Python中的三個」黑魔法「與」騷操作「,你知道嘛?
Python中的三個」黑魔法「與」騷操作「:
本文主要介紹Python的高階特性:列表推導式、迭代器和生成器,是面試中經常會被問到的特性。因爲生成器實現了迭代器協定,可由列表推導式來生成,所有,這三個概唸作爲一章來介紹,是最便於大家理解的,現在看不懂沒關係,下面 下麪我不僅是會讓大家知其然,重要的更是要知其所以然。
列表推導式
前幾天有個HR讓我談談列表推導式,我說這我經常用,就是用舊的列表生成一個新的列表的公式,他直接就把我拒了,讓我回去複習一下,挺受打擊的,所以決定也幫助大家回顧一下。
內容
- 列表推導式:舊的列表->新的列表
- 瞭解:字典推導式 集合推導式
1.列表推導式:
格式 [表達式 for 變數 in 舊列表]
或 [表達式 for 變數 in 舊列表 if 條件]
例1:生成名字長度大於3且首字母大寫的新列表。
names_old = ['tom', 'amy', 'daming', 'lingling']
names_new = [name.capitalize() for name in names_old if len(name) > 3]
print(names_new)
複製程式碼
免費領取Python自動化學習資料 工具,面試寶典面試技巧,加QQ羣,785128166,羣內還會大佬技術交流
輸出:
['Daming', 'Lingling']
複製程式碼
例2: (大廠初級筆試題目)生成一個元組列表,要求每個元素爲(0-5偶數, 0-10奇數)形式。輸出結果爲:
[(0, 1), (0, 3), (0, 5), (0, 7), (0, 9), (2, 1), (2, 3), (2, 5), (2, 7), (2, 9), (4, 1), (4, 3), (4, 5), (4, 7), (4, 9)]
複製程式碼
for回圈實現程式碼:
new_list = list()
for i in range(5): # 偶數
if i % 2 == 0:
for j in range(10): # 奇數
if j % 2 != 0:
new_list.append((i, j))
複製程式碼
列表推導式程式碼:
new_list = [(i, j) for i in range(5) for j in range(10) if i % 2 == 0 and j % 2 != 0]
複製程式碼
例3:(大廠初級筆試題目)給出一個員工列表:
employees_old = [{'name': "tmo", "salary": 4800},
{'name': "amy", "salary": 3800},
{'name': "daming", "salary": 7000},
{'name': "lingling", "salary": 5600}]
複製程式碼
如果員工薪資大於5000則加200,否則加500,輸出新的員工列表。
列表推導式:
employees_new = [employee['salary'] + 200 if employee['salary'] > 5000 else employee['salary'] + 500 for employee in employees_old]
print(employees_new)
複製程式碼
輸出:
[5300, 4300, 7200, 5800]
複製程式碼
發現結果是員工薪資列表,回過頭看一下程式碼,確實是把得到的數位給了列表,那要返回員工列表要怎麼實現呢?讓我們用普通for回圈的方式來進行一下對比:
for employee in employees_old:
if employee['salary'] > 5000:
employee['salary'] += 200
else:
employee['salary'] += 500
print(employees_old)
複製程式碼
輸出:
[{'name': 'tmo', 'salary': 5300}, {'name': 'amy', 'salary': 4300}, {'name': 'daming', 'salary': 7200}, {'name': 'lingling', 'salary': 5800}]
複製程式碼
沒錯,我們注意到兩者的差別了,列表推導式我們少了一步賦值(在字典元素上進行賦值),不能直接返回一個薪資數值而是一個員工字典給列表。正確的列表推導式如下:
employees_new = [
{'name': employee['name'], 'salary': employee['salary'] + 200} if employee['salary'] > 5000 else
{'name': employee['name'], 'salary': employee['salary'] + 500} for employee in employees_old]
print(employees_new)
複製程式碼
2.字典推導式:
例1:
dict_old = {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'C'}
dict_new = {value: key for key, value in dict_old.items()}
print(dict_new)
複製程式碼
輸出:
{'A': 'a', 'B': 'b', 'C': 'd'}
複製程式碼
3.集合推導式:
類似列表推導式 典型用法:去重
例1:
list_old = [1, 2, 3, 5, 2, 3]
set_new = {x for x in list_old}
print(set_new)
複製程式碼
輸出:
{1, 2 ,3, 5}
複製程式碼
小結:
到目前爲止,列表推導式不就是一個用來建立列表的式子麼?除了可以簡化程式碼,裝裝X?其實,列表推導式還有另一個優點是相比於for回圈更高效,因爲列表推導式在執行時呼叫的是Python的底層C程式碼,而for回圈則是用Python程式碼來執行。嗷~面試官最想聽到的,是第二點。
迭代器(免費領取Python自動化學習資料 工具,面試寶典面試技巧,加QQ羣,785128166,羣內還會大佬技術交流)
由於迭代器協定對很多人來說,是一個較爲抽象的概念,而且生成器自動實現了迭代器協定,所以我們需要先講解一下迭代器協定的概念,也是爲了更好的理解接下來的生成器。
概念
可以被next()函數呼叫並不斷返回下一個值的物件稱爲迭代器:Iterator。
迭代是存取集合元素的一種方式,迭代器是一個可以記住遍歷位置的物件。迭代器物件從集合的第一個元素開始存取,直到所有元素被存取完結束。
迭代器只能往前不能後退。
- 迭代器協定:是指物件需要提供
__next__()方法,它要麼返回迭代中的下一項,要麼就引起一個StopIteration異常,以終止迭代。 - 可迭代物件:就是實現了迭代器協定的物件。
舉個例子,對Python稍微熟悉一點的朋友應該知道,Python的for回圈不但可以用來遍歷list,還可以用來遍歷檔案物件,如下所示:
with open('F:/test/test.txt') as f:
for line in f:
print(line)
複製程式碼
爲什麼在Python中,檔案還可以使用for回圈進行遍歷呢?這是因爲,在Python中,檔案物件實現了迭代器協定,for回圈並不知道它遍歷的是一個檔案物件,它只管使用迭代器協定存取物件即可。正是由於Python的檔案物件實現了迭代器協定,我們才得以使用如此方便的方式存取檔案,如下所示:
with open('F:/test/test.txt') as f:
print(dir(f))
複製程式碼
輸出:
['__class__', '__del__', '__dict__', '__dir__', '__init__', '__iter__', '__next__', 'closed', 'line_buffering', 'newlines', 'read', 'readline'......]
複製程式碼
可迭代的是不是肯定就是迭代器?
- 生成器是可迭代的,也是迭代器。
list是可迭代的,但不是迭代器。list可以藉助iter()函數將可迭代的變成迭代器list->iter(list)->迭代器next():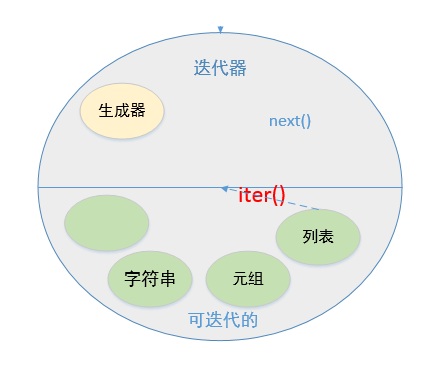
可迭代物件:
- 生成器
- 元組 列表 集合 字典 字串
如何判斷一個物件是否是可迭代?
藉助isinstance()函數:
from collections import Iterable
print(isinstance([x for x in range(10)], Iterable)) # 列表
print(isinstance('hello world', Iterable)) # 字串
print(isinstance(100, Iterable)) # 數位
print(isinstance((x for x in range(10)), Iterable)) # 迭代器
複製程式碼
輸出:
True
True
False
True
複製程式碼
生成器
生成器是Python最有用的特性之一,也是使用的最不廣泛的Python特性之一。究其原因,主要是因爲,在其他主流語言裏面沒有生成器的概念。正是由於生成器是一個「新」的東西,所以,它一方面沒有引起廣大工程師的重視,另一方面,也增加了工程師的學習成本,最終導致大家錯過了Python中如此有用的一個特性。
概念
我們已經知道,通過列表推導式可以直接建立一個列表,但是,受到記憶體限制,列表容量肯定是有限的。而且,建立一個包含100萬個元素的列表,不僅佔用很大的儲存空間,如果我們僅僅需要存取前面那幾個元素,那後面絕大多數元素佔用的空間都白白浪費了。所以,如果列表元素可以按照某種演算法在回圈的過程中不斷推算出後續的元素,這樣既不必建立完整的list,從而還可以節省大量的空間。在Python中,這種一邊回圈一邊計算的機制 機製,稱爲生成器:generator。
Python使用生成器對延遲操作提供了支援。所謂延遲操作,是指在需要的時候才產生結果,而不是立即產生結果。這也是生成器的主要好處。
定義生成器
Python有兩種不同的方式提供生成器:
方法一:藉助列表推導式
生成器表達式:類似於列表推導(這也就是爲什麼第一節我要先介紹列表推導式),但是,生成器返回按需產生結果的一個物件,而不是一次構建一個結果列表。
例1:
my_generator = (x for x in range(5)) # 注意是()不是[]
print(my_generator) # 發現不能列印出元素
print(type(my_generator))
print(my_generator.__next__()) # 三種得到元素的方法,注意看輸出結果
print(next(my_generator))
for i in my_generator:
print(i)
# 注意會拋出StopIteration異常
# print(next(my_generator))
print(next(my_generator)) # generator只能遍歷一次
複製程式碼
輸出:
Traceback (most recent call last):
File "E:/pycharm/Leetcode/RL_Learning/printdata.py", line 11, in <module>
print(next(my_generator))
StopIteration
<generator object <genexpr> at 0x0000000000513660>
<class 'generator'>
0
1
2
3
4
複製程式碼
方法二:藉助函數
生成器函數:使用yield語句而不是return語句返回函數結果。yield語句一次返回一個結果,在每個結果中間,掛起函數的狀態,起到暫停的作用,以便下次從它離開的地方繼續執行。
步驟:
- 定義函數,函數返回使用
yield關鍵字; - 呼叫函數,接收函數返回值;
- 得到的返回結果就是生成器;
- 藉助
next()或__nest__()得到想要的元素。
例2:你的函數裏面只要出現了yield關鍵字,你的函數就不再是函數了,就變成生成器了:
# 斐波那契數列:
def fib(length): # 1. 定義函數
a, b = 0, 1
n = 0
while n < length:
n += 1
yield b # return b + 暫停
a, b = b, a + b
g = fib(5) # 2. 呼叫函數
print(g) # 3. 返回的就是生成器
print(next(g)) # 4. 藉助`next()`或`__nest__()`得到想要的元素
print(next(g)) # 每呼叫一次產生一個值
print(next(g))
print(g.__next__())
print(g.__next__())
複製程式碼
輸出:
<generator object fib at 0x0000000001DDDFC0>
1
1
2
3
5
複製程式碼
注意:生成器只能遍歷一次。
當呼叫函數的時候,並沒有進函數進行執行,而是直接生成一個生成器,當呼叫next的時候,才進入函數真正開始執行,除了第一次呼叫next()方法是從函數頭開始執行,其餘每次都是接着從上次執行到yield的地方接着執行的。
小結:
使用生成器以後,程式碼行數更少。大家要記住,如果想把程式碼寫的Pythonic,在保證程式碼可讀性的前提下,程式碼行數越少越好。
合理使用生成器,能夠有效提高程式碼可讀性。只要大家完全接受了生成器的概念,理解了yield語句和return語句一樣,也是返回一個值。那麼,就能夠理解爲什麼使用生成器比不使用生成器要好,能夠理解使用生成器真的可以讓程式碼變得清晰易懂。
在實際工作中,充分利用Python生成器,不但能夠減少記憶體使用,還能夠提高程式碼可讀性。掌握生成器也是Python高手的標配。 如果本文對你有幫助,不要忘記關注點贊或收藏支援一下~