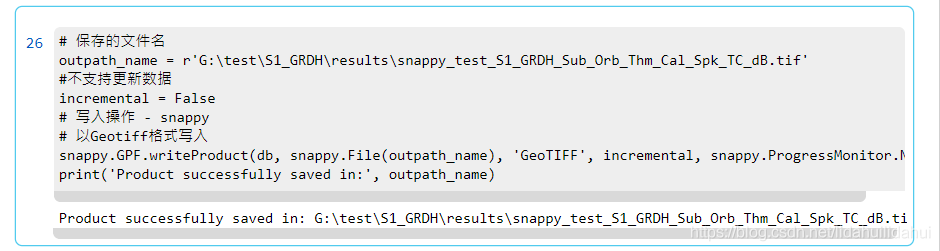
# 儲存的檔名
outpath_name = r'G:\test\S1_GRDH\results\snappy_test_S1_GRDH_Sub_Orb_Thm_Cal_Spk_TC_dB.tif'
#不支援更新數據
incremental = False
# 寫入操作 - snappy
# 以Geotiff格式寫入
snappy.GPF.writeProduct(db, snappy.File(outpath_name), 'GeoTIFF', incremental, snappy.ProgressMonitor.NULL)
print('Product successfully saved in:', outpath_name)
結果:
在SNAP中開啓驗證該結果看看:
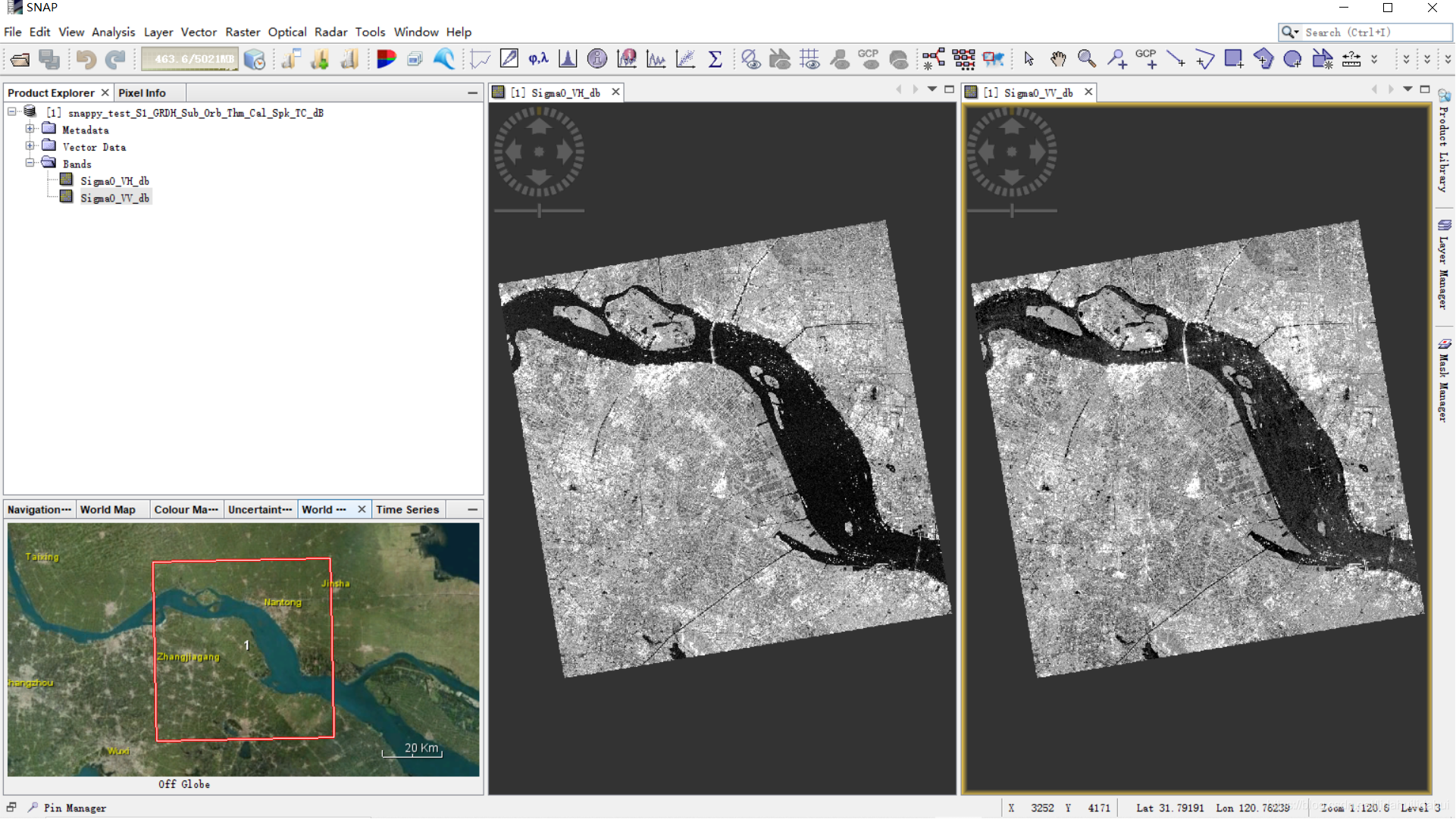
後來,我重新執行了整個流程,大約耗時約6分鐘,速度還可以的(儘管去掉一些檢視參數或視覺化之類的輔助函數可以更快一些),雖然在小數據集和使用gpt工具執行的時間差不多,但是,在大數據集中,gpt+流程圖檔案執行效率更高。
多個數據集預處理演示
SNAP中記憶體釋放問題,似乎還沒有解決,儘管官方很早就該問題的修復提上的日程。儘管可以將上述的單個數據的程式碼,編寫爲一個函數,從而,在批次處理是反覆 反復呼叫,但是,如果數據量大的話,可能很快就因爲記憶體不能及時釋放導致操作失敗。這裏,使用的是SNAP 官方論壇Temporary fix for snappy memory issues的解決方案,實際上,08篇部落格也是用了該方法,也是就通過呼叫python的subprocess模組以命令列「殺死進程」的方式強制釋放記憶體,這樣,就不用擔心記憶體不能及時釋放導致處理失敗的問題!
(由於處理的兩景Sentinel SAR影像數據量較大,8G執行記憶體處理起來可能有些吃力,16G以上執行記憶體應該是無壓力的)
下面 下麪程式碼使用的預處理流程,如下圖所示:
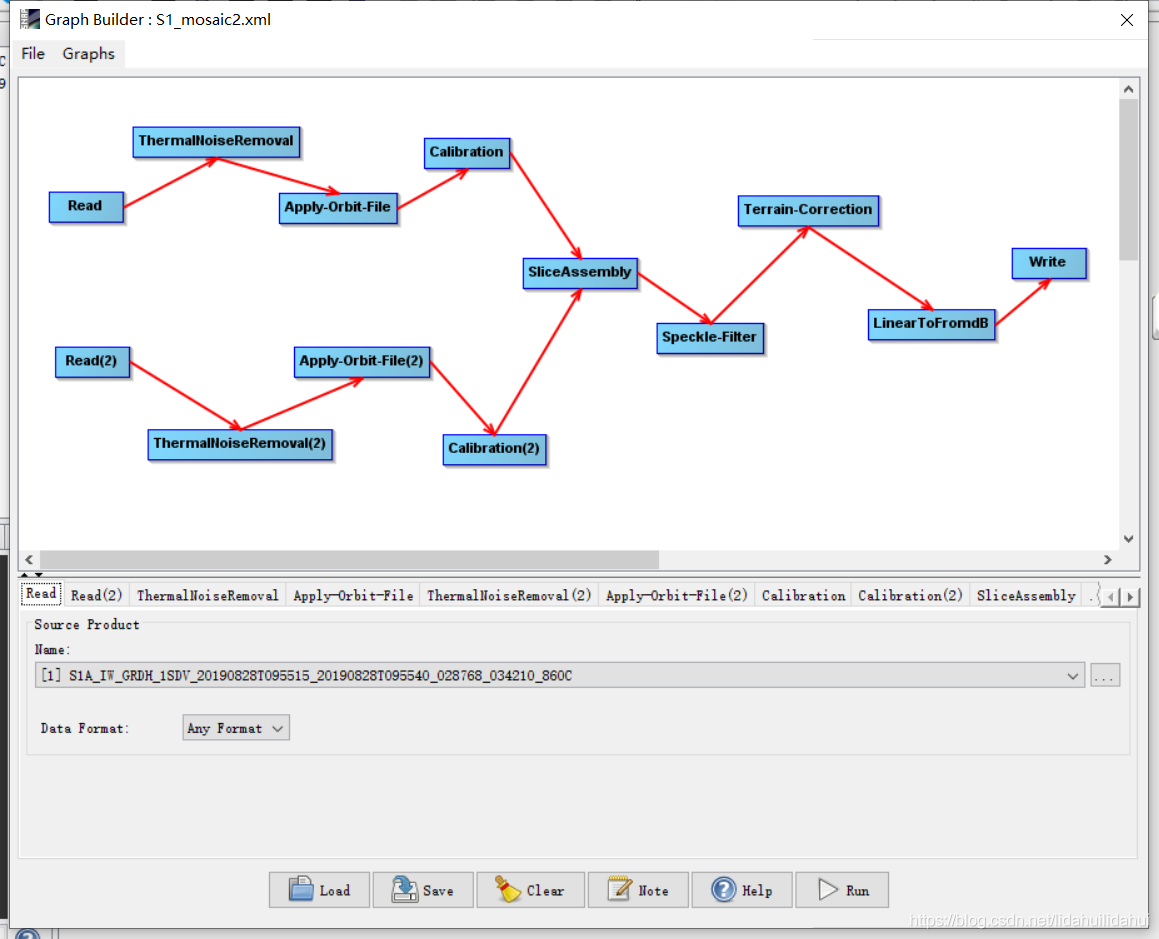
現將下述程式碼預處理程式碼儲存爲preprocess_S1.py(也是是別的python指令碼檔案,只要和別的python指令碼檔案混淆就可以):
(抱歉,很長的一段程式碼,但是,其邏輯是不難理解的)。
# -*- coding: utf-8 -*-
# Author: 超級禾欠水
import datetime
import time
from snappy import ProductIO
from snappy import HashMap
from snappy import GPF
from snappy import jpy
from snappy import File
from snappy import ProgressMonitor
import sys
import os
def read_s1_zip_file(file_name):
print('\tReading Sentinel-1 zip file...')
# 執行讀入操作
output = ProductIO.readProduct(file_name)
return output
def do_apply_orbit_file(product):
print('\tApply orbit file...')
# 軌道校正操作 - snappy
parameters = HashMap()
parameters.put('Apply-Orbit-File', True)
# 執行軌道校正操作
output = GPF.createProduct('Apply-Orbit-File', parameters, product)
return output
def do_thermal_noise_removal(product):
# 熱噪聲去除操作 - snappy
parameters = HashMap()
parameters.put('removeThermalNoise', True)
# 執行熱噪聲去除操作
output = GPF.createProduct('ThermalNoiseRemoval', parameters, product)
return output
def do_calibration(product):
print('\tCalibration...')
parameters = HashMap()
# 以標準後向散射係數sigma0的方式定標
parameters.put('outputSigmaBand', True)
parameters.put('productBands', 'Intensity_VH,Intensity_VV')
parameters.put('selectedPolarisations', 'VH,VV')
# 沒有分貝化
parameters.put('outputImageScaleInDb', False)
output = GPF.createProduct("Calibration", parameters, product)
return output
def do_speckle_filtering(product):
print('\tSpeckle filtering...')
parameters = HashMap()
# 使用Refine Lee濾波器。預設是Lee Sigma
parameters.put('filter','Refined Lee')
output = GPF.createProduct('Speckle-Filter', parameters, product)
return output
def do_terrain_correction(product, proj):
print('\tTerrain correction...')
parameters = HashMap()
parameters.put('demName', 'SRTM 3Sec')
parameters.put('imgResamplingMethod', 'BILINEAR_INTERPOLATION')
parameters.put('mapProjection', proj) # 如果你需要使用UTM/WGS84投影,可以註釋該行程式碼,預設是WGS84地理座標系
parameters.put('saveProjectedLocalIncidenceAngle', False)
parameters.put('saveSelectedproductBand', True)
parameters.put('nodataValueAtSea', False)
# 解析度爲10m
parameters.put('pixelSpacingInMeter', 10.0)
output = GPF.createProduct('Terrain-Correction', parameters, product)
return output
def do_line_to_db(product):#將線性單位轉爲分貝值
print('\tLining_to_db...')
# 使用預設參數值,即選擇所有通道
parameters = HashMap()
output = GPF.createProduct('LinearToFromdB',parameters,product)
return output
# 使用wkt座標範圍裁剪
def do_subset(product, wkt):
print('\tSubsetting...')
parameters = HashMap()
parameters.put('geoRegion', wkt)
output = GPF.createProduct('Subset', parameters, product)
return output
# 使用畫素座標裁剪
def do_subset(product, x, y, width, height):
parameters = HashMap()
# 複製元數據
parameters.put('copyMetadata', True)
# 設定裁剪區域參數
parameters.put('region', '%s, %s, %s, %s' % (x, y, width, height))
# 執行裁剪操作
output = GPF.createProduct('Subset', parameters, product)
return output
def do_SliceAssembly(product_list):
# 使用預設參數值,即選擇所有通道
# 建立一個product類陣列
products = jpy.array('org.esa.snap.core.datamodel.Product', len(product_list))
for count in range(len(product_list)):
products[count] = product_list[count]
parameters = HashMap()
output = GPF.createProduct('SliceAssembly', parameters, products)
return output
def write_to_file(product, file_path, format='BEAM-MAP'):
print("Writing...")
# 不支援更新數據
incremental = False
# 寫入操作 - snappy
# 以format格式寫入
GPF.writeProduct(product, File(file_path), format, incremental, ProgressMonitor.NULL)
def pre_process(path, files, outpath):
# 上海市UTM投影
proj = '''
PROJCS["UTM Zone 51 / World Geodetic System 1984",
GEOGCS["World Geodetic System 1984",
DATUM["World Geodetic System 1984",
SPHEROID["WGS 84", 6378137.0, 298.257223563, AUTHORITY["EPSG","7030"]],
AUTHORITY["EPSG","6326"]],
PRIMEM["Greenwich", 0.0, AUTHORITY["EPSG","8901"]],
UNIT["degree", 0.017453292519943295],
AXIS["Geodetic longitude", EAST],
AXIS["Geodetic latitude", NORTH]],
PROJECTION["Transverse_Mercator"],PARAMETER["central_meridian", 123.0],
PARAMETER["latitude_of_origin", 0.0],PARAMETER["scale_factor", 0.9996],
PARAMETER["false_easting", 500000.0],PARAMETER["false_northing", 0.0],
UNIT["m", 1.0],AXIS["Easting", EAST],AXIS["Northing", NORTH]]
''' # 不同的區域,通常需要修改帶號(UTM Zone 51)和中央經度123.0的值(即PARAMETER["central_meridian", 123.0])
# # 使用WGS84地理座標系對應的prj
# proj = '''
# GEOGCS["WGS 84",
# DATUM["WGS_1984",
# SPHEROID["WGS 84", 6378137, 298.257223563, AUTHORITY["EPSG", "7030"]],
# AUTHORITY["EPSG", "6326"]],
# PRIMEM["Greenwich", 0, AUTHORITY["EPSG", "8901"]],
# UNIT["degree", 0.0174532925199433, AUTHORITY["EPSG", "9122"]],
# AUTHORITY["EPSG", "4326"]]
files = files.split(';')
basename = os.path.basename(files[0])
# 獲取時間和日期
date = basename.split('_')[4].split('T')[0]
# 回圈開始時間
loopstarttime = str(datetime.datetime.now())
print('Start time:', loopstarttime)
start_time = time.time()
## 開始預處理:
# 鑲嵌
product_list = []
for index in range(len(files)):
sentinel_1 = read_s1_zip_file(files[index])
# 熱噪聲去除
thermalremoved = do_thermal_noise_removal(sentinel_1)
applyorbit = do_apply_orbit_file(thermalremoved)
# 輻射定標
calibrated = do_calibration(applyorbit)
product_list.append(calibrated)
# 鑲嵌
assembly = do_SliceAssembly(product_list)
del thermalremoved, applyorbit, calibrated
# 斑點濾波
filtered = do_speckle_filtering(assembly)
# 地形校正
terrain_corrected = do_terrain_correction(filtered, proj)
del filtered
# 分貝化
line_to_db = do_line_to_db(terrain_corrected )
del terrain_corrected
# 寫入數據
print("Writing...")
final_path = outpath + '\\' + 'Shanghai_S1_GRDH_' + date + '.tif'
write_to_file(line_to_db, final_path, format='GeoTIFF-BigTIFF')
del line_to_db
print('Done.')
print("--- %s seconds ---" % (time.time() - start_time))
path = sys.argv[1]
files = sys.argv[2]
outpath = sys.argv[3]
pre_process(path, files, outpath)
上述的鑲嵌部分的程式碼,需要多說一下的:
def do_SliceAssembly(product_list):
# 使用預設參數值,即選擇所有通道
# 建立一個product類陣列
products = jpy.array('org.esa.snap.core.datamodel.Product', len(product_list))
for count in range(len(product_list)):
products[count] = product_list[count]
parameters = HashMap()
output = GPF.createProduct('SliceAssembly', parameters, products)
return output
因爲鑲嵌使用兩個以上的數據集,這裏通過使用Product類陣列實現向SliceAssembly操作傳遞多個數據集的。
主程式,這裏儲存爲snappy_batch_process_S1_GRDH.py:
# -*- coding: utf-8 -*-
# Author: 超級禾欠水
# 匯入相關庫
import subprocess
import os, gc
import time
import glob
# python.exe檔案所在路徑,如果有多個版本的python,請注意對應的路徑
python_exe_path = r'E:\Anaconda\Anaconda3\envs\py36\python.exe'
# 要執行的python指令碼檔案
py_file_path = r'C:\Users\lidahui\Desktop\My_file\snappy_project\preprocess_S1.py'
# 批次處理Sentinel-1 GRDH 數據所在路徑(壓縮檔案即可)
in_path = r'G:\test\S1_GRDH' ###########
# 存放處理後數據的路徑
out_path= r'G:\test\S1_GRDH\snappy_batch_results' ######
if not os.path.exists(out_path):
os.makedirs(out_path)
# 獲取該輸入路徑的Sentinel-1 GRDH原始數據壓縮檔案.zip
zip_files = sorted(glob.glob(os.path.join(in_path, '*.zip')))
# 同一天兩景中的某景構成的part1列表
part1_files = zip_files[::2]
# 同一天兩景中的另一景構成的part2列表
part2_files = zip_files[1::2]
for file_ndex in range(len(part1_files)):
gc.enable()
gc.collect()
files = [part1_files[file_ndex],part2_files[file_ndex]]
basename = os.path.basename(files[0])
# 獲取時間和日期
date = basename.split('_')[4].split('T')[0]
print("PreProcessing %s's data..."%(date))
files = ';'.join(files)
pipeline_out = subprocess.check_output([python_exe_path, py_file_path, in_path, files, out_path],
stderr=subprocess.STDOUT)
print("The Preprocession of %s's data finishes!"%(date))
# # 睡眠30s,以等待釋放記憶體
print("Sleeping...")
time.sleep(30)
執行程式碼(可以直接執行snappy_batch_process_S1_GRDH.py,當然在命令列視窗頁也可以執行):
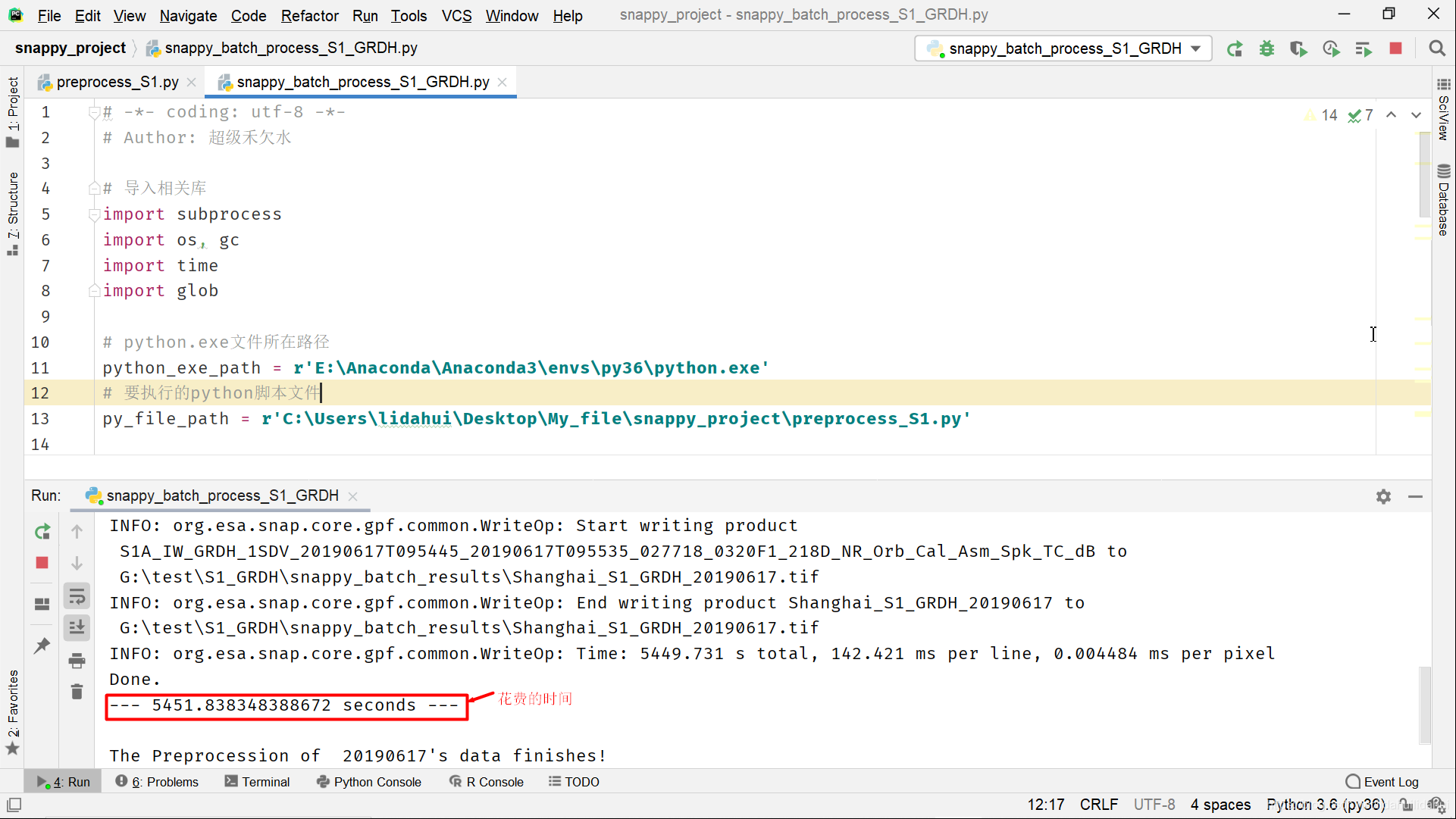
處理一天的鑲嵌數據耗費了1個半小時左右的時間,相交使用gpt和流程圖效率要低一些(gpt + 流程圖檔案,約爲半小時)。但是,預處理,並非snappy的優勢所在,重要的是其可以和Python第三方庫結合起來,從而大大擴充套件相應的可能應用。(無論gpt工具還是snappy,抑或是SNAP GUI介面也好,其實,耗費的時間,只要花費在寫操作上,因此,使用固態硬碟的話,寫入速度跟快,相應地處理時間會明顯減少!博主這裏使用的是機械硬碟,因此,耗費的時間還是較多的。當然,耗費的時間也會和寫入的影像格式有關,預設的SNAP 影像格式爲BEAM-DIMAP格式(這裏使用了GeoTiff-BigTiff格式),該格式相較別的格式寫入速度會快一些)
結果:
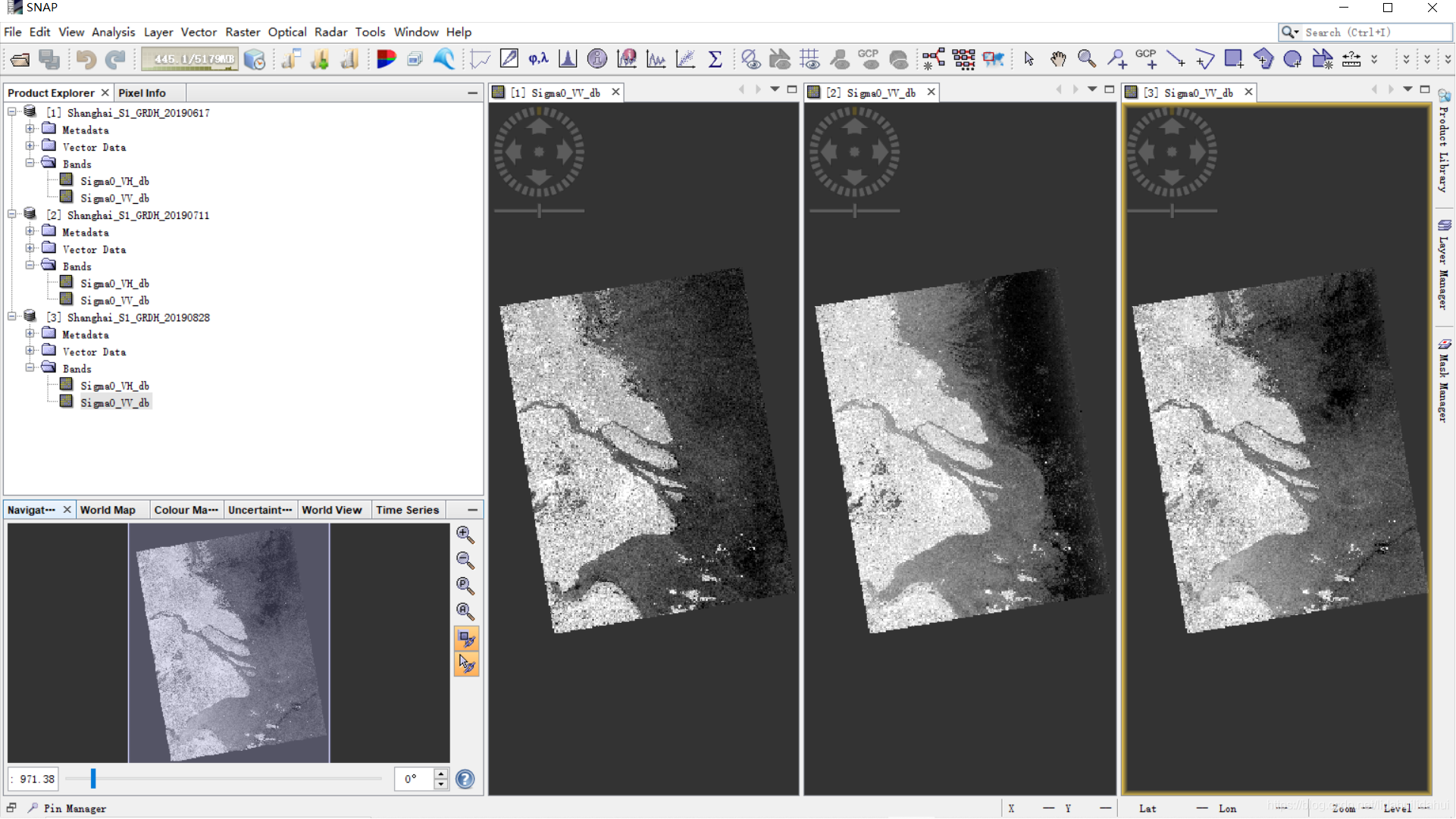
後語
抱歉,拖了很久纔開始介紹snappy的使用。不過,前面數篇部落格對於編寫snappy相關的程式碼是很有幫助的。本篇部落格程式碼遵循從簡單到複雜,循循漸進的思路。仔細地看這篇部落格的話,程式碼的一些片段是比較經典的,並且一些程式碼還是有點深度的,新手者可能需要琢磨一下才行。但願,你能有所收穫。
儘管使用snappy來做預處理,需要寫較長的程式碼,比不上使用gpt+流程圖檔案方式來得簡單一些,但是,使用snappy可以更精緻地控制各項流程參數(Java原始碼級別的呼叫),並且snappy還支援一些使用gpt工具很難實現的操作,比如一些控制點操作,變化分析等等。
儘管到目前爲此,仍然只是介紹了Sentinel衛星的預處理,但是,後面,將會展示利用snappy和python的第三方開源包結合起來實現一些Sentinel衛星影像數據分析和應用的強大功能。如果是處理SAR衛星,python還有另一個python包(pyroSAR)可用,該包的開發者也是屬於SNAP開發者團隊,實現了一些SNAP的SAR處理功能,感興趣的話,也可以學一下該包,SNAP論壇上有該包的開發者在答疑,也有相關的討論。
最後,老話了!如果你對歐空局開源軟體處理軟體SNAP及其snappy開發處理感興趣,可以加入博主建立的歐空局SNAP處理交流羣:665903216(這個羣已滿人),歐空SNAP處理交流羣(二):1102493346。
參考文獻
[1] SNAP 官方wiki部落格snappy的使用https://senbox.atlassian.net/wiki/spaces/SNAP/pages/19300362/How+to+use+the+SNAP+API+from+Python
[2] SNAP Engine API文件
http://step.esa.int/docs/v6.0/apidoc/engine/
[3] https://github.com/wajuqi/Sentinel-1-preprocessing-using-Snappy
[4] SNAP 官方論壇Temporary fix for snappy memory issues貼文
https://forum.step.esa.int/t/temporary-fix-for-snappy-memory-issues/9772
[5] SNAP 官方論壇Multi-Threading and Performance of snappy / jpy貼文
https://forum.step.esa.int/t/multi-threading-and-performance-of-snappy-jpy/7754