ClickHouse技術實踐V1.0
1 CLICKHOUSE簡述
ClickHouse是一個用於聯機分析(OLAP)的列式數據庫管理系統(DBMS)。能夠使用SQL查詢實時生成分析數據報告。
1.1 CLICKHOUSE架構組成介紹
ClickHouse數據始終是按列儲存的,包括向量(向量或列塊)執行的過程。ClickHouse的內部架構包括列(column)、欄位、抽象漏洞、塊(block)、塊流(block stream)、格式(format)、I/O、表(tables)、解析器、函數(Function)、服務(server)、合併樹等。
詳見:https://clickhouse.tech/docs/zh/development/architecture/
1.2 CLICKHOUSE的特點
ClickHouse的主要特點
1.真正的面向列的DBMS
在一個真正的面向列的DBMS中,沒有任何「垃圾」儲存在值中。例如,必須支援定長數值,以避免在數值旁邊儲存長度「數位」。例如,十億個UInt8型別的值實際上應該消耗大約1 GB的未壓縮磁碟空間,否則這將強烈影響CPU的使用。由於解壓縮的速度(CPU使用率)主要取決於未壓縮的數據量,所以即使在未壓縮的情況下,緊湊地儲存數據(沒有任何「垃圾」)也是非常重要的。
因爲有些系統可以單獨儲存單獨列的值,但由於其他場景的優化,無法有效處理分析查詢。例如HBase,BigTable,Cassandra和HyperTable。在這些系統中,每秒鐘可以獲得大約十萬行的吞吐量,但是每秒不會達到數億行。
另外,ClickHouse是一個DBMS,而不是一個單一的數據庫。ClickHouse允許在執行時建立表和數據庫,載入數據和執行查詢,而無需重新設定和重新啓動伺服器。
2.數據壓縮
一些面向列的DBMS(InfiniDB CE和MonetDB)不使用數據壓縮。但是,數據壓縮確實提高了效能。
3.磁碟儲存的數據
許多面向列的DBMS(SAP HANA和GooglePowerDrill)只能在記憶體中工作。但即使在數千台伺服器上,記憶體也太小,無法在Yandex.Metrica中儲存所有瀏覽量和對談。
4.多核並行處理
多核多節點並行化大型查詢。
5.在多個伺服器上分佈式處理
上面列出的列式DBMS幾乎都不支援分佈式處理。在ClickHouse中,數據可以駐留在不同的分片上。每個分片可以是用於容錯的一組副本。查詢在所有分片上並行處理。這對使用者來說是透明的。
6.SQL支援
如果你熟悉標準的SQL,我們不能真正談論SQL的支援。NULL不支援。所有的函數都有不同的名字。JOIN支援。子查詢在FROM,IN,JOIN子句中被支援;標量子查詢支援。關聯子查詢不支援。
7.向量化引擎
數據不僅按列儲存,而且由向量 - 列的部分進行處理。這使我們能夠實現高CPU效能。
8.實時數據更新
ClickHouse支援主鍵表。爲了快速執行對主鍵範圍的查詢,數據使用合併樹(MergeTree)進行遞增排序。由於這個原因,數據可以不斷地新增到表中。新增數據時無鎖處理。
9.索引
例如,帶有主鍵可以在特定的時間範圍內爲特定用戶端(Metrica計數器)抽取數據,並且延遲時間小於幾十毫秒。
10.支援線上查詢
這讓我們使用該系統作爲Web介面的後端。低延遲意味着可以無延遲實時地處理查詢,而Yandex.Metrica介面頁面正在載入(線上模式)。
11.支援近似計算
a.系統包含用於近似計算各種值,中位數和分位數的集合函數。
b.支援基於部分(樣本)數據執行查詢並獲得近似結果。在這種情況下,從磁碟檢索比例較少的數據。
c.支援爲有限數量的隨機金鑰(而不是所有金鑰)執行聚合。在數據中金鑰分發的特定條件下,這提供了相對準確的結果,同時使用較少的資源。
12.數據複製和對數據完整性的支援。
使用非同步多主複製。寫入任何可用的副本後,數據將分發到所有剩餘的副本。系統在不同的副本上保持相同的數據。數據在失敗後自動恢復
1.3 CLICKHOUSE的缺陷
1.不支援事物。
2.不支援Update/Delete操作。
3.支援有限操作系統。(Linux需要編譯,不支援Windows)
1.4 CLICKHOUSE應用場景
1.電信行業用於儲存數據和統計數據使用。
2.新浪微博用於使用者行爲數據記錄和分析工作。
3.用於廣告網路和RTB,電子商務的使用者行爲分析。
4.資訊保安裏面的日誌分析。
5.檢測和遙感資訊的挖掘。
6.商業智慧。
7.網絡遊戲以及物聯網的數據處理和價值數據分析。
8.最大的應用來自於Yandex的統計分析服務Yandex.Metrica,類似於谷歌Analytics(GA),或友盟統計,小米統計,幫助網站或移動應用進行數據分析和精細化運營工具,據稱Yandex.Metrica爲世界上第二大的網站分析平臺。ClickHouse在這個應用中,部署了近四百臺機器,每天支援200億的事件和歷史總記錄超過13萬億條記錄,這些記錄都存有原始數據(非聚合數據),隨時可以使用SQL查詢和分析,生成使用者報告
1.5 CLICKHOUSE與一些技術的比較
1.商業OLAP數據庫
例如:HP Vertica, Actian the Vector,
區別:ClickHouse是開源而且免費的
2.雲解決方案
例如:亞馬遜RedShift和谷歌的BigQuery
區別:ClickHouse可以使用自己機器部署,無需爲雲付費
3.Hadoop生態軟體
例如:Cloudera Impala, Spark SQL, Facebook Presto , Apache Drill
區別:
ClickHouse支援實時的高併發系統
ClickHouse不依賴於Hadoop生態軟體和基礎
ClickHouse支援分佈式機房的部署
4.開源OLAP數據庫
例如:InfiniDB, MonetDB, LucidDB
區別:這些專案的應用的規模較小,並沒有應用在大型的網際網路服務當中,相比之下,ClickHouse的成熟度和穩定性遠遠超過這些軟體。
5.開源分析,非關係型數據庫
例如:Druid , Apache Kylin
區別:ClickHouse可以支援從原始數據的直接查詢,ClickHouse支援類SQL語言,提供了傳統關係型數據的便利
1.6 CLICKHOUSE各個埠
| 埠名稱 | 預設埠 | 說明 |
|---|---|---|
| zookeeper | 2181 | zookeeper節點埠 |
| clickhouse.http_port | 8123 | clickhouse的web端 |
| clickhouse.tcp_port | 9000 | clickhouse的通訊埠 |
1.7 中介軟體版本選取
| 中介軟體名稱 | 版本號 |
|---|---|
| CentOS | CentOS 6.8 |
| Java | 1.8.0_121 |
| zookeeper | 3.4.10 |
| ClickHouse | 19.7.3.9-1 |
2 CLICKHOUSE部署
2.1 環境準備
本次技術實踐安裝ClickHouse叢集,安裝在3台虛擬機器上:hadoop102、hadoop103、hadoop104
由於ClickHouse在Linux(CentOS或者Ubantu)需要編譯,這裏我直接下載rpm包進行安裝部署
2.1.1 CentOS6.8
CentOS6.8安過程省略。預先建立使用者/使用者組zhouchen
預先安裝jdk1.8.0_92 +
預先安裝zookeeper
2.1.2 關閉防火牆-root
針對CentOS7以下
1.檢視防火牆狀態
service iptables status
2.停止防火牆
service iptables stop
3.啓動防火牆
service iptables start
2.2 叢集安裝
2.2.1 rpm安裝
先將rpm安裝包上傳到/opt/software,然後以root許可權執行安裝命令:
[zhouchen@hadoop102 software]$ sudo rpm -ivh clickhouse-server-common-19.7.3.9-1.el6.x86_64.rpm
[zhouchen@hadoop102 software]$ sudo rpm -ivh clickhouse-common-static-19.7.3.9-1.el6.x86_64.rpm
[zhouchen@hadoop102 software]$ sudo rpm -ivh clickhouse-server-19.7.3.9-1.el6.x86_64.rpm
[zhouchen@hadoop102 software]$ sudo rpm -ivh clickhouse-debuginfo-19.7.3.9-1.el6.x86_64.rpm
[zhouchen@hadoop102 software]$ sudo rpm -ivh clickhouse-test-19.7.3.9-1.el6.x86_64.rpm
[zhouchen@hadoop102 software]$ sudo rpm -ivh clickhouse-client-19.7.3.9-1.el6.x86_64.rpm
2.2.2 叢集設定
*三臺機器都需要修改如下設定:
1.修改clickhouse組態檔config.xml
[zhouchen@hadoop102 software]$ sudo vim /etc/clickhouse-server/config.xml
#修改的內容如下:
<listen_host>::</listen_host>
<!-- Path to data directory, with trailing slash. -->
<path>/var/lib/clickhouse/</path>
<!-- Path to temporary data for processing hard queries. -->
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
2.在/etc下建立metrika.xml檔案
[zhouchen@hadoop102 software]$ sudo vim /etc/metrika.xml
#新增如下內容:
<yandex>
<clickhouse_remote_servers>
<perftest_3shards_1replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>hadoop102</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>hadoop103</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
</perftest_3shards_1replicas>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
#填寫本機IP hadoop102/hadoop103/hadoop104
<macros>
<replica>hadoop102</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
2.2.3 叢集啓動
首先在三臺機器開啓Zookeeper
前臺啓動:
[zhouchen@hadoop102 software]# sudo clickhouse-server --config-file=/etc/clickhouse-server/config.xml
後臺啓動:
[zhouchen@hadoop102 software]# sudo nohup clickhouse-server --config-file=/etc/clickhouse-server/config.xml >null 2>&1 &
[1] 2696
2.2.4 安裝檢查
1.介面存取
http://Hadoop102:8123/
2.啓動日誌

3.檢視服務狀態

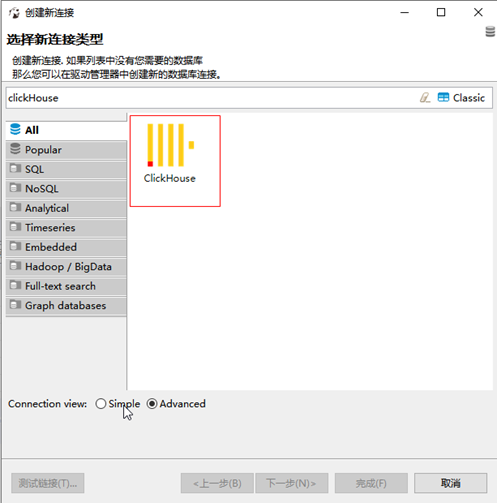
2.3 設定DBEAVER連線CLICKHOUSE
由於ClickHouse支援Sql協定,使用DBeaver操作ClickHouse會更加便捷。
1.點選建立連線
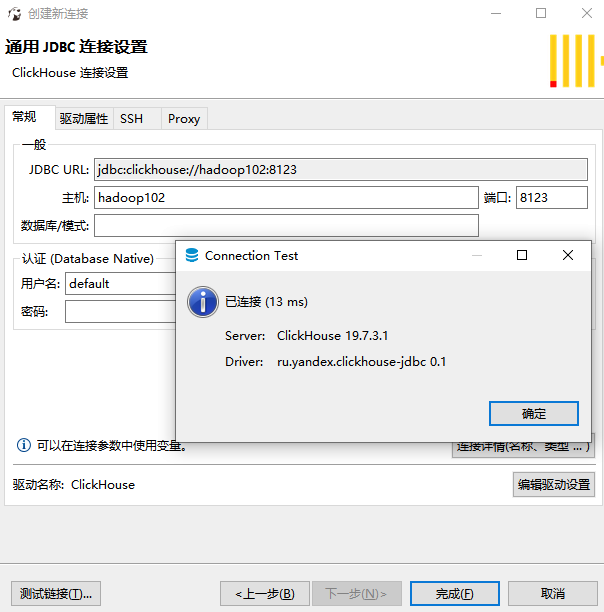
2.填寫連線資訊測試連線
點選測試連線,會下載驅動包
3.點選完成,建立成功
3 CLICKHOUSE的數據型別
ClickHouse的數據型別包含基本的整型、浮點型、布爾型,還包括一些其他的型別。
3.1 列舉型別
包括 Enum8 和 Enum16 型別。Enum 儲存 ‘string’= integer 的對應關係。
Enum8 用 ‘String’= Int8 對描述。
Enum16 用 ‘String’= Int16 對描述。
用法演示:
建立一個帶有一個列舉 Enum8(‘hello’ = 1, ‘world’ = 2) 型別的列:
:) CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog
這個 x 列只能儲存型別定義中列出的值:‘hello’或’world’。如果嘗試儲存任何其他值,ClickHouse 拋出異常。
:) INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello')
INSERT INTO t_enum VALUES
Ok.
3 rows in set. Elapsed: 0.002 sec.
:) insert into t_enum values('a')
INSERT INTO t_enum VALUES
Exception on client:
Code: 49. DB::Exception: Unknown element 'a' for type Enum8('hello' = 1, 'world' = 2)
從表中查詢數據時,ClickHouse 從 Enum 中輸出字串值。
SELECT * FROM t_enum
┌─x─────┐
│ hello │
│ world │
│ hello │
└───────┘
如果需要看到對應行的數值,則必須將 Enum 值轉換爲整數型別。
SELECT CAST(x, 'Int8') FROM t_enum
┌─CAST(x, 'Int8')─┐
│ 1 │
│ 2 │
│ 1 │
└─────────────────┘
3.2 陣列
Array(T):由 T 型別元素組成的陣列。
T 可以是任意型別,包含陣列型別。 但不推薦使用多維陣列,ClickHouse 對多維陣列的支援有限。例如,不能在 MergeTree 表中儲存多維陣列。
可以使用array函數來建立陣列:
array(T)
也可以使用方括號:
[]
建立陣列案例:
:) SELECT array(1, 2) AS x, toTypeName(x)
SELECT
[1, 2] AS x,
toTypeName(x)
┌─x─────┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└───────┴─────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
:) SELECT [1, 2] AS x, toTypeName(x)
SELECT
[1, 2] AS x,
toTypeName(x)
┌─x─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
3.3 元組
Tuple(T1, T2, …):元組,其中每個元素都有單獨的型別。
建立元組的範例:
:) SELECT tuple(1,'a') AS x, toTypeName(x)
SELECT
(1, 'a') AS x,
toTypeName(x)
┌─x───────┬─toTypeName(tuple(1, 'a'))─┐
│ (1,'a') │ Tuple(UInt8, String) │
└─────────┴───────────────────────────┘
1 rows in set. Elapsed: 0.021 sec.
3.4 DATE
日期型別,用兩個位元組儲存,表示從 1970-01-01 (無符號) 到當前的日期值。
還有很多數據結構,可以參考官方文件:https://clickhouse.tech/docs/zh/sql-reference/data-types/
4 CLICKHOUSE的表引擎
表引擎(即表的型別)決定了:
1)數據的儲存方式和位置,寫到哪裏以及從哪裏讀取數據
2)支援哪些查詢以及如何支援。
3)併發數據存取。
4)索引的使用(如果存在)。
5)是否可以執行多執行緒請求。
6)數據複製參數。
ClickHouse的表引擎有很多,下面 下麪介紹其中幾種,對其他引擎有興趣的可以去查閱官方文件:https://clickhouse.tech/docs/zh/engines/table-engines/
4.1 TINYLOG
最簡單的表引擎,用於將數據儲存在磁碟上。每列都儲存在單獨的壓縮檔案中,寫入時,數據將附加到檔案末尾。
該引擎沒有併發控制
- 如果同時從表中讀取和寫入數據,則讀取操作將拋出異常;
- 如果同時寫入多個查詢中的表,則數據將被破壞。
這種表引擎的典型用法是 write-once:首先只寫入一次數據,然後根據需要多次讀取。此引擎適用於相對較小的表(建議最多1,000,000行)。如果有許多小表,則使用此表引擎是適合的,因爲它比需要開啓的檔案更少。當擁有大量小表時,可能會導致效能低下。
不支援索引。
案例:建立一個TinyLog引擎的表並插入一條數據
:)create table t (a UInt16, b String) ENGINE=TinyLog;
:)insert into t (a, b) values (1, 'abc');
此時我們到儲存數據的目錄/var/lib/clickhouse/data/default/t中可以看到如下目錄結構:
[root@hadoop102 t]# ls
a.bin b.bin sizes.json
a.bin 和 b.bin 是壓縮過的對應的列的數據, sizes.json 中記錄了每個 *.bin 檔案的大小:
[root@hadoop102 t]# cat sizes.json
{"yandex":{"a%2Ebin":{"size":"28"},"b%2Ebin":{"size":"30"}}}
4.2 MEMORY
記憶體引擎,數據以未壓縮的原始形式直接儲存在記憶體當中,伺服器重新啓動數據就會消失。讀寫操作不會相互阻塞,不支援索引。簡單查詢下有非常非常高的效能表現(超過10G/s)。
一般用到它的地方不多,除了用來測試,就是在需要非常高的效能,同時數據量又不太大(上限大概 1 億行)的場景。
4.3 MERGE
Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不儲存數據,但可用於同時從任意多個其他的表中讀取數據。 讀是自動並行的,不支援寫入。讀取時,那些被真正讀取到數據的表的索引(如果有的話)會被使用。
Merge 引擎的參數:一個數據庫名和一個用於匹配表名的正則表達式。
案例:先建t1,t2,t3三個表,然後用 Merge 引擎的 t 表再把它們鏈接起來。
:)create table t1 (id UInt16, name String) ENGINE=TinyLog;
:)create table t2 (id UInt16, name String) ENGINE=TinyLog;
:)create table t3 (id UInt16, name String) ENGINE=TinyLog;
:)insert into t1(id, name) values (1, 'first');
:)insert into t2(id, name) values (2, 'second');
:)insert into t3(id, name) values (3, 'i am in t3');
:)create table t (id UInt16, name String) ENGINE=Merge(currentDatabase(), '^t');
:) select * from t;
┌─id─┬─name─┐
│ 2 │ second │
└────┴──────┘
┌─id─┬─name──┐
│ 1 │ first │
└────┴───────┘
┌─id─┬─name───────┐
│ 3 │ i am in t3 │
└────┴────────────┘
4.4 MERGETREE
Clickhouse 中最強大的表引擎當屬 MergeTree (合併樹)引擎及該系列(*MergeTree)中的其他引擎。
MergeTree 引擎系列的基本理念如下。當你有巨量數據要插入到表中,你要高效地一批批寫入數據片段,並希望這些數據片段在後台按照一定規則合併。相比在插入時不斷修改(重寫)數據進儲存,這種策略會高效很多。
格式:
ENGINE [=] MergeTree(date-column [, sampling_expression], (primary, key), index_granularity)
參數解讀:
date-column — 型別爲 Date 的列名。ClickHouse 會自動依據這個列按月建立分割區。分割區名格式爲 「YYYYMM」 。
sampling_expression — 採樣表達式。
(primary, key) — 主鍵。型別爲Tuple()
index_granularity — 索引粒度。即索引中相鄰」標記」間的數據行數。設爲 8192 可以適用大部分場景。
案例:
create table mt_table (date Date, id UInt8, name String) ENGINE=MergeTree(date, (id, name), 8192);
insert into mt_table values ('2020-05-01', 1, 'zhangsan');
insert into mt_table values ('2020-06-01', 2, 'lisi');
insert into mt_table values ('2020-05-03', 3, 'wangwu');
在/var/lib/clickhouse/data/ch_test/mt_table下可以看到:
[root@hadoop102 mt_table]# ls
20200501_20200501_2_2_0 20200503_20200503_6_6_0 20200601_20200601_4_4_0 detached
隨便進入一個目錄:
[root@hadoop102 20200601_20200601_2_2_0]# ls
checksums.txt columns.txt date.bin date.mrk id.bin id.mrk name.bin name.mrk primary.idx
- *.bin是按列儲存數據的檔案
- *.mrk儲存塊偏移量
- primary.idx儲存主鍵索引
4.5 REPLACING MERGE TREE
這個引擎是在 MergeTree 的基礎上,新增了「處理重複數據」的功能,該引擎和MergeTree的不同之處在於它會刪除具有相同主鍵的重複項。數據的去重只會在合併的過程中出現。合併會在未知的時間在後台進行,所以你無法預先作出計劃。有一些數據可能仍未被處理。因此,ReplacingMergeTree 適用於在後台清除重複的數據以節省空間,但是它不保證沒有重複的數據出現。
格式:
ENGINE [=] ReplacingMergeTree(date-column [, sampling_expression], (primary, key), index_granularity, [ver])
可以看出他比MergeTree只多了一個ver,這個ver指代版本列。
案例:
create table rmt_table (date Date, id UInt8, name String,point UInt8) ENGINE= ReplacingMergeTree(date, (id, name), 8192,point);
插入一些數據:
insert into rmt_table values ('2020-06-10', 1, 'a', 20);
insert into rmt_table values ('2020-06-10', 1, 'a', 30);
insert into rmt_table values ('2020-06-11', 1, 'a', 20);
insert into rmt_table values ('2020-06-11', 1, 'a', 30);
insert into rmt_table values ('2020-06-11', 1, 'a', 10);
等待一段時間或optimize table rmt_table手動觸發merge,後查詢
:) select * from rmt_table;
┌───────date─┬─id─┬─name─┬─point─┐
│ 2020-06-11 │ 1 │ a │ 30 │
└────────────┴────┴──────┴───────┘
4.6 SUMMING MERGE TREE
該引擎繼承自 MergeTree。區別在於,當合並 SummingMergeTree 表的數據片段時,ClickHouse 會把所有具有相同主鍵的行合併爲一行,該行包含了被合併的行中具有數值數據型別的列的彙總值。如果主鍵的組合方式使得單個鍵值對應於大量的行,則可以顯著的減少儲存空間並加快數據查詢的速度,對於不可加的列,會取一個最先出現的值。
語法:
ENGINE [=] SummingMergeTree(date-column [, sampling_expression], (primary, key), index_granularity, [columns])
columns — 包含將要被彙總的列的列名的元組
案例:
create table smt_table (date Date, name String, a UInt16, b UInt16) ENGINE=SummingMergeTree(date, (date, name), 8192, (a))
插入數據:
insert into smt_table (date, name, a, b) values ('2020-06-10', 'a', 1, 2);
insert into smt_table (date, name, a, b) values ('2020-06-10', 'b', 2, 1);
insert into smt_table (date, name, a, b) values ('2020-06-11', 'b', 3, 8);
insert into smt_table (date, name, a, b) values ('2020-06-11', 'b', 3, 8);
insert into smt_table (date, name, a, b) values ('2020-06-11', 'a', 3, 1);
insert into smt_table (date, name, a, b) values ('2020-06-12', 'c', 1, 3);
等待一段時間或optimize table smt_table手動觸發merge,後查詢
:) select * from smt_table
┌───────date─┬─name─┬─a─┬─b─┐
│ 2020-06-10 │ a │ 1 │ 2 │
│ 2020-06-10 │ b │ 2 │ 1 │
│ 2020-06-11 │ a │ 3 │ 1 │
│ 2020-06-11 │ b │ 6 │ 8 │
│ 2020-06-12 │ c │ 1 │ 3 │
└────────────┴──────┴───┴───┘
發現2020-06-11,b的a列合併相加了,b列取了8(因爲b列爲8的數據最先插入)。
4.7 DISTRIBUTED
分佈式引擎,本身不儲存數據, 但可以在多個伺服器上進行分佈式查詢。 讀是自動並行的。讀取時,遠端伺服器表的索引(如果有的話)會被使用。
Distributed(cluster_name, database, table [, sharding_key])
參數解析:
cluster_name - 伺服器組態檔中的叢集名,在/etc/metrika.xml中設定的
database – 數據庫名
table – 表名
sharding_key – 數據分片鍵
案例演示:
1)在hadoop102,hadoop103,hadoop104上分別建立一個表t
:)create table t(id UInt16, name String) ENGINE=TinyLog;
2)在三臺機器的t表中插入一些數據
:)insert into t(id, name) values (1, 'zhangsan');
:)insert into t(id, name) values (2, 'lisi');
3)在hadoop102上建立分佈式表
:)create table dis_table(id UInt16, name String) ENGINE=Distributed(perftest_3shards_1replicas, default, t, id);
4)往dis_table中插入數據
:) insert into dis_table select * from t
5)檢視數據量
:) select count() from dis_table
FROM dis_table
┌─count()─┐
│ 8 │
└─────────┘
:) select count() from t
SELECT count()
FROM t
┌─count()─┐
│ 3 │
└─────────┘
可以看到每個節點大約有1/3的數據
5 CLICKHOUSE使用者
ClickHouse的使用者設定包括使用者和密碼,密碼有兩種,一種是明文,一種是寫sha256sum的Hash值。ClickHouse預設提供了有個default使用者,擁有所有許可權。與Mysql不同的是,mysql的使用者在user表中,而clickhouse的使用者在/etc/clickhouse-server/user.xml組態檔中。
生成密文密碼的方式:
[zhouchen@hadoop103 etc]$ PASSWORD=chpw123; echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-'
chpw123
329942425a7e924264fce9d3aa0bd1eb47cc3446a5453b35c066f1bf089a984f
/etc/clickhouse-server/user.xml
<?xml version="1.0"?>
<yandex>
<!-- Profiles of settings. 一個Profile就是一堆設定(settings)的集合-->
<profiles>
<!-- default組是必須的 -->
<default>
<!-- 副本之間負載均衡的設定,可選項有random,nearest_hostname,in_order,first_or_random -->
<load_balancing>nearest_hostname</load_balancing>
</default>
<!-- readonly組 -->
<readonly>
<readonly>1</readonly>
</readonly>
</profiles>
<!-- Users and ACL. -->
<users>
<!-- If user name was not specified, 'default' user is used. -->
<default>
<!-- Password could be specified in plaintext or in SHA256 (in hex format).
If you want to specify password in plaintext (not recommended), place it in 'password' element.
Example: <password>qwerty</password>.
Password could be empty.
If you want to specify SHA256, place it in 'password_sha256_hex' element.
Example: <password_sha256_hex>65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5</password_sha256_hex>
Restrictions of SHA256: impossibility to connect to ClickHouse using MySQL JS client (as of July 2019).
If you want to specify double SHA1, place it in 'password_double_sha1_hex' element.
Example: <password_double_sha1_hex>e395796d6546b1b65db9d665cd43f0e858dd4303</password_double_sha1_hex>
How to generate decent password:
Execute: PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-'
In first line will be password and in second - corresponding SHA256.
How to generate double SHA1:
Execute: PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | openssl dgst -sha1 -binary | openssl dgst -sha1
In first line will be password and in second - corresponding double SHA1.-->
<!-- 這裏採用sha256加密,密碼是這樣生成的:PASSWORD=000000; echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-' -->
<password_sha256_hex>91b4d142823f7d20c5f08df69122de43f35f057a988d9619f6d3138485c9a203</password_sha256_hex>
<!-- List of networks with open access.
To open access from everywhere, specify:
<ip>::/0</ip>
To open access only from localhost, specify:
<ip>::1</ip>
<ip>127.0.0.1</ip>
Each element of list has one of the following forms:
<ip> IP-address or network mask. Examples: 213.180.204.3 or 10.0.0.1/8 or 10.0.0.1/255.255.255.0
2a02:6b8::3 or 2a02:6b8::3/64 or 2a02:6b8::3/ffff:ffff:ffff:ffff::.
<host> Hostname. Example: server01.yandex.ru.
To check access, DNS query is performed, and all received addresses compared to peer address.
<host_regexp> Regular expression for host names. Example, ^server\d\d-\d\d-\d\.yandex\.ru$
To check access, DNS PTR query is performed for peer address and then regexp is applied.
Then, for result of PTR query, another DNS query is performed and all received addresses compared to peer address.
Strongly recommended that regexp is ends with $
All results of DNS requests are cached till server restart.-->
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<!-- Settings profile for user. -->
<profile>default</profile>
<!-- Quota for user. -->
<quota>default</quota>
<!-- For testing the table filters -->
<databases>
<test>
<!-- Simple expression filter -->
<filtered_table1>
<filter>a = 1</filter>
</filtered_table1>
<!-- Complex expression filter -->
<filtered_table2>
<filter>a + b < 1 or c - d > 5</filter>
</filtered_table2>
<!-- Filter with ALIAS column -->
<filtered_table3>
<filter>c = 1</filter>
</filtered_table3>
</test>
</databases>
</default>
<!-- Example of user with readonly access. -->
<readonly>
<password></password>
<networks incl="networks" replace="replace">
<ip>::1</ip>
<ip>127.0.0.1</ip>
</networks>
<profile>readonly</profile>
<quota>default</quota>
</readonly>
</users>
<!-- Quotas. -->
<quotas>
<!-- Name of quota. -->
<default>
<!-- Limits for time interval. You could specify many intervals with different limits. -->
<interval>
<!-- Length of interval. -->
<duration>3600</duration>
<!-- No limits. Just calculate resource usage for time interval. -->
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
</yandex>
在節點下新增新使用者資訊的節點:
<tset_user>
<password_sha256_hex>91b4d142823f7d20c5f08df69122de43f35f057a988d9619f6d3138485c9a203</password_sha256_hex>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
<allow_databases>
<database>test</database>
</allow_databases>
</tset_user>
6 CLICKHOUSE數據匯入導出
ClickHouse支援檔案格式的數據匯入
6.1 CLICKHOUSE數據匯入
匯入數據庫的本機執行:cat table_name.sql | clickhouse-client --query=「INSERT INTO database.table_name FORMAT TabSeparated」
6.2 CLICKHOUSE數據導出
遠端導出命令,預設分割符是tab:
echo ‘select * from table_name’ | curl ip:8123?database=mybi -uroot:password -d @- > table_name.sql
7 CLICKHOUSE常見問題分析
7.1 缺少依賴包
報錯:
[zhouchen@hadoop102 software]$ sudo rpm -ivh clickhouse-common-static-19.7.3.9-1.el6.x86_64.rpm
錯誤:依賴檢測失敗:
libicudata.so.42()(64bit) 被 clickhouse-common-static-19.7.3.9-1.el6.x86_64 需要
libicui18n.so.42()(64bit) 被 clickhouse-common-static-19.7.3.9-1.el6.x86_64需要
libicuuc.so.42()(64bit) 被 clickhouse-common-static-19.7.3.9-1.el6.x86_64 需要
錯誤原因是缺少依賴,安裝依賴包就可以了:
[zhouchen@hadoop102 software]$ sudo yum install -y libtool
[zhouchen@hadoop102 software]$ sudo yum install -y *unixODBC*
[zhouchen@hadoop102 software]$ sudo yum install perl-JSON-XS -y