c++面試常見問題彙總與解析
c++面試常見問題彙總與解析
- 1.指針和參照的區別
- 2.堆和棧的區別
- 3.new和delete是如何實現的,new 與 malloc的異同處
- 4.C和C++的區別
- 5.C++、Java的聯繫與區別,包括語言特性、垃圾回收、應用場景等(java的垃圾回收機制 機製)
- 6.Struct和class的區別
- 7. define 和const的區別(編譯階段、安全性、記憶體佔用等)
- 8. 在C++中const和static的用法(定義,用途)
- 9. C++中的const類成員函數(用法和意義),以及和非const成員函數的區別
- 10. C++的頂層const和底層const
- 11. final和override關鍵字
- 12. 拷貝初始化和直接初始化
- 13. 初始化和賦值的區別
- 14. extern "C"的用法
- 15. 模板函數和模板類的特例化
- 16. C++的STL原始碼(這個系列也很重要,建議侯捷老師的STL原始碼剖析書籍與視訊),其中包括記憶體池機制 機製,各種容器的底層實現機制 機製,演算法的實現原理等)
- 17. STL原始碼中的hashtable的實現
- 18. STL中unordered_map和map的區別和應用場景
- 19. STL中vector的實現
- 20. STL容器的幾種迭代器以及對應的容器(輸入迭代器,輸出迭代器,前向迭代器,雙向迭代器,隨機存取迭代器)
- 21. STL中的traits技法
- 22. vector使用的注意點及其原因,頻繁對vector呼叫push_back()對效能的影響和原因。
- 23. C++中的過載和重寫的區別
- 24. C++記憶體管理,記憶體池技術(熱門問題),與csapp中幾種記憶體分配方式對比學習加深理解
- 25. 介紹物件導向的三大特性,並且舉例說明每一個
- 26. C++多型的實現
- 27. C++虛擬函式相關(虛擬函式表,虛擬函式指針),虛擬函式的實現原理(包括單一繼承,多重繼承等)(拓展問題:爲什麼基礎類別指針指向派生類物件時可以呼叫派生類成員函數,基礎類別的虛擬函式存放在記憶體的什麼區,虛擬函式表指針vptr的初始化時間)
- 28. C++中類的數據成員和成員函數記憶體分佈情況
- 29. this指針
- 30. 解構函式一般寫成虛擬函式的原因
- 31. 建構函式、拷貝建構函式和賦值操作符的區別
- 32. 建構函式宣告爲explicit
- 33. 建構函式爲什麼一般不定義爲虛擬函式
- 34. 建構函式的幾種關鍵字(default delete 0)
- 35. 建構函式或者解構函式中呼叫虛擬函式會怎樣
- 36. 純虛擬函式
- 37. 靜態型別和動態型別,靜態系結和動態系結的介紹
- 38. 參照是否能實現動態系結,爲什麼參照可以實現
- 39. 深拷貝和淺拷貝的區別(舉例說明深拷貝的安全性)
- 40. 物件複用的瞭解,零拷貝的瞭解
- 41. 介紹C++所有的建構函式
- 42. 什麼情況下會呼叫拷貝建構函式(三種情況)
- 43. 結構體記憶體對齊方式和爲什麼要進行記憶體對齊?
- 44. 記憶體泄露的定義,如何檢測與避免?
- 45. 手寫智慧指針的實現(shared_ptr和weak_ptr實現的區別)
- 46. 智慧指針的回圈參照
- 47. 遇到coredump要怎麼偵錯
- 48. 記憶體檢查工具的瞭解
- 49. 模板的用法與適用場景
- 50. 成員初始化列表的概念,爲什麼用成員初始化列表會快一些(效能優勢)?
- 51. 用過C++ 11嗎,知道C++ 11哪些新特性?
- 52. C++的呼叫慣例(簡單一點C++函數呼叫的壓棧過程)
- 53. C++的四種強制轉換
- 54. C++中將臨時變數作爲返回值的時候的處理過程(棧上的記憶體分配、拷貝過程)
- 55. C++的例外處理
- 56. volatile關鍵字
- 57. 優化程式的幾種方法
- 58. public,protected和private存取許可權和繼承
- 60. decltype()和auto
- 61. inline和宏定義的區別
- 62. C++和C的型別安全
- 63. 參考鏈接
1.指針和參照的區別
(1)指針有自己的一塊空間,而參照只是一個別名;
(2)使用 sizeof 看一個指針的大小爲4位元組(32位元,如果要是64位元的話指針爲8位元組),而參照則是被參照物件的大小。
(3)指針可以被初始化爲 NULL,而參照必須被初始化且必須是一個已有物件的參照。
(4)作爲參數傳遞時,指針需要被解除參照纔可以對物件進行操作,而直接對參照的修改都會改變參照所指向的物件。
(5)指針在使用中可以指向其他物件,但是參照只能是一個物件的參照,不能被改變。
(6)指針可以是多級,而參照沒有分級
(7)如果返回動態分配記憶體的物件或者記憶體,必須使用指針,參照可能引起記憶體漏失。
2.堆和棧的區別
(1)堆疊空間分配區別:
- 棧(操作系統):由操作系統自動分配釋放 ,存放函數的參數值,區域性變數的值等。其操作方式類似於數據結構中的棧;
- 堆(操作系統): 一般由程式設計師分配釋放, 若程式設計師不釋放,程式結束時可能由OS回收,分配方式倒是類似於鏈表。
(2)堆疊的快取方式區別
- 棧:是記憶體中儲存值型別的,大小爲2M(window,linux下預設爲8M,可以更改),超出則會報錯,記憶體溢位
- 堆:記憶體中,儲存的是參照數據型別,參照數據型別無法確定大小,堆實際上是一個在記憶體中使用到記憶體中零散空間的鏈表結構的儲存空間,堆的大小由參照型別的大小直接決定,參照型別的大小的變化直接影響到堆的變化
(3)堆疊數據結構上的區別
堆(數據結構):堆可以被看成是一棵樹,如:堆排序;
棧(數據結構):一種先進後出的數據結構。
3.new和delete是如何實現的,new 與 malloc的異同處
3.1. new操作針對數據型別的處理,分爲兩種情況:
(1) 簡單數據型別(包括基本數據型別和不需要建構函式的型別)
- 簡單型別直接呼叫 operator new 分配記憶體;
- 可以通過new_handler 來處理 new 失敗的情況;
- new 分配失敗的時候不像 malloc 那樣返回
NULL,它直接拋出異常(bad_alloc)。要判斷是否分配成功應該用異常捕獲的機制 機製;
(2)複雜數據型別(需要由建構函式初始化物件)
- new 複雜數據型別的時候先呼叫operator new,然後在分配的記憶體上呼叫建構函式。
3.2. delete也分爲兩種情況:
(1) 簡單數據型別(包括基本數據型別和不需要解構函式的型別)
- delete簡單數據型別預設只是呼叫free函數。
(2)複雜數據型別(需要由解構函式銷燬物件)
- delete複雜數據型別先呼叫解構函式再呼叫operator delete。 從原理上來分析可以看看這篇部落格:C++
new和delete的實現原理
3.3. new和delete與 malloc 和 free 的區別:
(1)屬性上:new / delete 是c++關鍵字,需要編譯器支援。 malloc/free是庫函數,需要c的標頭檔案支援。
(2)參數:使用new操作符申請記憶體分配時無須制定記憶體塊的大小,編譯器會根據型別資訊自行計算。而mallco則需要顯式地指出所需記憶體的尺寸。
(3)返回型別:new操作符記憶體分配成功時,返回的是物件型別的指針,型別嚴格與物件匹配,故new是符合型別安全性的操作符。而malloc記憶體成功分配返回的是void *,需要通過型別轉換將其轉換爲我們需要的型別。
(4)分配失敗時:new記憶體分配失敗時拋出bad_alloc異常;malloc分配記憶體失敗時返回 NULL。
(5)自定義型別:new會先呼叫operator new函數,申請足夠的記憶體(通常底層使用malloc實現)。然後呼叫型別的建構函式,初始化成員變數,最後返回自定義型別指針。delete先呼叫解構函式,然後呼叫operator delete函數釋放記憶體(通常底層使用free實現)。 malloc/free是庫函數,只能動態的申請和釋放記憶體,無法強制要求其做自定義型別物件構造和解構工作。
(6)過載:C++允許過載 new/delete 操作符。而malloc爲庫函數不允許過載。
(7)記憶體區域:new操作符從自由儲存區(free store)上爲物件動態分配記憶體空間,而malloc函數從堆上動態分配記憶體。其中自由儲存區爲:C++基於new操作符的一個抽象概念,凡是通過new操作符進行記憶體申請,該記憶體即爲自由儲存區。而堆是操作系統中的術語,是操作系統所維護的一塊特殊記憶體,用於程式的記憶體動態分配,C語言使用malloc從堆上分配記憶體,使用free釋放已分配的對應記憶體。自由儲存區不等於堆,如上所述,佈局new就可以不位於堆中。
4.C和C++的區別
C 是程序導向的一門程式語言,C++ 可以很好地進行物件導向的程式設計。C++ 雖然主要是以 C 的基礎發展起來的一門新語言,但它不是 C 的替代品,它們是兄弟關係。物件導向和麪向過程不是矛盾的,而是各有用途、互爲補充的。
C++ 對 C 的增強,表現在六個方面:
- 增強了型別檢查機制 機製
- 增加了物件導向的機制 機製
- 增加了泛型程式設計的機制 機製(template)
- 增加了例外處理
- 增加了過載的機制 機製
增加了標準模板庫(STL)
(1)型別檢查
C/C++ 是靜態數據型別語言,型別檢查發生在編譯時,因此編譯器知道程式中每一個變數對應的數據型別。C++ 的型別檢查相對更嚴格一些。
很多時候需要一種能夠實際表示多種型別的數據型別。傳統上 C 使用 void* 指針指向不同對象,使用時強制轉換回原始型別或相容型別。這樣做的缺陷是繞過了編譯器的型別檢查,如果錯誤轉換了型別並使用,會造成程式崩潰等嚴重問題。
C++ 通過使用基礎類別指針或參照來代替 void* 的使用,避免了這個問題(其實也是體現了類繼承的多型性)。
物件導向
C 的結構體傳遞的是一種數據結構,我們只是在主函數裏面對這種數據型別做某種呼叫。主函數的架構依然是基於函數、函數族的處理過程,即程序導向。
C++ 中最大的區別就是允許在結構體中封裝函數,而在其他的地方直接呼叫這個函數。這個封裝好的可直接呼叫的模組有個新名詞——物件;並且也把結構體換一個名字——類。這就是物件導向的思想。在構建物件的時候,把物件的一些操作全部定義好並且給出介面的方式,對於外部使用者而言,可以不需要知道函數的處理過程,只需要知道呼叫方式、傳遞參數、返回值、處理結果。
泛型程式設計(template)
所謂泛型程式設計,簡而言之就是不同的型別採用相同的方式來操作。在 C++ 的使用過程中,直接 template 用的不多,但是用 template 寫的庫是不可能不用的。因此需要對泛型有比較深入的瞭解,纔可以更好地使用這些庫。
C++ 裏面的模版技術具有比類、函數更高的抽象水平,因爲模版能夠生成出(範例化)類和函數。可以用來:
例外處理
C 語言不提供對錯誤處理的直接支援,但它以返回值的形式允許程式設計師存取底層數據。在發生錯誤時,大多數的 C 或 UNIX 函數呼叫返回 1 或 NULL,同時會設定一個錯誤程式碼 errno,該錯誤程式碼是全域性變數,表示在函數呼叫期間發生了錯誤。可以在 errno.h 標頭檔案中找到各種各樣的錯誤程式碼。
所以,C 程式設計師可以通過檢查返回值,然後根據返回值決定採取哪種適當的動作。開發人員應該在程式初始化時,把 errno 設定爲 0(表示沒有錯誤),這是一種良好的程式設計習慣。
C++ 提供了一系列標準的異常,定義在 中,我們可以在程式中使用這些標準的異常。
函數過載 & 運算子過載
C++ 可以實現函數過載,條件是:函數名必須相同,返回值型別也必須相同,但參數的個數、型別或順序至少有其一不同。
過載的運算子是帶有特殊名稱的函數,函數名是由關鍵字 operator 和其後要過載的運算子符號構成的。大多數的過載運算子可被定義爲普通的非成員函數(func(a, b) 形式呼叫)或者被定義爲類成員函數(a.func(b) 形式呼叫)。
標準模板庫(STL)
5.C++、Java的聯繫與區別,包括語言特性、垃圾回收、應用場景等(java的垃圾回收機制 機製)
通常,我們聊到Java,第一印象「物件導向」,「沒有指針,編寫效率高,執行效率較低」。更深入、專業一點就談論 「java記憶體自動回收(GC垃圾回收機制 機製),多執行緒程式設計」。**
java的三大特性是封裝、繼承和多型。**
總結如下:
(1) JAVA的應用在高層,C++在中介軟體和底層
(2) JAVA離不開業務邏輯,而C++可以離開業務爲JAVA們服務
(3) java語言給開發人員提供了更爲簡潔的語法;取消了指針帶來更高的程式碼品質;完全物件導向,獨特的執行機制 機製是其具有天然的可移植性。
(4) java 是執行在JVM上的,之所以說它的可移植性強,是因爲jvm可以安裝到任何的系統
(5) c++不是不能在其他系統執行,而是c++在不同的系統上執行,需要不同的編碼(這一點不如java,只編寫一次程式碼,到處執行)。java程式一般都是生成位元組碼,在JVM裏面執行得到結果。
(6) java 在web 應用上具有c++ 無可比擬的優勢
(7) java在桌面程式上不如c++實用,C++可以直接編譯成exe檔案,指針是c++的優勢,可以直接對記憶體的操作,但同時具有危險性 。(操作記憶體的確是一項非常危險的事情,一旦指針指向的位置發生錯誤,或者誤刪除了記憶體中某個地址單元存放的重要數據,後果是可想而知的)。
(8) 垃圾回收機制 機製的區別。c++用解構函式回收垃圾,java自動回收(GC演算法),寫C和C++程式時一定要注意記憶體的申請和釋放。
(9) java 豐富的外掛是java 發展如此迅速的原因
(10)java 很大的沿襲了c++的一些實用結構
(11)對於底層程式的程式設計以及控制方面的程式設計,c++很靈活,因爲有控制代碼的存在。Java並不僅僅是C++語言的一個變種,它們在某些本質問題上有根本的不同:
- Java比C++程式可靠性更高。有人曾估計每50行C++程式中至少有一個BUG。姑且不去討論這個數位是否誇張,但是任何一個C++程式設計師都不得不承認C++語言在提供強大的功能的同時也提高了程式含BUG的可能性。Java語言通過改變語言的特性大大提高了程式的可靠性。
- Java語言不需要程式對記憶體進行分配和回收。Java丟棄了C++
中很少使用的、很難理解的、令人迷惑的那些特性,如操作符過載、多繼承、自動的強制型別轉換。特別地,Java語言不使用指針,並提供了自動的廢料收集,在Java語言中,記憶體的分配和回收都是自動進行的,程式設計師無須考慮記憶體碎片的問題。 - Java語言中沒有指針的概念,引入了真正的陣列。不同於C++中利用指針實現的「僞陣列」,Java引入了真正的陣列,同時將容易造成麻煩的指針從語言中去掉,這將有利於防止在c++程式中常見的因爲陣列操作越界等指針操作而對系統數據進行非法讀寫帶來的不安全問題。
- Java用介面(Interface)技術取代C++程式中的多繼承性。介面與多繼承有同樣的功能,但是省卻了多繼承在實現和維護上的複雜性。
6.Struct和class的區別
(1)首先說一下C中的結構體和C++中的結構體的異同:
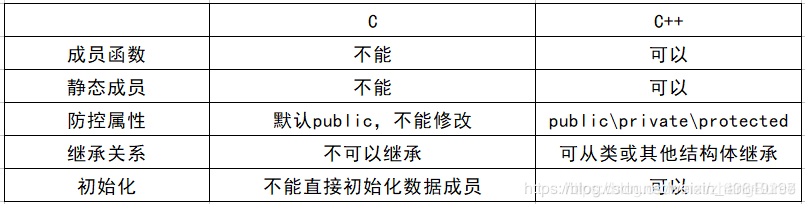
(2)C++中 struct 與 class 的區別:
- 內部成員變數及成員函數的預設存取屬性:struct 預設防控屬性是 public 的,而 class 預設的存取屬性是private的
- 繼承關係中預設存取屬性的區別:在繼承關係,struct 預設是 public 的,而 class 是 private
- class這個關鍵字還可用於定義模板參數,就等同於 typename;而strcut不用與定義模板參數
7. define 和const的區別(編譯階段、安全性、記憶體佔用等)
(1)起作用的階段: #define是在編譯的預處理階段起作用,而const是在編譯、執行的時候起作用。
(2)作用的方式:const常數有數據型別,而宏常數沒有數據型別,只是簡單的字串替換。編譯器可以對前者進行型別安全檢查。而對後者沒有型別安全檢查,並且在字元替換時可能會產生意料不到的錯誤。
(3)儲存的方式:#define只是進行展開,有多少地方使用,就替換多少次,它定義的宏常數在記憶體中有若幹個備份;const定義的只讀變數在程式執行過程中只有一份備份,const比較節省空間,避免不必要的記憶體分配,提高效率。
8. 在C++中const和static的用法(定義,用途)
(1)static:
- 修飾全域性變數:儲存在靜態儲存區;未經初始化的全域性靜態變數自動初始化爲 0;作用域爲整個檔案之內。
- 修飾區域性變數:儲存在靜態儲存;未經初始化的區域性靜態變數會被初始化爲0;作用域爲區域性作用域,但離開作用域不被銷燬。
- 修飾靜態函數:靜態函數只能在宣告的檔案中可見,不能被其他檔案參照
- 修飾類的靜態成員:在類中,靜態成員可以實現多個物件之間的數據共用,靜態成員是類的所有物件中共用的成員,而不屬於某一個物件;類中的靜態成員必須進行顯示的初始化
- 修飾類的靜態函數:靜態函數同類的靜態成員變數一個用法,都是屬於一個類的方法。而且靜態函數中只可以使用類的靜態變數。
(2)const:
- 修成類成員:在C++中,const成員變數也不能在類定義處初始化,只能通過建構函式初始化列表進行,並且必須有建構函式;
const數據成員只在某個物件生存期內是常數,而對於整個類而言卻是可變的。因爲類可以建立多個物件,不同的物件其const數據成員的值可以不同。 - 修飾類函數:該函數中所有變數均不可改變。
9. C++中的const類成員函數(用法和意義),以及和非const成員函數的區別
(1):在賦值方面,const數據成員只能採用初始化列表方式,而非數據成員可以採用初始化列表和建構函式體內賦值兩種方式。
class Test
{
public:
Test(int x,int y):m_y(y)
{
m_x = x;//m_x也可以採用初始化列表方式,對於非內部數據型別最好採用初始化列表方式進行初始化
}
private:
int m_x;
const int m_y;
};
(2):在函數呼叫方面,const成員函數可以存取const數據成員(本身顯示不能被修改)和const成員函數,可以存取非const數據成員,但是不能修改非const數據成員,且不能呼叫非const成員函數,而非const成員函數則沒有限制。
- 對於每個物件的成員函數(這裏不包括static成員函數,因爲其不屬於某個物件),其都有一個隱形的參數,也就是指向該類物件的一個指針,普通的成員函數,this指針型別是A(A類)const * this,其可以改變this所指向的值,但是不能修改this所儲存的地址。而對於const成員函數,this指針型別是const A * const *this,其既不能改變this所指向的值,也不能修改this所儲存的地址,因此上述就很好理解了。
10. C++的頂層const和底層const
- 指針實際定義了兩個物件,指針本身和它所指的物件。這兩個物件都可以用const進行限定。
- 底層const是代表物件本身是一個常數(不可改變);
const int* p2=&b; //-----可以改變p2的值,這是一個底層const
- 頂層const是代表指針的值是一個常數,而指針的值(即物件的地址)的內容可以改變(指向的不可改變);
int* const p1=&i; //-----不能改變p1的值,這是一個頂層const
11. final和override關鍵字
(1)final
- 用於限制某個類不能被繼承,或者某個虛擬函式不能被重寫,修飾函數,final只能修飾虛擬函式,並且要放到類或者函數的後面。
- final的用法
struct A
{
//A::foo is final 限定該虛擬函式不能被重寫
virtual void foo() final;
//Error: non-virtual function cannot be final,只能修改虛擬函式
void bar() final;
};
struct B final : A //struct B is final
{
//Error: foo cannot be overridden as it's final in A
void foo();
};
struct C : B //Error: B is final
{
};
(2)override
- 確保在派生類中宣告的重寫函數與基礎類別的虛擬函式有相同的簽名,同時也明確表明將會重寫基礎類別的虛擬函式,還可以防止因疏忽把本來想重寫基礎類別的虛擬函式宣告成過載。
- 保證重寫虛擬函式的正確性,又提高程式碼的可讀性。關鍵字要放到方法後面。確認自己目前在子類中正在重寫一個來自父類別的函數,那麼我們最好是用override關鍵字來修飾該函數,override修飾的函數表示這個函數一定是父類別(祖先)中傳下來的,這樣就幫助我們進行了函數的名稱、參數的檢查.
- 以後在子類中重寫父類別函數的時候,一定加上virtual和override關鍵字
- 程式碼範例
struct A
{
virtual void func() {}
};
struct D : A{
//顯式重寫
void func() override
{
}
};
12. 拷貝初始化和直接初始化
(1)什麼是拷貝初始化(也稱爲複製初始化):將一個已有的物件拷貝到正在建立的物件,如果需要的話還需要進行型別轉換。拷貝初始化發生在下列情況:
- 使用賦值運算子定義變數
- 將物件作爲實參傳遞給一個非參照型別的形參
- 將一個返回型別爲非參照型別的函數返回一個物件
(2)什麼是直接初始化:在物件初始化時,通過括號給物件提供一定的參數,並且要求編譯器使用普通的函數匹配來選擇與我們提供的參數最匹配的建構函式
(3)直接初始化和拷貝初始化效率基本一樣,因爲在底層的實現基本一樣,所以將拷貝初始化改爲直接初始化效率提高不大。
(4) 例子
- ClassTest ct1(「ab」); 這條語句屬於直接初始化,它不需要呼叫複製建構函式,直接呼叫建構函式ClassTest(const char *pc),所以當複製建構函式變爲私有時,它還是能直接執行的。
- ClassTest ct2 = 「ab」; 這條語句爲複製初始化,它首先呼叫建構函式 ClassTest(const char* pc)
函數建立一個臨時物件,然後呼叫複製建構函式,把這個臨時物件作爲參數,構造物件ct2;所以當複製建構函式變爲私有時,該語句不能編譯通過。 - ClassTest ct3 = ct1;這條語句爲複製初始化,因爲 ct1本來已經存在,所以不需要呼叫相關的建構函式,而直接呼叫複製建構函式,把它值複製給物件ct3;所以當複製建構函式變爲私有時,該語句不能編譯通過。
- ClassTest ct4(ct1);這條語句爲直接初始化,因爲 ct1 本來已經存在,直接呼叫複製建構函式,生成物件 ct3 的副本物件ct4。所以當複製建構函式變爲私有時,該語句不能編譯通過。
- 要點就是拷貝初始化和直接初始化呼叫的建構函式是不一樣的,但是當類進行復制時,類會自動生成一個臨時的物件,然後再進行拷貝初始化。
13. 初始化和賦值的區別
(1) 普通情況下,初始化和賦值好像沒有什麼特別去區分它的意義。
- int a=100;
- int a; a=100
(2)複雜數據型別,如類,情況不同;
- 預設建構函式是不傳參,構建的物件預設的使用那些值賦值給成員變數;
- 而拷貝建構函式是接受一個相同類的另一個物件,使用該物件來逐成員的爲自己的成員賦值;
- 建構函式的目的,是服務於類的初始化的,它並不服務於賦值。賦值是獨立於初始化之後的操作。
#include <iostream>
using namespace std;
class Point
{
public:
Point(int a=0, int b=0):x(a), y(b){};
~Point(){
};
Point& operator =(const Point &rhs);
int x;
int y;
};
Point& Point::operator =(const Point &rhs)
{
x = rhs.x+1;
y = rhs.y+1;
return *this;
}
int main(void)
{
Point p(1,1);
Point p1 = p; //初始化操作
Point p2;
p2 = p; //賦值操作
cout<<"p1.x = "<<p1.x<<" "<<"p1.y="<<p1.y<<endl;
cout<<"p2.x = "<<p2.x<<" "<<"p2.y="<<p2.y<<endl;
return 0;
}
在p1中,Point p1=p;這個操作中,實際上是通過一種類似於拷貝建構函式中逐member的方式(但並沒有生成一個拷貝建構函式,生成拷貝建構函式的四種情況見前面的隨筆),並沒有呼叫過載的"="運算子。所以最終結果是p1爲(1,1)。
而在p2中,初始化與賦值是分開的,Point p2;就已經完成了初始化,這個初始化是通過定義的含參建構函式(但是以a=0,b=0的預設值完成的)。
然後在呼叫過載運算子,對p中成員均自加後賦值給p2的成員變數。
14. extern "C"的用法
extern "C"的主要作用就是爲了能夠正確實現C++程式碼呼叫其他C語言程式碼。加上extern "C"後,會指示編譯器這部分程式碼按C語言的進行編譯,而不是C++的。
由於C++支援函數過載,因此編譯器編譯函數的過程中會將函數的參數型別也加到編譯後的程式碼中,而不僅僅是函數名;
而C語言並不支援函數過載,因此編譯C語言程式碼的函數時不會帶上函數的參數型別,一般只包括函數名。比如說你用C 開發了一個DLL 庫,爲了能夠讓C ++語言也能夠呼叫你的DLL輸出(Export)的函數,你需要用extern "C"來強制編譯器不要修改你的函數名。
15. 模板函數和模板類的特例化
引入的原因:編寫單一的模板,它能適應大衆化,使每種型別都具有相同的功能,但對於某種特定型別,如果要實現其特有的功能,單一模板就無法做到,這時就需要模板特例化。
定義:是對單一模板提供的一個特殊範例,它將一個或多個模板參數系結到特定的型別或值上。
(1)函數模板特例化:必須爲原函數模板的每個模板參數都提供實參,且使用關鍵字template後跟一個空尖括號對<>,表明將原模板的所有模板參數提供實參。
template<typename T> //函數模板
int compare(const T &v1,const T &v2)
{
if(v1 > v2) return -1;
if(v2 > v1) return 1;
return 0;
}
//模板特例化,滿足針對字串特定的比較,要提供所有實參,這裏只有一個T
template<>
int compare(const char* const &v1,const char* const &v2)
{
return strcmp(p1,p2);
}
此處如果是compare(3,5),則呼叫普通的模板,若爲compare(「hi」,」haha」)則呼叫特例化版本(因爲這個cosnt char*相對於T,更匹配實參型別),注意,二者函數體的語句不一樣了,實現不同功能。
(2)類別範本的部分特例化:不必爲所有模板參數提供實參,可以指定一部分而非所有模板參數,一個類別範本的部分特例化本身仍是一個模板,使用它時還必須爲其特例化版本中未指定的模板參數提供實參。此功能就用於STL原始碼剖析中的traits程式設計。詳見C++primer 628頁的例子。(特例化時類名一定要和原來的模板相同,只是參數型別不同,按最佳匹配原則,那個最匹配,就用相應的模板)
template<typename T>class Foo
{
void Bar();
void Barst(T a)();
};
template<>
void Foo<int>::Bar()
{
//進行int型別的特例化處理
}
Foo<string> fs;
Foo<int> fi;//使用特例化
fs.Bar();//使用的是普通模板,即Foo<string>::Bar()
fi.Bar();//特例化版本,執行Foo<int>::Bar()
//Foo<string>::Bar()和Foo<int>::Bar()功能不同
16. C++的STL原始碼(這個系列也很重要,建議侯捷老師的STL原始碼剖析書籍與視訊),其中包括記憶體池機制 機製,各種容器的底層實現機制 機製,演算法的實現原理等)
17. STL原始碼中的hashtable的實現
hash_table是STL中hash_map 和 hash_set 的內部數據結構,hash_table的插入/刪除/查詢的時間複雜度都爲O(1),是查詢速度最快的一種數據結構,但是hash_table中的數據是無序的,一般也只有在數據不需要排序,只需要滿足快速查詢/插入/刪除的時候使用hash_table。
18. STL中unordered_map和map的區別和應用場景
map是一種對映,這種對映是有序的,底層是使用紅黑樹來完成的,數據通過鍵值才儲存,鍵是唯一的。
unordered_map,是一種無序的,底層是通過hash表來完成的。unordered庫使用「桶」來儲存元素,雜湊值相同的被儲存在一個桶裏。當雜湊容器中有大量數據時,同一個桶裏的數據也會增多,造成存取衝突,降低效能。爲了提高雜湊容器的效能,unordered庫會在插入元素是自動增加桶的數量,不需要使用者指定。每個桶都是用list來完成的。
(1)map
優點:
- 有序性: 其元素的有序性再很多應用中都會簡化很多操作。
- 紅黑樹: 內部實現一個紅黑樹使得map的很多操作在lgn的時間複雜度下就可以實現,因此效率很高。
缺點:
- 空間佔用率高,每一個節點都需要額外儲存父節點,孩子節點以及紅黑性質,使得每一個節點都會佔用大量的空間。
適用於:
- 對順序有要求的問題。
(2)unordered_map
- 優點: 由於使用了雜湊表,因此查詢速度非常快。
- 缺點: 雜湊表的建立比較耗費時間
- 適用於: 查詢問題
19. STL中vector的實現
(1).vector有備用空間,當備用空間不夠的時候,會重新開闢原空間兩倍的空間進行重寫分配。
(2).vector支援隨機的存取,但是最好是選擇從末尾插入,因爲從中間插入會導致元素的移動,帶來了效能的開銷。
20. STL容器的幾種迭代器以及對應的容器(輸入迭代器,輸出迭代器,前向迭代器,雙向迭代器,隨機存取迭代器)
順序容器:vector,deque是隨機存取迭代器;list是雙向迭代器
容器適配器:stack,queue,priority_queue沒有迭代器
關聯容器:set,map,multiset,multimap是雙向迭代器
unordered_set,unordered_map,unordered_multiset,unordered_multimap是前向迭代器
21. STL中的traits技法
https://www.cnblogs.com/zhuwbox/p/3698083.html STL中的Traits程式設計技法
22. vector使用的注意點及其原因,頻繁對vector呼叫push_back()對效能的影響和原因。
vector壓入容器的物件都是拷貝操作,而且vector的數據存放都是連續儲存的,所以在操作vector操作時,應該儘量避免對尾部操作之後的地方插入刪除操作,因爲這樣會造成元素的移動,造成大量的開銷。
頻繁對vector呼叫push_back()會導致效能下降,這是由於系統每次給vector分配固定大小的空間,這個空間可能比使用者想分配的空間大一些,但是頻繁的使用push_back向容器中插入元素,會導致記憶體分配空間不夠,會再次將整個物件的儲存空間重新分配,將舊的元素移動到新的空間中,開銷是非常大的。
23. C++中的過載和重寫的區別
- 過載:是指同一可存取區內被宣告的幾個具有不同參數列(參數的型別,個數,順序不同)的同名函數,根據參數列表確定呼叫哪個函數,過載不關心函數返回型別。
- 重寫:指派生類中存在重新定義的函數。其函數名,參數列表,返回值型別,所有都必須同基礎類別中被重寫的函數一致。只有函數體不同(花括號內),派生類呼叫時會呼叫派生類的重寫函數,不會呼叫被重寫函數。重寫的基礎類別中被重寫的函數必須有virtual修飾。
24. C++記憶體管理,記憶體池技術(熱門問題),與csapp中幾種記憶體分配方式對比學習加深理解
c++的記憶體管理延續c語言的記憶體管理,但是也增加了其他的,例如智慧指針,除了常見的堆疊的記憶體管理之外,c++支援智慧指針,智慧指針的物件進行賦值拷貝等操作的時候,每個智慧指針都有一個關聯的計數器,該計數器記錄共用該物件的指針個數,當最後一個指針被銷燬的時候,計數器爲0,會自動呼叫解構函式來銷燬函數。
常見的記憶體管理錯誤有:
a>記憶體分配未成功卻使用了它,如果所用的操作符不是型別安全的話,請使用assert(p != NULL)或者if(p != NULL)來判斷。
b>記憶體分配成功但未初始化
c>記憶體分配成功並已初始化,但是操作超過了記憶體的邊界
d>忘記釋放記憶體,造成記憶體泄露,每申請一塊記憶體必須保證它被釋放,釋放記憶體後立即將指針置爲NULL
陣列與指針的對比,陣列要麼在靜態儲存區被建立(如全域性陣列),要麼在棧上被建立。陣列名對應着(而不是指向)一塊記憶體,其地址與容量在生命期內保持不變,只有陣列的內容可以改變。
指針可以隨時指向任意型別的記憶體塊,它的特徵是「可變」,所以我們常用指針來操作動態記憶體。指針遠比陣列靈活,但也更危險。
(1)記憶體池簡介
C/C++下記憶體管理是讓幾乎每一個程式設計師頭疼的問題,分配足夠的記憶體、追蹤記憶體的分配、在不需要的時候釋放記憶體——這個任務相當複雜。而直接使用系統呼叫malloc/free、new/delete進行記憶體分配和釋放,有以下弊端:
呼叫malloc/new,系統需要根據「最先匹配」、「最優匹配」或其他演算法在記憶體空閒塊表中查詢一塊空閒記憶體,呼叫free/delete,系統可能需要合併空閒記憶體塊,這些會產生額外開銷
頻繁使用時會產生大量記憶體碎片,從而降低程式執行效率
容易造成記憶體漏失
(2)記憶體池的優點
記憶體池則是在真正使用記憶體之前,預先申請分配一定數量、大小相等(一般情況下)的記憶體塊留作備用。當有新的記憶體需求時,就從記憶體池中分出一部分記憶體塊,若記憶體塊不夠再繼續申請新的記憶體。這樣做的一個顯著優點是,使得記憶體分配效率得到提升。
(3)記憶體池的分類
從執行緒安全的角度來分,記憶體池可以分爲單執行緒記憶體池和多執行緒記憶體池。單執行緒記憶體池整個生命週期只被一個執行緒使用,因而不需要考慮互斥存取的問題;多執行緒記憶體池有可能被多個執行緒共用,因此需要在每次分配和釋放記憶體時加鎖。相對而言,單執行緒記憶體池效能更高,而多執行緒記憶體池適用範圍更加廣泛。
從記憶體池可分配記憶體單元大小來分,可以分爲固定記憶體池和可變記憶體池。所謂固定記憶體池是指應用程式每次從記憶體池中分配出來的記憶體單元大小事先已經確定,是固定不變的;而可變記憶體池則每次分配的記憶體單元大小可以按需變化,應用範圍更廣,而效能比固定記憶體池要低。
(4)經典記憶體池的設計
經典記憶體池實現過程
a.先申請一塊連續的記憶體空間,該段記憶體空間能夠容納一定數量的物件;
b.每個物件連同一個指向下一個物件的指針一起構成一個記憶體節點(Memory Node)。各個空閒的記憶體節點通過指針形成一個鏈表,鏈表的每一個記憶體節點都是一塊可供分配的記憶體空間;
c.某個記憶體節點一旦分配出去,從空閒記憶體節點鏈表中去除;
d.一旦釋放了某個記憶體節點的空間,又將該節點重新加入空閒記憶體節點鏈表;
e.如果一個記憶體塊的所有記憶體節點分配完畢,若程式繼續申請新的物件空間,則會再次申請一個記憶體塊來容納新的物件。新申請的記憶體塊會加入記憶體塊鏈表中。
經典記憶體池的實現過程大致如上面所述,其形象化的過程如下圖所示:
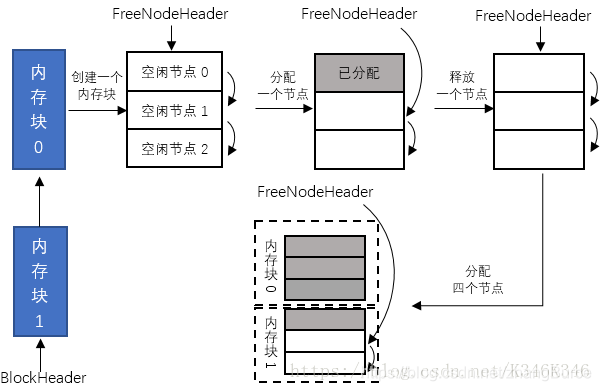
如上圖所示,申請的記憶體塊存放三個可供分配的空閒節點。空閒節點由空閒節點鏈表管理,如果分配出去,將其從空閒節點鏈表刪除,如果釋放,將其重新插入到鏈表的頭部。如果記憶體塊中的空閒節點不夠用,則重新申請記憶體塊,申請的記憶體塊由記憶體塊鏈表來管理。
注意,本文涉及到的記憶體塊鏈表和空閒記憶體節點鏈表的插入,爲了省去遍歷鏈表查詢尾節點,便於操作,新節點的插入均是插入到鏈表的頭部,而非尾部。當然也可以插入到尾部,讀者可自行實現。
經典記憶體池數據結構設計
按照上面的過程設計,記憶體池類別範本有這樣幾個成員。
兩個指針變數:
記憶體塊鏈表頭指針:pMemBlockHeader;
空閒節點鏈表頭指針:pFreeNodeHeader;
空閒節點結構體:
struct FreeNode
{
FreeNode* pNext;
char data[ObjectSize];
};
記憶體塊結構體:
struct MemBlock
{
MemBlock *pNext;
FreeNode data[NumofObjects];
};
經典記憶體池的實現
根據以上經典記憶體池的設計,編碼實現如下
#include <iostream>
using namespace std;
template<int ObjectSize, int NumofObjects = 20>
class MemPool
{
private:
//空閒節點結構體
struct FreeNode
{
FreeNode* pNext;
char data[ObjectSize];
};
//記憶體塊結構體
struct MemBlock
{
MemBlock* pNext;
FreeNode data[NumofObjects];
};
FreeNode* freeNodeHeader;
MemBlock* memBlockHeader;
public:
MemPool()
{
freeNodeHeader = NULL;
memBlockHeader = NULL;
}
~MemPool()
{
MemBlock* ptr;
while (memBlockHeader)
{
ptr = memBlockHeader->pNext;
delete memBlockHeader;
memBlockHeader = ptr;
}
}
void* malloc();
void free(void*);
};
//分配空閒的節點
template<int ObjectSize, int NumofObjects>
void* MemPool<ObjectSize, NumofObjects>::malloc()
{
//無空閒節點,申請新記憶體塊
if (freeNodeHeader == NULL)
{
MemBlock* newBlock = new MemBlock;
newBlock->pNext = NULL;
freeNodeHeader=&newBlock->data[0]; //設定記憶體塊的第一個節點爲空閒節點鏈表的首節點
//將記憶體塊的其它節點串起來
for (int i = 1; i < NumofObjects; ++i)
{
newBlock->data[i - 1].pNext = &newBlock->data[i];
}
newBlock->data[NumofObjects - 1].pNext=NULL;
//首次申請記憶體塊
if (memBlockHeader == NULL)
{
memBlockHeader = newBlock;
}
else
{
//將新記憶體塊加入到記憶體塊鏈表
newBlock->pNext = memBlockHeader;
memBlockHeader = newBlock;
}
}
//返回空節點閒鏈表的第一個節點
void* freeNode = freeNodeHeader;
freeNodeHeader = freeNodeHeader->pNext;
return freeNode;
}
//釋放已經分配的節點
template<int ObjectSize, int NumofObjects>
void MemPool<ObjectSize, NumofObjects>::free(void* p)
{
FreeNode* pNode = (FreeNode*)p;
pNode->pNext = freeNodeHeader; //將釋放的節點插入空閒節點頭部
freeNodeHeader = pNode;
}
class ActualClass
{
static int count;
int No;
public:
ActualClass()
{
No = count;
count++;
}
void print()
{
cout << this << ": ";
cout << "the " << No << "th object" << endl;
}
void* operator new(size_t size);
void operator delete(void* p);
};
//定義記憶體池物件
MemPool<sizeof(ActualClass), 2> mp;
void* ActualClass::operator new(size_t size)
{
return mp.malloc();
}
void ActualClass::operator delete(void* p)
{
mp.free(p);
}
int ActualClass::count = 0;
int main()
{
ActualClass* p1 = new ActualClass;
p1->print();
ActualClass* p2 = new ActualClass;
p2->print();
delete p1;
p1 = new ActualClass;
p1->print();
ActualClass* p3 = new ActualClass;
p3->print();
delete p1;
delete p2;
delete p3;
}
程式執行結果:
004AA214: the 0th object
004AA21C: the 1th object
004AA214: the 2th object
004AB1A4: the 3th object
程式分析
閱讀以上程式,應注意以下幾點。
(1)對一種特定的類物件而言,記憶體池中記憶體塊的大小是固定的,記憶體節點的大小也是固定的。記憶體塊在申請之初就被劃分爲多個記憶體節點,每個Node的大小爲ItemSize。剛開始,所有的記憶體節點都是空閒的,被串成鏈表。
(2)成員指針變數memBlockHeader是用來把所有申請的記憶體塊連線成一個記憶體塊鏈表,以便通過它可以釋放所有申請的記憶體。freeNodeHeader變數則是把所有空閒記憶體節點串成一個鏈表。freeNodeHeader爲空則表明沒有可用的空閒記憶體節點,必須申請新的記憶體塊。
(3)申請空間的過程如下。在空閒記憶體節點鏈表非空的情況下,malloc過程只是從鏈表中取下空閒記憶體節點鏈表的頭一個節點,然後把鏈表頭指針移動到下一個節點上去。否則,意味着需要一個新的記憶體塊。這個過程需要申請新的記憶體塊切割成多個記憶體節點,並把它們串起來,記憶體池技術的主要開銷就在這裏。
(4)釋放物件的過程就是把被釋放的記憶體節點重新插入到記憶體節點鏈表的開頭。最後被釋放的節點就是下一個即將被分配的節點。
(5)記憶體池技術申請/釋放記憶體的速度很快,其記憶體分配過程多數情況下複雜度爲O(1),主要開銷在freeNodeHeader爲空時需要生成新的記憶體塊。記憶體節點釋放過程複雜度爲O(1)。
(6) 在上面的程式中,指針p1和p2連續兩次申請空間,它們代表的地址之間的差值爲8,正好爲一個記憶體節點的大小(sizeof(FreeNode))。指針p1所指向的物件被釋放後,再次申請空間,得到的地址與剛剛釋放的地址正好相同。指針p3多代表的地址與前兩個物件的地址相聚很遠,原因是第一個記憶體塊中的空閒記憶體節點已經分配完了,p3指向的物件位於第二個記憶體塊中。
以上記憶體池方案並不完美,比如,只能單個單個申請物件空間,不能申請物件陣列,記憶體池中記憶體塊的個數只能增大不能減少,未考慮多執行緒安全等問題。現在,已經有很多改進的方案,請讀者自行查閱相關資料。
注:與深入理解計算機系統(csapp)中幾種記憶體分配方式對比學習加深理解
25. 介紹物件導向的三大特性,並且舉例說明每一個
物件導向的三大特性:封裝、繼承、多型。
(1)封裝:將很多有相似特性的內容封裝在一個類中,例如學生的成績學號、課程這些可以封裝在同一個類中;
(2)繼承:某些相似的特性,可以從一個類繼承到另一個類,類似生活中的繼承,例如有個所有的汽車都有4個輪子,那麼我們在父類別中定義4個輪子,通過繼承獲得4個輪子的功能,不用再類裏面再去定義這4個輪子的功能。
(3)多型:多型指的相同的功能,不同的狀態,多型在物件導向c++裏面是通過過載和覆蓋來完成的,覆蓋在c++裏面通過虛擬函式來完成的。例如鴨子的例子,所有的鴨子都有顏色,我們可以將這個顏色設定成爲一個虛擬函式,通過繼承子類對虛擬函式進行覆蓋,不同子類中有各自的顏色,也就是有各自不同的鴨子顏色,這就是多型的典型表現之一。
26. C++多型的實現
多型用虛擬函式來實現,結合動態系結。
參照/指針的靜態型別與動態型別不同這一事實正是C++語言支援多型性的根本所在。
C++的多型性用一句話概括就是:在基礎類別的函數前加上virtual關鍵字,在派生類中重寫該函數,執行時將會根據物件的實際型別來呼叫相應的函數。如果物件型別是派生類,就呼叫派生類的函數;如果物件型別是基礎類別,就呼叫基礎類別的函數。
27. C++虛擬函式相關(虛擬函式表,虛擬函式指針),虛擬函式的實現原理(包括單一繼承,多重繼承等)(拓展問題:爲什麼基礎類別指針指向派生類物件時可以呼叫派生類成員函數,基礎類別的虛擬函式存放在記憶體的什麼區,虛擬函式表指針vptr的初始化時間)
存在虛擬函式的類都有一個一維的虛擬函式表叫做虛表,類的物件有一個指向虛表開始的虛指針。虛表是和類對應的,虛表指針是和物件對應的。
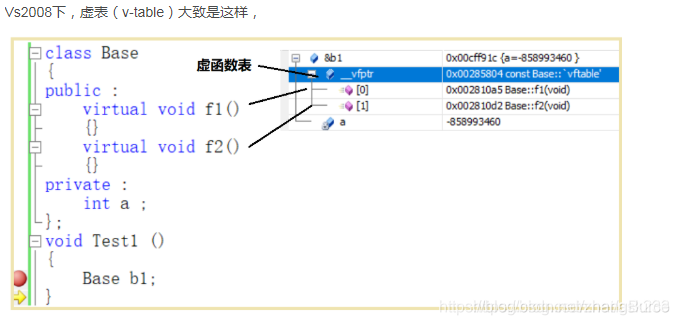
注意 :
①每個虛表後面都有一個‘0’,它類似字串的‘\0’,用來標識虛擬函式表的結尾。結束標識在不同的編譯器下可能會有所不同。
②不難發現虛擬函式表的指針存在於物件範例中最前面的位置(這是爲了保證取到虛擬函式表的有最高的效能——如果有多層繼承或是多重繼承的情況下)這意味着我們通過物件範例的地址得到這張虛擬函式表,然後就可以遍歷其中函數指針,並呼叫相應的函數。
多型實現利用到了虛擬函式表(虛表V-table)。它是一塊虛擬函式的地址表,通過一塊連續記憶體來儲存虛擬函式的地址。這張表解決了繼承、虛擬函式(重寫)的問題。在有虛擬函式的物件範例中都存在一張虛擬函式表,虛擬函式表就像一張地圖,指明瞭實際應該呼叫的虛擬函式函數。
爲什麼基礎類別指針指向派生類物件時可以呼叫派生類成員函數
虛表指針一般放在首地址,如果父類別有虛擬函式表,子類必定有;因爲構造子類時先構造父類別,所以使用父類別的指針,編譯器根據指針型別就能知道偏移多少就能找到父類別的成員(包括虛擬函式指針),但是對於子類獨有的成員,父類別的指針無法提供偏移量,因此找不到。
基礎類別的虛擬函式存放在記憶體的什麼區
全域性數據區(靜態區)
虛表指針vptr的初始化時間
所有基礎類別建構函式之後,但又在自身建構函式或初始化列表之前
編譯器處理虛擬函式的方法是:
編譯器爲每個包含虛擬函式的類建立一個表,在表中編譯器放置特定類的虛擬函式地址,在每個帶有虛擬函式的類中,編譯器爲每個類物件放置一個指針(爲每個類新增一個隱藏的成員),指向虛表。通過基礎類別的指針或參照做虛擬函式呼叫時,編譯器靜態插入取得該指針,並在虛表中找到函數地址。注意基礎類別和派生類的虛擬函式表是倆個東西,儲存在不同的空間,但這倆個東西的內容可能一樣。
虛擬函式實現原理(包括單一繼承,多重繼承等):虛擬函式表+虛表指針
每個虛擬函式都會有一個與之對應的虛擬函式表,該虛擬函式表的實質是一個指針陣列,存放的是每一個物件的虛擬函式入口地址。對於一個派生類來說,他會繼承基礎類別的虛擬函式表同時增加自己的虛擬函式入口地址,如果派生類重寫了基礎類別的虛擬函式的話,那麼繼承過來的虛擬函式入口地址將被派生類的重寫虛擬函式入口地址替代。那麼在程式執行時會發生動態系結,將父類別指針系結到範例化的物件實現多型。
單繼承環境下的虛擬函式
假設存在下面 下麪的兩個類Base和A,A類繼承自Base類:
class Base
{
public:
// 虛擬函式func1
virtual void func1() { cout << "Base::func1()" << endl; }
// 虛擬函式func2
virtual void func2() { cout << "Base::func2()" << endl; }
// 虛擬函式func3
virtual void func3() { cout << "Base::func3()" << endl; }
int a;
};
class A : public Base
{
public:
// 重寫父類別虛擬函式func1
void func1() { cout << "A::func1()" << endl; }
void func2() { cout << "A::func2()" << endl; }
// 新增虛擬函式func4
virtual void func4() { cout << "A::func3()" << endl; }
};
利用Visual Studio提供的命令列工具檢視一下這兩個類的記憶體佈局。
類Base的記憶體佈局圖:
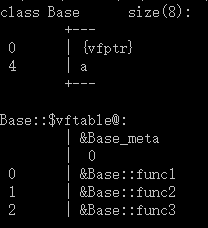
類A的記憶體佈局圖:

通過兩幅圖片的對比,我們可以看到:
在單繼承中,A類覆蓋了Base類中的同名虛擬函式,在虛擬函式表中體現爲對應位置被A類中的新函數替換,而沒有被覆蓋的函數則沒有發生變化。
對於子類自己的虛擬函式,直接新增到虛擬函式表後面。
另外,我們注意到,類A和類Base中都只有一個vfptr指針,前面我們說過,該指針指向虛擬函式表,我們分別輸出類A和類Base的vfptr:
int main()
{
typedef void(*pFunc)(void);
cout << "virtual function testing:" << endl;
Base b;
cout << "Base虛擬函式表地址:" << (int *)(&b) << endl;
A a;
cout << "A類虛擬函式表地址:" << (int *)(&a) << endl;
}
輸出資訊如下:
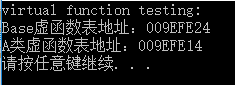
我們可以看到,類A和類B分別擁有自己的虛擬函式表指針vptr和虛擬函式表vtbl。到這裏,你是否已經明白爲什麼指向子類範例的基礎類別指針可以呼叫子類(虛)函數?每一個範例物件中都存在一個vptr指針,編譯器會先取出vptr的值,這個值就是虛擬函式表vtbl的地址,再根據這個值來到vtbl中呼叫目標函數。所以,只要vptr不同,指向的虛擬函式表vtbl就不同,而不同的虛擬函式表中存放着對應類的虛擬函式地址,這樣就實現了多型的」效果「。
最後,我們用一幅圖來表示單繼承下的虛擬函式實現:
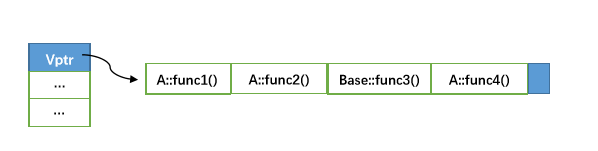
多繼承環境下的虛擬函式
假設存在下面 下麪這樣的四個類:
class Base
{
public:
// 虛擬函式func1
virtual void func1() { cout << "Base::func1()" << endl; }
// 虛擬函式func2
virtual void func2() { cout << "Base::func2()" << endl; }
// 虛擬函式func3
virtual void func3() { cout << "Base::func3()" << endl; }
};
class A : public Base
{
public:
// 重寫父類別虛擬函式func1
void func1() { cout << "A::func1()" << endl; }
void func2() { cout << "A::func2()" << endl; }
};
class B : public Base
{
public:
void func1() { cout << "B::func1()" << endl; }
void func2() { cout << "B::func2()" << endl; }
};
class C : public A, public B
{
public:
void func1() { cout << "D::func1()" << endl; }
void func2() { cout << "D::func2()" << endl; }
};
類A和類B分別繼承自類Base,類C繼承了類B和類A,我們檢視一下類C的記憶體佈局:
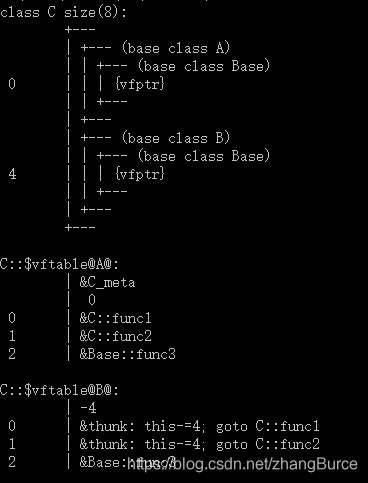
可以看到,類C中擁有兩個虛擬函式表指針vptr。類C中覆蓋了類A的兩個同名函數,在虛擬函式表中體現爲對應位置替換爲C中新函數;類C中覆蓋了類B中的兩個同名函數,在虛擬函式表中體現爲對應位置替換爲C中新函數(注意,這裏使用跳轉語句,而不是重複定義)。
類C的記憶體佈局可以歸納爲下圖:
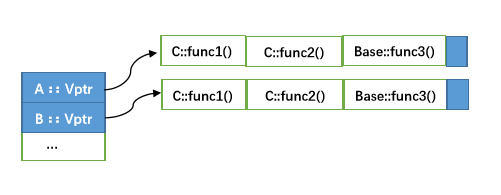
多重繼承會有多個虛擬函式表,幾重繼承,就會有幾個虛擬函式表。這些表按照派生的順序依次排列,如果子類改寫了父類別的虛擬函式,那麼就會用子類自己的虛擬函式覆蓋虛擬函式表的相應的位置,如果子類有新的虛擬函式,那麼就新增到第一個虛擬函式表的末尾。
28. C++中類的數據成員和成員函數記憶體分佈情況
C++類別成員所佔記憶體總結:
(1)空類所佔位元組數爲1
(2)類中的成員函數不佔記憶體空間,虛擬函式除外;如果父類別中如果有一個虛擬函式,則類所位元組發生變化,如果是32位元編譯器,則佔記憶體4個位元組;如果是64位元編譯器,則佔記憶體8個位元組;
(3)和結構體一樣,類中自身帶有四位元組對齊功能
(4)類中的static靜態成員變數不佔記憶體,靜態成員變數儲存在靜態區
https://www.cnblogs.com/hnfxs/p/5395015.html C++類別記憶體佈局圖(成員函數和成員變數分開討論)
29. this指針
用類去定義物件時,系統會爲每一個物件分配儲存空間。如果一個類包括了數據和函數,要分別爲數據和函數的程式碼分配儲存空間。按理說,如果用同一個類定義了10個物件,那麼就需要分別爲10個物件的數據和函數程式碼分配儲存單元,如下圖所示。
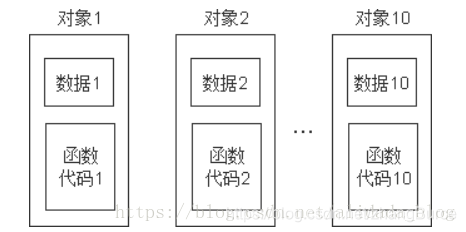
我們可以看出這樣不僅麻煩而且特別浪費空間,因此經過分析我們可以知道是按以下方式來儲存的。
只用一段空間來存放這個共同的函數程式碼段,在呼叫各物件的函數時,都去呼叫這個公用的函數程式碼。如下圖所示。
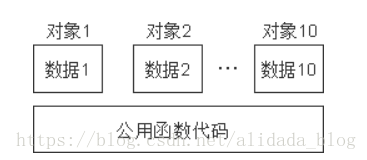
顯然,這樣做會大大節約儲存空間。C++編譯系統正是這樣做的,因此每個物件所佔用的儲存空間只是該物件的數據部分(虛擬函式指針和虛基礎類別指針也屬於數據部分)所佔用的儲存空間,而不包括函數程式碼所佔用的儲存空間。
那麼問題來了在不同對象但是呼叫的的程式碼又相同的情況下,編譯器是如何分辨且準確的呼叫到各自的函數???
在c++中專門設立了一個this指針,用來指向不同的物件,當呼叫物件t1的成員函數display1時,this指針就指向display1,當呼叫t2的成員函數display2,this指針就指向display2。。。。。以此類推來分辨準確的呼叫
30. 解構函式一般寫成虛擬函式的原因
#include <iostream>
using namespace std;
class Person
{
public:
virtual ~Person() //加了virtual,講解構函式宣告爲虛擬函式
{
cout << "Person::~Person()" << endl;
}
};
class Student : public Person
{
public:
~Student() // virtual可加可不加
{
cout << "Student::~Student()" << endl;
}
};
int main()
{
Person *pt1 = new Person;
Person *pt2 = new Student; // 用基礎類別的指針指向子類
// Student *pt3 = new Person; // 不能用子類指針指向基礎類別,錯誤!
Student *pt4 = new Student;
delete pt1;
cout << "*********" << endl;
delete pt2;
cout << "*********" << endl;
//delete pt3;
//cout << "*********" << endl;
delete pt4;
cout << "*********" << endl;
return 0;
}
-
執行結果: Person::~Person()
Student::~Student()
Person::~Person()
Student::~Student()
Person::~Person()
如果在基礎類別中解構函式不加virtual,結果爲:
Person::~Person()
Person::~Person()
Student::~Student()
Person::~Person()
可以看出:只有在用基礎類別的指針指向派生類的時候虛擬函式發揮了動態的作用。
解構函式執行時先呼叫派生類的解構函式,其次才呼叫基礎類別的解構函式。
如果解構函式不是虛擬函式,而程式執行時又要通過基礎類別的指針去銷燬派生類的動態物件,那麼用delete銷燬物件時,只調用了基礎類別的解構函式,未呼叫派生類的解構函式。這樣會造成銷燬物件不完全,容易造成記憶體泄露。
31. 建構函式、拷貝建構函式和賦值操作符的區別
物件不存在,且沒用別的物件來初始化,就是呼叫了建構函式;
物件不存在,且用別的物件來初始化,就是拷貝建構函式(上面說了三種用它的情況!)
物件存在,用別的物件來給它賦值,就是賦值函數。
32. 建構函式宣告爲explicit
C++中, 一個參數的建構函式(或者除了第一個參數外其餘參數都有預設值的多參建構函式), 承擔了兩個角色。 1 是個構造器 ,2 是個預設且隱含的型別轉換操作符。
- explicit建構函式是用來防止隱式轉換的。
- 關鍵字explicit只對一個實參的建構函式有效
- 需要多個實參的建構函式不能用於執行隱式轉換,所以無需將這些建構函式指定爲explicit的
- 只能在類內宣告建構函式時使用explicit關鍵字,在類外部定義時不應重複
33. 建構函式爲什麼一般不定義爲虛擬函式
-
從C++之父Bjarne的回答我們應該知道C++爲什麼不支援建構函式是虛函數了,簡單講就是沒有意義。虛擬函式的作用在於通過子類的指針或參照來呼叫父類別的那個成員函數。而建構函式是在建立物件時自己主動呼叫的,不可能通過子類的指針或者參照去呼叫。
-
虛擬函式相應一個指向vtable虛擬函式表的指針,但是這個指向vtable的指針事實上是儲存在物件的記憶體空間的。假設建構函式是虛的,就須要通過vtable來呼叫,但是物件還沒有範例化,也就是記憶體空間還沒有,怎麼找vtable呢?所以建構函式不能是虛擬函式。
34. 建構函式的幾種關鍵字(default delete 0)
35. 建構函式或者解構函式中呼叫虛擬函式會怎樣
總的來說,建構函式和解構函式呼叫虛擬函式並不能達到多型的效果,因爲在解構和構造過程中,該物件變爲一個基礎類別物件,呼叫的方法都是基礎類別的方法。
- 建構函式:在基礎類別的構造過程中,虛擬函式呼叫從不會被傳遞到派生類中。代之的是,派生類物件表現出來的行爲好象其本身就是基本類型。不規範地說,在基礎類別的構造過程中,虛擬函式並沒有被"構造"。簡單的說就是,在子類物件的基礎類別子物件構造期間,呼叫的虛擬函式的版本是基礎類別的而不是子類的。
- 解構函式:一旦一個派生類的解構器執行起來,該物件的派生類數據成員就被假設爲是未定義的值,這樣以來,C++就把它們當做是不存在一樣。一旦進入到基礎類別的解構器中,該物件即變爲一個基礎類別物件,C++中各個部分(虛擬函式,dynamic_cast運算子等等)都這樣處理。
36. 純虛擬函式
純虛擬函式不需要定義,我們不能夠爲純虛擬函式提供函數體,同樣的,包含純虛擬函式的基礎類別是抽象基礎類別,抽象基礎類別是不能建立物件的,只能通過繼承,繼承子類中覆蓋純虛擬函式,執行自己的功能,子類是可以建立物件的。
37. 靜態型別和動態型別,靜態系結和動態系結的介紹
靜態型別和動態型別:
-
物件的靜態型別:
物件在宣告是採用的型別,在編譯期確定; -
物件的動態型別:
當前物件所指的型別,在執行期決定,物件的動態型別可以更改,但靜態型別無法更改。
靜態系結和動態系結:
-
靜態系結:
系結的是物件的靜態型別,某特性(比如函數)依賴於物件的靜態型別,發生在編譯期。 -
動態系結:
系結的是物件的動態型別,某特性(比如函數)依賴於物件的動態型別,發生在執行期。
38. 參照是否能實現動態系結,爲什麼參照可以實現
可以實現,因爲動態系結是發生在程式執行階段的,c++中動態系結是通過對基礎類別的參照或者指針呼叫虛擬函式時發生。
因爲參照或者指針的物件是可以在編譯的時候不確定的,如果是直接傳物件的話,在程式編譯的階段就會完成,對於參照,其實就是地址,在編譯的時候可以不系結物件,在實際執行的時候,在通過虛擬函式系結物件即可。
39. 深拷貝和淺拷貝的區別(舉例說明深拷貝的安全性)
深拷貝就是拷貝內容,淺拷貝就是拷貝指針。
淺拷貝拷貝指針,也就是說同一個物件,拷貝了兩個指針,指向了同一個物件,那麼當銷燬的時候,可能兩個指針銷燬,就會導致記憶體漏失的問題。
深拷貝不存在這個問題,因爲是首先申請和拷貝數據一樣大的記憶體空間,把數據複製過去。這樣拷貝多少次,就有多少個不同的記憶體空間,幹擾不到對方。
40. 物件複用的瞭解,零拷貝的瞭解
物件複用指得是設計模式,物件可以採用不同的設計模式達到複用的目的,最常見的就是繼承和組合模式了。
零拷貝主要的任務就是避免CPU將數據從一塊儲存拷貝到另外一塊儲存,主要就是利用各種零拷貝技術,避免讓CPU做大量的數據拷貝任務,減少不必要的拷貝,或者讓別的元件來做這一類簡單的數據傳輸任務,讓CPU解脫出來專注於別的任務。這樣就可以讓系統資源的利用更加有效。
零拷貝技術常見linux中,例如使用者空間到內核空間的拷貝,這個是沒有必要的,我們可以採用零拷貝技術,這個技術就是通過mmap,直接將內核空間的數據通過對映的方法對映到使用者空間上,即物理上共用這段數據。
零拷貝介紹https://www.jianshu.com/p/fad3339e3448
41. 介紹C++所有的建構函式
預設建構函式、一般建構函式、拷貝建構函式
(1)預設建構函式(無參數):如果建立一個類你沒有寫任何建構函式,則系統會自動生成預設的建構函式,或者寫了一個不帶任何形參的建構函式。
(2)一般建構函式:一般建構函式可以有各種參數形式,一個類可以有多個一般建構函式,前提是參數的個數或者型別不同(基於c++的過載函數原理)。
(3)拷貝建構函式參數爲類物件本身的參照,用於根據一個已存在的物件複製出一個新的該類的物件,一般在函數中會將已存在物件的數據成員的值複製一份到新建立的物件中。參數(物件的參照)是不可變的(const型別)。此函數經常用在函數呼叫時使用者定義型別的值傳遞及返回。
42. 什麼情況下會呼叫拷貝建構函式(三種情況)
(1)用類的一個物件去初始化另一個物件時
(2)當函數的形參是類的物件時(也就是值傳遞時),如果是參照傳遞則不會呼叫
(3)當函數的返回值是類的物件或參照時
43. 結構體記憶體對齊方式和爲什麼要進行記憶體對齊?
(1).前面的地址必須是後面的地址正數倍,不是就補齊
(2).整個Struct的地址必須是最大位元組的整數倍
(3)爲什麼要?
- 空間換時間,加快cpu存取記憶體的效率,這是因爲許多計算機系統對基本數據型別合法地址做出了一些限制,要求某種型別物件的地址必須是某個值K(通常是2、4或8)的倍數。這種對齊限制簡化了形成處理器和記憶體系統之間介面的硬體設計
44. 記憶體泄露的定義,如何檢測與避免?
(1)首先說到c++記憶體漏失時要知道它的含義?
記憶體漏失(memory leak)是指由於疏忽或錯誤造成了程式未能釋放掉不再使用的記憶體的情況。記憶體漏失並非指記憶體在物理上的消失,而是應用程式分配某段記憶體後,由於設計錯誤,失去了對該段記憶體的控制,因而造成了記憶體的浪費。
(2)記憶體漏失的後果?
最難捉摸也最難檢測到的錯誤之一是記憶體漏失,即未能正確釋放以前分配的記憶體的 bug。 只發生一次的小的記憶體漏失可能不會被注意,但泄漏大量記憶體的程式或泄漏日益增多的程式可能會表現出各種徵兆:從效能不良(並且逐漸降低)到記憶體完全用盡。 更糟的是,泄漏的程式可能會用掉太多記憶體,以致另一個程式失敗,而使使用者無從查詢問題的真正根源。 此外,即使無害的記憶體漏失也可能是其他問題的徵兆。
(3)對於C和C++這種沒有垃圾回收機制 機製的語言來講,我們主要關注兩種型別的記憶體漏失:
堆記憶體漏失 (Heap leak)。對記憶體指的是程式執行中根據需要分配通過malloc,realloc new等從堆中分配的一塊記憶體,再是完成後必須通過呼叫對應的 free或者delete 刪掉。如果程式的設計的錯誤導致這部分記憶體沒有被釋放,那麼此後這塊記憶體將不會被使用,就會產生Heap Leak.
系統資源泄露(Resource Leak).主要指程式使用系統分配的資源比如 Bitmap,handle ,SOCKET等沒有使用相應的函數釋放掉,導致系統資源的浪費,嚴重可導致系統效能降低,系統執行不穩定。
(4)使用C/C++語言開發的軟體在執行時,出現記憶體漏失。可以使用以下兩種方式,進行檢查排除:
使用工具軟體BoundsChecker,BoundsChecker是一個執行時錯誤檢測工具,它主要定位程式執行時期發生的各種錯誤。
偵錯執行DEBUG版程式,運用以下技術:CRT(C run-time libraries)、執行時函數呼叫堆疊、記憶體漏失時提示的記憶體分配序號(整合開發環境OUTPUT視窗),綜合分析記憶體漏失的原因,排除記憶體漏失。
(5)解決記憶體漏失最有效的辦法就是使用智慧指針(Smart Pointer)。
使用智慧指針就不用擔心這個問題了,因爲智慧指針可以自動刪除分配的記憶體。智慧指針和普通指針類似,只是不需要手動釋放指針,而是通過智慧指針自己管理記憶體的釋放,這樣就不用擔心記憶體漏失的問題了。
45. 手寫智慧指針的實現(shared_ptr和weak_ptr實現的區別)
shared_ptr基於「參照計數」模型實現,多個shared_ptr可指向同一個動態物件,並維護了一個共用的參照計數器,記錄了參照同一物件的shared_ptr範例的數量。當最後一個指向動態物件的shared_ptr銷燬時,會自動銷燬其所指物件(通過delete操作符)。
shared_ptr的預設能力是管理動態記憶體,但支援自定義的Deleter以實現個性化的資源釋放動作。
weak_ptr用於解決「參照計數」模型回圈依賴問題,weak_ptr指向一個物件,並不增減該物件的參照計數器
46. 智慧指針的回圈參照
C++11中引入了三種智慧指針,分別是shared_ptr、weak_ptr和unique_ptr
智慧指針的作用
智慧指針可以幫助我們管理動態分配的堆記憶體,減少記憶體漏失的可能性
手動管理堆記憶體有引起記憶體漏失的可能,比如這段程式碼
try {
int* p = new int;
// Do something
delete p;
} catch(...) {
// Catch exception
}
如果在執行Do something的時候發生了異常,那麼程式就會直接跳到catch語句捕獲異常,delete p這句程式碼不會被執行,發生了記憶體漏失
我們把上面的程式改成
try {
shared_ptr<int> p(new int);
// Do something
} catch(...) {
// Catch exception
}
當執行Do something的時候發生了異常,那麼try塊中的棧物件都會被解構。因此程式碼中p的解構函式會被呼叫,參照計數從1變成0,通過new分配的堆記憶體被釋放,這樣就避免了記憶體漏失的問題
(1)回圈參照問題
雖然智慧指針會減少記憶體漏失的可能性,但是如果使用智慧指針的方式不對,一樣會造成記憶體漏失。比較典型的情況是回圈參照問題,比如這段程式碼
class B; // 前置宣告
class A {
public:
shared_ptr<B> ptr;
};
class B {
public:
shared_ptr<A> ptr;
};
int main()
{
while(true) {
shared_ptr<A> pa(new A());
shared_ptr<B> pb(new B());
pa -> ptr = pb;
pb -> ptr = pa;
}
return 0;
}
這個程式中智慧指針的參照情況如下圖
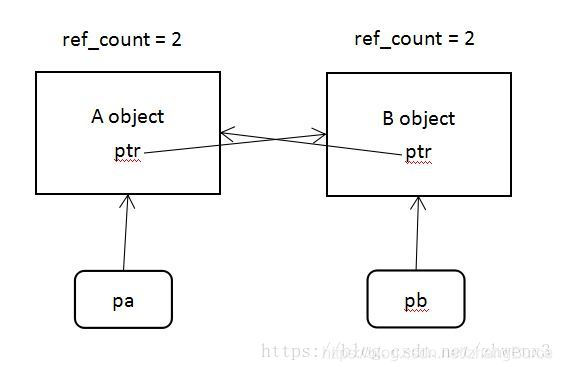
上圖中,class A和class B的物件各自被兩個智慧指針管理,也就是A object和B object參照計數都爲2,爲什麼是2?
分析class A物件的參照情況,該物件被main函數中的pa和class B物件中的ptr管理,因此A object參照計數是2,B object同理。
在這種情況下,在main函數中一個while回圈結束的時候,pa和pb的解構函式被呼叫,但是class A物件和class B物件仍然被一個智慧指針管理,A object和B object參照計數變成1,於是這兩個物件的記憶體無法被釋放,造成記憶體漏失,如下圖所示
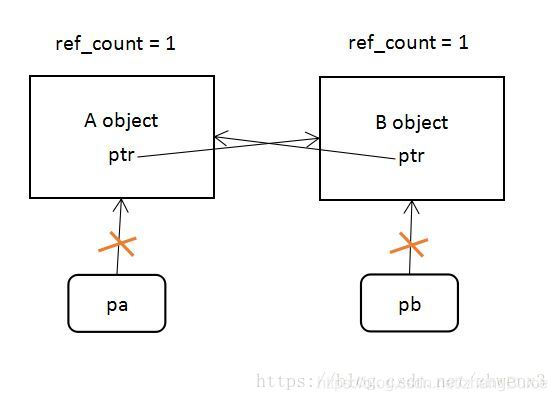
(2)解決方法
解決方法很簡單,把class A或者class B中的shared_ptr改成weak_ptr即可,由於weak_ptr不會增加shared_ptr的參照計數,所以A object和B object中有一個的參照計數爲1,在pa和pb解構時,會正確地釋放掉記憶體
(3)weak_ptr的使用
- weak_ptr是爲了配合shared_ptr而引入的一種智慧指針,因爲它不具有普通指針的行爲,沒有過載operator*和->,它的最大作用在於協助shared_ptr工作,像旁觀者那樣觀測資源的使用情況。
- weak_ptr可以從一個shared_ptr或者另一個weak_ptr物件構造,獲得資源的觀測權。但weak_ptr沒有共用資源,它的構造不會引起指針參照計數的增加。
- 使用weak_ptr的成員函數use_count()可以觀測資源的參照計數,另一個成員函數expired()的功能等價於use_count()==0,但更快,表示被觀測的資源(也就是shared_ptr的管理的資源)已經不復存在。
- weak_ptr可以使用一個非常重要的成員函數lock()從被觀測的shared_ptr獲得一個可用的shared_ptr物件, 從而操作資源。但當expired()==true的時候,lock()函數將返回一個儲存空指針的shared_ptr。
使用 weak_ptr 解決 shared_ptr 因回圈引有不能釋放資源的問題
- 使用 shared_ptr 時, shared_ptr 爲強參照, 如果存在回圈參照, 將導致記憶體泄露. 而 weak_ptr 爲弱參照, 可以避免此問題, 其原理:
- 對於弱參照來說, 當參照的物件活着的時候弱參照不一定存在. 僅僅是當它存在的時候的一個參照, 弱參照並不修改該物件的參照計數, 這意味這弱參照它並不對物件的記憶體進行管理.
- weak_ptr 在功能上類似於普通指針, 然而一個比較大的區別是, 弱參照能檢測到所管理的物件是否已經被釋放, 從而避免存取非法記憶體。
注意: 雖然通過弱參照指針可以有效的解除回圈參照, 但這種方式必須在程式設計師能預見會出現回圈參照的情況下才能 纔能使用, 也可以是說這個僅僅是一種編譯期的解決方案, 如果程式在執行過程中出現了回圈參照, 還是會造成記憶體漏失.
47. 遇到coredump要怎麼偵錯
記憶體漏失的方法很多,可以用gdb開啓core檔案,確定出錯的堆疊地點,從而判斷程式出錯的位置。
eg:
core dump又叫核心轉儲。當程式執行過程中發生異常, 程式異常退出時, 由操作系統把程式當前的記憶體狀況儲存在一個core檔案中, 叫core dump。
(1)ulimit -c unlimited命令設定coredump檔案
(2)gdb a.out core命令執行程式(linux下)
(3)使用bt命令檢視堆疊
48. 記憶體檢查工具的瞭解
linux可以使用開源的Valgrind工具包,包含多個工具:Memcheck常用語檢測malloc和new這類的問題,callgrind用來檢查函數呼叫,cachegrind快取使用,helgrind多執行緒程式中的競爭。除了valgrind還可以用mtrace這些工具
49. 模板的用法與適用場景
模板是C11裏面新增的,使用與在不知道型別的情況下,編寫一個泛型的程式,模板通過用一個指定的關鍵字來代替型別,進行泛型程式設計。
應用場景:應用場景很多,例如我們要程式設計一些和型別無關的程式碼時,STL裏面的很多容器都是用到了模板,容器的功能都可以使用,但並沒有確定容器裏面一定要用指定的型別,可以是任何的型別。
50. 成員初始化列表的概念,爲什麼用成員初始化列表會快一些(效能優勢)?
成員初始化列表:
- 在類建構函式中,不在函數體內對變數賦值,而在參數列表後,跟一個冒號和初始化列表。
- 初始化和賦值對內建型別的成員沒有什麼大的區別,像上面的人一個建構函式都可以。對非內建型別成員變數,爲了避免兩次構造,推薦使用類建構函式初始化列表。
但是有時候必須使用帶初始化列表的建構函式:
- 成員型別是沒有預設建構函式的類。若沒有提供顯示初始化,則類建立物件時會呼叫預設建構函式,如果沒有預設建構函式,則必須顯示初始化。
- const成員或者參照型別的成員。因爲const物件或者參照型別只能初始化,不能賦值。 子類初始化父類別的私有成員
爲什麼成員初始化列表效率更高?
- 因爲對於非內建型別,少了一次呼叫預設建構函式的過程。
類物件的構造順序是這樣的:
(1)分配記憶體,呼叫建構函式時,隱式/顯示的初始化各數據成員;
(2)進入建構函式後在建構函式中執行一般賦值與計算。
類物件的構造順序顯示,進入建構函式體後,進行的是計算,是對成員變數的賦值操作,顯然,賦值和初始化是不同的,這樣就體現出了效率差異,如果不用成員初始化類表,那麼類對自己的類成員分別進行的是一次隱式的預設建構函式的呼叫,和一次賦值操作符的呼叫,如果是類物件,這樣做效率就得不到保障。
注意:建構函式需要初始化的數據成員,不論是否顯示的出現在建構函式的成員初始化列表中,都會在該處完成初始化,並且初始化的順序和其在類中宣告時的順序是一致的,與列表的先後順序無關,所以要特別注意,保證兩者順序一致才能 纔能真正保證其效率和準確性。
51. 用過C++ 11嗎,知道C++ 11哪些新特性?
例如:decltype,lambda表達式,智慧指針, forward_list,tuple,正則表達式庫,亂數
nullptr 專門代表空指針
auto 自動進行型別推導
引入了基於範圍的迭代寫法for(auto &i : arr)
初始化列表
引入了外部模板,能夠顯式的告訴編譯器何時進行模板的範例化
可以指定模板的預設參數
引入了委託構造的概念,這使得建構函式可以在同一個類中一個建構函式呼叫另一個建構函式
提供了一個匿名函數的特性
52. C++的呼叫慣例(簡單一點C++函數呼叫的壓棧過程)
對於程式,編譯器會對其分配一段記憶體,在邏輯上可以分爲程式碼段,數據段,堆,棧
程式碼段:儲存程式文字,指令指針EIP就是指向程式碼段,可讀可執行不可寫
數據段:儲存初始化的全域性變數和靜態變數,可讀可寫不可執行
BSS:未初始化的全域性變數和靜態變數
堆(Heap):動態分配記憶體,向地址增大的方向增長,可讀可寫可執行
棧(Stack):存放區域性變數,函數參數,當前狀態,函數呼叫資訊等,向地址減小的方向增長,非常非常重要,可讀可寫可執行
程式開始,從main開始,首先將參數壓入棧,然後壓入函數返回地址,進行函數呼叫,通過跳轉指定進入函數,將函數內部的變數去堆疊上開闢空間,執行函數功能,執行完成,取回函數返回地址,進行下一個函數。
53. C++的四種強制轉換
四種強制轉換是static_cast、dynamic_cast、const_cast、reinterpret_cast。
static_cast:靜態強制轉換,類似傳統c語言裏面括號的強制轉換
dynamic_cast:動態強制轉換,主要應用於多型,父子類的型別轉換,dynamic_cast和static_cast不同的是,它會檢查型別轉換是否正確,不能轉換,則會返回null,所以不算是強制轉換。
const_cast:取出const屬性,比較簡單,可以把const型別轉換爲非conse指針型別。
reinterpret_cast:一種非常隨意的二進制轉換,簡單理解對一個二進制序列的重新解釋。
54. C++中將臨時變數作爲返回值的時候的處理過程(棧上的記憶體分配、拷貝過程)
對於所呼叫的函數裏面的臨時變數,在函數呼叫過程中是被壓到程式進程的棧中的,當函數退出時,臨時變數出棧,即臨時變數已經被銷燬,臨時變數佔用的記憶體空間沒有被清空,但是已經可以被分配給其他變數了,所以有可能在函數退出時,該記憶體已經被修改了,對於臨時變數來說已經是沒有意義的值了。
在C中,16bit程式中,返回值儲存在ax暫存器中,32bit程式中,返回值保持在eax暫存器中,如果是64bit返回值,edx暫存器儲存高32bit,eax暫存器儲存低32bit。
綜上,函數是可以將臨時變數的值作爲返回值的。
但是將一個指向區域性變數的指針作爲函數的返回值是有問題的。
由於指針指向區域性變數,因此在函數返回時,臨時變數被銷燬,指針指向一塊無意義的地址空間,所以一般不會有返回值。
如果得到正常的值,只能是幸運的,因爲退出函數的時候,系統只是修改了棧頂的指針,並沒有清記憶體;所以,是有可能正常存取到區域性變數的記憶體的。但因爲棧是系統自動管理的,所以該記憶體可能會可以被分配給其他函數,這樣,該記憶體的內容就會被覆蓋,不再是原來的值了。
常規程式中,函數返回的指針(函數指針,陣列指針,結構體指針,聯合體指針等)通常應該是:
(1)指向靜態(static)變數;
(2)指向專門申請分配的(如用malloc)空間;
(3)指向常數區(如指向字串"hello");
(4)指向全域性變數;
(5)指向程式程式碼區(如指向函數的指針)。
除這5項以外,其它怪技巧不提倡。
函數內的變數,沒有關鍵字static修飾的變數的生命週期只在本函數內,函數結束後變數自動銷燬。當返回爲指針的時候需要特別注意,因爲函數結束後指針所指向的地址依然存在,但是該地址可以被其他程式修改,裏面的內容就不確定了,有可能後面的操作會繼續用到這塊地址,有可能不會用到,所以會出現時對時錯的情況,如果需要返回一個指針而又不出錯的話只能呼叫記憶體申請函數
對於結構體和聯合體來說,在作爲函數的參數和返回值時,表現與C語言的內建型別(int,float, char等)是一樣的,當爲臨時變數的時候,作爲返回值時有效的。這個也是與指針不同的地方,所以一定要區分好,總是爲當返回結構體或者聯合體的時候,該怎麼處理,原來直接返回就可以了…
55. C++的例外處理
https://www.cnblogs.com/nbk-zyc/p/12449331.html c++中的例外處理
http://c.biancheng.net/view/422.html C++例外處理(try catch throw)完全攻略
56. volatile關鍵字
禁止編譯器優化,每次從記憶體中讀取數據,有利於執行緒安全。
volatile用在如下的幾個地方:
- 中斷服務程式中修改的供其它程式檢測的變數需要加volatile;
- 多工環境下各任務間共用的標誌應該加volatile;
- 記憶體對映的硬體暫存器通常也要加volatile說明,因爲每次對它的讀寫都可能由不同意義;
57. 優化程式的幾種方法
轉載自:http://www.708luo.com/?p=36
冗餘的變數拷貝
相對C而言,寫C++程式碼經常一不小心就會引入一些臨時變數,比如函數實參、函數返回值。在臨時變數之外,也會有其他一些情況會帶來一些冗餘的變數拷貝。
之前針對冗餘的變數拷貝問題寫過一些貼文,詳情請點選這裏。
多重過濾
很多服務都會過濾的部分結果的需求,比如遊戲交談中過濾需要過濾掉敏感詞。假設現在有兩個過濾詞典,一個詞典A內容較少,另一個詞典B內容較多,現在有1000個詞需要驗證合法性。
詞落在詞典A中的概率是1%,落在詞典B中的概率是10%,而判斷詞是否落在詞典A或B中的操作耗時差不多,記作N。
那麼要判斷詞是否合法,有兩種方式:
-
先判斷詞是否在A中,如果在返回非法;如果不在再判斷是否在B中,如果在返回非法,否則返回合法。
-
和方式一類似,不過是先判斷是否在B中。
現在我們來計算兩種方式的耗時:
-
1000N+1000(1-1%)*N
-
1000N+1000(1-10%)*N
很明顯,方式二的過濾操作排序優化方式一。
說得有些囉嗦,其實簡單點說就是一句話:多重過濾中把強過濾前移;過濾強度差不多時,過濾消耗較小的前移。
如果有些過濾條件較強,但是過濾消耗也較大怎麼辦?該前移還是後移?個人到沒遇到過這種情況,如果確實需要考慮,也可以用之前計算方式一、二整體耗時的方法也計算一遍。
字元陣列的初始化
一些情況是:寫程式碼時,很多人爲了省事或者說安全起見,每次申請一段記憶體之後都先全部初始化爲0。
另一些情況是:用了一些API,不瞭解底層實現,把申請的記憶體全部初始化爲0了,比如char buf[1024]=""的方式,有篇貼文寫得比較細,請看這裏。
上面提到兩種記憶體初始化爲0的情況,其實有些時候並不是必須的。比如把char型陣列作爲string使用的時候只需要初始化第一個元素爲0即可,或者把char型陣列作爲一個buffer使用的大部分時候根本不需要初始化。
頻繁的記憶體申請、釋放操作
曾經遇到過一個效能問題是:一個服務在啓動了4-5小時之後,效能突然下降。
檢視系統狀態發現,這時候CPU的sys態比較高,同時又發現系統的minflt值迅速增加,於是懷疑是記憶體的申請、釋放造成的效能下降。
最後定位到是服務的處理執行緒中,在處理請求時有大量申請和釋放記憶體的操作。定位到原因之後就好辦了,直接把臨時申請的記憶體改爲執行緒變數,效能一下子回升了。
能夠迅速的懷疑到是臨時的記憶體申請造成的效能下降,還虧之前看過這篇貼文。
至於爲什麼是4-5小時之後,效能突然下降,則懷疑是記憶體碎片的問題。
提前計算
這裏需要提到的有兩類問題:
-
區域性的冗餘計算:回圈體內的計算提到回圈體之前
-
全域性的冗餘計算
問題1很簡單,大部分人應該都接觸到過。有人會問編譯器不是對此有對應的優化措施麼?對,公共子表達式優化是可以解決一些這個問題。不過實測發現如果回圈體內是呼叫的某個函數,即使這個函數是沒有side effect的,編譯器也無法針對這種情況進行優化。(我是用gcc 3.4.5測試的,不排除更高版本的gcc或者其他編譯器可以針對這種情況進行優化)
對於問題2,我遇到的情況是:服務程式碼中定義了一個const變數,假設叫做MAX_X,處理請求是,會計算一個pow(MAX_X)用作過濾閾值,而效能分析發現,這個pow操作佔了整體系統CPU佔用的10%左右。對於這個問題,我的優化方式很簡單,直接計算定義一個MAX_X_POW變數用作過濾即可。程式碼修改2行,效能提升10%。
空間換時間
這其實是老生常談、在大學裏就經常提到的問題了。
不過第一次深有體會的應用卻是在前段時間剛遇到。簡單來說是這樣一個應用場景:系統內有一份詞表和一份非法詞表,原來的處理邏輯是根據請求中的數據查詢到對應的詞(很多),然後用非法詞表過濾掉其中非法的部分。對系統做效能分析發現,依次判斷查詢出來的詞是否在非法詞表中的操作比較耗效能,能佔整體系統消耗CPU的15-20%。後來的優化手段其實也不復雜,就是服務啓動載入詞表和非法詞表的時候,再生成一張合法詞表,請求再來的時候,直接在合法詞表中查到結果即可。不直接用合法詞表代替原來那份總的詞表的原因是,總的詞表還是其他用途。
內聯頻繁呼叫的短小函數
很多人知道這個問題,但是有時候會不太關注,個人揣測可能的原因有:
-
編譯器會內聯小函數
-
覺得函數呼叫的消耗也不是特別大
針對1,我的看法是,即使編譯器會內聯小函數,如果把函數定義寫在cpp檔案中並在另外一個cpp中呼叫該函數,這時編譯器無法內聯該呼叫。
針對2,我的實際經驗是,內聯了一個每個請求呼叫幾百次的get操作之後,響應時間減少5%左右。
位運算代替乘除法
據說如果是常數的運算的話,編譯器會自動優化選擇最優的計算方式。這裏的常數計算不僅僅是指"48"這樣的操作,也可能是"ab"但編譯的時候編譯器已經可以知道a和b的值。
不過在編譯階段無法知道變數值的時候,將*、/、% 2的冪的運算改爲位運算,對效能有時還是蠻有幫助的。
我遇到的一次優化經歷是,將每個請求都會呼叫幾十到數百次不等的函數中一個*8改爲<<3和一個%8改爲&7之後,伺服器的響應時間減少了5%左右。
下面 下麪是我實測的一些數據:
%2的次方可以用位運算代替,a%8=a&7(兩倍多效率提升)
/2的次方可以用移位運算代替,a/8=a>>3(兩倍多效率提升)
2的次方可以用移位運算代替,a8=a<<3(小數值測試效率不明顯,大數值1.5倍效率)
整數次方不要用pow,ii比pow(i,2)快8倍,ii*i比pow快40倍
strncpy, snprintf效率對比:目標串>>源串 strncpy效率低,源串>>目標串 snprintf效率低
編譯優化
gcc編譯的時候,很多服務都是採用O2的優化選項了。不過在使用公共庫的時候,可能沒注意到就使用了一個沒開任何優化的產出了。我就遇到過至少3個服務因爲打開了tcmalloc庫的O2選項之後效能提升有10%以上的。
不過開O2優化,有些時候可能會遇到一些非預期的結果,比如這篇貼文提到的memory aliasing的問題。
58. public,protected和private存取許可權和繼承
(1) 存取許可權
- public 這型別成員可以被類本身函數存取,也可以被外部建立的類物件呼叫。子類物件與子類內部可以存取
- protected型別成員,只能被類本身函數存取。外部建立的類物件沒有存取許可權。子類物件沒有存取許可權,子類內部可以存取
- private型別成員,只能被類本身函數存取,外部建立的類物件沒有存取許可權。子類物件和子類內部都沒有存取許可權
(2)繼承關係的存取控制
- public繼承,public繼承使子類順延父類別的存取控制屬性,即成員保持父類別的控制屬性,這樣在子類中的成員存取控制同父類別的一樣
- protected繼承,將父類別public和protected屬性的成員屬性順延到子類來後變成protected屬性。protected屬性是可以提供給子類在內部存取的。
- private繼承。這種繼承方式中斷了後續子類對當前類的父類別的所有存取許可權,在該種繼承方式下,會將父類別public和protected屬性順延成private屬性。這樣,即使後面子類再次繼承,都沒有了對當前父類別的成員的存取許可權。
60. decltype()和auto
auto
1.編譯器通過分析表達式的型別來確定變數的型別,所以auto定義的變數必須有初始值。
auto i=10; //ok,i爲整型
auto j; //error,定義時必須初始化。
j=2;
2.auto可以在一條語句中宣告多個變數,但該語句中所有變數的初始值型別必須有一樣。
auto i=0,*P=&i; //ok,i是整數,p是整型指針
auto a=2,b=3.14; //error,a和b型別不一致
3.auto會忽略掉頂層const,同時底層const則會保留下來
const int a=2,&b=a;
auto c=a; //c是int 型,而不是const int,即忽略了頂層const
auto d=&a; //d是一個指向const int 的指針,即保留了底層const
如果希望auto型別是一個頂層const ,需要明確指出:
const auto e=a; //e是const int 型別
4.當使用陣列作爲auto變數的初始值時,推斷得到的變數型別是指針,而非陣列
int a[10]={1,2,3,4,5,6,7,8,9,0}
auto b=a; //b是int *型別,指向陣列的第一個元素
int c[2][3]={1}
auto d=c; //d是int(*d)[3]型別的陣列指針
for(auto e:c) //e是int*型別,而不是int(*)[3]
for(auto &f:c) //f是int(&f)[3]
//**************************************************
decltype (a) c; //c是由10個整型數構成的陣列,c[10]
decltype
decltype和auto功能型別,但略有區別:
1.decltype根據表達式型別確定變數型別,但不要求定義時進行初始化
int a=2;
decltype (a) b; //b是int型別
b=3;
int &c=a;
decltype (c) d=a; //d爲int &型別,因此定義時必須初始化
2.解除參照指針操作將得到參照型別
int a=2,*b=a;
decltype (*b) c=a; //解除參照,c是int &型別,因此必須初始化
3.decltype所用的表達式加()得到的是該型別的參照
int a=2;
decltype ((a)) b=a; //b是int&型別,而不是int型別,必須初始化
decltype (a) c; //c是int型別
4.decltype所用變數時陣列時,得到的同類型的陣列,而不是指針
int a[2]={1,2}
decltype (a) b={3,4} //int b[2]型別
5.decltype所用變數是函數時,得到的是函數型別,而不是函數指針
int fun(int a);
decltype(fun) *f(); //函數f返回的是 int(*)(int),即函數指針,而decltype(fun)是int(int)型別
61. inline和宏定義的區別
(1)行內函式在編譯時展開,宏在預編譯時展開;
(2)行內函式直接嵌入到目的碼中,宏是簡單的做文字替換;
(3)行內函式有型別檢測、語法判斷等功能,而宏沒有;
(4)inline函數是函數,宏不是;
(5)宏定義時要注意書寫(參數要括起來)否則容易出現歧義,行內函式不會產生歧義;
62. C++和C的型別安全
型別安全很大程度上可以等價於記憶體安全,型別安全的程式碼不會試圖存取自己沒被授權的記憶體區域。絕對型別安全的程式語言暫時還沒有。
C語言的型別安全
C只在區域性上下文中表現出型別安全,比如試圖從一種結構體的指針轉換成另一種結構體的指針時,編譯器將會報告錯誤,除非使用顯式型別轉換。然而,C中相當多的操作是不安全的。
如果C++使用得當,它將遠比C更有型別安全性。相比於C,C++提供了一些新的機制 機製保障型別安全:
(1)操作符new返回的指針型別嚴格與物件匹配,而不是void *;
(2)C中很多以void*爲參數的函數可以改寫爲C++模板函數,而模板是支援型別檢查的;
(3)引入const關鍵字代替#define constants,它是有型別、有作用域的,而#define constants只是簡單的文字替換;
(4)一些#define宏可被改寫爲inline函數,結合函數的過載,可在型別安全的前提下支援多種型別,當然改寫爲模板也能保證型別安全;
(5)C++提供了dynamic_cast關鍵字,使得轉換過程更加安全,因爲dynamic_cast比static_cast涉及更多具體的型別檢查。即便如此,C++也不是絕對型別安全的程式語言。如果使用不得當,同樣無法保證型別安全。
63. 參考鏈接
https://blog.csdn.net/ask233/article/details/99713381
https://liyiye012.github.io/2018/09/21/C++%E9%9D%A2%E8%AF%95%E9%AB%98%E9%A2%91%E9%A2%98/
https://blog.csdn.net/weixin_43819197/article/details/94407751