網路數據包的解析以及數據大小端的處理
數據結構體的定義
本文的目標是基於本人所遇到的錯誤和採用的糾正方法,以tcp和ip協定爲例,對數據包普適的解析方式作一定程度的總結,並提供了一些常用的輔助函數作爲參考。
程式語言:c語言
一、前言
1.我們的輸入和輸出
一般通過libpcap等開源庫可以捕獲的數據包都是一個特定長度的unsigned char型別的無符號字元型陣列,關於數據包的捕獲不在本文的討論範圍內。假定我們可以正確地捕獲網路中的數據包,並且每個數據包都賦給無符號陣列,其指針爲宣告如下:
const unsigned char *pkt_data;
這些數據按照大端法排列,也就是按照我們平時理解的位元組順序。同時我們知道陣列的有效長度。
輸出是我們解析數據包所要獲得的各種欄位的值。
2.我們將獲得的數據賦給什麼型別的變數
c語言爲我們提供了8位元、16位元、32位元和64位元4種長度的變數,因爲數據包一個欄位的數據一般不會超過32位元,所以我們考慮使用8位元、16位元、32位元作爲變數的型別。
這裏要注意,雖然有的協定中的某些欄位長度小於8位元,結構體也允許我們定義任意位的變數,比如一個3位的a和一個5位的b,但是我們卻不能這樣定義這兩個變數:
struct data{
int a:3;
int b:5;
};
因爲它們在小端機器上執行時很容易出錯,具體原因後面會分析。正確的方法是先取一個或兩個位元組,然後用位運算定位這個值。
而考慮到有的欄位中的數據可能將所有位佔滿,我們最好使用無符號型別的數據(有符號數據型別的第一位爲符號位),以避免不必要的麻煩。
二、鏈路層結構體
先看鏈路層頭部的圖示:
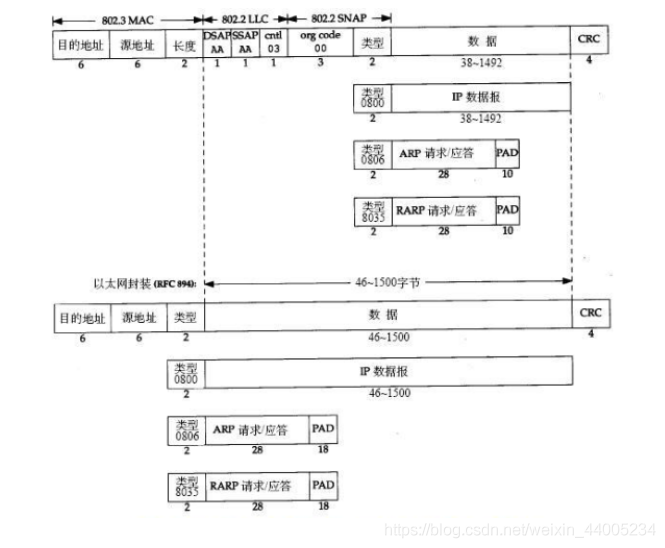
可以看到鏈路層數據包有3個欄位,分別是目的mac地址,源mac地址,而如果網路層的協定爲ip,第三個欄位表示的就是協定型別,這也是我們分析的例子。
下面 下麪是鏈路層頭部的宣告:
typedef struct{
unsigned char DestMac[6];
unsigned char SrcMac[6];
unsigned short Etype;
}ETH_HEADER;
mac地址是由6個8位元整型表示的網路地址,我們在struct中直接申請6個元素的陣列,那麼在賦值的時候6個數字將變成陣列的6個元素,同時我們可以使用下面 下麪的函數將mac地址轉化成xx:xx:xx:xx:xx:xx這種格式的字串:
void mac2str(u_char* Mac,unsigned char str[20]){
unsigned char tmp[6];
for(int i=0;i<6;i++){
sprintf(tmp,"%x",Mac[i]);
strcat(str,tmp);
if(i!=5){
strcat(str,":");
}
}
str[strlen(str)]='\0';
}
type欄位是16位元的變數,大端機器直接使用,小端機器用ntohs()函數轉爲大端後使用。
用下面 下麪程式碼獲得鏈路層頭部物件:
ETH_HEADER* eth_header=(ETH_HEADER*)pkt_data;
三、網路層結構體(以ip協定爲例)
ip首部圖示:
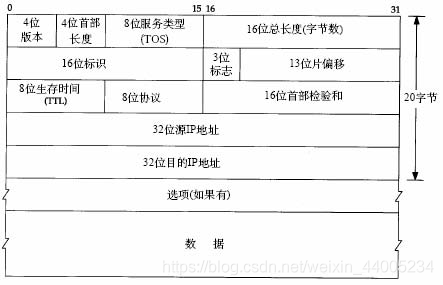
ip協定中協定版本欄位和首部長度欄位都是4位元變數,服務型別、生存時間、運輸層協定版本是8位元變數,總長度、校驗和是16位元,ip使用類似之前mac的處理方式。下面 下麪是ip頭部的宣告。
typedef struct{
unsigned char version_headerLen; //need bit operation
unsigned char tos;
unsigned short totalLen;
unsigned short packetId;
unsigned short sliceInfo;
unsigned char ttl;
unsigned char proto;
unsigned short checksum;
unsigned char srcIP[4];
unsigned char destIP[4];
}IP_HEADER;
下面 下麪的程式碼將ip陣列轉成xx.xx.xx.xx格式的字串:
void ip2str(u_char* IP,unsigned char str[20]){
unsigned char tmp[4];
for(int i=0;i<4;i++){
//itoa(IP[i],tmp,10);
sprintf(tmp,"%d",IP[i]);
strcat(str,tmp);
if(i!=3){
strcat(str,".");
}
}
}
用下面 下麪的函數獲取正確的tcp頭部:
unsigned int get_ip_header_len(IP_HEADER* ip_header){
return ((ip_header->version_headerLen)&0xf)*4;
}
由於鏈路層頭部爲固定長度14個位元組,我們用下面 下麪的程式碼獲得ip頭部:
IP_HEADER* ip_header=(IP_HEADER*)(pkt_data+14);
四、運輸層結構體(以tcp協定爲例)
tcp首部圖示:

tcp頭部其他大於等於8位元組的數據使用相應的變數型別賦值,然後根據需要通過ntohl()或ntohs()調整大小端。
而tcp首部長度和一些flag位於同一雙字內,如果直接讀取在小端機器會發生錯誤,我們考慮先放到一個雙字中,然後宣告新的結構體和函數進行處理。
typedef struct{
unsigned short SrcPort;
unsigned short DestPort;
unsigned int SeqNum;
unsigned int AckNum;
unsigned short headerLen_flags; //need bit operation
unsigned short winSize;
unsigned short checkSum;
unsigned short urgPtr;
}TCP_HEADER;
flag結構體宣告,可以根據需要增加其他flag:
typedef struct{
unsigned char urg:1;
unsigned char ack:1;
unsigned char psh:1;
unsigned char rst:1;
unsigned char syn:1;
unsigned char fin:1;
}TCP_FLAGS;
下面 下麪的程式碼獲取了正確的flag結構體:
//呼叫程式碼段
TCP_FLAGS* tcp_flags=(TCP_FLAGS*)malloc(sizeof(TCP_FLAGS));
get_tcp_flags(tcp_flags,tcp_header->headerLen_flags);
//函數申明
void get_tcp_flags(TCP_FLAGS* tcp_flags,unsigned short headerlen_flags){
headerlen_flags=ntohs(headerlen_flags);
tcp_flags->urg=(headerlen_flags&0x20)>>5;
tcp_flags->ack=(headerlen_flags&0x10)>>4;
tcp_flags->psh=(headerlen_flags&0x8)>>3;
tcp_flags->rst=(headerlen_flags&0x4)>>2;
tcp_flags->syn=(headerlen_flags&0x2)>>1;
tcp_flags->fin=headerlen_flags&0x1;
}
獲取tcp頭部長度:
unsigned int get_tcp_header_len(TCP_HEADER* tcp_header){
return (((tcp_header->headerLen_flags)&0xf0)>>4)*4;
}
由於ip頭部的長度不是定長,在獲取tcp頭部的時候需要先解析ip首部中ip首部的長度,然後再定位到tcp頭部:
int ip_header_len=get_ip_header_len(ip_header);
TCP_HEADER* tcp_header=(TCP_HEADER*)(pkt_data+14+ip_header_len);
同樣的,tcp首部長度也不固定,後面的payload同樣需要先獲取tcp首部長度,然後定位起始位置。
數據大小端的處理
一、前言
數據大小端的差異與機器的儲存方式有關,而與傳輸方式無關。也就是說,網路包都是以大端的方式傳輸,而傳輸到本地做解析時如果將變數賦值給本地變數儲存,就可能導致小端儲存法與大端儲存法的差異。
例如下面 下麪的程式碼段,在大端機器上執行得到16909060,在小端機器上執行得到67305985:
unsigned char data[4]={0x1,0x2,0x3,0x4};
printf("%d\n",*((int*)data));
這是因爲在大端機器上當這個四字的數據被轉化成int型別後它的解釋方式依然是0x1020304,而在小端機器上它便被解釋爲0x4030201。
這段程式碼也可以用於檢測執行機器的大小端情況。
二、兩種種大小端的基本情況
1.雙字
雙字在兩種機器上的區別是如果儲存的數據是0x0102,那麼大端機器輸出也是0x0102,小端機器反過來輸出0x0201,可以用下面 下麪的函數將小端轉成大端:
#include <netinet/in.h>
uint16_t ntohs(uint16_t netshort);
具體實現類似下面 下麪的程式碼:
uint16_t ntohs(uint16_t netshort){
return (netshort&0xff00)>>8+(netshort&0xff)<<8;
}
比如埠號之類16位元的變數在小端機器都需要呼叫該函數轉爲大端序。
2.四字
四字在兩種機器上的區別就是如果儲存爲0x01020304,那麼在大端機器上輸出就是0x01020304,在小端機器需要呼叫下面 下麪的函數進行轉換:
#include <netinet/in.h>
uint32_t ntohl(uint32_t netlong);
具體實現可能如下:
uint32_t ntohl(uint32_t netlong){
return (netlong&0xff000000)>>24+(netlong&0xff0000)>>8+(netlong&0xff00)<<8+(netlong&0xff)<<24;
}
在小端機器上,如32位元確認號等欄位都需要用這個函數進行轉換。
三、特殊情況
我們以tcp協定中這個位置的數據爲例:

在小端機器如果我們定義下面 下麪的結構體:
struct tcp_header{
unsigned char headerLen:4;
unsigned char reserved:6;
unsigned char urg:1;
unsigned char ack:1;
unsigned char psh:1;
unsigned char rst:1;
unsigned char syn:1;
unsigned char fin:1;
};
那麼在解析headerLen時實際上獲得的是psh<<4+rst<<3+syn<<2+fin,最好的解決方法就是用ntohl將整個32位元反轉,然後用位運算按照順序解析每一個欄位,可以有效避免錯誤(這個四字的解析程式碼詳見上文)。