lstm詞性標註
2020-08-10 10:26:40
LSTM 詞性標註(POS tagging)
本程式碼原理:
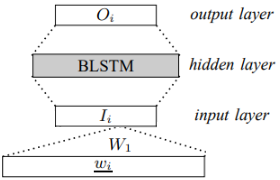
這個模型極其的簡單,就是把詞向量 w 放入lstm 中訓練,根據對應得tags 計算loss 並且跟新模型權重。
參考論文:https://arxiv.org/pdf/1510.06168.pdf
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.optim import lr_scheduler
from torchtext import data
import numpy as np
import random
from torch.utils.data import Dataset
import time
import shutil
EMBEDDING_DIM = 300
HIDDEN_DIM = 200
USE_CUDA = torch.cuda.is_available()
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
BATCH_SIZE = 128
batch_size = BATCH_SIZE
載入POS tagging訓練和dev數據集。這些檔案都是tab分隔的text和POS tag數據,
def load_datasets():
text = data.Field(include_lengths=True)
tags = data.Field()
train_data, val_data, test_data = data.TabularDataset.splits(path='./', train='train.txt', validation='dev.txt', test='dev.txt', fields=[('text', text), ('tags', tags)], format='tsv')
batch_sizes = (BATCH_SIZE, BATCH_SIZE, BATCH_SIZE)
train_loader, dev_loader, test_loader = data.BucketIterator.splits((train_data, val_data, test_data), batch_sizes=batch_sizes, sort_key=lambda x: len(x.text))
text.build_vocab(train_data)
tags.build_vocab(train_data)
dataloaders = {'train': train_loader,
'validation': dev_loader,
'test': dev_loader}
return text, tags, dataloaders
text, tags, dataloaders = load_datasets()
text_vocab_size = len(text.vocab.stoi) + 1
tag_vocab_size = len(tags.vocab.stoi) - 1 # = 42 (not including the <pad> token
print(text_vocab_size)
print(tag_vocab_size)
32353
43
定義訓練函數
def train(model, train_loader, loss_fn, optimizer, use_gpu=False):
model.train() # Set model to training mode
running_loss = 0.0
running_corrects = 0
example_count = 0
step = 0
# Iterate over data.
for batch in train_loader:
sentences = batch.text[0].transpose(1, 0)
tags = batch.tags.transpose(1, 0)
outputs = model(sentences)
total_correct = 0
mask = torch.ones(tags.size())
mask = ~(mask == tags).cuda()
tags = tags.cuda()
# 統計當前正確單詞數
total_correct += ((outputs.argmax(dim=-1) == tags) * mask).sum().item()
# 計算模型Mask交叉熵損失
# outputs shape: (batch_size * max_len, vocab_size)
outputs = outputs.view(-1, outputs.size(2))
tags = torch.reshape(tags,(-1,))
loss = loss_fn(outputs, tags) * mask
loss = (torch.sum(loss) / torch.sum(mask))
# 反向傳播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 統計當前總loss
running_loss += loss.item()
# 統計當前總預測單詞數
example_count += torch.sum(mask).item()
# 統計當前正確的單詞數量
running_corrects += total_correct
step += 1
if step % 100 == 0:
print('loss: {}, running_corrects: {}, example_count: {}, acc: {}'.format(loss.item(),
running_corrects, example_count, (
running_corrects / example_count) * 100))
print(running_corrects/example_count)
if step * batch_size >= 40000:
break
loss = running_loss / example_count
acc = (running_corrects / example_count) * 100
print(loss)
print(acc)
print('Train Loss: {:.4f} Acc: {:2.3f} ({}/{})'.format(loss, acc, running_corrects, example_count))
return loss, acc
def validate(model, val_loader, loss_fn, use_gpu=False):
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
example_count = 0
# Iterate over data.
with torch.no_grad():
for batch in val_loader:
sentences = batch.text[0].transpose(1, 0)
tags = batch.tags.transpose(1, 0)
outputs = model(sentences)
total_correct = 0
mask = torch.ones(tags.size())
mask = ~(mask == tags).cuda()
tags = tags.cuda()
# 統計當前正確單詞數
total_correct += ((outputs.argmax(dim=-1) == tags) * mask).sum().item()
# 計算模型Mask交叉熵損失
# outputs shape: (batch_size * max_len, vocab_size)
outputs = outputs.view(-1, outputs.size(2))
tags = torch.reshape(tags, (-1,))
loss = loss_fn(outputs, tags) * mask
loss = (torch.sum(loss) / torch.sum(mask))
# 統計當前總預測單詞數
example_count += torch.sum(mask).item()
running_corrects += total_correct
running_loss += loss.item()
loss = running_loss / example_count
acc = (running_corrects / example_count) * 100
print(loss)
print(acc)
print('Validation Loss: {:.4f} Acc: {:2.3f} ({}/{})'.format(loss, acc, running_corrects, example_count))
return loss, acc
def train_model(model, data_loaders, criterion, optimizer, scheduler, save_dir, num_epochs=25, use_gpu=False):
print('Training Model with use_gpu={}...'.format(use_gpu))
since = time.time()
best_model_wts = model.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
train_begin = time.time()
train_loss, train_acc = train(model, data_loaders['train'], criterion, optimizer, use_gpu)
train_time = time.time() - train_begin
print('Epoch Train Time: {:.0f}m {:.0f}s'.format(train_time // 60, train_time % 60))
validation_begin = time.time()
val_loss, val_acc = validate(model, data_loaders['validation'], criterion, use_gpu)
validation_time = time.time() - validation_begin
print('Epoch Validation Time: {:.0f}m {:.0f}s'.format(validation_time // 60, validation_time % 60))
# deep copy the model
is_best = val_acc > best_acc
if is_best:
best_acc = val_acc
best_model_wts = model.state_dict()
save_checkpoint(save_dir, {
'epoch': epoch,
'best_acc': best_acc,
'state_dict': model.state_dict(),
# 'optimizer': optimizer.state_dict(),
}, is_best)
scheduler.step()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
def save_checkpoint(save_dir, state, is_best):
savepath = save_dir + '/' + 'checkpoint.pth.tar'
torch.save(state, savepath)
if is_best:
shutil.copyfile(savepath, save_dir + '/' + 'model_best.pth.tar')
def test_model(model, test_loader, use_gpu=False):
model.eval() # Set model to evaluate mode
running_corrects = 0
example_count = 0
test_begin = time.time()
# Iterate over data.
with torch.no_grad():
for batch in test_loader:
sentences = batch.text[0].transpose(1, 0)
tags = batch.tags.transpose(1, 0)
outputs = model(sentences)
total_correct = 0
mask = torch.ones(tags.size())
mask = ~(mask == tags).cuda()
tags = tags.cuda()
# 統計當前正確單詞數
total_correct += ((outputs.argmax(dim=-1) == tags) * mask).sum().item()
# 計算模型Mask交叉熵損失
# outputs shape: (batch_size * max_len, vocab_size)
outputs = outputs.view(-1, outputs.size(2))
tags = torch.reshape(tags, (-1,))
loss = loss_fn(outputs, tags) * mask
loss = (torch.sum(loss) / torch.sum(mask))
# 統計當前總預測單詞數
example_count += torch.sum(mask).item()
running_corrects += total_correct
acc = (running_corrects / example_count) * 100
print('Test Acc: {:2.3f} ({}/{})'.format(acc, running_corrects, example_count))
test_time = time.time() - test_begin
print('Test Time: {:.0f}m {:.0f}s'.format(test_time // 60, test_time % 60))
return acc
定義詞性標註模型
class POSTagger(nn.Module):
def __init__(self, rnn_class, embedding_dim, hidden_dim, vocab_size, target_size, num_layers):
super(POSTagger, self).__init__()
self.embed = nn.Embedding(vocab_size,embedding_dim)
initrange = 0.1
self.embed.weight.data.uniform_(-initrange, initrange)
self.rnn_type = rnn_class
self.nhid = hidden_dim
self.nlayers = num_layers
self.rnn = getattr(nn, self.rnn_type)(embedding_dim, self.nhid, self.nlayers,bidirectional=True, dropout=0.5)
self.output = nn.Linear(2*self.nhid,tag_vocab_size)
self.drop = nn.Dropout(0.5)
def forward(self, sentences):
inputs = self.embed(sentences.long().cuda())
x_emb = self.drop(inputs)
hidden,states = self.rnn(x_emb)
tag_scores = self.output(hidden)
return tag_scores
model = POSTagger("LSTM", EMBEDDING_DIM, HIDDEN_DIM, text_vocab_size, tag_vocab_size, 2)
if USE_CUDA:
model = model.cuda()
LR = 0.001
GAMMA = 1.
STEP_SIZE = 10
NUM_EPOCHS = 10
SAVE_DIR = "./save/"
loss_fn = nn.CrossEntropyLoss(size_average=False)
optimizer = optim.Adam(model.parameters(), lr=LR)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=STEP_SIZE, gamma=GAMMA)
model = train_model(model, dataloaders, loss_fn, optimizer, exp_lr_scheduler, SAVE_DIR, NUM_EPOCHS, use_gpu=USE_CUDA)
D:\Anaconda\envs\jianbo\lib\site-packages\torch\nn\_reduction.py:43: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
Training Model with use_gpu=True...
Epoch 0/9
----------
loss: 6713.7099609375, running_corrects: 32788, example_count: 279463, acc: 11.732501261347656
0.11732501261347655
loss: 2382.45166015625, running_corrects: 193097, example_count: 559609, acc: 34.50569951519722
0.3450569951519722
loss: 1205.8953857421875, running_corrects: 429156, example_count: 840173, acc: 51.07948005946395
0.5107948005946394
1.7595628876173537
52.608865505038615
Train Loss: 1.7596 Acc: 52.609 (460558/875438)
Epoch Train Time: 0m 20s
0.3458316710620383
91.19104991394148
Validation Loss: 0.3458 Acc: 91.191 (79473/87150)
Epoch Validation Time: 0m 0s
Epoch 1/9
----------
loss: 788.6001586914062, running_corrects: 255259, example_count: 280816, acc: 90.89902284770098
0.9089902284770098
loss: 657.7770385742188, running_corrects: 513259, example_count: 560900, acc: 91.50632911392404
0.9150632911392405
loss: 654.6287231445312, running_corrects: 772700, example_count: 840615, acc: 91.9207960838196
0.9192079608381959
0.27519616667621843
91.96413680923149
Train Loss: 0.2752 Acc: 91.964 (805089/875438)
Epoch Train Time: 0m 20s
0.20717855185389997
93.47905909351692
Validation Loss: 0.2072 Acc: 93.479 (81467/87150)
Epoch Validation Time: 0m 0s
Epoch 2/9
----------
loss: 503.1857604980469, running_corrects: 263015, example_count: 280071, acc: 93.91011564924608
0.9391011564924608
loss: 438.1687316894531, running_corrects: 526459, example_count: 560533, acc: 93.92114291219251
0.939211429121925
loss: 582.8971557617188, running_corrects: 788880, example_count: 839945, acc: 93.92043526659484
0.9392043526659484
0.18409463342734067
93.9248696081276
Train Loss: 0.1841 Acc: 93.925 (822254/875438)
Epoch Train Time: 0m 20s
0.18583392897762926
93.85197934595524
Validation Loss: 0.1858 Acc: 93.852 (81792/87150)
Epoch Validation Time: 0m 0s
Epoch 3/9
----------
loss: 446.87322998046875, running_corrects: 265082, example_count: 280322, acc: 94.56339495294696
0.9456339495294697
loss: 464.0216979980469, running_corrects: 530022, example_count: 560644, acc: 94.5380669373078
0.9453806693730781
loss: 410.72332763671875, running_corrects: 794300, example_count: 840204, acc: 94.5365649294695
0.9453656492946951
0.15566875335780578
94.53462152659583
Train Loss: 0.1557 Acc: 94.535 (827592/875438)
Epoch Train Time: 0m 20s
0.17945726439519238
93.95410212277682
Validation Loss: 0.1795 Acc: 93.954 (81881/87150)
Epoch Validation Time: 0m 1s
Epoch 4/9
----------
loss: 396.01788330078125, running_corrects: 264086, example_count: 278659, acc: 94.77031066644179
0.9477031066644178
loss: 382.27227783203125, running_corrects: 529375, example_count: 558697, acc: 94.75171694138325
0.9475171694138326
loss: 389.7768859863281, running_corrects: 796325, example_count: 840452, acc: 94.74961092364585
0.9474961092364584
0.14375178969425295
94.7533691706323
Train Loss: 0.1438 Acc: 94.753 (829507/875438)
Epoch Train Time: 0m 20s
0.17910427774154655
93.94377510040161
Validation Loss: 0.1791 Acc: 93.944 (81872/87150)
Epoch Validation Time: 0m 0s
Epoch 5/9
----------
loss: 347.9952392578125, running_corrects: 265270, example_count: 279384, acc: 94.94817169200813
0.9494817169200813
loss: 440.2076110839844, running_corrects: 531218, example_count: 559887, acc: 94.87950247103434
0.9487950247103434
loss: 312.8500671386719, running_corrects: 797522, example_count: 840520, acc: 94.88435730262219
0.9488435730262219
0.1364570648125801
94.88279010049826
Train Loss: 0.1365 Acc: 94.883 (830640/875438)
Epoch Train Time: 0m 20s
0.1782135275897115
93.90246701090075
Validation Loss: 0.1782 Acc: 93.902 (81836/87150)
Epoch Validation Time: 0m 0s
Epoch 6/9
----------
loss: 367.9375, running_corrects: 265326, example_count: 279359, acc: 94.97671455009504
0.9497671455009504
loss: 372.747802734375, running_corrects: 532799, example_count: 560895, acc: 94.99086281746138
0.9499086281746137
loss: 336.6311340332031, running_corrects: 798718, example_count: 841091, acc: 94.9621384606422
0.9496213846064219
0.13180827568753328
94.96583424525781
Train Loss: 0.1318 Acc: 94.966 (831367/875438)
Epoch Train Time: 0m 20s
0.17693839129537123
94.04934021801492
Validation Loss: 0.1769 Acc: 94.049 (81964/87150)
Epoch Validation Time: 0m 1s
Epoch 7/9
----------
loss: 388.9825744628906, running_corrects: 265657, example_count: 279461, acc: 95.06049144603361
0.9506049144603361
loss: 380.8445739746094, running_corrects: 531823, example_count: 559566, acc: 95.04205044623869
0.9504205044623869
loss: 394.2706298828125, running_corrects: 798918, example_count: 840854, acc: 95.01268947998108
0.9501268947998107
0.1288225242628324
95.00981223113459
Train Loss: 0.1288 Acc: 95.010 (831752/875438)
Epoch Train Time: 0m 20s
0.17675768871383973
94.00458978772231
Validation Loss: 0.1768 Acc: 94.005 (81925/87150)
Epoch Validation Time: 0m 0s
Epoch 8/9
----------
loss: 367.4685363769531, running_corrects: 266538, example_count: 280444, acc: 95.04143429704325
0.9504143429704326
loss: 412.0025939941406, running_corrects: 532144, example_count: 559815, acc: 95.05711708332217
0.9505711708332217
loss: 359.5570983886719, running_corrects: 798475, example_count: 840172, acc: 95.03708764395861
0.9503708764395862
0.12611204016366306
95.04008279284199
Train Loss: 0.1261 Acc: 95.040 (832017/875438)
Epoch Train Time: 0m 20s
0.1793537753133068
94.122776821572
Validation Loss: 0.1794 Acc: 94.123 (82028/87150)
Epoch Validation Time: 0m 0s
Epoch 9/9
----------
loss: 348.4742126464844, running_corrects: 268397, example_count: 282178, acc: 95.1162032475955
0.9511620324759549
loss: 316.66815185546875, running_corrects: 534516, example_count: 562203, acc: 95.07526640732974
0.9507526640732974
loss: 362.1001281738281, running_corrects: 799966, example_count: 841212, acc: 95.0968364692848
0.950968364692848
0.12393243607308257
95.0991389453051
Train Loss: 0.1239 Acc: 95.099 (832534/875438)
Epoch Train Time: 0m 20s
0.1799404481766351
94.01950659781984
Validation Loss: 0.1799 Acc: 94.020 (81938/87150)
Epoch Validation Time: 0m 0s
Training complete in 3m 26s
Best val Acc: 94.122777