這篇3萬字的Java後端面試總結,面試官看了瑟瑟發抖(彙總)
「這篇總結我已經導出成pdf版的了,後臺回覆 回復"總結"即可獲取pdf版本哦~」
HashMap原始碼
「問:HashMap底層原理,爲什麼執行緒不安全。
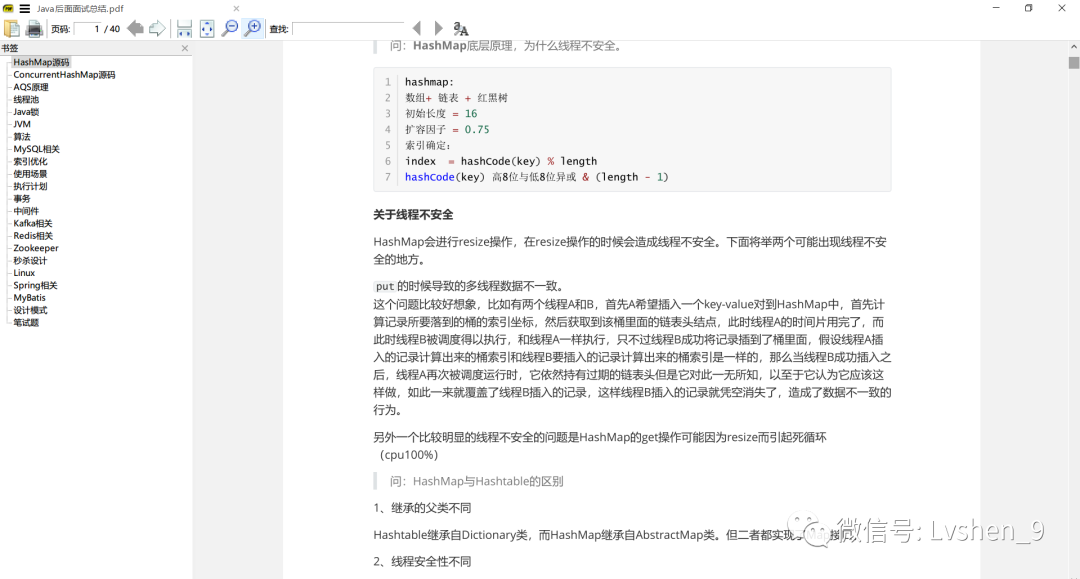
hashmap:
陣列+ 鏈表 + 紅黑樹
初始長度 = 16
擴容因子 = 0.75
索引確定:
index = hashCode(key) % length
hashCode(key) 高8位元與低8位元互斥或 & (length - 1)
關於執行緒不安全
HashMap會進行resize操作,在resize操作的時候會造成執行緒不安全。下面 下麪將舉兩個可能出現執行緒不安全的地方。
put的時候導致的多執行緒數據不一致。這個問題比較好想象,比如有兩個執行緒A和B,首先A希望插入一個key-value對到HashMap中,首先計算記錄所要落到的桶的索引座標,然後獲取到該桶裏面的鏈表頭結點,此時執行緒A的時間片用完了,而此時執行緒B被排程得以執行,和執行緒A一樣執行,只不過執行緒B成功將記錄插到了桶裏面,假設執行緒A插入的記錄計算出來的桶索引和執行緒B要插入的記錄計算出來的桶索引是一樣的,那麼當執行緒B成功插入之後,執行緒A再次被排程執行時,它依然持有過期的鏈表頭但是它對此一無所知,以至於它認爲它應該這樣做,如此一來就覆蓋了執行緒B插入的記錄,這樣執行緒B插入的記錄就憑空消失了,造成了數據不一致的行爲。
另外一個比較明顯的執行緒不安全的問題是HashMap的get操作可能因爲resize而引起死回圈(cpu100%)
「問:HashMap與Hashtable的區別
1、繼承的父類別不同
Hashtable繼承自Dictionary類,而HashMap繼承自AbstractMap類。但二者都實現了Map介面。
2、執行緒安全性不同
javadoc中關於hashmap的一段描述如下:此實現不是同步的。如果多個執行緒同時存取一個雜湊對映,而其中至少一個執行緒從結構上修改了該對映,則它必須保持外部同步。
Hashtable 中的方法是Synchronize的,而HashMap中的方法在預設情況下是非Synchronize的。在多執行緒併發的環境下,可以直接使用Hashtable,不需要自己爲它的方法實現同步,但使用HashMap時就必須要自己增加同步處理。
4、key和value是否允許null值
其中key和value都是物件,並且不能包含重複key,但可以包含重複的value。
通過上面的ContainsKey方法和ContainsValue的原始碼我們可以很明顯的看出:
Hashtable中,key和value都不允許出現null值。但是如果在Hashtable中有類似put(null,null)的操作,編譯同樣可以通過,因爲key和value都是Object型別,但執行時會拋出NullPointerException異常,這是JDK的規範規定的。
HashMap中,null可以作爲鍵,這樣的鍵只有一個;可以有一個或多個鍵所對應的值爲null。當get()方法返回null值時,可能是 HashMap中沒有該鍵,也可能使該鍵所對應的值爲null。因此,在HashMap中不能由get()方法來判斷HashMap中是否存在某個鍵, 而應該用containsKey()方法來判斷。
ConcurrentHashMap原始碼
「問:ConcurrentHashMap底層原理,如何保證執行緒安全的
這裏只討論JDK1.8的ConcurrentHashMap
採用了陣列+鏈表+紅黑樹的實現方式來設計。
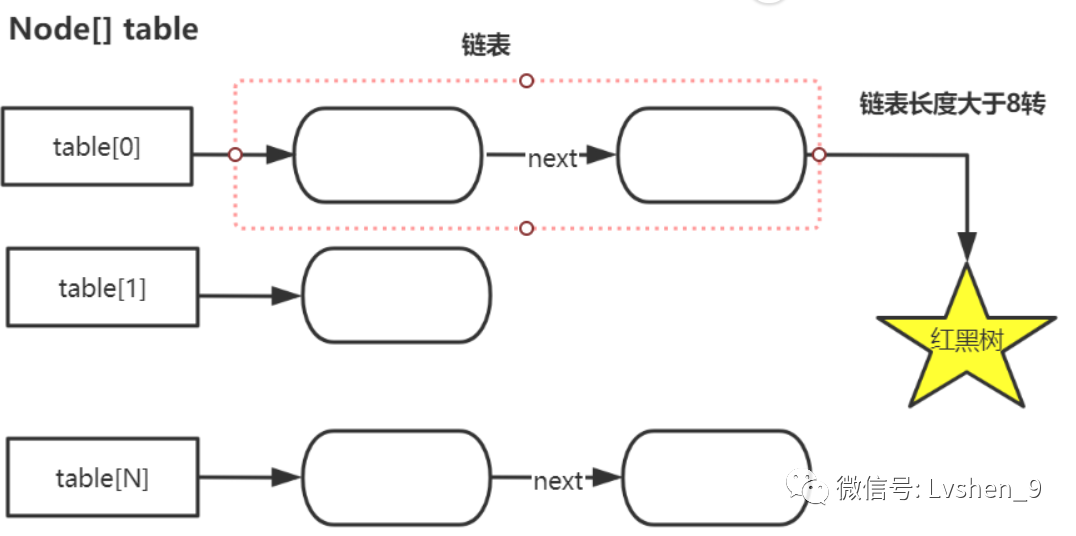
採用Node節點儲存key,value及key的hash值。如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
}
爲保證執行緒安全,採用synchronized+CAS+HashEntry+紅黑樹。
![]()
無鎖化保證執行緒安全。
我們看到put方法呼叫了casTabAt方法。
private static final sun.misc.Unsafe U;
////
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
////
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
會後呼叫的是本地放法。
「問:CAS底層原理
參照來源:https://youzhixueyuan.com/concurrenthashmap.html
CAS是compare and swap的縮寫,即我們所說的比較交換。cas是一種基於鎖的操作,而且是樂觀鎖。在java中鎖分爲樂觀鎖和悲觀鎖。悲觀鎖是將資源鎖住,等一個之前獲得鎖的執行緒釋放鎖之後,下一個執行緒纔可以存取。而樂觀鎖採取了一種寬泛的態度,通過某種方式不加鎖來處理資源,比如通過給記錄加version來獲取數據,效能較悲觀鎖有很大的提高。
CAS 操作包含三個運算元 —— 記憶體位置(V)、預期原值(A)和新值(B)。如果記憶體地址裏面的值和A的值是一樣的,那麼就將記憶體裏面的值更新成B。CAS是通過無限回圈來獲取數據的,若果在第一輪回圈中,a執行緒獲取地址裏面的值被b執行緒修改了,那麼a執行緒需要自旋,到下次回圈纔有可能機會執行。
AQS原理
「問:AQS底層以及相關的類
見文章:Java併發程式設計初探-AQS
「問:ThreadLocal底層,軟參照和弱參照
參照來源:使用ThreadLocal怕記憶體漏失?那你應該來看看這篇文章
執行緒池
「問:執行緒池組成原理,執行緒池的拒絕策略
見文章:手寫執行緒池
「問:如和理解多執行緒,高併發
參照來源:https://www.cnblogs.com/cheyunhua/p/10530023.html
高併發可以通過分佈式技術去解決,將併發流量分到不同的物理伺服器上。但除此之外,還可以有很多其他優化手段:比如使用快取系統,將所有的,靜態內容放到CDN等;還可以使用多執行緒技術將一臺伺服器的服務能力最大化。
多執行緒是指從軟體或者硬體上實現多個執行緒併發執行的技術,它更多的是解決CPU排程多個進程的問題,從而讓這些進程看上去是同時執行(實際是交替執行的)。
這幾個概念中,多執行緒解決的問題是最明確的,手段也是比較單一的,基本上遇到的最大問題就是執行緒安全。在JAVA語言中,需要對JVM記憶體模型、指令重排等深入瞭解,才能 纔能寫出一份高品質的多執行緒程式碼。
「問:如果有個執行緒4,要等前面執行緒1,2,3都執行完才能 纔能執行,你要怎麼做
範例:
/**
* Description:倒計數器
*
* @author Lvshen
* @version 1.0
* @date: 2020/4/16 14:28
* @since JDK 1.8
*/
public class CountDownLatchDemo {
static final int COUNT = 20;
static CountDownLatch cdl = new CountDownLatch(COUNT);
public static void main(String[] args) throws Exception {
new Thread(new Teacher(cdl)).start();
Thread.sleep(1);
for (int i = 0; i < COUNT; i++) {
new Thread(new Student(i, cdl)).start();
}
synchronized (CountDownLatchDemo.class) {
CountDownLatchDemo.class.wait();
}
}
static class Teacher implements Runnable {
CountDownLatch cdl;
Teacher(CountDownLatch cdl) {
this.cdl = cdl;
}
@Override
public void run() {
System.out.println("老師髮捲子。。。");
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("老師收卷子。。。");
}
}
static class Student implements Runnable {
CountDownLatch cdl;
int num;
Student(int num, CountDownLatch cdl) {
this.num = num;
this.cdl = cdl;
}
@Override
public void run() {
System.out.println(String.format("學生(%s)寫卷子。。。",num));
//doingLongTime();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("學生(%s)寫卷子。。。",num));
cdl.countDown();
}
}
}
public class ConcurrentTestDemo {
public static void main(String[] args) {
//併發數
int currency = 20;
//回圈屏障
CyclicBarrier cyclicBarrier = new CyclicBarrier(currency);
for (int i = 0; i < currency; i++) {
new Thread(() -> {
OrderServiceImplWithDisLock orderService = new OrderServiceImplWithDisLock();
System.out.println(Thread.currentThread().getName() + "====start====");
//等待一起出發
try {
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
orderService.createOrder();
}).start();
}
}
}
「問:i++ 要執行緒安全,你有幾種方法,這幾種哪種效能最好
volatile + sychronized/lock.lock , AtomicInteger高併發下lock.lock效能要好,atomicInteger.incrementAndGet()我不知道新能怎麼麼樣,我只知道底層用了CAS,lock.lock底層也用了CAS。
public class VolatileAtomicTest {
public static volatile int num = 0;
public synchronized static void increase() {
num++;
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
increase();
}
});
threads[i].start();
}
for (Thread thread : threads) {
thread.join();
}
System.out.println(num);
}
}
「問:執行緒間的共用怎麼實現
Callable的call方法有返回值;volatile關鍵字能實現執行緒變數的可見
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<String> callable = () -> {
log.info("當前執行緒:{}", Thread.currentThread().getName());
return "Lvshen";
};
//MyFutureTask<String> myFutureTask = new MyFutureTask(callable);
FutureTask<String> myFutureTask = new FutureTask<>(callable);
new Thread(myFutureTask).start();
System.out.println(String.format("當前執行緒:[%s],取出的值:[%s]", Thread.currentThread().getName(), myFutureTask.get()));
}
如上程式碼:Main執行緒獲取到[Thread-0]執行緒的值。

「問:
ThreadPoolExecutor參數
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
corePoolSize:核心執行緒數maximumPoolSize:最大執行緒數keepAliveTime:當沒有任務時,多餘核心執行緒數的執行緒存活時間
Java鎖
「問:synchronized與Lock的區別
「問:volatile關鍵字原理,以及原子自增類
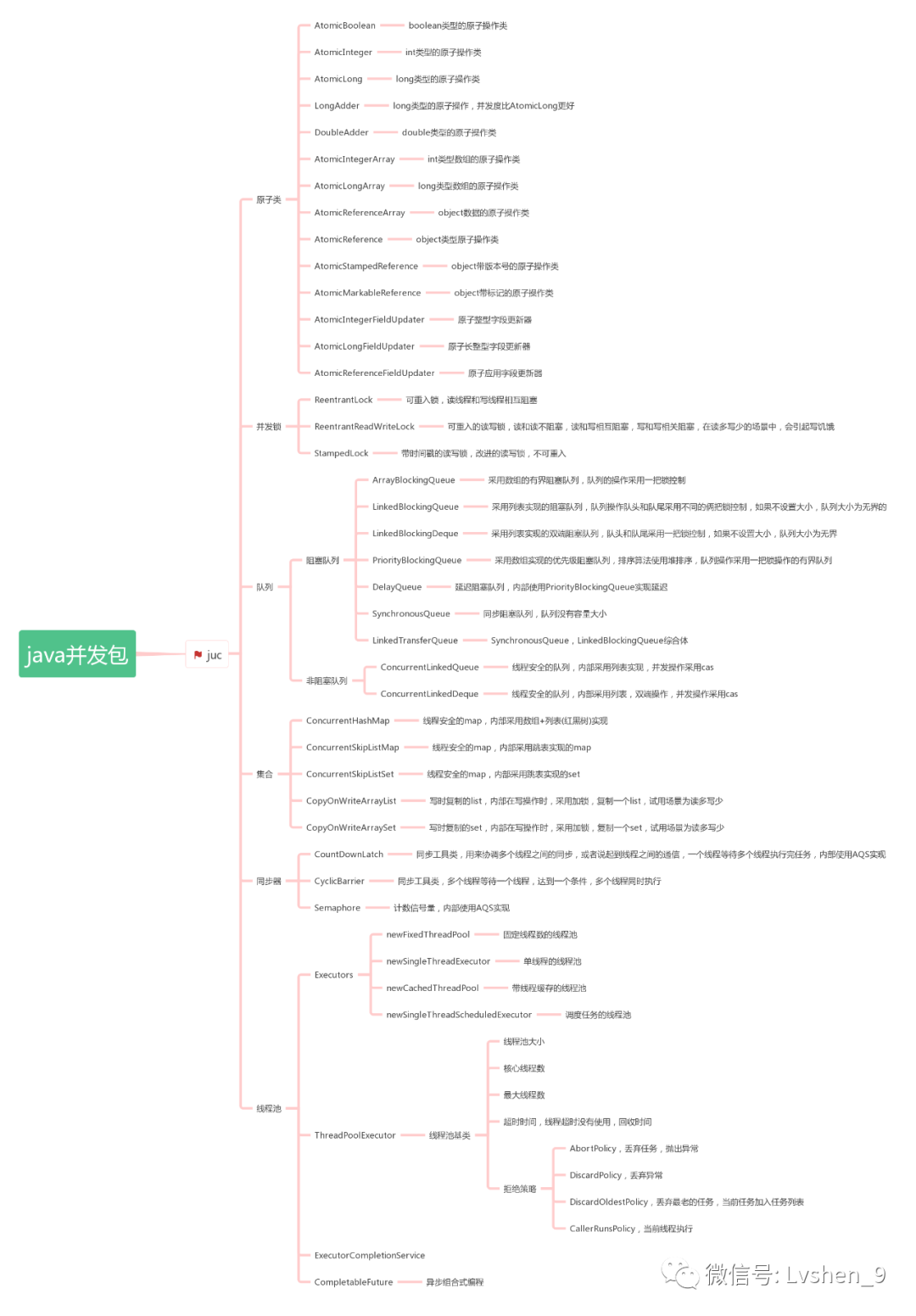
「問:JUC併發包
JDK併發工具類是JDK1.5引入的一大重要的功能,體現在java.util.concurrent包下。java.util.concurrent包主要包含了併發集合類,執行緒池和號志三組重要工具類,還包括了java.util.concurrent.atomic以及java.util.concurrent.locks兩個子包。一般來說,我們稱這個包爲J.U.C。
JVM
「問:Java虛擬機器記憶體劃分,GC回收演算法。
關於記憶體劃分:
可以看看這篇文章:https://mp.weixin.qq.com/s/fit90VdZUa2pG9lbET0i7w
關於GC回收演算法:
見文章:GC回收演算法
「問:記憶體溢位如何排查
見文章:https://mp.weixin.qq.com/s/7XGD-Z3wrThv5HyoK3B8AQ
「問:虛擬機器調優
見視訊:https://ke.qq.com/user/index/index.html#/plan/cid=2770807&term_id=102879437
「問:類載入
![]()
演算法
「問:雪花演算法,原理知道嗎,有沒有缺點。
long id2Long = ((nowTimestamp - baseTimestamp) << TIMESTAMP_LEFT_SHIFT) | workId | sequence;
ip + 埠 + 時間戳 。 跟機器時間有關,如果機器時間回撥,會生成重複的ID。
「問:說說二元樹,與B+Tree的區別
「問:紅黑樹和雜湊表使用場景
Hash:
hash表使用場景:bitmap的布隆過濾器使用的是hash表。在那些需要一次一次遍歷,去尋找元素的問題中,可以將問題轉化爲根據元素的內容去尋找索引,雜湊表在這方面的時間效率是賊高的;在一些字串詞頻統計問題、數獨問題等問題中,可以利用雜湊函數來計算某個元素出現的次數,作爲演算法的輔助工具;還有些問題,可以利用雜湊函數的思路,讓幾個不同的元素獲得同樣的結果,從而實現一個聚類。
舉個用於訊息摘要例子,銀行的數據庫中是不能儲存使用者密碼的原文的,只能儲存密碼的hash值。在這種應用場景裡,對於抗碰撞和抗篡改能力要求極高,對速度的要求在其次。一個設計良好的hash演算法,其抗碰撞能力是很高的。
紅黑樹:
-
epoll的事件管理模組
-
Java中的
TreeMap -
適用增刪比較多的情況
-
AVL適用查詢比較多的情況
-
相對於跳錶,紅黑樹不適用與範圍性的查詢
MySQL相關
索引優化
「問:索引優化,最左原則是什麼?原理知不知道;(id name age)組合索引 where id = ,name = , age> 索引失效麼。你怎麼看explain執行計劃。
1、在MySQL中,進行條件過濾時,是按照向右匹配直到遇到範圍查詢(>,<,between,like)就停止匹配,比如說a = 1 and b = 2 and c > 3 and d = 4 如果建立(a, b, c, d)順序的索引,d是用不到索引的,如果建立(a, b, d, c)索引就都會用上,其中a,b,d的順序可以任意調整。
2、= 和 in 可以亂序,比如 a = 1 and b = 2 and c = 3 建立(a, b, c)索引可以任意順序,MySQL的查詢優化器會優化索引可以識別的形式。

「問:建立索引時,需要考慮哪些因素
主鍵 自增,要int型別,不要頻繁修改。索引不是越多越好,以前公司要求最多5個索引,以常用查詢欄位建立索引
「問:介面慢,怎麼優化
-
[ ] arthas檢視呼叫鏈耗時
-
[ ] 看介面有沒有遠端呼叫,遠端呼叫這個網路耗時要考慮進去
-
[x] 呼叫的遠端介面有沒有問題,有問題的話,遠端介面也需要優化
-
[ ] 方法中的程式碼有沒有問題,比如,回圈裏面查庫了,一個數據多次查庫了,全表查詢了
-
[x] sql有沒有用到索引
-
[ ] 上面的檢查都沒問題,考慮使用快取(讀多寫少用快取,寫多讀少用佇列)
-
[ ] 還可考慮數據庫的主從,讀寫分離
「問:MySQL如果沒有定義主鍵,會建立主鍵索引嗎。有哪幾種儲存引擎
#儲存引擎
Innodb
MyIsam
如果表沒有建立主鍵,如果有唯一鍵,會用唯一鍵欄位建立主鍵
如果沒有唯一鍵,則用一個隱式的rowid建立主鍵索引
「問:MySQL回表
普通索引的葉子節點儲存的主鍵的值,通過普通索引查詢的值,還需要到主鍵索引中去查一遍,這就叫回表
「問:聚集索引與非聚集索引
-
聚集索引:葉子節點村的是數據
-
非聚集索引:葉子節點存的是數據的地址
「問:索引分類
主鍵索引,普通索引,唯一索引,聯合索引
「問:B+Tree 與Hash的優缺點
-
Hash,單個查詢最壞時間複雜度,但是不能進行範圍查詢
-
B+Tree,可以範圍查詢,能存更多的數據
使用場景
「問:怎麼找到最大 age的數值
--索引失效SELECT MAX(`code`) from member
EXPLAIN SELECT * FROM member WHERE code = (SELECT MAX(`code`) from member);
--兩個 表的查詢都不是失效
EXPLAIN SELECT * FROM member WHERE code = (SELECT `code` FROM member ORDER BY `code` DESC LIMIT 1);
「問:MySQL中,char_length() 與length()區別
char_length() : 一般判斷中文長度
length() : 一般判斷英文長度
「問:如何分庫分表
來源:https://www.imooc.com/article/301836
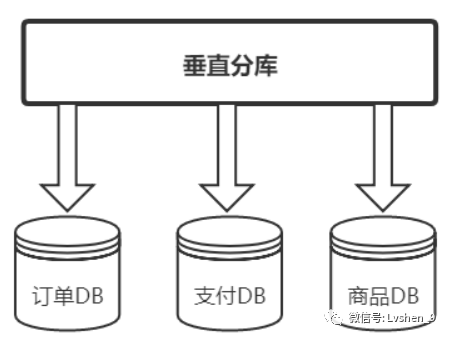
垂直分庫分表:
垂直分庫是基於業務分類的,和我們常聽到的微服務治理觀念很相似,每一個獨立的服務都擁有自己的數據庫,需要不同業務的數據需介面呼叫。而垂直分庫也是按照業務分類進行劃分,每個業務有獨立數據庫。
垂直分表是基於數據表的列爲依據切分的,是一種大表拆小表的模式。
例如:一個order表有很多欄位,把長度較大且存取不頻繁的欄位,拆分出來建立一個單獨的擴充套件表work_extend進行儲存。
拆分前:
order表:
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(2000) |
拆分後:
order核心表:
| id | workNo | price | … |
|---|---|---|---|
| int(12) | int(2) | int(15) |
work_extend表:
| id | workNo | describe | … |
|---|---|---|---|
| int(12) | int(2) | varchar(2000) |
水平切分:
水平切分將一張大數據量的表,切分成多個表結構相同,而每個表只佔原表一部分數據,然後按不同的條件分散到多個數據庫中。
假如一張order表有2000萬數據,水平切分後出來四個表,order_1、order_2、order_3、order_4,每張表數據500萬,以此類推。
order_1表:
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
order_2表
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
order_3表
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
order_4表
| id | workNo | price | describe | … |
|---|---|---|---|---|
| int(12) | int(2) | int(15) | varchar(200 |
「問:如何將10萬條數據匯入MySQL
// 外層回圈,總提交事務次數
for (int i = 1; i <= 100; i++) {
suffix = new StringBuffer();
// 第j次提交步長
for (int j = 1; j <= 10000; j++) {
// 構建SQL後綴
suffix.append("('" + uutil.UUIDUtil.getUUID()+"','"+i*j+"','123456'"+ ",'男'"+",'教師'"+",'www.bbk.com'"+",'XX大學'"+",'"+"2020-08-12 14:43:26"+"','備註'" +"),");
}
// 構建完整SQL
String sql = prefix + suffix.substring(0, suffix.length() - 1);
// 新增執行SQL
pst.addBatch(sql);
// 執行操作
pst.executeBatch();
// 提交事務
conn.commit();
// 清空上一次新增的數據
suffix = new StringBuffer();
}
如上面虛擬碼,分批次insert即可。
「問:怎麼查詢成績第二的學生
-- 子查詢索引沒有失效
EXPLAIN SELECT * FROM member m WHERE m.`code` =
(SELECT m2.`code` FROM member m2 WHERE m2.`code` < (SELECT m1.`code` FROM member m1 ORDER BY m1.`code` DESC LIMIT 1) ORDER BY m2.`code` DESC LIMIT 1);
-- 使用max()裏面的子查詢索引會失效
EXPLAIN SELECT * FROM member m WHERE m.`code` = (SELECT MAX(m2.code) FROM member m2 WHERE m2.code < (SELECT MAX(m1.code) FROM member m1));
執行計劃
「問:MySQL explain執行計劃
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
EXPLAIN SELECT * from member ORDER BY id; #index
EXPLAIN SELECT * from member WHERE code < 100 and code <120; #range
EXPLAIN SELECT * from member WHERE name < '1' and name <'3'; #range
EXPLAIN SELECT * from member WHERE code = '99'; #ref
EXPLAIN SELECT id from member WHERE name = '99'; #ref
EXPLAIN SELECT * from member WHERE id = '1'; #const
事務
「問:開啓了兩個事務,a事務裏面作修改未提交,b事務裏面做新增會怎樣
![]()
可以新增,只有修改同一條數據時會被鎖住
![]()
![]()
「問:MySQL預設事務隔離級別,以及哪些事務隔離級別
未提交讀
已提交讀
可重複讀 (Mysql預設)
序列化
中介軟體
Kafka相關
「問:怎麼保證kafka訊息的順序性,kafka消費端數據不丟失
順序性:
![]()
如上圖,分生產者順序發送,和消費者順序消費
對於順序發送,我們需要知道,當數據寫入一個partition時,可以保證順序性,所以如果有一批數據需要保證順序,那麼給這批數據指定一個key即可。
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
ProducerRecord<K, V> producerRecord = new ProducerRecord(topic, key, data);
return this.doSend(producerRecord);
}
如上程式碼,呼叫KafkaTemplate的這個send方法。
對於順序消費,需要將一個partition的數據發送到一個暫存佇列中,然後再將這個佇列仍給一個執行緒,這樣保證順序的數據是一個執行緒獲取的。
消費數據不丟失:
消費數據丟失情況可能是,消費者已經拿到數據,將offset提交給了kafka或者zookeeper,但是這個數據還沒有實際使用,比如儲存到數據庫中。這個時候消費者服務掛掉。當消費者服務重新啓動時。導致數據沒有存入庫中,但offset顯示已經消費,消費者再次去消費,拿不到數據了。關於解決辦法:將自動提交offset改爲手動提交,只有業務正真結束才提交offset。
「問:Kafka實現分佈式事務
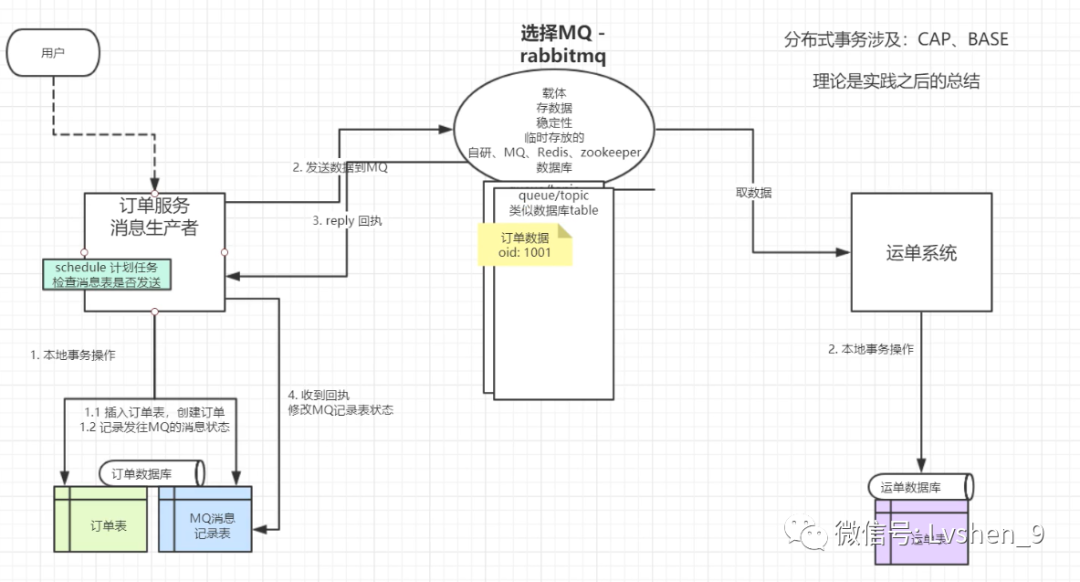
如果服務A呼叫服務B,那麼服務A就是生產者,服務B就是消費者。
如上圖,不一定是kafka,訊息中介軟體都可以處理分佈式事務問題。在訊息中介軟體處理數據過程中,並不需要處理事務回滾問題。我們需要保證兩件事:
1.生產者數據發到kafka一定成功
2.消費者從kafka消費數據一定成功
如何讓保證數據百分百發送到kafka?將生產的數據存一份到數據做兜底,如果生產者收不到kafka的回執,採用重試機制 機製,將數據庫中的數據發送到kafka中,直到成功,修改數據庫中的數據發送狀態。
由於這種方式是非同步的,生產者和消費者是非耦合的,所以消費者自行從kafka中消費數據。消費成功,消費者會提交偏移量給Zookeeper(新版本是消費者將偏移量提交給kafka了)。
「問:kafka爲什麼快,以及如何選型訊息佇列
爲什麼快:
-
順序讀寫
-
NIO多路複用模型,減少系統呼叫
-
零拷貝,減少系統呼叫
選型:
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 單機吞吐量 | 萬級,吞吐量比RocketMQ和Kafka要低了一個數量級 | 萬級,吞吐量比RocketMQ和Kafka要低了一個數量級 | 10萬級,RocketMQ也是可以支撐高吞吐的一種MQ | 10萬級別,這是kafka最大的優點,就是吞吐量高。 一般配合大數據類的系統來進行實時數據計算、日誌採集等場景 |
| topic數量對吞吐量的影響 | topic可以達到幾百,幾千個的級別,吞吐量會有較小幅度的下降 這是RocketMQ的一大優勢,在同等機器下,可以支撐大量的topic | topic從幾十個到幾百個的時候,吞吐量會大幅度下降 所以在同等機器下,kafka儘量保證topic數量不要過多。如果要支撐大規模topic,需要增加更多的機器資源 | ||
| 時效性 | ms級 | 微秒級,這是rabbitmq的一大特點,延遲是最低的 | ms級 | 延遲在ms級以內 |
| 可用性 | 高,基於主從架構實現高可用性 | 高,基於主從架構實現高可用性 | 非常高,分佈式架構 | 非常高,kafka是分佈式的,一個數據多個副本,少數機器宕機,不會丟失數據,不會導致不可用 |
| 訊息可靠性 | 有較低的概率丟失數據 | 經過參數優化設定,可以做到0丟失 | 經過參數優化設定,訊息可以做到0丟失 | |
| 功能支援 | MQ領域的功能極其完備 | 基於erlang開發,所以併發能力很強,效能極其好,延時很低 | MQ功能較爲完善,還是分佈式的,擴充套件性好 | 功能較爲簡單,主要支援簡單的MQ功能,在大數據領域的實時計算以及日誌採集被大規模使用,是事實上的標準 |
| 優劣勢總結 | 非常成熟,功能強大,在業內大量的公司以及專案中都有應用 偶爾會有較低概率丟失訊息 而且現在社羣以及國內應用都越來越少,官方社羣現在對ActiveMQ 5.x維護越來越少,幾個月才發佈一個版本 而且確實主要是基於解耦和非同步來用的,較少在大規模吞吐的場景中使用 | erlang語言開發,效能極其好,延時很低; 吞吐量到萬級,MQ功能比較完備 而且開源提供的管理介面非常棒,用起來很好用 社羣相對比較活躍,幾乎每個月都發布幾個版本分 在國內一些網際網路公司近幾年用rabbitmq也比較多一些 但是問題也是顯而易見的,RabbitMQ確實吞吐量會低一些,這是因爲他做的實現機制 機製比較重。 而且erlang開發,國內有幾個公司有實力做erlang原始碼級別的研究和定製?如果說你沒這個實力的話,確實偶爾會有一些問題,你很難去看懂原始碼,你公司對這個東西的掌控很弱,基本職能依賴於開源社羣的快速維護和修復bug。 而且rabbitmq叢集動態擴充套件會很麻煩,不過這個我覺得還好。其實主要是erlang語言本身帶來的問題。很難讀原始碼,很難定製和掌控。 | 介面簡單易用,而且畢竟在阿裡大規模應用過,有阿裡品牌保障 日處理訊息上百億之多,可以做到大規模吞吐,效能也非常好,分佈式擴充套件也很方便,社羣維護還可以,可靠性和可用性都是ok的,還可以支撐大規模的topic數量,支援複雜MQ業務場景 而且一個很大的優勢在於,阿裡出品都是java系的,我們可以自己閱讀原始碼,定製自己公司的MQ,可以掌控 社羣活躍度相對較爲一般,不過也還可以,文件相對來說簡單一些,然後介面這塊不是按照標準JMS規範走的有些系統要遷移需要修改大量程式碼 還有就是阿裡出臺的技術,你得做好這個技術萬一被拋棄,社羣黃掉的風險,那如果你們公司有技術實力我覺得用RocketMQ挺好的 | kafka的特點其實很明顯,就是僅僅提供較少的核心功能,但是提供超高的吞吐量,ms級的延遲,極高的可用性以及可靠性,而且分佈式可以任意擴充套件 同時kafka最好是支撐較少的topic數量即可,保證其超高吞吐量 而且kafka唯一的一點劣勢是有可能訊息重複消費,那麼對數據準確性會造成極其輕微的影響,在大數據領域中以及日誌採集中,這點輕微影響可以忽略 這個特性天然適合大數據實時計算以及日誌收集 |
總結:ActiveMQ較老的系統會使用,現在社羣不活躍,不推薦使用;
RabbitMQ比較穩定,吞吐量萬級別,適合小公司,小業務系統使用;
RocketMQ吞吐量10萬級別,適合高併發,阿裡開源,社羣活躍;
Kafka吞吐量10萬級別,適合日誌採集,大數據實時計算。非常穩定,社羣活躍。
Redis相關
「問:Redis發佈訂閱使用場景
見文章:Redis發佈訂閱
「問:Redis分佈式鎖底層怎麼實現
1. setnx + 過期時間 用lua指令碼保證原子性
2. 鎖持有心跳檢測(防止未解鎖,鎖失效問題)
3. 執行緒自選獲取鎖
Redisson框架已有實現
「問:怎麼處理快取雪崩,快取穿透的場景
見文章:Redis進階
「問:限流操作
見文章:用Redis實現介面限流
「問:分佈式快取與JVM的快取區別
JVM快取如List,Map。在單機內有效。如果叢集部署,就會使快取失效,需要全域性的快取,所以需要使用Redis等快取中介軟體。
「問:介面冪等如何實現
![]()
Github地址:https://github.com/lvshen9/demo-lvshen/tree/master/src/main/java/com/lvshen/demo/autoidempotent
「問:Redis分佈式鎖主從同步問題
RedLock演算法解決主從同步問題。
「問:Session共用
Redis實現,已經有成熟的API,可整合SpringBoot。
jar包 引入
<!--session redis-->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
直接使用,Session已經存入Redis中了。
@RequestMapping(value = "/testSession",method = RequestMethod.GET)
public String testSession(HttpSession session, Model model) {
List<Member> members = memberService.listMember();
System.out.println("sessionId------>" + session.getId());
model.addAttribute("member", JSON.toJSONString(members));
session.setAttribute("member",JSON.toJSONString(members));
return "hello world";
}
Zookeeper
「問:Zookeeper使用場景
見文章:手寫Zookeeper分佈式鎖
「問:Zookeeper底層結構,選舉原理,最小叢集數
文章來源:https://www.cnblogs.com/wuzhenzhao/p/9983231.html
Zookeeper本質還是一個儲存容器,以節點的形式儲存數據。
在 ZooKeeper中,每個數據節點都是有生命週期的,其生命週期的長短取決於數據節點的節點型別。在 ZooKeeper中,節點型別可以分爲持久節點(PERSISTENT)、臨時節點(EPHEMERAL)和順序節點(SEQUENTIAL)三大類,具體在節點建立過程中,通過組合使用,可以生成以下四種組合型節點型別:
-
持久節點(PERSISTENT):持久節點是 ZooKeeper中最常見的一種節點型別。所謂持久節點,是指該數據節點被建立後,就會一直存在於 ZooKeeper伺服器上,直到有刪除操作來主動清除這個節點。
-
持久順序節點(PERSISTENT SEQUENTIAL):持久順序節點的基本特性和持久節點是一致的,額外的特性表現在順序性上。在ZooKeeper中,每個父節點都會爲它的第一級子節點維護一份順序,用於記錄下每個子節點建立的先後順序。基於這個順序特性,在建立子節點的時候,可以設定這個標記,那麼在建立節點過程中, ZooKeeper會自動爲給定節點名加上一個數位後綴,作爲一個新的、完整的節點名。另外需要注意的是,這個數位後綴的上限是整型的最大值。
-
臨時節點(EPHEMERAL):和持久節點不同的是,臨時節點的生命週期和用戶端的對談系結在一起,也就是說,如果用戶端對談失效,那麼這個節點就會被自動清理掉。注意,這裏提到的是用戶端對談失效,而非TCP連線斷開。另外, ZooKeeper規定了不能基於臨時節點來建立子節點,即臨時節點只能作爲葉子節點。
-
臨時順序節點(EPHEMERAL SEQUENTIAL):臨時順序節點的基本特性和臨時節點也是一致的,同樣是在臨時節點的基礎上,新增了順序的特性。
剛啓動時的選舉:
Leader 選舉會分兩個過程啓動的時候的 leader 選舉、 leader 崩潰的時候的的選舉伺服器啓動時的 leader 選舉每個節點啓動的時候狀態都是 LOOKING,處於觀望狀態,接下來就開始進行選主流程進行 Leader 選舉,至少需要兩臺機器,我們選取 3 臺機器組成的伺服器叢集爲例。在叢集初始化階段,當有一臺伺服器 Server1 啓動時,它本身是無法進行和完成 Leader 選舉,當第二臺伺服器 Server2 啓動時,這個時候兩臺機器可以相互通訊,每臺機器都試圖找到 Leader,於是進入 Leader 選舉過程。選舉過程如下:
(1) 每個 Server 發出一個投票。由於是初始情況,Server1和 Server2 都會將自己作爲 Leader 伺服器來進行投票,每次投票會包含所推舉的伺服器的 myid 和 ZXID、epoch,使用(myid, ZXID,epoch)來表示,此時 Server1的投票爲(1, 0),Server2 的投票爲(2, 0),然後各自將這個投票發給叢集中其他機器。
(2) 接受來自各個伺服器的投票。叢集的每個伺服器收到投票後,首先判斷該投票的有效性,如檢查是否是本輪投票(epoch)、是否來自LOOKING狀態的伺服器。
(3) 處理投票。針對每一個投票,伺服器都需要將別人的投票和自己的投票進行 PK,PK 規則如下
i. 優先檢查 ZXID。ZXID 比較大的伺服器優先作爲Leader
ii. 如果 ZXID 相同,那麼就比較 myid。myid 較大的伺服器作爲 Leader 伺服器。
對於 Server1 而言,它的投票是(1, 0),接收 Server2的投票爲(2, 0),首先會比較兩者的 ZXID,均爲 0,再比較 myid,此時 Server2 的 myid 最大,於是更新自己的投票爲(2, 0),然後重新投票,對於 Server2 而言,它不需要更新自己的投票,只是再次向叢集中所有機器發出上一次投票資訊即可。
(4) 統計投票。每次投票後,伺服器都會統計投票資訊,判斷是否已經有過半機器接受到相同的投票資訊,對於 Server1、Server2 而言,都統計出叢集中已經有兩臺機器接受了(2, 0)的投票資訊,此時便認爲已經選出了 Leader。
(5) 改變伺服器狀態。一旦確定了 Leader,每個伺服器就會更新自己的狀態,如果是 Follower,那麼就變更爲FOLLOWING,如果是 Leader,就變更爲 LEADING。
執行時的選舉:
當叢集中的 leader 伺服器出現宕機或者不可用的情況時,那麼整個叢集將無法對外提供服務,而是進入新一輪的Leader 選舉,伺服器執行期間的 Leader 選舉和啓動時期的 Leader 選舉基本過程是一致的。
(1) 變更狀態。Leader 掛後,餘下的非 Observer 伺服器都會將自己的伺服器狀態變更爲 LOOKING,然後開始進入 Leader 選舉過程。
(2) 每個 Server 會發出一個投票。在執行期間,每個伺服器上的 ZXID 可能不同,此時假定 Server1 的 ZXID 爲123,Server3的ZXID爲122;在第一輪投票中,Server1和 Server3 都會投自己,產生投票(1, 123),(3, 122),然後各自將投票發送給叢集中所有機器。接收來自各個伺服器的投票。與啓動時過程相同。
(3) 處理投票。與啓動時過程相同,此時,Server1 將會成爲 Leader。
(4) 統計投票。與啓動時過程相同。 (5) 改變伺服器的狀態。與啓動時過程相同
「問:ElasticSearch有用怎建立索引的麼
這裏我們不說原理,我們來說Java API怎麼建立索引。
舉個例子:
/**
* 建立索引庫
*
* @author lvshen
* @date 2020年08月01日
*
* 需求:建立一個索引庫爲:msg訊息佇列,型別爲:tweet,id爲1
* 索引庫的名稱必須爲小寫
* @throws IOException
*/
@Test
public void addIndex() throws IOException {
IndexResponse response = client.prepareIndex("msg", "tweet", "1").setSource(XContentFactory.jsonBuilder()
.startObject().field("userName", "lvshen")
.field("sendDate", new Date())
.field("msg", "Lvshen的技術小屋")
.endObject()).get();
logger.info("索引名稱:" + response.getIndex() + "\n型別:" + response.getType()
+ "\n文件ID:" + response.getId() + "\n當前範例狀態:" + response.status());
}
秒殺設計
「問:如何設計一個秒殺系統
這個是面試阿裡的時候問的一個問題。問題比較範。要考慮
併發情況下數據庫能不能扛住,Mysql 最高併發估計在萬級別。如果秒殺使用者上千萬以上,要考慮分庫分表,讀寫分離,使用快取,還有使用訊息中介軟體在高峯時期削峯填谷(併發序列化)。也要考慮服務容錯,服務降級,以實現系統高可用
考慮執行緒安全,扣減庫存,執行緒安全問題,防止多扣,可使用數據庫狀態機思想,但要考慮批次修改時死鎖問題。可使用Redis原子性,做庫存扣減。
下面 下麪總結下需要注意的點:
1.不能超賣(直接的經濟損失,平臺信譽受損
2.防黑產、黃牛(阿裡月餅門):機器的請求速度比人的手速快太多了
3.瞬間爆發的高流量
-
典型的讀多寫少的場景(cache快取)
-
頁面靜態化,利用cdn伺服器快取前端檔案
-
按鈕置灰3秒、(利用風控規則過濾掉非法使用者)
-
介面層可以做開關限流(一旦搶購結束則直接返回失敗)
-
堆機器,搭建叢集利用nginx做負載均衡
-
熱點隔離增加資源有限放流(熔斷)多次請求合併爲一次
4.儘量把請求攔截在上層,Mysql單機讀能力爲5k,寫能力爲3k。redis單機讀能力最高可達10w,寫能力能達到3-5W。
5.預熱,運營人員提前將數據寫入Redis。
秒殺流程圖:
![]()
graph LR
A[秒殺開始] --> B[使用者點選秒殺鏈接]
B --> C[搶購資格]
C --> | 否| D>結束並且拉黑]
C --> | 是 | E[庫存是否足夠]
E --> | 是 | F>生成訂單]
E --> | 否 | G>活動結束]
G --> H{修改Redis的活動狀態}
文章推薦:https://mp.weixin.qq.com/s/Q8dWP5c0TJH8fqQdslSTKg
Linux
「問:linux中怎麼看日誌,怎麼看進程,怎麼看磁碟大小,怎麼看記憶體大小
#看日誌
tail -f xx.log
#看進程
jps / ps -ef | grep xx /netstat -tnlp | grep xx
#看磁碟大小
du / df
#看記憶體大小
free
更多Linu命令見文章:我在工作中用到的Linux命令
Spring相關
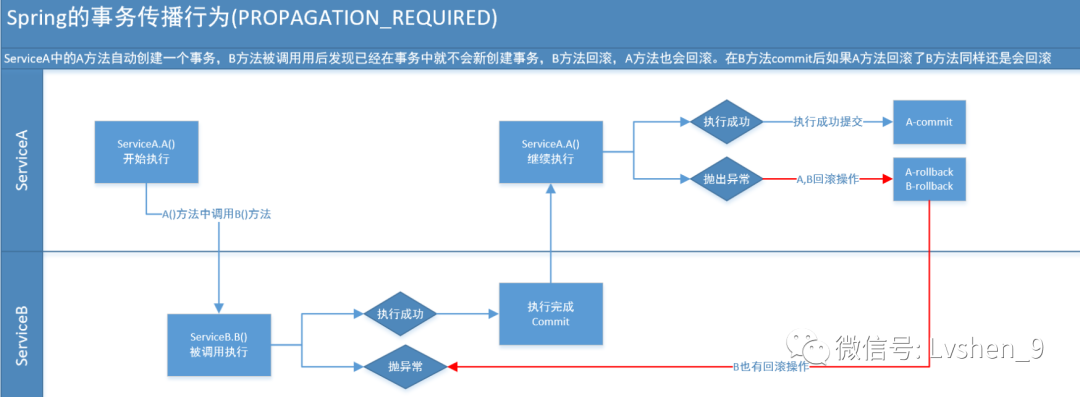
「問:Spring事務 A,B 。A調B, A異常,B會回滾麼
事務傳播型別:
| 務傳播行爲型別 | 說明 |
|---|---|
| PROPAGATION_REQUIRED | 如果當前沒有事務,就新建一個事務,如果已經存在一個事務中,加入到這個事務中。這是最常見的選擇。 |
| PROPAGATION_SUPPORTS | 支援當前事務,如果當前沒有事務,就以非事務方式執行。 |
| PROPAGATION_MANDATORY | 使用當前的事務,如果當前沒有事務,就拋出異常。 |
| PROPAGATION_REQUIRES_NEW | 新建事務,如果當前存在事務,把當前事務掛起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事務方式執行操作,如果當前存在事務,就把當前事務掛起。 |
| PROPAGATION_NEVER | 以非事務方式執行,如果當前存在事務,則拋出異常。 |
| PROPAGATION_NESTED | 如果當前存在事務,則在巢狀事務內執行。如果當前沒有事務,則執行與PROPAGATION_REQUIRED類似的操作。 |
預設傳播型別爲:PROPAGATION_REQUIRED,上面問題,A,B會合併成一個事務,所以A異常,B會回滾,B異常,A會回滾。
「問:Spring中 @Autowired與@Resource區別
-
@Autowired是Spring的註解,Autowired預設先按 byType,如果發現找到多個 bean,則,又按照 byName方式比對,如果還有多個,則報出異常;
-
@Resource 是JDK1.6支援的註解,預設按照名稱( ByName)進行裝配, 如果沒有指定 name屬性,當註解寫在欄位上時,預設取欄位名,按照名稱查詢,如果註解寫在 setter方法上預設取屬性名進行裝配。當找不到與名稱匹配的 bean時才按照型別進行裝配。
推薦文章:https://mp.weixin.qq.com/s/IglQITCkmx7Lpz60QOW7HA
「問:單體服務到微服務的演變史
演變:單體服務 -> SOA -> 微服務
單體服務:
概念:所有功能全部打包在一起。應用大部分是一個war包或jar包。我參與網約車最開始架構是:一個乘客專案中有 使用者、訂單、訊息、地圖等功能。隨着業務發展,功能增多,這個專案會越來越臃腫。
好處:容易開發、測試、部署,適合專案初期試錯。
壞處:
隨着專案越來越複雜,團隊不斷擴大。壞處就顯現出來了。
-
複雜性高:程式碼多,十萬行,百萬行級別。加一個小功能,會帶來其他功能的隱患,因爲它們在一起。
-
技術債務:人員流動,不壞不修,因爲不敢修。
-
持續部署困難:由於是全量應用,改一個小功能,全部部署,會導致無關的功能暫停使用。編譯部署上線耗時長,不敢隨便部署,導致部署頻率低,進而又導致兩次部署之間 功能修改多,越不敢部署,惡性循環。
-
可靠性差:某個小問題,比如小功能出現OOM,會導致整個應用崩潰。
-
擴充套件受限:只能整體擴充套件,無法按照需要進行擴充套件, 不能根據計算密集型(派單系統)和IO密集型(檔案服務) 進行合適的區分。
-
阻礙創新:單體應用是以一種技術解決所有問題,不容易引入新技術。但在高速的網際網路發展過程中,適應的潮流是:用合適的語言做合適的事情。比如在單體應用中,一個專案用spring MVC,想換成spring boot,切換成本很高,因爲有可能10萬,百萬行程式碼都要改,而微服務可以輕鬆切換,因爲每個服務,功能簡單,程式碼少。
SOA:
對單體應用的改進:引入SOA(Service-Oriented Architecture)面向服務架構,拆分系統,用服務的流程化來實現業務的靈活性。服務間需要某些方法進行連線,面向介面等,它是一種設計方法,其中包含多個服務, 服務之間通過相互依賴最終提供一系列的功能。一個服務 通常以獨立的形式存在於操作系統進程中。各個服務之間 通過網路呼叫。但是還是需要用些方法來進行服務組合,有可能還是個單體應用。
所以要引入微服務,是SOA思想的一種具體實踐。
微服務架構 = 80%的SOA服務架構思想 + 100%的元件化架構思想
微服務:
-
無嚴格定義。
-
微服務是一種架構風格,將單體應用劃分爲小型的服務單元。
-
微服務架構是一種使用一系列粒度較小的服務來開發單個應用的方式;每個服務執行在自己的進程中;服務間採用輕量級的方式進行通訊(通常是HTTP API);這些服務是基於業務邏輯和範圍,通過自動化部署的機制 機製來獨立部署的,並且服務的集中管理應該是最低限度的,即每個服務可以採用不同的程式語言編寫,使用不同的數據儲存技術。
那麼微服務有哪些特性呢:
獨立執行在自己進程中。
一系列獨立服務共同構建起整個系統。
一個服務只關注自己的獨立業務。
輕量的通訊機制 機製RESTful API。
使用不同語言開發。
全自動部署機制 機製
微服務優點
-
獨立部署。不依賴其他服務,耦合性低,不用管其他服務的部署對自己的影響。
-
易於開發和維護:關注特定業務,所以業務清晰,程式碼量少,模組變的易開發、易理解、易維護。
-
啓動塊:功能少,程式碼少,所以啓動快,有需要停機維護的服務,不會長時間暫停服務。
-
區域性修改容易:只需要部署 相應的服務即可,適合敏捷開發。
-
技術棧不受限:java,node.js等
-
按需伸縮:某個服務受限,可以按需增加記憶體,cpu等。
-
職責專一。專門團隊負責專門業務,有利於團隊分工。
-
程式碼複用。不需要重複寫。底層實現通過介面方式提供。
-
便於團隊共同作業:每個團隊只需要提供API就行,定義好API後,可以並行開發。
微服務缺點
-
分佈式固有的複雜性:容錯(某個服務宕機),網路延時,呼叫關係、分佈式事務等,都會帶來複雜。
-
分佈式事務的挑戰:每個服務有自己的數據庫,有點在於不同服務可以選擇適合自身業務的數據庫。訂單用MySQL,評論用Mongodb等。目前最理想解決方案是:柔性事務的最終一致性。
-
介面調整成本高:改一個介面,呼叫方都要改。
-
測試難度提升:一個介面改變,所有呼叫方都得測。自動化測試就變的重要了。API文件的管理也尤爲重要。推薦:yapi。
-
運維要求高:需要維護 幾十 上百個服務。監控變的複雜。並且還要關注多個叢集,不像原來單體,一個應用正常執行即可。
-
重複工作:比如java的工具類可以在共用common.jar中,但在多語言下行不通,C++無法直接用java的jar包。
什麼是剛性事務?
剛性事務:遵循ACID原則,強一致性。
柔性事務:遵循BASE理論,最終一致性;與剛性事務不同,柔性事務允許一定時間內,不同節點的數據不一致,但要求最終一致。
BASE 是 Basically Available(基本可用)、Soft state(軟狀態)和 Eventually consistent (最終一致性)三個短語的縮寫。BASE理論是對CAP中AP的一個擴充套件,通過犧牲強一致性來獲得可用性,當出現故障允許部分不可用但要保證核心功能可用,允許數據在一段時間內是不一致的,但最終達到一致狀態。滿足BASE理論的事務,我們稱之爲「柔性事務」。
關於如何設計劃分服務,我覺得可以學習下DDD領域驅動設計,有很好的指導作用。
「問:AOP怎麼實現的Redis快取註解
1.定義註解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface CustomizeCache {
String key();
String value();
long expireTimes() default 120L; //預設過期時間120s
int semaphoreCount() default Integer.MAX_VALUE; //預設限制執行緒併發數
}
2.AOP切面程式設計
@Component
@Aspect
@Slf4j
public class CacheAspect {
@Autowired
private RedisTemplate redisTemplate;
@Pointcut("@annotation(com.lvshen.demo.redis.cache.CustomizeCache)")
public void cachePointcut() {
}
@Around("cachePointcut()")
public Object doCache(ProceedingJoinPoint point) {
Object value = null;
Semaphore semaphore = null;
MethodSignature signature = (MethodSignature) point.getSignature();
try {
//獲取方法上註解的類容
Method method = point.getTarget().getClass().getMethod(signature.getName(), signature.getMethod().getParameterTypes());
CustomizeCache annotation = method.getAnnotation(CustomizeCache.class);
String keyEl = annotation.key();
String prefix = annotation.value();
long expireTimes = annotation.expireTimes();
int semaphoreCount = annotation.semaphoreCount();
//解析SpringEL表達式
SpelExpressionParser parser = new SpelExpressionParser();
Expression expression = parser.parseExpression(keyEl);
StandardEvaluationContext context = new StandardEvaluationContext();
//新增參數
Object[] args = point.getArgs();
DefaultParameterNameDiscoverer discoverer = new DefaultParameterNameDiscoverer();
String[] parameterNames = discoverer.getParameterNames(method);
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i].toString());
}
//解析
String key = prefix + "::" + expression.getValue(context).toString();
//判斷快取中是否存在
value = redisTemplate.opsForValue().get(key);
if (value != null) {
log.info("從快取中讀取到值:{}", value);
return value;
}
//自定義元件,如:限流,降級。。。
//建立限流令牌
semaphore = new Semaphore(semaphoreCount);
boolean tryAcquire = semaphore.tryAcquire(3000L, TimeUnit.MILLISECONDS);
if (!tryAcquire) {
//log.info("當前執行緒【{}】獲取令牌失敗,等帶其他執行緒釋放令牌", Thread.currentThread().getName());
throw new RuntimeException(String.format("當前執行緒【%s】獲取令牌失敗,等帶其他執行緒釋放令牌", Thread.currentThread().getName()));
}
//快取不存在則執行方法
value = point.proceed();
//同步value到快取
redisTemplate.opsForValue().set(key, value, expireTimes, TimeUnit.SECONDS);
} catch (Throwable t) {
t.printStackTrace();
} finally {
if (semaphore == null) {
return value;
} else {
semaphore.release();
}
}
return value;
}
}
3.使用
@CustomizeCache(value = "member", key = "#name")
public List<Member> listByNameSelfCache(String name) {
return memberMapper.listByName(name);
}
「問:Spring Boot註解
@EnableAutoConfiguration:是自動設定的註解;
@Configuration:用於定義設定類;
@ConditionalOnBean(A.class):僅僅在當前上下文中存在A物件時,纔會範例化一個Bean;
關於Conditional開頭的註解還有很多,有興趣的可以去Spring官網:https://spring.io/projects/spring-boot
或者SpringBoot中文社羣看看:https://springboot.io/
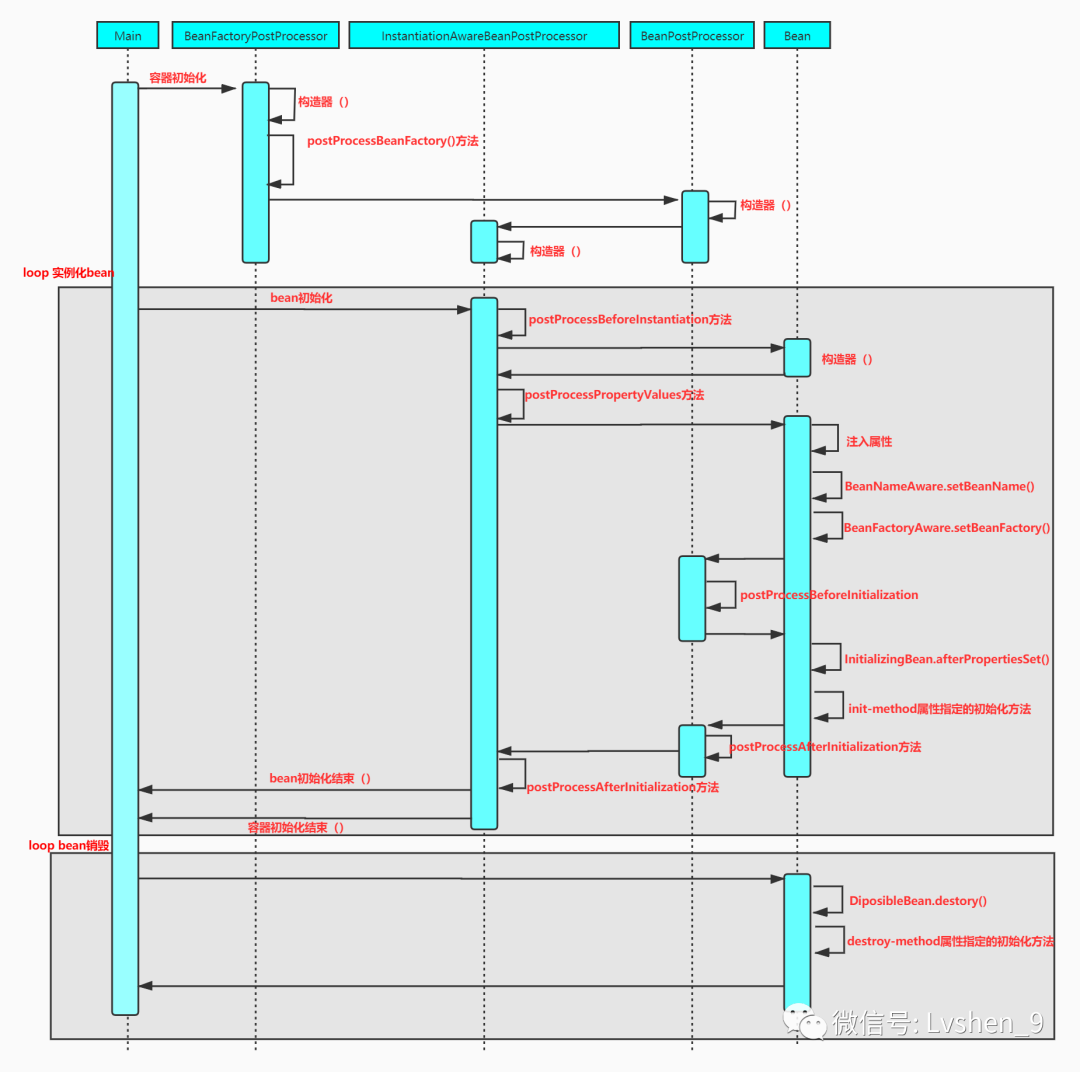
「問:Bean的生命週期
簡略的說,單列Bean生命隨容器存在而存在。非單例的Bean不參照時就會被垃圾回收器回收。
「問:AOP原理
AOP的思想是,不去動原來的程式碼,而是基於原來程式碼產生代理物件,通過代理的方法,去包裝原來的方法,就完成了對以前方法的增強。AOP的底層原理就是動態代理的實現。
關於AOP的使用,比如我之前用AOP思想做的快取註解等。
切入點:通過一個表達式告訴SpringAOP去哪個地方進行增強。也可以把這個表達式理解爲一個查詢條件,系統會根據這個查詢條件查詢到我們要進行增強的程式碼位置。
連線點:就是SpringAOP通過告訴它的切入點的位置找的的具體的要增強的程式碼的位置,這個程式碼位置就是連線點。
切面:切面由一組(增強處理和切入點)共同構成。
目標物件:目標物件就是被增強的目標類。我們也稱之爲委託類。
AOP代理:代理類就是AOP代理,裏面包含了目標物件以及一些增強處理。系統會用AOP代理類代替委託類去執行功能。
織入:織入就是將我們的增強處理增強到指定位置的過程。
具體使用可以看看問題:如何用AOP實現快取註解的程式碼。
「問:Spring的動態代理
動態代理其實就是Java中的一個方法,這個方法可以實現:動態建立一組指定的介面的實現物件(在執行時,建立實現了指定的一組介面的物件)
分爲JDK動態代理和Cglib動態代理
當目標物件實現了介面,預設使用JDK動態代理,也可以強制使用Cglib動態代理。
當目標物件沒有實現介面,必須使用Cglib動態代理。
下面 下麪是程式碼:
public interface UserService {
void addUser(String name, String password);
void delUser(String name);
}
public class UserServiceImpl implements UserService{
@Override
public void addUser(String name, String password) {
System.out.println("呼叫addUser()...");
System.out.println(String.format("參數爲:name[%s],password[%s]",name,password));
}
@Override
public void delUser(String name) {
System.out.println("呼叫delUser()");
System.out.println(String.format("參數爲:name[%s]",name));
}
}
JdkProxy
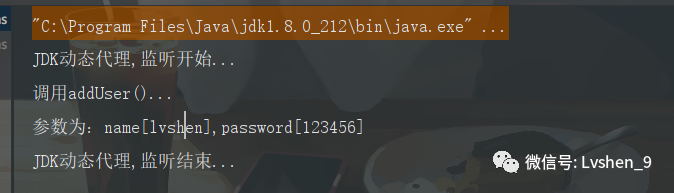
public class JdkProxy implements InvocationHandler {
//需要代理的目標物件
private Object target;
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("JDK動態代理,監聽開始...");
Object invoke = method.invoke(target, args);
System.out.println("JDK動態代理,監聽結束...");
return invoke;
}
public Object getJdkProxy(Object targetObject) {
this.target = targetObject;
//範例化
return Proxy.newProxyInstance(targetObject.getClass().getClassLoader(),targetObject.getClass().getInterfaces(),this);
}
}
測試JdKProxy
@org.junit.Test
public void testJdkProxy() {
JdkProxy jdkProxy = new JdkProxy();
UserService userService = (UserService) jdkProxy.getJdkProxy(new UserServiceImpl());
userService.addUser("lvshen","123456");
}
CglibProxy
public class CglibProxy implements MethodInterceptor {
private Object target;
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
System.out.println("CGLIB動態代理,監聽開始...");
Object invoke = method.invoke(target, objects);
System.out.println("CGLIB動態代理,監聽結束...");
return invoke;
}
public Object getCglibProxy(Object target) {
this.target = target;
Enhancer enhancer = new Enhancer();
//指定父類別
enhancer.setSuperclass(target.getClass());
enhancer.setCallback(this);
Object result = enhancer.create();
return result;
}
}
測試CglibProxy
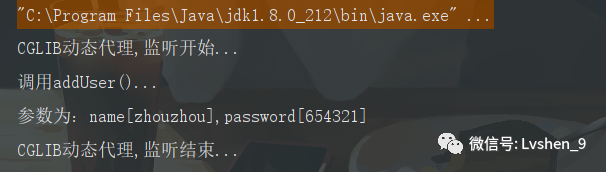
public class Test {
@org.junit.Test
public void testCglibProxy() {
CglibProxy cglibProxy = new CglibProxy();
UserService service = (UserService) cglibProxy.getCglibProxy(new UserServiceImpl());
service.addUser("zhouzhou","654321");
}
}
「問:Spring與SpringBoot的區別
SpringBoot特點:
-
用來實現微服務;
-
自動設定
-
自定義設定
-
模組化
-
獨立打包 直接執行
-
內嵌伺服器
「問:springboot中bootstrap.properties與application.properties的區別
區別:
-
application.properties(application.yml)系統級別的一些參數設定,這些參數一般是不會變動的 -
bootstrap.properties(bootstrap.yml)定義應用級別的設定
在SpringBoot 有兩種上下文:
-
bootstrap:應用程式的父上下文
-
application:應用程式上下文
bootstrap 載入優先於 applicaton
bootstrap 裏面的屬性會優先載入,預設也不能被本地相同設定覆蓋
應用場景:
-
使用 Spring Cloud Config Server時,在 bootstrap 組態檔中新增連線到設定中心的設定屬性來載入外部設定中心的設定資訊。eg:指定
spring.application.name和spring.cloud.config.server.git.uri -
一些固定的不能被覆蓋的屬性
-
一些加密/解密的場景
「問:applicationContext與beanFactory的區別
兩者都能獲取bean.
beanFactory:懶載入,呼叫getBean是才範例化物件
applicationContext:預載入,啓用applicationContext就範例化物件了
ApplicationContext 包含 BeanFactory 的所有特性,通常推薦使用前者。但是也有一些限制情形,比如移動應用記憶體消耗比較嚴苛,在那些情景中,使用更輕量級的 BeanFactory 是更合理的。然而,在大多數企業級的應用中,ApplicationContext 是你的首選。
public class HelloWorldApp {
public static void main(String[] args) {
XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource("beans.xml"));
HelloWorld obj = (HelloWorld) factory.getBean("helloWorld");
obj.getMessage();
}
}
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("beans.xml");
HelloWorld obj = (HelloWorld) context.getBean("helloWorld");
obj.getMessage();
}
MyBatis
「問:Mybatis中 #{} 與 ${}的區別
使用#{parameterName}參照參數的時候,Mybatis會把這個參數認爲是一個字串,並自動加上'',例如傳入參數是「Smith」,那麼在下面 下麪SQL中:
Select * from emp where name = #{employeeName}
使用的時候就會轉換爲:
Select * from emp where name = 'Smith';
同時使用${parameterName}的時候在下面 下麪SQL中
Select * from emp where name = ${employeeName}
就會直接轉換爲:
Select * from emp where name = Smith
簡單說**#{}是經過預編譯的,是安全的**。而**${}**是未經過預編譯的,僅僅是取變數的值,是非安全的,存在SQL隱碼攻擊。
sql注入問題:
當使用#{}時
DEBUG [http-nio-8080-exec-5] - ==> Preparing: select * from user where account = ? and password = ? DEBUG [http-nio-8080-exec-5] - ==> Parameters: 20200801(String), 111111 or account = 'admin' (String) DEBUG [http-nio-8080-exec-5] - <== Total: 0 返回結果:null
當使用${}時
DEBUG [http-nio-8080-exec-5] - ==> Preparing: select * from user where account = ? and password = ? DEBUG [http-nio-8080-exec-5] - ==> Parameters: 201301001(String), 111111 or account = 'admin' (String) DEBUG [http-nio-8080-exec-5] - <== Total: 0 轉換爲實際的SQL語句:select * from user where account = '20200801' and password = '111111 or account = 'admin''
設計模式
「問:介紹下DDD領域驅動設計,是說的什麼,裏面分爲哪些模組
這個說起來比較複雜。這種設計模式更加趨近於現實世界的狀態,要求我們寫程式碼時要區分業務程式碼與非業務程式碼。
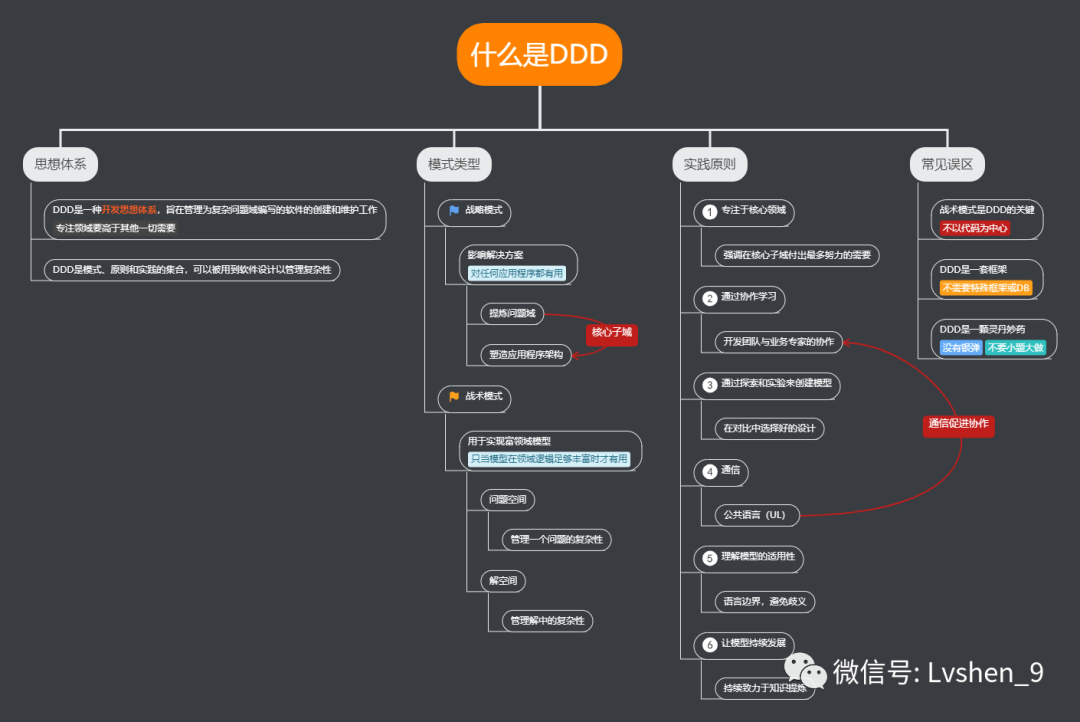
推薦文章:https://www.cnblogs.com/cuiqq/p/10961337.html
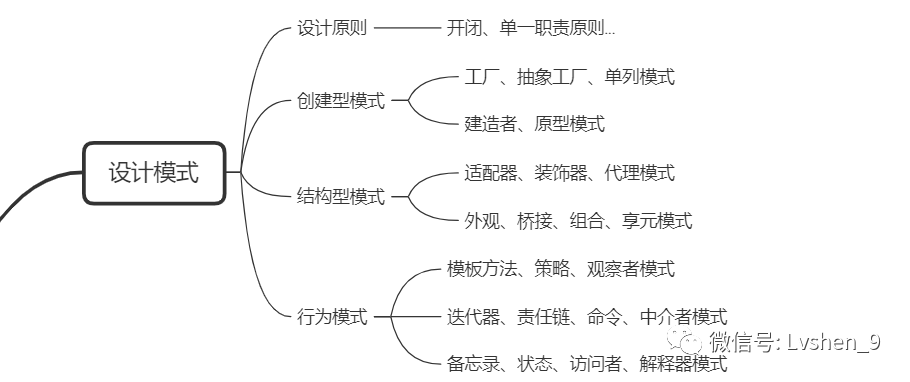
「問:設計模式分爲哪種類
「問:充血模型與貧血模型
一、貧血模型
所謂貧血模型,是指Model 中,僅包含狀態(屬性),不包含行爲(方法),採用這種設計時,需要分離出DB層,專門用於數據庫操作。
@Data
public class Employee {
public string Id ;
public string Name ;
public string Sex ;
public DateTime? BirthDay;
/// 直屬上級的Id
public string ParentId ;
}
//實現方法略
public class EmpDAO {
public static bool AddEmployee(Employee emp);
public static bool UpdateEmployee(Employee emp);
public static bool DeleteEmployee(Employee emp);
public static Employee GetEmployeeById(string Id);
}
二、充血模型
Model 中既包括狀態,又包括行爲,是最符合物件導向的設計方式。
@Data
public class Employee {
public string Id ;
public string Name ;
public string Sex ;
public DateTime;
/// 直屬上級的Id
public string ParentIdl;
private Employee _parent;
public static Employee query(string id){
Employee emp = new Employee();
//實現略,僅需填充emp的熟悉即可
return emp;
}
//儲存物件,實現略
public bool Save() {
return true;
}
// 刪除物件,實現略
public bool Drop(){
return true;
}
}
筆試題
「問:手寫單列模式
見文章:那些能讓人秀出花的單列模式
public class LazySimpleSingleton {
private static volatile LazySimpleSingleton instance = null;
private LazySimpleSingleton(){
if (instance != null) {
throw new RuntimeException("該構造方法禁止獲取");
}
}
public static LazySimpleSingleton getInstance() {
if (instance == null) {
synchronized (LazySimpleSingleton.class) {
if (instance == null) {
instance = new LazySimpleSingleton();
}
}
}
return instance;
}
}
「問:手寫氣泡排序
「問:評測題目: 三個執行緒A、B、C,實現一個程式讓執行緒A列印「A」,執行緒B列印「B」,執行緒C列印「C」, 三個執行緒輸出,回圈10次「ABC」
「問:Description:給出有序陣列(非遞減)和閉區間, 找出陣列中在區間之內的元素起始位置和結束位置
輸入:
有序陣列[1,1,2,3,4,5,5]
閉區間[-3,3]
輸出:[0,3]
解釋:在陣列中,前4個元素在區間之內,則起始位置爲0,結束位置爲3
要求:最壞情況時間複雜度小於O(n)
「問:寫一個二分查詢演算法
public static int getIndex(int[] arr, int key) {
int mid = arr.length / 2;
if (arr[mid] == key) {
return mid;
}
int start = 0;
int end = arr.length - 1;
while (start <= end) {
mid = (end - start) / 2 + start;
if (arr[mid] == key) {
return mid;
} else if (arr[mid] > key) {
end = mid - 1;
} else {
start = start + 1;
}
}
//找不到,返回-1
return -1;
}
關注公衆號:Lvshen_9 。回覆 回復"面試",獲取更多面試資料

福利:
Java進階之路的思維導圖
