[ML-04] Numpy-1
一、Numpy的優勢
1 Numpy介紹

Numpy(Numerical Python)是一個開源的Python科學計算庫,用於快速處理任意維度的陣列。
Numpy支援常見的陣列和矩陣操作。對於同樣的數值計算任務,使用Numpy比直接使用Python要簡潔的多。
Numpy使用ndarray物件來處理多維陣列,該物件是一個快速而靈活的大數據容器。
2 ndarray介紹
NumPy provides an N-dimensional array type, the ndarray,
which describes a collection of 「items」 of the same type.
NumPy提供了一個N維陣列型別ndarray,它描述了相同類型的「items」的集合。
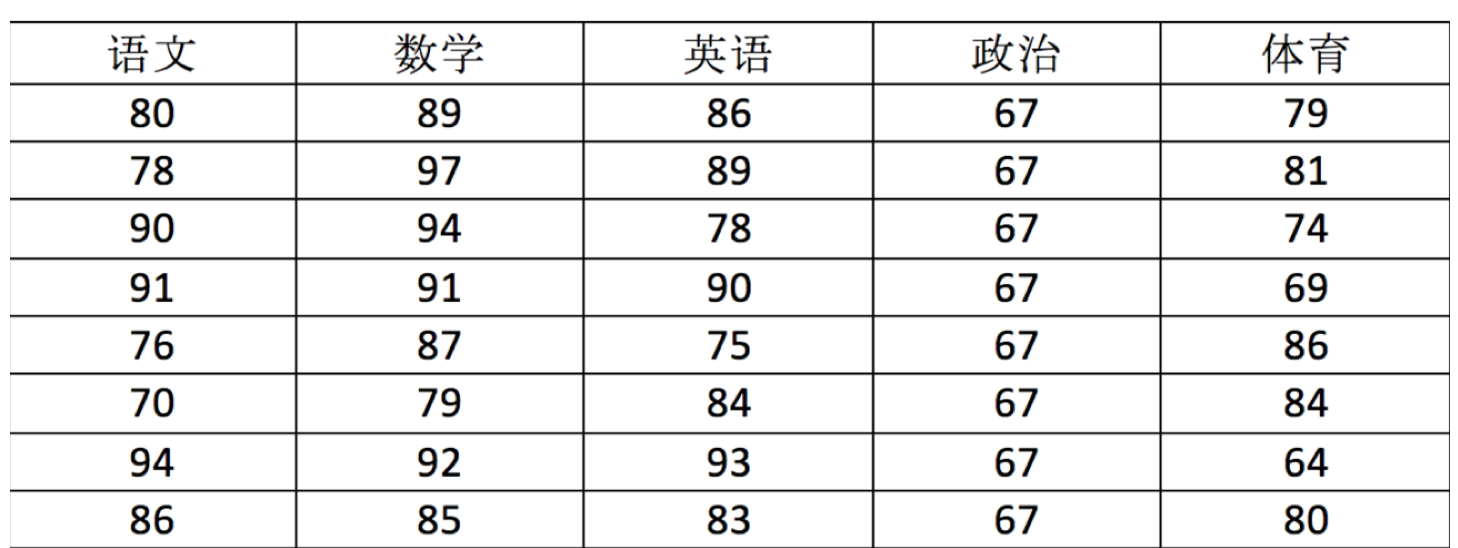
用ndarray進行儲存:
import numpy as np
# 建立ndarray
score = np.array(
[[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
score
返回結果:
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
3 ndarray與Python原生list運算效率對比
在這裏我們通過一段程式碼執行來體會到ndarray的好處
import random
import time
import numpy as np
a = []
for i in range(100000000):
a.append(random.random())
# 通過%time魔法方法, 檢視當前行的程式碼執行一次所花費的時間
%time sum1=sum(a)
b=np.array(a)
%time sum2=np.sum(b)
其中第一個時間顯示的是使用原生Python計算時間,第二個內容是使用numpy計算時間:
CPU times: user 852 ms, sys: 262 ms, total: 1.11 s
Wall time: 1.13 s
CPU times: user 133 ms, sys: 653 µs, total: 133 ms
Wall time: 134 ms
從中我們看到ndarray的計算速度要快很多,節約了時間。
機器學習的最大特點就是大量的數據運算,那麼如果沒有一個快速的解決方案,那可能現在python也在機器學習領域達不到好的效果。
Numpy專門針對ndarray的操作和運算進行了設計,所以陣列的儲存效率和輸入輸出效能遠優於Python中的巢狀列表,陣列越大,Numpy的優勢就越明顯。
4 ndarray的優勢
4.1 記憶體塊風格
ndarray到底跟原生python列表有什麼不同呢,請看一張圖:
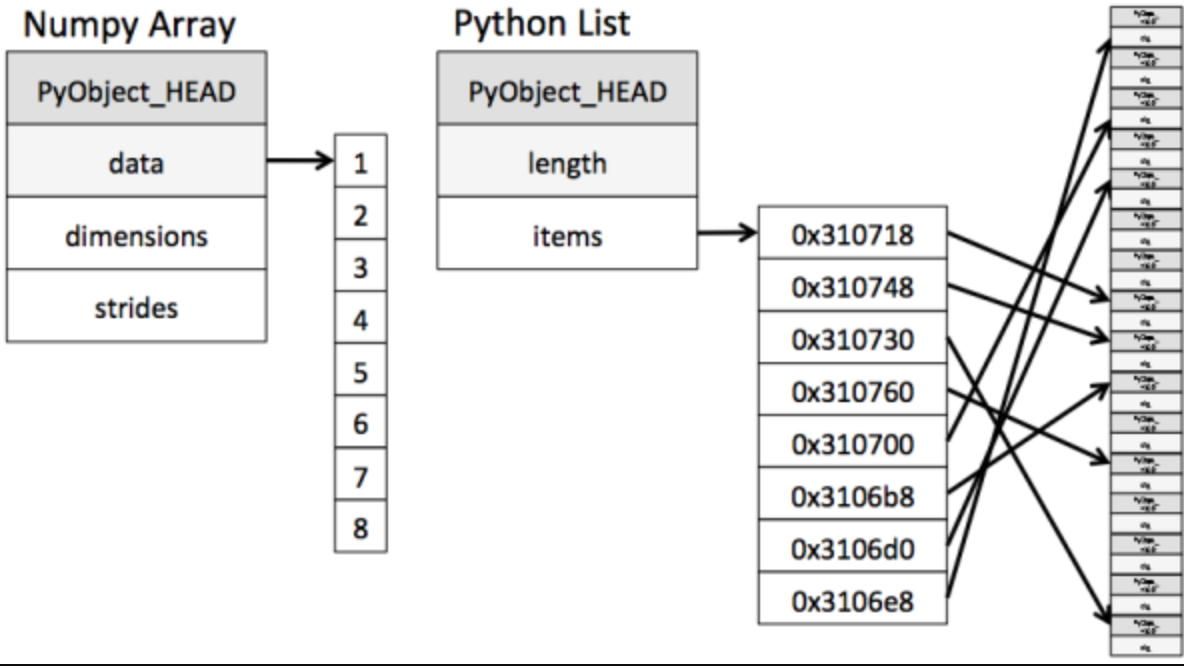
從圖中我們可以看出ndarray在儲存數據的時候,數據與數據的地址都是連續的,這樣就給使得批次運算元組元素時速度更快。
這是因爲ndarray中的所有元素的型別都是相同的,而Python列表中的元素型別是任意的,所以ndarray在儲存元素時記憶體可以連續,而python原生list就只能通過定址方式找到下一個元素,這雖然也導致了在通用效能方面Numpy的ndarray不及Python原生list,但在科學計算中,Numpy的ndarray就可以省掉很多回圈語句,程式碼使用方面比Python原生list簡單的多。
4.2 ndarray支援並行化運算(向量化運算)
numpy內建了並行運算功能,當系統有多個核心時,做某種計算時,numpy會自動做並行計算
4.3 效率遠高於純Python程式碼
Numpy底層使用C語言編寫,內部解除了GIL(全域性直譯器鎖),其對陣列的操作速度不受Python直譯器的限制,所以,其效率遠高於純Python程式碼。
二、N維陣列-ndarray
1 ndarray的屬性
陣列屬性反映了陣列本身固有的資訊。
| 屬性名字 | 屬性解釋 |
|---|---|
| ndarray.shape | 陣列維度的元組 |
| ndarray.ndim | 陣列維數 |
| ndarray.size | 陣列中的元素數量 |
| ndarray.itemsize | 一個數組元素的長度(位元組) |
| ndarray.dtype | 陣列元素的型別 |
2 ndarray的形狀
首先建立一些陣列。
# 建立不同形狀的陣列
>>> a = np.array([[1,2,3],[4,5,6]])
>>> b = np.array([1,2,3,4])
>>> c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
分別列印出形狀
>>> a.shape
>>> b.shape
>>> c.shape
(2, 3) # 二維陣列
(4,) # 一維陣列
(2, 2, 3) # 三維陣列
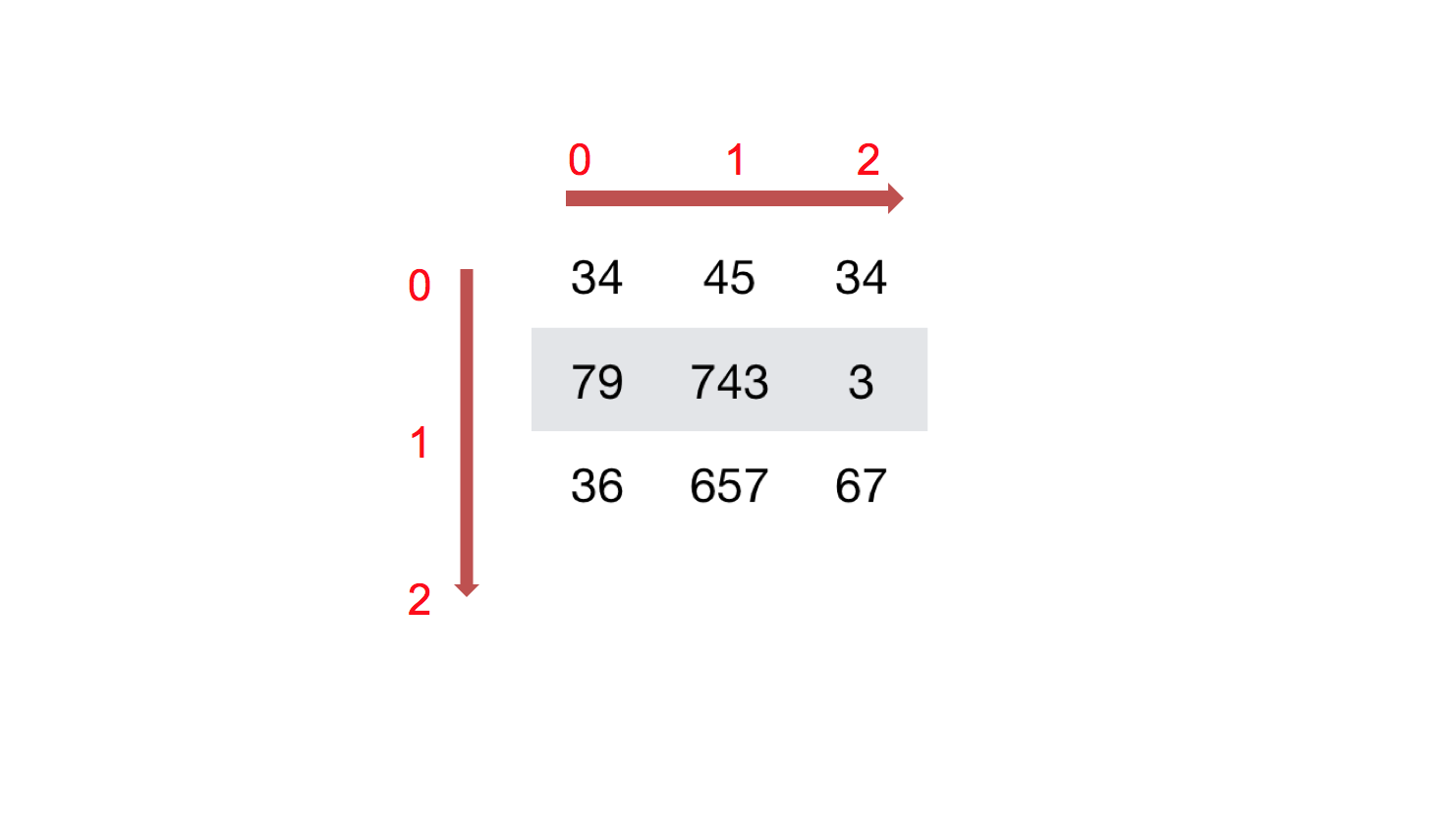
如何理解陣列的形狀?
二維陣列:
三維陣列:
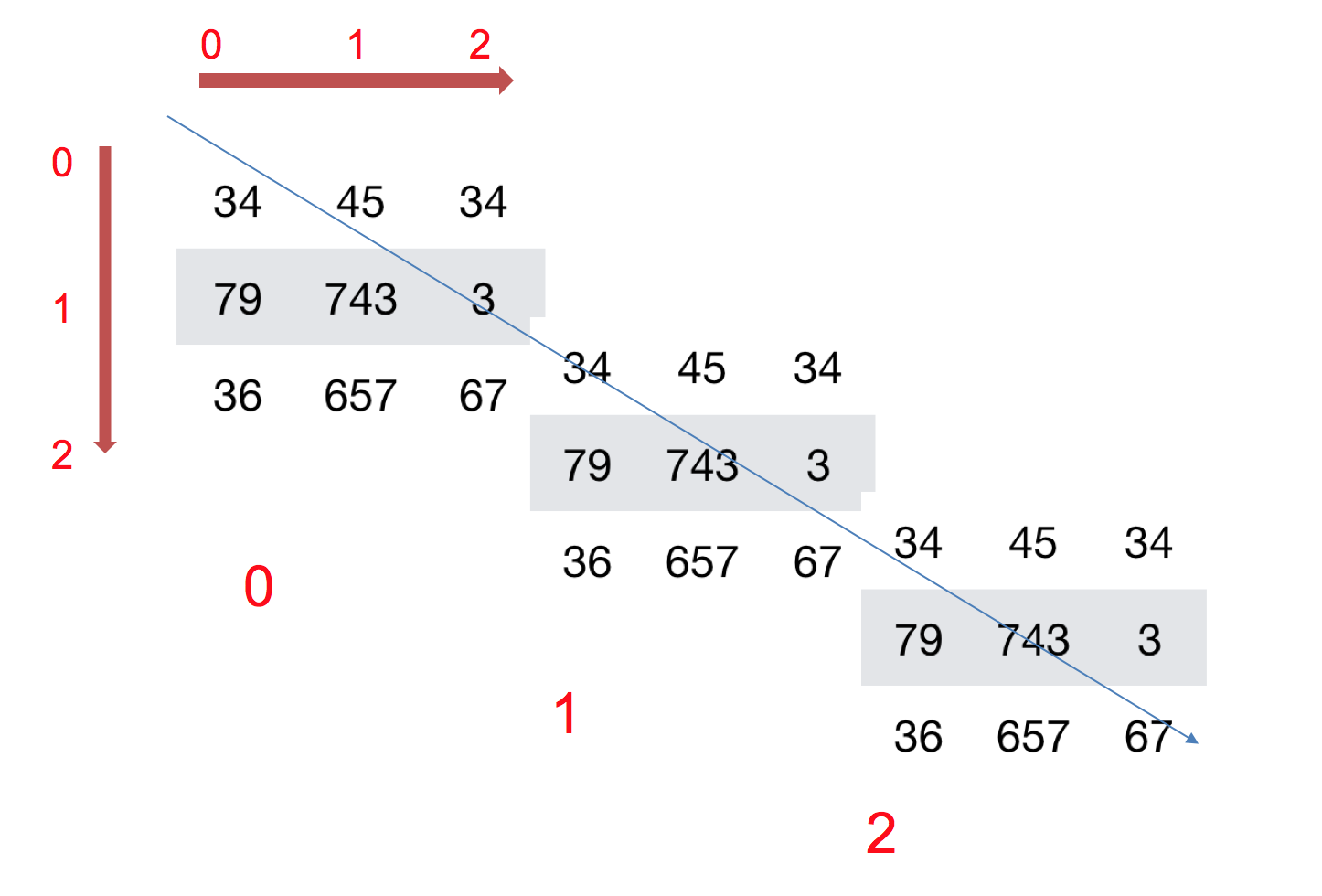
3 ndarray的型別
>>> type(score.dtype)
<type 'numpy.dtype'>
dtype是numpy.dtype型別,先看看對於陣列來說都有哪些型別
| 名稱 | 描述 | 簡寫 |
|---|---|---|
| np.bool | 用一個位元組儲存的布爾型別(True或False) | ‘b’ |
| np.int8 | 一個位元組大小,-128 至 127 | ‘i’ |
| np.int16 | 整數,-32768 至 32767 | ‘i2’ |
| np.int32 | 整數,-2^31 至 2^32 -1 | ‘i4’ |
| np.int64 | 整數,-2^63 至 2^63 - 1 | ‘i8’ |
| np.uint8 | 無符號整數,0 至 255 | ‘u’ |
| np.uint16 | 無符號整數,0 至 65535 | ‘u2’ |
| np.uint32 | 無符號整數,0 至 2^32 - 1 | ‘u4’ |
| np.uint64 | 無符號整數,0 至 2^64 - 1 | ‘u8’ |
| np.float16 | 半精度浮點數:16位元,正負號1位,指數5位,精度10位 | ‘f2’ |
| np.float32 | 單精度浮點數:32位元,正負號1位,指數8位元,精度23位 | ‘f4’ |
| np.float64 | 雙精度浮點數:64位元,正負號1位,指數11位,精度52位 | ‘f8’ |
| np.complex64 | 複數,分別用兩個32位元浮點數表示實部和虛部 | ‘c8’ |
| np.complex128 | 複數,分別用兩個64位元浮點數表示實部和虛部 | ‘c16’ |
| np.object_ | python物件 | ‘O’ |
| np.string_ | 字串 | ‘S’ |
| np.unicode_ | unicode型別 | ‘U’ |
建立陣列的時候指定型別
>>> a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32)
>>> a.dtype
dtype('float32')
>>> arr = np.array(['python', 'tensorflow', 'scikit-learn', 'numpy'], dtype = np.string_)
>>> arr
array([b'python', b'tensorflow', b'scikit-learn', b'numpy'], dtype='|S12')
- 注意:若不指定,整數預設int64,小數預設float64