PU learning
一、背景介紹
現實生活許多例子只有正樣本和大量未標記樣本,這是因爲獲取負類樣本較爲困難、負類數據太過多樣化且動態變化。比如在推薦系統,使用者點選爲正樣本,卻不能因爲使用者沒有點選就認爲它是負樣本,因爲可能樣本的位置很偏,導致使用者沒有點選。
PU Learning(Positive-unlabeled learning)是半監督學習的一個研究方向,指在只有正類和無標記數據的情況下,訓練二分類器,伊利諾伊大學芝加哥分校(UIC)的劉兵(Bing Liu)教授和日本理化研究所的杉山將(Masashi Sugiyama)實驗室對PU Learning有較深的研究。
二、方法介紹
目前有兩種解決方法:
1、啓發式地從未標註樣本裡找到可靠的負樣本,以此訓練二分類器,該方法問題是分類效果嚴重依賴先驗知識。
2、將未標註樣本作爲負樣本訓練分類器,由於負樣本中含有正樣本,錯誤的標籤指定導致分類錯誤。
2.1 直接利用標準分類方法
將正樣本和未標記樣本分別看作是positive samples和negative samples, 然後利用這些數據訓練一個標準分類器。分類器將爲每個物品打一個分數(概率值),通常正樣本分數高於負樣本的分數,因此對於那些未標記的物品,分數較高的最有可能爲positive。
這種樸素的方法在文獻Learning classifiers from only positive and unlabeled data中有介紹。論文核心結果是,在某些基本假設下,合理利用正例和未貼標籤數據進行訓練得到的標準分類器應該能夠給出與實際正確分數成正比的分數。
2.2 PU bagging
a)通過將所有正樣本和未標記樣本進行隨機組合來建立訓練集;
b)利用這個「bootstrap」樣本來構建分類器,分別將正樣本和未標記樣本視爲positive和negative;
c)將分類器應用於不在訓練集中的未標記樣本 - OOB(「out of bag」)- 並記錄其分數;
d)重複上述三個步驟,最後爲每個樣本的分數爲OOB分數的平均值。
通過bagging的方法可以將所有未標記樣本進行分類(粗),增大了分類精度。描述這種方法的一篇論文是A bagging SVM to learn from positive and unlabeled examples。該方法優於使用PU學習的最新方法的效能,特別是當正例的數量有限並且未標記的例子中的負片的比例小時。所提出的方法也可以比現有技術方法執行得快得多,特別是當未標記的範例集很大時。
2.3 Two-step approaches
大部分的PU learning策略屬於「two-step approaches」。最近的一篇介紹這些方法的論文是 An Evaluation of Two-Step Techniques for Positive-Unlabeled Learning in Text Classification。
a)識別可以百分之百標記爲negative的未標記樣本子集(「reliable negatives」);需要較大的人工標註
b)使用正負樣本訓練標準分類器並將其應用於剩餘的未標記樣本。
2.4 Positive unlabeled random forest
這裏值得一提的關於PU learning的最新一個發展是文獻Towards Positive Unlabeled Learning for Parallel Data Mining: A Random Forest Framework中提出的一種演算法。
所提議的框架,稱爲PURF(正無標籤隨機森林),能夠從正面和未標記範例中學習,通過並行計算根據UCI數據集上的實驗,通過完全標記數據訓練的RF實現可比較的分類效能。該框架將包括廣泛使用的PU資訊增益(PURF-IG)和新開發的PU基尼指數(PURF-GI)的PU學習技術與可延伸的並行計算演算法(即RF)相結合。
並行化步驟:
1、建立t棵樹、4個進程,每個進程負責建立t/4棵決策樹,建立好的t/4棵決策樹以列表形式返回主進程;
2、分別得到4個子進程的決策樹列表後,將4個子列表整合到一個長度爲t的決策樹列表L;
3、建立4個分類進程,將決策樹列表複製4份分別傳遞到4個分類進程,同時將測試數據分成4份,[0,388]行爲第1部分,[389,777]行爲第2部分,[778,1166]行爲第3部分,[1167,1558]行爲第4部分,分別傳遞到4個分類子進程;
4、第一個子進程以列表的形式返回[0,388]行的分類結果,第二個子進程以列表的形式返回[389,777]行的分類結果,第三個子進程以列表的形式返回[778,1166]行的分類結果,第四個子進程以列表的形式返回[1167,1558]行的分類結果。
5、分別得到4個子進程的標籤列表之後,將4個子列表整合到一個長度爲1559的結果標籤列表。
2.5 參考程式碼(介紹)
https://roywright.me/2017/11/16/positive-unlabeled-learning/(Positive-unlabeled learning)
https://github.com/phuijse/bagging_pu/blob/master/PU_Learning_simple_example.ipynb(PU_Learning_simple_example.ipynb)
https://github.com/roywright/pu_learning/blob/master/circles.ipynb(PU learning techniques applied to artificial data「circle」)
三、Estimating the Class Prior in Positive and Unlabeled Data through Decision Tree Induction(類先驗)
論文通過決策樹歸納對數據子域概率給出下限,隨着標記範例比率的增加,該下限更接近實際概率。論文方法的估計與現有技術方法的估計一樣準確,並且速度提高了一個數量級。
3.1 應用背景
1、醫療記錄通常只列出每個人的診斷疾病,而不是該人沒有的疾病,沒有診斷並不意味着患者沒有患病;
2、知識庫(KB)完成的任務本質上也是一個積極且無標籤的問題,自動構造的KB只包含真實的事實,並不完整,未包括在KB中的事實的真值是未知的,但並不一定錯誤;
3、文字分類也可通過正樣本和未標記數據來表徵,如對使用者的網頁偏好設定進行分類可以將帶書籤的頁面用作正例,將所有其他頁面用作未標記的頁面。
3.2 方法介紹
知道標籤頻率c(爲正樣本或副樣本)大大簡化了PU學習。首先,可以訓練概率分類器來預測Pr,並調整輸出概率;其次,使用相同的分類器對未標記的數據進行加權,然後對加權數據訓練不同的分類器。第三,使用下列等式修改學習演算法,如基於計數的演算法——樹歸納和樸素貝葉斯,只考慮數據的屬性條件子集中正例和負例的數量。標籤頻率可通過三種方式獲得:來自領域知識、通過從小的完全標記數據集估計、直接根據PU數據估算。
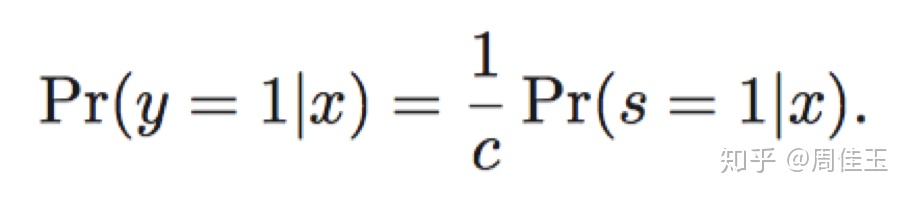
論文提出了一種簡單有效的方法估計類先驗,該方法基於以下觀點:標籤頻率預期在屬性的任何子域中相同,數據的子集自然地暗示標籤頻率的下限。使用基於PU數據的決策樹歸納可以容易地找到可能的正子域。論文將以下先前估計方法進行比較,使用了「完全隨機選擇」假設:EN(Elkan和Noto 2008),PE(du Plessis和Sugiyama 2014),pen-L1(du Plessis,Niu和Sugiyama 2015),KM1和KM2(Ramaswamy,Scott和Tewari 2016),AlphaMax(Jain等人2016)和AlphaMax N(Jain,White和Radivojac 2016)。與這些論文的作者一樣,本文對數據集二次抽樣,最多包含2000個範例,並重復該過程五次。
論文目標是深入瞭解TIcE(Tree Induction for Label Frequency Estimation)的效能,用於c估計的樹誘導,估計來自PU數據的標籤頻率。首先,檢查在實踐中是否最好採用下限的最大值或使用一個下限;其次,評估設定δ的方法;最後,將TIcE與其他類先驗估計演算法進行比較。
該演算法將數據集分成兩個獨立的集合,使用一組可能是正樣本的子域,並使用另一個集合通過最緊密下限來估計c在子域中的計算。尋找數據中純子集也是決策樹歸納的目標,因此TIcE通過引入決策樹來尋找純標記子集,將未標記數據視爲負數。
拆分標準決策樹歸納的目標是找到純節點,使用陽性比例(max-bepp)得分的最大偏差估計值,選擇給出具有最高bepp的子集的分裂:TP。
參考文獻
1-Learning from Positive and Unlabeled Examples with Different Data Distributions
2-Towards Positive Unlabeled Learning for Parallel Data Mining: A Random Forest Framework
3-Positive-Unlabeled Learning with Non-Negative Risk Estimator
4-Estimating Rule Quality for Knowledge Base Completion with the Relationship between Coverage Assumption
5-Beyond the Selected Completely At Random Assumption for Learning from Positive and Unlabeled Data
6-Learning From Positive and Unlabeled Data: A Survey