JVM實現
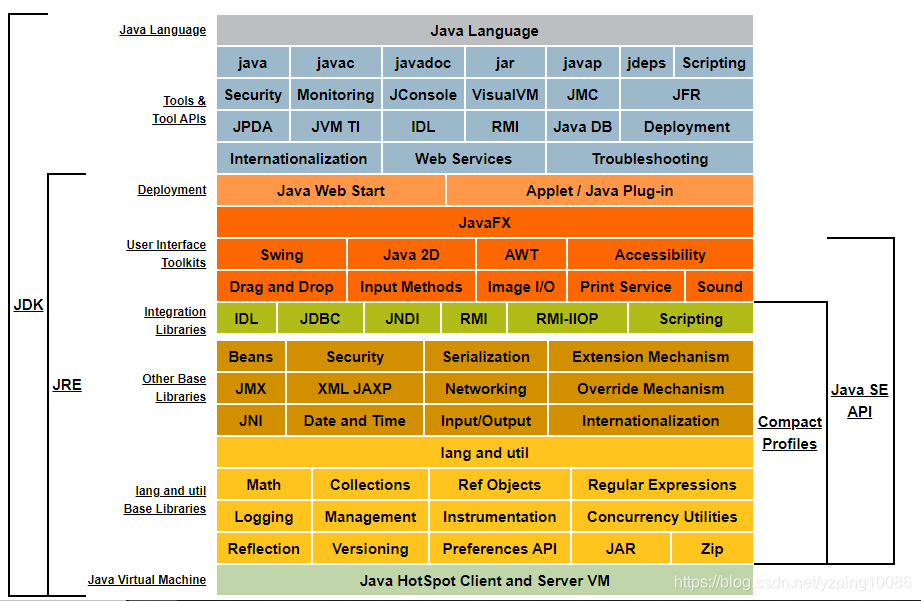
.class檔案交給JVM(類載入機制 機製)
#裝載(loading)
-
首先得找到類檔案所在位置(全路徑)
類載入器尋找類(ClassLoader.find(String name))
怎麼確保裝載的類只有一份:不同區域對應不同區域的裝載器現在需要裝載java.lang.String CustomClassLoader逐級找App ClassLoader是否已裝載 否再逐級找 Extension ClassLoader 是否已裝載 否 再逐級找Bootstrap ClassLoader是否已裝載 否 Custom ClassLoader自己裝載 ,即自己不會優先去裝載而是讓頂層 ClassLoader裝載;
即雙親委派;
怎麼不按這個模式,破壞它
複寫ClassLoader裏面的loadClass方法 -
類檔案的資訊交給JVM
.class 檔案中內容打散對應的放入JVM對應的區域
將類檔案的位元組碼流所代表的靜態儲存結構 放入JVM 某一塊區域(Method Area(方法區) 類的資訊儲存區域);
方法區被所有的執行緒所共用的一塊區域 ; -
類檔案對應的物件class交給JVM
這部分存放在堆(Heap)中|
堆也是被所有執行緒所共用的
#鏈接(Linking)
-
驗證
簡單的來說即保證被載入的類的正確性 -
準備
要爲類的靜態變數分配記憶體空間,並將其值初始化預設值
例如:
static int a = 10 預設值爲0; -
解析
將類中的符號參照轉換爲直接參照符號參照: 它是符合.class檔案格式的符號
直接參照:記憶體中某一個真實地址的指向
如:String str = 「123」 str存放在JVM中真實的地址
#初始化(Initialization)
爲靜態變數賦予真正的值 int a =10;
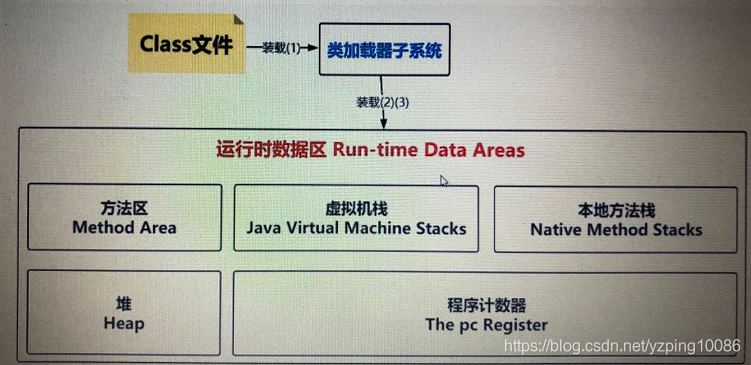
#JVM執行時的數據區
-
The pc Register 程式計數器
說明如下 -
Java Virtual Machine stacks java虛擬機器棧
棧的結構
棧簡單的理解爲:棧解決的是執行緒執行方法的表示先進後出,先進先出
表示方法的執行,Thead Stack 代表一個執行緒,每一個方法爲這個棧存放的元素,方法被執行即壓入棧中,再有一個方法又壓入棧中,執行完出棧 、
每一個java執行緒對應虛擬機器中一個棧,建立時期在每個執行緒建立的時候就會去建立
每個java虛擬機器棧中儲存的是frames(即方法的執行) -
Heap
-
Method Area
-
Run-Time Constant Pool 執行時常數池
存放在Method Area -
Native Method Stacks 本地方法棧
棧的結構
和java虛擬機器棧數據結構一樣的,只不過這裏執行的方法是C語言的程式碼
在多個執行緒同時工作時,就存在CPU的時間片的切換執行,但執行到java虛擬機器棧中某個方法程式碼塊時,由於CPU時間片的切換執行,希望下次切換回來從當前的位置繼續執行,就需要記住當時失去CPU時間片位置,所以在整個執行數據區中應該還有數據區域代表記錄每一個執行緒正在執行方法所在位置 即 The pc Register;
每一個java執行緒都有自己獨立的pc Register
#方法區
JDK 1.7 PermSpace 永久代
JDK 1.8 MetaSpace 元空間
方法區中只有一個,所有執行緒共用記憶體區域【執行緒非安全】,生命週期是跟虛擬機器一樣的;
方法區中儲存的數據: 類資訊,常數,靜態變數,即時編譯器編譯後的程式碼;
官網上: 邏輯上屬於堆的一部分,垃圾回收器不太會討論方法區的垃圾回收
#堆(Heap)
堆只有一個,執行緒共用的區域,生命週期是和虛擬機器一樣的;
堆中儲存的數據: class物件,或者陣列
#java虛擬機器棧
執行緒呼叫方法,方法壓棧,執行完出棧的過程;
一個執行緒的建立代表的是一個棧;
每個方法被當前執行緒呼叫了即代表一個棧幀
java虛擬機器棧執行方法的時候到底經歷了什麼?
對.class檔案反解析的時候 javap xxx.class 看到位元組碼指令,其實就對應了java虛擬機器棧執行過程
雖然裏面的符號看不太懂,但是整體過程是能看懂的;
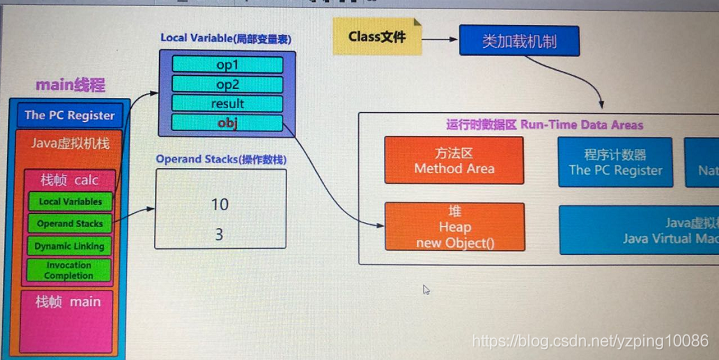
java虛擬機器棧中壓入的是frames也即是棧幀,其中包含:
- 動態鏈接 Dynamic linking
- 方法的返回值地址Invocation completion
- 區域性變數表Local Variables public void test(int a,int b) a,b
- 運算元棧 Operand Stacks a = 3, 如果需要把3賦值給區域性變數,首先把3壓入運算元棧,然後3再彈出賦值給區域性變數表,所以a = 3在反編譯後的執行是有兩句指令執行;
比如說
public static int test(int op1,int op2){ op1 = 3; int result = op1 + op2; return result }區域性變數表中按順序存放 op1, op2, result 並且數值從0開始, op1 = 3,經過javap 反編譯可以看到它其實是兩條指令,一條是先把3壓入運算元棧,然後3再彈出賦值給區域性變數表,op1+op2操作,先把3和op2壓入運算元棧,然後3和op2出棧,將3+0p2的值再壓入操縱數棧,再彈出賦值給區域性變數表中的result;
具體的每個反編譯的程式碼可以對應到oracle官網上的每個欄位的解析
方法返回值地址:
比如:
public static void main(String[] args){ calc(1,2); //繼續執行order方法 order(); }主函數,即一個主執行緒,主執行緒執行,主執行緒會對應一個棧幀,棧幀裏面會執行方法,主函數以棧幀的方式入棧,後呼叫calc(1,2),也執行剛纔相應的操作(壓棧),當它執行完成後,程式碼層面要繼續執行order()方法入棧,但是這裏怎麼知道calc(1,2)方法執行所在位置,所謂的方法返回值地址就是返回calc()方法執行到的位置,後order()方法繼續執行
動態鏈接 Dynamic linking
符號參照和直接參照在執行時進行解析和鏈接的過程,叫動態鏈接。
類比一下,在類載入機制 機製當中,類的一些元資訊,如果能夠進行解析的,它已經確定了型別的,或者它的值,它就會在類載入這個階段將它解析到方法區裏面,但是有些東西是需要在程式執行當中才能 纔能確定它的型別,舉一個例子,多型,父類別是不知道呼叫的時候是執行哪一個子類內容,這個確定只有在執行時纔會確定,所以可以簡單的理解爲程式在執行的時候某一些型別纔會確定;
棧指向堆,
private static Object obj = new Object(); //這段程式碼即方法區指向堆
那堆是否有指向方法區的時候;
new Person(); Java物件(可以確定是Person型別的物件)
再new Person(); Java物件(Person型別的物件)
這時一個疑問:怎麼知道建立物件是屬於Person型別呢?
類資訊相關的內容是存放在方法區中;當前Person應該是有一個指向方法區中Person資訊的;
怎麼證明?
每個JAVA物件應該要去維護一個東西,這個東西知道它是從哪裏來的?
JVM設計者已經設計好了,我們的java物件不僅僅只是數據這一個部分,還應該包含其他內容,比如說,當前物件屬於哪一個型別的,當前物件已經存活了多少次GC,即JAVA物件的記憶體佈局JAVA物件的記憶體佈局:
物件頭
Mark Word(一系列的標記位(雜湊碼,分代年齡,鎖狀態標記)
64位元系統: 8子節)
從物件頭可以得到當前物件存活了多少次GCClass Pointer(
指向物件對應的類元數據的記憶體地址
64位元系統:8位元組)
這個可以堆記憶體中數據指向方法區Length(
陣列物件特有
陣列長度)
範例數據
包含了物件的所有成員變數,大小由各個變數型別決定
boolean和byte: 1位元組
short和char: 1位元組
int 和float: 4位元組
long和double : 8位元組
reference: 8位元組(64位元系統)對齊填充
爲了保證物件的大小爲8位元組的整數倍從JAVA物件記憶體佈局可以得到一個物件的佔據的記憶體的大小
通過反解析
javap -c Person.class > Person.txt
#本地方法棧和程式計數器
瞭解它們是幹啥的即可,因爲一個是C語言層面的方法的呼叫,程式計數器瞭解它的功能點即可
#執行數據區【程式碼執行的狀態, JVM層面的事情】和記憶體模型【JMM(真實的物理落體的狀態) , Java層面上的事情,一般討論JMM時一般是討論執行緒安全性 】??
既然有了執行時數據區,那記憶體模型又是什麼?
#JVM記憶體模型
虛擬機器棧的生命週期是跟執行緒系結在一起的;
方法區和堆是跟java進程的生命週期系結在一起的;
在探討方法區和堆時JVM記憶體模型
JVM記憶體模型官方沒有給出它的說明;
讓我來設計記憶體分佈:分爲方法區和堆
堆中存放的物件按年齡劃分(避免垃圾回收時需要掃描堆中所有空間)
年齡:一次垃圾回收,歲數加1 , 15
垃圾回收:回收沒用的物件
老年代存放的物件特徵:
- 物件大小特別大
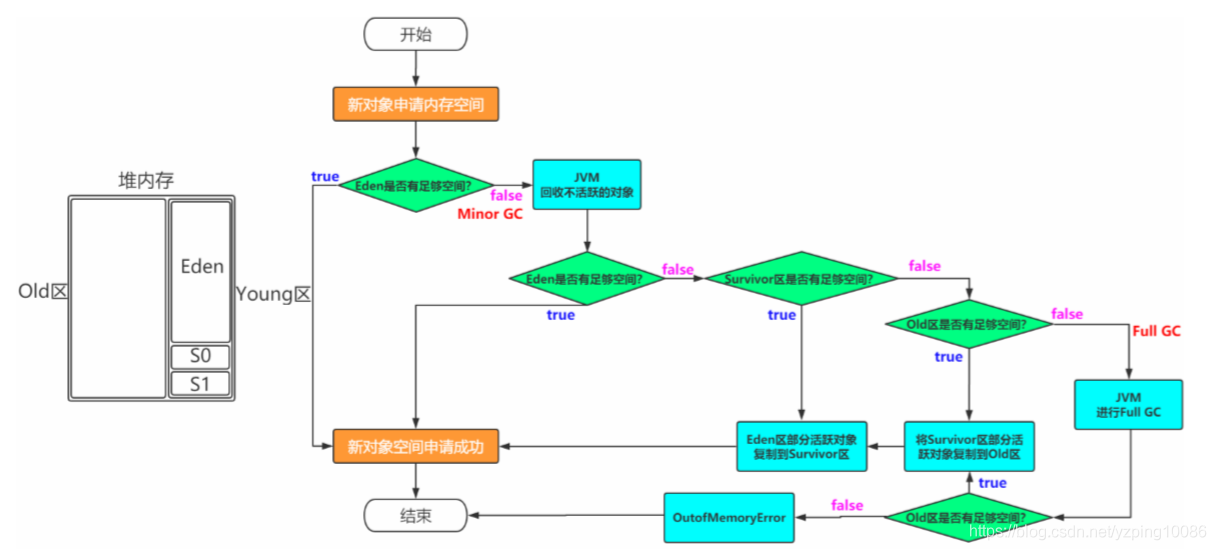
比如說老年代old區記憶體大小200M, Young區100M,現在一個物件的大小110M,Young區根本沒法放,直接分配到老年代;- 物件在Young區分配,Young區空間不夠用時必須要進行垃圾回收,回收一次,物件若沒有被回收,年齡加1,age>15,就不適合放入Young區,需要加入老年代
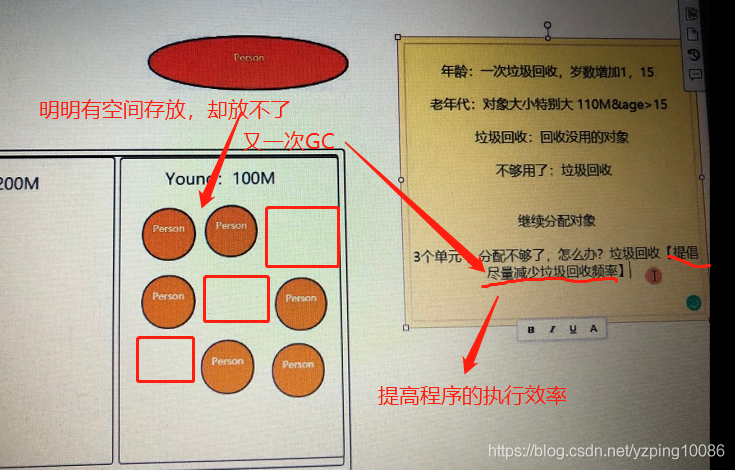
空間夠,但是物件分配不連續,導致分配失敗,即需要解決空間碎片問題;
這時對Young區再次分配
Eden區 90M,Survival區 10M
物件首先分配到Eden區(前提: 大多數物件都是朝生夕死的 ,生命週期比較短) web開發,瀏覽器一個請求過來下單,下單之後就結束了,Order物件沒有了;
GC垃圾回收之後存活的物件放入到Survival區,Eden區相對空間相對連續了,不會因爲少量存活的物件,而造成空間碎片,
下次再進行GC垃圾回收時,Survival區可能會產生空間碎片,導致存活的物件放不下

爲了使S區空間相對連續,記憶體空間再次進行優化 Eden區 80M S1【From】 10M ,S2【To】 10M
永遠保證S0或者S1區域某一塊區域爲空,這樣解決空間碎片的問題,會有10%的空間浪費
Eden : s1 : s2 = 8: 1: 1
S0/s1 空間不夠呢?11M的物件存放不下,向老年代借點空間 -> 擔保機制 機製
如果s區中物件的存活年齡大於15,放入到老年代
Java VisualVM
C:\Users\lenovo>jvisualvm
IDEA中設定記憶體空間:
VM options: 堆記憶體設定 -Xms(最小) 20M -Xmx(最大) 20M
VM options: 方法區記憶體設定: -XX: MetaspaceSize=50M -XX:MaxMetaspaceSize=50M
方法區和堆中都可能發生記憶體溢位;
VM options: java虛擬機器棧設定: -Xss 128K 設定棧的深度
棧的深度:
棧的深度設定到很大:
如果設定到不太可能stackOverflow
T1執行緒->對應 JAVA虛擬機器棧
T2執行緒-> java棧
現在設定到很大,系統資源有限意味着會影響執行緒的建立的數量,棧太大消耗的資源就越多,沒有更多的資源來建立執行緒;棧的深度設定很小:
很容易棧溢位
般說來預設的大小是512K,一般說來,Stack Space爲128K是夠用的
Young GC 【包括了Eden, S區】: Minor GC
Old GC: Major GC ,Major GC通常會伴隨着Minor GC, 也就意味着會觸發Full GC
YoungGC + Old GC : 通常稱之爲Full GC
1) 儘量減少GC頻率;
2)Full GC : STW(stop the world) ,需要儘可能的減少 Full GC 的頻率(允許一定範圍的Young GC)
S0和s1一定要保證有一塊是空的;
題外話:
垃圾回收爲什麼要減少Full GC?
實際上是爲了減少使用者執行緒程式碼停留的時間,爲什麼要減少使用者程式碼停留時間?因爲GC root掃描的時候,需要把使用者程式碼停了,因爲它沒有辦法掃描;
但是我覺得它本身設計就是一個問題,使用者程式碼能停止嗎?我覺得這時JAVA語言的弊端,java官方沒有設計好,只是它不承認,JAVA垃圾回收,它還有一個名詞:STOP the world STW, 垃圾回收時需要停止使用者程式碼的執行緒,例如在一個促銷的場景下因爲FULL GC需要停止業務程式碼,在C++裏面就不存在; 設計並沒有那麼精彩;
#JVM擴充套件
反編譯過來的位元組碼指令,誰來執行
分爲兩個維度:
- java的位元組碼指令
- 本地方法棧中呼叫native方法時誰來呼叫的? native方法庫
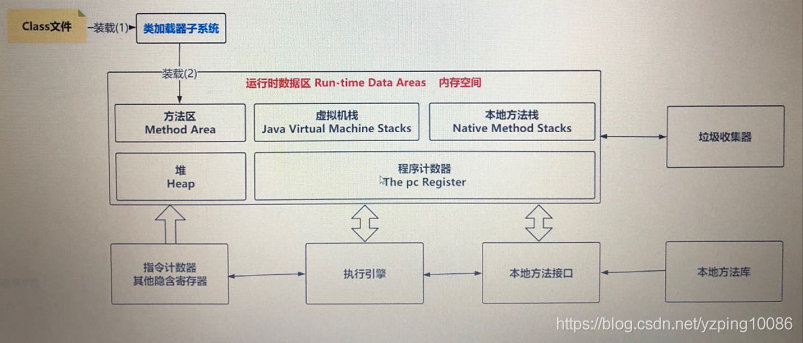
- 計數器和暫存器
- 執行引擎(執行位元組碼指令的)
- 本地方法介面(本地方法之所以可以呼叫方法庫)
學習垃圾回收,如果出問題知道如果排查;
#設計垃圾回收機制 機製
確定什麼樣的物件是垃圾?
參照計數(兩個物件相互參照對方時,這兩個物件永遠不會被回收)
可達性分析【需要選擇出一個GC root,root節點由它出發,某個物件是否可達】
什麼樣的東西可以成爲GC root???在很多資料可以看到比如:類載入器,
爲什麼它可以成爲GC root?
GC root在Java進程中要很長時間存在,存在意義
該如何回收?有對應的回收演算法
基於回收演算法的垃圾回收器
垃圾回收器的優勢和劣勢,該如何進行選型?
學會檢視垃圾回收的日誌檔案
GCRoot:
- 虛擬機器棧中本地變數表
op2【GC Root】 = 參照 - > 參照其他物件 -> 其他物件(該物件就不能稱爲垃圾),在這條鏈路中的所有物件都不能稱爲垃圾
-
static 成員
存在於方法區中,它會很長一段時間存在於方法區裏面,
-
常數參照
-
本地方法棧中的變數
-
類載入器
它的存在的角色,在整個虛擬機器當中充當的角色ClassLoader去進行載入類的,它的生命週期相對來說比較長;它會一直存在JVM虛擬機器裏面; -
Thread
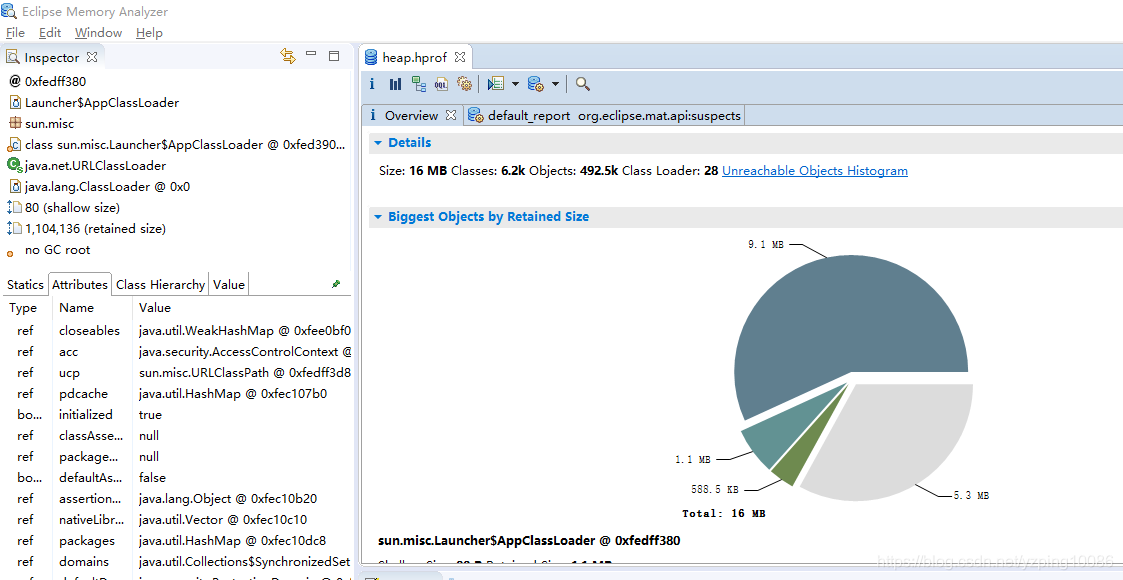
成爲GC root會有很多,可以把當前java進程中的內容 導出 -> heap.檔案
java進程中堆的物件的內容
每個物件都是可以去檢視它的GC root
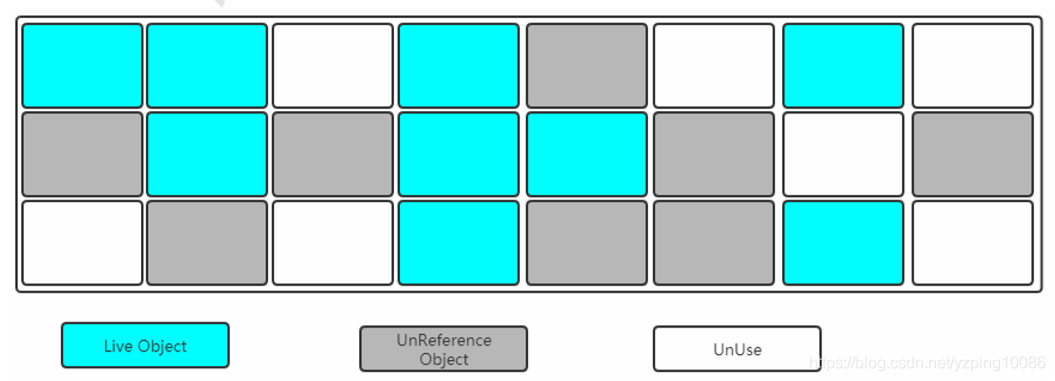
#回收演算法
-
標記和清除
標記:
清除:
-
缺點:
- 產生空間碎片,空間不連續,可能下一次存放的又得GC;
- 標記和清除都比較耗時,效率比較低;
-
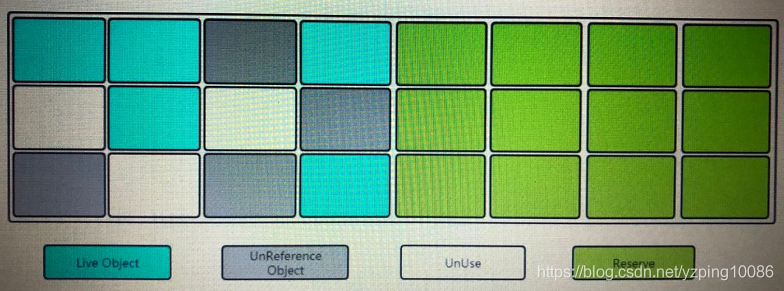
複製演算法
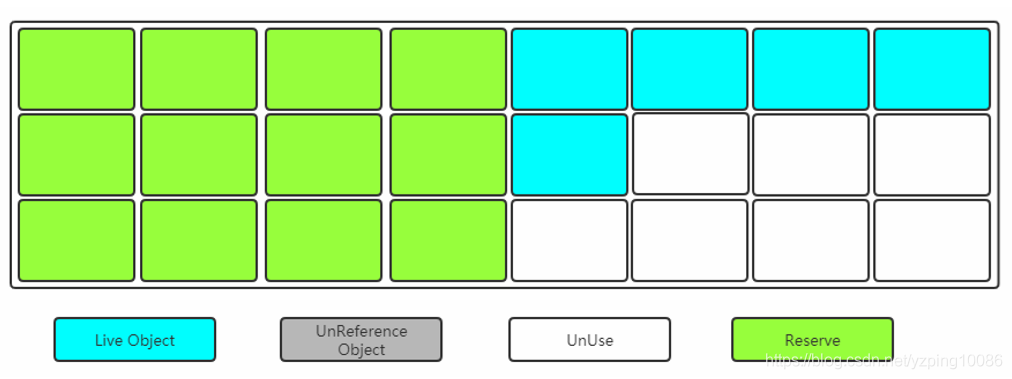
-
缺點:
空間利用率降低;優點:
空間連續 -
標記-整理演算法
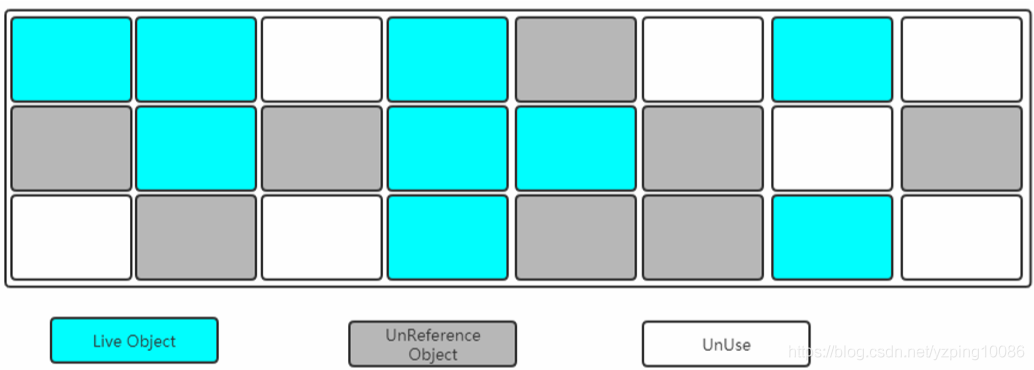
把垃圾回收演算法落地–> 垃圾收集器
垃圾收集器還需要適合不同的代【分代】
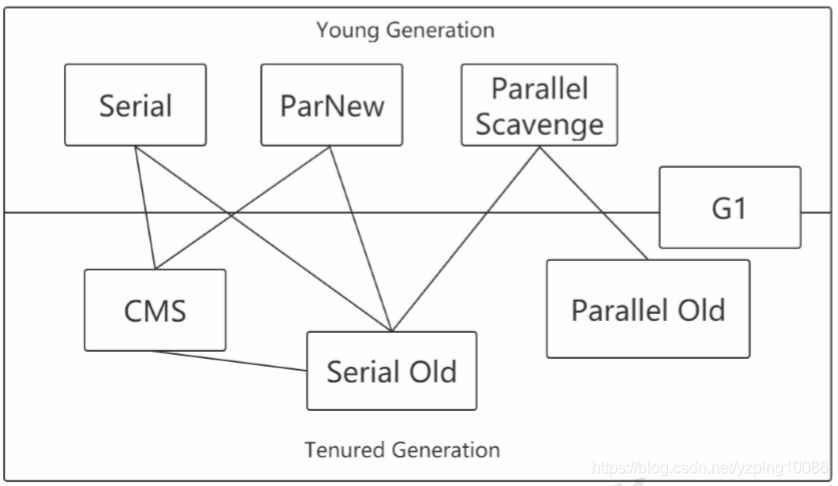
按照新生代和老年代進行了劃分
垃圾回收考慮的維度:
- 執行緒是單執行緒/多執行緒
- 採用什麼演算法去實現的
- 使用的範圍是哪個代
- 優缺點
新生代: 複製演算法(複製也是需要存本的,複製演算法只能允許你只有少量的物件存活)
對應垃圾收集器:到底用的是什麼樣的垃圾回收演算法;
ParNew 約等於 Parallel Scavenge ,後者更關注於吞吐量
吞吐量= 使用者業務程式碼執行的時間/(業務程式碼執行的時間+垃圾收集的時間)
吞吐量越大,垃圾收集的時間就越短;
使用者程式碼就可以充分利用CPU資源,儘快去完成任務
**老年代:**標記-整理,或者標記清除演算法
老年代大多數物件都是存活的,生命週期很長,用複製演算法顯然不合適,用標記-整理,或者標記清除演算法都是可以的;
CMS收集器: Concurrent Mark Sweep 併發類的垃圾收集器【使用者執行緒和垃圾回收執行緒可以同時進行】
它比較關注的停頓時間,降低了對吞吐量的要求
-XX:+UseConcMarkSweepGC
G1 JDK1.9 預設的
根據region篩選回收,通過設定它的停頓時間,和CMS很像主要區別它是篩選回收,
評價一個垃圾回收器的好壞:吞吐量+停頓時間+GC次數
JVM調優:
2個維度:
GC收集器: 停頓時間和吞吐量
在滿足停頓時間低情況下儘可能的提升吞吐量停頓時間:垃圾收集器進行垃圾回收終端執行相應的時間;-> 很好的使用者體驗->適用於和使用者互動比較多的場景;G1可以有選擇器性的設定停頓時間;CMS 20ms和G1[set pause time 15ms]停頓時間少使用web運用
併發類的收集器吞吐量:執行使用者程式碼時間/ 執行使用者程式碼時間+ 垃圾收集時間,它適合於使用者程式碼執行佔用CPU資源的時間比較大,運算任務,不需要跟使用者互動太多;
比如說:parallel Scanvent + Parallel Old
並行類的收集器停頓時間是要追求的, JDK11中有新的垃圾回收器追求到10ms
記憶體使用的維度
檢視當前進程:
C:\Users\lenovo>jps -l
檢視當前是否用了G1
C:\Users\lenovo>jinfo -flag UseG1GC +進程號
-XX:-UseG1GC //’-'號表示沒有使用
JDK1.8 用的是ParallelGC
C:\Users\lenovo>jinfo -flag UseParallelGC 16104
-XX:+UseParallelGC
垃圾回收器設定
1) 序列
-XX: +UseSerialGC
-XX: +UseSerialoldGC
2) 並行(吞吐量優先)
-XX: +UseParallelGC
-XX: +UseParalleloldGC
3) 併發收集器(響應時間優先)
-XX: +UseConcMarkSweepGC
-XX: +UseG1GC
#JVM參數
-
標準參數: 不會隨着JDK版本的變化而變化
java -version/-help -
-X參數
非標準參數:JDK版本而變動(用的不多) -
-XX參數
a-Boolean型別的
-XX:[+/-]name 啓動或者停止b-非Boolean型別
-XX:name=value
-XX:MaxHeapSize=100M -
其他參數[-XX參數]
-Xms100M ==> -XX:InitialHeapSize=100M
-Xmx100M ==> -XX:MaxHeapSize=100M
-Xss100s ==> -XX:ThreadStackSize=100k
#展示JVM所有的參數
VM options: -XX:+PrintFlagsFinal
或者:
PS C:\Users\lenovo> java -XX:+PrintFlagsFinal -version
檢視某一個 jinfo :不僅可以檢視某一個,而且可以修改
參數知道後怎麼修改
- IDEA中 設定 VM options:
- java -XX:+UseG1GC xxx.jar’
- Tomcat -----bin------xxxx.sh/catalina.sh ---->JVM參數修改
- 實時修改 jinfo修改
常用參數
| 參數 | 含義 | 說明 |
|---|---|---|
| -XX:CICompilerCount=3 | 最大並行編譯數 | 如果設定大於1,雖然編譯速度會提高,但是同樣影響系統穩定性,會增加JVM崩潰的可能 |
| -XX:InitialHeapSize=100M | 初始化堆大小 | 簡寫-Xms100M |
| -XX:MaxHeapSize=100M | 最大堆大小 | 簡寫-Xmx100M |
| -XX:NewSize=20M | 設定年輕代的大小 | |
| -XX:MaxNewSize=50M | 年輕代最大大小 | |
| -XX:OldSize=50M | 設定老年代大小 | |
| -XX:MetaspaceSize=50M | 設定方法區大小 | |
| -XX:MaxMetaspaceSize=50M | 方法區最大大小 | |
| -XX:+UseParallelGC | 使用UseParallelGC | 新生代,吞吐量優先 |
| -XX:+UseParallelOldGC | 使用UseParallelOldGC | 老年代,吞吐量優先 |
| -XX:+UseConcMarkSweepGC | 使用CMS | 老年代,停頓時間優先 |
| -XX:+UseG1GC | 使用G1GC | 新生代,老年代,停頓時間優先 |
| -XX:NewRatio | 新老生代的比值 | 比如-XX:Ratio=4,則表示新生代:老年代=1:4,也就是新 生代佔整個堆記憶體的1/5 |
| -XX:SurvivorRatio | 兩個S區和Eden區的比值 | 比如-XX:SurvivorRatio=8,也就是(S0+S1):Eden=2:8, 也就是一個S佔整個新生代的1/10 |
| -XX:+HeapDumpOnOutOfMemoryError | 啓動堆記憶體溢位列印 | 當JVM堆記憶體發生溢位時,也就是OOM,自動生成dump 檔案 |
| -XX:HeapDumpPath=heap.hprof | 指定堆記憶體溢位列印目錄 | 表示在當前目錄生成一個heap.hprof檔案 |
| XX:+PrintGCDetails XX:+PrintGCTimeStamps XX:+PrintGCDateStamps Xloggc:$CATALINA_HOME/logs/gc.log | 列印出GC日誌 | 可以使用不同的垃圾收集器,對比檢視GC情況 |
| -Xss128k | 設定每個執行緒的堆疊大小 | 經驗值是3000-5000最佳 |
| -XX:MaxTenuringThreshold=6 | 提升年老代的最大臨界值 | 預設值爲 15 |
| -XX:InitiatingHeapOccupancyPercent | 啓動併發GC週期時堆記憶體使用佔比 | G1之類的垃圾收集器用它來觸發併發GC週期,基於整個堆 的使用率,而不只是某一代記憶體的使用比. 值爲 0 則表 示」一直執行GC回圈」. 預設值爲 45. |
| -XX:G1HeapWastePercent | 允許的浪費堆空間的佔比 | 預設是10%,如果併發標記可回收的空間小於10%,則不 會觸發MixedGC。 |
| -XX:MaxGCPauseMillis=200ms | G1最大停頓時間 | 暫停時間不能太小,太小的話就會導致出現G1跟不上垃 圾產生的速度。最終退化成Full GC。所以對這個參數的 調優是一個持續的過程,逐步調整到最佳狀態。 |
| -XX:ConcGCThreads=n | 併發垃圾收集器使用的執行緒數量 | 預設值隨JVM執行的平臺不同而不同 |
| -XX:G1MixedGCLiveThresholdPercent=65 | 混合垃圾回收週期中要包括的舊區域設定 佔用率閾值 | 預設佔用率爲65% |
| -XX:G1MixedGCCountTarget=8 | 設定標記週期完成後,對存活數據上限爲 G1MixedGCLIveThresholdPercent 的舊 區域執行混合垃圾回收的目標次數 | 預設8次混合垃圾回收,混合回收的目標是要控制在此目 標次數以內 |
| -XX:G1OldCSetRegionThresholdPercent=1 | 描述Mixed GC時,Old Region被加入到 CSet中 | 預設情況下,G1只把10%的Old Region加入到CSet中 |
#命令
-
jps: 檢視當前java進程的
-
jinfo : 檢視或者修改JVM參數
例如檢視
jinfo -flag UseG1GC PID //檢視是否是G1垃圾回收器
jinfo -flag MaxHeapSize PID //檢視最大堆記憶體大小
實時修改某個進程中的JVM參數的值: jinfo -flag name=value PID[條件]
並不是所有的參數值都可以修改,得是{manageable纔可以修改} -
jstat
//檢視進程PID,檢視類的資訊, 每一秒鐘,輸出10次
jstat -class PID 1000 10//檢視進程PID ,檢視GC資訊
jstat -gc PID 1000 10 -
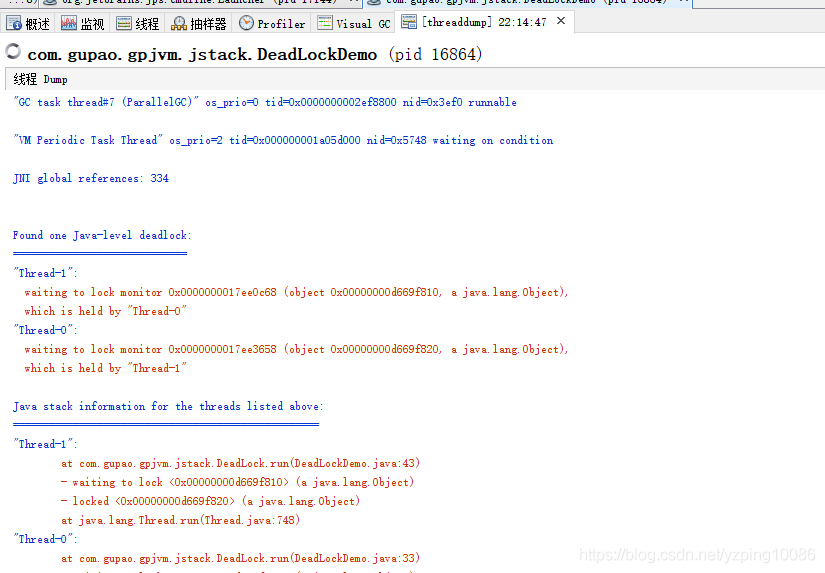
jstack: 檢視執行緒堆疊資訊
jstack PID //檢視當前進程,執行緒資訊;
作用:如果執行緒發生問題了,方便排查
比如:java中出現死鎖; -
jmap:生成堆記憶體快照
jps
jmap -heap PID
檢視堆記憶體資訊的意義:
例如在生產環境發生OOM(OutOfMemory) —>在發生OOM的時候,能夠把堆記憶體中的資訊導出來,
檢視是什麼樣的物件佔用記憶體空間比較大,排查作用
dump檔案:
jmap -dump:format=b,file=heap.hprof PID
在發生OOM的時候自動dump
設定:
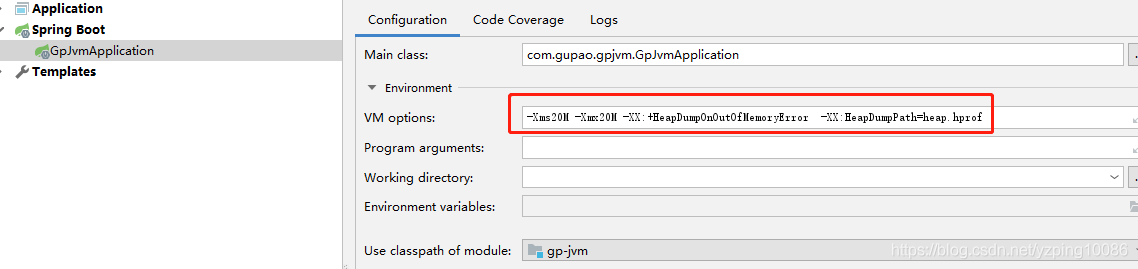
VM options中設定如下:
-Xms20M -Xmx20M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap.hprof
#工具
-
jconsole
JDK自帶的視覺化的工具,可以檢視當前JAVA執行緒執行情況;
MBean中展示了java中所有的bean的情況 -
jvisualvm
它的功能跟jconsole是有重複的,只不過有些它做的好些,有些jconsole做的好些
預設情況下是沒有Visual GC,->工具->外掛
進入Linux tomcat 的bin目錄下設定
#vim catalina.sh
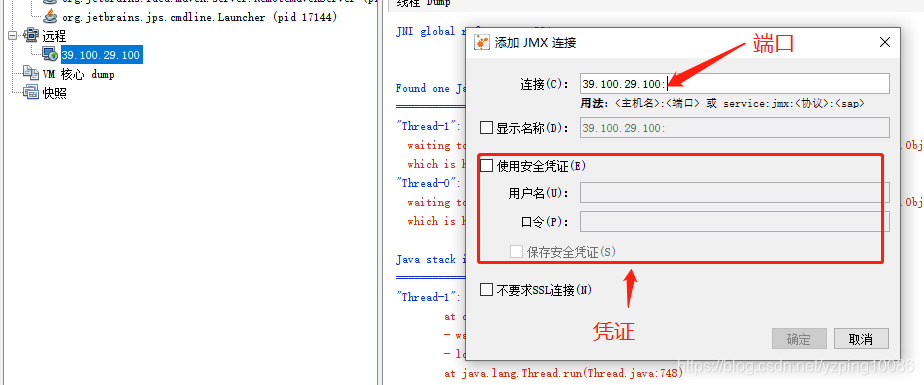
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote Djava.rmi.server.hostname=31.100.39.63 -Dcom.sun.management.jmxremote.port=8998 -Dcom.sun.management.jmxremote.ssl=false Dcom.sun.management.jmxremote.authenticate=true Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.access Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password"31.100.39.63: 阿裡雲的公網的IP地址
8998:用戶端進行連線的埠號
access.file/ password.file 設定使用者名稱和密碼#cd conf
新建了兩個檔案:jmxremote.access / jmxremote.password
cat jmxremote.accessguest readonly
manager readwritecat jmxremote.password
guest guest
manager manager給這兩個檔案賦予許可權:
chmod 600 ****
還有就是連線伺服器的內網和公網IP進行對映conf# hostname -i
172.26.225.240 … 內網的IP地址
conf # vim /ect/hosts172.26.225.240 39.100.39.63
conf# lsof -i:8080 //檢視當前tomcat是否監聽的是8080埠
conf# lsof -i:8998 //是遠端連線要用的埠號
//防火牆設定,埠可能被防火牆攔截了
conf # systemctl status firewalld //檢視防火牆是否已開啓
-
jmc (java manager controller)
-
arthas:(阿裡的)
Quick start:
curl -O https://alibaba.github.io/arthas/arthas-boot.jar
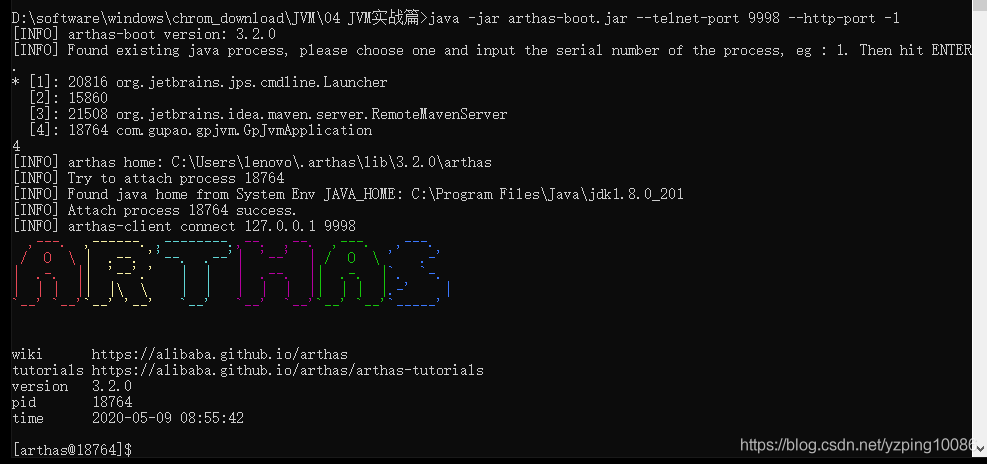
java -jar arthas-boot.jar
-
命令:dashboard //檢視執行緒,堆相關資訊
help // 檢視可以用哪些命令
seesion //檢視當前是跟哪個進程在互動
thread //檢視當前執行緒的資訊
#JVM調優的維度:
- 堆記憶體:堆記憶體使用的情況;
- 垃圾回收:
生產環境裏面更多的是考慮這個指標;
比如說,堆記憶體溢位OOM,排查哪個物件佔的記憶體比較多,根據OOM時產生的heap檔案;
上述的工具的檢視的東西有點界限,不夠強大
#強大的工具
-
MAT
支援在eclipse當中去安裝
也支援單獨的執行方式去安裝
通過這個工具去開啓heap檔案public class StackOverFlowDemo { public static long count=0; public static void method(long i){ System.out.println(count++); method(i); } public static void main(String[] args) { method(1); } }
//例舉出當前類的範例:
再例如:
@RestController
public class HeapController {
List<Person> list=new ArrayList<Person>();
@GetMapping("/heap")
public String heap() throws Exception{
while(true){
list.add(new Person());
// Thread.sleep(1);
}
}
}
-Xms20M -Xmx20M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap.hprof
1.例舉出當前類的範例
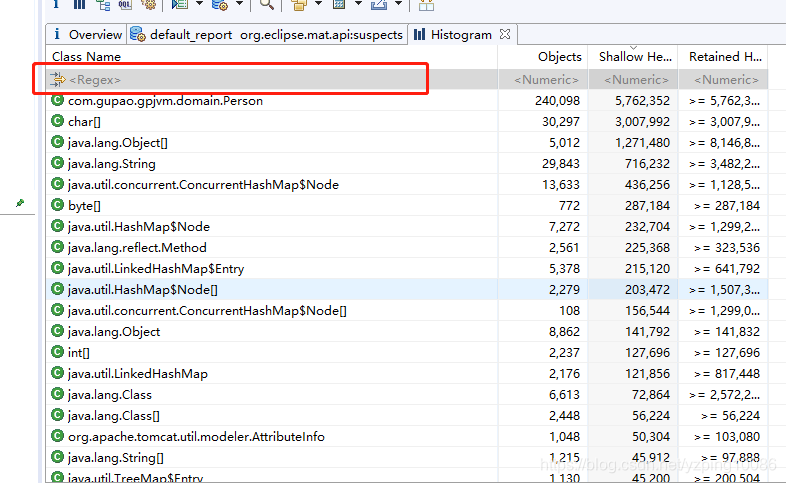
2.利用正則查詢匹配的類
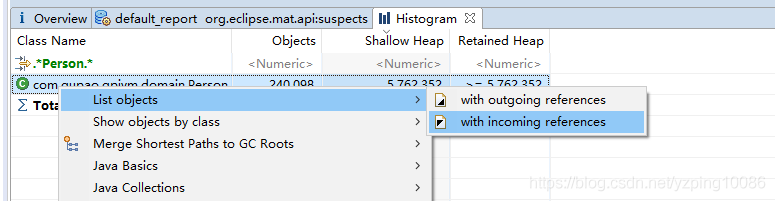
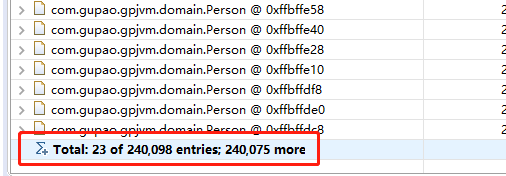
3.檢視當前物件建立了多少個物件
檢視當前物件GC root ,可達性分析,這個物件爲什麼沒有被回收,因爲存在它的GC root
果然查到了
上述是在知道哪個類出現了死回圈,那生產環境是不知道的,那怎麼解決??
//記憶體漏失可能的原因:
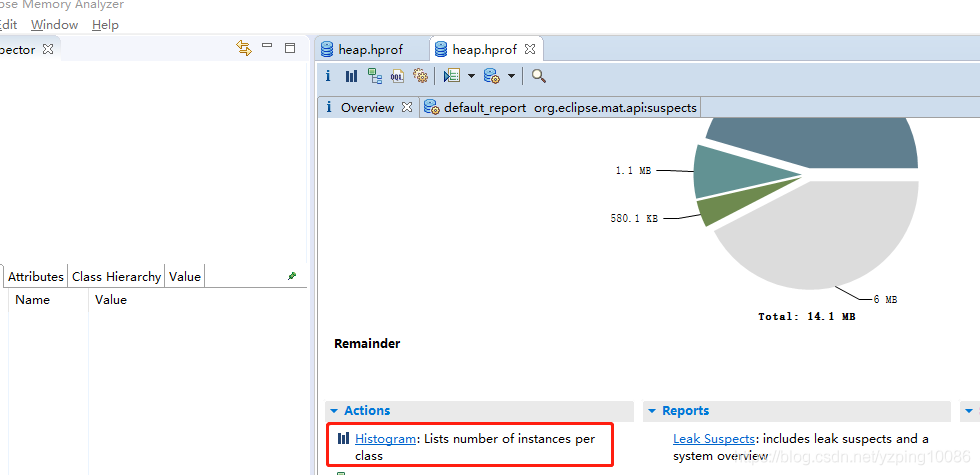
如上圖可以清楚的看到哪個類導致了問題的產生,佔用了 56.83%的記憶體
具體的原因:



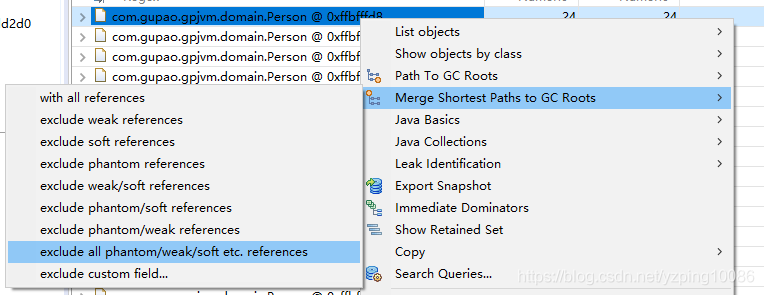

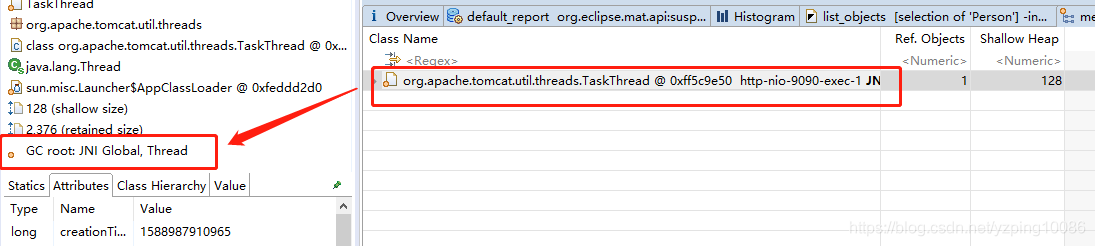
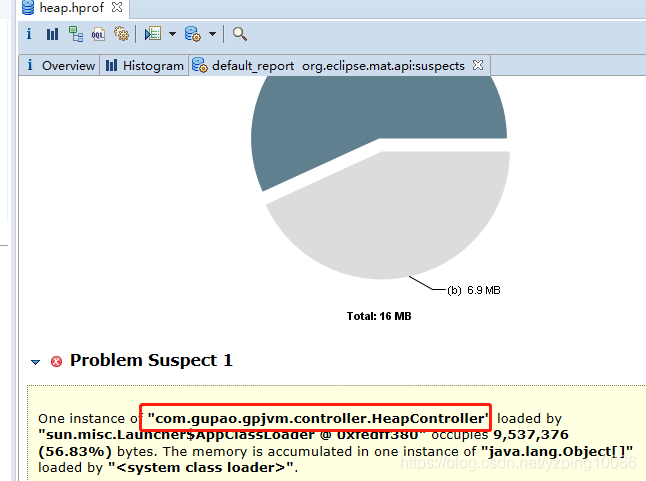
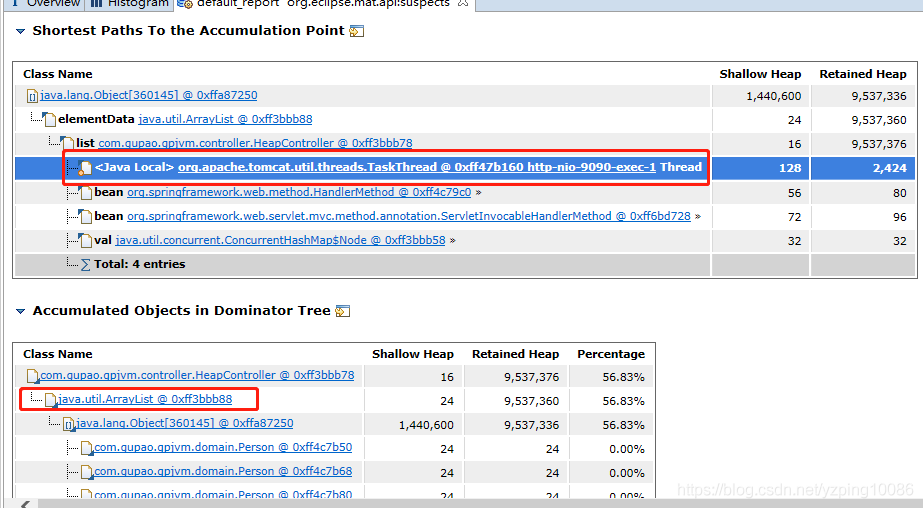
-
基於此,如果有一個工具能線上的分析堆記憶體??
不要輕易去用,會有安全性的問題
如下 -
PerfMa(瞭解)
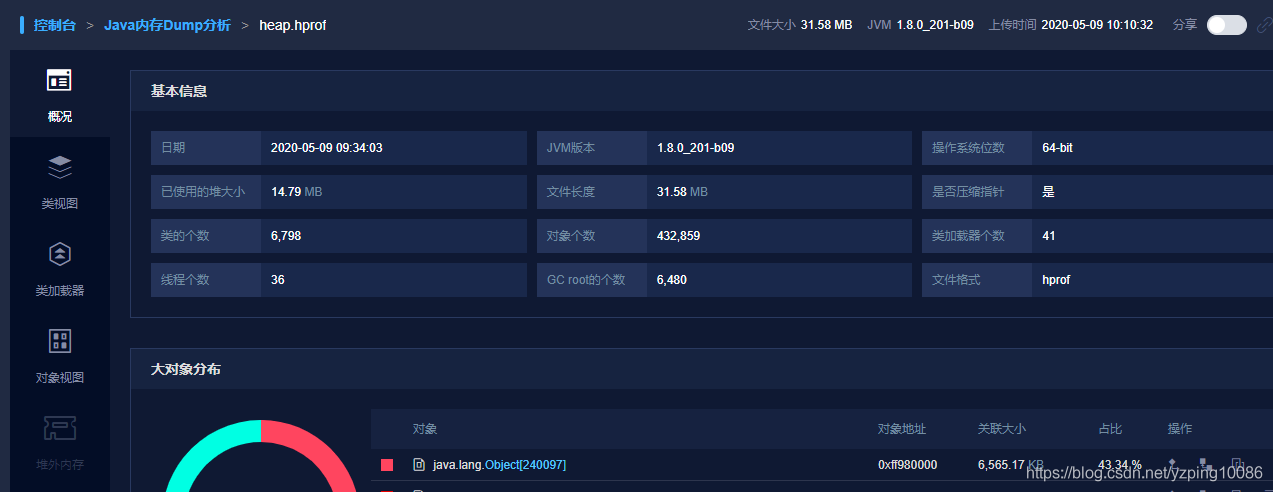
體驗:
社羣->討論區->選擇話題 JAVA記憶體Dump分析->選擇產品體驗地址->選擇本地上傳->上傳原生的heap.hprof
#談論 垃圾回收 GC日誌
衡量指標: 吞吐量 ,停頓時間
設定
VM options
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:gc.log
用gcviewer-1.36-SNAPSHOT.jar對gc.log進行分析
當前GC的次數

停頓時間GC pauses:
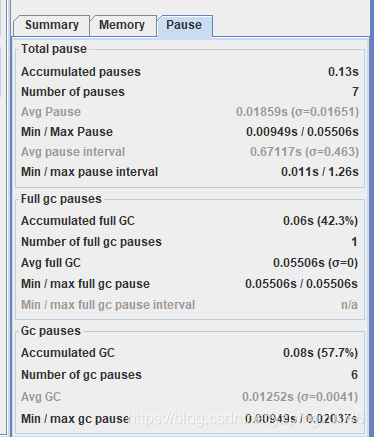
以及吞吐量Throughout
線上分析GC日誌???
-
gceasy
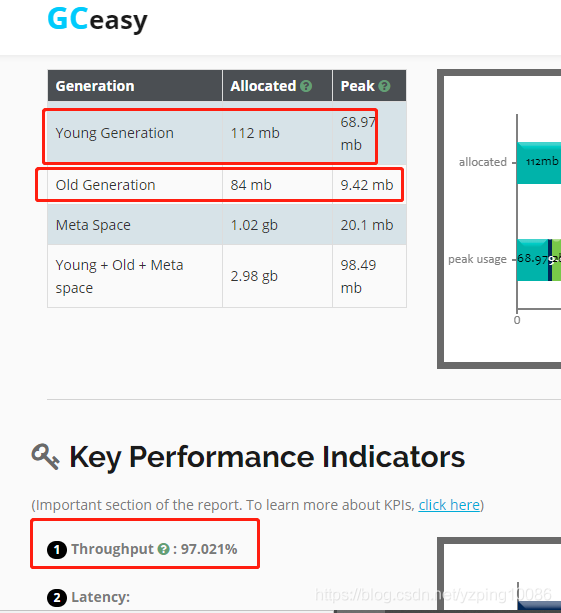
最佳做法
不斷的選擇垃圾回收器,然後觀察吞吐量和停頓時間的最佳值JVM調優,是建立在JVM參數,和一些工具的使用基礎之上的;
垃圾收集器發生的時機是什麼時候?
Minor GC ,Major GC , Full GC = Minor GC + Major GC+ MetaSpace GC
1) Minor GC 通常是Eden區或者S區不夠用了,會觸發一次Minor GC
2) 老年代空間不夠用了 會觸發Major GC 通常伴隨着Minor GC
- 方法區空間b不夠用
4) System.gc() -----> 手動呼叫(但是這個gc()方法的解釋中可以看出它只是發出信號或者是指令,也就是說它什麼時候區進行垃圾的收集是由JVM虛擬機器決定的)
改爲使用cms 垃圾回收器
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseConcMarkSweepGC -Xloggc:cms-gc.log
改用爲G1垃圾收集器
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseG1GC -Xloggc:g1-gc.log
生成的g1-gc.log檔案中包含大量的參數,需要看懂可以看oracle官網:https://blogs.oracle.com/poonam/understanding-g1-gc-logs
裏面包含了mixed GC = Young區+ old區,因爲它不在是物理上的Young區和Old區,分爲邏輯上的;
它不會說爲FULL GC 而是 mixed GC
當堆記憶體使用率達到45%以上時會產生併發標記
JVM調優場景:
- CPU飆升太快;
- 記憶體空間不夠用;
- gc次數太多; (更多的暫停使用者程式碼的時間,搶奪CPU資源)執行緒使用者程式碼執行受影響;CPU使用率會高;
最佳:儘可能的提升吞吐量(吞吐量大使用者程式碼搶奪CPU時間比較多), 減少停頓時間(給使用者反應比較迅速)
G1 能夠設定停頓時間可控(因爲它有選擇性的篩選回收) 15ms —> 怎樣取得吞吐量的最佳值?
Throughput min pause max pause Avg pause GC次數
93.3% 0.00023s 0.11044s 0.0104s 19
1)堆的大小不夠用了?乾脆我就調正下堆的大小,看這邊參數的變化?設定堆記憶體大小爲500M
-Xms500M -Xmx500M -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseG1GC -Xloggc:g1-gc.log
Throughput min pause max pause Avg pause GC次數
93.3% 0.00023s 0.11044s 0.0104s 19
96.78% 0.01712s 2
好的方向發展:吞吐量增加+ GC次數減少
不好的方向:停頓時間變大 原因是堆記憶體變大每次存放的垃圾物件也就變大了;週期就會拉長; 17ms
2)G1 可以設定停頓時間 -XX:MaxGCPauseMillis=15 15ms(停頓時間不要太嚴格)(它會自動的去調整young區大小,來滿足這個停頓時間,所以不建議手動的設定Young區(大小) ) 停頓時間不要太嚴格以減少GC的次數
-Xms500M -Xmx500M -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseG1GC -XX:MaxGCPauseMillis=15 -Xloggc:g1-gc.log
Throughput min pause max pause Avg pause GC次數
93.3% 0.00023s 0.11044s 0.0104s 19
96.78% 0.01712s 2
96.01% 0.009s 12
分析:
優勢:果然停頓時間可以被我們所控制了,
劣勢: GC次數增加 ???
標記沒有標記完, 只有下一次回收,GC的次數就增加了;
3)啓動併發GC時設定堆記憶體使用佔比多少時觸發GC
堆記憶體使用的比例,以觸發併發的週期
jinfo -flag InitiatingHeapOccupancyPercent PID
預設是45%
-XX:InitiatingHeapOccupancyPercent=50
Oracle官方關於G1 有一個Recommendations(一些建議)來設定JVM參數
G1和CMS的區別在哪?
-
CMS : 標記—清除 空間碎片
G1: 標記—整理 減少空間碎片
-
CMS:堆記憶體空間是eden區,S區,Old區 空間連續,G1 採用把堆記憶體劃分爲一個個Region,可以標記爲S區,Old區,H(大物件區)
-
1 收集方式採用了Garbage First,優先收集垃圾比較多的區域;
-
1 CMS:假如需要去毁一個物件,是在新生代或者老年代;從老年代開始掃描新生代需要走很長的路徑,或者說從新生代GC Root開始到老年代也需要掃描很長的路徑,這樣的一個路徑在CMS裏面採用的一種方式
card Table 記錄到底參照了誰,這樣就不需要全盤掃描老年代
G1:這個在G1中採用了Rset ,和card Table是差不多的思想,誰參照了我,它是反向的
-
-
G1設計的初衷
要求CPU是多核 ,大記憶體 6G以上
G1的停頓時間
Cset: 一組被回收的分割區的集合
即存活物件移動到另外分割區 Cset 佔用堆記憶體 小於等於1%空間
#高併發場景之下如何進行調優?
伺服器的採購 JVM 參數 記憶體設定多大合適
3000單/秒 (通過中介軟體,nginx等過來的流量) 峯值
三臺伺服器
每個伺服器1000單/秒
JVM 參數 記憶體設定多大合適
4000MB
每筆訂單會產生一個Order物件,物件頭,範例數據 Order物件【2KB已經很大了】
2KB*1000=2000KB,每秒鐘就要去產生2000KB的物件大小,這個還不能算是它的最大值,它還會呼叫其他服務
2000KB x 20 = 40000KB = 40MB,即一秒鐘會消耗40M的記憶體空間;如果把我的機器的記憶體大小設定爲4000MB空間,即新生代和老年代比例= 1333MB:26666MB -> eden區 1000MB
1000MB/40MB = 25秒鐘的時間 將整個Eden區填充滿
26秒鐘會觸發一次minor GC 還能存活的移動到S區,隨着物件的年齡的增長放入老年區,老年代越來越多的物件,觸發Full GC,
優化的思路:
如果減少頻繁的Full GC,
- 適當的將young區的大小增大些 Eden 區 2000MB
#JVM效能優化?
重新思考這個問題? 什麼是JVM的效能優化? 站在我們的角度該如何進行優化?
優化的前提》有問題》現像展示出來
-
GC的次數頻繁,你會怎麼辦?
反問,爲什麼你知道頻繁?GC次數多了,CPU佔用率高了
專業:列印出GC日誌-》到底是minor gc / major gc次數頻繁,結合工具看下
1)適當增加堆記憶體空間 2) 選擇垃圾收集器不合適
若是大記憶體空間,可以選擇G1 3) set pause time 太多於嚴格了(設定時間太短,很多物件沒有被標記,選擇篩選回收時很多物件沒有被回收掉)/堆記憶體使用率 不是45%
-
CPU持續飆升
專業: top 看下 定位哪個進程佔用率最高
檢視執行緒使用的情況jstack
檢視下JVM參數jinfo
檢視下堆記憶體jmap
解決:1)執行緒開銷太大了,可能應用使用者併發量太大了,是本質的併發量高還是沒有去做非同步的處理;
1.1叢集 —》 讓併發打到不同的機器上
1.2 MQ
1.3 業務程式碼層面會不會有死鎖的情況 -
OOM
反問:爲什麼?因爲看了Dump檔案,日誌-》分析dump檔案-》 MAT/或者其他工具
-
記憶體泄露和記憶體溢位OOM有區別嗎 ?
記憶體漏失:是指一些物件沒有辦法及時回收,一直持續的佔用記憶體空間,由於記憶體漏失不斷的累積會導致記憶體的溢位;
-
方法區中主要回收的是什麼內容?
反問:方法區中儲存的內容是什麼? 類資訊,靜態變數,常數等
沒有用的類的資訊,常數
類的資訊什麼時候被回收?
1)類的資訊對應的物件存放在堆當中,那麼當堆中不在有該物件了2)載入這個類的ClassLoader已經被回收了
ClassLoader是可以作爲GC Root的
3)java.lang.class物件也不在有任何地方參照了;可以回收了 --> 也不是一定
-
什麼樣的物件可以稱之爲垃圾物件
不可達的物件,
不可達的物件一定就要被回收嗎?標記有像G1中初始標記,併發標記,重新標記,
只有被重新標記後物件才能 纔能被回收
不可達的物件------> finalize()----》變成不是垃圾的物件 -
Young GC 會有stop the world嗎?
反問什麼是Young GC --> 新生代的GC -----》有沒有暫停使用者程式碼的?
像新生代的垃圾回收器都是有暫停使用者程式碼的只不過是停頓的時間不一樣