深度學習(機器學習)知識總結
目錄
1. Python概述
發展歷程

Python is a programming language that lets you work quickly and integrate systems more effectively.
- Python是一門解釋型、物件導向的高階程式語言
- Python是開源免費的、支援互動式、可跨平臺移植的指令碼語言
誕生和發展
- 1991年,第一個Python編譯器(同時也是直譯器)誕生。它是用C語言實現的,並能夠呼叫C庫(.so檔案)。從一開始,Python已經具有了 類、函數、例外處理、包含表和詞典在內的核心數據型別以及模組爲基礎的拓展系統。
- 2000年,Python 2.0 由BeOpenPythonLabs團隊發佈,加入記憶體回收機制 機製,奠定了Python語言框架的基礎
- 2008年,Python 3 在一個意想不到的情況下發布了,對語言進行了徹底的修改,沒有向後相容
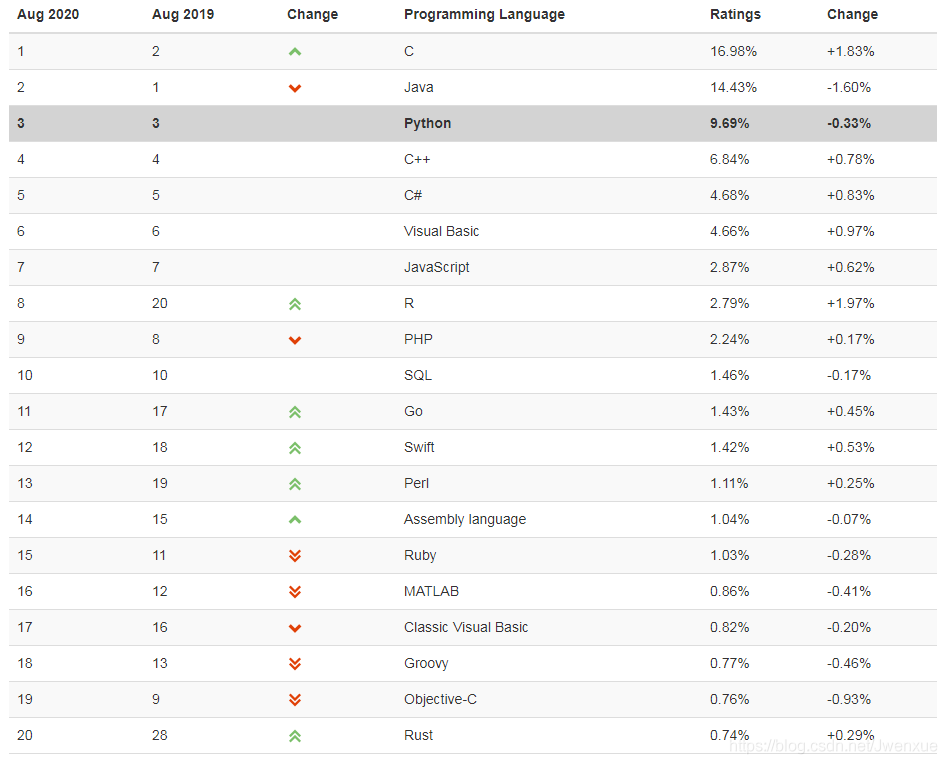
2020年8月份程式語言排行榜
Python典型應用方向
- 數據分析:對數據進行清洗、去重、規格化和針對性的分析是大數據行業的基石。Python是數據分析的主流語言之一,其它如R、SAS、Perl等
- 科學計算:隨着NumPy、SciPy、Matplotlib、Pandas等衆多程式庫的開發,Python越來越適合於做科學計算、繪製高品質的2D和3D影象
- 人工智慧:Python在人工智慧大範疇領域內的機器學習、神經網路、深度學習等方面都是主流的程式語言,得到廣泛的支援和應用。主流的深度學習框架如TensorFlow、Torch、Caffe等都支援Python,甚至大部分官方推薦使用Python
- 常規軟件開發:支援函數語言程式設計和OOP物件導向程式設計,適用於常規的軟件開發、指令碼編寫、網路程式設計
- 雲端計算:開源雲端計算解決方案OpenStack就是基於Python開發的
- 網路爬蟲:大數據行業獲取數據的核心工具。Python是編寫網路爬蟲的主流程式語言,Scrapy爬蟲框架應用非常廣泛
- WEB開發:基於Python的Web開發框架很多,如Django,Tornado,Flask
- 自動化運維:運維工程師首選的程式語言
2. 基本語法
2.1 安裝
Python是跨平臺的,可以執行在Windows、Mac和各種Unix/Linux系統上,安裝方法請自行查詢。
目前,Python有兩個版本,一個是2.x版,一個是3.x版,這兩個版本是不相容的,本教學以Python3.5版本爲基礎(Windows上安裝時注意新增環境變數)。
Python程式碼是以.py爲擴充套件名的文字檔案,要執行程式碼,需要安裝Python直譯器:
- CPython:官方預設編譯器,安裝Python後直接獲得該直譯器,以>>>作爲提示符
- Ipython:基於Cpython的一個互動式直譯器,用In [序號]: 作爲提示符
- 其他:如PyPy(採用JIT技術,執行速度快)、Jython(執行在Java平臺)、IronPython
2.2 Python數據結構
2.2.1 數位(Number)
Python Number 數據型別用於儲存數值,包括整型、長整型、浮點型、複數。
Python原生支援常用數位運算,例如加、減、乘、除、冪等
Python中其它數學運算常用的函數基本都在math 模組:

Python 亂數
- 隨機生成一個[0,1)範圍內的實數

- 隨機生成一個[1,20)範圍內的整數

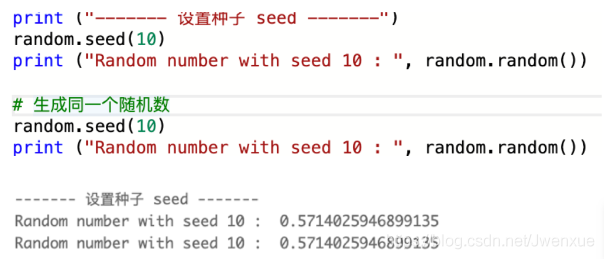
- 當使用random.seed(x) 設定好種子之後,random() 生成的亂數將會是同一個
2.2.2 字串(String)
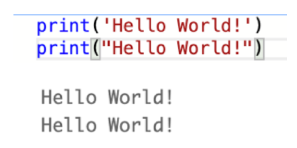
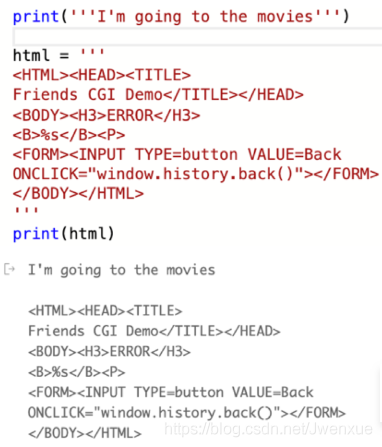
- 單引號、雙引號、三引號:Python中的字串可以使用單引號、雙引號和三引號(三個單引號或三個雙引號)括起來,使用反斜槓\跳脫特殊字元

- 字串連線
使用+運算子:

使用join運算子:

2.2.3 列表(List)
宣告一個列表,並使用下標存取元素:

存取最後一個元素:

存取第一個元素:

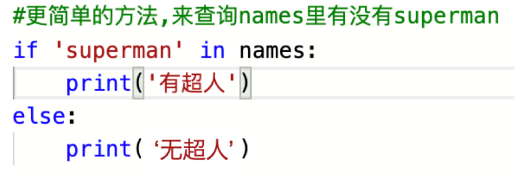
列表查詢:查詢names列表中有沒有值爲’superman’的元素

列表新增:
- append():在列表末尾追加元素

- extend():合併列表

- insert():在指定位置新增

列表修改:
- 修改指定元素

- 將fruits列表中的‘香蕉’替換爲‘banana’

列表刪除:
- del()函數:刪除列表指定元素

- remove():

- pop():

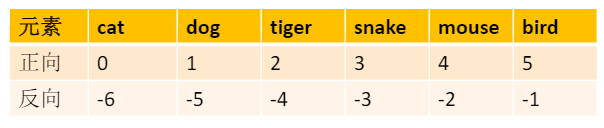
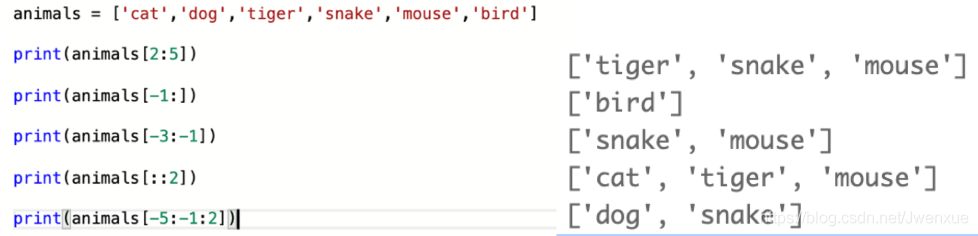
列表切片:[]中設定要使用的第一個元素和最後一個元素的索引。牢記:左閉右開。
假設列表元素爲:
列表排序:
生成10個不同的亂數,存至列表中,並進行排序


2.2.4 元組(Tuple)
與列表類似,區別是元組中的內容不可修改。
定義無組:定義一個元組,注意元組中只有一個元素時,需要在後面加逗號。

列錶轉元組:
元組不能修改,所以不存在往元組裏加入元素。那作爲容器的元組,如何存放元素?

元組擷取:

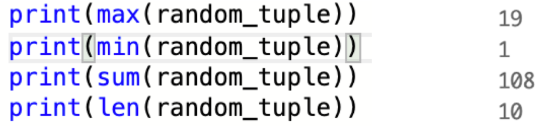
元組的一些函數:max()、min()、sum()、len()這些函數針對序列都是通用的,例如列表、元組、集合等。
元組的拆包與裝包
-
元組元素個數與變數個數相等:

- 元組元素個數與變數個數不相等:

2.2.5 字典(Dict)
-
定義一個空字典:注意與定義空集合的區別
-
定義一個字典的同時,進行初始化

- 定義一個字典,之後新增元素

-
修改字典元素

- 字典相關函數
items():
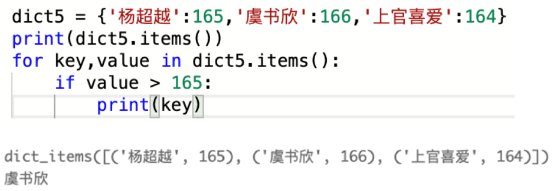
keys():

values():

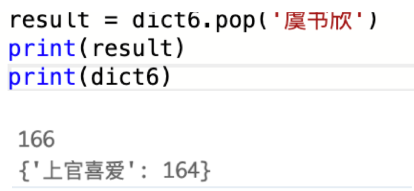
字典刪除:
- del()

- pop()
2.3 類
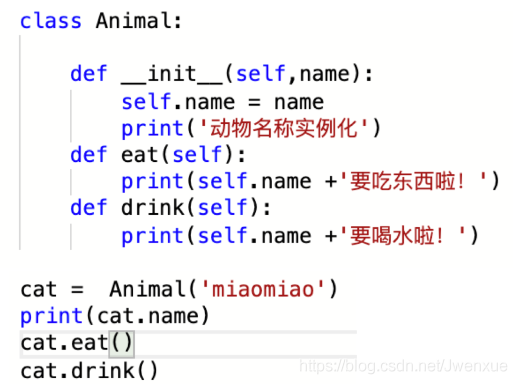
定義一個類Animals:
- init()定義建構函式,與其他物件導向語言不同的是,Python語言中,會明確地把代表自身範例的self作爲第一個參數傳入
- 建立一個範例化物件cat,init()方法接收參數
- 使用點號.來存取物件的屬性。

通過繼承建立的新類稱爲子類或派生類,被繼承的類稱爲基礎類別、父類別或超類。


2.4 Python JSON
JSON序列化與反序列化
- JSON序列化:json.dumps用於將Python 物件編碼成JSON 字串。


- JSON反序列化:json.loads用於解碼JSON 數據。該函數返回Python 欄位的數據型別。

![]()
2.5 Python例外處理
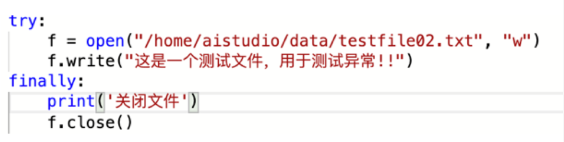
- try/except語句用來檢測try語句塊中的錯誤,從而讓except語句捕獲異常資訊並處理。
- finally中的內容,退出try時總會執行。常常用來關閉檔案、釋放資源等操作。

3. 機器學習常用庫
3.1 Numpy庫
Numpy(Numerical Python的簡稱)是高效能科學計算和數據分析的基礎包。其部分功能如下:
- ndarray,一個具有向量算術運算和複雜廣播能力的快速且節省空間的多維陣列。
- 用於對整組數據進行快速運算的標準數學函數(無需編寫回圈)。
- 用於讀寫磁碟數據的工具以及用於操作記憶體對映檔案的工具。
- 線性代數、亂數生成以及傅裡葉變換功能。
- 用於整合由C、C++、Fortran等語言編寫的程式碼的工具。
3.2 Pandas庫
Pandas庫介紹:
- Pandas是python第三方庫,提供高效能易用數據型別和分析工具
- Pandas基於Numpy實現,常與Numpy和Matplotlib並稱爲機器學習三駕馬車。也有四駕馬車的叫法:NumPy、Pandas、Matplotlib、Seaborn,其中Seaborn是基於Matplotlib的高階封裝,提供了許多繪圖模板。
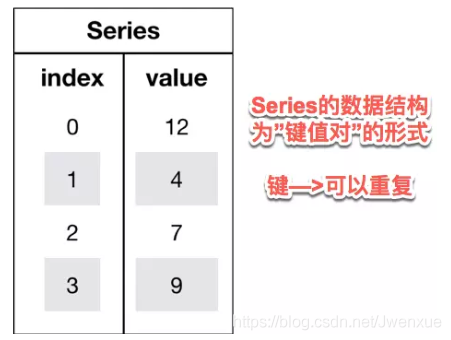
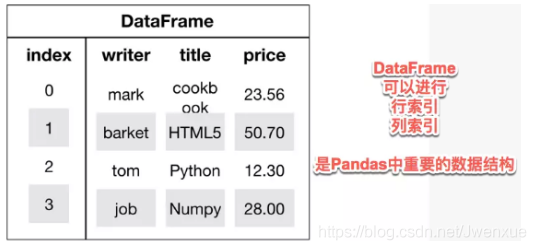
- Pandas中有兩大核心數據結構:Series(一維數據)和DataFrame(多特徵數據,既有行索引,又有列索引)
3.3 PIL庫
PIL庫介紹:
- PIL庫是一個具有強大影象處理能力的第三方庫
- 在命令列下的安裝方法:pip install pillow
- 在使用過程中的引入方法:from PIL import Image
- Image 是PIL 庫中代表一個影象的類(物件)
3.4 Matplotlib庫

Matplotlib庫介紹:
- Matplotlib庫由各種視覺化類構成,內部結構複雜
- 受Matlab啓發,matplotlib.pylot是繪製各類視覺化圖形的命令字型檔,相當於快捷方式
4. 深度學習平臺
4.1 主流的深度學習平臺
目前市面上存在很多深度學習框架,那麼如何選擇一款合適的框架進行學習、研究或落地呢?
總體的一個建議是:
- 如果是深度學習新手,建議選擇Keras進行學習,因爲其簡單、容易上手。
- 如果是出於研究目的,建議選擇PyTorch,好多頂會論文、優秀專案都是基於PyTorch的。
- 如果是基於落地生產、平臺部署等目的,建議選擇TensorFlow,谷歌出品,必屬精品,在工業支援方面做的非常優秀。
- 其它目的或領域,相信您有能力找到一個合適的框架。
4.1.1 TensorFlow

TensorFlow是歌基於C++開發、發佈的第二代機器學習系統。開發目的是用於進行機器學習和深度神經網路的研究。但內部概念衆多,結構複雜,API繁重上手困難,版本迭代快而API相容性存在問題。
TensorFlow官網:https://www.tensorflow.org/ (國內可能打不開)
TensorFlow中文官網:https://tensorflow.google.cn/
github專案地址:https://github.com/tensorflow/tensorflow
4.1.2 PyTorch

PyTorch是Facebook在深度學習框架Torch的基礎上使用Python重寫的一個全新的深度學習框架,它更像NumPy的替代產物,但其模型部署難度較高,對於工業界應用支援存在比較明顯的缺陷。
PyTorch官網:https://pytorch.org/
github專案地址:https://github.com/pytorch/pytorch
4.1.3 Keras
4.1.4 MXNet
4.1.5 PaddlePaddle

飛槳是以百度多年的深度學習技術研究和業務應用爲基礎,集深度學習核心框架、基礎模型庫、端到端開發套件、工具元件和服務平臺於一體,2016 年正式開源,是全面開源開放、技術領先、功能完備的產業級深度學習平臺。飛槳源於產業實踐,始終致力於與產業深入融合。目前飛槳已廣泛應用於工業、農業、服務業等,服務190 多萬開發者,與合作夥伴一起幫助越來越多的行業完成AI 賦能。
官網:https://www.paddlepaddle.org.cn/
github專案地址:https://github.com/paddlepaddle/paddle
4.2 PaddlePaddle
4.2.1 飛槳的全景
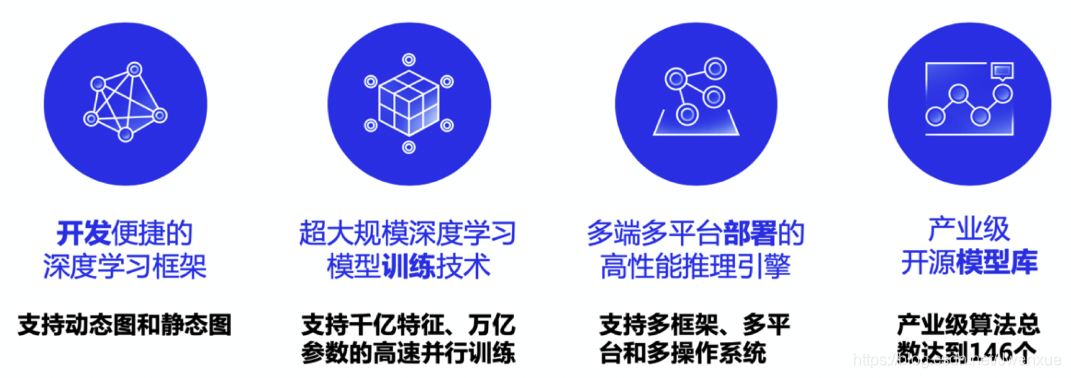
飛槳(PaddlePaddle)以百度多年的深度學習技術研究和業務應用爲基礎,是中國首個開源開放、技術領先、功能完備的產業級深度學習平臺,集深度學習核心訓練和推理框架、基礎模型庫、端到端開發套件和豐富的工具元件於一體。

飛槳四大領先技術:
4.2.2 本地環境搭建
目前飛槳支援以下環境:
- Ubuntu 14.04 /16.04 /18.04
- CentOS 7 / 6
- MacOS 10.11 / 10.12 / 10.13 / 10.14
- Windows7 / 8/ 10 (專業版/企業版)
飛槳支援使用pip快速安裝,執行下面 下麪命令完成CPU版本的快速安裝:
pip install paddlepaddle-i https://pypi.tuna.tsinghua.edu.cn/simple
如需安裝GPU版本的飛槳PaddlePaddle,或查詢更詳細的安裝方法,請參考安裝說明:
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/index_cn.html
4.3 AI Studio平臺
AI Studio是一站式深度學習開發平臺,集開放數據、開源演算法、免費算力三位一體,爲開發者提供高效學習和開發環境、高價值高獎金競賽專案,支撐高校老師輕鬆實現AI教學,並助力開發者加速落地AI業務場景。

官網地址:http://aistudio.baidu.com/
幫助文件:https://ai.baidu.com/docs#/AIStudio_Tutorial/top
5. 深度學習基礎
5.1 深度學習概述
5.1.1 什麼是人工智慧
人工智慧(Artificial Intelligence),英文縮寫爲AI。它是研究、開發用於模擬、延伸和擴充套件人的智慧的理論、方法、技術及應用系統的一門新技術科學。
- 結構模擬:機器人學
- 功能模擬:以任務爲核心,例如模式識別、機器學習、深度學習自然語言處理、音訊識別、定位跟蹤、影象理解、知識推理、數據預測等等
總結來說:人工智慧就是使一部機器的反應方式像人一樣進行感知、認知、決策、執行的人工程式或系統。
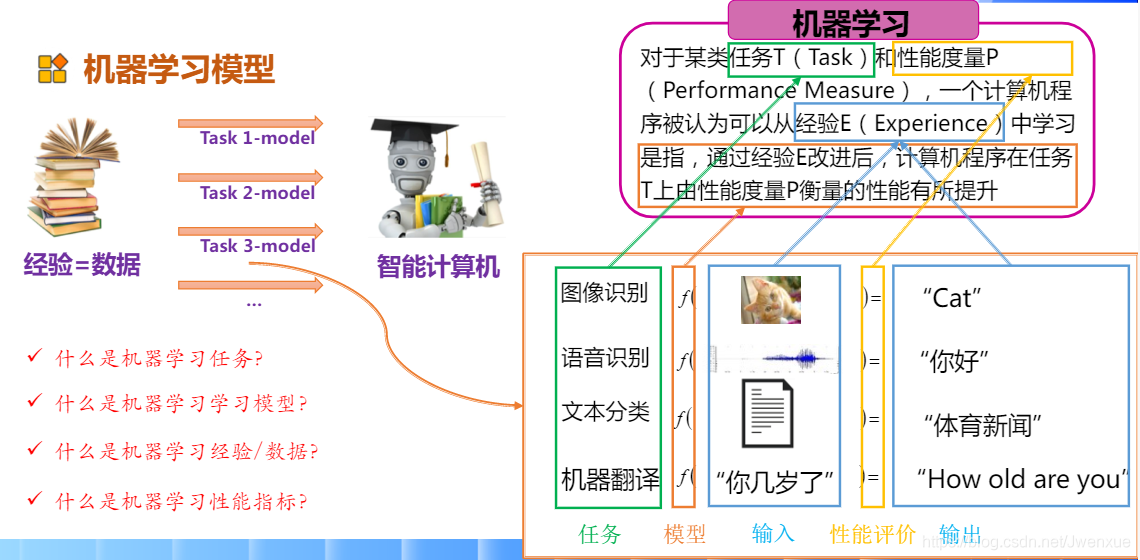
5.1.2 什麼是機器學習
5.1.3 什麼是深度學習
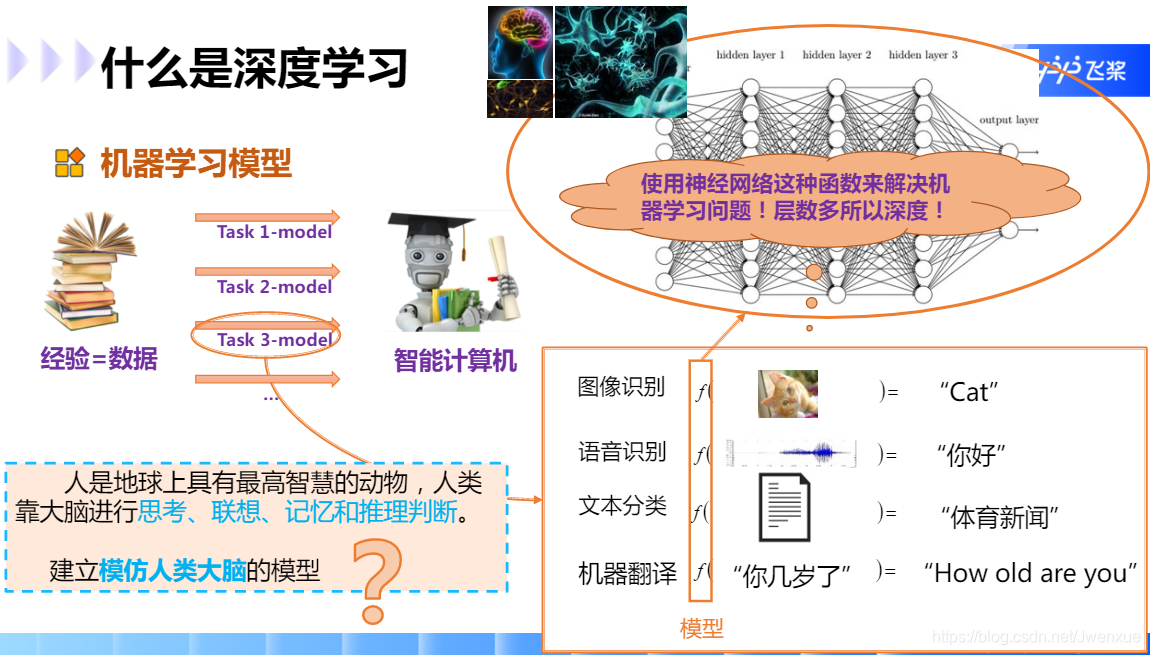
5.1.4 深度學習發展歷程
- 第一次高潮:
1962年,Frank Rosenblatt 提出感知器模型
1969年,M.Minsky 等人指出感知器不能解決高階謂詞問題和互斥或問題,將感知器拉下神壇
-
第二次高潮:
人工智慧對自動制導車的失敗,而利用神經網路有可能解決這個問題,導致了人工神經網路的第二次高潮。
1986年,Rumelhart等提出多層網路的學習演算法—反向傳播演算法
-
第三次高潮:
2006年,深度學習被提出,開始使用更深的網路模型。
2012年,深度學習演算法在語言和視覺識別上實現突破。
5.2 深度學習入門知識
5.2.1 生物神經元
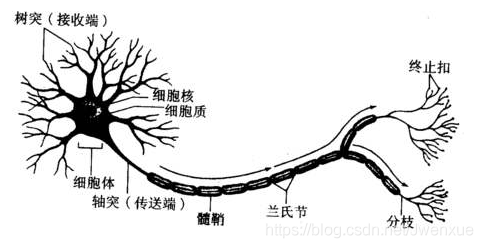
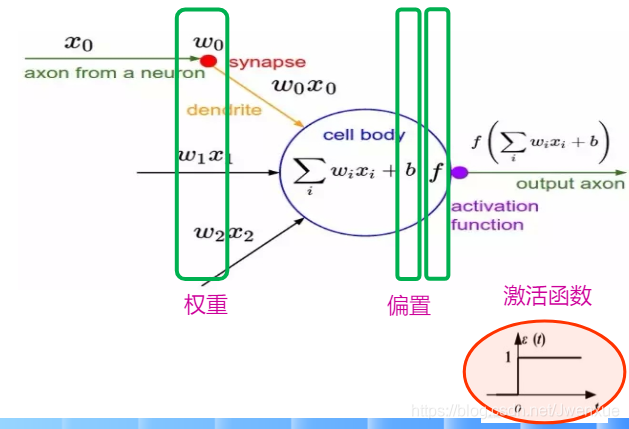
生物神經元:
- 神經元間通過突觸兩兩相連
- 樹突接收來自多個神經元的信號
- 軸突根據樹突傳遞過來的綜合信號的強弱是否超過某一閾值來決定是否將該信號傳遞給下一個神經元
生物神經元的啓示:
- 每個神經元都是一個多輸入單輸出的信號處理單元
- 神經元具有閾值特性
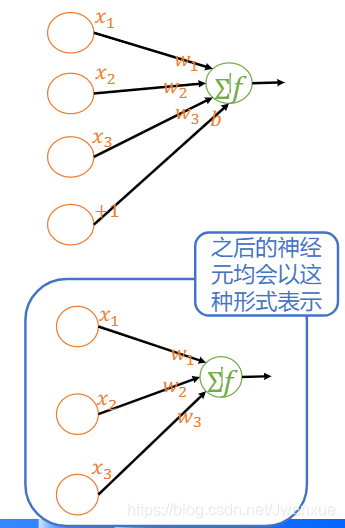
5.2.2 人工神經元
5.2.3 啓用函數
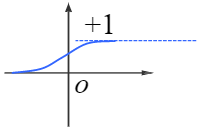
- Sigmoid函數:
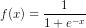 ,導數表達式爲:
,導數表達式爲: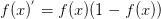
-
tanh(雙曲正切)函數:
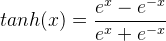 ,導數表達式爲:
,導數表達式爲: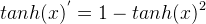
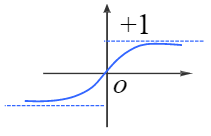
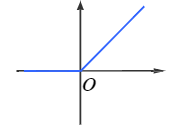
- ReLU函數:
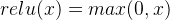 ,導數表達式爲:
,導數表達式爲: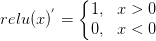
5.2.4 多層神經網路
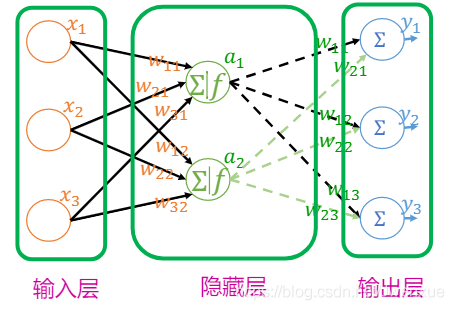
- 輸入層:接收輸入信號的層
- 隱含層:不直接與外部環境打交道,隱含層的層數可從零到若幹層
- 輸出層:產生輸出信號的層
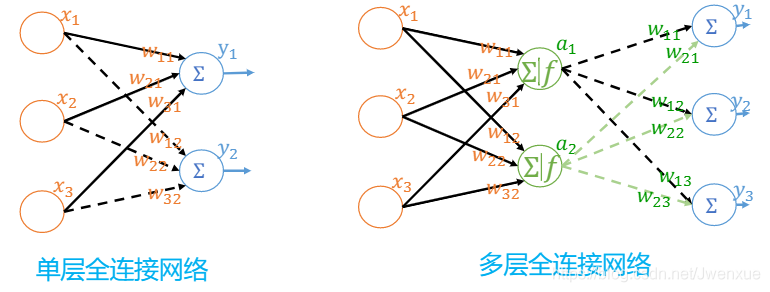
5.2.5 全連線神經網路
前饋/全連線神經網路:每層每個節點均和上一層的所有節點相連
全連線/前饋神經網路是能解決很多問題,但是本身存在一個問題,對於某些數據而言,一是參數量巨大,二是不能充分應用數據的某些特性。
5.2.6 折積神經網路(CNN)
- 引入特性:區域性連線(影象區域性上下文)
- 輸入層:不是向量,而是一個三維陣列(影象)
- 折積層:對三維陣列及其權重的計算方式。折積核(參數)在通過逐一滑動視窗計算而得
- 池化/採樣層:直接抽樣選取極小區域性的某一元素作爲下一層的元素。有最大池化和平均池化。
折積神經網路就相當於一個黑盒,輸入影象經過黑盒(折積神經網路)輸出一些提取的特徵。
經典折積神經網路有:LeNet、AlexNet、VGGNet、GoogLeNet、ResNet等。
5.2.7 回圈神經網路(RNN)
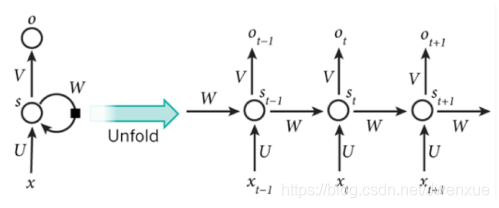
- 引入特性:時序,處理序列數據(文字上下文)
- 對序列數據的處理:每次輸入序列中的一個單元,然後儲存每一個隱層神經元的計算結果,留給下一個輸入時該神經元進行使用
- 歷史資訊:儲存的隱層單元計算結果,含有上一次輸入的資訊
經典RNN網路有:LSTM、GRU、Bi-RNN、Seq2Seq