有了這篇文章, Python 中的編碼不再是噩夢
有了這篇文章, Python 中的編碼不再是噩夢
Python 中編碼問題,一直是很多 Python 開發者的噩夢,儘管你是工作多年的 Python 開發者,也肯定會經常遇到令人神煩的編碼問題,好不容易花了半天搞明白了。
一段時間後,又全都忘光光了,一臉懵逼的你又開始你找各種部落格、貼文,從頭搞清楚什麼是編碼?什麼是 unicode?它和 ASCII 有什麼區別?爲什麼 decode encode 老是報錯?python2 裡和 python3 的字串型別怎麼都不一樣,怎麼對應起來?如何檢測編碼格式?
反反覆覆,這個過程真是太痛苦了。
今天我把大家在 Python 上會遇到的一些編碼問題都講清楚了,以後你可以不用再 Google,收藏這篇文章就行。
1. Python 3 中 str 與 bytes
在 Python3中,字串有兩種型別 ,str 和 bytes。
今天就來說一說這二者的區別:
unicode string(str 型別):以 Unicode code points 形式儲存,人類認識的形式byte string(bytes 型別):以 byte 形式儲存,機器認識的形式
在 Python 3 中你定義的所有字串,都是 unicode string型別,使用 type 和 isinstance 可以判別
# python3
>>> str_obj = "你好"
>>>
>>> type(str_obj)
<class 'str'>
>>>
>>> isinstance("你好", str)
True
>>>
>>> isinstance("你好", bytes)
False
>>>
複製程式碼
而 bytes 是一個二進制序列物件,你只要你在定義字串時前面加一個 b,就表示你要定義一個 bytes 型別的字串物件。
# python3
>>> byte_obj = b"Hello World!"
>>> type(byte_obj)
<class 'bytes'>
>>>
>>> isinstance(byte_obj, str)
False
>>>
>>> isinstance(byte_obj, bytes)
True
>>>
複製程式碼
但是在定義中文字串時,你就不能直接在前面加 b 了,而應該使用 encode 轉一下。
>>> byte_obj=b"你好"
File "<stdin>", line 1
SyntaxError: bytes can only contain ASCII literal characters.
>>>
>>> str_obj="你好"
>>>
>>> str_obj.encode("utf-8")
b'\xe4\xbd\xa0\xe5\xa5\xbd'
>>>
複製程式碼
2. Python 2 中 str 與 unicode
而在 Python2 中,字串的型別又與 Python3 不一樣,需要仔細區分。
在 Python2 裡,字串也只有兩種型別,unicode 和 str 。
只有 unicode object 和 非unicode object(其實應該叫 str object) 的區別:
unicode string(unicode型別):以 Unicode code points 形式儲存,人類認識的形式byte string(str 型別):以 byte 形式儲存,機器認識的形式
當我們直接使用雙引號或單引號包含字元的方式來定義字串時,就是 str 字串物件,比如這樣
# python2
>>> str_obj="你好"
>>>
>>> type(str_obj)
<type 'str'>
>>>
>>> str_obj
'\xe4\xbd\xa0\xe5\xa5\xbd'
>>>
>>> isinstance(str_obj, bytes)
True
>>> isinstance(str_obj, str)
True
>>> isinstance(str_obj, unicode)
False
>>>
>>> str is bytes
True
複製程式碼
而當我們在雙引號或單引號前面加個 u,就表明我們定義的是 unicode 字串物件,比如這樣
# python2
>>> unicode_obj = u"你好"
>>>
>>> unicode_obj
u'\u4f60\u597d'
>>>
>>> type(unicode_obj)
<type 'unicode'>
>>>
>>> isinstance(unicode_obj, bytes)
False
>>> isinstance(unicode_obj, str)
False
>>>
>>> isinstance(unicode_obj, unicode)
True
複製程式碼
3. 如何檢測物件的編碼(免費領取Python自動化學習資料 工具,面試寶典面試技巧,加QQ羣,785128166,羣內還會大佬技術交流)
所有的字元,在 unicode 字元集中都有對應的編碼值(英文叫做:code point)
而把這些編碼值按照一定的規則儲存成二進制位元組碼,就是我們說的編碼方式,常見的有:UTF-8,GB2312 等。
也就是說,當我們要將記憶體中的字串持久化到硬碟中的時候,都要指定編碼方法,而反過來,讀取的時候,也要指定正確的編碼方法(這個過程叫解碼),不然會出現亂碼。
那問題就來了,當我們知道了其對應的編碼方法,我們就可以正常解碼,但並不是所有時候我們都能知道應該用什麼編碼方式去解碼?
這時候就要介紹到一個 python 的庫 -- chardet ,使用它之前 需要先安裝
python3 -m pip install chardet
複製程式碼
chardet 有一個 detect 方法,可以 預測其其編碼格式
>>> import chardet
>>> chardet.detect('微信公衆號:Python程式設計時光'.encode('gbk'))
{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
複製程式碼
爲什麼說是預測呢,通過上面的輸出來看,你會看到有一個 confidence 欄位,其表示預測的可信度,或者說成功率。
但是使用它時,若你的字元數較少,就有可能 「誤診」),比如只有 中文 兩個字,就像下面 下麪這樣,我們是 使用 gbk 編碼的,使用 chardet 卻識別成 KOI8-R 編碼。
>>> str_obj = "中文"
>>> byte_obj = bytes(a, encoding='gbk') # 先得到一個 gbk 編碼的 bytes
>>>
>>> chardet.detect(byte_obj)
{'encoding': 'KOI8-R', 'confidence': 0.682639754276994, 'language': 'Russian'}
>>>
>>> str_obj2 = str(byte_obj, encoding='KOI8-R')
>>> str_obj2
'жпнд'
複製程式碼
所以爲了編碼診斷的準確,要儘量使用足夠多的字元。
chardet 支援多國的語言,從官方文件中可以看到支援如下這些語言(chardet.readthedocs.io/en/latest/s…)

4. 編碼與解碼的區別
編碼和解碼,其實就是 str 與 bytes 的相互轉化的過程(Python 2 已經遠去,這裏以及後面都只用 Python 3 舉例)
-
編碼:encode 方法,把字串物件轉化爲二進制位元組序列
-
解碼:decode 方法,把二進制位元組序列轉化爲字串物件
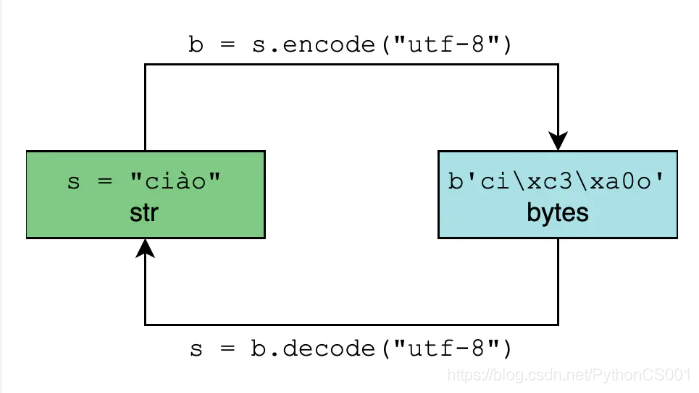
那麼假如我們真知道了其編碼格式,如何來轉成 unicode 呢?
有兩種方法
第一種是,直接使用 decode 方法
>>> byte_obj.decode('gbk')
'中文'
>>>
複製程式碼
第二種是,使用 str 類來轉
>>> str_obj = str(byte_obj, encoding='gbk')
>>> str_obj
'中文'
>>>
複製程式碼
5. 如何設定檔案編碼
在 Python 2 中,預設使用的是 ASCII 編碼來讀取的,因此,我們在使用 Python 2 的時候,如果你的 python 檔案裡有中文,執行是會報錯的。
SyntaxError: Non-ASCII character '\xe4' in file demo.py
複製程式碼
原因就是 ASCII 編碼表太小,無法解釋中文。
而在 Python 3 中,預設使用的是 uft-8 來讀取,所以省了不少的事。
對於這個問題,通常解決方法有兩種:
第一種方法
在 python2 中,可以使用在頭部指定
可以這樣寫,雖然很好看
# -*- coding: utf-8 -*-
複製程式碼
但這樣寫太麻煩了,我通常使用下面 下麪兩種寫法
# coding:utf-8
# coding=utf-8
複製程式碼
第二種方法
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
複製程式碼
這裏在呼叫sys.setdefaultencoding(‘utf-8’) 設定預設的解碼方式之前,執行了reload(sys),這是必須的,因爲python在載入完sys之後,會刪除 sys.setdefaultencoding 這個方法,我們需要重新載入sys,才能 纔能呼叫 sys.setdefaultencoding 這個方法。