學習 KVM 的系列文章:
1. 爲什麼需要 CPU 虛擬化
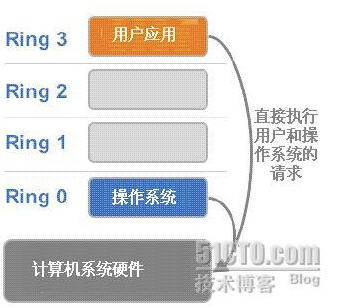
X86 操作系統是設計在直接執行在裸硬體裝置上的,因此它們自動認爲它們完全佔有計算機硬體。x86 架構提供四個特權級別給操作系統和應用程式來存取硬體。 Ring 是指 CPU 的執行級別,Ring 0是最高級別,Ring1次之,Ring2更次之…… 就 Linux+x86 來說,
-
操作系統(內核)需要直接存取硬體和記憶體,因此它的程式碼需要執行在最高執行級別 Ring0上,這樣它可以使用特權指令,控制中斷、修改頁表、存取裝置等等。
-
應用程式的程式碼執行在最低執行級別上ring3上,不能做受控操作。如果要做,比如要存取磁碟,寫檔案,那就要通過執行系統呼叫(函數),執行系統呼叫的時候,CPU的執行級別會發生從ring3到ring0的切換,並跳轉到系統呼叫對應的內核程式碼位置執行,這樣內核就爲你完成了裝置存取,完成之後再從ring0返回ring3。這個過程也稱作使用者態和內核態的切換。
那麼,虛擬化在這裏就遇到了一個難題,因爲宿主操作系統是工作在 ring0 的,客戶操作系統就不能也在 ring0 了,但是它不知道這一點,以前執行什麼指令,現在還是執行什麼指令,但是沒有執行許可權是會出錯的。所以這時候虛擬機器管理程式(VMM)需要避免這件事情發生。 虛機怎麼通過
VMM 實現 Guest CPU 對硬體的存取,根據其原理不同有三種實現技術:
1. 全虛擬化
2. 半虛擬化
3. 硬體輔助的虛擬化
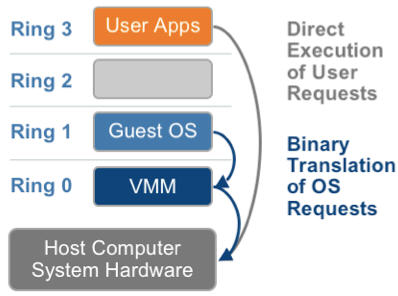
1.1 基於二進制翻譯的全虛擬化(Full Virtualization with Binary Translation)
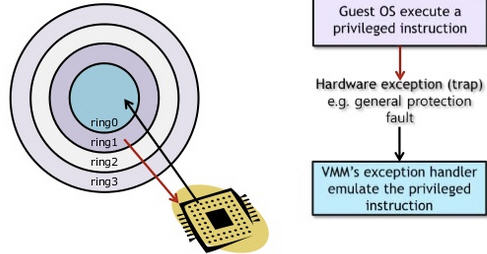
客戶操作系統執行在 Ring 1,它在執行特權指令時,會觸發異常(CPU的機制 機製,沒許可權的指令會觸發異常),然後 VMM 捕獲這個異常,在異常裏面做翻譯,模擬,最後返回到客戶操作系統內,客戶操作系統認爲自己的特權指令工作正常,繼續執行。但是這個效能損耗,就非常的大,簡單的一條指令,執行完,了事,現在卻要通過複雜的例外處理過程。
異常 「捕獲(trap)-翻譯(handle)-模擬(emulate)」 過程:
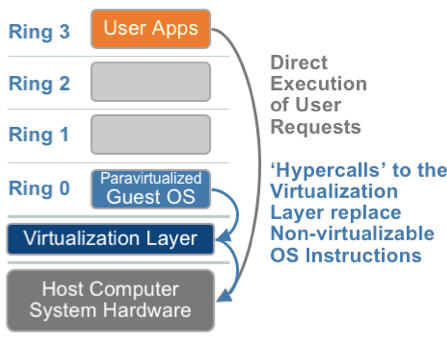
1.2. 超虛擬化(或者半虛擬化/操作系統輔助虛擬化 Paravirtualization)
半虛擬化的思想就是,修改操作系統內核,替換掉不能虛擬化的指令,通過超級呼叫(hypercall)直接和底層的虛擬化層hypervisor來通訊,hypervisor 同時也提供了超級呼叫介面來滿足其他關鍵內核操作,比如記憶體管理、中斷和時間保持。
這種做法省去了全虛擬化中的捕獲和模擬,大大提高了效率。所以像XEN這種半虛擬化技術,客戶機操作系統都是有一個專門的定製內核版本,和x86、mips、arm這些內核版本等價。這樣以來,就不會有捕獲異常、翻譯、模擬的過程了,效能損耗非常低。這就是XEN這種半虛擬化架構的優勢。這也是爲什麼XEN只支援虛擬化Linux,無法虛擬化windows原因,微軟不改程式碼啊。
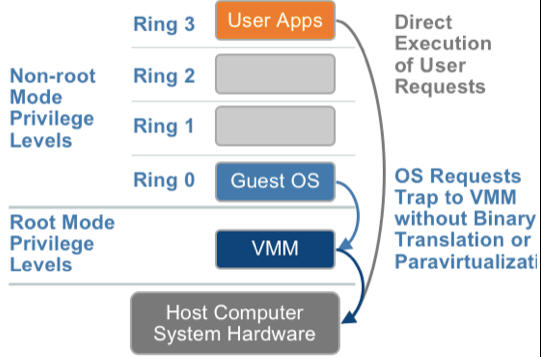
1.3. 硬體輔助的全虛擬化
2005年後,CPU廠商Intel 和 AMD 開始支援虛擬化了。 Intel 引入了 Intel-VT (Virtualization Technology)技術。 這種 CPU,有 VMX root operation 和 VMX non-root operation兩種模式,兩種模式都支援Ring 0 ~ Ring 3 共 4 個執行級別。這樣,VMM 可以執行在 VMX root operation模式下,客戶 OS 執行在VMX
non-root operation模式下。
而且兩種操作模式可以互相轉換。執行在 VMX root operation 模式下的 VMM 通過顯式呼叫 VMLAUNCH 或 VMRESUME 指令切換到 VMX non-root operation 模式,硬體自動載入 Guest OS 的上下文,於是 Guest OS 獲得執行,這種轉換稱爲 VM entry。Guest OS 執行過程中遇到需要 VMM 處理的事件,例如外部中斷或缺頁異常,或者主動呼叫 VMCALL 指令呼叫 VMM
的服務的時候(與系統呼叫類似),硬體自動掛起 Guest OS,切換到 VMX root operation 模式,恢復 VMM 的執行,這種轉換稱爲 VM exit。VMX root operation 模式下軟體的行爲與在沒有 VT-x 技術的處理器上的行爲基本一致;而VMX non-root operation 模式則有很大不同,最主要的區別是此時執行某些指令或遇到某些事件時,發生 VM exit。
也就說,硬體這層就做了些區分,這樣全虛擬化下,那些靠「捕獲異常-翻譯-模擬」的實現就不需要了。而且CPU廠商,支援虛擬化的力度越來越大,靠硬體輔助的全虛擬化技術的效能逐漸逼近半虛擬化,再加上全虛擬化不需要修改客戶操作系統這一優勢,全虛擬化技術應該是未來的發展趨勢。
|
|
利用二進制翻譯的全虛擬化
|
硬體輔助虛擬化
|
操作系統協助/半虛擬化
|
|
實現技術 |
BT和直接執行
|
遇到特權指令轉到root模式執行
|
Hypercall
|
|
客戶操作系統修改/相容性 |
無需修改客戶操作系統,最佳相容性
|
無需修改客戶操作系統,最佳相容性
|
客戶操作系統需要修改來支援hypercall,因此它不能執行在物理硬體本身或其他的hypervisor上,相容性差,不支援Windows
|
|
效能 |
差
|
全虛擬化下,CPU需要在兩種模式之間切換,帶來效能開銷;但是,其效能在逐漸逼近半虛擬化。
|
好。半虛擬化下CPU效能開銷幾乎爲0,虛機的效能接近於物理機。
|
|
應用廠商 |
VMware Workstation/QEMU/Virtual PC
|
VMware ESXi/Microsoft Hyper-V/Xen 3.0/KVM
|
Xen
|
2. KVM CPU 虛擬化
KVM 是基於CPU 輔助的全虛擬化方案,它需要CPU虛擬化特性的支援。
2.1. CPU 物理特性
這個命令檢視主機上的CPU 物理情況:
[s1@rh65 ~]$ numactl --hardware
available: 2 nodes (0-1) //2顆CPU node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17 //這顆 CPU 有8個內核 node 0 size: 12276 MB
node 0 free: 7060 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23 node 1 size: 8192 MB
node 1 free: 6773 MB
node distances:
node 0 1 0: 10 21 1: 21 10
要支援 KVM, Intel CPU 的 vmx 或者 AMD CPU 的 svm 擴充套件必須生效了:
[root@rh65 s1]# egrep "(vmx|svm)" /proc/cpuinfo
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 popcnt aes lahf_lm arat epb dts tpr_shadow vnmi flexpriority ept vpid
2.2 多 CPU 伺服器架構:SMP,NMP,NUMA
從系統架構來看,目前的商用伺服器大體可以分爲三類:
-
多處理器結構 (SMP : Symmetric Multi-Processor):所有的CPU共用全部資源,如匯流排,記憶體和I/O系統等,操作系統或管理數據庫的複本只有一個,這種系統有一個最大的特點就是共用所有資源。多個CPU之間沒有區別,平等地存取記憶體、外設、一個操作系統。SMP 伺服器的主要問題,那就是它的擴充套件能力非常有限。實驗證明, SMP 伺服器 CPU 利用率最好的情況是 2 至 4 個 CPU 。
-
海量並行處理結構 (MPP : Massive Parallel Processing) :NUMA 伺服器的基本特徵是具有多個 CPU 模組,每個 CPU 模組由多個 CPU( 如 4 個 ) 組成,並且具有獨立的本地記憶體、 I/O 槽口等。在一個物理伺服器內可以支援上百個 CPU 。但 NUMA 技術同樣有一定缺陷,由於存取遠地記憶體的延時遠遠超過本地記憶體,因此當 CPU 數量增加時,系統效能無法線性增加。
-
MPP 模式則是一種分佈式記憶體模式,能夠將更多的處理器納入一個系統的記憶體。一個分佈式記憶體模式具有多個節點,每個節點都有自己的記憶體,可以設定爲SMP模式,也可以設定爲非SMP模式。單個的節點相互連線起來就形成了一個總系統。MPP可以近似理解成一個SMP的橫向擴充套件叢集,MPP一般要依靠軟體實現。
-
非一致儲存存取結構 (NUMA : Non-Uniform Memory Access):它由多個 SMP 伺服器通過一定的節點網際網路絡進行連線,協同工作,完成相同的任務,從使用者的角度來看是一個伺服器系統。其基本特徵是由多個 SMP 伺服器 ( 每個 SMP 伺服器稱節點 ) 通過節點網際網路絡連線而成,每個節點只存取自己的本地資源 ( 記憶體、儲存等 ) ,是一種完全無共用 (Share Nothing) 結構。
詳細描述可以參考 SMP、NUMA、MPP體系結構介紹。
檢視你的伺服器的 CPU 架構:
[root@rh65 s1]# uname -a
Linux rh65 2.6.32-431.el6.x86_64 #1 SMP Sun Nov 10 22:19:54 EST 2013 x86_64 x86_64 x86_64 GNU/Linux #這伺服器是 SMP 架構
2.2 KVM CPU 虛擬化
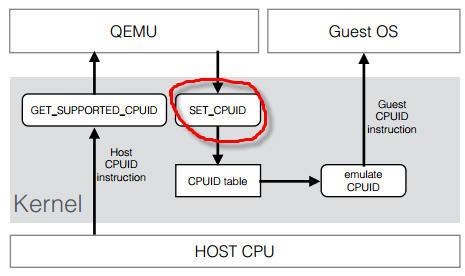
2.2.1 KVM 虛機的建立過程
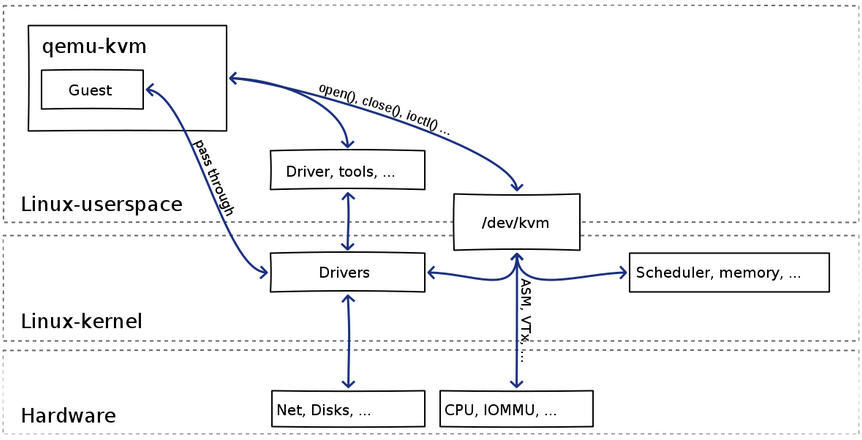
可見:
(1)qemu-kvm 通過對 /dev/kvm 的 一系列 ICOTL 命令控制虛機,比如
open("/dev/kvm", O_RDWR|O_LARGEFILE) = 3 ioctl(3, KVM_GET_API_VERSION, 0) = 12 ioctl(3, KVM_CHECK_EXTENSION, 0x19) = 0 ioctl(3, KVM_CREATE_VM, 0) = 4 ioctl(3, KVM_CHECK_EXTENSION, 0x4) = 1 ioctl(3, KVM_CHECK_EXTENSION, 0x4) = 1 ioctl(4, KVM_SET_TSS_ADDR, 0xfffbd000) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0x25) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0xb) = 1 ioctl(4, KVM_CREATE_PIT, 0xb) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0xf) = 2 ioctl(3, KVM_CHECK_EXTENSION, 0x3) = 1 ioctl(3, KVM_CHECK_EXTENSION, 0) = 1 ioctl(4, KVM_CREATE_IRQCHIP, 0) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0x1a) = 0
(2)一個 KVM 虛機即一個 Linux qemu-kvm 進程,與其他 Linux 進程一樣被Linux 進程排程器排程。
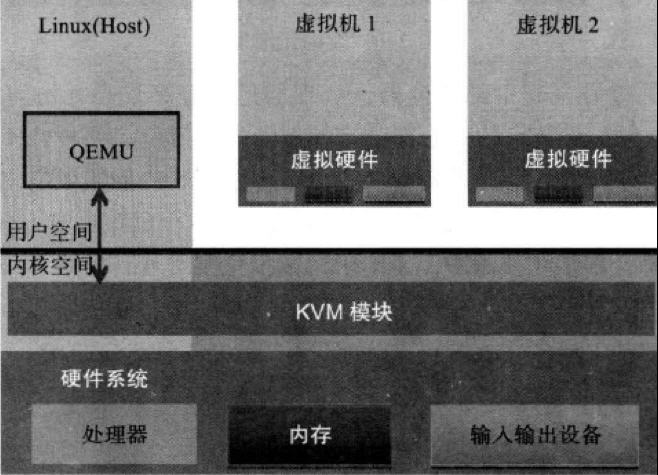
(3)KVM 虛機包括虛擬記憶體、虛擬CPU和虛機 I/O裝置,其中,記憶體和 CPU 的虛擬化由 KVM 內核模組負責實現,I/O 裝置的虛擬化由 QEMU 負責實現。
(3)KVM戶機系統的記憶體是 qumu-kvm 進程的地址空間的一部分。
(4)KVM 虛機的 vCPU 作爲 執行緒執行在 qemu-kvm 進程的上下文中。
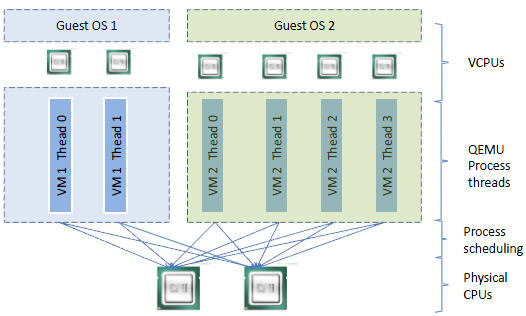
vCPU、QEMU 進程、LInux 進程排程和物理CPU之間的邏輯關係:
2.2.2 因爲 CPU 中的虛擬化功能的支援,並不存在虛擬的 CPU,KVM Guest 程式碼是執行在物理 CPU 之上
根據上面的 1.3 章節,支援虛擬化的 CPU 中都增加了新的功能。以 Intel VT 技術爲例,它增加了兩種執行模式:VMX root 模式和 VMX nonroot 模式。通常來講,主機操作系統和 VMM 執行在 VMX root 模式中,客戶機操作系統及其應用執行在 VMX nonroot 模式中。因爲兩個模式都支援所有的 ring,因此,客戶機可以執行在它所需要的 ring 中(OS 執行在 ring 0 中,應用執行在 ring 3 中),VMM 也執行在其需要的 ring 中 (對 KVM
來說,QEMU 執行在 ring 3,KVM 執行在 ring 0)。CPU 在兩種模式之間的切換稱爲 VMX 切換。從 root mode 進入 nonroot mode,稱爲 VM entry;從 nonroot mode 進入 root mode,稱爲 VM exit。可見,CPU 受控制地在兩種模式之間切換,輪流執行 VMM 程式碼和 Guest OS 程式碼。
對 KVM 虛機來說,執行在 VMX Root Mode 下的 VMM 在需要執行 Guest OS 指令時執行 VMLAUNCH 指令將 CPU 轉換到 VMX non-root mode,開始執行客戶機程式碼,即 VM entry
過程;在 Guest OS 需要退出該 mode 時,CPU 自動切換到 VMX Root mode,即 VM exit 過程。可見,KVM 客戶機程式碼是受 VMM 控制直接執行在物理 CPU 上的。QEMU 只是通過 KVM 控制虛機的程式碼被 CPU 執行,但是它們本身並不執行其程式碼。也就是說,CPU 並沒有真正的被虛級化成虛擬的 CPU 給客戶機使用。
這篇文章 是關於
vSphere 中 CPU 虛擬化的,我覺得它和 KVM CPU 虛擬化存在很大的一致。下圖是使用 2 socket 2 core 共 4 個 vCPU 的情形:
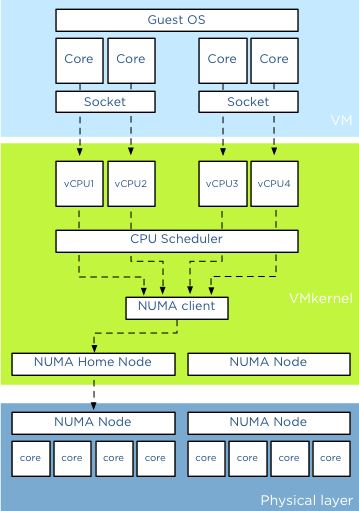
幾個概念:socket (顆,CPU 的物理單位),core (核,每個 CPU 中的物理內核),thread (超執行緒,通常來說,一個 CPU core 只提供一個 thread,這時客戶機就只看到一個 CPU;但是,超執行緒技術實現了 CPU 核的虛擬化,一個核被虛擬化出多個邏輯 CPU,可以同時執行多個執行緒)。
上圖分三層,他們分別是是VM層,VMKernel層和物理層。對於物理伺服器而言,所有的CPU資源都分配給單獨的操作系統和上面執行的應用。應用將請求先發送給操作系統,然後操作系統排程物理的CPU資源。在虛擬化平臺比如 KVM 中,在VM層和物理層之間加入了VMkernel層,從而允許所有的VM共用物理層的資源。VM上的應用將請求發送給VM上的操作系統,然後操縱系統排程Virtual CPU資源(操作系統認爲Virtual
CPU和物理 CPU是一樣的),然後VMkernel層對多個物理CPU Core進行資源排程,從而滿足Virtual CPU的需要。在虛擬化平臺中OS CPU Scheduler和Hyperviisor CPU Scheduler都在各自的領域內進行資源排程。
KVM 中,可以指定 socket,core 和 thread 的數目,比如 設定 「-smp 5,sockets=5,cores=1,threads=1」,則 vCPU 的數目爲 5*1*1 = 5。客戶機看到的是基於 KVM vCPU 的 CPU 核,而 vCPU 作爲 QEMU 執行緒被 Linux 作爲普通的執行緒/輕量級進程排程到物理的 CPU 核上。至於你是該使用多
socket 和 多core,這篇文章 有仔細的分析,其結論是在
VMware ESXi 上,效能沒什麼區別,只是某些客戶機操作系統會限制物理 CPU 的數目,這種情況下,可以使用少 socket 多 core。
2.2.3 客戶機系統的程式碼是如何執行的
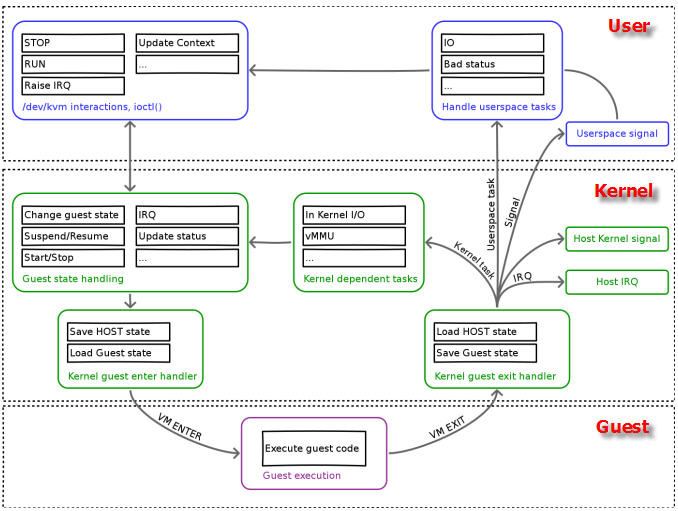
一個普通的 Linux 內核有兩種執行模式:內核模式(Kenerl)和使用者模式 (User)。爲了支援帶有虛擬化功能的 CPU,KVM 向 Linux 內核增加了第三種模式即客戶機模式(Guest),該模式對應於 CPU 的 VMX non-root mode。
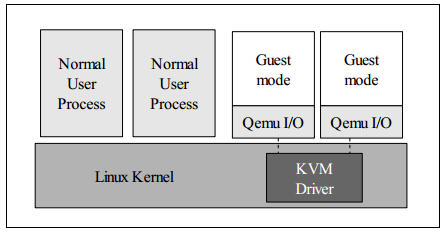
KVM 內核模組作爲 User mode 和 Guest mode 之間的橋樑:
-
User mode 中的 QEMU-KVM 會通過 ICOTL 命令來執行虛擬機器
-
KVM 內核模組收到該請求後,它先做一些準備工作,比如將 VCPU 上下文載入到 VMCS (virtual machine control structure)等,然後驅動 CPU 進入 VMX non-root 模式,開始執行客戶機程式碼
三種模式的分工爲:
-
Guest 模式:執行客戶機系統非 I/O 程式碼,並在需要的時候驅動 CPU 退出該模式
-
Kernel 模式:負責將 CPU 切換到 Guest mode 執行 Guest OS 程式碼,並在 CPU 退出 Guest mode 時回到 Kenerl 模式
-
User 模式:代表客戶機系統執行 I/O 操作
(來源)
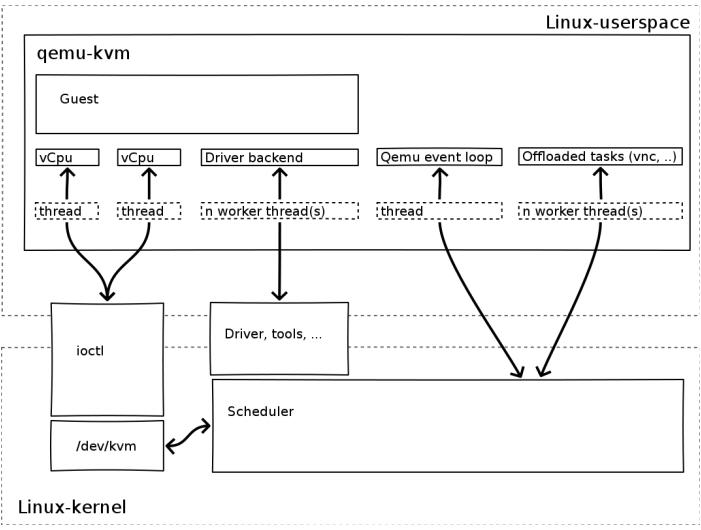
QEMU-KVM 相比原生 QEMU 的改動:
-
原生的 QEMU 通過指令翻譯實現 CPU 的完全虛擬化,但是修改後的 QEMU-KVM 會呼叫 ICOTL 命令來呼叫 KVM 模組。
-
原生的 QEMU 是單執行緒實現,QEMU-KVM 是多執行緒實現。
主機 Linux 將一個虛擬視作一個 QEMU 進程,該進程包括下面 下麪幾種執行緒:
-
I/O 執行緒用於管理模擬裝置
-
vCPU 執行緒用於執行 Guest 程式碼
-
其它執行緒,比如處理 event loop,offloaded tasks 等的執行緒
在我的測試環境中(RedHata Linux 作 Hypervisor):
|
smp 設定的值 |
執行緒數 |
執行緒 |
|
4 |
8 |
1 個主執行緒(I/O 執行緒)、4 個 vCPU 執行緒、3 個其它執行緒
|
|
6 |
10 |
1 個主執行緒(I/O 執行緒)、6 個 vCPU 執行緒、3 個其它執行緒 |
這篇文章 談談了這些執行緒的情況。
(來源)
|
客戶機程式碼執行(客戶機執行緒) |
I/O 執行緒 |
非 I/O 執行緒 |
|
虛擬CPU(主機 QEMU 執行緒) |
QEMU I/O 執行緒 |
QEMU vCPU 執行緒 |
|
物理 CPU |
物理 CPU 的 VMX non-root 模式中 |
物理 CPU 的 VMX non-root 模式中
|
2.2.4 從客戶機執行緒到物理 CPU 的兩次排程
要將客戶機內的執行緒排程到某個物理 CPU,需要經歷兩個過程:
-
客戶機執行緒排程到客戶機物理CPU 即 KVM vCPU,該排程由客戶機操作系統負責,每個客戶機操作系統的實現方式不同。在 KVM 上,vCPU 在客戶機系統看起來就像是物理 CPU,因此其排程方法也沒有什麼不同。
-
vCPU 執行緒排程到物理 CPU 即主機物理 CPU,該排程由 Hypervisor 即 Linux 負責。
KVM 使用標準的 Linux 進程排程方法來排程 vCPU 進程。Linux 系統中,執行緒和進程的區別是 進程有獨立的內核空間,執行緒是程式碼的執行單位,也就是排程的基本單位。Linux 中,執行緒是就是輕量級的進程,也就是共用了部分資源(地址空間、檔案控制代碼、號志等等)的進程,所以執行緒也按照進程的排程方式來進行排程。
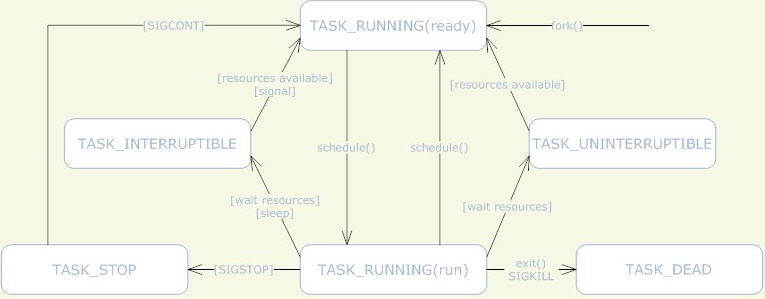
(1)Linux 進程排程原理可以參考 這篇文章 和 這篇文章。通常情況下,在SMP系統中,Linux內核的進程排程器根據自有的排程策略將系統中的一個可執行(runable)進程排程到某個CPU上執行。下面 下麪是
Linux 進程的狀態機:
(2)處理器親和性:可以設定 vCPU 在指定的物理 CPU 上執行,具體可以參考這篇文章 和 這篇文章。
根據 Linux 進程排程策略,可以看出,在 Linux 主機上執行的 KVM 客戶機 的總 vCPU 數目最好是不要超過物理 CPU 內核數,否則,會出現執行緒間的 CPU 內核資源競爭,導致有虛機因爲 vCPU 進程等待而導致速度很慢。
關於這兩次排程,業界有很多的研究,比如上海交大的論文 Schedule Processes, not VCPUs 提出動態地減少 vCPU
的數目即減少第二次排程。
另外,這篇文章 談到的是 vSphere CPU 的排程方式,有空的時候可以研究下並和 KVM vCPU 的排程方式進行比較。
2.3 客戶機CPU結構和模型
KVM 支援 SMP 和 NUMA 多CPU架構的主機和客戶機。對 SMP 型別的客戶機,使用 「-smp」參數:
-smp [,cores=][,threads=][,sockets=][,maxcpus=]
對 NUMA 型別的客戶機,使用 「-numa」參數:
-numa [,mem=][,cpus=]][,nodeid=]
CPU 模型 (models)定義了哪些主機的 CPU 功能 (features)會被暴露給客戶機操作系統。爲了在具有不同 CPU 功能的主機之間做安全的遷移,qemu-kvm 往往不會將主機CPU的所有功能都暴露給客戶機。其原理如下:
你可以執行 qemu-kvm
-cpu ? 命令來獲取主機所支援的 CPU 模型列表。

[root@rh65 s1]# kvm -cpu ? x86 Opteron_G5 AMD Opteron 63xx class CPU
x86 Opteron_G4 AMD Opteron 62xx class CPU
x86 Opteron_G3 AMD Opteron 23xx (Gen 3 Class Opteron)
x86 Opteron_G2 AMD Opteron 22xx (Gen 2 Class Opteron)
x86 Opteron_G1 AMD Opteron 240 (Gen 1 Class Opteron)
x86 Haswell Intel Core Processor (Haswell)
x86 SandyBridge Intel Xeon E312xx (Sandy Bridge)
x86 Westmere Westmere E56xx/L56xx/X56xx (Nehalem-C)
x86 Nehalem Intel Core i7 9xx (Nehalem Class Core i7)
x86 Penryn Intel Core 2 Duo P9xxx (Penryn Class Core 2)
x86 Conroe Intel Celeron_4x0 (Conroe/Merom Class Core 2)
x86 cpu64-rhel5 QEMU Virtual CPU version (cpu64-rhel5)
x86 cpu64-rhel6 QEMU Virtual CPU version (cpu64-rhel6)
x86 n270 Intel(R) Atom(TM) CPU N270 @ 1.60GHz
x86 athlon QEMU Virtual CPU version 0.12.1 x86 pentium3
x86 pentium2
x86 pentium
x86 486 x86 coreduo Genuine Intel(R) CPU T2600 @ 2.16GHz
x86 qemu32 QEMU Virtual CPU version 0.12.1 x86 kvm64 Common KVM processor
x86 core2duo Intel(R) Core(TM)2 Duo CPU T7700 @ 2.40GHz
x86 phenom AMD Phenom(tm) 9550 Quad-Core Processor
x86 qemu64 QEMU Virtual CPU version 0.12.1 Recognized CPUID flags:
f_edx: pbe ia64 tm ht ss sse2 sse fxsr mmx acpi ds clflush pn pse36 pat cmov mca pge mtrr sep apic cx8 mce pae msr tsc pse de vme fpu
f_ecx: hypervisor rdrand f16c avx osxsave xsave aes tsc-deadline popcnt movbe x2apic sse4.2|sse4_2 sse4.1|sse4_1 dca pcid pdcm xtpr cx16 fma cid ssse3 tm2 est smx vmx ds_cpl monitor dtes64 pclmulqdq|pclmuldq pni|sse3
extf_edx: 3dnow 3dnowext lm|i64 rdtscp pdpe1gb fxsr_opt|ffxsr fxsr mmx mmxext nx|xd pse36 pat cmov mca pge mtrr syscall apic cx8 mce pae msr tsc pse de vme fpu
extf_ecx: perfctr_nb perfctr_core topoext tbm nodeid_msr tce fma4 lwp wdt skinit xop ibs osvw 3dnowprefetch misalignsse sse4a abm cr8legacy extapic svm cmp_legacy lahf_lm
[root@rh65 s1]#
每個 Hypervisor 都有自己的策略,來定義預設上哪些CPU功能會被暴露給客戶機。至於哪些功能會被暴露給客戶機系統,取決於客戶機的設定。qemu32 和 qemu64 是基本的客戶機 CPU 模型,但是還有其他的模型可以使用。你可以使用 qemu-kvm 命令的 -cpu 參數來指定客戶機的 CPU 模型,還可以附加指定的 CPU 特性。"-cpu" 會將該指定 CPU 模型的所有功能全部暴露給客戶機,即使某些特性在主機的物理CPU上不支援,這時候QEMU/KVM 會模擬這些特性,因此,這時候也許會出現一定的效能下降。
RedHat Linux 6 上使用預設的 cpu64-rhe16 作爲客戶機 CPU model:
你可以指定特定的 CPU model 和 feature:
qemu-kvm -cpu Nehalem,+aes
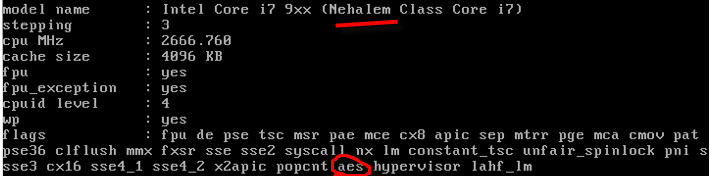
你也可以直接使用 -cpu host,這樣的話會客戶機使用和主機相同的 CPU model。
2.4 客戶機 vCPU 數目的分配方法
-
不是客戶機的 vCPU 越多,其效能就越好,因爲執行緒切換會耗費大量的時間;應該根據負載需要分配最少的 vCPU。
-
主機上的客戶機的 vCPU 總數不應該超過物理 CPU 內核總數。不超過的話,就不存在 CPU 競爭,每個 vCPU 執行緒在一個物理 CPU 核上被執行;超過的話,會出現部分執行緒等待 CPU 以及一個 CPU 核上的執行緒之間的切換,這會有 overhead。
-
將負載分爲計算負載和 I/O 負載,對計算負載,需要分配較多的 vCPU,甚至考慮 CPU 親和性,將指定的物理 CPU 核分給給這些客戶機。
這篇文章 (http://my.oschina.net/chape/blog/173981) 介紹了一些指導性方法,摘要如下:
我們來假設一個主機有 2 個socket,每個 socket 有 4 個core。主頻2.4G MHZ 那麼一共可用的資源是 2*4*2.4G= 19.2G MHZ。假設主機上執行了三個VM,VM1和VM2設定爲1socket*1core,VM3設定爲1socket*2core。那麼VM1和VM2分別有1個vCPU,而VM3有2個vCPU。假設其他設定爲預設設定。
那麼三個VM獲得該主機CPU資源分配如下:VM1:25%; VM2:25%; VM3:50%
假設執行在VM3上的應用支援多執行緒,那麼該應用可以充分利用到所非配的CPU資源。2vCPU的設定是合適的。假設執行在VM3上的應用不支援多執行緒,該應用根本無法同時使用利用2個vCPU. 與此同時,VMkernal層的CPU Scheduler必須等待物理層中兩個空閒的pCPU,纔開始資源調配來滿足2個vCPU的需要。在僅有2vCPU的情況下,對該VM的效能不會有太大負面影響。但如果分配4vCPU或者更多,這種資源排程上的負擔有可能會對該VM上執行的應用有很大負面影響。
確定 vCPU 數目的步驟。假如我們要建立一個VM,以下幾步可以幫助確定合適的vCPU數目
1 瞭解應用並設定初始值
該應用是否是關鍵應用,是否有Service Level Agreement。一定要對執行在虛擬機器上的應用是否支援多執行緒深入瞭解。諮詢應用的提供商是否支援多執行緒和SMP(Symmetricmulti-processing)。參考該應用在物理伺服器上執行時所需要的CPU個數。如果沒有參照資訊,可設定1vCPU作爲初始值,然後密切觀測資源使用情況。
2 觀測資源使用情況
確定一個時間段,觀測該虛擬機器的資源使用情況。時間段取決於應用的特點和要求,可以是數天,甚至數週。不僅觀測該VM的CPU使用率,而且觀測在操作系統內該應用對CPU的佔用率。特別要區分CPU使用率平均值和CPU使用率峯值。
假如分配有4個vCPU,如果在該VM上的應用的CPU
-
使用峯值等於25%, 也就是僅僅能最多使用25%的全部CPU資源,說明該應用是單執行緒的,僅能夠使用一個vCPU (4 * 25% = 1 )
-
平均值小於38%,而峯值小於45%,考慮減少 vCPU 數目
-
平均值大於75%,而峯值大於90%,考慮增加 vCPU 數目
3 更改vCPU數目並觀測結果
每次的改動儘量少,如果可能需要4vCPU,先設定2vCPU在觀測效能是否可以接受。
2. KVM 記憶體虛擬化
2.1 記憶體虛擬化的概念
除了 CPU 虛擬化,另一個關鍵是記憶體虛擬化,通過記憶體虛擬化共用物理系統記憶體,動態分配給虛擬機器。虛擬機器的記憶體虛擬化很象現在的操作系統支援的虛擬記憶體方式,應用程式看到鄰近的記憶體地址空間,這個地址空間無需和下面 下麪的物理機器記憶體直接對應,操作系統保持着虛擬頁到物理頁的對映。現在所有的
x86 CPU 都包括了一個稱爲記憶體管理的模組MMU(Memory Management Unit)和 TLB(Translation
Lookaside Buffer),通過MMU和TLB來優化虛擬記憶體的效能。
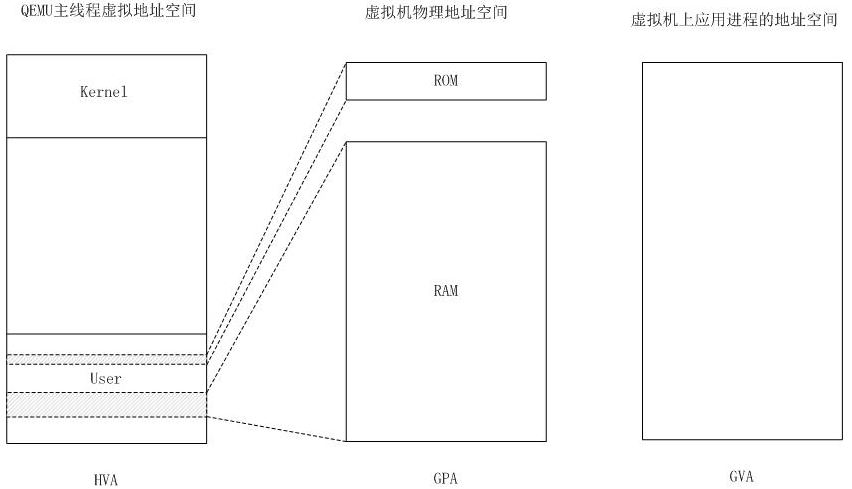
KVM 實現客戶機記憶體的方式是,利用mmap系統呼叫,在QEMU主執行緒的虛擬地址空間中申明一段連續的大小的空間用於客戶機實體記憶體對映。
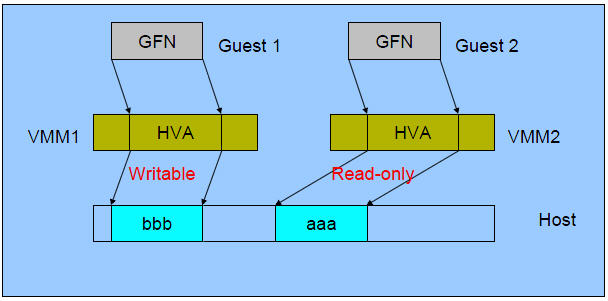
(圖片來源 HVA
同下面 下麪的 MA,GPA 同下面 下麪的 PA,GVA 同下面 下麪的 VA)
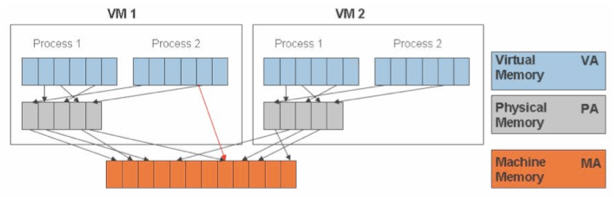
在有兩個虛機的情況下,情形是這樣的:
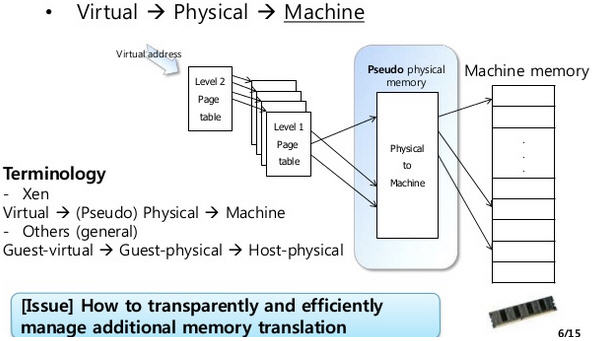
可見,KVM 爲了在一臺機器上執行多個虛擬機器,需要增加一個新的記憶體虛擬化層,也就是說,必須虛擬 MMU 來支援客戶操作系統,來實現 VA -> PA -> MA 的翻譯。客戶操作系統繼續控制虛擬地址到客戶記憶體實體地址的對映
(VA -> PA),但是客戶操作系統不能直接存取實際機器記憶體,因此VMM 需要負責對映客戶實體記憶體到實際機器記憶體 (PA -> MA)。
VMM 記憶體虛擬化的實現方式:
-
軟體方式:通過軟體實現記憶體地址的翻譯,比如 Shadow page table (影子頁表)技術
-
硬體實現:基於 CPU 的輔助虛擬化功能,比如 AMD 的 NPT 和 Intel 的 EPT 技術
影子頁表技術:
2.2 KVM 記憶體虛擬化
KVM 中,虛機的實體記憶體即爲 qemu-kvm 進程所佔用的記憶體空間。KVM 使用 CPU 輔助的記憶體虛擬化方式。在 Intel 和 AMD 平臺,其記憶體虛擬化的實現方式分別爲:
-
AMD 平臺上的 NPT (Nested Page Tables) 技術
-
Intel 平臺上的 EPT (Extended Page Tables)技術
EPT 和 NPT採用類似的原理,都是作爲 CPU 中新的一層,用來將客戶機的實體地址翻譯爲主機的實體地址。關於 EPT, Intel 官方文件中的技術如下(實在看不懂...)
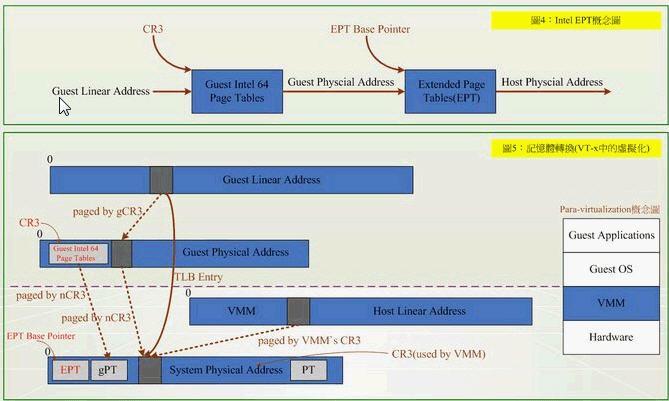
EPT的好處是,它的兩階段記憶體轉換,特點就是將 Guest Physical Address → System Physical Address,VMM不用再保留一份 SPT (Shadow Page Table),以及以往還得經過 SPT 這個轉換過程。除了降低各部虛擬機器器在切換時所造成的效能損耗外,硬體指令集也比虛擬化軟體處理來得可靠與穩定。
2.3 KSM (Kernel SamePage Merging 或者 Kernel Shared Memory)
KSM 在 Linux 2.6.32 版本中被加入到內核中。
2.3.1 原理
其原理是,KSM 作爲內核中的守護行程(稱爲 ksmd)存在,它定期執行頁面掃描,識別副本頁面併合並副本,釋放這些頁面以供它用。因此,在多個進程中,Linux將內核相似的記憶體頁合併成一個記憶體頁。這個特性,被KVM用來減少多個相似的虛擬機器的記憶體佔用,提高記憶體的使用效率。由於記憶體是共用的,所以多個虛擬機器使用的記憶體減少了。這個特性,對於虛擬機器使用相同映象和操作系統時,效果更加明顯。但是,事情總是有代價的,使用這個特性,都要增加內核開銷,用時間換空間。所以爲了提高效率,可以將這個特性關閉。
2.3.2 好處
其好處是,在執行類似的客戶機操作系統時,通過 KSM,可以節約大量的記憶體,從而可以實現更多的記憶體超分,執行更多的虛機。
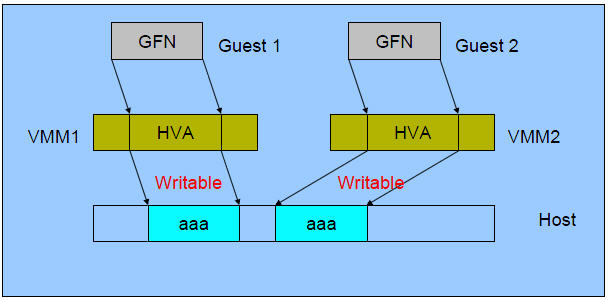
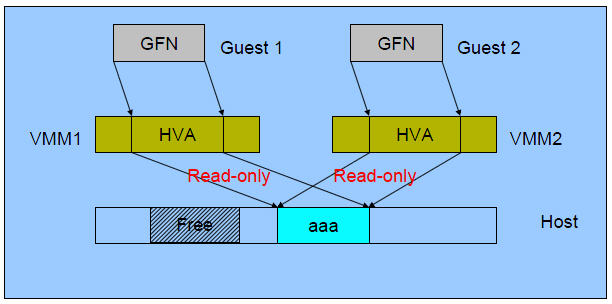
2.3.3 合併過程
(1)初始狀態:
(2)合併後:
(3)Guest 1 寫記憶體後:
2.4 KVM Huge Page Backed Memory (巨頁記憶體技術)
這是KVM虛擬機器的又一個優化技術.。Intel 的 x86 CPU 通常使用4Kb記憶體頁,當是經過設定,也能夠使用巨頁(huge page): (4MB on x86_32, 2MB on x86_64 and x86_32 PAE)
使用巨頁,KVM的虛擬機器的頁表將使用更少的記憶體,並且將提高CPU的效率。最高情況下,可以提高20%的效率!
使用方法,需要三部:
mkdir /dev/hugepages
mount -t hugetlbfs hugetlbfs /dev/hugepages
#保留一些記憶體給巨頁
sysctl vm.nr_hugepages=2048 (使用 x86_64 系統時,這相當於從實體記憶體中保留了2048 x 2M = 4GB 的空間來給虛擬機器使用)
#給 kvm 傳遞參數 hugepages
qemu-kvm - qemu-kvm -mem-path /dev/hugepages
也可以在組態檔裡加入:
驗證方式,當虛擬機器正常啓動以後,在物理機裡檢視:
cat /proc/meminfo |grep -i hugepages
老外的一篇文件,他使用的是libvirt方式,先讓libvirtd進程使用hugepages空間,然後再分配給虛擬機器。
參考資料:
http://www.cnblogs.com/xusongwei/archive/2012/07/30/2615592.html
https://www.ibm.com/developerworks/cn/linux/l-cn-vt/
http://www.slideshare.net/HwanjuKim/3cpu-virtualization-and-scheduling
http://www.cse.iitb.ac.in/~puru/courses/autumn12/cs695/classes/kvm-overview.pdf
http://www.linux-kvm.com/content/using-ksm-kernel-samepage-merging-kvm
http://blog.csdn.net/summer_liuwei/article/details/6013255
http://blog.pchome.net/article/458429.html
http://blog.chinaunix.net/uid-20794164-id-3601787.html
虛擬化技術效能比較和分析,周斌,張瑩
http://wiki.qemu.org/images/c/c8/Cpu-models-and-libvirt-devconf-2014.pdf
http://frankdenneman.nl/2011/01/11/beating-a-dead-horse-using-cpu-affinity/
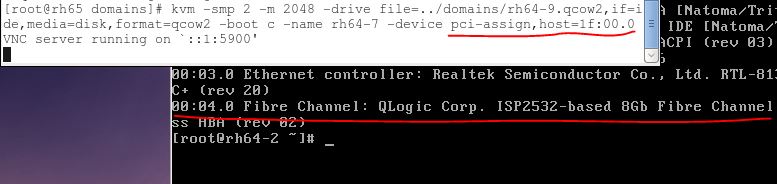
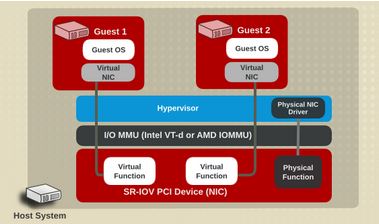
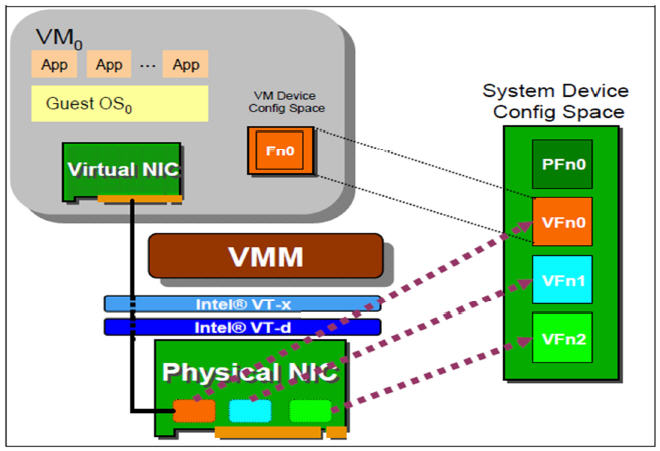
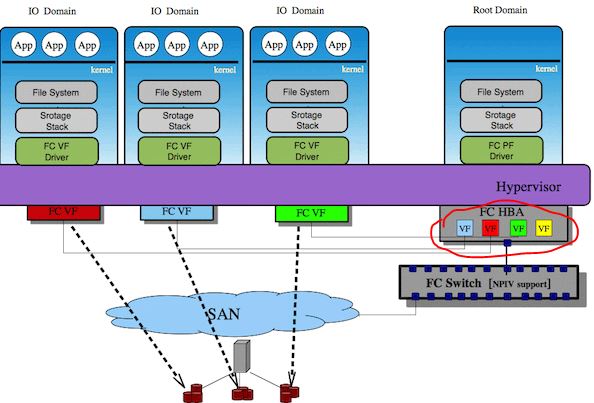
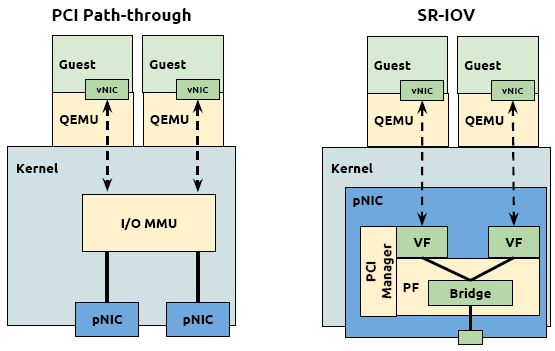
在 QEMU/KVM 中,客戶機可以使用的裝置大致可分爲三類:
1. 模擬裝置:完全由 QEMU 純軟體模擬的裝置。
2. Virtio 裝置:實現 VIRTIO API 的半虛擬化裝置。
3. PCI 裝置直接分配 (PCI device assignment) 。
1. 全虛擬化 I/O 裝置
KVM 在 IO 虛擬化方面,傳統或者預設的方式是使用 QEMU 純軟體的方式來模擬 I/O 裝置,包括鍵盤、滑鼠、顯示器,硬碟 和 網絡卡 等。模擬裝置可能會使用物理的裝置,或者使用純軟體來模擬。模擬裝置只存在於軟體中。
1.1 原理
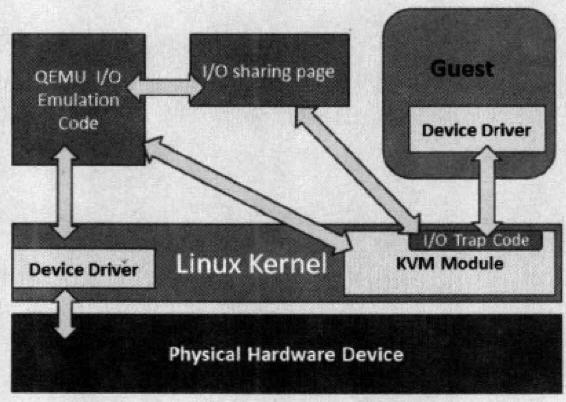
過程:
-
客戶機的裝置驅動程式發起 I/O 請求操作請求
-
KVM 模組中的 I/O 操作捕獲程式碼攔截這次 I/O 請求
-
經過處理後將本次 I/O 請求的資訊放到 I/O 共用頁 (sharing page),並通知使用者空間的 QEMU 程式。
-
QEMU 程式獲得 I/O 操作的具體資訊之後,交由硬體模擬程式碼來模擬出本次 I/O 操作。
-
完成之後,QEMU 將結果放回 I/O 共用頁,並通知 KMV 模組中的 I/O 操作捕獲程式碼。
-
KVM 模組的捕獲程式碼讀取 I/O 共用頁中的操作結果,並把結果放回客戶機。
注意:當客戶機通過DMA (Direct Memory Access)存取大塊I/O時,QEMU 模擬程式將不會把結果放進共用頁中,而是通過記憶體對映的方式將結果直接寫到客戶機的記憶體中共,然後通知KVM模組告訴客戶機DMA操作已經完成。
這種方式的優點是可以模擬出各種各樣的硬體裝置;其缺點是每次 I/O 操作的路徑比較長,需要多次上下文切換,也需要多次數據複製,所以效能較差。
1.2 QEMU 模擬網絡卡的實現
Qemu 純軟體的方式來模擬I/O裝置,其中包括經常使用的網絡卡裝置。Guest OS啓動命令中沒有傳入的網路設定時,QEMU預設分配 rtl8139 型別的虛擬網絡卡型別,使用的是預設使用者設定模式,這時候由於沒有具體的網路模式的設定,Guest的網路功能是有限的。 全虛擬化情況下,KVM虛機可以選擇的網路模式包括:
-
預設使用者模式(User);
-
基於網橋(Bridge)的模式;
-
基於NAT(Network Address Translation)的模式;
分別使用的 qemu-kvm 參數爲:
-
-net user[,vlan=n]:使用使用者模式網路堆疊,這樣就不需要管理員許可權來執行.如果沒有指 定-net選項,這將是預設的情況.-net tap[,vlan=n][,fd=h]
-
-net nic[,vlan=n][,macaddr=addr]:建立一個新的網絡卡並與VLAN n(在預設的情況下n=0)進行連線。作爲可選項的專案,MAC地址可以進行改變.如果 沒有指定-net選項,則會建立一個單一的NIC.
-
-net tap[,vlan=n][,fd=h][,ifname=name][,script=file]:將TAP網路介面 name 與 VLAN n 進行連線,並使用網路設定指令碼檔案進行 設定。預設的網路設定指令碼爲/etc/qemu-ifup。如果沒有指定name,OS 將會自動指定一個。fd=h可以用來指定一個已經開啓的TAP主機介面的控制代碼。
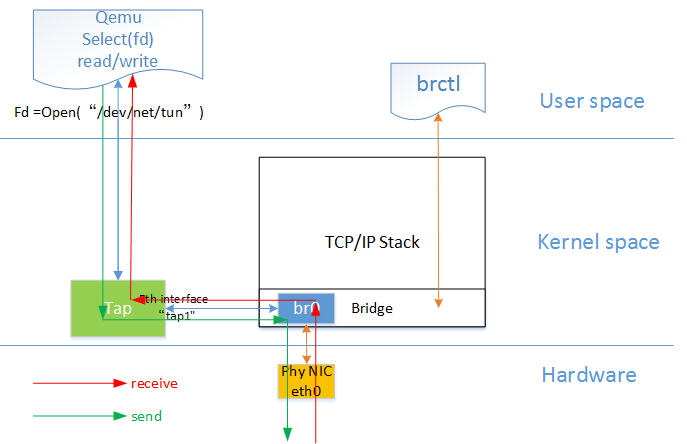
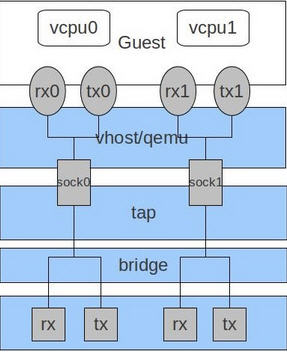
網橋模式是目前比較簡單,也是用的比較多的模式,下圖是網橋模式下的 VM的收發包的流程。
如圖中所示,紅色箭頭表示數據報文的入方向,步驟:
-
網路數據從 Host 上的物理網絡卡接收,到達網橋;
-
由於 eth0 與 tap1 均加入網橋中,根據二層轉發原則,br0 將數據從 tap1 口轉發出去,即數據由 Tap裝置接收;
-
Tap 裝置通知對應的 fd 數據可讀;
-
fd 的讀動作通過 tap 裝置的字元裝置驅動將數據拷貝到使用者空間,完成數據報文的前端接收。
(參照自 http://luoye.me/2014/07/17/netdev-virtual-1/)
1.3 RedHat Linux 6 中提供的模擬裝置
-
模擬顯示卡:提供2塊模擬顯示卡。
-
系統元件:
-
ntel i440FX host PCI bridge
-
PIIX3 PCI to ISA bridge
-
PS/2 mouse and keyboard
-
EvTouch USB Graphics Tablet
-
PCI UHCI USB controller and a virtualized USB hub
-
Emulated serial ports
-
EHCI controller, virtualized USB storage and a USB mouse
-
模擬的音效卡:intel-hda
-
模擬網絡卡:e1000,模擬 Intel E1000 網絡卡;rtl8139,模擬 RealTeck 8139 網絡卡。
-
模擬記憶卡:兩塊模擬 PCI IDE 介面卡。KVM 限制每個虛擬機器最多隻能有4塊虛擬記憶卡。還有模擬軟碟機。
注意:RedHat Linux KVM 不支援 SCSI 模擬。
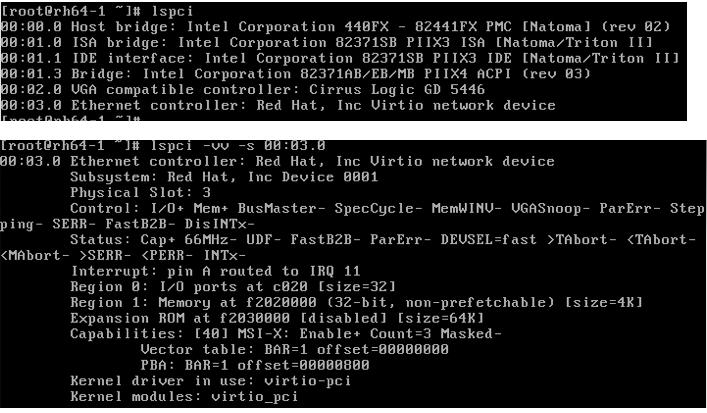
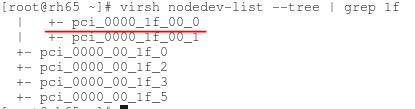
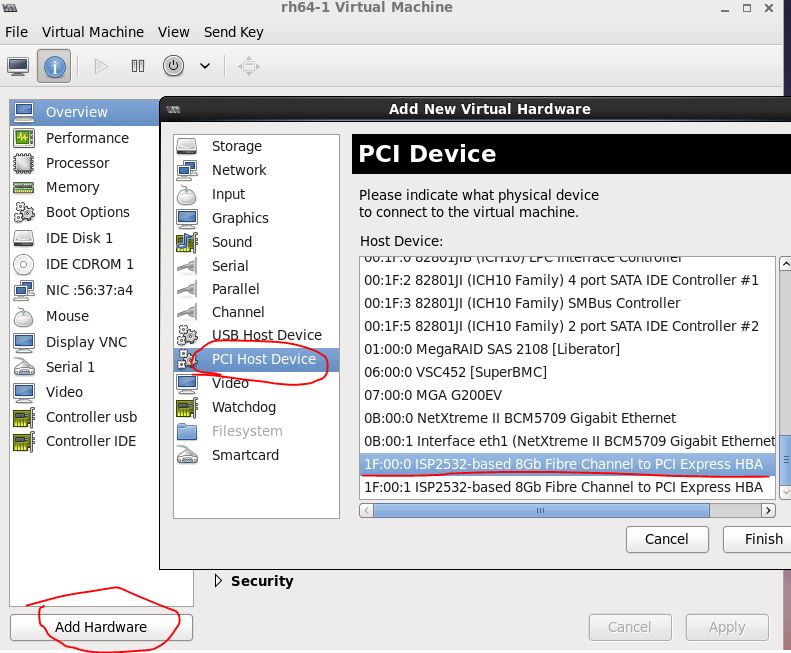
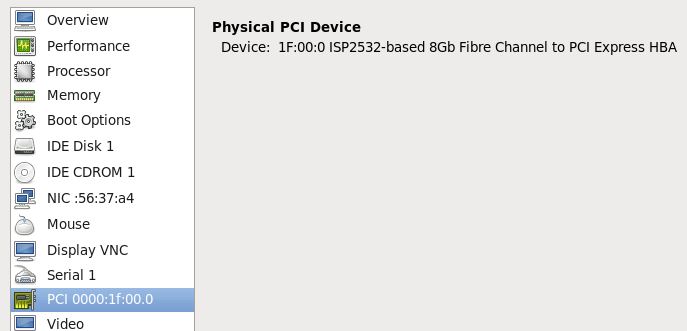
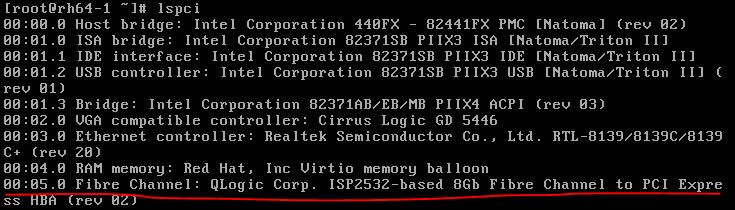
在不顯式指定使用其它型別裝置的情況下,KVM 虛機將使用這些預設的虛擬裝置。比如上面描述的預設情況下 KVM 虛機預設使用rtl8139網絡卡。比如,在 RedHat Linxu 6.5 主機上啓動KVM RedHat Linux 6.4 虛機後,登錄虛機,檢視 pci 裝置,可以看到這些模擬裝置:
當使用 「-net nic,model=e1000」 指定網絡卡model 爲 e1000 時,
1.4 qemu-kvm 關於磁碟裝置和網路的主要選項
|
型別 |
選項 |
|
磁碟裝置(軟碟、硬碟、CDROM等) |
-drive option[,option[,option[,...]]]:定義一個硬碟裝置;可用子選項有很多。
file=/path/to/somefile:硬體映像檔案路徑;
if=interface:指定硬碟裝置所連線的介面型別,即控制器型別,如ide、scsi、sd、mtd、floppy、pflash及virtio等;
index=index:設定同一種控制器型別中不同裝置的索引號,即標識號;
media=media:定義媒介型別爲硬碟(disk)還是光碟(cdrom); format=format:指定映像檔案的格式,具體格式可參見qemu-img命令;
-boot [order=drives][,once=drives][,menu=on|off]:定義啓動裝置的引導次序,每種裝置使用一個字元表示;不同的架構所支援的裝置及其表示字元不盡相同,在x86 PC架構上,a、b表示軟碟機、c表示第一塊硬碟,d表示第一個光碟機裝置,n-p表示網路適配器;預設爲硬碟裝置(-boot order=dc,once=d)
|
|
網路 |
-net nic[,vlan=n][,macaddr=mac][,model=type][,name=name][,addr=addr][,vectors=v]:建立一個新的網絡卡裝置並連線至vlan n中;PC架構上預設的NIC爲e1000,macaddr用於爲其指定MAC地址,name用於指定一個在監控時顯示的網上裝置名稱;emu可以模擬多個型別的網絡卡裝置;可以使用「qemu-kvm -net nic,model=?」來獲取當前平臺支援的型別;
-net tap[,vlan=n][,name=name][,fd=h][,ifname=name][,script=file][,downscript=dfile]:通過物理機的TAP網路介面連線至vlan n中,使用script=file指定的指令碼(預設爲/etc/qemu-ifup)來設定當前網路介面,並使用downscript=file指定的指令碼(預設爲/etc/qemu-ifdown)來撤消介面設定;使用script=no和downscript=no可分別用來禁止執行指令碼;
-net user[,option][,option][,...]:在使用者模式設定網路棧,其不依賴於管理許可權;有效選項有:
vlan=n:連線至vlan n,預設n=0;
name=name:指定介面的顯示名稱,常用於監控模式中;
net=addr[/mask]:設定GuestOS可見的IP網路,掩碼可選,預設爲10.0.2.0/8;
host=addr:指定GuestOS中看到的物理機的IP地址,預設爲指定網路中的第二個,即x.x.x.2;
dhcpstart=addr:指定DHCP服務地址池中16個地址的起始IP,預設爲第16個至第31個,即x.x.x.16-x.x.x.31;
dns=addr:指定GuestOS可見的dns伺服器地址;預設爲GuestOS網路中的第三個地址,即x.x.x.3;
tftp=dir:啓用內建的tftp伺服器,並使用指定的dir作爲tftp伺服器的預設根目錄;
bootfile=file:BOOTP檔名稱,用於實現網路引導GuestOS;如:qemu -hda linux.img -boot n -net user,tftp=/tftpserver/pub,bootfile=/pxelinux.0
|
對於網絡卡來說,你可以使用 modle 參數指定虛擬網路的型別。 RedHat Linux 6 所支援的虛擬網路型別有:
[root@rh65 isoimages]# kvm -net nic,model=? qemu: Supported NIC models: ne2k_pci,i82551,i82557b,i82559er,rtl8139,e1000,pcnet,virtio
2. 準虛擬化 (Para-virtualizaiton) I/O 驅動 virtio
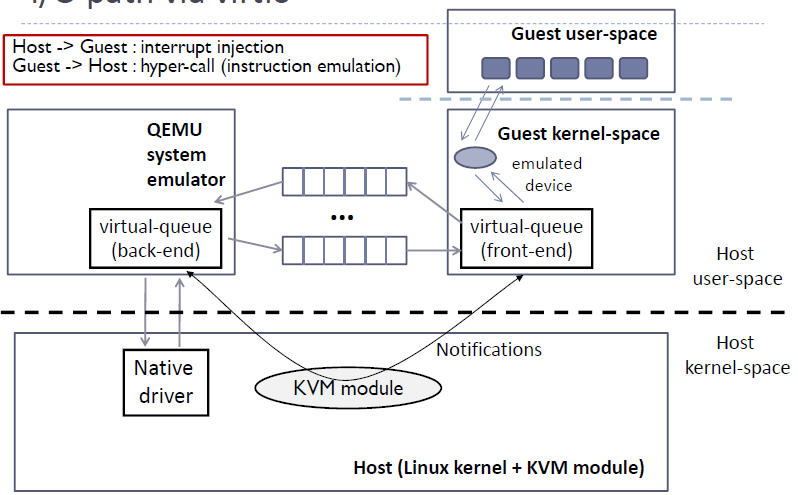
在 KVM 中可以使用準虛擬化驅動來提供客戶機的I/O 效能。目前 KVM 採用的的是 virtio 這個 Linux 上的裝置驅動標準框架,它提供了一種 Host 與 Guest 互動的 IO 框架。
2.1 virtio 的架構
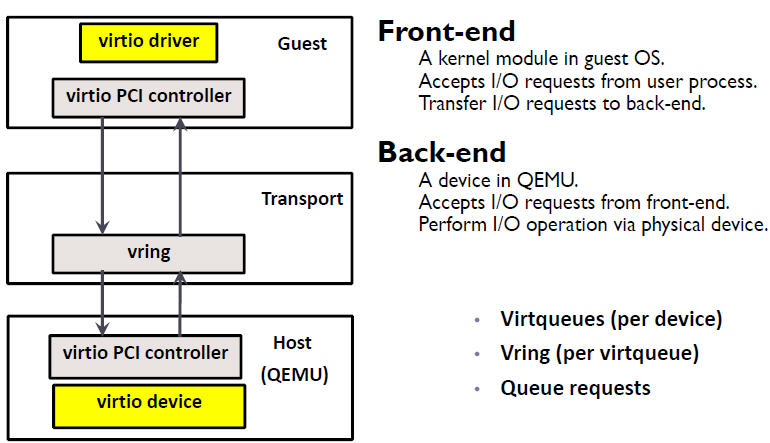
KVM/QEMU 的 vitio 實現採用在 Guest OS 內核中安裝前端驅動 (Front-end driver)和在 QEMU 中實現後端驅動(Back-end)的方式。前後端驅動通過 vring 直接通訊,這就繞過了經過 KVM 內核模組的過程,達到提高 I/O 效能的目的。
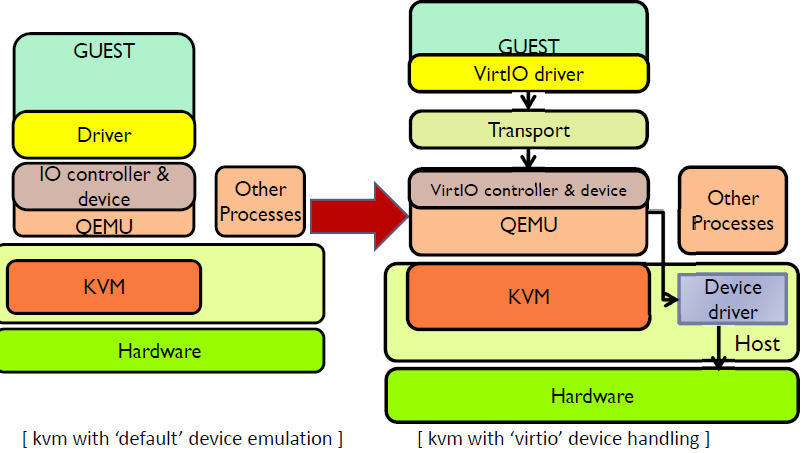
純軟體模擬的裝置和 Virtio 裝置的區別:virtio 省去了純模擬模式下的異常捕獲環節,Guest OS 可以和 QEMU 的 I/O 模組直接通訊。
使用 Virtio 的完整虛機 I/O流程:
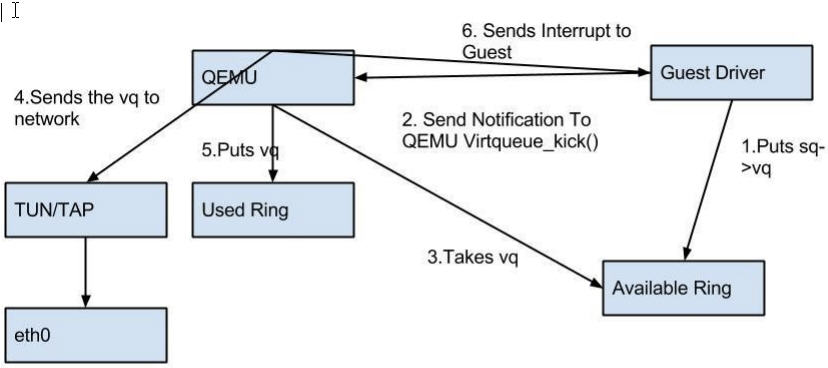
Host 數據發到 Guest:
1. KVM 通過中斷的方式通知 QEMU 去獲取數據,放到 virtio queue 中
2. KVM 再通知 Guest 去 virtio queue 中取數據。
2.2 Virtio 在 Linux 中的實現
Virtio 是在半虛擬化管理程式中的一組通用模擬裝置的抽象。這種設計允許管理程式通過一個應用程式設計介面 (API)對外提供一組通用模擬裝置。通過使用半虛擬化管理程式,客戶機實現一套通用的介面,來配合後面的一套後端裝置模擬。後端驅動不必是通用的,只要它們實現了前端所需的行爲。因此,Virtio 是一個在 Hypervisor 之上的抽象API介面,讓客戶機知道自己執行在虛擬化環境中,進而根據 virtio 標準與 Hypervisor 共同作業,從而客戶機達到更好的效能。
-
前端驅動:客戶機中安裝的驅動程式模組
-
後端驅動:在 QEMU 中實現,呼叫主機上的物理裝置,或者完全由軟體實現。
-
virtio 層:虛擬佇列介面,從概念上連線前端驅動和後端驅動。驅動可以根據需要使用不同數目的佇列。比如 virtio-net 使用兩個佇列,virtio-block只使用一個佇列。該佇列是虛擬的,實際上是使用 virtio-ring 來實現的。
-
virtio-ring:實現虛擬佇列的環形緩衝區
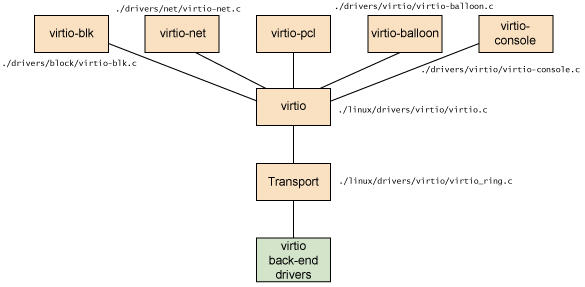
Linux 內核中實現的五個前端驅動程式:
-
塊裝置(如磁碟)
-
網路裝置
-
PCI 裝置
-
氣球驅動程式(動態管理客戶機記憶體使用情況)
-
控制檯驅動程式
Guest OS 中,在不使用 virtio 裝置的時候,這些驅動不會被載入。只有在使用某個 virtio 裝置的時候,對應的驅動纔會被載入。每個前端驅動器具有在管理程式中的相應的後端的驅動程式。
以 virtio-net 爲例,解釋其原理:
(1)virtio-net 的原理:
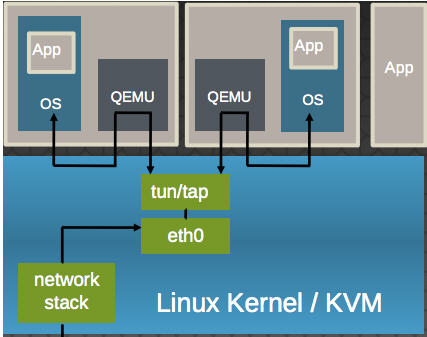
它使得:
-
多個虛機共用主機網絡卡 eth0
-
QEMU 使用標準的 tun/tap 將虛機的網路橋接到主機網絡卡上
-
每個虛機看起來有一個直接連線到主機PCI總線上的私有 virtio 網路裝置
-
需要在虛機裏面安裝 virtio驅動
(2)virtio-net 的流程:
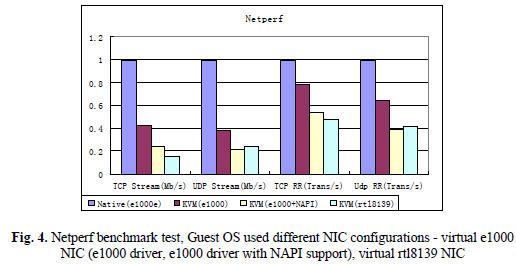
總結 Virtio 的優缺點:
-
優點:更高的IO效能,幾乎可以和原生系統差不多。
-
缺點:客戶機必須安裝特定的 virtio 驅動。一些老的 Linux 還沒有驅動支援,一些 Windows 需要安裝特定的驅動。不過,較新的和主流的OS都有驅動可以下載了。Linux 2.6.24+ 都預設支援 virtio。可以使用 lsmod | grep virtio 檢視是否已經載入。
2.3 使用 virtio 裝置 (以 virtio-net 爲例)
使用 virtio 型別的裝置比較簡單。較新的 Linux 版本上都已經安裝好了 virtio 驅動,而 Windows 的驅動需要自己下載安裝。
(1)檢查主機上是否支援 virtio 型別的網絡卡裝置
[root@rh65 isoimages]# kvm -net nic,model=? qemu: Supported NIC models: ne2k_pci,i82551,i82557b,i82559er,rtl8139,e1000,pcnet,virtio
(2)指定網絡卡裝置model 爲 virtio,啓動虛機

(3)通過 vncviewer 登錄虛機,能看到被載入了的 virtio-net 需要的內核模組

(4)檢視 pci 裝置
其它 virtio 型別的裝置的使用方式類似 virtio-net。
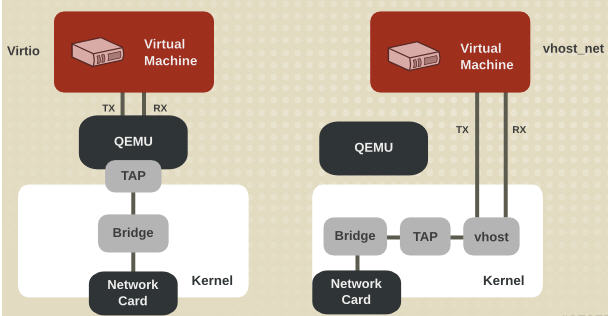
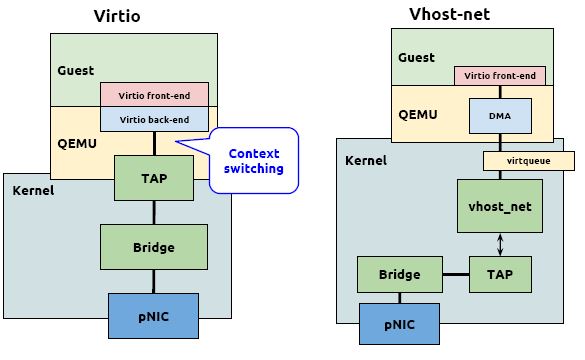
2.4 vhost-net (kernel-level virtio server)
前面提到 virtio 在宿主機中的後端處理程式(backend)一般是由使用者空間的QEMU提供的,然而如果對於網路 I/O 請求的後端處理能夠在在內核空間來完成,則效率會更高,會提高網路吞吐量和減少網路延遲。在比較新的內核中有一個叫做 「vhost-net」 的驅動模組,它是作爲一個內核級別的後端處理程式,將virtio-net的後端處理任務放到內核空間中執行,減少內核空間到使用者空間的切換,從而提高效率。
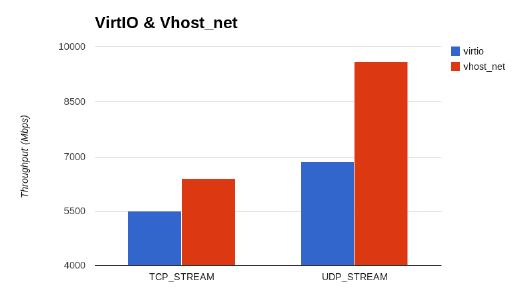
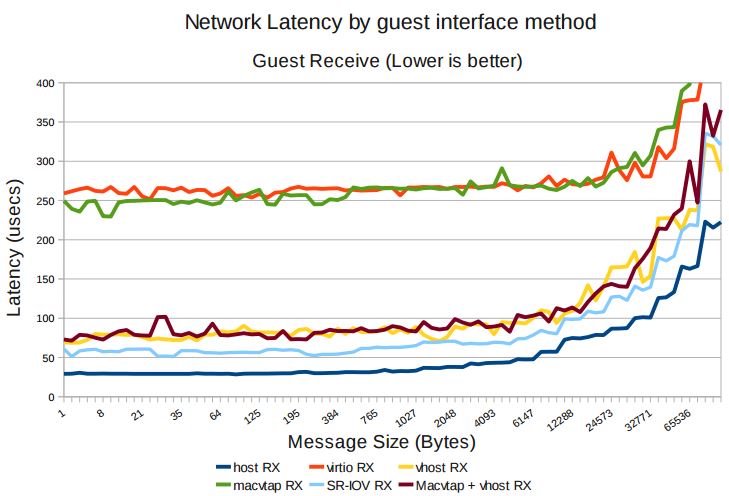
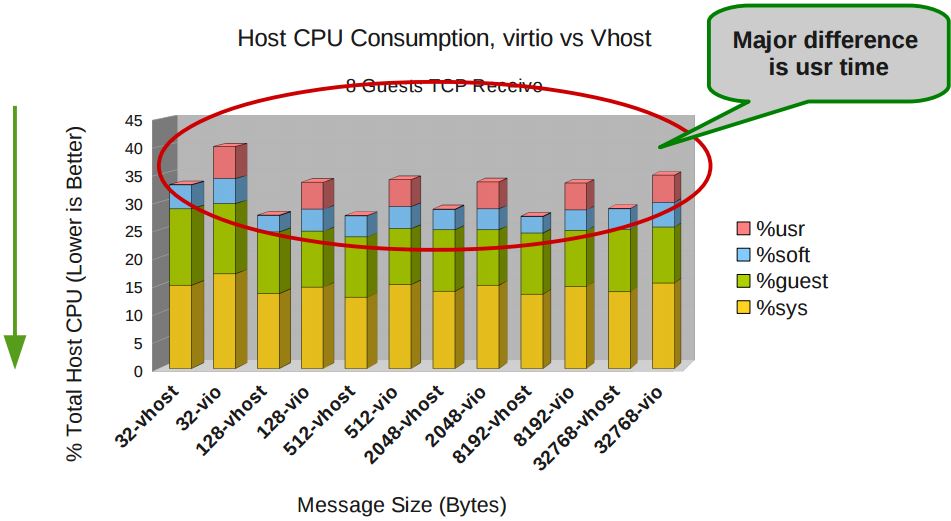
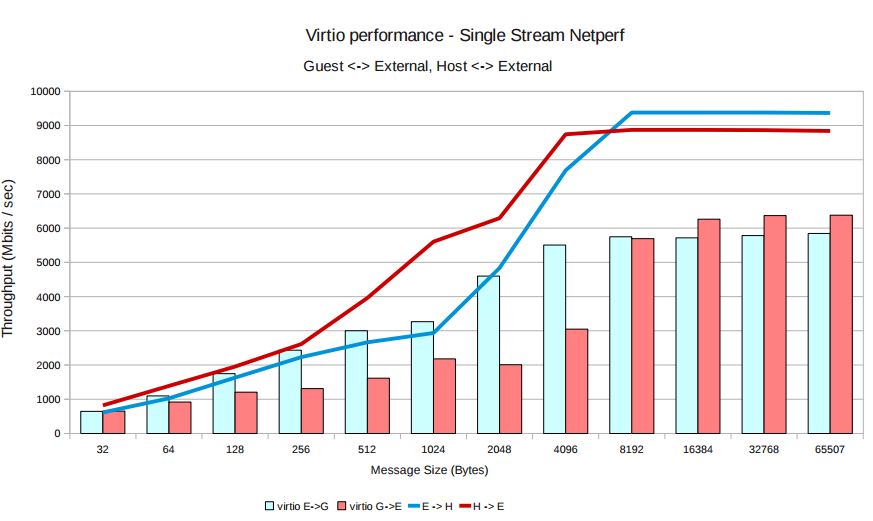
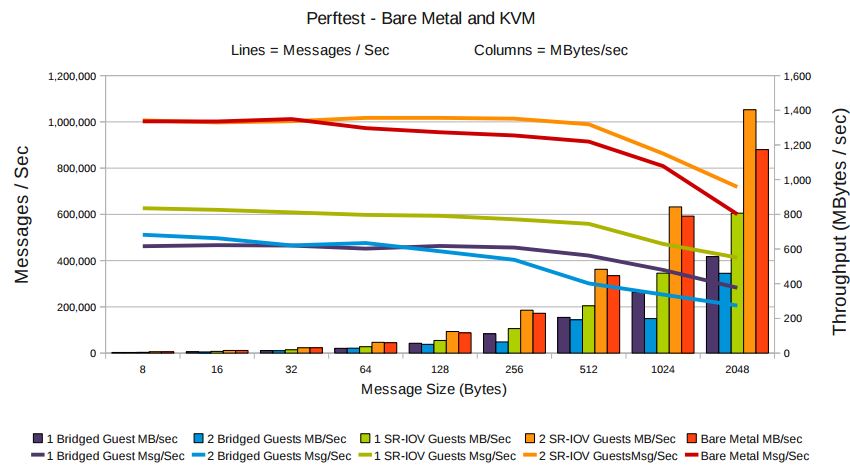
根據 KVM 官網的這篇文章,vhost-net 能提供更低的延遲(latency)(比 e1000 虛擬網絡卡低 10%),和更高的吞吐量(throughput)(8倍於普通 virtio,大概 7~8
Gigabits/sec )。
vhost-net 與 virtio-net 的比較:
vhost-net 的要求:
-
qemu-kvm-0.13.0 或者以上
-
主機內核中設定 CONFIG_VHOST_NET=y 和在虛機操作系統內核中設定 CONFIG_PCI_MSI=y (Red Hat Enterprise Linux 6.1 開始支援該特性)
-
在客戶機內使用 virtion-net 前段驅動
-
在主機內使用網橋模式,並且啓動 vhost_net
qemu-kvm 命令的 -net tap 有幾個選項和 vhost-net 相關的: -net tap,[,vnet_hdr=on|off][,vhost=on|off][,vhostfd=h][,vhostforce=on|off]
-
vnet_hdr =on|off:設定是否開啓TAP裝置的「IFF_VNET_HDR」標識。「vnet_hdr=off」表示關閉這個標識;「vnet_hdr=on」則強制開啓這個標識,如果沒有這個標識的支援,則會觸發錯誤。IFF_VNET_HDR是tun/tap的一個標識,開啓它則允許發送或接受大數據包時僅僅做部分的校驗和檢查。開啓這個標識,可以提高virtio_net驅動的吞吐量。
-
vhost=on|off:設定是否開啓vhost-net這個內核空間的後端處理驅動,它只對使用MIS-X中斷方式的virtio客戶機有效。
-
vhostforce=on|off:設定是否強制使用 vhost 作爲非MSI-X中斷方式的Virtio客戶機的後端處理程式。
-
vhostfs=h:設定爲去連線一個已經開啓的vhost網路裝置。
vhost-net 的使用範例:
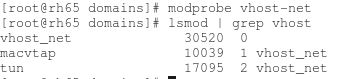
(1)確保主機上 vhost-net 內核模組被載入了
(2)啓動一個虛擬機器,在客戶機中使用 -net 定義一個 virtio-net 網絡卡,在主機端使用 -netdev 啓動 vhost

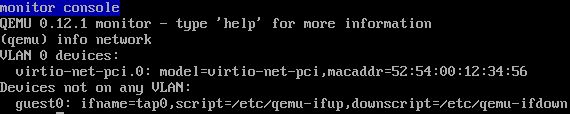
(3)在虛擬機器端,看到 virtio 網絡卡使用的 TAP 裝置爲 tap0。
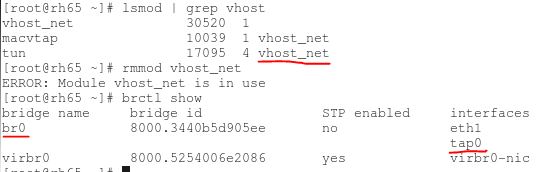
(4)在宿主機中看 vhost-net 被載入和使用了,以及 Linux 橋 br0,它連線物理網絡卡 eth1 和 客戶機使用的 TAP 裝置 tap0
一般來說,使用 vhost-net 作爲後端處理驅動可以提高網路的效能。不過,對於一些網路負載型別使用 vhost-net 作爲後端,卻可能使其效能不升反降。特別是從宿主機到其中的客戶機之間的UDP流量,如果客戶機處理接受數據的速度比宿主機發送的速度要慢,這時就容易出現效能下降。在這種情況下,使用vhost-net將會是UDP socket的接受緩衝區更快地溢位,從而導致更多的數據包丟失。故這種情況下,不使用vhost-net,讓傳輸速度稍微慢一點,反而會提高整體的效能。
使用 qemu-kvm 命令列,加上「vhost=off」(或沒有vhost選項)就會不使用vhost-net,而在使用libvirt時,需要對客戶機的設定的XML檔案中的網路設定部分進行如下的設定,指定後端驅動的名稱爲「qemu」(而不是「vhost」)。
2.6 virtio-balloon
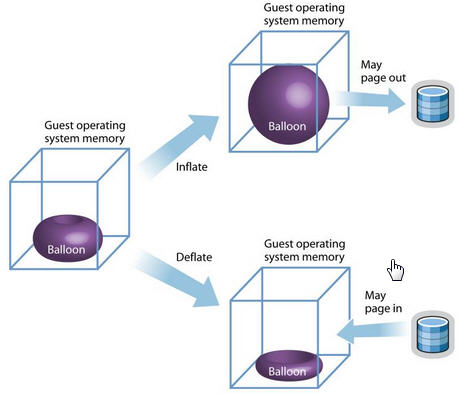
另一個比較特殊的 virtio 裝置是 virtio-balloon。通常來說,要改變客戶機所佔用的宿主機記憶體,要先關閉客戶機,修改啓動時的記憶體設定,然後重新啓動客戶機纔可以實現。而 記憶體的 ballooning (氣球)技術可以在客戶機執行時動態地調整它所佔用的宿主機記憶體資源,而不需要關閉客戶機。該技術能夠:
-
當宿主機記憶體緊張時,可以請求客戶機回收利用已分配給客戶機的部分記憶體,客戶機就會釋放部分空閒記憶體。若其記憶體空間不足,可能還會回收部分使用中的記憶體,可能會將部分記憶體換到交換分割區中。
-
當客戶機記憶體不足時,也可以讓客戶機的記憶體氣球壓縮,釋放出記憶體氣球中的部分記憶體,讓客戶機使用更多的記憶體。
目前很多的VMM,包括 KVM, Xen,VMware 等都對 ballooning 技術提供支援。其中,KVM 中的 Ballooning 是通過宿主機和客戶機協同來實現的,在宿主機中應該使用 2.6.27 及以上版本的 Linux內核(包括KVM模組),使用較新的 qemu-kvm(如0.13版本以上),在客戶機中也使用 2.6.27 及以上內核且將「CONFIG_VIRTIO_BALLOON」設定爲模組或編譯到內核。在很多Linux發行版中都已經設定有「CONFIG_VIRTIO_BALLOON=m」,所以用較新的Linux作爲客戶機系統,一般不需要額外設定virtio_balloon驅動,使用預設內核設定即可。
原理:
-
KVM 發送請求給 VM 讓其歸還一定數量的記憶體給KVM。
-
VM 的 virtio_balloon 驅動接到該請求。
-
VM 的驅動是客戶機的記憶體氣球膨脹,氣球中的記憶體就不能被客戶機使用。
-
VM 的操作系統歸還氣球中的記憶體給VMM
-
KVM 可以將得到的記憶體分配到任何需要的地方。
-
KM 也可以將記憶體返還到客戶機中。
優勢和不足:
|
優勢 |
不足 |
-
ballooning 可以被控制和監控
-
對記憶體的調節很靈活,可多可少。
-
KVM 可以歸還記憶體給客戶機,從而緩解其記憶體壓力。
|
-
需要客戶機安裝驅動
-
大量記憶體被回收時,會降低客戶機的效能。
-
目前沒有方便的自動化的機制 機製來管理 ballooning,一般都在 QEMU 的 monitor 中執行命令來實現。
-
記憶體的動態增加或者減少,可能是記憶體被過度碎片化,從而降低記憶體使用效能。
|
在QEMU monitor中,提供了兩個命令檢視和設定客戶機記憶體的大小。
-
(qemu) info balloon #檢視客戶機記憶體佔用量(Balloon資訊)
-
(qemu) balloon num #設定客戶機記憶體佔用量爲numMB
使用範例:
(1)啓動一個虛機,記憶體爲 2048M,啓用 virtio-balloon

(2)通過 vncviewer 進入虛機,檢視 pci 裝置
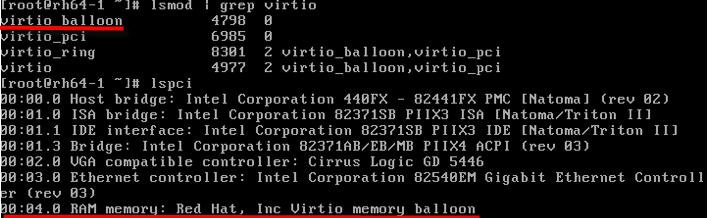
(3)看看記憶體情況,共 2G 記憶體

(4)進入 QEMU Monitor,調整 balloon 記憶體爲 500M

(5)回到虛機,檢視記憶體,變爲 500 M

2.7 RedHat 的 多佇列 Virtio (multi-queue)
目前的高階伺服器都有多個處理器,虛擬使用的虛擬CPU數目也不斷增加。預設的 virtio-net 不能並行地傳送或者接收網路包,因爲 virtio_net 只有一個TX 和 RX 佇列。而多佇列 virtio-net 提供了一個隨着虛機的虛擬CPU增加而增強網路效能的方法,通過使得 virtio 可以同時使用多個 virt-queue
佇列。
它在以下情況下具有明顯優勢:
-
網路流量非常大
-
虛機同時有非常多的網路連線,包括虛擬機器之間的、虛機到主機的、虛機到外部系統的等
-
virtio 佇列的數目和虛機的虛擬CPU數目相同。這是因爲多佇列能夠使得一個佇列獨佔一個虛擬CPU。
注意:對佇列 virtio-net 對流入的網路流工作得非常好,但是對外發的數據流偶爾會降低效能。開啓對佇列 virtio 會增加中的吞吐量,這相應地會增加CPU的負擔。 在實際的生產環境中需要做必須的測試後才確定是否使用。
在 RedHat 中,要使用多佇列 virtio-net,在虛機的 XML 檔案中增加如下設定:
然後在主機上執行下面 下麪的命令:
ethtool -L eth0 combined M ( 1 <= M <= N)
2.8 Windows 客戶機的 virtio 前端驅動
Windows 客戶機下的 virtio 前端驅動必須下載後手工安裝。 RedHat Linux
這篇文章 說明了在
Windows 客戶機內安裝virtio 驅動的方法。
參考文件:
.png)
.png)
.png)
.png)
.png)


.png)




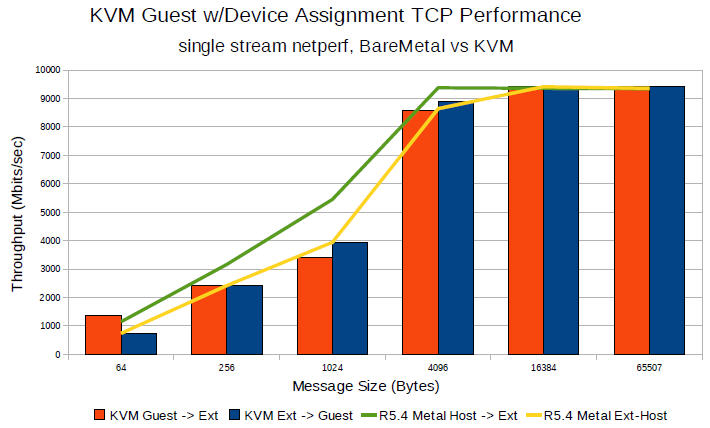
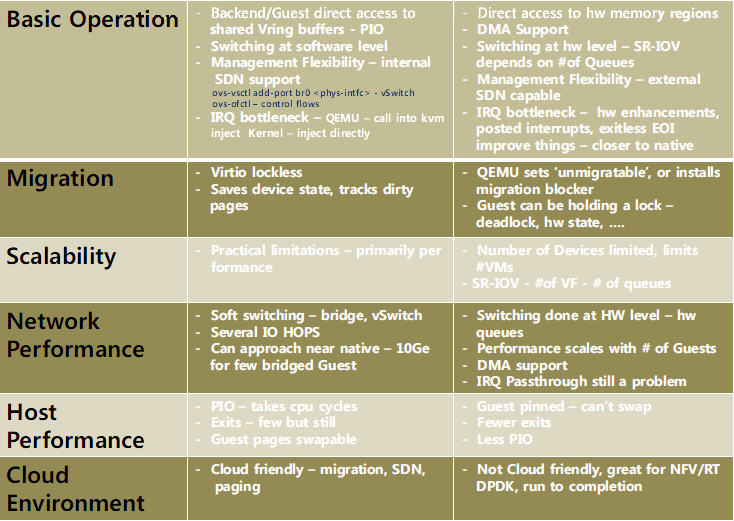
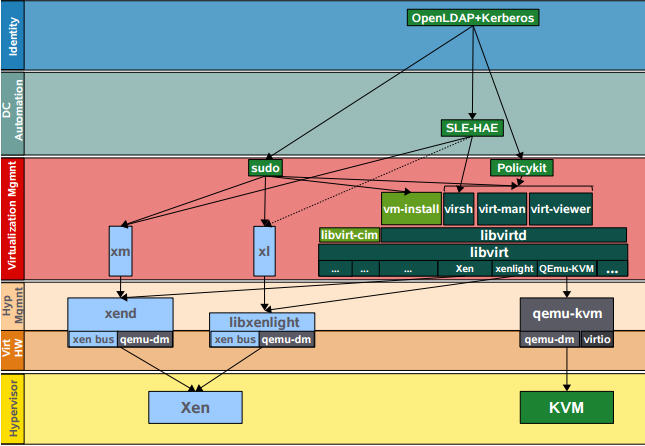 (SLE
11)
(SLE
11)