大數據hadoop篇:MapReduce
一、MapReduce概述
1.1 MapReduce定義、優缺點
-
MapReduce是一個分佈式運算程式的程式設計框架,是使用者開發「基於 Hadoop的數據分析應用」的核心框架。
-
MapReduce核心功能是將使用者編寫的業務邏輯程式碼和自帶預設元件整合成一個完整的分佈式運算程式,併發執行在一個 Hadoop叢集上。
1.1.1 優點
- MapReduce易於程式設計,它簡單的實現一些介面,就可以完成一個分佈式程式,這個分佈式程式可以分佈到大量廉價的PC機器上執行。也就是說你寫一個分佈式程式,跟寫 一個簡單的序列程式是一模一樣的。就是因爲這個特點使得Map Reduce程式設計變得非常流行。
- 良好的擴充套件性,當你的計算資源不能得到滿足的時候,你可以通過簡單的增加機器來擴充套件 它的計算能力。
- 高容錯性,Map Reduce設計的初衷就是使程式能夠部署在廉價的PC機器上, 這就要求它具有很高的容錯性。比如其中一臺機器掛了,它可以把上面的計算任務 轉移到另外一個節點上執行,不至於這個任務執行失敗,而且這個過程不需要人工參與, 而完全是由Hadoop內部完成的。
- 適合PB級以上海量數據的離線處理可以實現上千台伺服器叢集併發工作,提供數據處理能力。
1.1.2 缺點
- 不擅長實時計算MapReduce無法像MySQL一樣, 在毫秒或者秒級內返回結果。
- 不擅長流式計算,流式計算的輸入數據是動態的, 而MapReduce的輸入數據集是靜態的, 不能動態變化。這是因爲MapReduce自身的設計特點決定了數據源必須是靜態的。
- 不擅長DAG(有向圖) 計算,多個應用程式存在依賴關係,後一個應用程式的輸入爲前一個的輸出。在這種情況下, MapReduce並不是不能做, 而是使用後, 每個MapReduce作業的輸出結果都會寫入到磁碟,會造成大量的磁碟IO,導致效能非常的低下。
1.2 MapReduce核心思想
1.MapReduce核心程式設計思想,如圖所示。
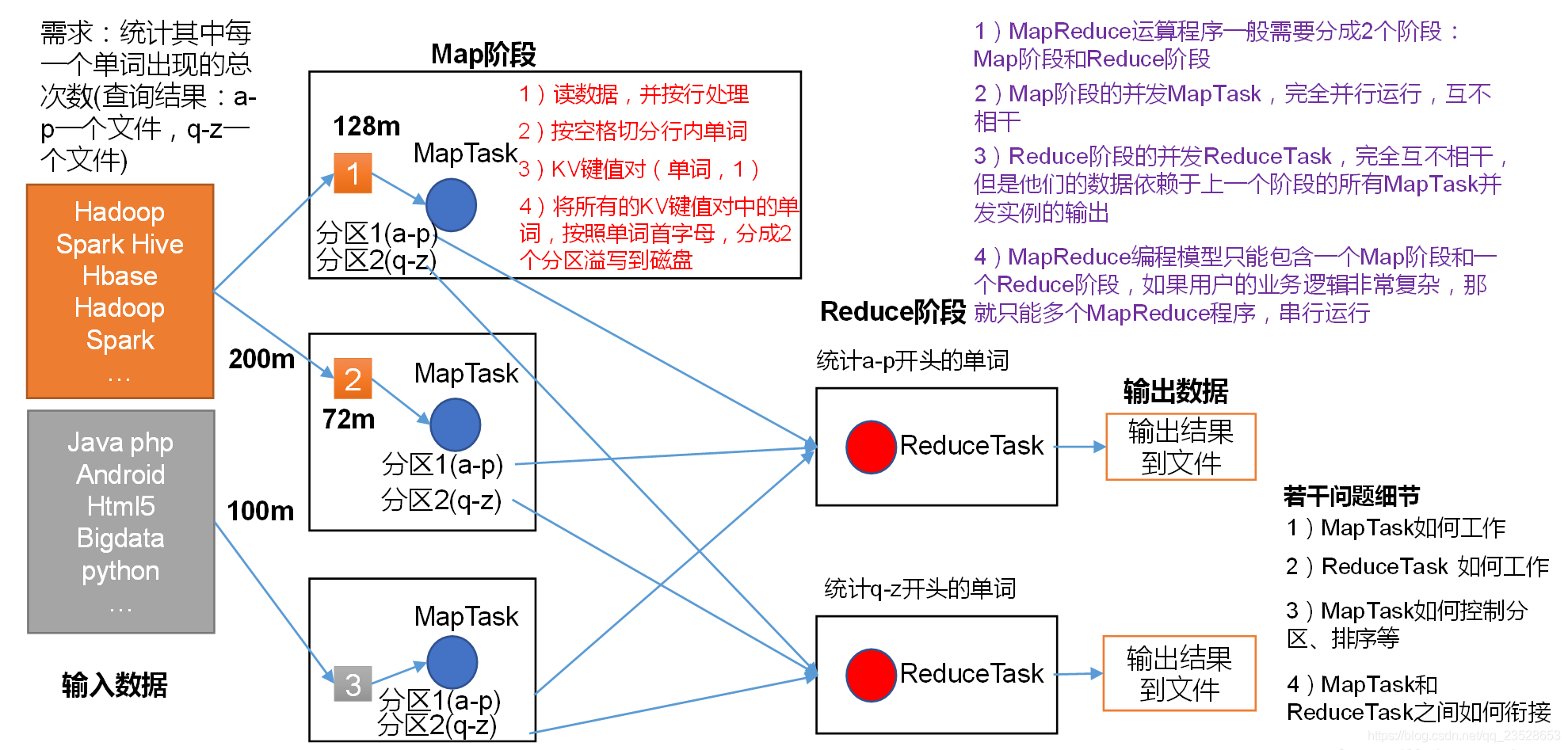
1)分佈式的運算程式往往需要分成至少2個階段。
2)第一個階段的MapTask併發範例,完全並行執行,互不相幹。
3)第二個階段的ReduceTask併發範例互不相幹,但是他們的數據依賴於上一個階段的所有MapTask併發範例的輸出。
4)MapReduce程式設計模型只能包含一個Map階段和一個Reduce階段,如果使用者的業務邏輯非常複雜,那就只能多個MapReduce程式,序列執行。
總結:分析WordCount數據流走向深入理解MapReduce核心思想。
2.MapReduce進程
一個完整的Map Reduce程式在分佈式執行時有三類範例進程:
- Mr App Master:負責整個程式的過程排程及狀態協調。
- Map Task:負責Map階段的整個數據處理流程。
- Reduce Task:負責Reduce階段的整個數據處理流程。
使用者編寫的程式分成三個部分:Mapper、Reducer和Driver。
- Mapper階段
(1) 使用者自定義的Mapper要繼承自己的父類別
(2) Mapper的輸入數據是KV對的形式(KV的型別可自定義)
(3) Mapper中的業務邏輯寫在map()方法中
(4) Mapper的輸出數據是KV對的形式(KV的型別可自定義)
(5) map()方法(Map Task進程) 對每一個<K, V>呼叫一次 - Reducer階段
(1) 使用者自定義的Reducer要繼承自己的父類別
(2) Reducer的輸入數據型別對應Mapper的輸出數據型別, 也是KV
(3) Reducer的業務邏輯寫在reduce()方法中
(4) Reduce Task進程對每一組相同k的k, v>組呼叫一次reduce()方法 - Driver階段
相當於YARN叢集的用戶端, 用於提交我們整個程式到YARN叢集, 提交的是
封裝了Map Reduce程式相關執行參數的job物件
1.3 WordCount程式
1.需求
在給定的文字檔案中統計輸出每一個單詞出現的總次數
2.需求分析
按照MapReduce程式設計規範,分別編寫Mapper,Reducer,Driver。

3.環境準備
(1)建立maven工程
(2)在pom.xml檔案中新增如下依賴
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
(2)在專案的src/main/resources目錄下,新建一個檔案,命名爲「log4j.properties」,在檔案中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4.編寫程式
(1)編寫Mapper類
package com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 獲取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 輸出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
(2)編寫Reducer類
package com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 輸出
v.set(sum);
context.write(key,v);
}
}
(3)編寫Driver驅動類
package com.mapreduce;
import java.io.IOException;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
// 1 獲取設定資訊以及封裝任務
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 設定jar載入路徑
job.setJarByClass(WordcountDriver.class);
// 3 設定map和reduce類
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 設定map輸出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 設定最終輸出kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//FileSystem fs = FileSystem.get(new URI("hdfs://spark1:9000"), configuration, "root");
Path outPath = new Path("hdfs://spark1:9000/meanwhileFind");// 輸出路徑
FileSystem fs = outPath.getFileSystem(configuration);// 根據輸出路徑找到檔案,參數爲組態檔
if (fs.exists(outPath)) {
fs.delete(outPath);
// fs.delete(outPath, true);true的意思是,就算output有東西,也一帶刪除,預設爲true
}
Path inpPath = new Path("hdfs://spark1:9000/wordcount.txt");
// 6 設定輸入和輸出路徑 args[0]
FileInputFormat.setInputPaths(job, inpPath);
FileOutputFormat.setOutputPath(job, outPath);
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
7.叢集上測試
(0)用maven打jar包,需要新增的打包外掛依賴
注意:mainClass部分需要替換爲自己工程主類
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin </artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.atguigu.mr.WordcountDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
注意:如果工程上顯示紅叉。在專案上右鍵->maven->update project即可。
(1)將程式打成jar包,然後拷貝到Hadoop叢集中
步驟詳情:右鍵->Run as->maven install。等待編譯完成就會在專案的target資料夾中生成jar包。如果看不到。在專案上右鍵-》Refresh,即可看到。修改不帶依賴的jar包名稱爲wc.jar,並拷貝該jar包到Hadoop叢集。
(2)啓動Hadoop叢集
(3)執行WordCount程式
hadoop jar wc.jar com.mapreduce.WordcountDriver
二、Hadoop序列化
2.1 序列化概述
- 什麼是序列化
序列化就是把記憶體中的物件,轉換成位元組序列(或其他數據傳輸協定)以便於儲存到磁碟(持久化)和網路傳輸。反序列化就是將收到位元組序列(或其他數據傳輸協定)或者是磁碟的持久化數據,轉換成記憶體中的物件。 - 爲什麼要序列化
一般來說,「活的」物件只生存在記憶體裡,關機斷電就沒有了。而且「活的」物件只能由原生的進程使用,不能被髮送到網路上的另外一臺計算機。然而序列化可以儲存「活的」物件,可以將「活的」物件發送到遠端計算機。 - 爲什麼不用Java的序列化
Java的序列化是一個重量級序列化框架(Serializable) , 一個物件被序列化後, 會附帶很多額外的資訊(各種校驗資訊, Header, 繼承體系等) , 不便於在網路中高效傳輸。所以, Hadoop自己開發了一套序列化機制 機製(Writable) 。 - Hadoop序列化特點:
(1)緊湊:高效使用儲存空間。
(2)快速:讀寫數據的額外開銷小。
(3)可延伸:隨着通訊協定的升級而可升級
(4)互操作:支援多語言的互動
2.1.2 常用數據序列化型別
| Java型別 | Hadoop Writable型別 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
2.2 自定義bean物件實現序列化介面(Writable)
在開發中往往常用的基本序列化型別不能滿足所有需求,比如在Hadoop框架內部傳遞一個bean物件,那麼該物件就需要實現序列化介面。
具體實現bean物件序列化步驟如下7步。
(1)必須實現Writable介面
(2)反序列化時,需要反射呼叫空參建構函式,所以必須有空參構造
public FlowBean() {
super();
}
(3)重寫序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
(4)重寫反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(5)注意反序列化的順序和序列化的順序完全一致
(6)要想把結果顯示在檔案中,需要重寫toString(),可用」\t」分開,方便後續用。
(7)如果需要將自定義的bean放在key中傳輸,則還需要實現Comparable介面,因爲MapReduce框中的Shuffle過程要求對key必須能排序。詳見後面排序案例。
@Override
public int compareTo(FlowBean o) {
// 倒序排列,從大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
2.3 序列化例子
-
流程

-
編碼
編寫流量統計的Bean物件
package com.serialize;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable{
private long upFlow;
private long downFlow;
private long sumFlow;
//2 反序列化時,需要反射呼叫空參建構函式,所以必須有
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
//3 寫序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//4 反序列化方法
//5 反序列化方法讀順序必須和寫序列化方法的寫順序必須一致
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
// 6 編寫toString方法,方便後續列印到文字
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
}
三、MapReduce框架原理
3.1 InputFormat數據輸入
3.1.1 切片與MapTask並行度決定機制 機製
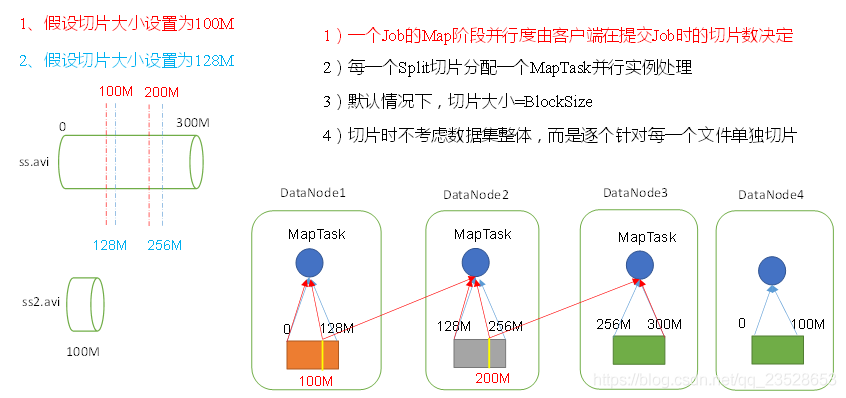
1.問題引出
MapTask的並行度決定Map階段的任務處理併發度,進而影響到整個Job的處理速度。
思考:1G的數據,啓動8個MapTask,可以提高叢集的併發處理能力。那麼1K的數據,也啓動8個MapTask,會提高叢集效能嗎?MapTask並行任務是否越多越好呢?哪些因素影響了MapTask並行度?
2.MapTask並行度決定機制 機製
數據塊:Block是HDFS物理上把數據分成一塊一塊。
數據切片:數據切片只是在邏輯上對輸入進行分片,並不會在磁碟上將其切分成片進行儲存。
3.1.2 Job提交流程原始碼和切片原始碼詳解
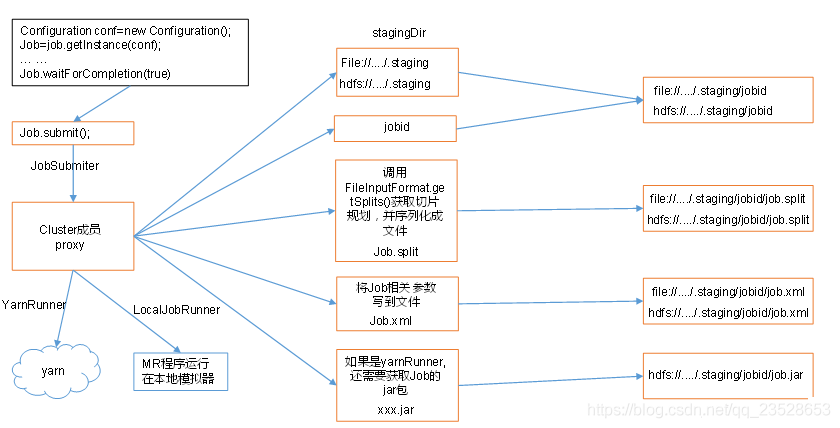
1.Job提交流程原始碼詳解
waitForCompletion()
submit();
// 1建立連線
connect();
// 1)建立提交Job的代理
new Cluster(getConfiguration());
// (1)判斷是本地yarn還是遠端
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)建立給叢集提交數據的Stag路徑
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)獲取jobid ,並建立Job路徑
JobID jobId = submitClient.getNewJobID();
// 3)拷貝jar包到叢集
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)計算切片,生成切片規劃檔案
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路徑寫XML組態檔
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交狀態
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
2.FileInputFormat切片原始碼解析(input.getSplits(job))

3.1.3 FileInputFormat切片機制 機製
-
切片機制 機製
(1)簡單地按照檔案的內容長度進行切片
(2) 切片大小, 預設等於Block大小
(3)切片時不考慮數據集整體,而是逐個針對每一個檔案單獨切片 -
案例分析
(1)輸入數據有兩個檔案:
file l.txt320M
file 2.txt10M
(2) 經過File Input Format的切片機制 機製
運算後,形成的切片資訊如下:
file l.txt.split 1–0~128
file l.txt.split 2–128~256
file l.txt.split 3–256~320
file 2.txt.split 1–0~10M -
FileInputFormat切片大小的參數設定
(1)原始碼中計算切片大小的公式
Math.max(minSize, Math.min(maxSize, blockSize) ) ;
map reduce n put.file input format.splt minsize=1預設值爲1
map reduce.n put.file input format.spl imax size=Long.MAXValue預設值Long.MAXValue
因此, 預設情況下, 切片大小=blocksize。
(2)切片大小設定
maxsize(切片最大值) :參數如果調得比blockSize小, 則會讓切片變小, 而且就等於設定的這個參數的值。
minsize(切片最小值) :參數調的比blockSize大, 則可以讓切片變得比blockSize還大。
(3) 獲取切片資訊API
//獲取切片的檔名稱
String name = inputSplit.getPath().getName();
//根據檔案型別獲取切片資訊
FileSplit inputSplit = (FileSplit) context.getInputSplit();
3.1.4 CombineTextInputFormat切片機制 機製
框架預設的TextInputFormat切片機制 機製是對任務按檔案規劃切片,不管檔案多小,都會是一個單獨的切片,都會交給一個MapTask,這樣如果有大量小檔案,就會產生大量的MapTask,處理效率極其低下。
1、應用場景:
CombineTextInputFormat用於小檔案過多的場景,它可以將多個小檔案從邏輯上規劃到一個切片中,這樣,多個小檔案就可以交給一個MapTask處理。
2、虛擬儲存切片最大值設定
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虛擬儲存切片最大值設定最好根據實際的小檔案大小情況來設定具體的值。
3、切片機制 機製
生成切片過程包括:虛擬儲存過程和切片過程二部分。
(1)虛擬儲存過程:
將輸入目錄下所有檔案大小,依次和設定的setMaxInputSplitSize值比較,如果不大於設定的最大值,邏輯上劃分一個塊。如果輸入檔案大於設定的最大值且大於兩倍,那麼以最大值切割一塊;當剩餘數據大小超過設定的最大值且不大於最大值2倍,此時將檔案均分成2個虛擬儲存塊(防止出現太小切片)。
例如setMaxInputSplitSize值爲4M,輸入檔案大小爲8.02M,則先邏輯上分成一個4M。剩餘的大小爲4.02M,如果按照4M邏輯劃分,就會出現0.02M的小的虛擬儲存檔案,所以將剩餘的4.02M檔案切分成(2.01M和2.01M)兩個檔案。
(2)切片過程:
(a)判斷虛擬儲存的檔案大小是否大於setMaxInputSplitSize值,大於等於則單獨形成一個切片。
(b)如果不大於則跟下一個虛擬儲存檔案進行合併,共同形成一個切片。
(c)測試舉例:有4個小檔案大小分別爲1.7M、5.1M、3.4M以及6.8M這四個小檔案,則虛擬儲存之後形成6個檔案塊,大小分別爲:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最終會形成3個切片,大小分別爲:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
3.1.5 CombineTextInputFormat案例
1.需求
將輸入的大量小檔案合併成一個切片統一處理。
(1)輸入數據
準備4個小檔案
(2)期望
期望一個切片處理4個檔案
2.實現過程
(1)不做任何處理,執行WordCount案例程式,觀察切片個數爲4。
(2)在WordcountDriver中增加如下程式碼,執行程式,並觀察執行的切片個數爲3。
(a)驅動類中新增程式碼如下:
// 如果不設定InputFormat,它預設用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虛擬儲存切片最大值設定4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
(b)執行結果爲3個切片。擴大最大值設定爲20971520執行結果爲1個切片。(number of splits:1)
3.1.6 FileInputFormat實現類
思考:在執行Map Reduce程式時, 輸入的檔案格式包括:基於行的日誌檔案、二進制格式檔案、數據庫表等。那麼, 針對不同的數據型別, Map Reduce是如何讀取這些數據的呢?
FileInputFormat常見的接實現類包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定義InputFormat等。
3.1.6.1 TextInputFormat
- TextInputFormat是預設的FileInputFormat實現類。按行讀取每條記錄。鍵是儲存該行在整個檔案中的起始位元組偏移量,LongWritable型別。值是這行的內容, 不包括任何行終止符(換行符和回車符) ,Text型別。
以下是一個範例,比如,一個分片包含瞭如下4條文字記錄。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
每條記錄表示爲以下鍵/值對:
(0, Rich learning form)
(19, Intelligent learning engine)
(47, Learning more convenient)
(72, From the real demand for more close to the enterprise)
3.1.6.2 KeyValueTextInputFormat
-
每一行均爲一條記錄, 被分隔符分割爲key, value。可以通過在驅動類中設定conf.set(KeyValue Line Record Reader KEY_VALUE_SEPERATOR, 」\t」) ; 來設定分隔符。預設分隔符是tab() 。
以下是一個範例,輸入是一個包含4條記錄的分片。其中——>表示一個(水平方向的)製表符。
此時的鍵是每行排在製表符之前的Text序列。
line 1 —>Rich learning form
line 2 —>Intelligent learning engine
line 3 —>Learning more convenient
line 4—>From the real demand for more close to the enterprise
每條記錄表示爲以下鍵/值對:
(line 1, Rich learning form)
(line 2, Intelligent learning engine)
(line 3, Learning more convenient)
(line 4, From the realdemand for more close to the enterprise) -
例統計輸入檔案中每一行的第一個單詞相同的行數。
(1)輸入數據
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
(2)期望結果數據
banzhang 2
xihuan 2
(3)程式碼實現
編寫Mapper類
package com.TextInputFormat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class KVTextMapper extends Mapper<Text,Text,Text,LongWritable>{
LongWritable v = new LongWritable(1);
@Override
protected void map(Text key, Text value, Mapper<Text, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
System.out.println("mapper key:" + key +" value:"+v);
context.write(key, v);
}
}
編寫Reducer類
package com.TextInputFormat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class KVTextReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable v = new LongWritable();
@Override
protected void reduce(Text k, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0L;
for (LongWritable value : values) {
sum += value.get();
}
v.set(sum);
System.out.println("reduce key:" + k +" value:"+v);
// 2 輸出
context.write(k, v);
}
}
編寫Driver類
package com.TextInputFormat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class KVTextDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"D:\\Users\\Administrator\\Desktop\\KVTextDriver.txt","hdfs://spark1:9000/out"};
Configuration conf = new Configuration();
// 設定切割符
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
// 1 獲取job物件
Job job = Job.getInstance(conf);
// 2 設定jar包位置,關聯mapper和reducer
job.setJarByClass(KVTextDriver.class);
job.setMapperClass(KVTextMapper.class);
job.setReducerClass(KVTextReducer.class);
// 3 設定map輸出kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4 設定最終輸出kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5 設定輸入輸出數據路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 設定輸入格式
job.setInputFormatClass(KeyValueTextInputFormat.class);
Path outPath = new Path(args[1]);// 輸出路徑
FileSystem fs = outPath.getFileSystem(conf);// 根據輸出路徑找到檔案,參數爲組態檔
if (fs.exists(outPath)) {
fs.delete(outPath);
// fs.delete(outPath, true);true的意思是,就算output有東西,也一帶刪除,預設爲true
}
// 6 設定輸出數據路徑
FileOutputFormat.setOutputPath(job,outPath);
// 7 提交job
job.waitForCompletion(true);
}
}
3.1.6.3 NLineInputFormat
- 如果使用NLineInputFormat, 代表每個map進程處理的InputSplit不再按Block塊去劃分, 而是按NlneInputFormat指定的行數N來劃分。即輸入檔案的總行數/N=切片數, 如果不整除, 切片數=商+1。
以下是一個範例,仍然以上面的4行輸入爲例。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
例如, 如果N是2, 則每個輸入分片包含兩行。開啓2個Map Task。
(0, Rich learning form)
(19, Intelligent learning engine)
另一個mapper則收到後兩行:
(47, Learning more convenient)
(72, From the real demand for more close to the enterprise)
這裏的鍵和值與TextInputFormat生成的一樣。 - 例對每個單詞進行個數統計,要求根據每個輸入檔案的行數來規定輸出多少個切片。此案例要求每三行放入一個切片中。
(1)輸入數據
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
(2)期望切片數
Number of splits:4
(3)程式碼實現
編寫Mapper類
package com.NLineInputFormat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class NLineMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
private Text k = new Text();
private LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// 1 獲取一行
String line = value.toString();
// 2 切割
String[] splited = line.split(" ");
// 3 回圈寫出
for (int i = 0; i < splited.length; i++) {
k.set(splited[i]);
System.out.println("mapper key:" + k +" value:"+v);
context.write(k, v);
}
}
}
編寫Reducer類
package com.NLineInputFormat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class NLineReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0l;
// 1 彙總
for (LongWritable value : values) {
sum += value.get();
}
v.set(sum);
System.out.println("reduce key:" + key +" value:"+v);
// 2 輸出
context.write(key, v);
}
}
編寫Driver類
package com.NLineInputFormat;
import java.io.IOException;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class NLineDriver {
public static void main(String[] args)
throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設定
args = new String[] { "D:\\Users\\Administrator\\Desktop\\NLineDriver.txt", "hdfs://spark1:9000/out" };
// 1 獲取job物件
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 7設定每個切片InputSplit中劃分三條記錄
NLineInputFormat.setNumLinesPerSplit(job, 3);
// 8使用NLineInputFormat處理記錄數
job.setInputFormatClass(NLineInputFormat.class);
// 2設定jar包位置,關聯mapper和reducer
job.setJarByClass(NLineDriver.class);
job.setMapperClass(NLineMapper.class);
job.setReducerClass(NLineReducer.class);
// 3設定map輸出kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4設定最終輸出kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
Path outPath = new Path(args[1]);// 輸出路徑
FileSystem fs = outPath.getFileSystem(configuration);// 根據輸出路徑找到檔案,參數爲組態檔
if (fs.exists(outPath)) {
fs.delete(outPath);
// fs.delete(outPath, true);true的意思是,就算output有東西,也一帶刪除,預設爲true
}
// 5設定輸入輸出數據路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, outPath);
// 6提交job
job.waitForCompletion(true);
}
}
3.1.6.4 自定義InputFormat
無論HDFS還是MapReduce,在處理小檔案時效率都非常低,但又難免面臨處理大量小檔案的場景,此時,就可以自定義InputFormat實現小檔案的合併。
-
需求
將多個小檔案合併成一個SequenceFile檔案(SequenceFile檔案是Hadoop用來儲存二進制形式的key-value對的檔案格式),SequenceFile裏面儲存着多個檔案,儲存的形式爲檔案路徑+名稱爲key,檔案內容爲value。 -
程式實現
(1)自定義InputFromat
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
// 定義類繼承FileInputFormat
public class WholeFileInputformat extends FileInputFormat<Text, BytesWritable>{
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
WholeRecordReader recordReader = new WholeRecordReader();
recordReader.initialize(split, context);
return recordReader;
}
}
(2)自定義RecordReader類
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class WholeRecordReader extends RecordReader<Text, BytesWritable>{
private Configuration configuration;
private FileSplit split;
private boolean isProgress= true;
private BytesWritable value = new BytesWritable();
private Text k = new Text();
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.split = (FileSplit)split;
configuration = context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (isProgress) {
// 1 定義快取區
byte[] contents = new byte[(int)split.getLength()];
FileSystem fs = null;
FSDataInputStream fis = null;
try {
// 2 獲取檔案系統
Path path = split.getPath();
fs = path.getFileSystem(configuration);
// 3 讀取數據
fis = fs.open(path);
// 4 讀取檔案內容
IOUtils.readFully(fis, contents, 0, contents.length);
// 5 輸出檔案內容
value.set(contents, 0, contents.length);
// 6 獲取檔案路徑及名稱
String name = split.getPath().toString();
// 7 設定輸出的key值
k.set(name);
} catch (Exception e) {
}finally {
IOUtils.closeStream(fis);
}
isProgress = false;
return true;
}
return false;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return k;
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
}
}
(3)編寫SequenceFileMapper類處理流程
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class SequenceFileMapper extends Mapper<Text, BytesWritable, Text, BytesWritable>{
@Override
protected void map(Text key, BytesWritable value,Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
(4)編寫SequenceFileReducer類處理流程
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SequenceFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable> {
@Override
protected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, values.iterator().next());
}
}
(5)編寫SequenceFileDriver類處理流程
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
public class SequenceFileDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設定
args = new String[] { "e:/input/inputinputformat", "e:/output1" };
// 1 獲取job物件
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 設定jar包儲存位置、關聯自定義的mapper和reducer
job.setJarByClass(SequenceFileDriver.class);
job.setMapperClass(SequenceFileMapper.class);
job.setReducerClass(SequenceFileReducer.class);
// 7設定輸入的inputFormat
job.setInputFormatClass(WholeFileInputformat.class);
// 8設定輸出的outputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 3 設定map輸出端的kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
// 4 設定最終輸出端的kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
// 5 設定輸入輸出路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.2 Shuffle機制 機製
3.2.1 Shuffle機制 機製
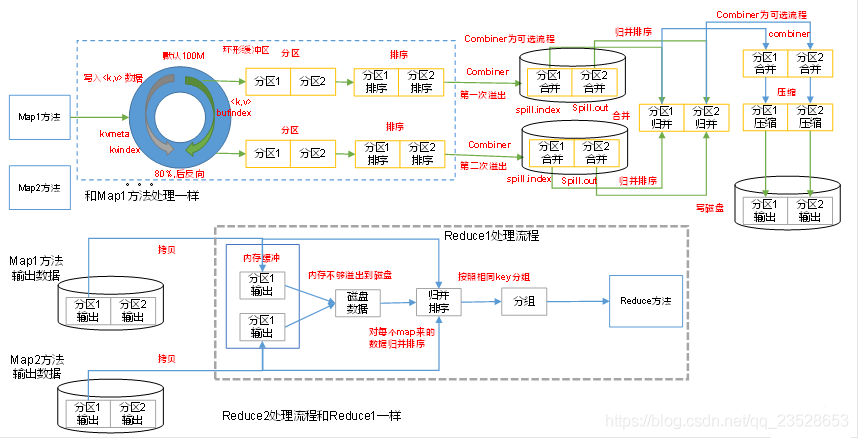
Map方法之後,Reduce方法之前的數據處理過程稱之爲Shuffle。
如圖3.4流程是整個MapReduce最全工作流程,但是Shuffle過程只是從第7步開始到第16步結束,具體Shuffle過程詳解,如下:
1)MapTask收集我們的map()方法輸出的kv對,放到記憶體緩衝區中
2)從記憶體緩衝區不斷溢位本地磁碟檔案,可能會溢位多個檔案
3)多個溢位檔案會被合併成大的溢位檔案
4)在溢位過程及合併的過程中,都要呼叫Partitioner進行分割區和針對key進行排序
5)ReduceTask根據自己的分割區號,去各個MapTask機器上取相應的結果分割區數據
6)ReduceTask會取到同一個分割區的來自不同MapTask的結果檔案,ReduceTask會將這些檔案再進行合併(歸併排序)
7)合併成大檔案後,Shuffle的過程也就結束了,後面進入ReduceTask的邏輯運算過程(從檔案中取出一個一個的鍵值對Group,呼叫使用者自定義的reduce()方法)
3. 注意
Shuffle中的緩衝區大小會影響到MapReduce程式的執行效率,原則上說,緩衝區越大,磁碟io的次數越少,執行速度就越快。
緩衝區的大小可以通過參數調整,參數:io.sort.mb預設100M。
4. 原始碼解析流程
context.write(k, NullWritable.get());
output.write(key, value);
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner();
collect()
close()
collect.flush()
sortAndSpill()
sort() QuickSort
mergeParts();
collector.close();
3.2.2 Partition分割區
1、問題引出
要求將統計結果按照條件輸出到不同檔案中(分割區)。比如:將統計結果按照手機歸屬地不同省份輸出到不同檔案中(分割區)
2、預設Partitioner分割區
public class Hash Partitioner<K, v>extends Partitioner<K, v>{
public int getPartition(K key, V value, int numReduceTasks) {
return(key.hashCode() & Integer.MAXVALUE) % numReduceTasks;
}
}
預設分割區是根據key的hashCode對ReduceTasks個數取模得到的。使用者沒法控制哪個key儲存到哪個分割區。
3、自定義Partitioner步驟
(1) 自定義類繼承Parttioner, 重寫getPariion() 方法
public class CustomPartitioner extends Partitioner<Text, FlowBean>{
@override
public int getPartition(Text key, Flow Beanvalue, int numPartitions) {
//控制分割區程式碼邏輯
.....
return partition;
}
}
(2) 在Job驅動中, 設定自定義Partitioner
job.setPartitionerClass(CustomParttioner.class);
(3) 自定義Partition後, 要根據自定義Partitioner的邏輯設定相應數量的ReduceTask
job.setNumReduceTasks(5);
4、分割區總結
(1) 如果ReduceTask的數量>getParttion的結果數, 則會多產生幾個空的輸出檔案part-r-000xx;
(2) 如果1<ReduceTask的數量<getPartition的結果數, 則有一部分分割區數據無處安放, 會Exception;
(3) 如果ReduceTask的數量=1, 則不管MapTask端輸出多少個分割區檔案, 最終結果都交給這一個ReduceTask, 最終也就只會產生一個結果檔案part-r-00000;
(4)分割區號必須從零開始,逐一累加。
例如:假設自定義分割區數爲5,則
(1) job.setNumReduceTasks(1) ;會正常執行,只不過會產生一個輸出檔案
(2) job.setNumReduceTasks(2) ;會報錯
(3) job.setNumReduceTasks(6) ; 大於5,程式會正常執行,會產生空檔案
5、 Partition分割區例
-
需求
將統計結果按照手機歸屬地不同省份輸出到不同檔案中(分割區)
手機號136、137、138、139開頭都分別放到一個獨立的4個檔案中,其他開頭的放到一個檔案中。 -
在序列化例子的基礎上,增加一個分割區類
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 1 獲取電話號碼的前三位
String preNum = key.toString().substring(0, 3);
int partition = 4;
// 2 判斷是哪個省
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
}
在驅動函數中增加自定義數據分割區設定和ReduceTask設定
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowsumDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設定
args = new String[]{"e:/output1","e:/output2"};
// 1 獲取設定資訊,或者job物件範例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程式的jar包所在的本地路徑
job.setJarByClass(FlowsumDriver.class);
// 3 指定本業務job要使用的mapper/Reducer業務類
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 4 指定mapper輸出數據的kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 5 指定最終輸出的數據的kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 8 指定自定義數據分割區
job.setPartitionerClass(ProvincePartitioner.class);
// 9 同時指定相應數量的reduce task
job.setNumReduceTasks(5);
// 6 指定job的輸入原始檔案所在目錄
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 將job中設定的相關參數,以及job所用的java類所在的jar包, 提交給yarn去執行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.2.3 WritableComparable排序
3.2.3.1 WritableComparable排序種類
- 排序的分類
-
排序是MapReduce框架中最重要的操作之一。MapTask和ReduceTask均會對數據按照key進行排序。該操作屬於Hadoop的預設行爲。任何應用程式中的數據均會被排序, 而不管邏輯上是否需要。
-
預設排序是按照字典順序排序,且實現該排序的方法是快速排序。
-
對於MapTask, 它會將處理的結果暫時放到環形緩衝區中, 當環形緩衝區使用率達到一定閾值後,再對緩衝區中的數據進行一次快速排序,並將這些有序數據溢寫到磁碟上,而當數據處理完畢後,它會對磁碟上所有檔案進行歸併排序。
-
對於ReduceTask, 它從每個MapTask上遠端拷貝相應的數據檔案, 如果檔案大小超過一定閾值,則溢寫磁碟上,否則儲存在記憶體中。如果磁碟上檔案數目達到一定閾值,則進行一次歸併排序以生成一個更大檔案;如果記憶體中檔案大小或者數目超過一定閾值,則進行一次合併後將數據溢寫到磁碟上。當所有數據拷貝完畢後, ReduceTask統一對記憶體和磁碟上的所有數據進行一次歸併排序。
- 自定義排序WritableComparable
(1)原理分析
bean物件做爲key傳輸,需要實現WritableComparable介面重寫compareTo方法,就可以實現排序。
@Override
public int compareTo(FlowBean o) {
int result;
// 按照總流量大小,倒序排列
if (sumFlow > bean.getSumFlow()) {
result = -1;
}else if (sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
3.2.3.2 WritableComparable排序案例
- 全排序
根據序列化案例實操產生的結果再次對總流量進行排序。
(1)FlowBean物件在在需求1基礎上增加了比較功能
package com.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean>{
private long upFlow;
private long downFlow;
private long sumFlow;
// 反序列化時,需要反射呼叫空參建構函式,所以必須有
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
/**
* 序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化方法 注意反序列化的順序和序列化的順序完全一致
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
@Override
public int compareTo(FlowBean o) {
int result;
// 按照總流量大小,倒序排列
System.out.println("sumFlow:" + sumFlow +" o.getSumFlow():"+o.getSumFlow());
if (sumFlow > o.getSumFlow()) {
result = -1;
}else if (sumFlow < o.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
}
(2)編寫Mapper類
package com.WritableComparable;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowCountSortMapper extends Mapper<LongWritable, Text, FlowBean, Text>{
FlowBean bean = new FlowBean();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 獲取一行
String line = value.toString();
// 2 擷取
String[] fields = line.split(" ");
// 3 封裝物件
String phoneNbr = fields[0];
long upFlow = Long.parseLong(fields[1]);
long downFlow = Long.parseLong(fields[2]);
bean.set(upFlow, downFlow);
v.set(phoneNbr);
System.out.println("mapper key:" + bean +" value:"+v);
// 4 輸出
context.write(bean, v);
}
}
(3)編寫Reducer類
package com.WritableComparable;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowCountSortReducer extends Reducer<FlowBean, Text, Text, FlowBean>{
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 回圈輸出,避免總流量相同情況
for (Text text : values) {
System.out.println("reduce key:" + text +" value:"+key);
context.write(text, key);
}
}
}
(4)編寫Driver類
package com.WritableComparable;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowCountSortDriver {
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
// 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設定
args = new String[] { "D:\\Users\\Administrator\\Desktop\\FlowCountSortDriver.txt", "hdfs://spark1:9000/out" };
// 1 獲取設定資訊,或者job物件範例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程式的jar包所在的本地路徑
job.setJarByClass(FlowCountSortDriver.class);
// 3 指定本業務job要使用的mapper/Reducer業務類
job.setMapperClass(FlowCountSortMapper.class);
job.setReducerClass(FlowCountSortReducer.class);
// 4 指定mapper輸出數據的kv型別
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
// 5 指定最終輸出的數據的kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
Path outPath = new Path(args[1]);// 輸出路徑
FileSystem fs = outPath.getFileSystem(configuration);// 根據輸出路徑找到檔案,參數爲組態檔
if (fs.exists(outPath)) {
fs.delete(outPath);
// fs.delete(outPath, true);true的意思是,就算output有東西,也一帶刪除,預設爲true
}
// 6 指定job的輸入原始檔案所在目錄
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, outPath);
// 7 將job中設定的相關參數,以及job所用的java類所在的jar包, 提交給yarn去執行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
- 區內排序
要求每個省份手機號輸出的檔案中按照總流量內部排序。
基於前一個需求,增加自定義分割區類,分割區按照省份手機號設定。
(1)增加自定義分割區類
package com.atguigu.mapreduce.sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<FlowBean, Text> {
@Override
public int getPartition(FlowBean key, Text value, int numPartitions) {
// 1 獲取手機號碼前三位
String preNum = value.toString().substring(0, 3);
int partition = 4;
// 2 根據手機號歸屬地設定分割區
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
}
(2)在驅動類中新增分割區類
// 載入自定義分割區類
job.setPartitionerClass(ProvincePartitioner.class);
// 設定Reducetask個數
job.setNumReduceTasks(5);
3.2.4 Combiner合併
- 敘述
(1) Combiner是MR程式中Mapper和Reducer之外的一種元件。
(2) Combiner元件的父類別就是Reducer。
(3) Combiner和Reducer的區別在於執行的位置Combiner是在每一個MapTask所在的節點執行,Reducer是接收全域性所有Mapper的輸出結果。
(4) Combiner的意義就是對每一個MapTask的輸出進行區域性彙總, 以減小網路傳輸量。
(5) Combiner能夠應用的前提是不能影響最終的業務邏輯, 而且, Combiner的輸出kv應該跟Reducer的輸入kv型別要對應起來。
| Mapper | Reducer |
|---|---|
| 357->(3+5+7)/3=5 | (3+5+7+2+6)/5=23/5不等於(5+4)/2=9/2 |
| 26->(2+6)/2=4 |
(6)自定義Combiner實現步驟
(a)自定義一個Combiner繼承Reducer,重寫Reduce方法
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 彙總操作
int count = 0;
for(IntWritable v :values){
count += v.get();
}
// 2 寫出
context.write(key, new IntWritable(count));
}
}
(b)在Job驅動類中設定:
job.setCombinerClass(WordcountCombiner.class);
- Combiner合併案例
統計過程中對每一個MapTask的輸出進行區域性彙總,以減小網路傳輸量即採用Combiner功能。
期望:Combine輸入數據多,輸出時經過合併,輸出數據降低。
方法一
1)增加一個WordcountCombiner類繼承Reducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1 彙總
int sum = 0;
for(IntWritable value :values){
sum += value.get();
}
v.set(sum);
// 2 寫出
context.write(key, v);
}
}
2)在WordcountDriver驅動類中指定Combiner
// 指定需要使用combiner,以及用哪個類作爲combiner的邏輯
job.setCombinerClass(WordcountCombiner.class);
方法二
1)將WordcountReducer作爲Combiner在WordcountDriver驅動類中指定
// 指定需要使用Combiner,以及用哪個類作爲Combiner的邏輯
job.setCombinerClass(WordcountReducer.class);
3.2.5 GroupingComparator分組(輔助排序)
對Reduce階段的數據根據某一個或幾個欄位進行分組。
分組排序步驟:
(1)自定義類繼承WritableComparator
(2)重寫compare()方法
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 比較的業務邏輯
return result;
}
(3)建立一個構造將比較物件的類傳給父類別
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
案例
有如下訂單數據
| 訂單id | 商品id | 成交金額 |
|---|---|---|
| 0000001 | Pdt_01 | 222.8 |
| Pdt_02 | 33.8 | |
| 0000002 | Pdt_03 | 522.8 |
| Pdt_04 | 122.4 | |
| Pdt_05 | 722.4 | |
| 0000003 | Pdt_06 | 232.8 |
| Pdt_02 | 33.8 |
現在需要求出每一個訂單中最貴的商品。
期望輸出數據
1 222.8
2 722.4
3 232.8
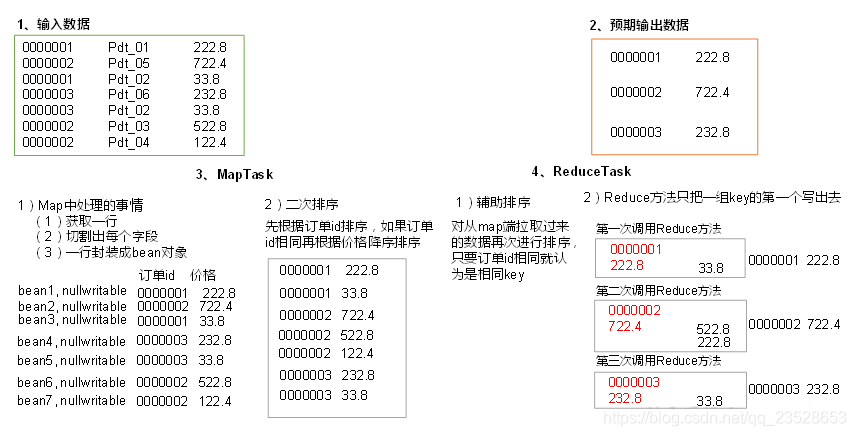
- 利用「訂單id和成交金額」作爲key,可以將Map階段讀取到的所有訂單數據按照id升序排序,如果id相同再按照金額降序排序,發送到Reduce。
- 在Reduce端利用groupingComparator將訂單id相同的kv聚合成組,然後取第一個即是該訂單中最貴商品。
(1)定義訂單資訊OrderBean類
package com.atguigu.mapreduce.order;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class OrderBean implements WritableComparable<OrderBean> {
private int order_id; // 訂單id號
private double price; // 價格
public OrderBean() {
super();
}
public OrderBean(int order_id, double price) {
super();
this.order_id = order_id;
this.price = price;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeDouble(price);
}
@Override
public void readFields(DataInput in) throws IOException {
order_id = in.readInt();
price = in.readDouble();
}
@Override
public String toString() {
return order_id + "\t" + price;
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
// 二次排序
@Override
public int compareTo(OrderBean o) {
int result;
if (order_id > o.getOrder_id()) {
result = 1;
} else if (order_id < o.getOrder_id()) {
result = -1;
} else {
// 價格倒序排序
result = price > o.getPrice() ? -1 : 1;
}
return result;
}
}
(2)編寫OrderSortMapper類
package com.atguigu.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 獲取一行
String line = value.toString();
// 2 擷取
String[] fields = line.split("\t");
// 3 封裝物件
k.setOrder_id(Integer.parseInt(fields[0]));
k.setPrice(Double.parseDouble(fields[2]));
// 4 寫出
context.write(k, NullWritable.get());
}
}
(3)編寫OrderSortGroupingComparator類
package com.atguigu.mapreduce.order;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderGroupingComparator extends WritableComparator {
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
}
return result;
}
}
(4)編寫OrderSortReducer類
package com.atguigu.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
(5)編寫OrderSortDriver類
package com.atguigu.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OrderDriver {
public static void main(String[] args) throws Exception, IOException {
// 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設定
args = new String[]{"e:/input/inputorder" , "e:/output1"};
// 1 獲取設定資訊
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 設定jar包載入路徑
job.setJarByClass(OrderDriver.class);
// 3 載入map/reduce類
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// 4 設定map輸出數據key和value型別
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
// 5 設定最終輸出數據的key和value型別
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 設定輸入數據和輸出數據路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 8 設定reduce端的分組
job.setGroupingComparatorClass(OrderGroupingComparator.class);
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.3 OutputFormat數據輸出
OutputFormat是MapReduce輸出的基礎類別, 所有實現MapReduce輸出都實現了OutputFormat介面。下面 下麪我們介紹幾種常見的OutputFormat實現類。
- 文字輸出TextOutputFormat
預設的輸出格式是TextOutputFormat, 它把每條記錄寫爲文字行。它的鍵和值可以是任意型別, 因爲TextOutputFormat呼叫toString()方法把它們轉換爲字串。 - SequenceFileOutputFormat
將SequenceFileOutputFormat輸出作爲後續MapReduce任務的輸入, 這便是一種好的輸出格式,因爲它的格式緊湊,很容易被壓縮。 - 自定義Output Format
根據使用者需求,自定義實現輸出。
(1)自定義一個類繼承FileOutputFormat。
(2)改寫RecordWriter, 具體改寫輸出數據的方法write() 。
自定義OutputFormat案例
過濾輸入的log日誌,包含atguigu的網站輸出到e:/atguigu.log,不包含atguigu的網站輸出到e:/other.log。
(1)編寫FilterMapper類
package com.OutputFormat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FilterMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 寫出
context.write(value, NullWritable.get());
}
}
(2)編寫FilterReducer類
package com.OutputFormat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FilterReducer extends Reducer<Text, NullWritable, Text, NullWritable>{
Text k = new Text();
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// 1 獲取一行
String line = key.toString();
// 2 拼接
line = line + "\r\n";
// 3 設定key
k.set(line);
// 4 輸出
context.write(k, NullWritable.get());
}
}
(3)自定義一個OutputFormat類
package com.OutputFormat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FilterOutputFormat extends FileOutputFormat<Text, NullWritable>{
@Override
public org.apache.hadoop.mapreduce.RecordWriter<Text, NullWritable> getRecordWriter(
org.apache.hadoop.mapreduce.TaskAttemptContext job) throws IOException, InterruptedException {
// 建立一個RecordWriter
return new FilterRecordWriter(job);
}
}
(4)編寫RecordWriter類
package com.OutputFormat;
import java.io.IOException;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
public class FilterRecordWriter extends RecordWriter<Text, NullWritable> {
FSDataOutputStream atguiguOut = null;
FSDataOutputStream otherOut = null;
public FilterRecordWriter(TaskAttemptContext job) {
// 1 獲取檔案系統
FileSystem fs;
try {
fs = FileSystem.get(job.getConfiguration());
// 2 建立輸出檔案路徑
Path atguiguPath = new Path("e:/atguigu.log");
Path otherPath = new Path("e:/other.log");
// 3 建立輸出流
atguiguOut = fs.create(atguiguPath);
otherOut = fs.create(otherPath);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
// 判斷是否包含「atguigu」輸出到不同檔案
if (key.toString().contains("atguigu")) {
atguiguOut.write(key.toString().getBytes());
} else {
otherOut.write(key.toString().getBytes());
}
}
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
// 關閉資源
IOUtils.closeStream(atguiguOut);
IOUtils.closeStream(otherOut);
}
}
(5)編寫FilterDriver類
package com.OutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FilterDriver {
public static void main(String[] args) throws Exception {
// 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設定
args = new String[] { "D:\\Users\\Administrator\\Desktop\\FilterDriver.txt", "hdfs://spark1:9000/out" };
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FilterDriver.class);
job.setMapperClass(FilterMapper.class);
job.setReducerClass(FilterReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 要將自定義的輸出格式元件設定到job中
job.setOutputFormatClass(FilterOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
Path outPath = new Path(args[1]);// 輸出路徑
FileSystem fs = outPath.getFileSystem(conf);// 根據輸出路徑找到檔案,參數爲組態檔
if (fs.exists(outPath)) {
fs.delete(outPath);
// fs.delete(outPath, true);true的意思是,就算output有東西,也一帶刪除,預設爲true
}
// 雖然我們自定義了outputformat,但是因爲我們的outputformat繼承自fileoutputformat
// 而fileoutputformat要輸出一個_SUCCESS檔案,所以,在這還得指定一個輸出目錄
FileOutputFormat.setOutputPath(job,outPath);
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.4 MapReduce工作機制 機製
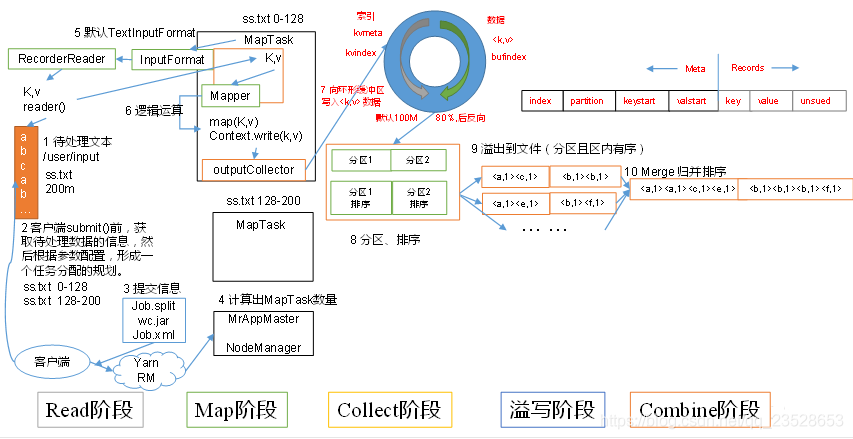
3.4.1 MapTask工作機制 機製
MapTask工作機制 機製如圖所示。
MapTask工作機制 機製
(1)Read階段:MapTask通過使用者編寫的RecordReader,從輸入InputSplit中解析出一個個key/value。
(2)Map階段:該節點主要是將解析出的key/value交給使用者編寫map()函數處理,併產生一系列新的key/value。
(3)Collect收集階段:在使用者編寫map()函數中,當數據處理完成後,一般會呼叫OutputCollector.collect()輸出結果。在該函數內部,它會將生成的key/value分割區(呼叫Partitioner),並寫入一個環形記憶體緩衝區中。
(4)Spill階段:即「溢寫」,當環形緩衝區滿後,MapReduce會將數據寫到本地磁碟上,生成一個臨時檔案。需要注意的是,將數據寫入本地磁碟之前,先要對數據進行一次本地排序,並在必要時對數據進行合併、壓縮等操作。
溢寫階段詳情:
步驟1:利用快速排序演算法對快取區內的數據進行排序,排序方式是,先按照分割區編號Partition進行排序,然後按照key進行排序。這樣,經過排序後,數據以分割區爲單位聚集在一起,且同一分割區內所有數據按照key有序。
步驟2:按照分割區編號由小到大依次將每個分割區中的數據寫入任務工作目錄下的臨時檔案output/spillN.out(N表示當前溢寫次數)中。如果使用者設定了Combiner,則寫入檔案之前,對每個分割區中的數據進行一次聚集操作。
步驟3:將分割區數據的元資訊寫到記憶體索引數據結構SpillRecord中,其中每個分割區的元資訊包括在臨時檔案中的偏移量、壓縮前數據大小和壓縮後數據大小。如果當前記憶體索引大小超過1MB,則將記憶體索引寫到檔案output/spillN.out.index中。
(5)Combine階段:當所有數據處理完成後,MapTask對所有臨時檔案進行一次合併,以確保最終只會生成一個數據檔案。
當所有數據處理完後,MapTask會將所有臨時檔案合併成一個大檔案,並儲存到檔案output/file.out中,同時生成相應的索引檔案output/file.out.index。
在進行檔案合併過程中,MapTask以分割區爲單位進行合併。對於某個分割區,它將採用多輪遞回合併的方式。每輪合併io.sort.factor(預設10)個檔案,並將產生的檔案重新加入待合併列表中,對檔案排序後,重複以上過程,直到最終得到一個大檔案。
讓每個MapTask最終只生成一個數據檔案,可避免同時開啓大量檔案和同時讀取大量小檔案產生的隨機讀取帶來的開銷。
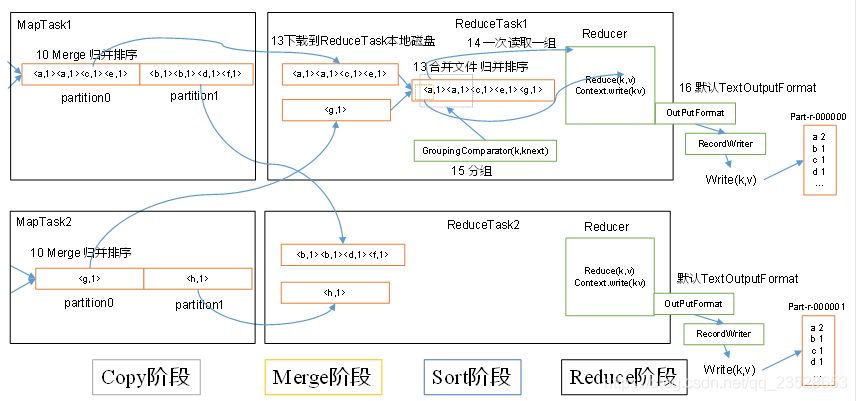
3.4.2 ReduceTask工作機制 機製
ReduceTask工作機制 機製,如圖所示。
- ReduceTask工作機制 機製
(1)Copy階段:ReduceTask從各個MapTask上遠端拷貝一片數據,並針對某一片數據,如果其大小超過一定閾值,則寫到磁碟上,否則直接放到記憶體中。
(2)Merge階段:在遠端拷貝數據的同時,ReduceTask啓動了兩個後臺執行緒對記憶體和磁碟上的檔案進行合併,以防止記憶體使用過多或磁碟上檔案過多。
(3)Sort階段:按照MapReduce語意,使用者編寫reduce()函數輸入數據是按key進行聚集的一組數據。爲了將key相同的數據聚在一起,Hadoop採用了基於排序的策略。由於各個MapTask已經實現對自己的處理結果進行了區域性排序,因此,ReduceTask只需對所有數據進行一次歸併排序即可。
(4)Reduce階段:reduce()函數將計算結果寫到HDFS上。 - 設定ReduceTask並行度(個數)
ReduceTask的並行度同樣影響整個Job的執行併發度和執行效率,但與MapTask的併發數由切片數決定不同,ReduceTask數量的決定是可以直接手動設定:
// 預設值是1,手動設定爲4
job.setNumReduceTasks(4); - 測試ReduceTask多少合適
(1)實驗環境:1個Master節點,16個Slave節點:CPU:8GHZ,記憶體: 2G
(2)實驗結論:ReduceTask (數據量爲1GB)
MapTask =16
| ReduceTask | 1 | 5 | 10 | 15 | 16 | 20 | 25 | 30 | 45 | 60 |
|---|---|---|---|---|---|---|---|---|---|---|
| 總時間 | 892 | 146 | 110 | 92 | 88 | 100 | 128 | 101 | 145 | 104 |
- 注意事項
(1) ReduceTask=0, 表示沒有Reduce階段, 輸出檔案個數和Map個數一致。
(2) ReduceTask預設值就是1, 所以輸出檔案個數爲一個。
(3) 如果數據分佈不均勻, 就有可能在Reduce階段產生數據傾斜
(4) ReduceTask數量並不是任意設定, 還要考慮業務邏輯需求, 有些情況下, 需要計算全域性彙總結果, 就只能有1個ReduceTask
(5) 具體多少個ReduceTask, 需要根據叢集效能而定。
(6) 如果分割區數不是1, 但是ReduceTask爲1, 是否執行分割區過程。答案是:不執行分割區過程。因爲在MapTask的原始碼中, 執行分割區的前提是先判斷ReduceNum個數是否大於1,不大於1肯定不執行。
3.5 Join多種應用
- Map端的主要工作:爲來自不同表或檔案的key/value對, 打標籤以區別不同來源的記錄。然後用連線欄位作爲key, 其餘部分和新加的標誌作爲value, 最後進行輸出。
- Reduce端的主要工作:在Reduce端以連線欄位作爲key的分組已經完成, 我們只需要在每一個分組當中將那些來源於不同檔案的記錄(在Map階段已經打標誌)分開,最後進行合併就ok了。
3.5.1 ReduceJoin案例
1、需求
訂單數據表t_order
| id | pid | amount |
|---|---|---|
| 1001 | 01 | 1 |
| 1002 | 02 | 2 |
| 1003 | 03 | 3 |
| 1004 | 01 | 4 |
| 1005 | 02 | 5 |
| 1006 | 03 | 6 |
商品資訊表t_product
| pid | pname |
|---|---|
| 01 | 小米 |
| 02 | 華爲 |
| 03 | 格力 |
將商品資訊表中數據根據商品pid合併到訂單數據表中。
最終數據形式
| id | pname | amount |
|---|---|---|
| 1001 | 小米 | 1 |
| 1004 | 小米 | 4 |
| 1002 | 華爲 | 2 |
| 1005 | 華爲 | 5 |
| 1003 | 格力 | 3 |
| 1006 | 格力 | 6 |
2、需求分析
通過將關聯條件作爲Map輸出的key,將兩表滿足Join條件的數據並攜帶數據所來源的檔案資訊,發往同一個ReduceTask,在Reduce中進行數據的串聯。
3、程式碼實現
1)建立商品和訂合併後的Bean類
package com.atguigu.mapreduce.table;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class TableBean implements Writable {
private String order_id; // 訂單id
private String p_id; // 產品id
private int amount; // 產品數量
private String pname; // 產品名稱
private String flag; // 表的標記
public TableBean() {
super();
}
public TableBean(String order_id, String p_id, int amount, String pname, String flag) {
super();
this.order_id = order_id;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.flag = flag;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
public String getOrder_id() {
return order_id;
}
public void setOrder_id(String order_id) {
this.order_id = order_id;
}
public String getP_id() {
return p_id;
}
public void setP_id(String p_id) {
this.p_id = p_id;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(order_id);
out.writeUTF(p_id);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.order_id = in.readUTF();
this.p_id = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.flag = in.readUTF();
}
@Override
public String toString() {
return order_id + "\t" + pname + "\t" + amount + "\t" ;
}
}
2)編寫TableMapper類
package com.atguigu.mapreduce.table;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean>{
String name;
TableBean bean = new TableBean();
Text k = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 1 獲取輸入檔案切片
FileSplit split = (FileSplit) context.getInputSplit();
// 2 獲取輸入檔名稱
name = split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 獲取輸入數據
String line = value.toString();
// 2 不同檔案分別處理
if (name.startsWith("order")) {// 訂單表處理
// 2.1 切割
String[] fields = line.split("\t");
// 2.2 封裝bean物件
bean.setOrder_id(fields[0]);
bean.setP_id(fields[1]);
bean.setAmount(Integer.parseInt(fields[2]));
bean.setPname("");
bean.setFlag("order");
k.set(fields[1]);
}else {// 產品表處理
// 2.3 切割
String[] fields = line.split("\t");
// 2.4 封裝bean物件
bean.setP_id(fields[0]);
bean.setPname(fields[1]);
bean.setFlag("pd");
bean.setAmount(0);
bean.setOrder_id("");
k.set(fields[0]);
}
// 3 寫出
context.write(k, bean);
}
}
3)編寫TableReducer類
package com.atguigu.mapreduce.table;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> {
@Override
protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException {
// 1準備儲存訂單的集合
ArrayList<TableBean> orderBeans = new ArrayList<>();
// 2 準備bean物件
TableBean pdBean = new TableBean();
for (TableBean bean : values) {
if ("order".equals(bean.getFlag())) {// 訂單表
// 拷貝傳遞過來的每條訂單數據到集閤中
TableBean orderBean = new TableBean();
try {
BeanUtils.copyProperties(orderBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
orderBeans.add(orderBean);
} else {// 產品表
try {
// 拷貝傳遞過來的產品表到記憶體中
BeanUtils.copyProperties(pdBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
}
}
// 3 表的拼接
for(TableBean bean:orderBeans){
bean.setPname (pdBean.getPname());
// 4 數據寫出去
context.write(bean, NullWritable.get());
}
}
}
4)編寫TableDriver類
package com.atguigu.mapreduce.table;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TableDriver {
public static void main(String[] args) throws Exception {
// 0 根據自己電腦路徑重新設定
args = new String[]{"e:/input/inputtable","e:/output1"};
// 1 獲取設定資訊,或者job物件範例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程式的jar包所在的本地路徑
job.setJarByClass(TableDriver.class);
// 3 指定本業務job要使用的Mapper/Reducer業務類
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
// 4 指定Mapper輸出數據的kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TableBean.class);
// 5 指定最終輸出的數據的kv型別
job.setOutputKeyClass(TableBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 指定job的輸入原始檔案所在目錄
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 將job中設定的相關參數,以及job所用的java類所在的jar包, 提交給yarn去執行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
2020-08-10 10:57:17,561 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2020-08-10 10:57:17,570 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2020-08-10 10:57:17,588 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2020-08-10 10:57:17,594 WARN [org.apache.hadoop.mapred.LocalJobRunner] - job_local1090202339_0001
java.lang.Exception: java.lang.ClassCastException: org.apache.hadoop.mapreduce.lib.input.FileSplit cannot be cast to org.apache.hadoop.mapred.FileSplit
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522)
Caused by: java.lang.ClassCastException: org.apache.hadoop.mapreduce.lib.input.FileSplit cannot be cast to org.apache.hadoop.mapred.FileSplit
at com.ReduceJoin.TableMapper.setup(TableMapper.java:25)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:143)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2020-08-10 10:57:17,821 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1090202339_0001 running in uber mode : false
2020-08-10 10:57:17,824 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%
2020-08-10 10:57:17,829 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1090202339_0001 failed with state FAILED due to: NA
2020-08-10 10:57:17,840 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 0
4.測試
執行程式檢視結果
1001 小米 1
1001 小米 1
1002 華爲 2
1002 華爲 2
1003 格力 3
1003 格力 3
5.總結
缺點:這種方式中, 合併的操作是在Reduce階段完成, Reduce端的處理壓力太大, Map節點的運算負載則很低, 資源利用率不高, 且在Reduce階段極易產生數據傾斜。
解決方案:Map端實現數據合併。
3.5.2 MapJoin
1.使用場景
Map Join適用於一張表十分小、一張表很大的場景。
2.優點
在Map端快取多張表,提前處理業務邏輯,這樣增加Map端業務,減少Reduce端數據的壓力,儘可能的減少數據傾斜。
3.具體辦法:採用DistributedCache
(1)在Mapper的setup階段,將檔案讀取到快取集閤中。
(2)在驅動函數中載入快取。
// 快取普通檔案到Task執行節點。
job.addCacheFile(new URI(「file://e:/cache/pd.txt」));
實現程式碼
(1)先在驅動模組中新增快取檔案
package test;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DistributedCacheDriver {
public static void main(String[] args) throws Exception {
// 0 根據自己電腦路徑重新設定
args = new String[]{"e:/input/inputtable2", "e:/output1"};
// 1 獲取job資訊
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 設定載入jar包路徑
job.setJarByClass(DistributedCacheDriver.class);
// 3 關聯map
job.setMapperClass(DistributedCacheMapper.class);
// 4 設定最終輸出數據型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 設定輸入輸出路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 載入快取數據
job.addCacheFile(new URI("file:///e:/input/inputcache/pd.txt"));
// 7 Map端Join的邏輯不需要Reduce階段,設定reduceTask數量爲0
job.setNumReduceTasks(0);
// 8 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
(2)讀取快取的檔案數據
package test;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Map<String, String> pdMap = new HashMap<>();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 1 獲取快取的檔案
URI[] cacheFiles = context.getCacheFiles();
String path = cacheFiles[0].getPath().toString();
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8"));
String line;
while(StringUtils.isNotEmpty(line = reader.readLine())){
// 2 切割
String[] fields = line.split("\t");
// 3 快取數據到集合
pdMap.put(fields[0], fields[1]);
}
// 4 關流
reader.close();
}
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 獲取一行
String line = value.toString();
// 2 擷取
String[] fields = line.split("\t");
// 3 獲取產品id
String pId = fields[1];
// 4 獲取商品名稱
String pdName = pdMap.get(pId);
// 5 拼接
k.set(line + "\t"+ pdName);
// 6 寫出
context.write(k, NullWritable.get());
}
}
3.6 計數器應用
Hadoop爲每個作業維護若幹內建計數器, 以描述多項指標。例如, 某些計數器記錄已處理的位元組數和記錄數,使使用者可監控已處理的輸入數據量和已產生的輸出數據量.
1.計數器API
(1)採用列舉的方式統計計數
enum My Counter(MALFORORMED,NORMAL)
//對列舉定義的自定義計數器加1
context.get Counter(MyCounter.MALFORORMED) increment(1);
(2)採用計數器組、計數器名稱的方式統計
context.get Counter(」counterGroup」, 」counter」) .increment(1);
組名和計數器名稱隨便起,但最好有意義。
(3)計數結果在程式執行後的控制檯上檢視。
計數器案例詳見數據清洗案例。
3.7 數據清洗(ETL)
在執行核心業務MapReduce程式之前,往往要先對數據進行清洗,清理掉不符合使用者要求的數據。清理的過程往往只需要執行Mapper程式,不需要執行Reduce程式。
- 數據清洗案例實操-簡單解析版
去除日誌中欄位長度小於等於11的日誌。每行欄位長度都大於11。需要在Map階段對輸入的數據根據規則進行過濾清洗。
實現程式碼
(1)編寫LogMapper類
package com.atguigu.mapreduce.weblog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 獲取1行數據
String line = value.toString();
// 2 解析日誌
boolean result = parseLog(line,context);
// 3 日誌不合法退出
if (!result) {
return;
}
// 4 設定key
k.set(line);
// 5 寫出數據
context.write(k, NullWritable.get());
}
// 2 解析日誌
private boolean parseLog(String line, Context context) {
// 1 擷取
String[] fields = line.split(" ");
// 2 日誌長度大於11的爲合法
if (fields.length > 11) {
// 系統計數器
context.getCounter("map", "true").increment(1);
return true;
}else {
context.getCounter("map", "false").increment(1);
return false;
}
}
}
(2)編寫LogDriver類
package com.atguigu.mapreduce.weblog;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
// 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設定
args = new String[] { "e:/input/inputlog", "e:/output1" };
// 1 獲取job資訊
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 載入jar包
job.setJarByClass(LogDriver.class);
// 3 關聯map
job.setMapperClass(LogMapper.class);
// 4 設定最終輸出型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 設定reducetask個數爲0
job.setNumReduceTasks(0);
// 5 設定輸入和輸出路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
job.waitForCompletion(true);
}
}
- 數據清洗案例實操-複雜解析版
對Web存取日誌中的各欄位識別切分,去除日誌中不合法的記錄。根據清洗規則,輸出過濾後的數據。
實現程式碼
(1)定義一個bean,用來記錄日誌數據中的各數據欄位
package com.atguigu.mapreduce.log;
public class LogBean {
private String remote_addr;// 記錄用戶端的ip地址
private String remote_user;// 記錄用戶端使用者名稱稱,忽略屬性"-"
private String time_local;// 記錄存取時間與時區
private String request;// 記錄請求的url與http協定
private String status;// 記錄請求狀態;成功是200
private String body_bytes_sent;// 記錄發送給用戶端檔案主體內容大小
private String http_referer;// 用來記錄從那個頁面鏈接存取過來的
private String http_user_agent;// 記錄客戶瀏覽器的相關資訊
private boolean valid = true;// 判斷數據是否合法
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.valid);
sb.append("\001").append(this.remote_addr);
sb.append("\001").append(this.remote_user);
sb.append("\001").append(this.time_local);
sb.append("\001").append(this.request);
sb.append("\001").append(this.status);
sb.append("\001").append(this.body_bytes_sent);
sb.append("\001").append(this.http_referer);
sb.append("\001").append(this.http_user_agent);
return sb.toString();
}
}
(2)編寫LogMapper類
package com.atguigu.mapreduce.log;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 獲取1行
String line = value.toString();
// 2 解析日誌是否合法
LogBean bean = parseLog(line);
if (!bean.isValid()) {
return;
}
k.set(bean.toString());
// 3 輸出
context.write(k, NullWritable.get());
}
// 解析日誌
private LogBean parseLog(String line) {
LogBean logBean = new LogBean();
// 1 擷取
String[] fields = line.split(" ");
if (fields.length > 11) {
// 2封裝數據
logBean.setRemote_addr(fields[0]);
logBean.setRemote_user(fields[1]);
logBean.setTime_local(fields[3].substring(1));
logBean.setRequest(fields[6]);
logBean.setStatus(fields[8]);
logBean.setBody_bytes_sent(fields[9]);
logBean.setHttp_referer(fields[10]);
if (fields.length > 12) {
logBean.setHttp_user_agent(fields[11] + " "+ fields[12]);
}else {
logBean.setHttp_user_agent(fields[11]);
}
// 大於400,HTTP錯誤
if (Integer.parseInt(logBean.getStatus()) >= 400) {
logBean.setValid(false);
}
}else {
logBean.setValid(false);
}
return logBean;
}
}
(3)編寫LogDriver類
package com.atguigu.mapreduce.log;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
// 1 獲取job資訊
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 載入jar包
job.setJarByClass(LogDriver.class);
// 3 關聯map
job.setMapperClass(LogMapper.class);
// 4 設定最終輸出型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 設定輸入和輸出路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
job.waitForCompletion(true);
}
}
3.8 MapReduce開發總結
在編寫MapReduce程式時,需要考慮如下幾個方面:
-
輸入數據介面:InputFormat
(1) 預設使用的實現類是:TextInputFormat
(2) TextInputFormat的功能邏輯是:一次讀一行文字, 然後將該行的起始偏移量作爲key, 行內容作爲value返回。
(3) KeyValueTextInputFormat每一行均爲一條記錄, 被分隔符分割爲key,value。預設分隔符是tab(\t) 。
(4) NlineInputFormat按照指定的行數N來劃分切片。
(5) CombineTextInputFormat可以把多個小檔案合併成一個切片處理, 提高處理效率。
(6) 使用者還可以自定義InputFormat。 -
邏輯處理介面:Mapper
使用者根據業務需求實現其中三個方法:map();setup();cleanup() -
Partitioner分割區
(1)有預設實現
HashPartitioner, 邏輯是根據key的雜湊值和numReduces來返回一個分割區號;
key.hashCode() & Integer.MAXVALUE % numReduces
(2)如果業務上有特別的需求,可以自定義分割區。 -
Comparable排序
(1) 當我們用自定義的物件作爲key來輸出時, 就必須要實現WritableComparable介面, 重寫其中的compareTo()方法。
(2)部分排序:對最終輸出的每一個檔案進行內部排序。
(3) 全排序:對所有數據進行排序, 通常只有一個Reduce。
(4)二次排序:排序的條件有兩個。 -
Combiner合併
Combiner合併可以提高程式執行效率, 減少IO傳輸。但是使用時必須不能影響原有的業務處理結果。 -
Reduce端分組:Grouping Comparator
在Reduce端對key進行分組。應用於:在接收的key爲bean物件時, 想讓一個或幾個欄位相同(全部欄位比較不相同) 的key進入到同一個reduce方法時, 可以採用分組排序。 -
邏輯處理介面:Reducer
使用者根據業務需求實現其中三個方法:reduce() setup() cleanup() -
輸出數據介面:OutputFormat
(1) 預設實現類是TextOutputFormat, 功能邏輯是:將每一個KV對, 向目標文字檔案輸出一行。
(2) 將SequenceFileOutputFormat輸出作爲後續MapReduce任務的輸入, 這便是一種好的輸出格式,因爲它的格式緊湊,很容易被壓縮。
(3) 使用者還可以自定義Output Format。
四、Hadoop數據壓縮
4.1 概述
- 壓縮技術能夠有效減少底層儲存系統(HDFS) 讀寫位元組數。壓縮提高了網鑑於磁碟I/O和網路頻寬是Hadoop的寶貴資源, 數據壓縮對於節省資源、最絡頻寬和磁碟空間的效率。在執行MR程式時,I/O操作、網路數據傳輸、和Merge要花大量的時間, 尤其是數據規模很大和工作負載密集的情況下, 因此,使用數據壓縮顯得非常重要。小化磁碟I/O和網路傳輸非常有幫助。可以在任意Map Reduce階段啓用壓縮。不過, 儘管壓縮與解壓操作的CPU開銷不高, 其效能的提升和資源的節省並非沒有代價。
- 壓縮是提高Hadoop執行效率的一種優化策略。通過對Mapper、Reducer執行過程的數據進行壓縮, 以減少磁碟IO,提高MR程式執行速度。所以,壓縮特性運用得當能提高效能,但運用不當也可能降低效能。
注意:採用壓縮技術減少了磁碟IO, 但同時增加了CPU運算負擔。
壓縮基本原則:
(1) 運算密集型的job, 少用壓縮
(2) IO密集型的job, 多用壓縮
4.2 MR支援的壓縮編碼
| 壓縮格式 | hadoop自帶? | 演算法 | 副檔名 | 是否可切分 | 換成壓縮格式後,原來的程式是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文字處理一樣,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文字處理一樣,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文字處理一樣,不需要修改 |
| LZO | 否,需要安裝 | LZO | .lzo | 是 | 需要建索引,還需要指定輸入格式 |
| Snappy | 否,需要安裝 | Snappy | .snappy | 否 | 和文字處理一樣,不需要修改 |
爲了支援多種壓縮/解壓縮演算法,Hadoop引入了編碼/解碼器,如下表所示。
| 壓縮格式 | 對應的編碼/解碼器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
壓縮效能的比較
| 壓縮演算法 | 原始檔案大小 | 壓縮檔案大小 | 壓縮速度 | 解壓速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
http://google.github.io/snappy/
在64位元模式的CoreI7處理器的單核上,Snappy壓縮速度約爲250 MB/s或更高,解壓縮速度約爲500 MB/s或更高。
4.3 壓縮方式選擇
-
Gzip壓縮
優點:壓縮率比較高, 而且壓縮/解壓速度也比較快; Had oop本身支援, 在應用中處理Gzip格式的檔案就和直接處理文字一樣; 大部分Linux系統都自帶Gzip命令, 使用方便。
缺點:不支援Split。
應用場景:當每個檔案壓縮之後在130M以內的(1個塊大小內),都可以考慮用Gzip壓縮格式。例如說一天或者一個小時的日誌壓縮成一個Gzip檔案。 -
Bzip2壓縮
優點:支援Split; 具有很高的壓縮率, 比Gzip壓縮率都高; Had oop本身自帶,使用方便。
缺點:壓縮/解壓速度慢。
應用場景:適合對速度要求不高,但需要較高的壓縮率的時候;或者輸出之後的數據比較大,處理之後的數據需要壓縮存檔減少磁碟空間並且以後數據用得比較少的情況;或者對單個很大的文字檔案想壓縮減少儲存空間,同時又需要支援Split, 而且相容之前的應用程式的情況。 -
Lzo壓縮
優點:壓縮/解壓速度也比較快, 合理的壓縮率; 支援Split, 是Hadoop中最流行的壓縮格式; 可以在Linux系統下安裝lzop命令, 使用方便。
缺點:壓縮率比Gzip要低一些; Had oop本身不支援, 需要安裝; 在應用中對Lzo格式的檔案需要做一些特殊處理(爲了支援Spt需要建索引, 還需要指定Input Format爲Lzo格式) 。
應用場景:一個很大的文字檔案,壓縮之後還大於200M以上的可以考慮,而且單個檔案越大, Lzo優點越越明顯。 -
Snappy壓縮
優點:高速壓縮速度和合理的壓縮率。
缺點:不支援Split; 壓縮率比Gzip要低; Had oop本身不支援, 需要安裝。
應用場景:當Map Reduce作業的Map輸出的數據比較大的時候, 作爲Map到Reduce的中間數據的壓縮格式; 或者作爲一個Map Reduce作業的輸出和另外一個Map Reduce作業的輸入。
4.4 壓縮位置選擇
壓縮可以在MapReduce作用的任意階段啓用,如圖MapReduce數據壓縮

4.5 壓縮參數設定
要在Hadoop中啓用壓縮,可以設定如下參數:
| 參數 | 預設值 | 階段 | 建議 |
|---|---|---|---|
| io.compression.codecs(在core-site.xml中設定) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec | 輸入壓縮 | Hadoop使用副檔名判斷是否支援某種編解碼器 |
| mapreduce.map.output.compress(在mapred-site.xml中設定) | false | mapper輸出 | 這個參數設爲true啓用壓縮 |
| mapreduce.map.output.compress.codec(在mapred-site.xml中設定) | org.apache.hadoop.io.compress.DefaultCodec | mapper輸出 | 企業多使用LZO或Snappy編解碼器在此階段壓縮數據 |
| mapreduce.output.fileoutputformat.compress(在mapred-site.xml中設定) | false | reducer輸出 | 這個參數設爲true啓用壓縮 |
| mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中設定) | org.apache.hadoop.io.compress. DefaultCodec | reducer輸出 | 使用標準工具或者編解碼器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type(在mapred-site.xml中設定) | RECORD | reducer輸出 | SequenceFile輸出使用的壓縮型別:NONE和BLOCK |
4.6 壓縮實操案例
4.6.1 數據流的壓縮和解壓縮
測試一下如下壓縮方式:
表4-11
DEFLATE org.apache.hadoop.io.compress.DefaultCodec
gzip org.apache.hadoop.io.compress.GzipCodec
bzip2 org.apache.hadoop.io.compress.BZip2Codec
package com.atguigu.mapreduce.compress;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils;
public class TestCompress {
public static void main(String[] args) throws Exception {
compress("e:/hello.txt","org.apache.hadoop.io.compress.BZip2Codec");
// decompress("e:/hello.txt.bz2");
}
// 1、壓縮
private static void compress(String filename, String method) throws Exception {
// (1)獲取輸入流
FileInputStream fis = new FileInputStream(new File(filename));
Class codecClass = Class.forName(method);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, new Configuration());
// (2)獲取輸出流
FileOutputStream fos = new FileOutputStream(new File(filename + codec.getDefaultExtension()));
CompressionOutputStream cos = codec.createOutputStream(fos);
// (3)流的對拷
IOUtils.copyBytes(fis, cos, 1024*1024*5, false);
// (4)關閉資源
cos.close();
fos.close();
fis.close();
}
// 2、解壓縮
private static void decompress(String filename) throws FileNotFoundException, IOException {
// (0)校驗是否能解壓縮
CompressionCodecFactory factory = new CompressionCodecFactory(new Configuration());
CompressionCodec codec = factory.getCodec(new Path(filename));
if (codec == null) {
System.out.println("cannot find codec for file " + filename);
return;
}
// (1)獲取輸入流
CompressionInputStream cis = codec.createInputStream(new FileInputStream(new File(filename)));
// (2)獲取輸出流
FileOutputStream fos = new FileOutputStream(new File(filename + ".decoded"));
// (3)流的對拷
IOUtils.copyBytes(cis, fos, 1024*1024*5, false);
// (4)關閉資源
cis.close();
fos.close();
}
}
4.6.2 Map輸出端採用壓縮
即使你的MapReduce的輸入輸出檔案都是未壓縮的檔案,你仍然可以對Map任務的中間結果輸出做壓縮,因爲它要寫在硬碟並且通過網路傳輸到Reduce節點,對其壓縮可以提高很多效能,這些工作只要設定兩個屬性即可,我們來看下程式碼怎麼設定。
1.給大家提供的Hadoop原始碼支援的壓縮格式有:BZip2Codec 、DefaultCodec
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
// 開啓map端輸出壓縮
configuration.setBoolean("mapreduce.map.output.compress", true);
// 設定map端輸出壓縮方式
configuration.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 1 : 0);
}
}
2.Mapper保持不變
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
// 1 獲取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 回圈寫出
for(String word:words){
k.set(word);
context.write(k, v);
}
}
}
3.Reducer保持不變
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
// 1 彙總
for(IntWritable value:values){
sum += value.get();
}
v.set(sum);
// 2 輸出
context.write(key, v);
}
}
4.6.3 Reduce輸出端採用壓縮
基於WordCount案例處理。
1.修改驅動
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.Lz4Codec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 設定reduce端輸出壓縮開啓
FileOutputFormat.setCompressOutput(job, true);
// 設定壓縮的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
boolean result = job.waitForCompletion(true);
System.exit(result?1:0);
}
}
2.Mapper和Reducer保持不變(詳見4.6.2)
五、Yarn資源排程器
Yarn是一個資源排程平臺,負責爲運算程式提供伺服器運算資源,相當於一個分佈式的操作系統平臺,而MapReduce等運算程式則相當於執行於操作系統之上的應用程式。
5.1 Yarn基本架構
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等元件構成
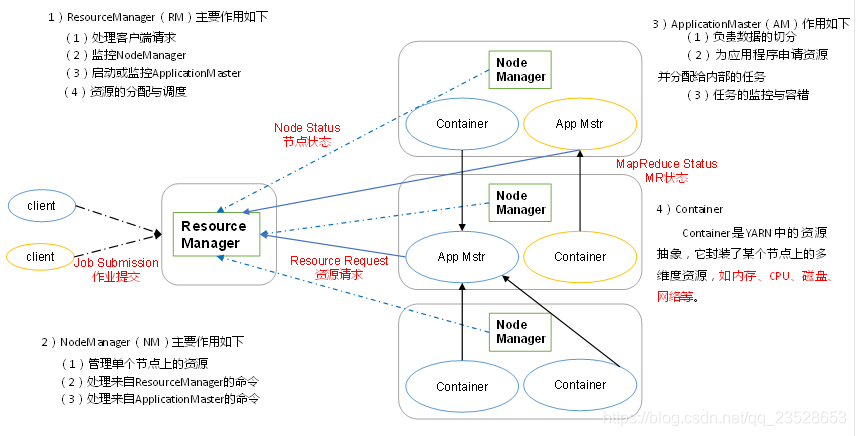
5.2 Yarn工作機制 機製
1.Yarn執行機制 機製。
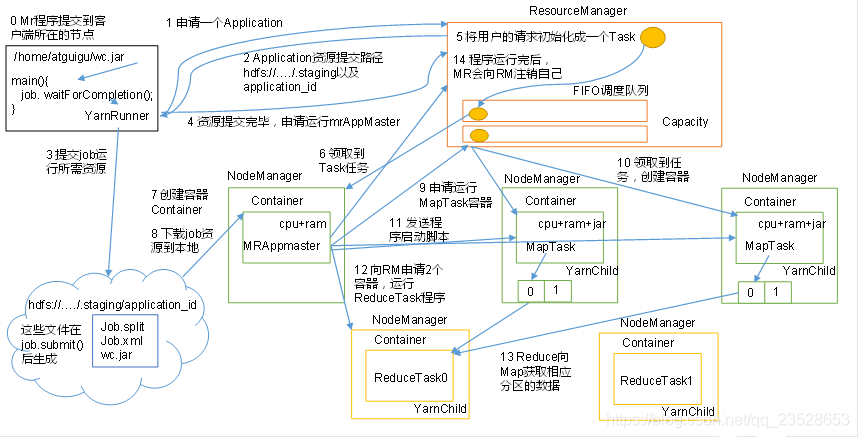
2.工作機制 機製詳解
(1)MR程式提交到用戶端所在的節點。
(2)YarnRunner向ResourceManager申請一個Application。
(3)RM將該應用程式的資源路徑返回給YarnRunner。
(4)該程式將執行所需資源提交到HDFS上。
(5)程式資源提交完畢後,申請執行mrAppMaster。
(6)RM將使用者的請求初始化成一個Task。
(7)其中一個NodeManager領取到Task任務。
(8)該NodeManager建立容器Container,併產生MRAppmaster。
(9)Container從HDFS上拷貝資源到本地。
(10)MRAppmaster向RM 申請執行MapTask資源。
(11)RM將執行MapTask任務分配給另外兩個NodeManager,另兩個NodeManager分別領取任務並建立容器。
(12)MR向兩個接收到任務的NodeManager發送程式啓動指令碼,這兩個NodeManager分別啓動MapTask,MapTask對數據分割區排序。
(13)MrAppMaster等待所有MapTask執行完畢後,向RM申請容器,執行ReduceTask。
(14)ReduceTask向MapTask獲取相應分割區的數據。
(15)程式執行完畢後,MR會向RM申請註銷自己。
5.3 作業提交全過程
1.作業提交過程之YARN。
作業提交過程之Yarn
作業提交全過程詳解
(1)作業提交
第1步:Client呼叫job.waitForCompletion方法,向整個叢集提交MapReduce作業。
第2步:Client向RM申請一個作業id。
第3步:RM給Client返回該job資源的提交路徑和作業id。
第4步:Client提交jar包、切片資訊和組態檔到指定的資源提交路徑。
第5步:Client提交完資源後,向RM申請執行MrAppMaster。
(2)作業初始化
第6步:當RM收到Client的請求後,將該job新增到容量排程器中。
第7步:某一個空閒的NM領取到該Job。
第8步:該NM建立Container,併產生MRAppmaster。
第9步:下載Client提交的資源到本地。
(3)任務分配
第10步:MrAppMaster向RM申請執行多個MapTask任務資源。
第11步:RM將執行MapTask任務分配給另外兩個NodeManager,另兩個NodeManager分別領取任務並建立容器。
(4)任務執行
第12步:MR向兩個接收到任務的NodeManager發送程式啓動指令碼,這兩個NodeManager分別啓動MapTask,MapTask對數據分割區排序。
第13步:MrAppMaster等待所有MapTask執行完畢後,向RM申請容器,執行ReduceTask。
第14步:ReduceTask向MapTask獲取相應分割區的數據。
第15步:程式執行完畢後,MR會向RM申請註銷自己。
(5)進度和狀態更新
YARN中的任務將其進度和狀態(包括counter)返回給應用管理器, 用戶端每秒(通過mapreduce.client.progressmonitor.pollinterval設定)嚮應用管理器請求進度更新, 展示給使用者。
(6)作業完成
除了嚮應用管理器請求作業進度外, 用戶端每5秒都會通過呼叫waitForCompletion()來檢查作業是否完成。時間間隔可以通過mapreduce.client.completion.pollinterval來設定。作業完成之後, 應用管理器和Container會清理工作狀態。作業的資訊會被作業歷史伺服器儲存以備之後使用者覈查。
2.作業提交過程之MapReduce.
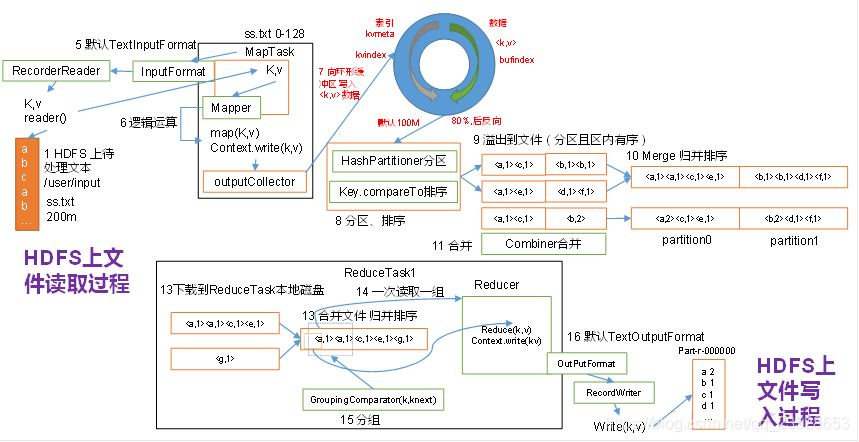
作業提交過程之MapReduce
5.4 資源排程器
目前,Hadoop作業排程器主要有三種:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.7.2預設的資源排程器是Capacity Scheduler。
具體設定詳見:yarn-default.xml檔案
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
1.先進先出排程器(FIFO)
2.容量排程器(Capacity Scheduler)

3.公平排程器(Fair Scheduler)
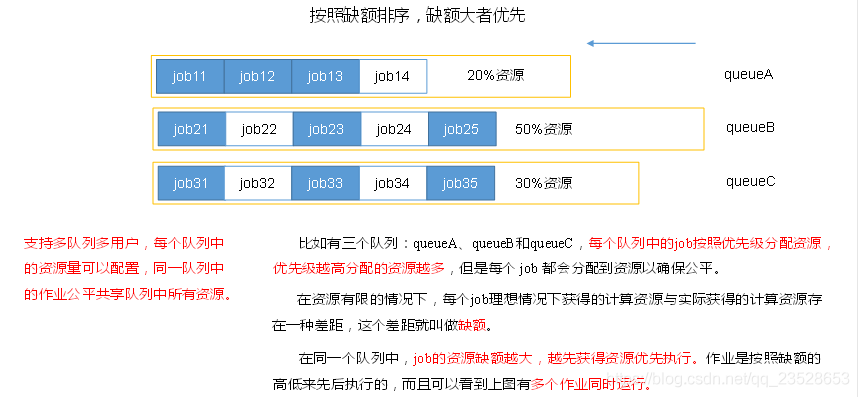
5.5 任務的推測執行
1.作業完成時間取決於最慢的任務完成時間
一個作業由若幹個Map任務和Reduce任務構成。因硬體老化、軟體Bug等,某些任務可能執行非常慢。
思考:系統中有99%的Map任務都完成了,只有少數幾個Map老是進度很慢,完不成,怎麼辦?
2.推測執行機制 機製
發現拖後腿的任務,比如某個任務執行速度遠慢於任務平均速度。爲拖後腿任務啓動一個備份任務,同時執行。誰先執行完,則採用誰的結果。
3.執行推測任務的前提條件
(1)每個Task只能有一個備份任務
(2)當前Job已完成的Task必須不小於0.05(5%)
(3)開啓推測執行參數設定。mapred-site.xml檔案中預設是開啓的。
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks may be executed in parallel.</description>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks may be executed in parallel.</description>
</property>
4.不能啓用推測執行機制 機製情況
(1)任務間存在嚴重的負載傾斜;
(2)特殊任務,比如任務向數據庫中寫數據。
5.演算法原理

第6章 Hadoop優化
MapReduce 跑的慢的原因, MapReduce程式效率的瓶頸在於兩點:
- 計算機效能
CPU、記憶體、磁碟健康、網路 - I/O操作優化
(1)數據傾斜
(2) Map和Reduce數設定不合理
(3) Map執行時間太長, 導致Reduce等待過久
(4)小檔案過多
(5)大量的不可分塊的超大檔案
(6) Spill次數過多
(7) Merge次數過多等。
6.1 MapReduce優化方法
MapReduce優化方法主要從六個方面考慮:數據輸入、Map階段、Reduce階段、IO傳輸、數據傾斜問題和常用的調優參數。
- 數據輸入
(1)合併小檔案:在執行MR任務前將小檔案進行合併,大量的小檔案會產生大量的Map任務, 增大Map任務裝載次數, 而任務的裝載比較耗時, 從而導致MR執行較慢。
(2) 採用Combine Text Input Format來作爲輸入, 解決輸入端大量小檔案場景。 - Map階段
(1) 減少溢寫(Spill) 次數:通過調整io.sort.mb及sort.spill.percent參數值, 增大觸發Spil的記憶體上限, 減少Spill次數, 從而減少磁碟IO.
(2) 減少合併(Merge) 次數:通過調整io.sort.factor參數, 增大Merge的檔案數目, 減少Merge的次數, 從而縮短MR處理時間。
(3) 在Map之後, 不影響業務邏輯前提下, 先進行Combine處理, 減少I/O。 - Reduce階段
(1) 合理設定Map和Reduce數:兩個都不能設定太少, 也不能設定太多。太少, 會導致Task等待, 延長處理時間; 太多,會導致Map、Reduce任務間競爭資源,造成處理超時等錯誤。
(2)設定Map、Reduce共存:調整slowstart.completed maps參數, 使Map執行到一定程度後, Reduce也開始執行, 減少Reduce的等待時間。
(3) 規避使用Reduce:因爲Reduce在用於連線數據集的時候將會產生大量的網路消耗。
(4) 合理設定Reduce端的Buffer:預設情況下, 數據達到一個閾值的時候,Buffer中的數據就會寫入磁碟, 然後Reduce會從磁碟中獲得所有的數據。也就是說, Buffer和Reduce是沒有直接關聯的, 中間多次寫磁碟->讀磁碟的過程, 既然有這個弊端, 那麼就可以通過參數來設定, 使得Buffer中的一部分數據可以直接輸送到Reduce, 從而減少IO開銷:mapreduce.reduce.inputbuffer.percent, 預設爲0.0。當值大於0的時候, 會保留指定比例的記憶體讀Buffer中的數據直接拿給
Reduce使用。這樣一來, 設定Buffer需要記憶體, 讀取數據需要記憶體, Reduce計算也要記憶體,所以要根據作業的執行情況進行調整。 - I/O傳輸
(1) 採用數據壓縮的方式, 減少網路IO的的時間。安裝Snappy和LZO壓縮編碼器。
(2) 使用Sequence File二進制檔案。 - 數據傾斜問題
數據傾斜現象
(1):數據頻率傾斜——某一個區域的數據量要遠遠大於其他區域。
(2):數據大小傾斜一部分記錄的大小遠遠大於平均值。
減少數據傾斜的方法
(1):抽樣和範圍分割區
可以通過對原始數據進行抽樣得到的結果集來預設分割區邊界值。
(2):自定義分割區
基於輸出鍵的背景知識進行自定義分割區。例如, 如果Map輸出鍵的單詞來源於一本書。且其中某幾個專業詞彙較多。那麼就可以自定義分割區將這這些專業詞彙發送給固定的一部分Reduce範例。而將其他的都發送給剩餘的Reduce範例。
(3):Combine
使用Combine可以大量地減小數據傾斜。在可能的情況下, Combine的目的就是聚合併精簡數據。
(4):採用Map Join, 儘量避免Reduce Join。 - 常用的調優參數
1.資源相關參數
(1)以下參數是在使用者自己的MR應用程式中設定就可以生效(mapred-default.xml)
| 設定參數 | 參數說明 |
|---|---|
| mapreduce.map.memory.mb | 一個MapTask可使用的資源上限(單位:MB),預設爲1024。如果MapTask實際使用的資源量超過該值,則會被強制殺死。 |
| mapreduce.reduce.memory.mb | 一個ReduceTask可使用的資源上限(單位:MB),預設爲1024。如果ReduceTask實際使用的資源量超過該值,則會被強制殺死。 |
| mapreduce.map.cpu.vcores | 每個MapTask可使用的最多cpu core數目,預設值: 1 |
| mapreduce.reduce.cpu.vcores | 每個ReduceTask可使用的最多cpu core數目,預設值: 1 |
| mapreduce.reduce.shuffle.parallelcopies | 每個Reduce去Map中取數據的並行數。預設值是5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的數據達到多少比例開始寫入磁碟。預設值0.66 |
| mapreduce.reduce.shuffle.input.buffer.percent | Buffer大小佔Reduce可用記憶體的比例。預設值0.7 |
| mapreduce.reduce.input.buffer.percent | 指定多少比例的記憶體用來存放Buffer中的數據,預設值是0.0 |
(2)應該在YARN啓動之前就設定在伺服器的組態檔中才能 纔能生效(yarn-default.xml)
| 設定參數 | 參數說明 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 給應用程式Container分配的最小記憶體,預設值:1024 |
| yarn.scheduler.maximum-allocation-mb | 給應用程式Container分配的最大記憶體,預設值:8192 |
| yarn.scheduler.minimum-allocation-vcores | 每個Container申請的最小CPU核數,預設值:1 |
| yarn.scheduler.maximum-allocation-vcores | 每個Container申請的最大CPU核數,預設值:3 |
| yarn.nodemanager.resource.memory-mb | 給Containers分配的最大實體記憶體,預設值:8192 |
(3)Shuffle效能優化的關鍵參數,應在YARN啓動之前就設定好(mapred-default.xml)
| 設定參數 | 參數說明 |
|---|---|
| mapreduce.task.io.sort.mb | Shuffle的環形緩衝區大小,預設100m |
| mapreduce.map.sort.spill.percent | 環形緩衝區溢位的閾值,預設80% |
2.容錯相關參數(MapReduce效能優化)
| 設定參數 | 參數說明 |
|---|---|
| mapreduce.map.maxattempts | 每個Map Task最大重試次數,一旦重試參數超過該值,則認爲Map Task執行失敗,預設值:4。 |
| mapreduce.reduce.maxattempts | 每個Reduce Task最大重試次數,一旦重試參數超過該值,則認爲Map Task執行失敗,預設值:4。 |
| mapreduce.task.timeout | Task超時時間,經常需要設定的一個參數,該參數表達的意思爲:如果一個Task在一定時間內沒有任何進入,即不會讀取新的數據,也沒有輸出數據,則認爲該Task處於Block狀態,可能是卡住了,也許永遠會卡住,爲了防止因爲使用者程式永遠Block住不退出,則強制設定了一個該超時時間(單位毫秒),預設是600000。如果你的程式對每條輸入數據的處理時間過長(比如會存取數據庫,通過網路拉取數據等),建議將該參數調大,該參數過小常出現的錯誤提示是「AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.」。 |
6.2 HDFS小檔案優化方法
HDFS小檔案弊端
HDFS上每個檔案都要在NameNode上建立一個索引,這個索引的大小約爲150byte,這樣當小檔案比較多的時候,就會產生很多的索引檔案,一方面會大量佔用NameNode的記憶體空間,另一方面就是索引檔案過大使得索引速度變慢。
6.3.2 HDFS小檔案解決方案
小檔案的優化無非以下幾種方式:
(1)在數據採集的時候,就將小檔案或小批數據合成大檔案再上傳HDFS。
(2)在業務處理之前,在HDFS上使用MapReduce程式對小檔案進行合併。
(3)在MapReduce處理時,可採用CombineTextInputFormat提高效率。
1.Hadoop Archive
是一個高效地將小檔案放入HDFS塊中的檔案存檔工具, 它能夠將多個小檔案打包成一個HAR檔案, 這樣就減少了Name Node的記憶體使用。
2.Sequence File
Sequence File由一系列的二進制key/value組成, 如果key爲檔名, value爲檔案內容,則可以將大批小檔案合併成一個大檔案。
3.CombineFileInputFormat
CombineFileInputFormat是一種新的InputFormat, 用於將多個檔案合併成一個單獨的Split, 另外, 它會考慮數據的儲存位置。
4.開啓JVM重用
對於大量小檔案Job, 可以開啓JVM重用會減少45%執行時間。JVM重用原理:一個Map執行在一個JVM上, 開啓重用的話, 該Map在JVM上執行完畢後, JVM繼續執行其他Map。
具體設定:map reduce.job.jvm.num tasks值在10-20之間。
宣告:文章內容來自尚硅谷,B站有免費視屏。