【轉載】分佈式分庫分表後,ID主鍵如何處理?
面試題
分庫分表之後,id 主鍵如何處理?(唯一性,排序等)
面試官心理分析
其實這是分庫分表之後你必然要面對的一個問題,就是 ID 咋生成?
ID是數據的唯一標識,傳統的做法是利用UUID和數據庫的自增ID,在網際網路企業中,大部分公司使用的都是Mysql,並且因爲需要事務支援,所以通常會使用Innodb儲存引擎,UUID太長以及無序,所以並不適合在Innodb中來作爲主鍵,自增ID比較合適,但是隨着公司的業務發展,數據量將越來越大,需要對數據進行分表,而分表後,每個表中的數據都會按自己的節奏進行自增,很有可能出現ID衝突。這時就需要一個單獨的機制 機製來負責生成唯一ID,生成出來的ID也可以叫做分佈式ID,或全域性ID。下面 下麪來分析各個生成分佈式ID的機制 機製。
基於數據庫的實現方案
數據庫自增ID
這個就是說你的系統裡每次得到一個 id,都是往一個庫的一個表裏插入一條沒什麼業務含義的數據,然後獲取一個數據庫自增的一個 id。拿到這個 id 之後再往對應的分庫分表裏去寫入。
這個方案的好處就是方便簡單,誰都會用;缺點就是單庫生成自增 id,要是高併發的話,就會有瓶頸的。如果你硬是要改進一下,那麼就專門開一個服務出來,這個服務每次就拿到當前 id 最大值,然後自己遞增幾個 id,一次性返回一批 id,然後再把當前最大 id 值修改成遞增幾個id之後的一個值,但是無論如何都是基於單個數據庫。
適合的場景:你分庫分表就倆原因,要不就是單庫併發太高,要不就是單庫數據量太大;除非是你併發不高,但是數據量太大導致的分庫分表擴容,你可以用這個方案,因爲可能每秒最高併發最多就幾百,那麼就走單獨的一個庫和表生成自增主鍵即可。
設定數據庫 sequence 或者表自增欄位步長
可以通過設定數據庫 sequence 或者表的自增欄位步長來進行水平伸縮。
比如說,現在有 8 個服務節點,每個服務節點使用一個 sequence 功能來產生 ID,每個 sequence 的起始 ID 不同,並且依次遞增,步長都是 8。
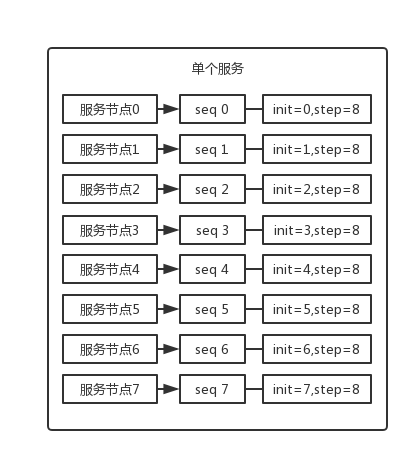
適合的場景:在使用者防止產生的 ID 重複時,這種方案實現起來比較簡單,也能達到效能目標。但是服務節點固定,步長也固定,將來如果還要增加服務節點,就不好搞了。
UUID
好處就是本地生成,不要基於數據庫來了。不好之處就是,UUID 太長了、佔用空間大,作爲主鍵效能太差了。更重要的是,UUID 不具有有序性,會導致 B+ 樹索引在寫的時候有過多的隨機寫操作(連續的 ID 可以產生部分順序寫),還有,由於在寫的時候不能產生有順序的 append 操作,而需要進行 insert 操作,將會讀取整個 B+ 樹節點到記憶體,在插入這條記錄後會將整個節點寫回磁碟,這種操作在記錄佔用空間比較大的情況下,效能下降明顯。
適合的場景:如果你是要隨機生成個什麼檔名、編號之類的,你可以用 UUID,但是作爲主鍵是不能用 UUID 的。
UUID.randomUUID().toString().replace(「-」, 「」) -> sfsdf23423rr234sfdaf
獲取系統當前時間
這個就是獲取當前時間即可,但是問題是,併發很高的時候,比如一秒併發幾千,會有重複的情況,這個是肯定不合適的。基本就不用考慮了。
適合的場景:一般如果用這個方案,是將當前時間跟很多其他的業務欄位拼接起來,作爲一個 id,如果業務上你覺得可以接受,那麼也是可以的。你可以將別的業務欄位值跟當前時間拼接起來,組成一個全域性唯一的編號。
snowflake (雪花)演算法
snowflake 演算法是 twitter 開源的分佈式 id 生成演算法,採用 Scala 語言實現,是把一個 64 位的 long 型的 id,1 個 bit 是不用的 + 用其中的 41 bit 作爲毫秒數 + 用 10 bit 作爲工作機器 id + 12 bit 作爲序列號。
1 bit:不用,爲啥呢?因爲二進制裡第一個 bit 位如果是 1,那麼都是負數,但是我們生成的 id 都是正數,所以第一個 bit 統一都是 0。
41 bit:表示的是時間戳,單位是毫秒。41 bit 可以表示的數位多達 2^41 - 1,也就是可以標識 2^41 - 1 個毫秒值,換算成年就是表示69年的時間。
10 bit:記錄工作機器 id,代表的是這個服務最多可以部署在 2^10臺機器上哪,也就是1024臺機器。但是 10 bit 裡 5 個 bit 代表機房 id,5 個 bit 代表機器 id。意思就是最多代表 2^5個機房(32個機房),每個機房裏可以代表 2^5 個機器(32臺機器)。
12 bit:這個是用來記錄同一個毫秒內產生的不同 id,12 bit 可以代表的最大正整數是 2^12 - 1 = 4096,也就是說可以用這個 12 bit 代表的數位來區分同一個毫秒內的 4096 個不同的 id。
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000000
public class IdWorker {
private long workerId;
private long datacenterId;
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence) {
// sanity check for workerId
// 這兒不就檢查了一下,要求就是你傳遞進來的機房id和機器id不能超過32,不能小於0
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(
String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(
String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
System.out.printf(
"worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
// 這個是二進制運算,就是 5 bit最多隻能有31個數字,也就是說機器id最多隻能是32以內
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 這個是一個意思,就是 5 bit最多隻能有31個數字,機房id最多隻能是32以內
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << sequenceBits);
private long lastTimestamp = -1L;
public long getWorkerId() {
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
public long getTimestamp() {
return System.currentTimeMillis();
}
public synchronized long nextId() {
// 這兒就是獲取當前時間戳,單位是毫秒
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 這個意思是說一個毫秒內最多隻能有4096個數字
// 無論你傳遞多少進來,這個位運算保證始終就是在4096這個範圍內,避免你自己傳遞個sequence超過了4096這個範圍
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
// 這兒記錄一下最近一次生成id的時間戳,單位是毫秒
lastTimestamp = timestamp;
// 這兒就是將時間戳左移,放到 41 bit那兒;
// 將機房 id左移放到 5 bit那兒;
// 將機器id左移放到5 bit那兒;將序號放最後12 bit;
// 最後拼接起來成一個 64 bit的二進制數位,轉換成 10 進位制就是個 long 型
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
// ---------------測試---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1, 1, 1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}
怎麼說呢,大概這個意思吧,就是說 41 bit 是當前毫秒單位的一個時間戳,就這意思;然後 5 bit 是你傳遞進來的一個機房 id(但是最大隻能是 32 以內),另外 5 bit 是你傳遞進來的機器 id(但是最大隻能是 32 以內),剩下的那個 12 bit序列號,就是如果跟你上次生成 id 的時間還在一個毫秒內,那麼會把順序給你累加,最多在 4096 個序號以內。
所以你自己利用這個工具類,自己搞一個服務,然後對每個機房的每個機器都初始化這麼一個東西,剛開始這個機房的這個機器的序號就是 0。然後每次接收到一個請求,說這個機房的這個機器要生成一個 id,你就找到對應的 Worker 生成。
利用這個 snowflake 演算法,你可以開發自己公司的服務,甚至對於機房 id 和機器 id,反正給你預留了 5 bit + 5 bit,你換成別的有業務含義的東西也可以的。
當然,你也可以用 : 1 個 bit 是不用的 + 用其中的 41 bit 作爲毫秒數 + 12 bit 作爲序列號 + 用 10 bit 作爲工作機器 id,或者顛倒兌換一下順序,怎麼使用根據你自己的業務需要進行組合配用。
這個 snowflake 演算法相對來說還是比較靠譜的,所以你要真是搞分佈式 id 生成,如果是高併發啥的,那麼用這個應該效能比較好,一般每秒幾萬併發的場景,也足夠你用了。
百度(uid-generator)
uid-generator使用的就是snowflake,只是在生產機器id,也叫做workId時有所不同。
uid-generator中的workId是由uid-generator自動生成的,並且考慮到了應用部署在docker上的情況,在uid-generator中使用者可以自己去定義workId的生成策略,預設提供的策略是:應用啓動時由數據庫分配。說的簡單一點就是:應用在啓動時會往數據庫表(uid-generator需要新增一個WORKER_NODE表)中去插入一條數據,數據插入成功後返回的該數據對應的自增唯一id就是該機器的workId,而數據由host,port組成。
對於uid-generator中的workId,佔用了22個bit位,時間佔用了28個bit位,序列化佔用了13個bit位,需要注意的是,和原始的snowflake不太一樣,時間的單位是秒,而不是毫秒,workId也不一樣,同一個應用每重新啓動一次就會消費一個workId。
美團(Leaf)
美團的Leaf也是一個分佈式ID生成框架。它非常全面,即支援號段模式,也支援snowflake模式。號段模式這裏就不介紹了,和上面的分析類似。
Leaf中的snowflake模式和原始snowflake演算法的不同點,也主要在workId的生成,Leaf中workId是基於ZooKeeper的順序Id來生成的,每個應用在使用Leaf-snowflake時,在啓動時都會都在Zookeeper中生成一個順序Id,相當於一臺機器對應一個順序節點,也就是一個workId。
Redis
這裏額外再介紹一下使用Redis來生成分佈式ID,其實和利用Mysql自增ID類似,可以利用Redis中的incr命令來實現原子性的自增與返回,比如:
127.0.0.1:6379> set seq_id 1 // 初始化自增ID爲1
OK
127.0.0.1:6379> incr seq_id // 增加1,並返回
(integer) 2
127.0.0.1:6379> incr seq_id // 增加1,並返回
(integer) 3
使用redis的效率是非常高的,但是要考慮持久化的問題。Redis支援RDB和AOF兩種持久化的方式。
RDB持久化相當於定時打一個快照進行持久化,如果打完快照後,連續自增了幾次,還沒來得及做下一次快照持久化,這個時候Redis掛掉了,重新啓動Redis後會出現ID重複。
AOF持久化相當於對每條寫命令進行持久化,如果Redis掛掉了,不會出現ID重複的現象,但是會由於incr命令過多,導致重新啓動恢復數據時間過長。