如何讓你的程式賞析悅目-帕斯卡命名法
2020-08-10 12:02:26
帕斯卡命名法
屬性
| 字首 | 含義 |
|---|---|
| g_ | 全域性變數 |
| c_ | 常數 |
| m_ | c++類成員變數 |
| s_ | 靜態變數 |
型別
| 字首 | 含義 |
|---|---|
| a | 陣列 |
| p | 指針 |
| fn | 函數 |
| v | 無效 |
| l | 控制代碼 |
| h | 長整型 |
| b | 布爾 |
| f | 浮點型 、檔案 |
| dw | 雙字 |
| sz | 字串 |
| n | 短整型 |
| d | 雙精度浮點 |
| cnt | 計數 |
| c \ ch | 字元 |
| n \ i | 整型 |
| by | 位元組 |
| w | 字 |
| r | 實型 |
| u | 無符號 |
描述
| 字首 | 含義 |
|---|---|
| Max | 最大 |
| Min | 最小 |
| Init | 初始化 |
| Temp \ T | 臨時變數 |
| Src | 源物件 |
| Dest | 目標 |
帕斯卡命名法
- 帕斯卡命名法指當變數名和函式名稱是由二個或二個以上單詞連結在一起,每個單詞首字母大寫。
- 單字之間不以空格斷開或連線號(-)、底線(_)連結,第一個單詞首字母採用大寫字母;後續單詞的首字母亦用大寫字母,例如:FirstName、LastName。 也有人稱之爲大駝峯式命名法(Upper Camel Case) 。
下劃線命名法
- 下劃線命名法變數名和函式名稱是由二個或二個以上單詞連結在一起,每個單詞用下劃線隔開並且單詞都是小寫。
- 例如:print_employee。下劃線命名法是隨着C語言的出現流行起來的,在UNIX/LIUNX這樣的環境,以及GNU程式碼中使用非常普遍。
檔案與目錄
檔案的命名
- 檔案的命名要準確清晰地表達其內容,同時檔名應該精練,防止檔名過長而造成使用不便。在檔名中可以適當地使用縮寫。以下提供兩種命名方式以供參考:
- 各程式模組的檔案命名開頭 2 個消協字母代表本模組的功能:
如:主控程式爲 mpMain.c,mpDisp.c 等。
- 不寫模組功能標識:
如:主控程式爲 Main.c,Disp.c 等。
標頭檔案中段落安排順序
// 檔案頭註釋
// 防止重複參照標頭檔案的設定
// #include 部分
// enum 常數宣告
// 型別宣告和定義,包括 struct、union、typedef 等
// 全域性變數宣告
// 檔案級變數宣告
// 全域性或檔案級函數宣告
// 函數實現。按函數宣告的順序排列
// 檔案尾註釋
在參照標頭檔案時,不要使用絕對路徑
- 如果使用絕對路徑,當需要移動目錄時,必須修改所有相關程式碼,繁瑣且不安全;使用相對路徑,當需要移動目錄時,只需修改編譯器的某個選項即可。例如:
#include 「/project/inc/hello.h」 /* 不應使用絕對路徑 */
#include 「../inc/hello.h」 /* 可以使用相對路徑 */
在參照標頭檔案時 ,使用<>還是""
#include <stdio.h> /* 標準標頭檔案 */
#include <projdefs.h> /* 工程制定目錄標頭檔案 */
#include 「global.h」 /* 當前目錄標頭檔案 */
#include 「inc/config.h」 /* 路徑相對於當前目錄的標頭檔案 */
防止標頭檔案被重複參照
#ifndef __DISP_H /* 檔名前名加兩個下劃線「__」,後面加 「_H」
#define __DISP_H
//...
//...
#endif
標頭檔案中只存放「宣告」而不存放「定義」
/* 模組1標頭檔案:module1.h */
extern int a = 5;
/* 在模組1的 .h 檔案中宣告變數 */
檔案的長度
- 檔案的長度沒有非常嚴格的要求,但應儘量避免檔案過長。一般來說,檔案長度應儘量保持在 1000 行之內 。
排版
- 程式塊要採用縮排風格編寫,縮排的空格數爲 4 個。
- 相對獨立的程式塊之間、變數說明之後必須加空行 。
void DemoFunc(void){
uint8_t i;
/* 功能塊1 */
for(i = 0; i < 10; i++){
}
//不同的功能塊間空一行
/* 功能塊2 */
for(i = 0; i < 10; i++){
}
}
- 較長的語句或函數過程參數(>80 字元)要分成多行書寫,長表達式要在低優先順序操作符處劃分新行,操作符放在新行之首,劃分出的新行要進行適當的縮排,使排版整齊,語句可讀。
if((ucParam1 == 0) && (ucParam2 == 0) && (uParam3 == 0))
|| (ucParam4 == 0){
//長表達式需要換行書寫
}
- 不允許把多個短語句寫在一行中,即一行只寫一條語句
rect.length = 0; rect.width = 0;//錯誤寫法
rect.length = 0;
rect.width = 0;//正確寫法
程式塊的分界符(如大括號‘{’和‘}’ )應各獨佔一行並且位於同一列
~~for(){
}//不規範
for()
{
}//規範~~
- 在兩個以上的關鍵字、變數、常數進行對等操作時,它們之間的操作符之前、之後或者前後要加空格;進行非對等操作時,如果是關係密切的立即操作符(如->),後不應加空格。
範例:
- 逗號、分號只在後面加空格。
int_32 a, b, c;
- 比較操作符,賦值操作符"="、 「+=」,算術操作符"+"、"%",邏輯操作符"&&"、"&",位域操作符"<<"、"^"等雙目操作符的前後加空格。
if(current_time >= MAX_TIME_VALUE)
a = b + c;
a *= 2;
a = b ^ 2;
- 「!」、"~"、"++"、"–"、"&"(地址運算子)等單目操作符前後不加空格。
*p = 'a';
flag = !sEmpty;
p = &mem;
i++;
- 「->」、"."前後不加空格。
p->id = pid;
- if、for、while、switch 等與後面的括號間應加空格,使 if 等關鍵字更爲突出、明顯,函數名與其後的括號之間不加空格,以與保留字區別開。
if (a>=b && c >d){
}
註釋
一般的,源程式有效註釋量必須在 20%以上。
- 註釋的原則是有助於對程式的閱讀理解,在該加的地方都加,註釋不宜太多也不能太少,註釋語言必須準確、易懂、簡潔 。
在檔案的開始部分,應該給出關於檔案版權、內容簡介、修改歷史等專案的說明。
- 在建立程式碼和每次更新程式碼時,都必須在檔案的歷史記錄中標註版本號、日期、作者、更改說明等專案。下面 下麪是一個範例,當然,並不侷限於此格式,但上述資訊建議要包含在內。
對於函數,在函數實現之前,應該給出和函數的實現相關的足夠而精練的註釋資訊。
邊寫程式碼邊註釋,修改程式碼同時修改相應的註釋,以保證註釋與程式碼的一致性。不再有用的註釋要刪除。
註釋的內容要清楚、明瞭,含義準確,防止註釋二義性。
- 錯誤的註釋不但無益反而有害。註釋主要闡述程式碼做了什麼(What),或者如果有必要的話,闡述爲什麼要這麼做(Why),註釋並不是用來闡述它究竟是如何實現演算法(How)的。
避免在註釋中使用縮寫,特別是非常用縮寫。
- 說明:在使用縮寫時或之前,應對縮寫進行必要的說明。
註釋應與其描述的程式碼靠近,對程式碼的註釋應放在其上方或右方(對單條語句的註釋)相鄰位置, 不可放在下面 下麪,如放於上方則需與其上面的程式碼用空行隔開。
範例:如下例子不符合規範。
- 例 1:不規範的寫法
/* 測試 */
//規範寫法無此空行
test_id = test[index].index;
test_val = test[index].value;
- 例 2:不規範的寫法
test_id = test[index].index;
test_val = test[index].value;
/* 測試 */ //規範寫法註釋應在語句前
- 例 3:規範的寫法
/* 測試 */
test_id = test[index].index;
test_val = test[index].value;
- 例 4:不規範的寫法,顯得程式碼過於緊湊
/* code one comments */
program code one
/* code two comments */
program code two
- 例 5:規範的寫法
/* code one comments */
program code one
/* code two comments */
program code two
註釋與所描述內容進行同樣的縮排
- 可使程式排版整齊,並方便註釋的閱讀與理解。
- 例 1:如下例子,排版不整齊,閱讀稍感不方便。
void example_fun( void )
{
/* code one comments */
CodeBlock One
/* code two comments */
CodeBlock Two
}
- 例 2:正確的佈局。
void example_fun(void){
/* code one comments */
CodeBlock One
/* code two comments */
CodeBlock Two
}
對變數的定義和分支語句(條件分支、回圈語句等)必須編寫註釋
- 這些語句往往是程式實現某一特定功能的關鍵,對於維護人員來說,良好的註釋幫助更好的理解程式,有時甚至優於看設計文件。
對於 switch 語句下的 case 語句,如果因爲特殊情況需要處理完一個 case 後進入下一個 case 處理,必須在該 case 語句處理完、下一個 case 語句前加上明確的註釋
- 這樣比較清楚程式編寫者的意圖,有效防止無故遺漏 break 語句。
- 範例(注意斜體加粗部分):
case CMD_FWD:
ProcessFwd():
if(){
}
if(){
***ProcessCFW_B(); /* now junp into case CMD_A */***
}
case CMD_A:
ProcessA();
break
註釋格式儘量統一,建議使用「/* …… */」,因爲 C++註釋「//」並不被所有 C 編譯器支援
註釋應考慮程式易讀及外觀排版的因素,使用的語言若是中、英兼有的,建議多使用中文,除非能非常流利準確的用英文表達
- 註釋語言不統一,影響程式易讀性和外觀排版,出於對維護人員的考慮,建議使用中文。
識別符號的命名要清晰、明瞭,有明確含義,同時使用完整的單詞或大家基本可以理解的縮寫,避 免使人產生誤解
- 較短的單詞可通過去掉「元音」形成縮寫;較長的單詞可取單詞的頭幾個字母形成縮寫;一些單詞有大家公認的縮寫。
- 範例:如下單詞的縮寫能夠被大家基本認可。
temp 可縮寫爲 tmp;
flag 可縮寫爲 flg;
statistic 可縮寫爲 stat;
increment 可縮寫爲 inc;
message 可縮寫爲 msg;
命名中若使用特殊約定或縮寫,則要有註釋說明
- 應該在原始檔的開始之處,對檔案中所使用的縮寫或約定,特別是特殊的縮寫,進行必要的註釋說明。
自己特有的命名風格,要自始至終保持一致,不可來回變化
- 個人的命名風格,在符合所在專案組或產品組的命名規則的前提下,纔可使用。(即命名規則中沒有規定到的地方纔可有個人命名風格)
對於變數命名,禁止取單個字元(如 i、j、k…)
- 建議除了要有具體含義外,還能表明其變數型別、數據型別等,但 i、j、k 作區域性回圈變數是允許的。變數,尤其是區域性變數,如果用單個字元表示,很容易敲錯(如i寫成j),而編譯時又檢查不出來,有可能爲了這個小小的錯誤而花費大量的查錯時間 。
命名規範必須與所使用的系統風格保持一致,並在同一專案中統一
- 比如採用 UNIX 的全小寫加下劃線的風格或大小寫混排的方式,不要使用大小寫與下劃線混排的方式,用作特殊標識如標識成員變數或全域性變數的 m_和 g_,其後加上大小寫混排的方式是允許的。
- 範例:Add_User不允許,add_user、AddUser、m_AddUser允許。
除非必要,不要用數位或較奇怪的字元來定義識別符號
- 範例:如下命名,使人產生疑惑。
uint8_t dat01;
void Set00(uint8_t c);
應改爲有意義的單詞命名:
uint8_t ucWidth;
void SetParam(uint8_t _ucValue);
可讀性
注意運算子的優先順序,並用括號明確表達式的操作順序,避免使用預設優先順序
- 正確寫法
word = (high << 8) | low;
if ((a | b) && (a &c))
if ((a | b) < (c &d))
- 錯誤寫法
word = high << 8 | low
if (a | b && a & c)
if (a | b < c & d)
避免使用不易理解的數位,用有意義的標識來替代
- 範例:如下的程式可讀性差
if (Trunk[index].trunk_state == 0) {
Trunk[index].trunk_state = 1;
}
應改爲如下形式 :
if (Trunk[index].trunk_state == 0) {
Trunk[index].trunk_state = TRUNK_BUSY;
}
不要使用難懂的技巧性很高的語句,除非很有必要時
- 高技巧語句不等於高效率的程式,實際上程式的效率關鍵在於演算法。
- 如下表達式,考慮不周就可能出問題,也較難理解。
* stat_poi ++ +=1
* ++ stat_poi += 1;
應分別改爲如下:
*stat_poi +=1;
stat_poi++; /* 相當於 "stat_poi ++ +=1"*/
++stat_poi;
*stat_poi += 1; /* 相當於 "++ stat_poi += 1;"*/
變數、 結構、 常數、 宏
爲了方便書寫及記憶,變數型別採用如下重定義
typedef unsigned char uint8_t
typedef unsigned short uint16_t
typedef unsigned long int uint32_t
typedef signed char int8_t
typedef signed short int16_t
typedef signed long int int32_t
常見型別的字首
- 對於一些常見型別的變數,應在其名字前標註表示其型別的字首。字首用小寫字母表示。字首的使用請參照下列表格中說明。
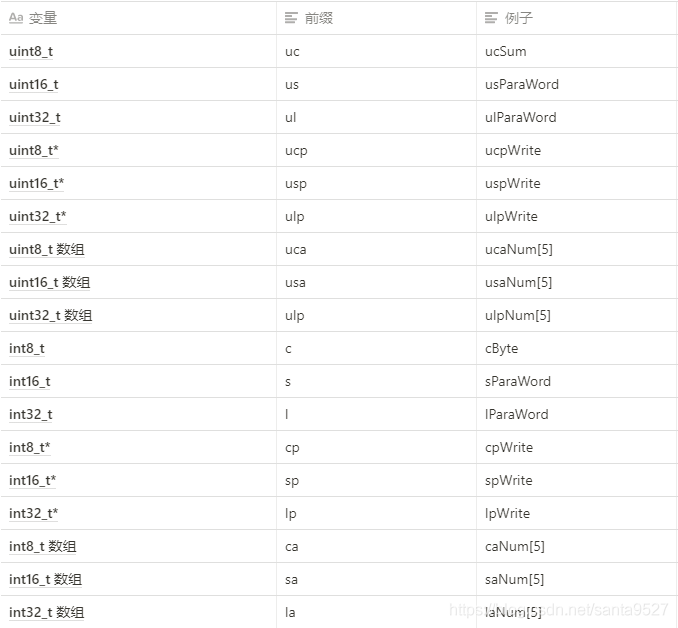
變數作用域的字首
- 爲了清晰的標識變數的作用域,減少發生命名衝突,應該在變數型別字首之前再加上表示變數作用域的字首,並在變數型別字首和變數作用域字首之間用下劃線 - 隔開。
- 具體的規則如下:
對於全域性變數(global variable),在其名稱前加g和變數型別符號字首。
uint32_t g_ulParaWord;
uint8_t g_ucByte;
對於靜態變數(static variable),在其名稱前加s和變數型別符號字首。
static uint32_t s_ulParaWord;
static uint8_t s_ucByte;
- 函數內部等區域性變數前不加作用域字首。
- 對於常數,當可能發生作用域和名字衝突問題時,以上幾條規則對於常數同樣適用。注意,雖然常數名的核心部分全部大寫,但此時常數的字首仍然用小寫字母,以保持字首的一致性。
結構體命名規則
- 表示型別的名字,所有名字以小寫字母tag開頭,之後每個英文單詞的第一個字母大寫(包括第一個單詞的第一個字母),其他字母小寫,結尾_T 標識。單詞之間不使用下劃線分隔,結構體變數以 t 開頭。如:
typedef enum{
KB_F1 = 0; /* F1鍵程式碼 */
KB_F2,
KB_F3
}KEY_CODE_E;
對於列舉定義全部採用大寫,結尾_E 標識。
常數、宏、模版的名字應該全部大寫。如果這些名字由多個單詞組成,則單詞之間用下劃線分隔。
#define LOG_BUF_SIZE 8000
函數
函數的命名規則。
- 每一個函數名字首需包含模組名,模組名爲小寫,與函數名區別開。
uartReceive(串列埠接收)
- 備註:對於非常簡單的程式,可以不加模組名。
函數的形參。
函數的的形參都以下劃線_開頭,已示與普通變數進行區分,對於沒有形參爲空的函數(void)括號緊跟函數後面。
uint32_t uartConvUartBaud(uint32_t _ulBaud){
}
一個函數僅完成一件功能。
函數名應準確描述函數的功能,使用動賓詞組爲執行某操作的函數命名。
- 避免用含義不清的動詞如process、handle等爲函數命名,因爲這些動詞並沒有說明要具體做什麼。
- 參照如下方式命名函數。
void PrintRecord(uint32_t _RecInd);
int32 InputRecord(void);
uint8_t GetCurrentColor(void);
避免設計五個以上參數函數,不使用的參數從介面中去掉。
- 目的減少函數間介面的複雜度,複雜的參數可以使用結構傳遞。
在呼叫函數填寫參數時,應儘量減少沒有必要的預設數據型別轉換或強制數據型別轉換。
- 因爲數據型別轉換或多或少存在危險。
防止把沒有關聯的語句放到一個函數中。
- 如下函數就是一種隨機內聚。
void InitVar(void){
Rect.length = 0;
Rect.Width = 0; /* 初始化矩形的長寬 */
Point.x = 10;
Point.y = 10; /* 初始化點的座標 */
}
- 矩形的長、寬與點的座標基本沒有任何關係,故以上函數是隨機內聚。應如下分爲兩個函數:
void InitRect(void){
Rect.length = 0;
Rect.Width = 0; /* 初始化矩形的長寬 */
}
void InitPoint(void){
Point.x = 10;
Point.y = 10; /* 初始化點的座標 */
}
- 文章內容總結於網路與書籍,可能與其他部落格大同小異,見諒。