Redis在Linux中詳細安裝、Nosql概述
一、NoSql入門和概述
1、入門概述
1、網際網路時代背景下,爲什麼用nosql?
1.單機Mysql的美好時代
一個網站的存取量一般都不大,用單個數據庫完全可以輕鬆應對。在那個時候,更多的都是靜態網頁,動態互動型別的網站不多。
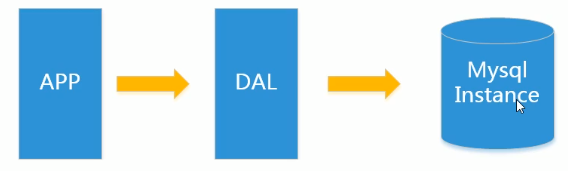
上述架構下,我們來看看數據儲存的瓶頸是什麼?
-
數據量的總大小 一個機器放不下去時。
-
數據的索引(B+Tree) 一個機器的記憶體放不下時。
-
存取量(讀寫混合)一個範例不能承受
2.Memcached(快取)+Mysql+垂直拆分
隨着存取量的上升,幾乎大部分使用MySQL架構的網站在數據庫上都開始出現了效能問題,web程式不在僅僅專注在功能上,同時也在追求效能。程式設計師們大量使用的快取技術來緩解數據庫的壓力,優化數據庫的結構和索引。開始比較流行的是通過檔案快取來緩解數據庫壓力,但是存取量繼續增大的時候,多臺web機器通過檔案快取不能共用,大量的小檔案快取也帶來了比較高的IO壓力。這個時候Memcached就成爲了一個非常時尚的技術產品。
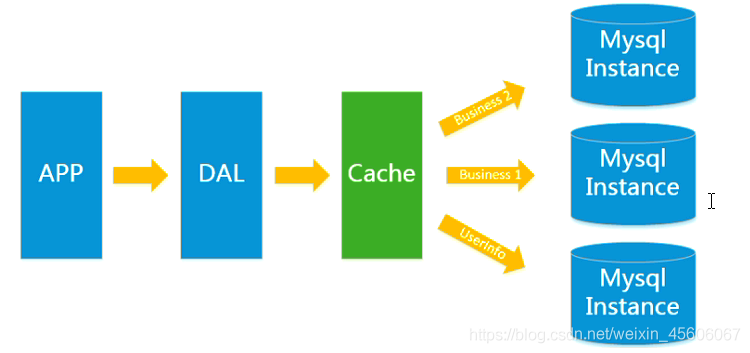
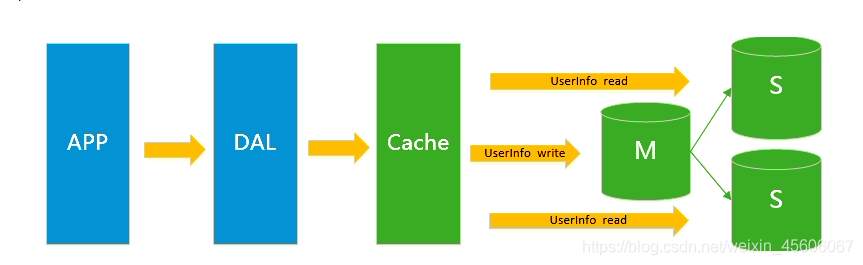
3.Mysql主從讀寫分離
由於數據庫的寫入壓力增加,Memcached只能緩解數據庫的讀取壓力。讀寫集中在一個數據庫上讓數據庫不堪重負,大部分網站開始使用主從複製技術來達到讀寫分離,以及高書寫效能和讀庫的可延伸性。Mysql的master-slave模式成爲這個時候的網站標配。
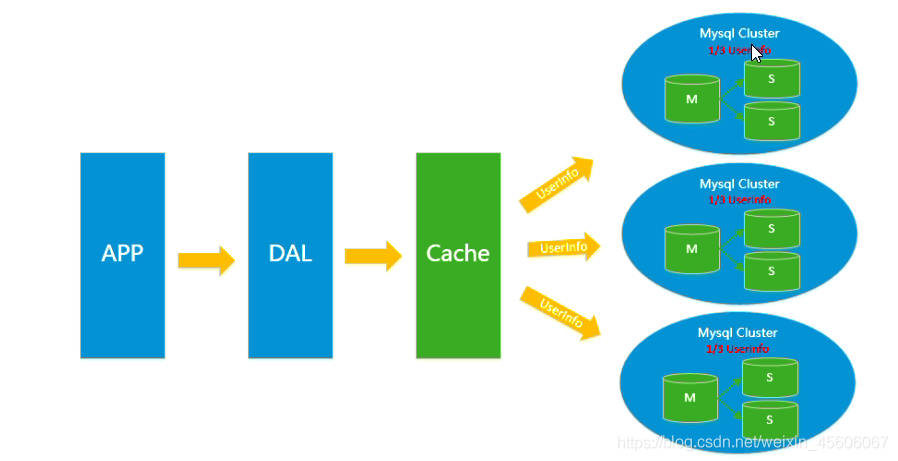
4.分表分庫+水平拆分+mysql叢集
在Memcached的快取記憶體,Mysql的主從複製,讀寫分離的基礎之上,這時mysql主庫的寫壓力開始出現瓶頸,而數據量的持續猛增,由於MyISAM使用表鎖,在高併發下會出現嚴重的鎖問題,大量的高併發MySQL應用開始使用InnoDB引擎代替MyISAM。
同時開始流行使用分表分庫來緩解寫壓力和數據增長的擴充套件問題。這個時候,分表分庫成了一個熱門技術,是面試的熱門問題也是業界討論的熱門技術問題。也就在這個時候,Mysql推出了還不太穩定的表分割區,這也給技術實力一般的公司帶來了希望。雖然Mysql推出了Mysql Cluster叢集,但效能也不能很好滿足網際網路的要求,只是高可靠性提供了非常大的希望。
5.Mysql的擴充套件性瓶頸
Mysql數據庫也經常儲存一些大文字欄位,倒是數據庫表非常的大,在做數據庫恢復的時候就導致非常的慢,不容易快速恢復數據。比如1000萬4KB大小的文字就接近40GB的大小,如果能把這些數據從Mysql省去,Mysql將變得非常的小。關係數據庫很強大,但是他並不能很好的應對所有的應用場景。Mysql的擴充套件性差(需要複雜的技術來實現),大數據下IO壓力下,表結構更加困難,正是當前使用Mysql的開發人員面臨的問題。
6.今天是什麼樣子的?
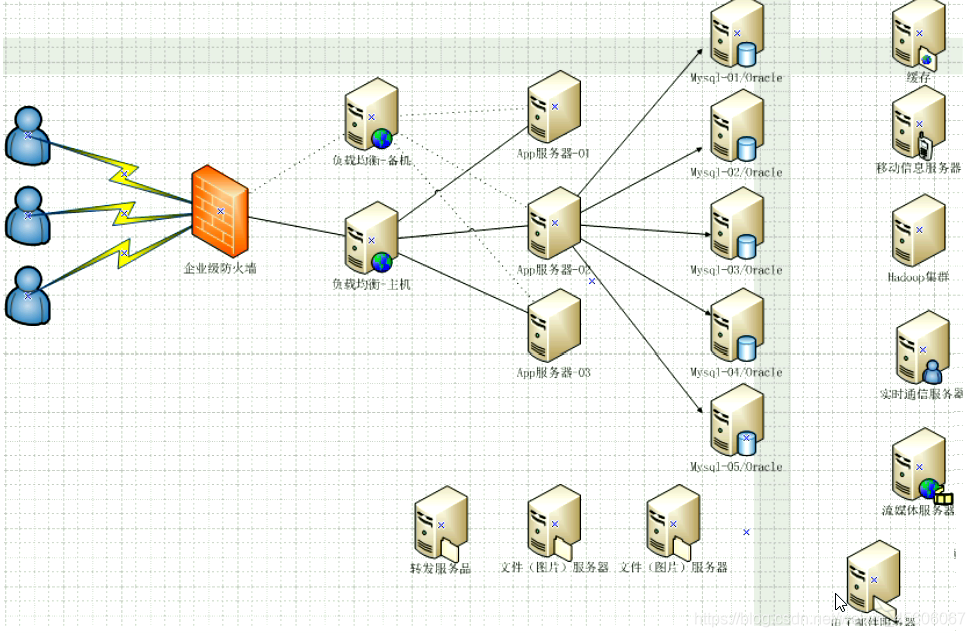
7.爲什麼用NoSQL?
今天我們可以通過第三方平臺(如:Google,Facebook等)可以很容易的存取和抓取數據。使用者的個人資訊,社羣網路,地理位置,使用者生產的數據和使用者操作日誌已經成倍的增加。我們如果要對這些用戶數據進行挖掘,那SQL數據庫已經不適合這些應用了,NoSQL數據庫的發展也確能很好的處理這些大的數據。
2、NoSql是什麼?
NoSQL(NOSQL ==Not Only SQL) 意即「不僅僅是SQL」。
泛指非關係型的數據庫。隨着網際網路 web2.0 網路的興起,傳統的關係數據庫在應付 web2.0 網站,特別是超大規模和高併發的SNS型別的 web2.0 存動態網站已經顯得力不從心,暴露了很多難以克服的困難,而非關係型的數據庫則由於其本身的特點得到了非常迅速的發展。NoSQL數據庫的生產就是爲了解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題,包括差大規模數據的儲存。
這些型別的數據儲存不需要固定的模式,無需多餘操作就可以橫向擴充套件。
3、NoSql能幹嘛?
① 易擴充套件:
NOSQL數據庫種類繁多。但是一個共同的特點都是去掉關係數據庫的關係型特性。
數據之間無關係,這種就非常容易擴充套件。也無形之間,在架構層面上帶來了可延伸的能力。
② 大數據量高效能:
NoSQL數據庫都具有非常高的讀寫效能。尤其在大數據量下,同樣表現優秀。
這得益於它的無關係性。數據庫的結構簡單。
一般MySQL使用Query Cache,每次表的更新Cache就失效,是一種大粒度的Cache,在針web2.0的互動頻繁的應用,Cache效能不高。而NOSQL的Cache是記錄級的,是一種細粒度的Cache,所以NOSQL在這個層面上來說就要效能高很多了。
③ 多樣靈活的數據模型
NOSQL無需事先爲儲存數據建立欄位,隨着可以儲存自定義的數據格式,而在關係數據庫裡,增刪欄位是一件非常麻煩的事情。如果是非常大數據量的表,增加欄位簡直就是一個噩夢。
④ 傳統 RDBMS VS NOSQL
RDBMS :
- 高度組織化結構化數據。
- 結構化查詢語言。(SQL)
- 數據和關係都儲存在單獨的表中。
- 數據操縱語言,數據定義語言。
- 嚴格的一致性。
- 基礎事務。
NOSQL:
- 代表着不僅僅是SQL。
- 沒有宣告性查詢語言。
- 沒有預定義的模式。
- 鍵 - 值對儲存,列儲存,文件儲存,圖形數據庫。
- 最終一致性,而非ACID屬性·。
- 非結構化和不可預知的數據。
- CAP定理。
- 高效能,高可用性的可伸縮性。
4、NoSql去哪下?
Redis官網:https://redis.io/
Memcache官網
Mongdb官網
5、NoSql怎麼玩?
KV:鍵值對
Cache:快取
Persistence:持續化
…
2、3V+3高
大數據時代的3V:海量Volume,多樣Variety,實時Velocity。
網際網路需求的3高:高併發,高可擴(橫向),高效能。
3、當下的NoSql經典應用
當下的應用是sql和nosql一起使用。
阿裡巴巴中文網站商品資訊如何存放的:
看看阿裡巴巴中文網站首頁(以女裝、女包包爲例)
和我們相關的,多數據源多數據型別的儲存問題。
① 商品基本資訊
如:名稱、價格、出產日期、生產廠商等
關係型數據庫:mysql/oracle目前淘寶在去o化(也即要拿下oracle)
注意:淘寶內部使用的mysql是自己改造過的
爲什麼去IOE?
在IT建設中,去除IBM小型機,Oracle數據庫及WMC儲存裝置。
② 商品描述、詳情、評價資訊(多文字類)
多文字資訊描述類,IO讀寫效能變差
文件數據庫MongDB中
③ 商品圖片
商品圖片展示類
分佈式的檔案系統中
- 淘寶自己的TFS
- Google的GFS
- Hadoop的HDFS
④ 商品的關鍵字
搜尋引擎,淘寶內用
ISearch
⑤ 商品的波段性的熱點高頻資訊
記憶體數據庫
Tair、Redis 、Memcache
⑥ 商品的交易、價格計算、積分累計
外部系統,外部第3方支付介面
支付寶…
⑦ 總結大型網際網路應用(大數據、高併發、多樣數據型別)的難點和解決方案。
難點:
- 數據型別多樣性。
- 數據源多樣性和變化重構。
- 數據源改造而數據服務平臺不需要大面積重構。
解決辦法:
- EAI 和 統一數據平臺服務層
- 阿裡、淘寶幹了 乾了什麼? UDSL
UDSL:在網站應用叢集和底層數據源之間,構建一層代理,統一數據層。
4、NoSql數據模型簡介
以一個電商客戶、訂單、訂購、地址模型來對比下 關係型數據庫和非關係型數據庫:
- 傳統的關係型數據庫的你如何設計?
ER圖(1:1 / 1:n / n:n,主外來鍵等)
- Nosql你是如何設計的?
什麼是BSON?
BSON是一種類json的一種二進制形式的儲存形式,簡稱Binary JSON,它和 Json一樣,支援內嵌的文件物件和陣列物件。
- 兩者對比,問題和難點:
爲什麼上述情況可以用聚合模型來處理?
高併發的操作是不太建議有關聯查詢的,網際網路公司用冗餘數據來避免關聯查詢。
分佈式事務是支援不了太多的併發的。
聚合模型:
- KV鍵值
- BSON
- 列族
顧名思義是按列儲存數據的。最大的特點是方便儲存結構化和半結構化數據,方便做數據壓縮,針對某一列或者某幾列的查詢有非常大的IO優勢。
- 圖形
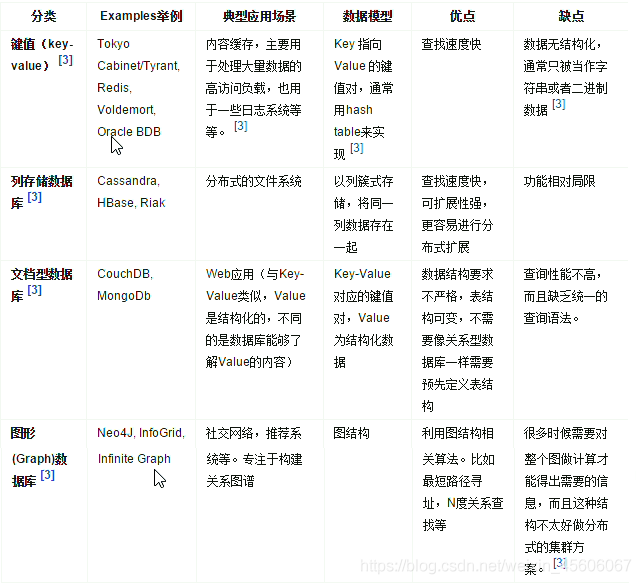
5、NoSql數據庫的四大分類
-
KV鍵值:典型介紹
- 新浪:BerkeleyDB+redis
- 美團:redis+tair
- 阿裡、百度:memcache+redis
-
文件型數據庫(bson格式比較多):典型介紹
- CouchDB
- MongDB
MongoDB是一個基於分佈式檔案儲存的數據庫。由C++語言編寫,旨在爲WEB應用提供可延伸的高效能數據儲存解決方案。
MongoDB是一個介於關係型數據庫和非關係型數據庫之間的產品,是非關係數據庫當中功能最豐富的,最像關係數據庫的。
-
列儲存數據庫
- Cassandra,HBase
- 分佈式檔案系統
-
圖關係數據庫
- 他不是放圖形的,放的是關係 比如:朋友圈社羣網路、廣告推薦系統、社羣網路、推薦系統等,專注於構建關係圖譜。
- Neo4J,InfoGrid
四者對比
6、在分佈式數據庫中CAP原理 CAP+BASE
① 傳統的ACID分別是什麼?
事務在英文是transaction,和現實世界中的建議很類似,他有如下四個特性:
- A(Atomicity)原子性
原子性很容易理解,也就是說事務裡的所有操作要麼全部做完,要麼都不做,事務成功的條件是事務裡的所有操作都成功,只要有一個操作失敗,整個事務就失敗,需要回滾。比如銀行轉賬,從A賬戶轉100元至B賬戶,分爲兩個步驟:1)從A賬戶取100元;2)存入100元至B賬戶。這兩部要麼一起完成,要麼一起不完成,如果只完成第一步,第二部失敗,錢會莫名其妙少了100元。
- C(Consistency)一致性
一致性也比較容易理解。也就是說數據庫要一直處於一致的狀態。事務的執行不會改變數據庫原本的一致性約束。
- I(Isolation)獨立性
所謂的獨立性是指併發的事物之間不會互相影響,一個事物要存取的數據正在被另一個事物修改,只要另外一個事物未提交,他所存取的數據就不受未提交事務的影響。比如現在有個交易是從A賬戶轉100元至B賬戶,在這個交易還未完成的情況下,如果此時B查詢自己的賬戶,是看不到新增的100元。
- D(Durability)永續性
持久化是指一旦事務提交後,它所做的修改將會永久的儲存在數據庫上,即使出現宕機的也不會丟失。
② CAP
- C:Consistency(強一致性)
- A:Availability(高可用性)
- P:Partition talerance(分割區容錯性)
③ CAP的3進2【重點】
CAP理論就是說在分佈式儲存系統中,最多隻能實現上面的亮點。而由於當前的網路硬體會出現延遲丟包等問題,所以**分割區容忍性使我們必須要實現的**。
所以我們只能在一致性和可用性之間進行權衡,沒有NoSQL系統能同時保證這三點。
- CA 傳統Oracle數據庫
- AP 大多數網站架構的選擇
- CP Redis、MongoDB
=-------------開始---------------=
一致性與可用性的決擇:
數據庫事務一致性需求
很多web實時系統並不要求嚴格的數據庫事務,對讀一致性的要求很低,有些場合對寫一致性要求並不高。允許實現最終一致性。
數據庫的寫實時性和讀實時性需求
對關係數據庫來說,插入一條數據之後立即查詢,是很定可以讀出來這條數據的,但是對於很多web應用來說,並不要求這麼高的實時性,比方說發一條訊息之後,過幾秒乃至十幾秒之後,我的訂閱纔看到這條動態是完全可以接受的。
對複雜的SQL查詢,特別是多表關係查詢的需求
任何大數據量的web系統,都非常忌諱多個大表的關聯查詢,以及複雜的數據分析型別的報表查詢,特別是SNS型別的網站,從需求以及查詢設計角度,就避免了這種情況的發生。往往更多的只是單表的主鍵查詢,以及單表的簡單條件分頁查詢,SQL的功能被極大的弱化了 。
=-------------結束---------------=
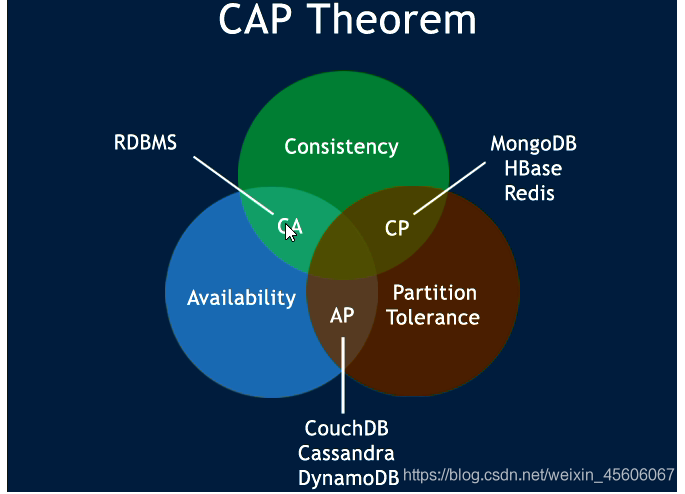
④ 經典CAP圖
CAP理論的核心是:一個分佈式系統不可能同時很好的滿足一致性,可用性和可區容錯性這三個需求,最多可以同時較好的滿足兩個。
因此,根據CAP原理將NoSQL數據庫分成了滿足CA原則、滿足CP原則和滿足AP原則三大類:
CA - 單個叢集,滿足一致性,可用性的系統,通常在可延伸性不上太強大。
CP - 滿足一致性,區分容忍必性的系統,通常效能不是特別高。
AP - 滿足可用性,分割區容忍性的系統,通常可能對一致性要求低一些。
⑤ BASE
BASE就是爲了解決關係數據庫強一致性引起的問題而引起的可用性降低而提出的解決方案。
BASE其實是下面 下麪三個術語的縮寫:
- 基本可用(Basically Available)
- 軟狀態(Soft state)
- 最終一致(Eventually consistent)
他的思想是通過系統放鬆對某一時刻數據一致性的要求來換取系統整體伸縮性和效能上改觀。爲什麼這麼說呢,緣由就於大型系統往往由於地域分佈和極高效能的要求,可能分佈式事物來完成這些指標,要想獲得這些指標,必須採用另外一種方式來完成,BASE就是解決這個問題的辦法。
⑥ 分佈式+叢集簡介
分佈式系統:
由多臺計算機和通訊的軟體元件通過計算機網路連線(本地網路或廣域網)組成。分佈式系統時間裏在網路之上的軟件系統。正是因爲軟體的效能,所以分佈式系統具有高度的內聚性和透明性。因此,網路和分佈式系統之間的區別更多的在於高層軟體(特別是操作系統),而不是硬體。分佈式系統可以應用在不同的平臺上如:PC、工作站、區域網和廣域網上等。
簡單來講:
分佈式:不同的多臺伺服器上面部署不同的服務模組(工程),他們之間通過Rpc/Rmi之間通訊和呼叫,對外提供服務和組內共同作業。
叢集:不同的多臺伺服器上面部署相同的服務模組,通過分佈式排程軟體進行統一的排程,對外提供服務和存取。
二、Redis入門介紹
1、入門概述
1.是什麼
Redis:REmote DIctionary Server(遠端字典服務)是完全開源免費的,用c語言編寫,遵守BSD協定,是一個高效能的(key/value)分佈式記憶體數據庫,基於記憶體執行並支援持久化的NoSQL數據庫,是當前最熱門的Nosql數據庫之一,也被人們稱爲數據結構伺服器。
Redis與其他 key - value 快取產品有以下三個特點:
- Redis支援數據的持久化,可以將記憶體中的數據保持在磁碟中,重新啓動的時候可以再次載入進行使用。
- Redis不僅僅支援簡單的key - value型別的數據,同時還提供list,set,zset,hash等數據結構的儲存。
- Redis支援數據的備份,即master -slave 模式的數據備份。
2.能幹嘛
記憶體儲存和持久化:redis支援非同步將記憶體中的數據寫到硬碟上,同時不影響繼續服務
取最新N個數據的操作,如:可以將最新的10條評論的ID放在Redis的List集合裏面
模擬類似於HttpSession這種需要設定過期時間的功能。
發佈、訂閱訊息系統
定時器、計算器
3.去哪下
4.怎麼玩
- 數據型別、基本操作和設定
- 持久化和複製、RDB/AOF
- 事務的控制
- 複製
- …
2、VMWare+VMTools千裡之行始於足下
-
VMWare虛擬機器的安裝
-
CentOS或者RedHad5的安裝
1)如何檢視自己的linux是32位元還是64位元:
getconf LONG_BIT
返回是多少就是幾位2)假如出現了不支援虛擬化的問題:

是「宿主機BIOS設定中的硬體虛擬化被禁用了。」
需要開啓筆電BIOS中的IVT對虛擬化的支援。
找到選單「Security」–「System Security」,
將Virtualization Technology(VTx)和Virtualization Technology DirectedI/O(VTd)設定爲 Enabled。
儲存並退出BIOS設定,重新啓動電腦。 -
VMTools的安裝
-
設定共用目錄
上述環境都OK後開始進行Redis的伺服器安裝設定。
3、Redis的安裝
1)windows版安裝
下載地址:https://GitHub.com/dmajkic/redis/downloads
下載到的Redis支援32bit和64bit。根據自己實際情況選擇,將64bit的內容cp到自定義碟符安裝取名redis,如C:\redis 。 開啓一個cmd視窗 使用cd命令切換目錄到 C:\redis 執行 redis-server.exe redis.conf 。
如果想方便的話,可以把redis的路徑加到系統的環境變數裡,這樣就省的在輸路徑了,後面的那個 redis.conf 可以省略,
如果省略,會啓用預設的。輸入之後,會顯示如下介面: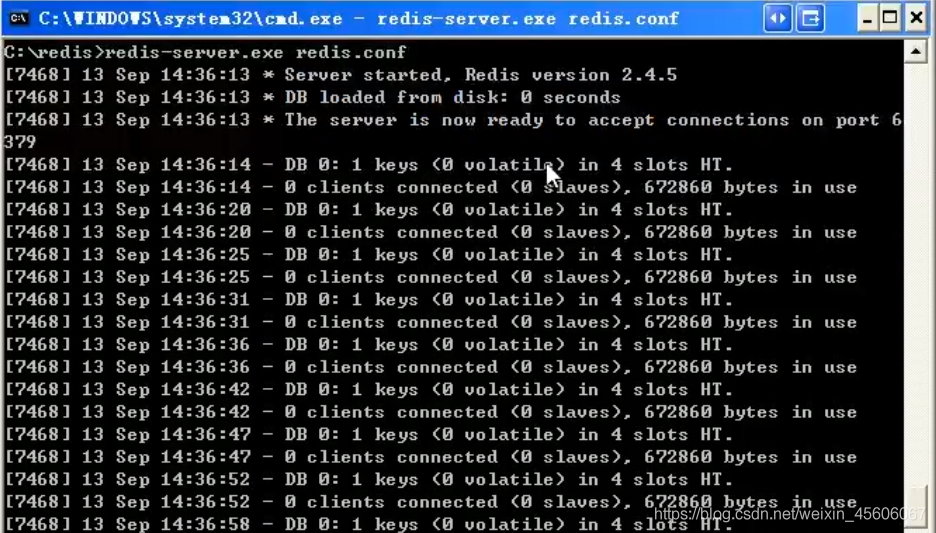
這時候另啓一個cmd視窗,原來不要關閉,不然就無法存取伺服器了。
切換到redis目錄下執行 redis-cli.exe -h 127.0.0.1 -p 6379 。
設定鍵值對 set myKey abc
取出鍵值對 get myKey
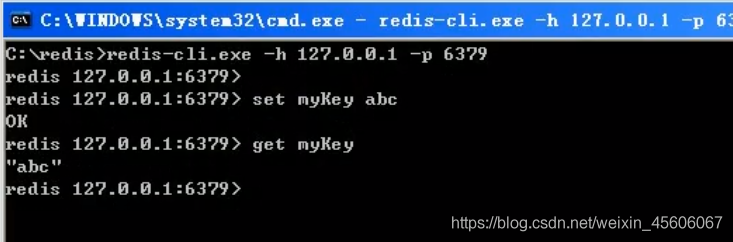
重要提示:由於企業裏面做redis開發,99%都是用Linux版的運用和安裝,幾乎不涉及到Windows版,上一步的講解只是爲了知識的完整性,windows版不作爲重點,企業實戰就認一個版:Linux
2)Linux版安裝
-
下載獲得 redis-3.0.4.tar.gz 後將它放入我們的Linux目錄 /opt 下
-
/opt目錄下,解壓命令:tar -zxvf redis-3.0.4.tar.gz
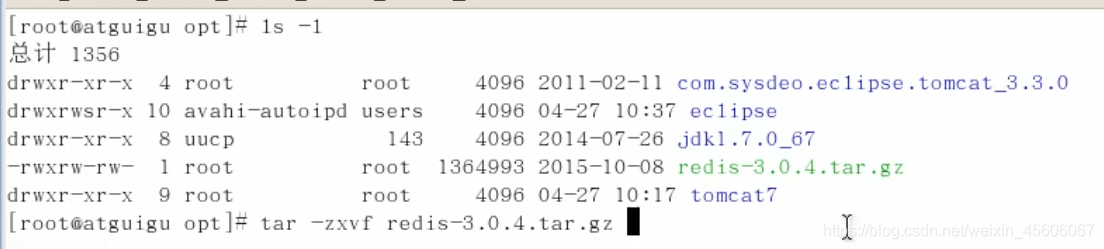
-
解壓完成後出現資料夾:redis-3.0.4
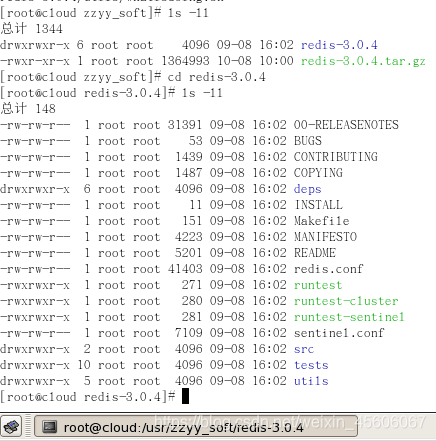
-
進入目錄:cd redis-3.0.4
-
在 redis-3.0.4目錄下執行
make命令執行 make 命令時故意出現的錯誤解析:【缺少gcc命令】

=-------------解決開始---------------=
1.安裝gcc
gcc是linux下的一個編譯程式,是C程式的編譯工具。
GCC(GNU Compiler Collection) 是 GNU(GNU’s Not Unix) 計劃提供的編譯器家族,它能夠支援 C, C++, Objective-C, Fortran, Java 和 Ada 等等程式設計語言前端,同時能夠執行在 x86, x86-64, IA-64, PowerPC, SPARC 和 Alpha 等等幾乎目前所有的硬體平臺上。鑑於這些特徵,以及 GCC 編譯程式碼的高效性,使得 GCC 成爲絕大多數自由軟件開發編譯的首選工具。雖然對於程式設計師們來說,編譯器只是一個工具,除了開發和維護人員,很少有人關注編譯器的發展,但是 GCC 的影響力是如此之大,它的效能提升甚至有望改善所有的自由軟體的執行效率,同時它的內部結構的變化也體現出現代編譯器發展的新特徵。能上網:yum install gcc-c++
不上網 :操作如下
① 從ISO映象中安裝gcc,按照下圖操作
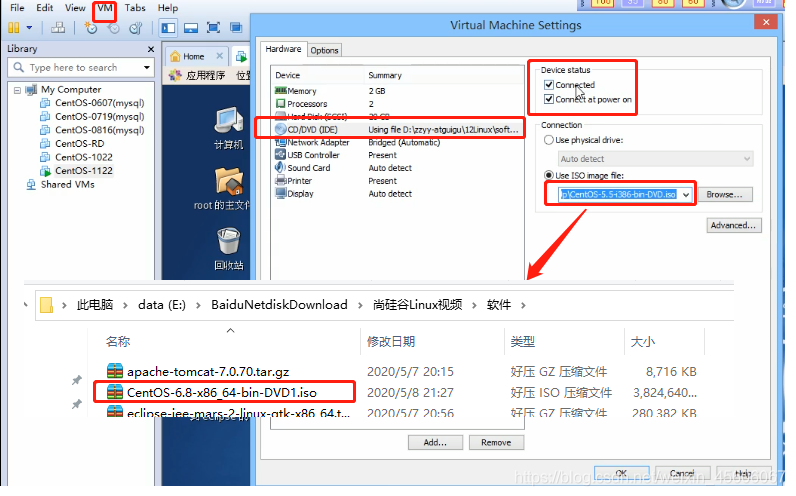
② 在終端中輸入 cd/media/CentOS_5.2_Final/CentOS 回車 (或者輸入pwd進行檢視)

③ 分別執行如下命令:rpm -ivh cpp-4.1.2-48.el5.i386.rpm 回車
rpm -ivh kernel-headers-2.6.18-194.el5.i386.rpm 回車
rpm -ivh glibc-headers-2.5-49.i386.rpm 回車
rpm -ivh glibc-devel-2.5-24.i386.rpm 回車
rpm -ivh libgomp-4.4.0-6.el5.i386.rpm 回車
rpm -ivh gcc-4.1.2-48.el5.i386.rpm 回車
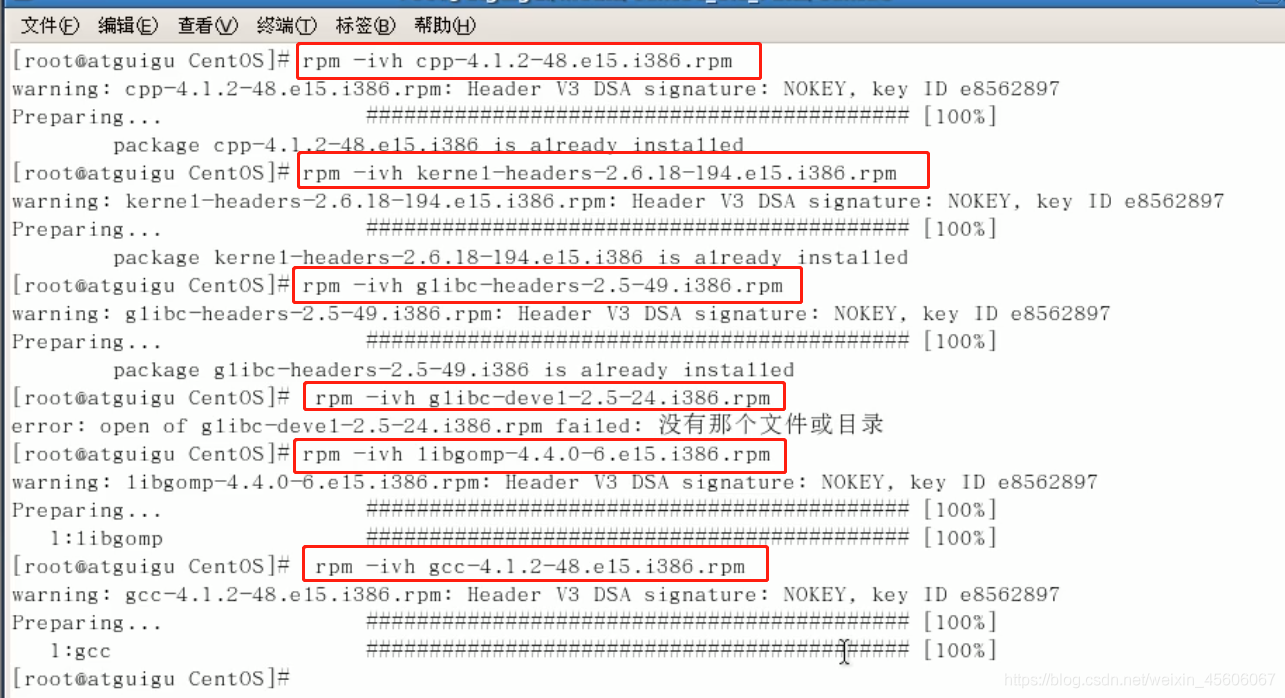
④ 之後執行:gcc -v
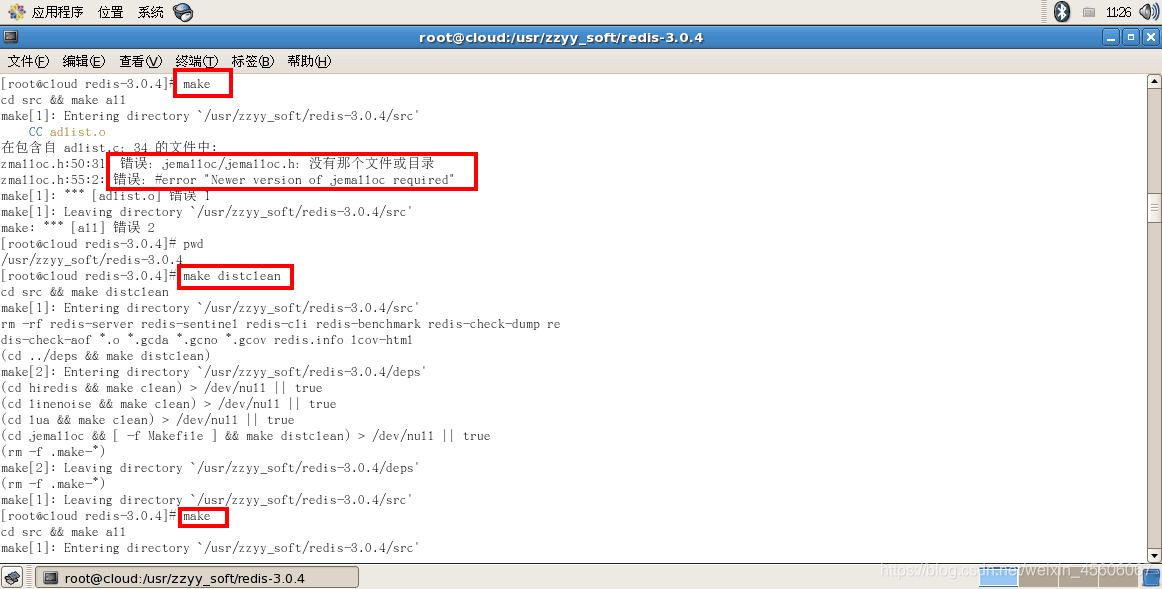
2.二次make
3.Jemalloc/jemalloc.h:沒有那個檔案或目錄
執行make distclean之後再 make
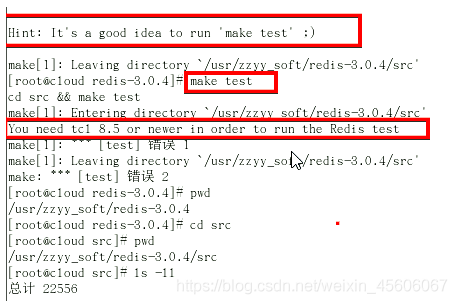
4.Redis Test【可以不用執行】
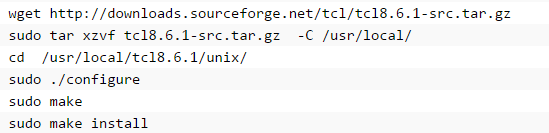
下載TCL的網址:http://www.linuxfromscratch.org/blfs/view/cvs/general/tcl.html安裝TCL:
=-------------結束---------------= -
如果make完成後繼續執行 make install
-
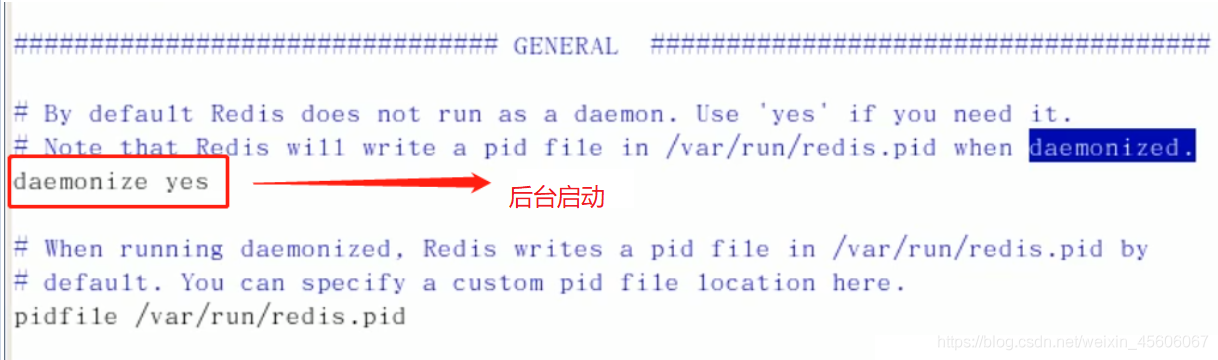
備份組態檔,以防出錯:此時redis的組態檔在/opt 下,我們可以在根目錄建立一個myredis目錄,將 redis.conf 組態檔拷貝到myredis中。修改組態檔中的
daemonize屬性。
mkdir myredis
cp redis.conf /myredis
vim redis.conf
-
此時Redis的安裝完成。。。
4、redis啓動與關閉
Redis-benchmark:效能測試工具,可以在自己本子執行,看看自己本子效能如何
- 服務啓動起來後執行
- Redis-check-aof:修復有問題的AOF檔案,rdb和aof後面文件說明。
- Redis-check-dump:修復有問題的dump.rdb檔案。
- Redis-cli:用戶端,操作入口。
- Redis-sentinel:redis叢集使用。
- Redis-server:Redis伺服器啓動命令。
檢視預設安裝目錄:/usr/local/bin
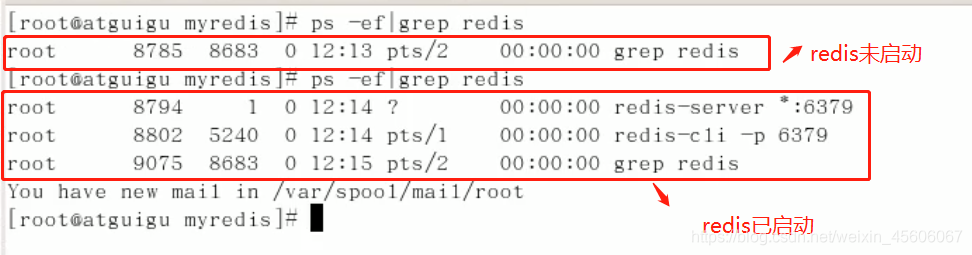
檢視我的redis是否啓用:ps -ef|grep redis 或者 lsof -i : 6379
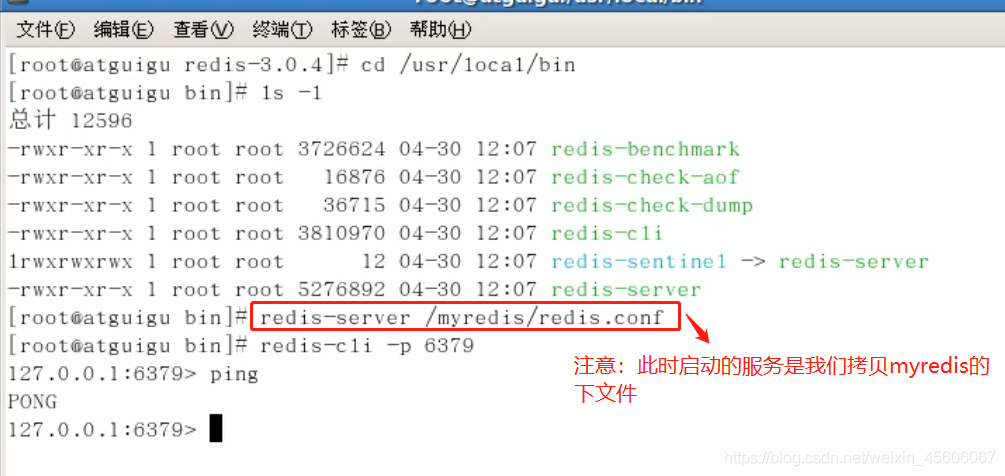
啓動並連通測試:
- 伺服器啓動:redis-server /myredis/redis.conf
- 使用者啓動:redis-cli -p 6379
helloworld案例

關閉服務
- 單範例關閉:redis-cli shutdown
- 多範例關閉,指定埠關閉:redis-cli -p 6379 shutdown

5、Redis啓動後雜亂項基礎知識
- 單進程
單進程模型來處理用戶端的請求。對讀寫等事件的響應是通過對 epoll 函數的包裝來做到的。Redis的實際處理速度完全依靠主進程的執行效率。
Epoll是Linux內核爲處理大批次檔案描述符而作了改進的epoll,是Linux下多路複用IO介面select/poll的增強版本,它能顯著提高程式在大量併發連線中只有少量活躍的情況下的系統CPU利用率。
- 預設16個數據庫,類似陣列下表從零開始,初始預設使用零號庫
設定數據庫的數量,預設數據庫爲0,可以使用 SELECT <dbid>命令在連線上指定數據庫id
databases 16
- Select:命令切換數據庫
- Dbsize:檢視當前數據庫的key的數量
- Flushdb:清空當前庫
- Flushall:通殺全部庫
- 統一密碼管理,16個庫都是同樣密碼,要麼都OK要麼一個也連線不上
- Redis索引都是從零開始
- 爲什麼預設埠是6379
如果有收穫!!! 希望老鐵們來個三連,點贊、收藏、轉發。
創作不易,別忘點個贊,可以讓更多的人看到這篇文章,順便鼓勵我寫出更好的部落格