從小白開始學python-網路爬蟲二
python網路爬蟲二
主要內容:
- HTML和CSS簡介
- Beautiful Soup的安裝
- BS的使用
- 正則表達式
- 爬取實戰
HTML AND CSS
HTML
HTML又稱超文件標示語言,是現在建立網頁的標準標示語言,它指定了文件的結構和格式
它通過一系列標籤來問文件提供結構和格式,標籤通常成對出現
比如
<p>...</p>一個是段落的開始標籤,另一個是結束標籤,當然標籤允許巢狀
我們不需要擔心這部分內容的學習是不是又要花費大量的時間,實際上我們的瀏覽器已經提供了我們檢視HTML的工具,比如chrome
我們只需要右擊滑鼠,選擇檢查,我們就能看到這些HTML
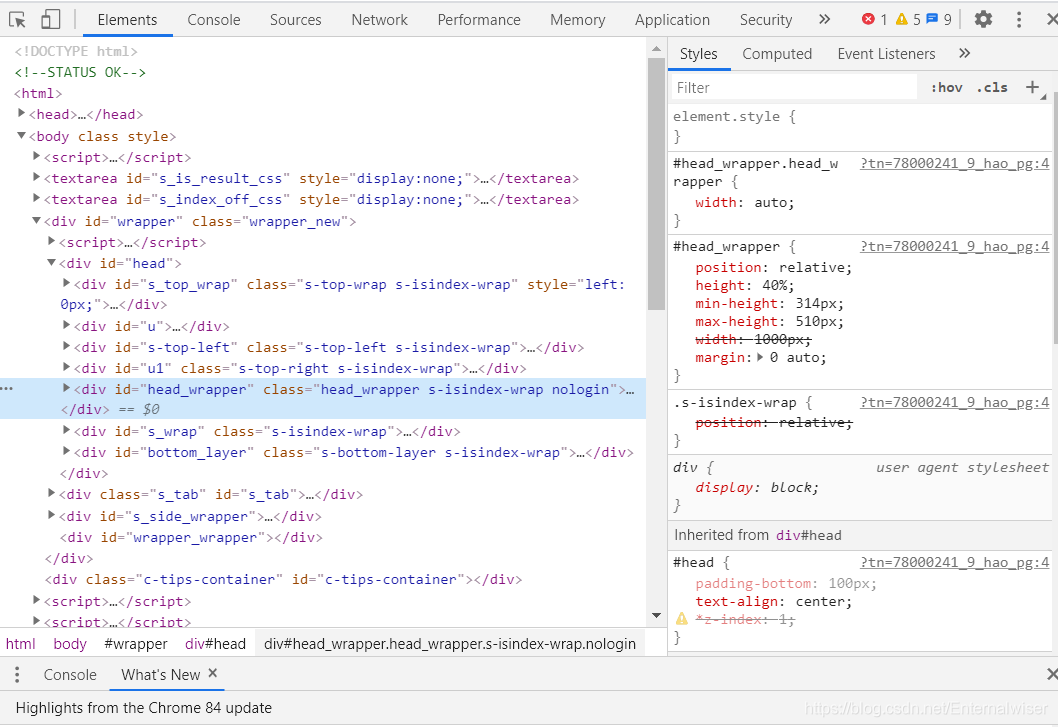
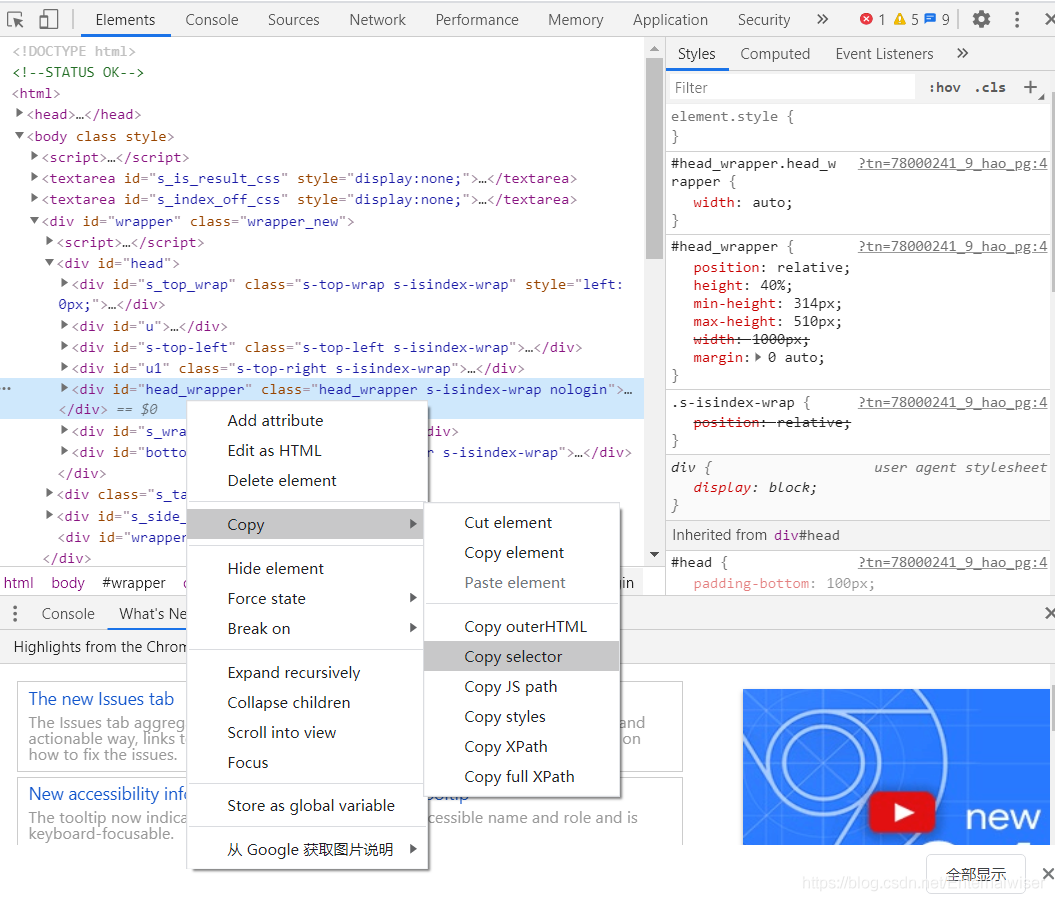
跟我們爬取下來的內容是一致的,當然裏面有些指令碼是使用JavaScript的程式語言編寫的,我們後面也會提到,當我們想要提取某個HTML元素的時候,我們可以在其上面右擊,選擇「copy selector」或者「copy xpath」
這對不會正則表達式的我們提供了極大的幫助!
CSS
層疊樣式表
我們通過冒號分隔的基於鍵值的語句列表來表示樣式資訊
比如
color:'red';
font-size:14pt;
background-color:#ccc;
當然這樣的宣告是可以嵌入HTML中的,我們開啓任何一個網頁都能找到這樣的用法
如果想要學習更多關於HTML和CSS的知識,可以存取下面 下麪這個網站喲
超級棒的學習網站(菜鳥教學)
下面 下麪我們進入正題:beautiful soup的學習
beautiful soup的安裝
我們爲了處理獲得的網頁資訊引入的美麗湯
使用這個庫我們能夠抓取我們感興趣的內容
使用pip安裝
pip install -U beautifulsoup4
接下來就是BS發揮它神奇作用的時候了
beautiful soup的使用
首先我們需要建立一個beautiful soup的物件
from bs4 import BeautifulSoup
import requests
import re
target = 'https://www.baidu.com/'
get_url = requests.get(url=target)
print(get_url.status_code)
get_url.encoding = 'utf-8'
test = get_url.text
bs = BeautifulSoup(test)//有的時候這種用法會出錯
最後一句建立了一個BS物件,這句出錯的原因在於BS庫本身依賴HTML解析器來執行大部分批次解析的工作,而python中存在不止一個這樣的解析器:
- html.parser : python內建的解析器
- lxml : 處理速度很快,需要額外安裝
- html5lib : 旨在與瀏覽器完全相同的方式解析網頁,但速度稍慢
所以當我們擁有不止一個這樣的解析器時,我們應該加上我們使用的解析器
bs = BeautifulSoup(test, "html.parser")//加上解析器
BS的主要任務時解析HTML內容並將其轉換爲基於樹的表現形式
所以我們有兩種獲取數據的方法:
- find
- find_all
他們都可以用於查詢HTML樹中的元素
我們來看看他們的函數原型
find(name, attrs, recursive, string, **keywords)
find_all(name, attrs, recursive, string, limit, **keywords)
- name: 參數定義你希望找到的標籤名字,可以傳遞字串或者列表
- attrs: 屬性的python字典
- recursive: 控制搜尋的深度,預設爲Ture,可以查詢子標籤
- string:根據元素的文字內容執行匹配
- limit: 限制檢索的元素數量
注意find返回的是檢索的元素,find_all返回的專案列表
兩個方法返回的都是tag物件
正則表達式(re庫)
這是高階的匹配模式(我也還沒完全搞懂hhh)
正則表達式是定義一系列搜尋模式的模式
經常用於字串搜尋和匹配程式碼以查詢或替換字串片段
(對於批次爬取下載有奇效!!!)
基本符號:
^ 表示匹配字串的開始位置 (例外 用在中括號中[ ] 時,可以理解爲取反,表示不匹配括號中字串)
$ 表示匹配字串的結束位置
* 表示匹配 零次到多次
+ 表示匹配 一次到多次 (至少有一次)
? 表示匹配零次或一次
. 表示匹配單個字元
| 表示爲或者,兩項中取一項
( ) 小括號表示匹配括號中全部字元
[ ] 中括號表示匹配括號中一個字元 範圍描述 如[0-9 a-z A-Z]
{ } 大括號用於限定匹配次數 如 {n}表示匹配n個字元 {n,}表示至少匹配n個字元 {n,m}表示至少n,最多m
\ 跳脫字元 如上基本符號匹配都需要跳脫字元 如 \* 表示匹配*號
\w 表示英文字母和數位 \W 非字母和數位
\d 表示數位 \D 非數位
更多細緻的用法參考這位博主的部落格:
比如這行程式碼:
bs.find_all(re.compile('^h'))
//用於匹配所有以字母h開頭的標籤
最後的實戰程式碼
from bs4 import BeautifulSoup
import requests
import re
target = 'https://www.baidu.com/'
get_url = requests.get(url=target)
test = get_url.text
bs = BeautifulSoup(test, "html.parser")
print(bs.title) # 獲取title標籤的名稱
print(bs.title.string) # 獲取title標籤的文字內容
你會發現你的輸出好像並不和你想象的一樣
輸出結果:
<title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é「</title>
ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é「
爲啥是亂碼啊!!!
別慌,其實只是編碼出現了錯誤而已只需要加上一行程式碼,告訴編譯器編碼格式即可
get_url.encoding = 'utf-8' # 編碼格式
那麼輸出就會成這樣:
<title>百度一下,你就知道</title>
百度一下,你就知道
下面 下麪我們貼出各種方法查詢元素方法的程式碼:
find_all方法
for item in bs.find_all('a'):
# print(item.get('href')) # 獲取屬性 與下面 下麪的方法等價
print(item['href'])
for item in bs.find_all('a'):
print(item.get_text()) # 遍歷a標籤的文字值
輸出結果:
http://news.baidu.com
https://www.hao123.com
http://map.baidu.com
http://v.baidu.com
http://tieba.baidu.com
http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1
//www.baidu.com/more/
http://home.baidu.com
http://ir.baidu.com
http://www.baidu.com/duty/
http://jianyi.baidu.com/
新聞
hao123
地圖
視訊
貼吧
登錄
更多產品
關於百度
About Baidu
使用百度前必讀
意見反饋
正則表達式
t_list = bs.find_all(re.compile("^a")) # 傳入正則表達式來匹配內容-開頭爲a標籤
for item in t_list:
print(item)
輸出結果:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新聞</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123</a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地圖</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">視訊</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">貼吧</a>
<a class="lb" href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1" name="tj_login">登錄</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多產品</a>
<a href="http://home.baidu.com">關於百度</a>
<a href="http://ir.baidu.com">About Baidu</a>
<a href="http://www.baidu.com/duty/">使用百度前必讀</a>
<a class="cp-feedback" href="http://jianyi.baidu.com/">意見反饋</a>
下篇預告:
使用表單和post請求
構造請求頭
使用cookie
json相關