python 爬蟲入門之---xpath
本人爬蟲也是小白一枚,先轉在一部分還不錯的基礎文章。
原文鏈接:[尊重別人的勞動成果是對自己的尊重~~~]
https://www.cnblogs.com/lei0213/p/7506130.html
一、簡介
XPath 是一門在 XML 文件中查詢資訊的語言。XPath 可用來在 XML 文件中對元素和屬性進行遍歷。XPath 是 W3C XSLT 標準的主要元素,並且 XQuery 和 XPointer 都構建於 XPath 表達之上。
二、安裝
|
1 |
|
三、使用
1、匯入
|
1 |
|
2、基本使用
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
從下面 下麪的結果來看,我們印表機html其實就是一個python物件,etree.tostring(html)則是不全裡html的基本寫法,補全了缺胳膊少腿的標籤。
|
1 2 3 4 5 6 7 8 9 10 11 |
|
3、獲取某個標籤的內容(基本使用),注意,獲取a標籤的所有內容,a後面就不用再加正斜槓,否則報錯。
寫法一
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
寫法二(直接在需要查詢內容的標籤後面加一個/text()就行)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
|
4、開啓讀取html檔案
|
1 2 3 4 5 6 |
|
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
5、列印指定路徑下a標籤的屬性(可以通過遍歷拿到某個屬性的值,查詢標籤的內容)
|
1 2 3 4 5 6 7 8 9 10 11 |
|
6、我們知道我們使用xpath拿到得都是一個個的ElementTree物件,所以如果需要查詢內容的話,還需要遍歷拿到數據的列表。
查到絕對路徑下a標籤屬性等於link2.html的內容。
|
1 2 3 4 5 6 7 8 9 |
|
7、上面我們找到全部都是絕對路徑(每一個都是從根開始查詢),下面 下麪我們查詢相對路徑,例如,查詢所有li標籤下的a標籤內容。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
8、上面我們使用絕對路徑,查詢了所有a標籤的屬性等於href屬性值,利用的是/---絕對路徑,下面 下麪我們使用相對路徑,查詢一下l相對路徑下li標籤下的a標籤下的href屬性的值,注意,a標籤後面需要雙//。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
9、相對路徑下跟絕對路徑下查特定屬性的方法類似,也可以說相同。
|
1 2 3 4 5 6 7 8 9 |
|
10、查詢最後一個li標籤裡的a標籤的href屬性
|
1 2 3 4 5 6 7 8 9 |
|
11、查詢倒數第二個li標籤裡的a標籤的href屬性
|
1 2 3 4 5 6 7 8 9 |
|
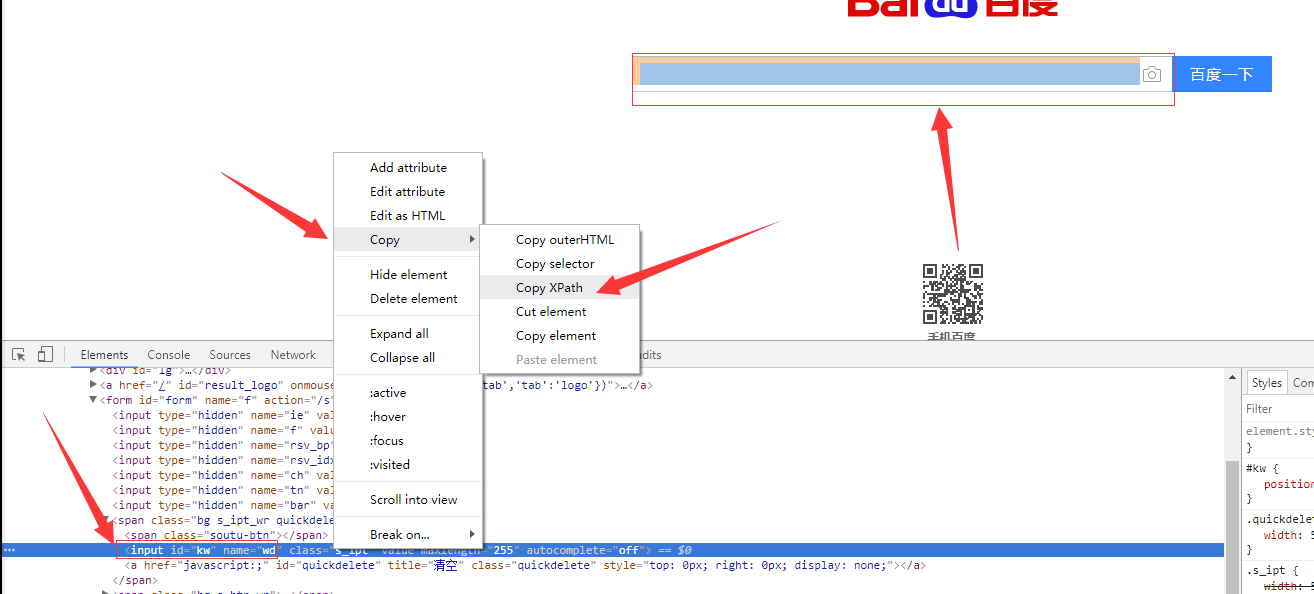
12、如果在提取某個頁面的某個標籤的xpath路徑的話,可以如下圖:
//*[@id="kw"]
解釋:使用相對路徑查詢所有的標籤,屬性id等於kw的標籤。


#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.selector import Selector, HtmlXPathSelector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
<li class="item-"><a id='i1' href="link.html">first item</a></li>
<li class="item-0"><a id='i2' href="llink.html">first item</a></li>
<li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li>
</ul>
<div><a href="llink2.html">second item</a></div>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
# hxs = HtmlXPathSelector(response)
# print(hxs)
# hxs = Selector(response=response).xpath('//a')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[2]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[contains(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first()
# print(hxs)
# ul_list = Selector(response=response).xpath('//body/ul/li')
# for item in ul_list:
# v = item.xpath('./a/span')
# # 或
# # v = item.xpath('a/span')
# # 或
# # v = item.xpath('*/a/span')
# print(v)