LeetCode上僅有的四道shell程式設計題解析
LeetCode 195 第十行
01題目描述
給定一個文字檔案 file.txt,請只列印這個檔案中的第十行。
02檔案內容
Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
Line 8
Line 9
Line 10
03輸出
Line 10
說明:
1. 如果檔案少於十行,你應當輸出什麼?
2. 至少有三種不同的解法,請嘗試儘可能多的方法來解題。
04解析
參考答案:
三種不同的解法
第一種:grep -n "" file.txt | grep -w '10' | cut -d: -f2
第二種:sed -n '10p' file.txt
第三種:awk '{if(NR==10){print $0}}' file.txt
說明當中提到,我們應該考慮檔案少於十行的情況,那麼我們就要知道檔案本身包含的行數,以下給大家提供10種獲取檔案行數的方式:
[root@localhost ~]# awk '{print NR}' file.txt | tail -n1
10
[root@localhost ~]# awk 'END{print NR}' file.txt
10
[root@localhost ~]# grep -nc "" file.txt
10
[root@localhost ~]# grep -c "" file.txt
10
[root@localhost ~]# grep -vc "^$" file.txt
10
[root@localhost ~]# grep -n "" file.txt|awk -F: '{print '}|tail -n1 | cut -d: -f1
10
[root@localhost ~]# sed -n "$=" file.txt
10
[root@localhost ~]# wc -l file.txt
10 file.txt
[root@localhost ~]# cat file.txt | wc -l
10
[root@localhost ~]# wc -l file.txt | cut -d' ' -f1
10
知道了行號之後,我們就可以判斷檔案是否足夠十行,足夠十行則輸出第十行,不足十行則列印檔案不足十行,只有多少行即可。
row_num=$(cat file.txt | wc -l)
echo $row_num
if [ $row_num -lt 10 ];then
echo "The number of row is less than 10"
else
awk '{if(NR==10){print $0}}' file.txt
fi
其中列印輸出第10行的程式碼可以替換爲:
grep -n "" file.txt | grep -w '10' | cut -d: -f2
sed -n '10p' file.txt
awk '{if(NR==10){print $0}}' file.txt
05拓展
tail命令將每個檔案的最後10行列印到標準輸出。對於多個檔案,在每個檔案前面加上一個給出檔名的頭。如果沒有檔案,或者檔案爲-,則讀取標準輸入。
如何使用tail命令
使用tail命令檢視yum.log日誌檔案,顯示最後10行內容,tail預設顯示問價你的最後10行內容:
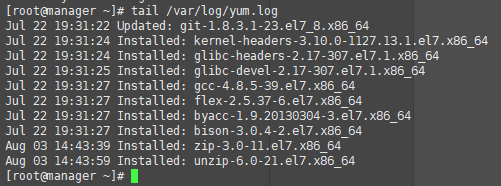
如何顯示指定的行數
使用-n命令顯示指定的行數,也可以省略字母n,只使用-和數位(數位和-之間沒有空格)。
例如:檢視自己建立的使用者,檢視/etc/passwd檔案最後兩行內容:

如何實時監控檔案的更改
如果需要監視檔案內容的更改,使用-f選項。這個選項對於監視日誌檔案非常有用。例如,要顯示/var/log/messages檔案的最後10行,並監視檔案的更新:
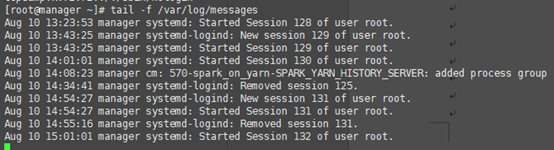
想要退出,請按Ctrl+C退出。
檢視多個檔案
如果提供了多個檔案作爲tail命令的輸入,它將顯示每個檔案的最後十行。下面 下麪例子,使用tail命令顯示/etc/passwd和/etc/shadow檔案的最後兩行內容:
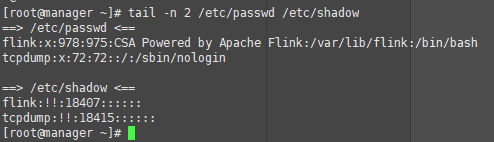
tail命令和其他命令一起使用
例如,要實時監視/var/log/messages檔案並顯示包含session爲129的行,可以使用:

LeetCode 193 有效電話號碼
01題目描述
給定一個包含電話號碼列表(一行一個電話號碼)的文字檔案 file.txt,寫一個 bash 指令碼輸出所有有效的電話號碼。
你可以假設一個有效的電話號碼必須滿足以下兩種格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一個數字)
你也可以假設每行前後沒有多餘的空格字元。
02檔案內容
987-123-4567
123 456 7890
(123) 456-7890
03輸出
你的指令碼應當輸出下列有效的電話號碼:
987-123-4567
(123) 456-7890
04解析
這道題目主要考察正則表達式和行匹配工具。
解決此問題,只要寫出兩種電話號碼格式 (xxx) xxx-xxxx 或 xxx-xxx-xxxx 所對應的正則表達式即可:
(xxx) xxx-xxxx 所對應的正則表達式最笨的寫法:
'\([0-9][0-9][0-9]\) [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]'
'[(][0-9][0-9][0-9][)] [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]'
也就是把每一個x換成數位[0-9],再將給小括號加上反斜槓進行跳脫或者放進一對中括號內即可。
xxx-xxx-xxxx 則可以表示爲:
'[0-9][0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]'
對上面兩種正則表達式做進一步的簡化:
'\([0-9]{3}\) [0-9]{3}-[0-9]{4}'
'[(][0-9]{3}[)] [0-9]{3}-[0-9]{4}'
'[0-9]{3}-[0-9]{3}-[0-9]{4}'
此處再給出另外一種電話號碼的正則表達式表示方式:
#\d 是基於 Perl 的正則表達式
#(xxx) xxx-xxxx
'[(]\d{3}[)] \d{3}-\d{4}'
'\(\d{3}\) \d{3}-\d{4}'
#xxx-xxx-xxxx
'\d{3}-\d{3}-\d{4}'
有了上面我們總結出來的正則表達式,進行行匹配就簡單多了,只需要一個或|就可以將兩個正則表達式連在一起:
'\(\d{3}\) \d{3}-\d{4}|\d{3}-\d{3}-\d{4}'
'[(]\d{3}[)] \d{3}-\d{4}|\d{3}-\d{3}-\d{4}'
'\([0-9]{3}\) [0-9]{3}-[0-9]{4}|[0-9]{3}-[0-9]{3}-[0-9]{4}'
使用或運算連線在一起,你如果覺得還不夠簡化可以再提取出兩個正則中相同的部分,則表示爲:
'(\(\d{3}\) |\d{3}-)\d{3}-\d{4}'
'([(]\d{3}[)] |\d{3}-)\d{3}-\d{4}'
'(\([0-9]{3}\) |[0-9]{3}-)[0-9]{3}-[0-9]{4}'
最後匹配出電話號碼格式正確的就輕而易舉:6種方法
grep -P '(\(\d{3}\) |\d{3}-)\d{3}-\d{4}' file.txt
grep -P '([(]\d{3}[)] |\d{3}-)\d{3}-\d{4}' file.txt
grep -E '(\([0-9]{3}\) |[0-9]{3}-)[0-9]{3}-[0-9]{4}' file.txt
grep -P '^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$' file.txt
awk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txt
gawk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txt
05拓展
溫馨提示:這道題主要考察正則表達式和行匹配,可以參考下面 下麪的文章學習
LeetCode 192 統計詞頻
01題目描述
寫一個 bash 指令碼以統計一個文字檔案 words.txt 中每個單詞出現的頻率。
爲了簡單起見,你可以假設:
words.txt只包括小寫字母和 ' ' 。
每個單詞只由小寫字母組成。
單詞間由一個或多個空格字元分隔。
02檔案內容
the day is sunny the the
the sunny is is
03輸出
你的指令碼應當輸出(以詞頻降序排列):
the 4
is 3
sunny 2
day 1
說明:
不要擔心詞頻相同的單詞的排序問題,每個單詞出現的頻率都是唯一的。
你可以使用一行 Unix pipes 實現嗎?
04解析
對於words.txt檔案進行詞頻統計,首先要做的事情就是把words.txt檔案當中的每一個單詞分割出來,分割出每一個單詞可以使用以下兩種方式:
使用awk命令:
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){print $i}}' words.txt
the
day
is
sunny
the
the
the
sunny
is
is
其中NF表示當前記錄的欄位數(即列數)
$i 檔案中每行以間隔符號分割的不同欄位
使用xargs命令:
[root@localhost ~]# cat words.txt | xargs -n1
the
day
is
sunny
the
the
the
sunny
is
is
[root@localhost ~]# cat words.txt | xargs -n2
the day
is sunny
the the
the sunny
is is
xargs命令是用於給其他命令傳遞參數的一個過濾器,也是組合多個命令的一個工具。
-n選項,指定輸出時每行輸出的列數
當我們將words.txt檔案中的所有單詞都分割出來之後,就可以統計這些單詞當中每一個單詞出現的次數了。
我們僅考慮使用awk命令來完成這個任務的話很簡單,在進行分割的過程中直接用一個關聯陣列直接儲存每一個單詞出現的次數,此處我們可以暫時將關聯陣列理解爲一個字典,關鍵字爲單詞,值爲單詞出現的次數(這樣理解只是一種通俗的說法)
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){asso_array[$i]++;}};END{for(w in asso_array){print w,asso_array[w];}}' words.txt
day 1
sunny 2
the 4
is 3
當然我們也可以在xargs的基礎之上使用一些shell小工具來得到每個單詞出現的次數。sort 工具及 uniq 工具
[root@localhost ~]# cat words.txt | xargs -n1 | sort
day
is
is
is
sunny
sunny
the
the
the
the
[root@localhost ~]# cat words.txt | xargs -n1 | sort | uniq -c
1 day
3 is
2 sunny
4 the
sort工具用於排序,它將檔案的每一行作爲一個單位,從首字母向後按照ASCII碼值進行比較,預設將他們升序輸出。
-r : 降序排列
-n : 以數位排序,預設是按照字元排序的。
uniq用去取出連續的重複行
-c :統計重複行的次數
最後我們僅需要對上面的結果進行排序啦,很簡單的使用sort就可以啦!
[root@localhost ~]# cat words.txt | xargs -n1 | sort | uniq -c | sort -rn | awk '{print $2,$1}'
the 4
is 3
sunny 2
day 1
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){asso_array[$i]++;}};END{for(w in asso_array){print w,asso_array[w];}}' words.txt | sort -rn
the 4
sunny 2
is 3
day 1
05拓展
關聯陣列的更多內容可以閱讀:SHELL程式設計之變數與四則運算
LeetCode 194 轉置檔案
01題目描述
給定一個檔案 file.txt,轉置它的內容。你可以假設每行列數相同,並且每個欄位由 ' ' 分隔.
02檔案內容
name age
alice 21
ryan 30
03輸出
name alice ryan
age 21 30
04解析
對於這道題目我們可以簡單的理解爲將第一列變成第一行,第二列變爲第二行,...,第n列變爲第n行。這樣一來,問題就簡單了,只需要把一列元素串起來,儲存起來並輸出即可,如何獲取一列元素成了我們問題的關鍵了,awk命令就可以輕鬆解決這個問題了:
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){print "row[",i,"]="$i}}' file.txt
row[ 1 ]=name
row[ 2 ]=age
row[ 1 ]=alice
row[ 2 ]=21
row[ 1 ]=ryan
row[ 2 ]=30
可以從awk命令對每一行處理後的結果觀察到,現在要做的就是把所有row[1]的給串起來,也就是第一列的給串起來,構成第一行,所有的row[2]串起來構成第二行。這個實現起來就簡單了,我們只需要加一個判斷語句即可:
[root@localhost ~]# awk '{
for (i=1;i<=NF;i++){
if (NR==1){
res[i]=$i
}
else{
res[i]=res[i]" "$i
}
}
}END{
for(j=1;j<=NF;j++){
print res[j]
}
}' file.txt
name alice ryan
age 21 30
其中NR表示行號,判斷行號是否等於1的目的在於,第一行的內容轉置之後爲每一行的行首,保證第一行內容在行首就得通過判斷得到。
另外給大家提供一種投機取巧的做法,那就是使用cut命令進行列分割,程式碼如下:
#!/bin/env bash
column=$(awk '{print NF}' file.txt | uniq)
for((i=1;i<=column;i++))
do
cut -d' ' -f$i file.txt|xargs
done
其中變數column用來儲存列數,cut -d' ' -f$i file.txt 表示取出檔案當中的一列元素,配合xargs將一列內容轉化爲一行並輸出。是不是超簡單,看着比awk簡單。
05拓展
關於awk命令不熟悉的讀者朋友,可以參考此文學習: